The Data Factory that you can deploy with this solution will contain several pipelines that showcase different activities.
-
00-ControlPipelineThis pipeline calls all other pipelines and serves as orchestration for the entire loading process. This pipeline is triggered by a daily trigger. It uses Execute Pipeline activities to call the other pipelines.

This folder contains the pipelines for handling data from Dynamics 365. If you have created a demo account and entered its credentials when deploying the solution to Azure, the pipelines in this folder will process the data from Dynamics 365.
-
01-CopySalesActivityToCosmosThis pipeline reads the sales activity entity from Dynamics 365 and writes its contents to Cosmos DB. It uses a copy activity to achieve this
After this pipeline was run, you can browse your Cosmos DB using the data explorer from the Azure portal to see the entities that were written

-
02-CopyD365SalesLeadToStorageThis pipeline copies the Leads from Dynamics 365 to your storage account. It uses a copy activity to achieve this
After it was run, you can locate the data in your storage accout when browsing it through the Azure portal. The leads will be contained in the
d365datacontainer in a folder structure containing the year, month and day, you ran the pipeline in a file called ``leads.txt`
-
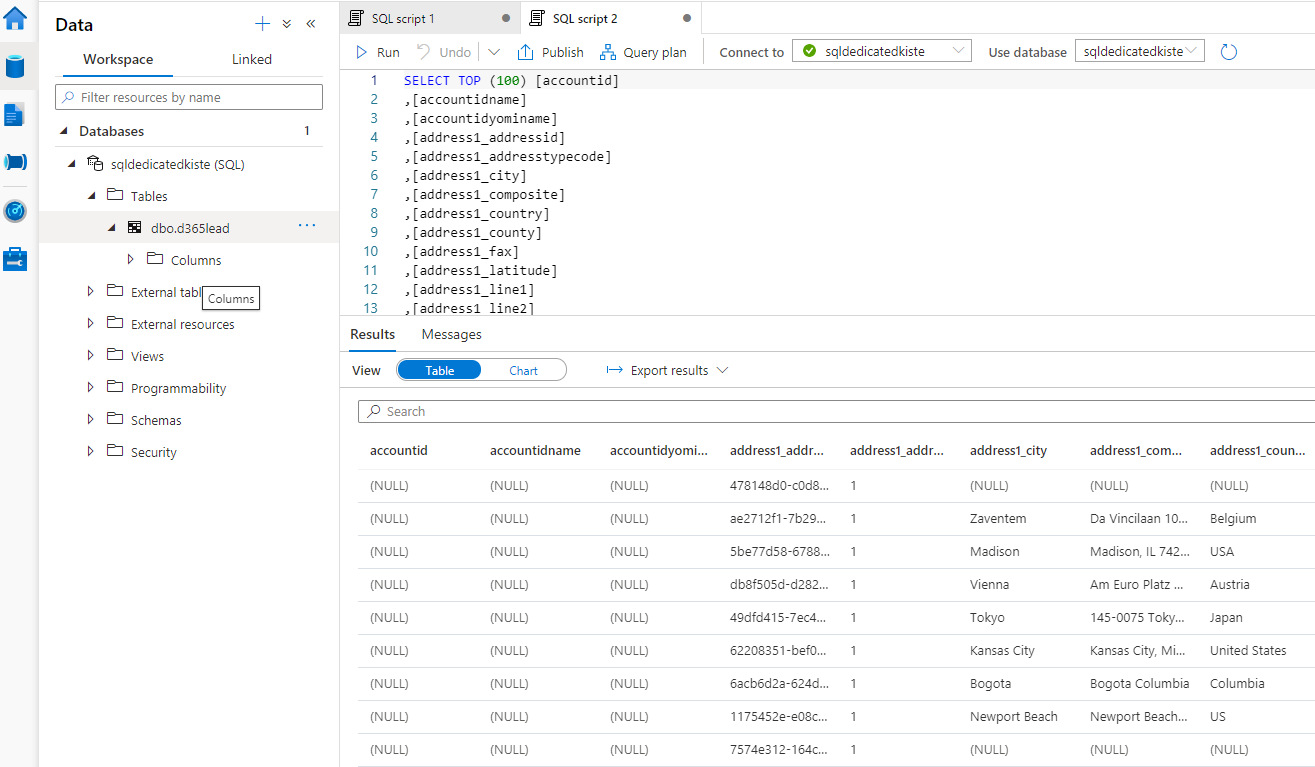
03-CopyD365SalesLeadsToSQLThis pipeline copies the same leads to the dedicated pool of your Azure Synapse Analytics workspace. You need to grant permissions to your ADF managed identity in order to run this pipeline by following the steps in the main documentation.
After you ran this pipeline, your sales leads are visible in the dedicated SQL pool in your Synapse workspace

-
04-AnonymizeSalesLeadsThis pipelines runs the Leads through a presidio webapp in order to remove personal information from it before storing it to the data lake. It iterates the files in the storage account and runs each row of each file through the presidio analyzer and presidio anonymizer before storing them to the storage account. Calling the presidio solution is handled in04-01-DataAnonymizationSingleFilefor each single file.First all files are iterated

For each file the
04-01-DataAnonymizationSingleFileis called
In
04-01-DataAnonymizationSingleFile, the files are read and a loop over their contents is created
In the foreach loop, