diff --git a/README.md b/README.md
index b7810b1b1..caaab076b 100644
--- a/README.md
+++ b/README.md
@@ -18,7 +18,7 @@
-**DeepEval** is a simple-to-use, open-source evaluation framework for LLM applications. It is similar to Pytest but specialized for unit testing LLM applications. DeepEval evaluates performance based on metrics such as factual consistency, accuracy, answer relevancy, etc., using LLMs and various other NLP models. It's a production-ready alternative to RAGAS .
+**DeepEval** is a simple-to-use, open-source evaluation framework for LLM applications. It is similar to Pytest but specialized for unit testing LLM applications. DeepEval evaluates performance based on metrics such as hallucination, answer relevancy, RAGAS, etc., using LLMs and various other NLP models **locally on your machine**.
Whether your application is implemented via RAG or fine-tuning, LangChain or LlamaIndex, DeepEval has you covered. With it, you can easily determine the optimal hyperparameters to improve your RAG pipeline, prevent prompt drifting, or even transition from OpenAI to hosting your own Llama2 with confidence.
@@ -26,14 +26,27 @@ Whether your application is implemented via RAG or fine-tuning, LangChain or Lla
# Features
-- Large variety of ready-to-use evaluation metrics, ranging from LLM evaluated (G-Eval) to metrics computed via statistical methods or NLP models.
+- Large variety of ready-to-use evaluation metrics powered by LLMs, statistical methods, or NLP models that runs **locally on your machine**:
+ - Hallucination
+ - Answer Relevancy
+ - RAGAS
+ - G-Eval
+ - Toxicity
+ - Bias
+ - etc.
- Easily create your own custom metrics that are automatically integrated with DeepEval's ecosystem by inheriting DeepEval's base metric class.
-- Evaluate your entire dataset in bulk using fewer than 20 lines of Python code.
-- [Integrated with Confident AI](https://confident-ai.com) for instant observability into evaluation results and hyperparameter comparisons (such as prompt templates and model version used).
+- Evaluate your entire dataset in bulk using fewer than 20 lines of Python code **in parallel**.
+- [Automatically integrated with Confident AI](https://app.confident-ai.com) for continous evaluation throughout the lifetime of your LLM (app):
+ - log evaluation results and analyze metrics pass / fails
+ - compare and pick the optimal hyperparameters (eg. prompt templates, chunk size, models used, etc.) based on evaluation results
+ - debug evaluation results via LLM traces
+ - manage evaluation test cases / datasets in one place
+ - track events to identify live LLM responses in production
+ - add production events to existing evaluation datasets to strength evals over time
-# Getting Started 🚀
+# 🚀 Getting Started 🚀
Let's pretend your LLM application is a customer support chatbot; here's how DeepEval can help test what you've built.
@@ -43,9 +56,9 @@ Let's pretend your LLM application is a customer support chatbot; here's how Dee
pip install -U deepeval
```
-## [Optional] Create an account
+## Create an account (highly recommended)
-Creating an account on our platform will allow you to log test results, enabling easy tracking of changes and performances over iterations. This step is optional, and you can run test cases even without logging in, but we highly recommend giving it a try.
+Although optional, creating an account on our platform will allow you to log test results, enabling easy tracking of changes and performances over iterations. This step is optional, and you can run test cases even without logging in, but we highly recommend giving it a try.
To login, run:
@@ -67,9 +80,9 @@ Open `test_chatbot.py` and write your first test case using DeepEval:
```python
import pytest
+from deepeval import assert_test
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
-from deepeval.evaluator import assert_test
def test_case():
input = "What if these shoes don't fit?"
@@ -98,9 +111,61 @@ deepeval test run test_chatbot.py
-# View results on our platform
+## Evaluting a Dataset / Test Cases in Bulk
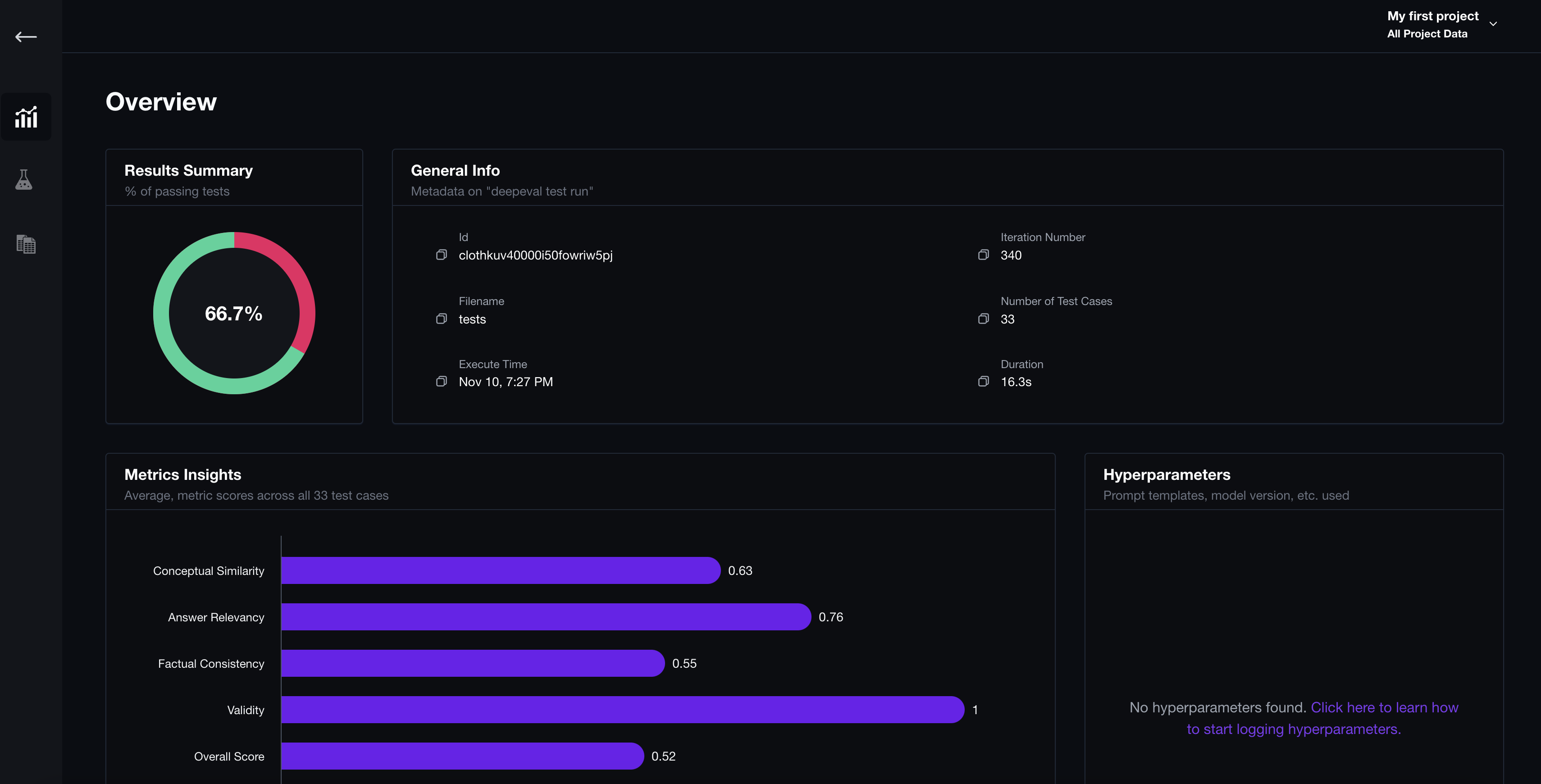
-We offer a [free web platform](https://app.confident-ai.com) for you to log and view all test results from DeepEval test runs. Our platform allows you to quickly draw insights on how your metrics are improving with each test run and to determine the optimal parameters (such as prompt templates, models, retrieval pipeline) for your specific LLM application.
+In DeepEval, a dataset is simply a collection of test cases. Here is how you can evaluate things in bulk:
+
+```python
+import pytest
+from deepeval import assert_test
+from deepeval.metrics import HallucinationMetric, AnswerRelevancyMetric
+from deepeval.test_case import LLMTestCase
+from deepeval.dataset import EvaluationDataset
+
+first_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
+second_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
+
+dataset = EvaluationDataset(test_cases=[first_test_case, second_test_case])
+
+@pytest.mark.parametrize(
+ "test_case",
+ dataset,
+)
+def test_customer_chatbot(test_case: LLMTestCase):
+ hallucination_metric = HallucinationMetric(minimum_score=0.3)
+ answer_relevancy_metric = AnswerRelevancyMetric(minimum_score=0.5)
+ assert_test(test_case, [hallucination_metric, answer_relevancy_metric])
+```
+
+```bash
+# Run this in the CLI, you can also add an optional -n flag to run tests in parallel
+deepeval test run test_.py -n 4
+```
+
+
+
+Alternatively, although we recommend using `deepeval test run`, you can evaluate a dataset/test cases without using pytest:
+
+```python
+from deepeval import evaluate
+...
+
+evaluate(dataset, [hallucination_metric])
+# or
+dataset.evaluate([hallucination_metric])
+```
+
+# View results on Confident AI
+
+We offer a [free web platform](https://app.confident-ai.com) for you to:
+
+1. Log and view all test results / metrics data from DeepEval's test runs.
+2. Debug evaluation results via LLM traces
+3. Compare and pick the optimal hyperparameteres (prompt templates, models, chunk size, etc.).
+4. Create, manage, and centralize your evaluation datasets.
+5. Track events in production and augment your evaluation dataset for continous evaluation in production.
+
+Everything on Confident AI, including how to use Confident is available [here](https://docs.confident-ai.com/docs/confident-ai-introduction).
To begin, login from the CLI:
@@ -118,7 +183,7 @@ deepeval test run test_chatbot.py
You should see a link displayed in the CLI once the test has finished running. Paste it into your browser to view the results!
-
+
@@ -133,9 +198,9 @@ Please read [CONTRIBUTING.md](https://github.com/confident-ai/deepeval/blob/main
Features:
- [x] Implement G-Eval
-- [ ] Referenceless Evaluation
-- [ ] Production Evaluation & Logging
-- [ ] Evaluation Dataset Creation
+- [x] Referenceless Evaluation
+- [x] Production Evaluation & Logging
+- [x] Evaluation Dataset Creation
Integrations:
diff --git a/deepeval/__init__.py b/deepeval/__init__.py
index 8bc2f0cc2..6dddcb609 100644
--- a/deepeval/__init__.py
+++ b/deepeval/__init__.py
@@ -6,8 +6,16 @@
from ._version import __version__
from .decorators.hyperparameters import set_hyperparameters
-
-__all__ = ["set_hyperparameters"]
+from deepeval.event import track
+from deepeval.evaluate import evaluate, run_test, assert_test
+
+__all__ = [
+ "set_hyperparameters",
+ "track",
+ "evaluate",
+ "run_test",
+ "assert_test",
+]
def compare_versions(version1, version2):
diff --git a/deepeval/_version.py b/deepeval/_version.py
index 0be336dac..e9913d66a 100644
--- a/deepeval/_version.py
+++ b/deepeval/_version.py
@@ -1 +1 @@
-__version__: str = "0.20.24"
+__version__: str = "0.20.29"
diff --git a/deepeval/api.py b/deepeval/api.py
index b9c703192..ece563393 100644
--- a/deepeval/api.py
+++ b/deepeval/api.py
@@ -18,8 +18,9 @@
class Endpoints(Enum):
- CREATE_DATASET_ENDPOINT = "/v1/dataset"
- CREATE_TEST_RUN_ENDPOINT = "/v1/test-run"
+ DATASET_ENDPOINT = "/v1/dataset"
+ TEST_RUN_ENDPOINT = "/v1/test-run"
+ EVENT_ENDPOINT = "/v1/event"
class Api:
@@ -132,7 +133,6 @@ def _api_request(
data=None,
):
"""Generic HTTP request method with error handling."""
-
url = f"{self.base_api_url}/{endpoint}"
res = self._http_request(
method,
@@ -154,30 +154,19 @@ def _api_request(
except ValueError:
# Some endpoints only return 'OK' message without JSON
return json
- elif (
- res.status_code == 409
- and "task" in endpoint
- and body.get("unique_id")
- ):
- retry_history = res.raw.retries.history
- # Example RequestHistory tuple
- # RequestHistory(method='POST',
- # url='/v1/task/imageannotation',
- # error=None,
- # status=409,
- # redirect_location=None)
- if retry_history != ():
- # See if the first retry was a 500 or 503 error
- if retry_history[0][3] >= 500:
- uuid = body["unique_id"]
- newUrl = f"{self.base_api_url}/tasks?unique_id={uuid}"
- # grab task from api
- newRes = self._http_request(
- "GET", newUrl, headers=headers, auth=auth
- )
- json = newRes.json()["docs"][0]
+ elif res.status_code == 409:
+ message = res.json().get("message", "Conflict occurred.")
+
+ # Prompt user for input
+ user_input = input(f"{message} [y/N]: ").strip().lower()
+ if user_input == "y":
+ body["overwrite"] = True
+ return self._api_request(
+ method, endpoint, headers, auth, params, body, files, data
+ )
else:
- self._raise_on_response(res)
+ print("Aborted.")
+ return None
else:
self._raise_on_response(res)
return json
diff --git a/deepeval/check/__init__.py b/deepeval/check/__init__.py
new file mode 100644
index 000000000..2d1a120b5
--- /dev/null
+++ b/deepeval/check/__init__.py
@@ -0,0 +1 @@
+from .check import check
diff --git a/deepeval/check/benchmarks.py b/deepeval/check/benchmarks.py
new file mode 100644
index 000000000..6a134a821
--- /dev/null
+++ b/deepeval/check/benchmarks.py
@@ -0,0 +1,6 @@
+from enum import Enum
+
+
+class BenchmarkType(Enum):
+ HELM = "Stanford HELM"
+ LM_HARNESS = "LM Harness"
diff --git a/deepeval/check/check.py b/deepeval/check/check.py
new file mode 100644
index 000000000..61fe2ab6c
--- /dev/null
+++ b/deepeval/check/check.py
@@ -0,0 +1,21 @@
+from typing import Union
+
+from .benchmarks import BenchmarkType
+
+
+def check(benchmark: Union[str, BenchmarkType]):
+ if benchmark == BenchmarkType.HELM:
+ handleHELMCheck()
+ if benchmark == BenchmarkType.LM_HARNESS:
+ handleLMHarnessCheck()
+ else:
+ # catch all for custom benchmark checks
+ pass
+
+
+def handleHELMCheck():
+ pass
+
+
+def handleLMHarnessCheck():
+ pass
diff --git a/deepeval/dataset/api.py b/deepeval/dataset/api.py
index 4fcbaeb37..2b474948c 100644
--- a/deepeval/dataset/api.py
+++ b/deepeval/dataset/api.py
@@ -1,5 +1,5 @@
from pydantic import BaseModel, Field
-from typing import Optional, List
+from typing import Optional, List, Union
class Golden(BaseModel):
@@ -11,8 +11,13 @@ class Golden(BaseModel):
class APIDataset(BaseModel):
alias: str
+ overwrite: bool
goldens: Optional[List[Golden]] = Field(default=None)
class CreateDatasetHttpResponse(BaseModel):
link: str
+
+
+class DatasetHttpResponse(BaseModel):
+ goldens: List[Golden]
diff --git a/deepeval/dataset/dataset.py b/deepeval/dataset/dataset.py
index 2d99932fe..75e028e86 100644
--- a/deepeval/dataset/dataset.py
+++ b/deepeval/dataset/dataset.py
@@ -8,18 +8,27 @@
from deepeval.metrics import BaseMetric
from deepeval.test_case import LLMTestCase
-from deepeval.evaluator import evaluate
from deepeval.api import Api, Endpoints
-from deepeval.dataset.utils import convert_test_cases_to_goldens
-from deepeval.dataset.api import APIDataset, CreateDatasetHttpResponse
+from deepeval.dataset.utils import (
+ convert_test_cases_to_goldens,
+ convert_goldens_to_test_cases,
+)
+from deepeval.dataset.api import (
+ APIDataset,
+ CreateDatasetHttpResponse,
+ Golden,
+ DatasetHttpResponse,
+)
@dataclass
class EvaluationDataset:
test_cases: List[LLMTestCase]
+ goldens: List[Golden]
def __init__(self, test_cases: List[LLMTestCase] = []):
self.test_cases = test_cases
+ self.goldens = []
def add_test_case(self, test_case: LLMTestCase):
self.test_cases.append(test_case)
@@ -28,7 +37,7 @@ def __iter__(self):
return iter(self.test_cases)
def evaluate(self, metrics: List[BaseMetric]):
- from deepeval.evaluator import evaluate
+ from deepeval import evaluate
return evaluate(self.test_cases, metrics)
@@ -234,29 +243,45 @@ def push(self, alias: str):
)
if os.path.exists(".deepeval"):
goldens = convert_test_cases_to_goldens(self.test_cases)
- body = APIDataset(alias=alias, goldens=goldens).model_dump(
- by_alias=True, exclude_none=True
- )
+ body = APIDataset(
+ alias=alias, overwrite=False, goldens=goldens
+ ).model_dump(by_alias=True, exclude_none=True)
api = Api()
result = api.post_request(
- endpoint=Endpoints.CREATE_DATASET_ENDPOINT.value,
+ endpoint=Endpoints.DATASET_ENDPOINT.value,
body=body,
)
- response = CreateDatasetHttpResponse(
- link=result["link"],
- )
- link = response.link
- console = Console()
- console.print(
- "✅ Dataset pushed to Confidnet AI! View on "
- f"[link={link}]{link}[/link]"
- )
- # webbrowser.open(link)
+ if result:
+ response = CreateDatasetHttpResponse(
+ link=result["link"],
+ )
+ link = response.link
+ console = Console()
+ console.print(
+ "✅ Dataset successfully pushed to Confidnet AI! View at "
+ f"[link={link}]{link}[/link]"
+ )
+ webbrowser.open(link)
else:
raise Exception(
"To push dataset to Confident AI, run `deepeval login`"
)
- # TODO
def pull(self, alias: str):
- pass
+ if os.path.exists(".deepeval"):
+ api = Api()
+ result = api.get_request(
+ endpoint=Endpoints.DATASET_ENDPOINT.value,
+ params={"alias": alias},
+ )
+ response = DatasetHttpResponse(
+ goldens=result["goldens"],
+ )
+ self.goldens.extend(response.goldens)
+
+ # TODO: make this conversion at evaluation time instead
+ self.test_cases.extend(convert_goldens_to_test_cases(self.goldens))
+ else:
+ raise Exception(
+ "Run `deepeval login` to pull dataset from Confident AI"
+ )
diff --git a/deepeval/dataset/utils.py b/deepeval/dataset/utils.py
index 9f59e3103..8ebf2e294 100644
--- a/deepeval/dataset/utils.py
+++ b/deepeval/dataset/utils.py
@@ -17,3 +17,16 @@ def convert_test_cases_to_goldens(
}
goldens.append(Golden(**golden))
return goldens
+
+
+def convert_goldens_to_test_cases(goldens: List[Golden]) -> List[LLMTestCase]:
+ test_cases = []
+ for golden in goldens:
+ test_case = LLMTestCase(
+ input=golden.input,
+ actual_output=golden.actual_output,
+ expected_output=golden.expected_output,
+ context=golden.context,
+ )
+ test_cases.append(test_case)
+ return test_cases
diff --git a/deepeval/evaluator.py b/deepeval/evaluate.py
similarity index 96%
rename from deepeval/evaluator.py
rename to deepeval/evaluate.py
index 11c3a1056..5f798edc7 100644
--- a/deepeval/evaluator.py
+++ b/deepeval/evaluate.py
@@ -130,6 +130,9 @@ def print_test_result(test_result: TestResult):
print(
f" - ✅ {metric.__name__} (score: {metric.score}, minimum_score: {metric.minimum_score})"
)
+ if metric.score_metadata:
+ for metric_name, score in metric.score_metadata.items():
+ print(f" - {metric_name} (score: {score})")
print("\nFor test case:\n")
print(f" - input: {test_result.input}")
diff --git a/deepeval/event.py b/deepeval/event.py
new file mode 100644
index 000000000..709f03c09
--- /dev/null
+++ b/deepeval/event.py
@@ -0,0 +1,57 @@
+from typing import Optional, List, Dict
+from deepeval.api import Api, Endpoints
+from pydantic import BaseModel, Field
+
+
+class APIEvent(BaseModel):
+ name: str = Field(..., alias="name")
+ model: str
+ input: str
+ output: str
+ retrieval_context: Optional[List[str]] = Field(
+ None, alias="retrievalContext"
+ )
+ completion_time: Optional[float] = Field(None, alias="completionTime")
+ token_usage: Optional[float] = Field(None, alias="tokenUsage")
+ token_cost: Optional[float] = Field(None, alias="tokenCost")
+ distinct_id: Optional[str] = Field(None, alias="distinctId")
+ conversation_id: Optional[str] = Field(None, alias="conversationId")
+ additional_data: Optional[Dict] = Field(None, alias="additionalData")
+
+
+def track(
+ event_name: str,
+ model: str,
+ input: str,
+ output: str,
+ retrieval_context: Optional[List[str]] = None,
+ completion_time: Optional[float] = None,
+ token_usage: Optional[float] = None,
+ token_cost: Optional[float] = None,
+ distinct_id: Optional[str] = None,
+ conversation_id: Optional[str] = None,
+ additional_data: Optional[Dict] = None,
+ fail_silently: Optional[bool] = True,
+):
+ event = APIEvent(
+ name=event_name,
+ model=model,
+ input=input,
+ output=output,
+ retrievalContext=retrieval_context,
+ completionTime=completion_time,
+ tokenUsage=token_usage,
+ tokenCost=token_cost,
+ distinctId=distinct_id,
+ conversationId=conversation_id,
+ additionalData=additional_data,
+ )
+ api = Api()
+ try:
+ _ = api.post_request(
+ endpoint=Endpoints.EVENT_ENDPOINT.value,
+ body=event.dict(by_alias=True, exclude_none=True),
+ )
+ except Exception as e:
+ if not fail_silently:
+ raise (e)
diff --git a/deepeval/metrics/answer_relevancy.py b/deepeval/metrics/answer_relevancy.py
index 43bc2c9a6..5176d759a 100644
--- a/deepeval/metrics/answer_relevancy.py
+++ b/deepeval/metrics/answer_relevancy.py
@@ -1,47 +1,14 @@
from deepeval.singleton import Singleton
from deepeval.test_case import LLMTestCase
from deepeval.metrics import BaseMetric
-import numpy as np
-
-
-def softmax(x):
- e_x = np.exp(x - np.max(x))
- return e_x / e_x.sum(axis=0)
-
-
-class AnswerRelevancyModel(metaclass=Singleton):
- def __init__(self):
- from sentence_transformers import SentenceTransformer
-
- # Load the model
- self.model = SentenceTransformer(
- "sentence-transformers/multi-qa-MiniLM-L6-cos-v1"
- )
-
- def encode(self, text):
- return self.model.encode(text)
-
-
-class CrossEncoderAnswerRelevancyModel(metaclass=Singleton):
- def __init__(self, model_name: str = "cross-encoder/nli-deberta-v3-base"):
- from sentence_transformers.cross_encoder import CrossEncoder
-
- self.model = CrossEncoder(model_name)
-
- def encode(self, question: str, answer: str):
- scores = self.model.predict([[question, answer]])
- return softmax(scores[0])[2]
+from deepeval.scorer import Scorer
class AnswerRelevancyMetric(BaseMetric, metaclass=Singleton):
def __init__(
self, minimum_score: float = 0.5, model_type: str = "cross_encoder"
):
- self.minimum_score = minimum_score
- if model_type == "cross_encoder":
- self.model = CrossEncoderAnswerRelevancyModel()
- else:
- self.model = AnswerRelevancyModel()
+ self.minimum_score, self.model_type = minimum_score, model_type
def __call__(self, test_case: LLMTestCase):
score = self.measure(test_case.input, test_case.actual_output)
@@ -49,26 +16,15 @@ def __call__(self, test_case: LLMTestCase):
return score
def measure(self, test_case: LLMTestCase) -> float:
- from sentence_transformers import util
-
- if test_case.input is None or test_case.actual_output is None:
- raise ValueError("query and output cannot be None")
-
- if isinstance(self.model, CrossEncoderAnswerRelevancyModel):
- score = self.model.encode(test_case.input, test_case.actual_output)
- else:
- docs = [test_case.actual_output]
- # Encode query and documents
- query_emb = self.model.encode(test_case.input)
- doc_emb = self.model.encode(docs)
- # Compute dot score between query and all document embeddings
- scores = util.dot_score(query_emb, doc_emb)[0].cpu().tolist()
- score = scores[0]
+ answer_relevancy_score = Scorer.answer_relevancy_score(
+ predictions=test_case.input,
+ target=test_case.actual_output,
+ model_type=self.model_type,
+ )
- self.success = score > self.minimum_score
- # Log answer relevancy
- self.score = score
- return score
+ self.success = answer_relevancy_score > self.minimum_score
+ self.score = answer_relevancy_score
+ return answer_relevancy_score
def is_successful(self) -> bool:
return self.success
diff --git a/deepeval/metrics/base_metric.py b/deepeval/metrics/base_metric.py
index 8299e2d35..ce2cdb866 100644
--- a/deepeval/metrics/base_metric.py
+++ b/deepeval/metrics/base_metric.py
@@ -1,12 +1,13 @@
from abc import abstractmethod
from deepeval.test_case import LLMTestCase
-from typing import Optional
+from typing import Optional, Dict
class BaseMetric:
# set an arbitrary minimum score that will get over-ridden later
score: float = 0
+ score_metadata: Dict = None
reason: Optional[str] = None
@property
diff --git a/deepeval/metrics/factual_consistency.py b/deepeval/metrics/factual_consistency.py
index a4a6ef6e5..854c4826b 100644
--- a/deepeval/metrics/factual_consistency.py
+++ b/deepeval/metrics/factual_consistency.py
@@ -1,26 +1,8 @@
-import os
from deepeval.singleton import Singleton
from deepeval.test_case import LLMTestCase
-from deepeval.utils import chunk_text, softmax
from deepeval.metrics.base_metric import BaseMetric
-from deepeval.progress_context import progress_context
-from sentence_transformers import CrossEncoder
-
-
-class FactualConsistencyModel(metaclass=Singleton):
- def __init__(self, model_name: str = "cross-encoder/nli-deberta-v3-large"):
- # We use a smple cross encoder model
- os.environ["TOKENIZERS_PARALLELISM"] = "false"
- self.model = CrossEncoder(model_name)
-
- def predict(self, text_a: str, text_b: str):
- scores = self.model.predict([(text_a, text_b), (text_b, text_a)])
- # https://huggingface.co/cross-encoder/nli-deberta-base
- # label_mapping = ["contradiction", "entailment", "neutral"]
- softmax_scores = softmax(scores)
- score = softmax_scores[0][1]
- second_score = softmax_scores[1][1]
- return max(score, second_score)
+from deepeval.utils import chunk_text
+from deepeval.scorer import Scorer
class FactualConsistencyMetric(BaseMetric, metaclass=Singleton):
@@ -29,12 +11,7 @@ def __init__(
minimum_score: float = 0.6,
model_name: str = "cross-encoder/nli-deberta-v3-large",
):
- # For Crossencoder model, move to singleton to avoid re-instantiating
-
- with progress_context(
- "Downloading FactualConsistencyModel (may take up to 2 minutes if running for the first time)..."
- ):
- self.model = FactualConsistencyModel(model_name)
+ self.model_name = model_name
self.minimum_score = minimum_score
def measure(self, test_case: LLMTestCase):
@@ -50,15 +27,14 @@ def measure(self, test_case: LLMTestCase):
else:
raise ValueError("Context must be a string or a list of strings")
- max_score = 0
- for c in context_list:
- score = self.model.predict(c, test_case.actual_output)
- if score > max_score:
- max_score = score
-
- self.success = max_score > self.minimum_score
- self.score = max_score
- return max_score
+ score = Scorer.factual_consistency_score(
+ contexts=context_list,
+ prediction=test_case.actual_output,
+ model=self.model_name,
+ )
+ self.score = score
+ self.success = score > self.minimum_score
+ return score
def is_successful(self) -> bool:
return self.success
diff --git a/deepeval/metrics/non_toxic_metric.py b/deepeval/metrics/non_toxic_metric.py
index 48a8eab61..96318bef2 100644
--- a/deepeval/metrics/non_toxic_metric.py
+++ b/deepeval/metrics/non_toxic_metric.py
@@ -3,24 +3,9 @@
0 - Toxic
"""
from typing import List
-
-from deepeval.singleton import Singleton
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.metrics.base_metric import BaseMetric
-
-
-class DetoxifyModel(metaclass=Singleton):
- def __init__(self, model_name: str = "original"):
- self.model_name = model_name
-
- try:
- from detoxify import Detoxify
- except ImportError as e:
- print(e)
- self.model = Detoxify(model_name)
-
- def predict(self, text: str):
- return self.model.predict(text)
+from deepeval.scorer import Scorer
class NonToxicMetric(BaseMetric):
@@ -34,8 +19,7 @@ def __init__(
raise ValueError("evaluation_params cannot be empty or None")
self.evaluation_params = evaluation_params
- self.detoxify_model = DetoxifyModel(model_name)
- self.minimum_score = minimum_score
+ self.minimum_score, self.model_name = minimum_score, model_name
def __call__(self, test_case: LLMTestCase):
score = self.measure(test_case.actual_output)
@@ -57,7 +41,9 @@ def measure(self, test_case: LLMTestCase):
for param in self.evaluation_params:
text_to_evaluate = getattr(test_case, param.value)
- results = self.detoxify_model.predict(text_to_evaluate)
+ _, results = Scorer.neural_toxic_score(
+ prediction=text_to_evaluate, model=self.model_name
+ )
# sample output
# {'toxicity': 0.98057544,
# 'severe_toxicity': 0.106649496,
diff --git a/deepeval/metrics/ragas_metric.py b/deepeval/metrics/ragas_metric.py
index 50f7b84eb..c7b7f852a 100644
--- a/deepeval/metrics/ragas_metric.py
+++ b/deepeval/metrics/ragas_metric.py
@@ -2,7 +2,7 @@
"""
from deepeval.metrics import BaseMetric
from deepeval.test_case import LLMTestCase
-from typing import List
+import warnings
class ContextualPrecisionMetric(BaseMetric):
@@ -495,7 +495,7 @@ def measure(self, test_case: LLMTestCase):
# Create a dataset from the test case
# Convert the LLMTestCase to a format compatible with Dataset
- scores = []
+ score_metadata = {}
metrics = [
ContextualPrecisionMetric(),
ContextualRelevancyMetric(),
@@ -503,20 +503,30 @@ def measure(self, test_case: LLMTestCase):
FaithfulnessMetric(),
AnswerRelevancyMetric(),
]
+
+ warnings_list = []
+
for metric in metrics:
score = metric.measure(test_case)
- scores.append(score)
+ score_metadata[metric.__name__] = score
+ if score == 0:
+ warnings_list.append(
+ f"The RAGAS score will be 0 since {metric.__name__} has a score of 0"
+ )
- # ragas score is harmonic mean of all the scores
- if len(scores) > 0:
- ragas_score = len(scores) / sum(
- 1.0 / score for score in scores if score != 0
- )
- else:
+ for warning in warnings_list:
+ print(warning)
+
+ if any(score == 0 for score in score_metadata.values()):
ragas_score = 0
+ else:
+ ragas_score = len(score_metadata) / sum(
+ 1.0 / score for score in score_metadata.values()
+ )
self.success = ragas_score >= self.minimum_score
self.score = ragas_score
+ self.score_metadata = score_metadata
return self.score
def is_successful(self):
diff --git a/deepeval/metrics/unbias_metric.py b/deepeval/metrics/unbias_metric.py
index 2945a05e8..945d07c67 100644
--- a/deepeval/metrics/unbias_metric.py
+++ b/deepeval/metrics/unbias_metric.py
@@ -4,11 +4,10 @@
0 - Bias
"""
-import warnings
from typing import Optional, List
-
from deepeval.metrics import BaseMetric
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
+from deepeval.scorer import Scorer
class UnBiasedMetric(BaseMetric):
@@ -41,19 +40,15 @@ def measure(self, test_case: LLMTestCase, return_all_scores: bool = False):
f"Test case is missing the required attribute: {param.value}"
)
- from Dbias.bias_classification import classifier
-
- warnings.warn(
- "Run `pip install deepeval[bias]`. If you have, please ignore this warning."
- )
-
total_score = 0 # to accumulate scores for all evaluation params
all_results = (
[]
) # to accumulate all individual results if return_all_scores is True
for param in self.evaluation_params:
- result = classifier(getattr(test_case, param.value))
+ result = Scorer.neural_bias_score(
+ getattr(test_case, param.value), model=self.model_name
+ )
if return_all_scores:
all_results.append(result)
diff --git a/deepeval/models/__init__.py b/deepeval/models/__init__.py
index e69de29bb..c29c53c14 100644
--- a/deepeval/models/__init__.py
+++ b/deepeval/models/__init__.py
@@ -0,0 +1,9 @@
+from deepeval.models.base import DeepEvalBaseModel
+from deepeval.models.answer_relevancy_model import (
+ AnswerRelevancyModel,
+ CrossEncoderAnswerRelevancyModel,
+)
+from deepeval.models.summac_model import SummaCModels
+from deepeval.models.factual_consistency_model import FactualConsistencyModel
+from deepeval.models.detoxify_model import DetoxifyModel
+from deepeval.models.unbias_model import UnBiasedModel
diff --git a/deepeval/models/_summac_model.py b/deepeval/models/_summac_model.py
new file mode 100644
index 000000000..6541f103f
--- /dev/null
+++ b/deepeval/models/_summac_model.py
@@ -0,0 +1,574 @@
+# mypy: check_untyped_defs = False
+###############################################
+# Source: https://github.com/tingofurro/summac
+###############################################
+
+from transformers import AutoTokenizer, AutoModelForSequenceClassification
+import nltk
+import numpy as np
+import torch
+import os
+import json
+from deepeval import utils as utils_misc
+
+
+model_map = {
+ "snli-base": {
+ "model_card": "boychaboy/SNLI_roberta-base",
+ "entailment_idx": 0,
+ "contradiction_idx": 2,
+ },
+ "snli-large": {
+ "model_card": "boychaboy/SNLI_roberta-large",
+ "entailment_idx": 0,
+ "contradiction_idx": 2,
+ },
+ "mnli-base": {
+ "model_card": "microsoft/deberta-base-mnli",
+ "entailment_idx": 2,
+ "contradiction_idx": 0,
+ },
+ "mnli": {
+ "model_card": "roberta-large-mnli",
+ "entailment_idx": 2,
+ "contradiction_idx": 0,
+ },
+ "anli": {
+ "model_card": "ynie/roberta-large-snli_mnli_fever_anli_R1_R2_R3-nli",
+ "entailment_idx": 0,
+ "contradiction_idx": 2,
+ },
+ "vitc-base": {
+ "model_card": "tals/albert-base-vitaminc-mnli",
+ "entailment_idx": 0,
+ "contradiction_idx": 1,
+ },
+ "vitc": {
+ "model_card": "tals/albert-xlarge-vitaminc-mnli",
+ "entailment_idx": 0,
+ "contradiction_idx": 1,
+ },
+ "vitc-only": {
+ "model_card": "tals/albert-xlarge-vitaminc",
+ "entailment_idx": 0,
+ "contradiction_idx": 1,
+ },
+}
+
+
+def card_to_name(card):
+ card2name = {v["model_card"]: k for k, v in model_map.items()}
+ if card in card2name:
+ return card2name[card]
+ return card
+
+
+def name_to_card(name):
+ if name in model_map:
+ return model_map[name]["model_card"]
+ return name
+
+
+def get_neutral_idx(ent_idx, con_idx):
+ return list(set([0, 1, 2]) - set([ent_idx, con_idx]))[0]
+
+
+class _SummaCImager:
+ def __init__(
+ self,
+ model_name="mnli",
+ granularity="paragraph",
+ use_cache=True,
+ max_doc_sents=100,
+ device="cuda",
+ **kwargs
+ ):
+ self.grans = granularity.split("-")
+
+ assert (
+ all(
+ gran in ["paragraph", "sentence", "document", "2sents", "mixed"]
+ for gran in self.grans
+ )
+ and len(self.grans) <= 2
+ ), "Unrecognized `granularity` %s" % (granularity)
+ assert (
+ model_name in model_map.keys()
+ ), "Unrecognized model name: `%s`" % (model_name)
+
+ self.model_name = model_name
+ if model_name != "decomp":
+ self.model_card = name_to_card(model_name)
+ self.entailment_idx = model_map[model_name]["entailment_idx"]
+ self.contradiction_idx = model_map[model_name]["contradiction_idx"]
+ self.neutral_idx = get_neutral_idx(
+ self.entailment_idx, self.contradiction_idx
+ )
+
+ self.granularity = granularity
+ self.use_cache = use_cache
+ self.cache_folder = "/export/share/plaban/summac_cache/"
+
+ self.max_doc_sents = max_doc_sents
+ self.max_input_length = 500
+ self.device = device
+ self.cache = {}
+ self.model = None # Lazy loader
+
+ def load_nli(self):
+ if self.model_name == "decomp":
+ try:
+ from allennlp.predictors.predictor import Predictor
+ except ModuleNotFoundError:
+ print(
+ "allennlp library is not installed. "
+ "Please install the library by following the instruction from their documentation:"
+ "https://docs.allennlp.org/main/"
+ )
+ self.model = Predictor.from_path(
+ "https://storage.googleapis.com/allennlp-public-models/decomposable-attention-elmo-2020.04.09.tar.gz",
+ cuda_device=0,
+ )
+
+ else:
+ self.tokenizer = AutoTokenizer.from_pretrained(self.model_card)
+ self.model = AutoModelForSequenceClassification.from_pretrained(
+ self.model_card
+ ).eval()
+ self.model.to(self.device)
+
+ def split_sentences(self, text):
+ sentences = nltk.tokenize.sent_tokenize(text)
+ sentences = [sent for sent in sentences if len(sent) > 10]
+ return sentences
+
+ def split_2sents(self, text):
+ sentences = nltk.tokenize.sent_tokenize(text)
+ sentences = [sent for sent in sentences if len(sent) > 10]
+ two_sents = [
+ " ".join(sentences[i : (i + 2)]) for i in range(len(sentences))
+ ]
+ return two_sents
+
+ def split_paragraphs(self, text):
+ if text.count("\n\n") > 0:
+ paragraphs = [p.strip() for p in text.split("\n\n")]
+ else:
+ paragraphs = [p.strip() for p in text.split("\n")]
+ return [p for p in paragraphs if len(p) > 10]
+
+ def split_text(self, text, granularity="sentence"):
+ if granularity == "document":
+ return [text]
+ elif granularity == "paragraph":
+ return self.split_paragraphs(text)
+ elif granularity == "sentence":
+ return self.split_sentences(text)
+ elif granularity == "2sents":
+ return self.split_2sents(text)
+ elif granularity == "mixed":
+ return self.split_sentences(text) + self.split_paragraphs(text)
+
+ def build_image(self, original, generated):
+ cache_key = (original, generated)
+ if self.use_cache and cache_key in self.cache:
+ cached_image = self.cache[cache_key]
+ cached_image = cached_image[:, : self.max_doc_sents, :]
+ return cached_image
+
+ if len(self.grans) == 1:
+ gran_doc, gran_sum = self.grans[0], self.grans[0]
+ else:
+ gran_doc, gran_sum = self.grans[0], self.grans[1]
+
+ original_chunks = self.split_text(original, granularity=gran_doc)[
+ : self.max_doc_sents
+ ]
+ generated_chunks = self.split_text(generated, granularity=gran_sum)
+
+ N_ori = len(original_chunks)
+ N_gen = len(generated_chunks)
+
+ if N_ori == 0 or N_gen == 0:
+ return np.zeros((3, 1, 1))
+ # assert (N_ori > 0 and N_gen > 0), "One of the inputs has no chunks"
+
+ image = np.zeros((3, N_ori, N_gen))
+
+ if self.model is None:
+ self.load_nli()
+
+ dataset = [
+ {
+ "premise": original_chunks[i],
+ "hypothesis": generated_chunks[j],
+ "doc_i": i,
+ "gen_i": j,
+ }
+ for i in range(N_ori)
+ for j in range(N_gen)
+ ]
+ for batch in utils_misc.batcher(dataset, batch_size=20):
+ if self.model_name == "decomp":
+ batch_evids, batch_conts, batch_neuts = [], [], []
+ batch_json = [
+ {"premise": d["premise"], "hypothesis": d["hypothesis"]}
+ for d in batch
+ ]
+ model_outs = self.model.predict_batch_json(batch_json)
+ for out in model_outs:
+ probs = out["label_probs"]
+ batch_evids.append(probs[0])
+ batch_conts.append(probs[1])
+ batch_neuts.append(probs[2])
+
+ else:
+ batch_prems = [b["premise"] for b in batch]
+ batch_hypos = [b["hypothesis"] for b in batch]
+ batch_tokens = self.tokenizer.batch_encode_plus(
+ list(zip(batch_prems, batch_hypos)),
+ padding=True,
+ truncation=True,
+ max_length=self.max_input_length,
+ return_tensors="pt",
+ truncation_strategy="only_first",
+ )
+ batch_tokens = {
+ k: v.to(self.device) for k, v in batch_tokens.items()
+ }
+ with torch.no_grad():
+ model_outputs = self.model(**batch_tokens)
+
+ batch_probs = torch.nn.functional.softmax(
+ model_outputs["logits"], dim=-1
+ )
+ batch_evids = batch_probs[:, self.entailment_idx].tolist()
+ batch_conts = batch_probs[:, self.contradiction_idx].tolist()
+ batch_neuts = batch_probs[:, self.neutral_idx].tolist()
+
+ for b, evid, cont, neut in zip(
+ batch, batch_evids, batch_conts, batch_neuts
+ ):
+ image[0, b["doc_i"], b["gen_i"]] = evid
+ image[1, b["doc_i"], b["gen_i"]] = cont
+ image[2, b["doc_i"], b["gen_i"]] = neut
+
+ if self.use_cache:
+ self.cache[cache_key] = image
+ return image
+
+ def get_cache_file(self):
+ return os.path.join(
+ self.cache_folder,
+ "cache_%s_%s.json" % (self.model_name, self.granularity),
+ )
+
+ def save_cache(self):
+ cache_cp = {"[///]".join(k): v.tolist() for k, v in self.cache.items()}
+ with open(self.get_cache_file(), "w") as f:
+ json.dump(cache_cp, f)
+
+ def load_cache(self):
+ cache_file = self.get_cache_file()
+ if os.path.isfile(cache_file):
+ with open(cache_file, "r") as f:
+ cache_cp = json.load(f)
+ self.cache = {
+ tuple(k.split("[///]")): np.array(v)
+ for k, v in cache_cp.items()
+ }
+
+
+class _SummaCConv(torch.nn.Module):
+ def __init__(
+ self,
+ models=["mnli", "anli", "vitc"],
+ bins="even50",
+ granularity="sentence",
+ nli_labels="e",
+ device="cuda",
+ start_file=None,
+ imager_load_cache=True,
+ agg="mean",
+ norm_histo=False,
+ **kwargs
+ ):
+ # `bins` should be `even%d` or `percentiles`
+ assert nli_labels in [
+ "e",
+ "c",
+ "n",
+ "ec",
+ "en",
+ "cn",
+ "ecn",
+ ], "Unrecognized nli_labels argument %s" % (nli_labels)
+
+ super(SummaCConv, self).__init__()
+ self.device = device
+ self.models = models
+
+ self.imagers = []
+ for model_name in models:
+ self.imagers.append(
+ SummaCImager(
+ model_name=model_name, granularity=granularity, **kwargs
+ )
+ )
+ if imager_load_cache:
+ for imager in self.imagers:
+ imager.load_cache()
+ assert len(self.imagers) > 0, "Imager names were empty or unrecognized"
+
+ if "even" in bins:
+ n_bins = int(bins.replace("even", ""))
+ self.bins = list(np.arange(0, 1, 1 / n_bins)) + [1.0]
+ elif bins == "percentile":
+ self.bins = [
+ 0.0,
+ 0.01,
+ 0.02,
+ 0.03,
+ 0.04,
+ 0.07,
+ 0.13,
+ 0.37,
+ 0.90,
+ 0.91,
+ 0.92,
+ 0.93,
+ 0.94,
+ 0.95,
+ 0.955,
+ 0.96,
+ 0.965,
+ 0.97,
+ 0.975,
+ 0.98,
+ 0.985,
+ 0.99,
+ 0.995,
+ 1.0,
+ ]
+
+ self.nli_labels = nli_labels
+ self.n_bins = len(self.bins) - 1
+ self.norm_histo = norm_histo
+ self.n_rows = 10
+ self.n_labels = 2
+ self.n_depth = len(self.imagers) * len(self.nli_labels)
+ self.full_size = self.n_depth * self.n_bins
+ if self.norm_histo:
+ self.full_size += (
+ 2 # Will explicitely give the count of originals and generateds
+ )
+
+ self.agg = agg
+
+ self.mlp = torch.nn.Linear(self.full_size, 1).to(device)
+ self.layer_final = torch.nn.Linear(3, self.n_labels).to(device)
+
+ if start_file is not None:
+ print(self.load_state_dict(torch.load(start_file)))
+
+ def build_image(self, original, generated):
+ images = [
+ imager.build_image(original, generated) for imager in self.imagers
+ ]
+ image = np.concatenate(images, axis=0)
+ return image
+
+ def compute_histogram(self, original=None, generated=None, image=None):
+ # Takes the two texts, and generates a (n_rows, 2*n_bins)
+
+ if image is None:
+ image = self.build_image(original, generated)
+
+ N_depth, N_ori, N_gen = image.shape
+
+ full_histogram = []
+ for i_gen in range(N_gen):
+ histos = []
+
+ for i_depth in range(N_depth):
+ if (
+ (i_depth % 3 == 0 and "e" in self.nli_labels)
+ or (i_depth % 3 == 1 and "c" in self.nli_labels)
+ or (i_depth % 3 == 2 and "n" in self.nli_labels)
+ ):
+ histo, X = np.histogram(
+ image[i_depth, :, i_gen],
+ range=(0, 1),
+ bins=self.bins,
+ density=self.norm_histo,
+ )
+ histos.append(histo)
+
+ if self.norm_histo:
+ histos = [[N_ori, N_gen]] + histos
+ histogram_row = np.concatenate(histos)
+ full_histogram.append(histogram_row)
+
+ n_rows_missing = self.n_rows - len(full_histogram)
+ full_histogram += [[0.0] * self.full_size] * n_rows_missing
+ full_histogram = full_histogram[: self.n_rows]
+ full_histogram = np.array(full_histogram)
+ return image, full_histogram
+
+ def forward(self, originals, generateds, images=None):
+ if images is not None:
+ # In case they've been pre-computed.
+ histograms = []
+ for image in images:
+ _, histogram = self.compute_histogram(image=image)
+ histograms.append(histogram)
+ else:
+ images, histograms = [], []
+ for original, generated in zip(originals, generateds):
+ image, histogram = self.compute_histogram(
+ original=original, generated=generated
+ )
+ images.append(image)
+ histograms.append(histogram)
+
+ N = len(histograms)
+ histograms = torch.FloatTensor(histograms).to(self.device)
+
+ non_zeros = (torch.sum(histograms, dim=-1) != 0.0).long()
+ seq_lengths = non_zeros.sum(dim=-1).tolist()
+
+ mlp_outs = self.mlp(histograms).reshape(N, self.n_rows)
+ features = []
+
+ for mlp_out, seq_length in zip(mlp_outs, seq_lengths):
+ if seq_length > 0:
+ Rs = mlp_out[:seq_length]
+ if self.agg == "mean":
+ features.append(
+ torch.cat(
+ [
+ torch.mean(Rs).unsqueeze(0),
+ torch.mean(Rs).unsqueeze(0),
+ torch.mean(Rs).unsqueeze(0),
+ ]
+ ).unsqueeze(0)
+ )
+ elif self.agg == "min":
+ features.append(
+ torch.cat(
+ [
+ torch.min(Rs).unsqueeze(0),
+ torch.min(Rs).unsqueeze(0),
+ torch.min(Rs).unsqueeze(0),
+ ]
+ ).unsqueeze(0)
+ )
+ elif self.agg == "max":
+ features.append(
+ torch.cat(
+ [
+ torch.max(Rs).unsqueeze(0),
+ torch.max(Rs).unsqueeze(0),
+ torch.max(Rs).unsqueeze(0),
+ ]
+ ).unsqueeze(0)
+ )
+ elif self.agg == "all":
+ features.append(
+ torch.cat(
+ [
+ torch.min(Rs).unsqueeze(0),
+ torch.mean(Rs).unsqueeze(0),
+ torch.max(Rs).unsqueeze(0),
+ ]
+ ).unsqueeze(0)
+ )
+ else:
+ features.append(
+ torch.FloatTensor([0.0, 0.0, 0.0]).unsqueeze(0)
+ ) # .cuda()
+ features = torch.cat(features)
+ logits = self.layer_final(features)
+ histograms_out = [histogram.cpu().numpy() for histogram in histograms]
+ return logits, histograms_out, images
+
+ def save_imager_cache(self):
+ for imager in self.imagers:
+ imager.save_cache()
+
+ def score(self, originals, generateds, **kwargs):
+ with torch.no_grad():
+ logits, histograms, images = self.forward(originals, generateds)
+ probs = torch.nn.functional.softmax(logits, dim=-1)
+ batch_scores = probs[:, 1].tolist()
+ return {
+ "scores": batch_scores
+ } # , "histograms": histograms, "images": images
+
+
+class _SummaCZS:
+ def __init__(
+ self,
+ model_name="mnli",
+ granularity="paragraph",
+ op1="max",
+ op2="mean",
+ use_ent=True,
+ use_con=True,
+ imager_load_cache=True,
+ device="cuda",
+ **kwargs
+ ):
+ assert op2 in ["min", "mean", "max"], "Unrecognized `op2`"
+ assert op1 in ["max", "mean", "min"], "Unrecognized `op1`"
+
+ self.imager = _SummaCImager(
+ model_name=model_name,
+ granularity=granularity,
+ device=device,
+ **kwargs
+ )
+ if imager_load_cache:
+ self.imager.load_cache()
+ self.op2 = op2
+ self.op1 = op1
+ self.use_ent = use_ent
+ self.use_con = use_con
+
+ def save_imager_cache(self):
+ self.imager.save_cache()
+
+ def score_one(self, original, generated):
+ image = self.imager.build_image(original, generated)
+
+ ent_scores = np.max(image[0], axis=0)
+ co_scores = np.max(image[1], axis=0)
+ if self.op1 == "mean":
+ ent_scores = np.mean(image[0], axis=0)
+ co_scores = np.mean(image[1], axis=0)
+ elif self.op1 == "min":
+ ent_scores = np.min(image[0], axis=0)
+ co_scores = np.min(image[1], axis=0)
+
+ if self.use_ent and self.use_con:
+ scores = ent_scores - co_scores
+ elif self.use_ent:
+ scores = ent_scores
+ elif self.use_con:
+ scores = 1.0 - co_scores
+
+ final_score = np.mean(scores)
+ if self.op2 == "min":
+ final_score = np.min(scores)
+ elif self.op2 == "max":
+ final_score = np.max(scores)
+
+ return {"score": final_score, "image": image}
+
+ def score(self, sources, generateds, **kwargs):
+ output = {"scores": [], "images": []}
+ for source, gen in zip(sources, generateds):
+ score = self.score_one(source, gen)
+ output["scores"].append(score["score"])
+ output["images"].append(score["image"])
+ return output
diff --git a/deepeval/models/answer_relevancy_model.py b/deepeval/models/answer_relevancy_model.py
new file mode 100644
index 000000000..88ee30391
--- /dev/null
+++ b/deepeval/models/answer_relevancy_model.py
@@ -0,0 +1,74 @@
+import numpy as np
+from typing import Optional
+from deepeval.models.base import DeepEvalBaseModel
+
+
+def softmax(x):
+ e_x = np.exp(x - np.max(x))
+ return e_x / e_x.sum(axis=0)
+
+
+class AnswerRelevancyModel(DeepEvalBaseModel):
+ def __init__(self, model_name: Optional[str] = None):
+ model_name = (
+ "sentence-transformers/multi-qa-MiniLM-L6-cos-v1"
+ if model_name is None
+ else model_name
+ )
+ super().__init__(model_name=model_name)
+
+ def load_model(self):
+ """Loads a model, that will be responsible for scoring.
+
+ Returns:
+ A model object
+ """
+ from sentence_transformers import SentenceTransformer
+
+ return SentenceTransformer(self.model_name)
+
+ def _call(self, text: str):
+ """Runs the model to score the predictions.
+
+ Args:
+ text (str): Text, which can be output from a LLM or a simple input text.
+
+ Returns:
+ Answer relevancy score.
+ """
+ if not hasattr(self, "model") or self.model is None:
+ self.model = self.load_model()
+ return self.model.encode(text)
+
+
+class CrossEncoderAnswerRelevancyModel(DeepEvalBaseModel):
+ def __init__(self, model_name: str | None = None):
+ model_name = (
+ "cross-encoder/nli-deberta-v3-base"
+ if model_name is None
+ else model_name
+ )
+ super().__init__(model_name)
+
+ def load_model(self):
+ """Loads a model, that will be responsible for scoring.
+
+ Returns:
+ A model object
+ """
+ from sentence_transformers.cross_encoder import CrossEncoder
+
+ return CrossEncoder(model_name=self.model_name)
+
+ def _call(self, question: str, answer: str):
+ """Runs the model to score the predictions.
+
+ Args:
+ question (str): The input text.
+ answer (str): This can be the output from an LLM or the answer from a question-answer pair.
+
+ Returns:
+ Cross Answer relevancy score of the question and the answer.
+ """
+ scores = self.model.predict([[question, answer]])
+ return softmax(scores[0])[2]
diff --git a/deepeval/models/base.py b/deepeval/models/base.py
new file mode 100644
index 000000000..4d0c8e20b
--- /dev/null
+++ b/deepeval/models/base.py
@@ -0,0 +1,29 @@
+from abc import ABC, abstractmethod
+from typing import Any, Optional
+
+
+class DeepEvalBaseModel(ABC):
+ def __init__(self, model_name: Optional[str] = None, *args, **kwargs):
+ self.model_name = model_name
+ self.model = self.load_model(*args, **kwargs)
+
+ @abstractmethod
+ def load_model(self, *args, **kwargs):
+ """Loads a model, that will be responsible for scoring.
+
+ Returns:
+ A model object
+ """
+ pass
+
+ def __call__(self, *args: Any, **kwargs: Any) -> Any:
+ return self._call(*args, **kwargs)
+
+ @abstractmethod
+ def _call(self, *args, **kwargs):
+ """Runs the model to score / ourput the model predictions.
+
+ Returns:
+ A score or a list of results.
+ """
+ pass
diff --git a/deepeval/models/detoxify_model.py b/deepeval/models/detoxify_model.py
new file mode 100644
index 000000000..00f72ea8d
--- /dev/null
+++ b/deepeval/models/detoxify_model.py
@@ -0,0 +1,26 @@
+import torch
+from deepeval.models.base import DeepEvalBaseModel
+from detoxify import Detoxify
+
+
+class DetoxifyModel(DeepEvalBaseModel):
+ def __init__(self, model_name: str | None = None, *args, **kwargs):
+ if model_name is not None:
+ assert model_name in [
+ "original",
+ "unbiased",
+ "multilingual",
+ ], "Invalid model. Available variants: original, unbiased, multilingual"
+ model_name = "original" if model_name is None else model_name
+ super().__init__(model_name, *args, **kwargs)
+
+ def load_model(self):
+ device = "cuda" if torch.cuda.is_available() else "cpu"
+ return Detoxify(self.model_name, device=device)
+
+ def _call(self, text: str):
+ toxicity_score_dict = self.model.predict(text)
+ mean_toxicity_score = sum(list(toxicity_score_dict.values())) / len(
+ toxicity_score_dict
+ )
+ return mean_toxicity_score, toxicity_score_dict
diff --git a/deepeval/models/factual_consistency_model.py b/deepeval/models/factual_consistency_model.py
new file mode 100644
index 000000000..ca5e40e0c
--- /dev/null
+++ b/deepeval/models/factual_consistency_model.py
@@ -0,0 +1,27 @@
+import os
+from deepeval.models.base import DeepEvalBaseModel
+from sentence_transformers import CrossEncoder
+from deepeval.utils import softmax
+
+
+class FactualConsistencyModel(DeepEvalBaseModel):
+ def __init__(self, model_name: str | None = None, *args, **kwargs):
+ model_name = (
+ "cross-encoder/nli-deberta-v3-large"
+ if model_name is None
+ else model_name
+ )
+ os.environ["TOKENIZERS_PARALLELISM"] = "false"
+ super().__init__(model_name, *args, **kwargs)
+
+ def load_model(self):
+ return CrossEncoder(self.model_name)
+
+ def _call(self, text_a: str, text_b: str):
+ scores = self.model.predict([(text_a, text_b), (text_b, text_a)])
+ # https://huggingface.co/cross-encoder/nli-deberta-base
+ # label_mapping = ["contradiction", "entailment", "neutral"]
+ softmax_scores = softmax(scores)
+ score = softmax_scores[0][1]
+ second_score = softmax_scores[1][1]
+ return max(score, second_score)
diff --git a/deepeval/models/hallucination_model.py b/deepeval/models/hallucination_model.py
index 5e3f48464..65c4681bf 100644
--- a/deepeval/models/hallucination_model.py
+++ b/deepeval/models/hallucination_model.py
@@ -1,18 +1,22 @@
import os
+from typing import Optional
from deepeval.singleton import Singleton
from sentence_transformers import CrossEncoder
from deepeval.progress_context import progress_context
-from deepeval.models.model_map import model_map, name_to_card
class HallucinationModel(metaclass=Singleton):
- def __init__(self, model_name: str = "vectara-hallucination"):
+ def __init__(self, model_name: Optional[str] = None):
# We use a smple cross encoder model
+ model_name = (
+ "vectara/hallucination_evaluation_model"
+ if model_name is None
+ else model_name
+ )
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# TODO: add this progress context in the correct place
with progress_context(
"Downloading HallucinationEvaluationModel (may take up to 2 minutes if running for the first time)..."
):
- model_name = name_to_card(model_name)
self.model = CrossEncoder(model_name)
diff --git a/deepeval/models/model_map.py b/deepeval/models/model_map.py
deleted file mode 100644
index 1b4058530..000000000
--- a/deepeval/models/model_map.py
+++ /dev/null
@@ -1,65 +0,0 @@
-model_map = {
- "snli-base": {
- "model_card": "boychaboy/SNLI_roberta-base",
- "entailment_idx": 0,
- "contradiction_idx": 2,
- },
- "snli-large": {
- "model_card": "boychaboy/SNLI_roberta-large",
- "entailment_idx": 0,
- "contradiction_idx": 2,
- },
- "mnli-base": {
- "model_card": "microsoft/deberta-base-mnli",
- "entailment_idx": 2,
- "contradiction_idx": 0,
- },
- "mnli": {
- "model_card": "roberta-large-mnli",
- "entailment_idx": 2,
- "contradiction_idx": 0,
- },
- "anli": {
- "model_card": "ynie/roberta-large-snli_mnli_fever_anli_R1_R2_R3-nli",
- "entailment_idx": 0,
- "contradiction_idx": 2,
- },
- "vitc-base": {
- "model_card": "tals/albert-base-vitaminc-mnli",
- "entailment_idx": 0,
- "contradiction_idx": 1,
- },
- "vitc": {
- "model_card": "tals/albert-xlarge-vitaminc-mnli",
- "entailment_idx": 0,
- "contradiction_idx": 1,
- },
- "vitc-only": {
- "model_card": "tals/albert-xlarge-vitaminc",
- "entailment_idx": 0,
- "contradiction_idx": 1,
- },
- # "decomp": 0,
- "vectara-hallucination": {
- "model_card": "vectara/hallucination_evaluation_model",
- "entailment_idx": None,
- "contradiction_idx": None,
- },
-}
-
-
-def card_to_name(card):
- card2name = {v["model_card"]: k for k, v in model_map.items()}
- if card in card2name:
- return card2name[card]
- return card
-
-
-def name_to_card(name):
- if name in model_map:
- return model_map[name]["model_card"]
- return name
-
-
-def get_neutral_idx(ent_idx, con_idx):
- return list(set([0, 1, 2]) - set([ent_idx, con_idx]))[0]
diff --git a/deepeval/models/summac_model.py b/deepeval/models/summac_model.py
index b5e887873..7df978794 100644
--- a/deepeval/models/summac_model.py
+++ b/deepeval/models/summac_model.py
@@ -1,514 +1,64 @@
-# mypy: check_untyped_defs = False
-###############################################
-# Source: https://github.com/tingofurro/summac
-###############################################
-
-from transformers import AutoTokenizer, AutoModelForSequenceClassification
-import nltk
-import numpy as np
import torch
-import os
-import json
-from deepeval import utils as utils_misc
-from deepeval.models.model_map import name_to_card, get_neutral_idx, model_map
+from typing import Union, List
+from typing import List, Union, get_origin
+from deepeval.models.base import DeepEvalBaseModel
+from deepeval.models._summac_model import _SummaCZS
-class SummaCImager:
+class SummaCModels(DeepEvalBaseModel):
def __init__(
self,
- model_name="mnli",
- granularity="paragraph",
- use_cache=True,
- max_doc_sents=100,
- device="cuda",
+ model_name: str | None = None,
+ granularity: str | None = None,
+ device: str | None = None,
+ *args,
**kwargs
):
- self.grans = granularity.split("-")
-
- assert (
- all(
- gran in ["paragraph", "sentence", "document", "2sents", "mixed"]
- for gran in self.grans
- )
- and len(self.grans) <= 2
- ), "Unrecognized `granularity` %s" % (granularity)
- assert (
- model_name in model_map.keys()
- ), "Unrecognized model name: `%s`" % (model_name)
-
- self.model_name = model_name
- if model_name != "decomp":
- self.model_card = name_to_card(model_name)
- self.entailment_idx = model_map[model_name]["entailment_idx"]
- self.contradiction_idx = model_map[model_name]["contradiction_idx"]
- self.neutral_idx = get_neutral_idx(
- self.entailment_idx, self.contradiction_idx
- )
-
- self.granularity = granularity
- self.use_cache = use_cache
- self.cache_folder = "/export/share/plaban/summac_cache/"
-
- self.max_doc_sents = max_doc_sents
- self.max_input_length = 500
- self.device = device
- self.cache = {}
- self.model = None # Lazy loader
-
- def load_nli(self):
- if self.model_name == "decomp":
- try:
- from allennlp.predictors.predictor import Predictor
- except ModuleNotFoundError:
- print(
- "allennlp library is not installed. "
- "Please install the library by following the instruction from their documentation:"
- "https://docs.allennlp.org/main/"
- )
- self.model = Predictor.from_path(
- "https://storage.googleapis.com/allennlp-public-models/decomposable-attention-elmo-2020.04.09.tar.gz",
- cuda_device=0,
- )
-
- else:
- self.tokenizer = AutoTokenizer.from_pretrained(self.model_card)
- self.model = AutoModelForSequenceClassification.from_pretrained(
- self.model_card
- ).eval()
- self.model.to(self.device)
-
- def split_sentences(self, text):
- sentences = nltk.tokenize.sent_tokenize(text)
- sentences = [sent for sent in sentences if len(sent) > 10]
- return sentences
-
- def split_2sents(self, text):
- sentences = nltk.tokenize.sent_tokenize(text)
- sentences = [sent for sent in sentences if len(sent) > 10]
- two_sents = [
- " ".join(sentences[i : (i + 2)]) for i in range(len(sentences))
- ]
- return two_sents
-
- def split_paragraphs(self, text):
- if text.count("\n\n") > 0:
- paragraphs = [p.strip() for p in text.split("\n\n")]
- else:
- paragraphs = [p.strip() for p in text.split("\n")]
- return [p for p in paragraphs if len(p) > 10]
-
- def split_text(self, text, granularity="sentence"):
- if granularity == "document":
- return [text]
- elif granularity == "paragraph":
- return self.split_paragraphs(text)
- elif granularity == "sentence":
- return self.split_sentences(text)
- elif granularity == "2sents":
- return self.split_2sents(text)
- elif granularity == "mixed":
- return self.split_sentences(text) + self.split_paragraphs(text)
-
- def build_image(self, original, generated):
- cache_key = (original, generated)
- if self.use_cache and cache_key in self.cache:
- cached_image = self.cache[cache_key]
- cached_image = cached_image[:, : self.max_doc_sents, :]
- return cached_image
-
- if len(self.grans) == 1:
- gran_doc, gran_sum = self.grans[0], self.grans[0]
- else:
- gran_doc, gran_sum = self.grans[0], self.grans[1]
-
- original_chunks = self.split_text(original, granularity=gran_doc)[
- : self.max_doc_sents
- ]
- generated_chunks = self.split_text(generated, granularity=gran_sum)
-
- N_ori = len(original_chunks)
- N_gen = len(generated_chunks)
-
- if N_ori == 0 or N_gen == 0:
- return np.zeros((3, 1, 1))
- # assert (N_ori > 0 and N_gen > 0), "One of the inputs has no chunks"
-
- image = np.zeros((3, N_ori, N_gen))
-
- if self.model is None:
- self.load_nli()
-
- dataset = [
- {
- "premise": original_chunks[i],
- "hypothesis": generated_chunks[j],
- "doc_i": i,
- "gen_i": j,
- }
- for i in range(N_ori)
- for j in range(N_gen)
- ]
- for batch in utils_misc.batcher(dataset, batch_size=20):
- if self.model_name == "decomp":
- batch_evids, batch_conts, batch_neuts = [], [], []
- batch_json = [
- {"premise": d["premise"], "hypothesis": d["hypothesis"]}
- for d in batch
- ]
- model_outs = self.model.predict_batch_json(batch_json)
- for out in model_outs:
- probs = out["label_probs"]
- batch_evids.append(probs[0])
- batch_conts.append(probs[1])
- batch_neuts.append(probs[2])
-
- else:
- batch_prems = [b["premise"] for b in batch]
- batch_hypos = [b["hypothesis"] for b in batch]
- batch_tokens = self.tokenizer.batch_encode_plus(
- list(zip(batch_prems, batch_hypos)),
- padding=True,
- truncation=True,
- max_length=self.max_input_length,
- return_tensors="pt",
- truncation_strategy="only_first",
- )
- batch_tokens = {
- k: v.to(self.device) for k, v in batch_tokens.items()
- }
- with torch.no_grad():
- model_outputs = self.model(**batch_tokens)
-
- batch_probs = torch.nn.functional.softmax(
- model_outputs["logits"], dim=-1
- )
- batch_evids = batch_probs[:, self.entailment_idx].tolist()
- batch_conts = batch_probs[:, self.contradiction_idx].tolist()
- batch_neuts = batch_probs[:, self.neutral_idx].tolist()
-
- for b, evid, cont, neut in zip(
- batch, batch_evids, batch_conts, batch_neuts
- ):
- image[0, b["doc_i"], b["gen_i"]] = evid
- image[1, b["doc_i"], b["gen_i"]] = cont
- image[2, b["doc_i"], b["gen_i"]] = neut
-
- if self.use_cache:
- self.cache[cache_key] = image
- return image
-
- def get_cache_file(self):
- return os.path.join(
- self.cache_folder,
- "cache_%s_%s.json" % (self.model_name, self.granularity),
+ model_name = "vitc" if model_name is None else model_name
+ self.granularity = "sentence" if granularity is None else granularity
+ self.device = (
+ device
+ if device is not None
+ else "cuda"
+ if torch.cuda.is_available()
+ else "cpu"
)
+ super().__init__(model_name, *args, **kwargs)
- def save_cache(self):
- cache_cp = {"[///]".join(k): v.tolist() for k, v in self.cache.items()}
- with open(self.get_cache_file(), "w") as f:
- json.dump(cache_cp, f)
-
- def load_cache(self):
- cache_file = self.get_cache_file()
- if os.path.isfile(cache_file):
- with open(cache_file, "r") as f:
- cache_cp = json.load(f)
- self.cache = {
- tuple(k.split("[///]")): np.array(v)
- for k, v in cache_cp.items()
- }
-
-
-class SummaCConv(torch.nn.Module):
- def __init__(
- self,
- models=["mnli", "anli", "vitc"],
- bins="even50",
- granularity="sentence",
- nli_labels="e",
- device="cuda",
- start_file=None,
- imager_load_cache=True,
- agg="mean",
- norm_histo=False,
- **kwargs
- ):
- # `bins` should be `even%d` or `percentiles`
- assert nli_labels in [
- "e",
- "c",
- "n",
- "ec",
- "en",
- "cn",
- "ecn",
- ], "Unrecognized nli_labels argument %s" % (nli_labels)
-
- super(SummaCConv, self).__init__()
- self.device = device
- self.models = models
-
- self.imagers = []
- for model_name in models:
- self.imagers.append(
- SummaCImager(
- model_name=model_name, granularity=granularity, **kwargs
- )
- )
- if imager_load_cache:
- for imager in self.imagers:
- imager.load_cache()
- assert len(self.imagers) > 0, "Imager names were empty or unrecognized"
-
- if "even" in bins:
- n_bins = int(bins.replace("even", ""))
- self.bins = list(np.arange(0, 1, 1 / n_bins)) + [1.0]
- elif bins == "percentile":
- self.bins = [
- 0.0,
- 0.01,
- 0.02,
- 0.03,
- 0.04,
- 0.07,
- 0.13,
- 0.37,
- 0.90,
- 0.91,
- 0.92,
- 0.93,
- 0.94,
- 0.95,
- 0.955,
- 0.96,
- 0.965,
- 0.97,
- 0.975,
- 0.98,
- 0.985,
- 0.99,
- 0.995,
- 1.0,
- ]
-
- self.nli_labels = nli_labels
- self.n_bins = len(self.bins) - 1
- self.norm_histo = norm_histo
- self.n_rows = 10
- self.n_labels = 2
- self.n_depth = len(self.imagers) * len(self.nli_labels)
- self.full_size = self.n_depth * self.n_bins
- if self.norm_histo:
- self.full_size += (
- 2 # Will explicitely give the count of originals and generateds
- )
-
- self.agg = agg
-
- self.mlp = torch.nn.Linear(self.full_size, 1).to(device)
- self.layer_final = torch.nn.Linear(3, self.n_labels).to(device)
-
- if start_file is not None:
- print(self.load_state_dict(torch.load(start_file)))
-
- def build_image(self, original, generated):
- images = [
- imager.build_image(original, generated) for imager in self.imagers
- ]
- image = np.concatenate(images, axis=0)
- return image
-
- def compute_histogram(self, original=None, generated=None, image=None):
- # Takes the two texts, and generates a (n_rows, 2*n_bins)
-
- if image is None:
- image = self.build_image(original, generated)
-
- N_depth, N_ori, N_gen = image.shape
-
- full_histogram = []
- for i_gen in range(N_gen):
- histos = []
-
- for i_depth in range(N_depth):
- if (
- (i_depth % 3 == 0 and "e" in self.nli_labels)
- or (i_depth % 3 == 1 and "c" in self.nli_labels)
- or (i_depth % 3 == 2 and "n" in self.nli_labels)
- ):
- histo, X = np.histogram(
- image[i_depth, :, i_gen],
- range=(0, 1),
- bins=self.bins,
- density=self.norm_histo,
- )
- histos.append(histo)
-
- if self.norm_histo:
- histos = [[N_ori, N_gen]] + histos
- histogram_row = np.concatenate(histos)
- full_histogram.append(histogram_row)
-
- n_rows_missing = self.n_rows - len(full_histogram)
- full_histogram += [[0.0] * self.full_size] * n_rows_missing
- full_histogram = full_histogram[: self.n_rows]
- full_histogram = np.array(full_histogram)
- return image, full_histogram
-
- def forward(self, originals, generateds, images=None):
- if images is not None:
- # In case they've been pre-computed.
- histograms = []
- for image in images:
- _, histogram = self.compute_histogram(image=image)
- histograms.append(histogram)
- else:
- images, histograms = [], []
- for original, generated in zip(originals, generateds):
- image, histogram = self.compute_histogram(
- original=original, generated=generated
- )
- images.append(image)
- histograms.append(histogram)
-
- N = len(histograms)
- histograms = torch.FloatTensor(histograms).to(self.device)
-
- non_zeros = (torch.sum(histograms, dim=-1) != 0.0).long()
- seq_lengths = non_zeros.sum(dim=-1).tolist()
-
- mlp_outs = self.mlp(histograms).reshape(N, self.n_rows)
- features = []
-
- for mlp_out, seq_length in zip(mlp_outs, seq_lengths):
- if seq_length > 0:
- Rs = mlp_out[:seq_length]
- if self.agg == "mean":
- features.append(
- torch.cat(
- [
- torch.mean(Rs).unsqueeze(0),
- torch.mean(Rs).unsqueeze(0),
- torch.mean(Rs).unsqueeze(0),
- ]
- ).unsqueeze(0)
- )
- elif self.agg == "min":
- features.append(
- torch.cat(
- [
- torch.min(Rs).unsqueeze(0),
- torch.min(Rs).unsqueeze(0),
- torch.min(Rs).unsqueeze(0),
- ]
- ).unsqueeze(0)
- )
- elif self.agg == "max":
- features.append(
- torch.cat(
- [
- torch.max(Rs).unsqueeze(0),
- torch.max(Rs).unsqueeze(0),
- torch.max(Rs).unsqueeze(0),
- ]
- ).unsqueeze(0)
- )
- elif self.agg == "all":
- features.append(
- torch.cat(
- [
- torch.min(Rs).unsqueeze(0),
- torch.mean(Rs).unsqueeze(0),
- torch.max(Rs).unsqueeze(0),
- ]
- ).unsqueeze(0)
- )
- else:
- features.append(
- torch.FloatTensor([0.0, 0.0, 0.0]).unsqueeze(0)
- ) # .cuda()
- features = torch.cat(features)
- logits = self.layer_final(features)
- histograms_out = [histogram.cpu().numpy() for histogram in histograms]
- return logits, histograms_out, images
-
- def save_imager_cache(self):
- for imager in self.imagers:
- imager.save_cache()
-
- def score(self, originals, generateds, **kwargs):
- with torch.no_grad():
- logits, histograms, images = self.forward(originals, generateds)
- probs = torch.nn.functional.softmax(logits, dim=-1)
- batch_scores = probs[:, 1].tolist()
- return {
- "scores": batch_scores
- } # , "histograms": histograms, "images": images
-
-
-class SummaCZS:
- def __init__(
+ def load_model(
self,
- model_name="mnli",
- granularity="paragraph",
- op1="max",
- op2="mean",
- use_ent=True,
- use_con=True,
- imager_load_cache=True,
- device="cuda",
+ op1: str | None = "max",
+ op2: str | None = "mean",
+ use_ent: bool | None = True,
+ use_con: bool | None = True,
+ image_load_cache: bool | None = True,
**kwargs
):
- assert op2 in ["min", "mean", "max"], "Unrecognized `op2`"
- assert op1 in ["max", "mean", "min"], "Unrecognized `op1`"
-
- self.imager = SummaCImager(
- model_name=model_name,
- granularity=granularity,
- device=device,
+ return _SummaCZS(
+ model_name=self.model_name,
+ granularity=self.granularity,
+ device=self.device,
+ op1=op1,
+ op2=op2,
+ use_con=use_con,
+ use_ent=use_ent,
+ imager_load_cache=image_load_cache,
**kwargs
)
- if imager_load_cache:
- self.imager.load_cache()
- self.op2 = op2
- self.op1 = op1
- self.use_ent = use_ent
- self.use_con = use_con
-
- def save_imager_cache(self):
- self.imager.save_cache()
-
- def score_one(self, original, generated):
- image = self.imager.build_image(original, generated)
-
- ent_scores = np.max(image[0], axis=0)
- co_scores = np.max(image[1], axis=0)
- if self.op1 == "mean":
- ent_scores = np.mean(image[0], axis=0)
- co_scores = np.mean(image[1], axis=0)
- elif self.op1 == "min":
- ent_scores = np.min(image[0], axis=0)
- co_scores = np.min(image[1], axis=0)
-
- if self.use_ent and self.use_con:
- scores = ent_scores - co_scores
- elif self.use_ent:
- scores = ent_scores
- elif self.use_con:
- scores = 1.0 - co_scores
- final_score = np.mean(scores)
- if self.op2 == "min":
- final_score = np.min(scores)
- elif self.op2 == "max":
- final_score = np.max(scores)
-
- return {"score": final_score, "image": image}
-
- def score(self, sources, generateds, **kwargs):
- output = {"scores": [], "images": []}
- for source, gen in zip(sources, generateds):
- score = self.score_one(source, gen)
- output["scores"].append(score["score"])
- output["images"].append(score["image"])
- return output
+ def _call(
+ self, predictions: Union[str, List[str]], targets: Union[str, List[str]]
+ ) -> Union[float, dict]:
+ list_type = List[str]
+
+ if (
+ get_origin(predictions) is list_type
+ and get_origin(targets) is list_type
+ ):
+ return self.model.score(targets, predictions)
+ elif isinstance(predictions, str) and isinstance(targets, str):
+ return self.model.score_one(targets, predictions)
+ else:
+ raise TypeError(
+ "Either both predictions and targets should be List or both should be string"
+ )
diff --git a/deepeval/models/unbias_model.py b/deepeval/models/unbias_model.py
new file mode 100644
index 000000000..5104b214f
--- /dev/null
+++ b/deepeval/models/unbias_model.py
@@ -0,0 +1,18 @@
+from typing import Optional
+from deepeval.models.base import DeepEvalBaseModel
+
+
+class UnBiasedModel(DeepEvalBaseModel):
+ def __init__(self, model_name: str | None = None, *args, **kwargs):
+ model_name = "original" if model_name is None else model_name
+ super().__init__(model_name, *args, **kwargs)
+
+ def load_model(self):
+ try:
+ from Dbias.bias_classification import classifier
+ except ImportError as e:
+ print("Run `pip install deepeval[bias]`")
+ return classifier
+
+ def _call(self, text):
+ return self.model(text)
diff --git a/deepeval/scorer/scorer.py b/deepeval/scorer/scorer.py
index 6e76056a8..f7a19f643 100644
--- a/deepeval/scorer/scorer.py
+++ b/deepeval/scorer/scorer.py
@@ -4,7 +4,6 @@
from nltk.translate.bleu_score import sentence_bleu
from typing import Union, List, Optional, Any
from deepeval.utils import normalize_text
-from deepeval.models.summac_model import SummaCZS
# TODO: More scores are to be added
@@ -175,7 +174,12 @@ def bert_score(
@classmethod
def faithfulness_score(
- cls, target: str, prediction: str, model: Optional[str] = None
+ cls,
+ target: str,
+ prediction: str,
+ model: Optional[str] = None,
+ granularity: Optional[str] = None,
+ device: Optional[str] = None,
) -> float:
"""Calculate the faithfulness score of a prediction compared to a target text using SummaCZS.
@@ -189,16 +193,18 @@ def faithfulness_score(
Returns:
float: The computed faithfulness score. Higher values indicate greater faithfulness to the target text.
+
+ Right now we are using score_one method under the hood. Instead of scoring multiple predictions for faithfullness.
"""
- model = "vitc" if model is None else model
- device = "cuda" if torch.cuda.is_available() else "cpu"
- scorer = SummaCZS(
- granularity="sentence",
- model_name=model,
- imager_load_cache=False,
- device=device,
+ try:
+ from deepeval.models import SummaCModels
+ except Exception as e:
+ print(f"SummaCZS model can not be loaded.\n{e}")
+
+ scorer = SummaCModels(
+ model_name=model, granularity=granularity, device=device
)
- return scorer.score_one(target, prediction)["score"]
+ return scorer(target, prediction)["score"]
@classmethod
def hallucination_score(
@@ -221,11 +227,10 @@ def hallucination_score(
HallucinationModel,
)
except ImportError as e:
- print(e)
- model = "vectara-hallucination" if model is None else model
-
+ print(
+ f"Vectera Hallucination detection model can not be loaded.\n{e}"
+ )
scorer = HallucinationModel(model_name=model)
-
return scorer.model.predict([source, prediction])
@classmethod
@@ -236,7 +241,7 @@ def PII_score(
@classmethod
def neural_toxic_score(
- cls, prediction: str, model: Optional[Any] = None
+ cls, prediction: str, model: Optional[str] = None
) -> Union[float, dict]:
"""
Calculate the toxicity score of a given text prediction using the Detoxify model.
@@ -267,22 +272,97 @@ def neural_toxic_score(
If the model is 'multilingual', we get a dict same as the unbiasd one.
"""
try:
- from detoxify import Detoxify
+ from deepeval.models import DetoxifyModel
except ImportError as e:
- print(e)
+ print(f"Unable to import.\n {e}")
+ scorer = DetoxifyModel(model_name=model)
+ return scorer(prediction)
- device = "cuda" if torch.cuda.is_available() else "cpu"
- if model is not None:
- assert model in [
- "original",
- "unbiased",
- "multilingual",
- ], "Invalid model. Available variants: original, unbiased, multilingual"
- detoxify_model = Detoxify(model, device=device)
+ @classmethod
+ def answer_relevancy_score(
+ cls,
+ predictions: Union[str, List[str]],
+ target: str,
+ model_type: Optional[str] = None,
+ model_name: Optional[str] = None,
+ ) -> float:
+ """Calculates the Answer relevancy score.
+
+ Args:
+ predictions (Union[str, List[str]]): The predictions from the model.
+ target (str): The target on which we need to check relevancy.
+ model_name (str): The type of the answer relevancy model. This can be either an self_encoder or a cross_encoder. By default it is cross_encoder.
+ model_name (Optional[str], optional): The name of the model. Defaults to None.
+
+ Returns:
+ float: Answer relevancy score.
+ """
+ from sentence_transformers import util
+
+ try:
+ from deepeval.models import (
+ AnswerRelevancyModel,
+ CrossEncoderAnswerRelevancyModel,
+ )
+ except Exception as e:
+ print(f"Unable to load AnswerRelevancyModel model.\n{e}")
+
+ if model_type is not None:
+ assert model_type in [
+ "self_encoder",
+ "cross_encoder",
+ ], "model_type can be either 'self_encoder' or 'cross_encoder'"
+
+ model_type = "cross_encoder" if model_type is None else model_type
+
+ if model_type == "cross_encoder":
+ assert isinstance(
+ predictions, str
+ ), "When model_type is 'cross_encoder', you can compare with one prediction and one target."
+ answer_relevancy_model = CrossEncoderAnswerRelevancyModel(
+ model_name=model_name
+ )
+ score = answer_relevancy_model(predictions, target)
else:
- detoxify_model = Detoxify("original", device=device)
- toxicity_score_dict = detoxify_model.predict(prediction)
- mean_toxicity_score = sum(list(toxicity_score_dict.values())) / len(
- toxicity_score_dict
- )
- return mean_toxicity_score, toxicity_score_dict
+ answer_relevancy_model = AnswerRelevancyModel(model_name=model_name)
+ docs = (
+ [predictions] if isinstance(predictions, str) else predictions
+ )
+ query_embedding = answer_relevancy_model(target)
+ document_embedding = answer_relevancy_model(docs)
+ scores = (
+ util.dot_score(query_embedding, document_embedding)[0]
+ .cpu()
+ .tolist()
+ )
+ score = scores[0]
+ return score
+
+ @classmethod
+ def factual_consistency_score(
+ cls,
+ contexts: Union[List[str], str],
+ prediction: str,
+ model: Optional[str] = None,
+ ) -> float:
+ try:
+ from deepeval.models import FactualConsistencyModel
+ except Exception as e:
+ print(f"Unable to load FactualConsistencyModel\n{e}")
+
+ scorer = FactualConsistencyModel(model)
+ contexts = [contexts] if isinstance(contexts, str) else contexts
+ max_score = 0
+ for context in contexts:
+ score = scorer.predict(context, prediction)
+ max_score = max(max_score, score)
+ return max_score
+
+ @classmethod
+ def neural_bias_score(cls, text: str, model: Optional[str] = None) -> float:
+ try:
+ from deepeval.models import UnBiasedModel
+ except Exception as e:
+ print(f"Unable to load UnBiasedModel.\n{e}")
+ scorer = UnBiasedModel(model_name=model)
+ return scorer(text)
diff --git a/deepeval/test_run.py b/deepeval/test_run.py
index 1e466c6db..85d3454b7 100644
--- a/deepeval/test_run.py
+++ b/deepeval/test_run.py
@@ -4,7 +4,6 @@
from typing import Any, Optional, List, Dict
from deepeval.metrics import BaseMetric
from deepeval.test_case import LLMTestCase
-from collections import defaultdict
from deepeval.tracing import get_trace_stack
from deepeval.constants import PYTEST_RUN_TEST_NAME
from deepeval.decorators.hyperparameters import get_hyperparameters
@@ -281,7 +280,7 @@ def post_test_run(self, test_run: TestRun):
body = test_run.dict(by_alias=True, exclude_none=True)
api = Api()
result = api.post_request(
- endpoint=Endpoints.CREATE_TEST_RUN_ENDPOINT.value,
+ endpoint=Endpoints.TEST_RUN_ENDPOINT.value,
body=body,
)
response = TestRunHttpResponse(
diff --git a/deepeval/tracing/__init__.py b/deepeval/tracing/__init__.py
new file mode 100644
index 000000000..76ea3893c
--- /dev/null
+++ b/deepeval/tracing/__init__.py
@@ -0,0 +1 @@
+from .tracing import trace, TraceType, get_trace_stack
diff --git a/deepeval/tracing.py b/deepeval/tracing/tracing.py
similarity index 100%
rename from deepeval/tracing.py
rename to deepeval/tracing/tracing.py
diff --git a/docs/assets/3-step-metrics.png b/docs/assets/3-step-metrics.png
deleted file mode 100644
index 6a2c246e0..000000000
Binary files a/docs/assets/3-step-metrics.png and /dev/null differ
diff --git a/docs/assets/bulk-review.png b/docs/assets/bulk-review.png
deleted file mode 100644
index 42ea21add..000000000
Binary files a/docs/assets/bulk-review.png and /dev/null differ
diff --git a/docs/assets/deepeval-cli-reveal.png b/docs/assets/deepeval-cli-reveal.png
deleted file mode 100644
index dc871a3a5..000000000
Binary files a/docs/assets/deepeval-cli-reveal.png and /dev/null differ
diff --git a/docs/assets/llm-evaluation-framework-example.png b/docs/assets/llm-evaluation-framework-example.png
deleted file mode 100644
index b45e3463e..000000000
Binary files a/docs/assets/llm-evaluation-framework-example.png and /dev/null differ
diff --git a/docs/assets/llm-evaluation-framework.png b/docs/assets/llm-evaluation-framework.png
deleted file mode 100644
index cd638390f..000000000
Binary files a/docs/assets/llm-evaluation-framework.png and /dev/null differ
diff --git a/docs/assets/synthetic-query-generation.png b/docs/assets/synthetic-query-generation.png
deleted file mode 100644
index 091b36710..000000000
Binary files a/docs/assets/synthetic-query-generation.png and /dev/null differ
diff --git a/docs/docs/confident-ai-analyze-evaluations.mdx b/docs/docs/confident-ai-analyze-evaluations.mdx
new file mode 100644
index 000000000..f8f2f6af1
--- /dev/null
+++ b/docs/docs/confident-ai-analyze-evaluations.mdx
@@ -0,0 +1,57 @@
+---
+id: confident-ai-analyze-evaluations
+title: Analyzing Evals
+sidebar_label: Analyzing Evals
+---
+
+## Quick Summary
+
+Confident AI keeps track of your evaluation histories in both development and deployment and allows you to:
+
+- visualize evaluation results
+- compare and select optimal hyperparameters (eg. prompt templates, model used, etc.) for each test run
+
+## Visualize Evaluation Results
+
+Once logged in via `deepeval login`, all evaluations executed using `deepeval test run`, `evaluate(dataset, metrics)`, or `dataset.evaluate(metrics)`, will automatically have their results available on Confident.
+
+
+
+## Compare Hyperparameters
+
+Begin by associating hyperparameters with each test run:
+
+```python title=test_example.py
+import deepeval
+from deepeval import assert_test
+from deepeval.metrics import HallucinationMetric
+
+def test_hallucination():
+ metric = HallucinationMetric()
+ test_case = LLMTestCase(...)
+ assert_test(test_case, [metric])
+
+
+# Although the values in this example are hardcoded,
+# you should ideally pass in variables as values to keep things dynamic
+@deepeval.set_hyperparameters
+def hyperparameters():
+ return {
+ "chunk_size": 500,
+ "temperature": 0,
+ "model": "GPT-4",
+ "prompt_template": """You are a helpful assistant, answer the following question in a non-judgemental tone.
+
+ Question:
+ {question}
+ """,
+ }
+```
+
+:::note
+This only works if you're running evaluations using `deepeval test run`. If you're not already using `deepeval test run` for evaluations, we highly recommend you to start using it.
+:::
+
+That's all! All test runs will now log hyperparameters for you to compare and optimize on.
+
+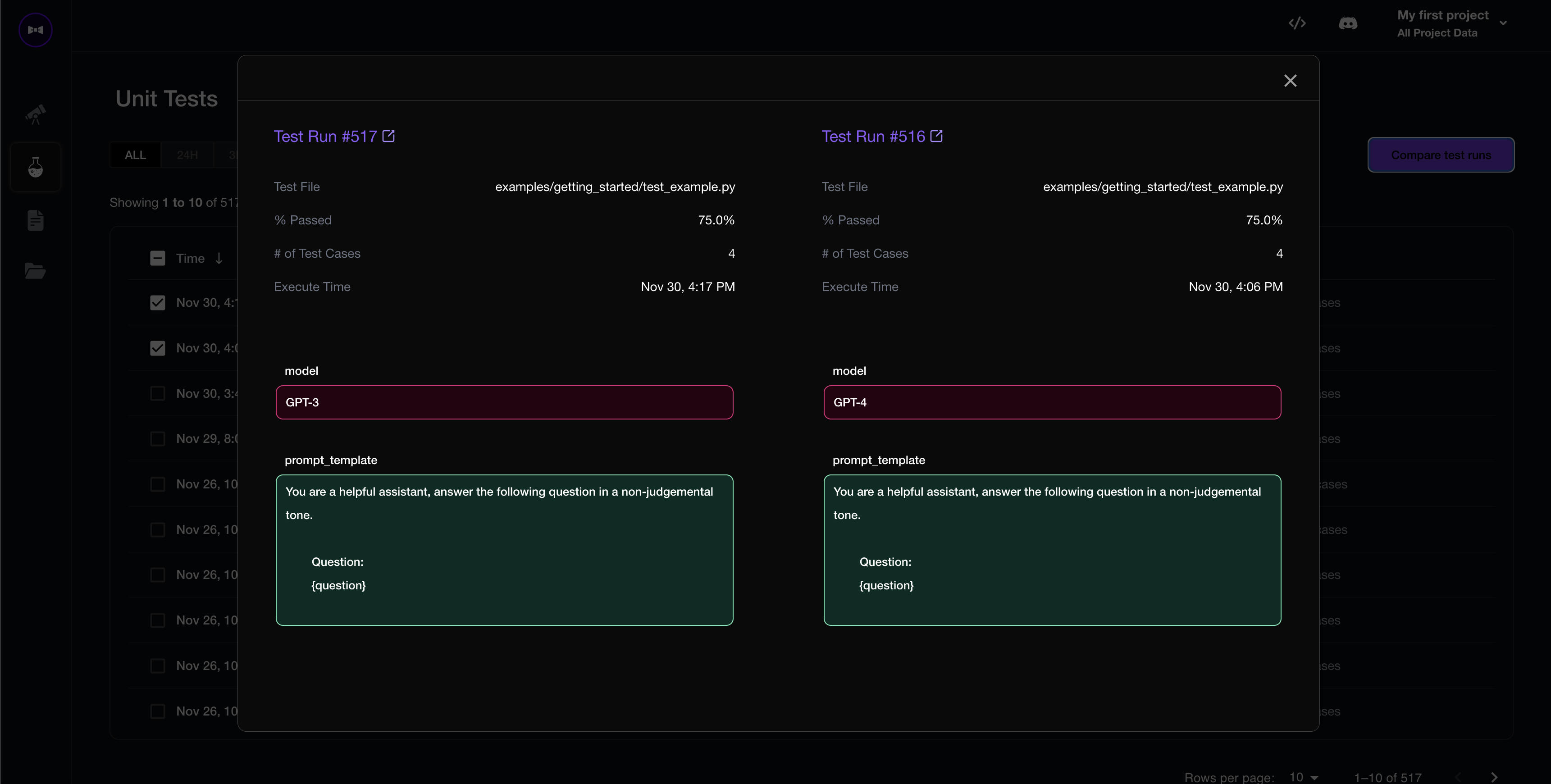
diff --git a/docs/docs/evaluation-tracing.mdx b/docs/docs/confident-ai-debug-evaluations.mdx
similarity index 85%
rename from docs/docs/evaluation-tracing.mdx
rename to docs/docs/confident-ai-debug-evaluations.mdx
index c41839602..c4aa15364 100644
--- a/docs/docs/evaluation-tracing.mdx
+++ b/docs/docs/confident-ai-debug-evaluations.mdx
@@ -1,12 +1,14 @@
---
-id: evaluation-tracing
-title: Tracing
-sidebar_label: Tracing
+id: confident-ai-debug-evaluations
+title: Debugging Evals
+sidebar_label: Debugging Evals
---
## Quick Summary
-Tracing in the context of evaluating LLM applications provides a quick and easy way for you to identify why certain test cases are failing on specific metrics. From chunking to embedding, retrieval to generation, tracing allows you to debug your LLM application pipeline at a component level.
+Confident AI uses "tracing" to help debug unsatisfactory evaluation results. Tracing in the context of evaluating LLM applications provides a quick and easy way for you to identify why certain test cases are failing on specific metrics.
+
+From chunking to embedding, retrieval to generation, tracing allows you to debug your LLM application pipeline at a component level.
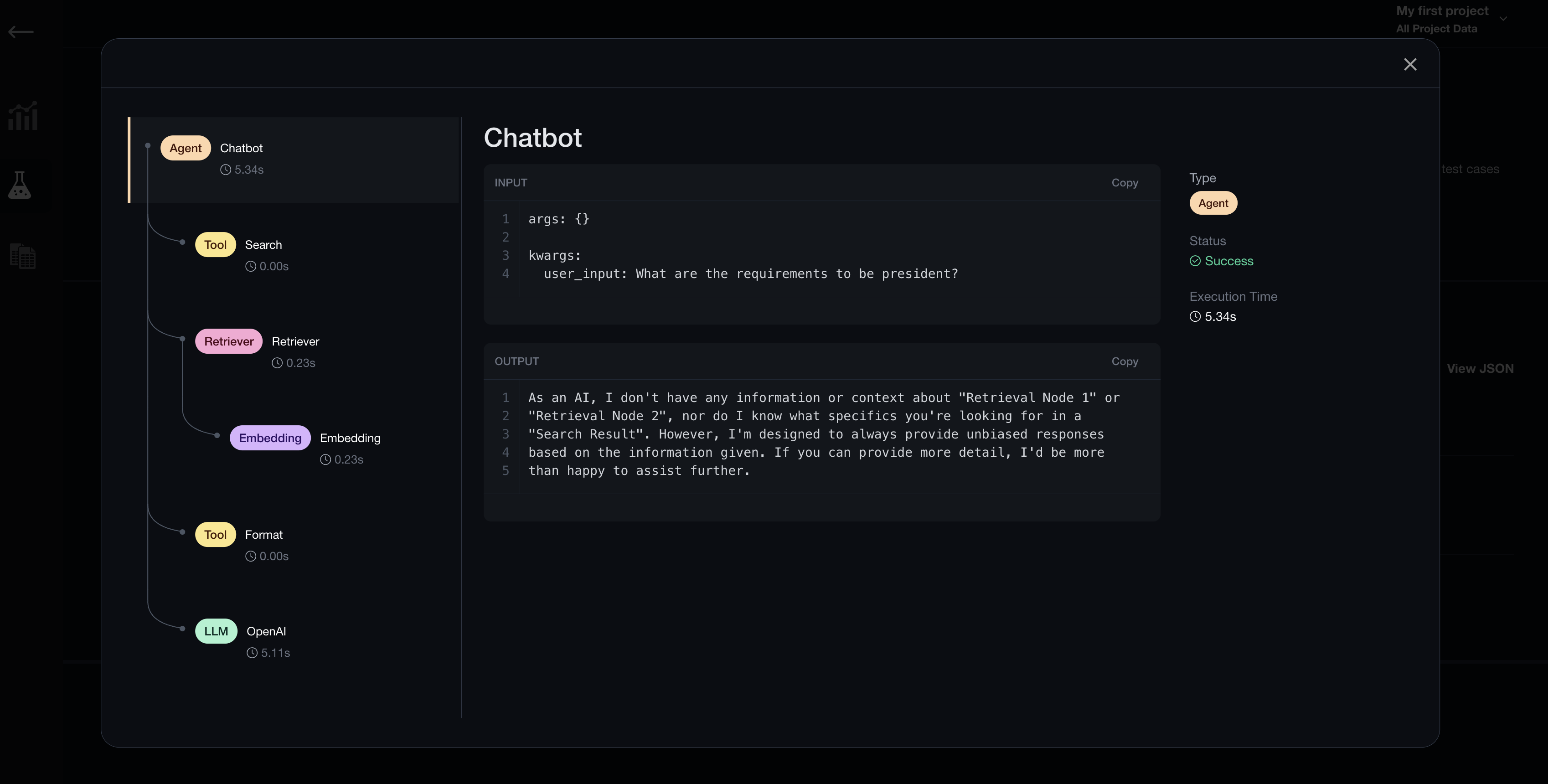
@@ -124,7 +126,11 @@ class Chatbot:
Applying the `@trace` decorator will automatically log LLM traces each time `chatbot.query()` is called during `deepeval test run`. This will allow you to debug failing test cases by inspecting individual trace stacks on Confident AI.
-## Log Your First Trace
+:::note
+Currently, tracing only works if you're running evaluations using `deepeval test run`, and generating `actual_output`s from your LLM application at evaluation time (ie. tracing does not work with pre-computed outputs)
+:::
+
+## Debugging with Traces
Continuning from the previous code snippet where you've defined your `Chatbot` class, paste in the following test case to evaluate whether your LLM application is outputting factually correct answers.
@@ -132,9 +138,9 @@ Continuning from the previous code snippet where you've defined your `Chatbot` c
...
import pytest
+from deepeval import assert_test
from deepeval.test_case import LLMTestCase
from deepeval.metrics import HallucinationMetric
-from deepeval.evaluator import assert_test
chatbot = Chatbot()
@@ -155,19 +161,13 @@ def test_hallucination():
assert_test(test_case, [metric])
```
-[Login to Confident AI](https://app.confident-ai.com/login) to start tracing your LLM application for each test case.
-
-```
-deepeval login
-```
-
-Follow the instructions displayed on the CLI to create an account, get your Confident API key, and paste it in the CLI. Once you're logged in, run `deepeval test run`:
+Lastly, run `deepeval test run`:
```
deepeval test run test_chatbot.py
```
-You should see the test case has failed, but that' ok because it's meant to fail. Paste the link returned from the CLI into the same browser you logged in with to view and debug why your test case failed.
+You can now go to Confident AI to debug failing test cases with tracing.
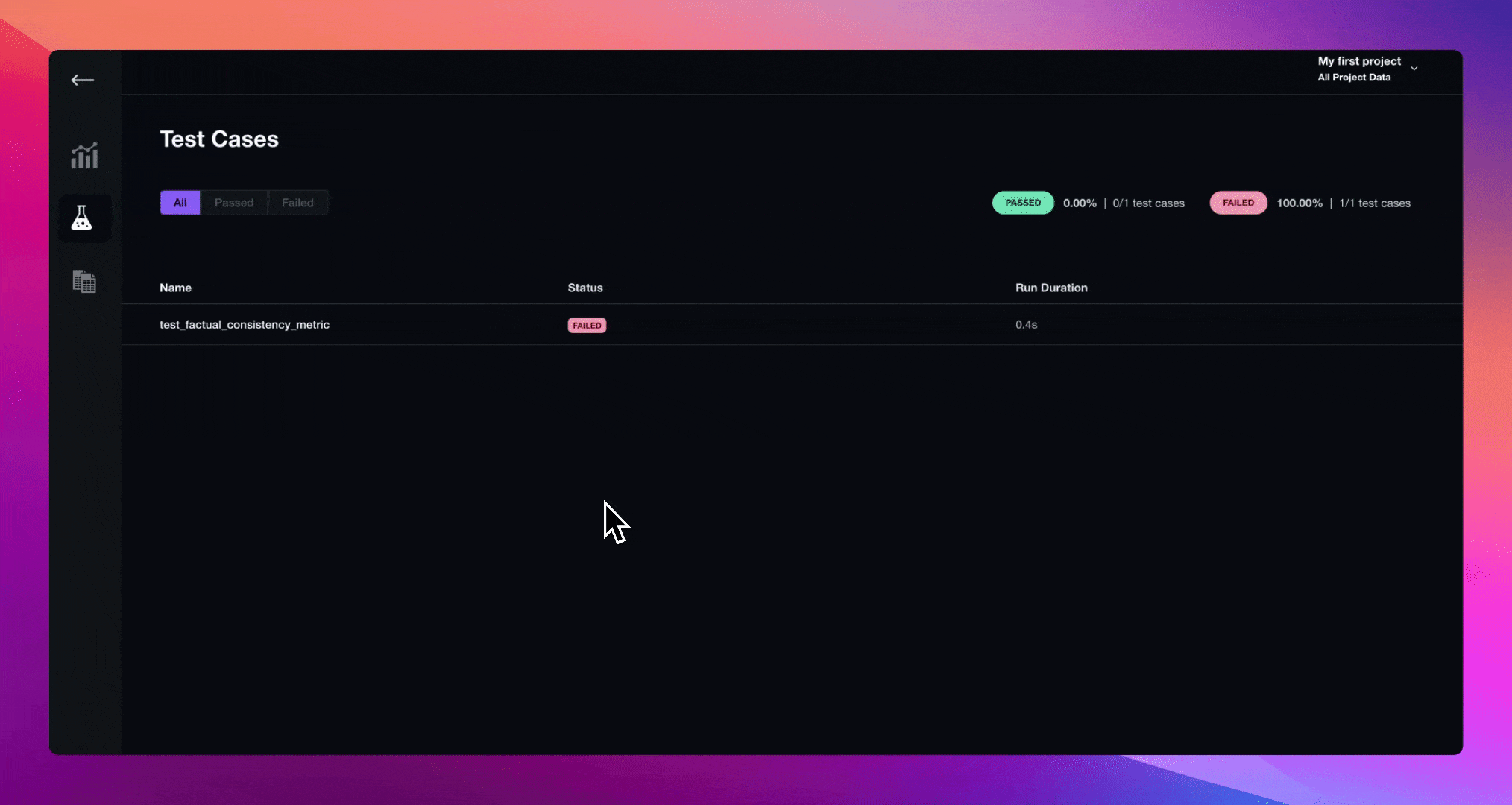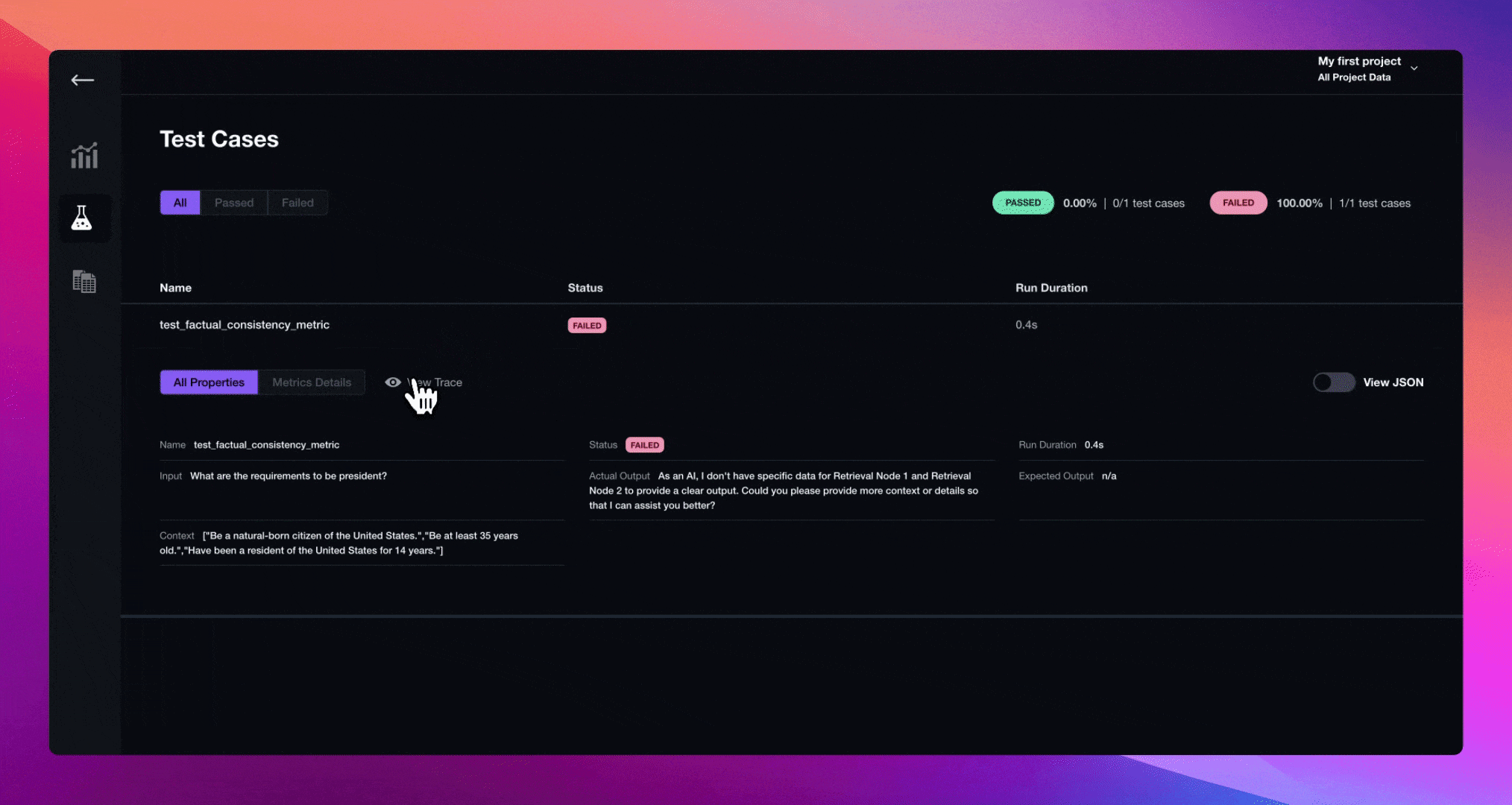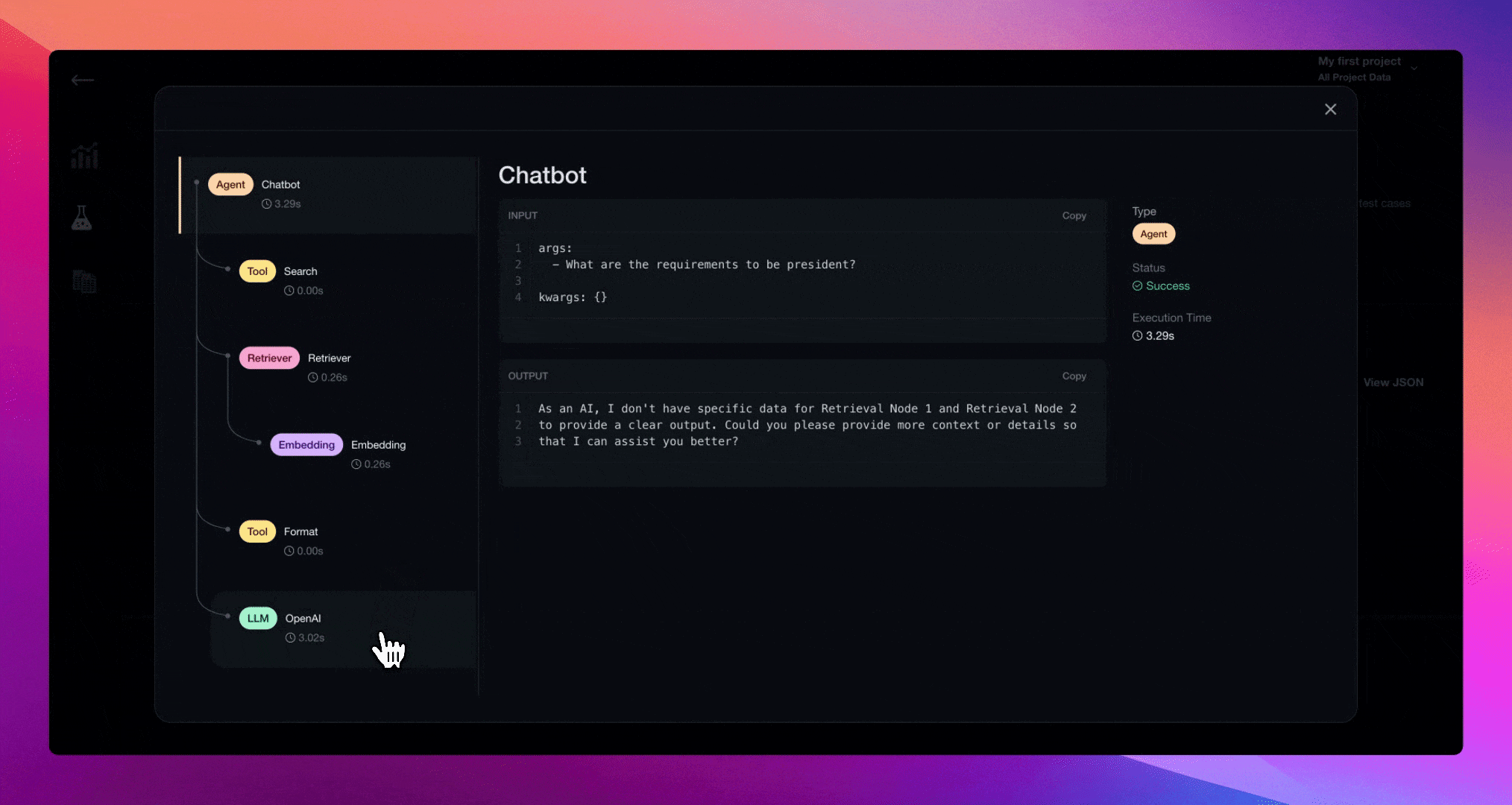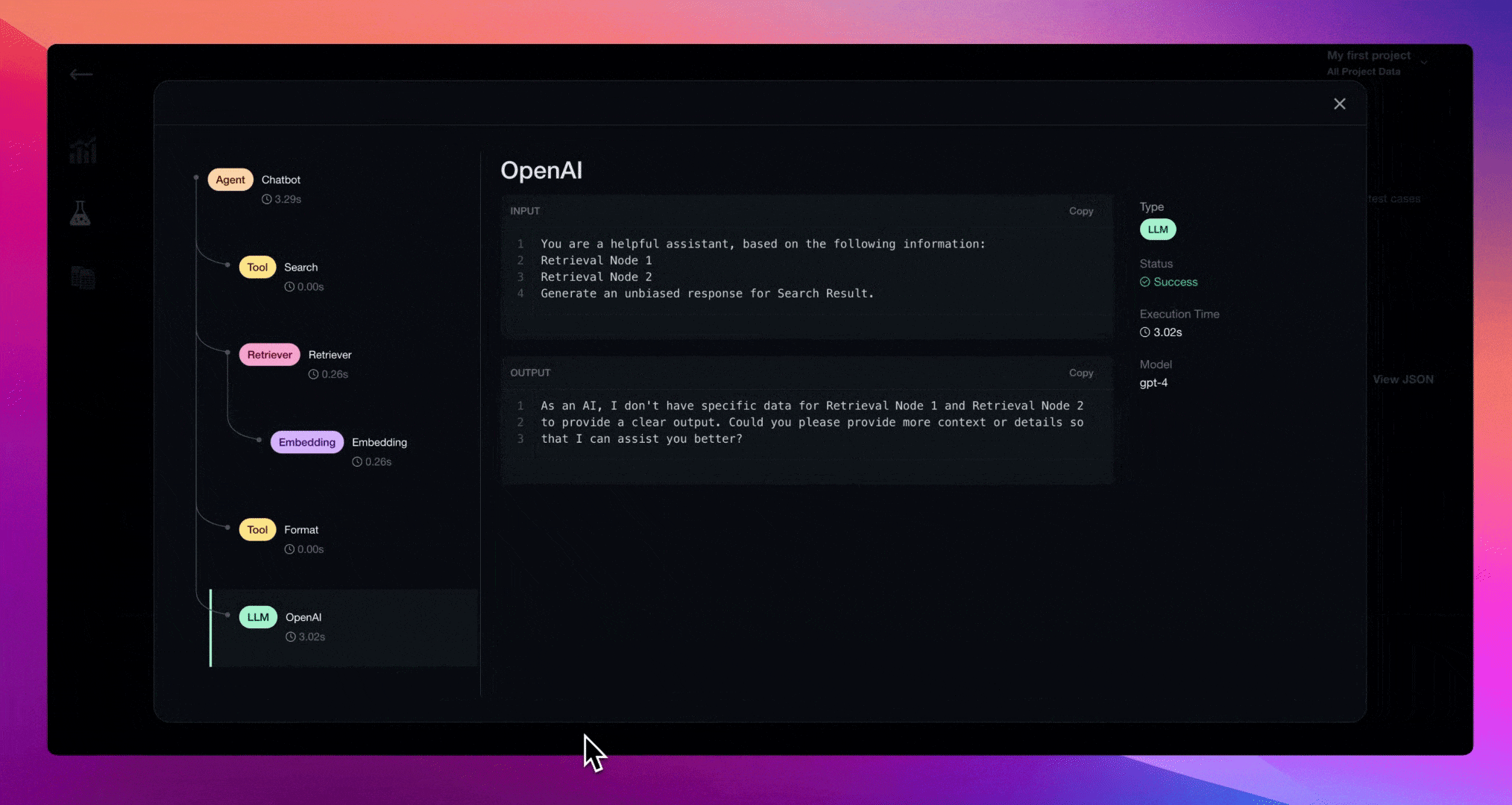
diff --git a/docs/docs/confident-ai-evaluate-datasets.mdx b/docs/docs/confident-ai-evaluate-datasets.mdx
new file mode 100644
index 000000000..8489b969b
--- /dev/null
+++ b/docs/docs/confident-ai-evaluate-datasets.mdx
@@ -0,0 +1,79 @@
+---
+id: confident-ai-evaluate-datasets
+title: Evaluating Datasets
+sidebar_label: Evaluating Datasets
+---
+
+## Quick Summary
+
+You can pull evaluation datasets from Confident AI and run evaluations using `deepeval` as described in the [datasets seciton.](evaluation-datasets)
+
+## Pull Your Dataset From Confident AI
+
+Pull datasets from Confident by specifying its `alias`:
+
+```python
+from deepeval.dataset import EvaluationDataset
+
+# Initialize empty dataset object
+dataset = EvaluationDataset()
+
+# Pull from Confident
+dataset.pull(alias="My Confident Dataset")
+```
+
+## Evaluate Your Dataset
+
+You can start running evaluations as usual once you have your dataset pulled from Confident AI. Remember, a dataset is simply a list of test cases, so what you previously learned on [evaluating test cases](evaluation-test-cases#assert-test-cases) still applies.
+
+:::note
+The term "evaluations" and "test run" means the same and is often used interchangebly throughout this documentation.
+:::
+
+### With Pytest (highly recommended)
+
+```python title="test_example.py"
+from deepeval import assert_test
+from deepeval.metrics import HallucinationMetric
+from deepeval.dataset import EvaluationDataset
+from deepeval.test_case import LLMTestCase
+
+# Initialize empty dataset object
+dataset = EvaluationDataset()
+
+# Pull from Confident
+dataset.pull(alias="My Confident Dataset")
+
+@pytest.mark.parametrize(
+ "test_case",
+ dataset,
+)
+def test_customer_chatbot(test_case: LLMTestCase):
+ hallucination_metric = HallucinationMetric(minimum_score=0.3)
+ assert_test(test_case, [hallucination_metric])
+```
+
+Don't forget to run `deepeval test run` in the CLI:
+
+```console
+deepeval test run test_example.py
+```
+
+### Without Pytest
+
+```python
+from deepeval import evaluate
+from deepeval.metrics import HallucinationMetric
+from deepeval.dataset import EvaluationDataset
+
+hallucination_metric = HallucinationMetric(minimum_score=0.3)
+
+# Initialize empty dataset object and pull from Confident
+dataset = EvaluationDataset()
+dataset.pull(alias="My Confident Dataset")
+
+dataset.evaluate([hallucination_metric])
+
+# You can also call the evaluate() function directly
+evaluate(dataset, [hallucination_metric, answer_relevancy_metric])
+```
diff --git a/docs/docs/confident-ai-introduction.mdx b/docs/docs/confident-ai-introduction.mdx
new file mode 100644
index 000000000..7cc3a0bcb
--- /dev/null
+++ b/docs/docs/confident-ai-introduction.mdx
@@ -0,0 +1,41 @@
+---
+id: confident-ai-introduction
+title: Introduction
+sidebar_label: Introduction
+---
+
+## Quick Summary
+
+Confident AI was designed for teams to bring LLM evaluations from development to production. It is an all-in-one platform that unlocks `deepeval`'s full potential by allowing you to:
+
+- evaluate LLM applications continously in production
+- centralize and standardize evaluation datasets on the cloud
+- trace and debug LLM applications during evaluation
+- keep track of the evaluation history of your LLM application
+- generate evaluation-based summary reports for relevant stakeholders
+
+## Continuous Evaluation
+
+Continuous evaluation refers to the process of evaluating LLM applications in not just development, but also in production and throughout the lifetime of your LLM application. Here's a quick diagram outlining how Confident AI enables this process:
+
+
+

+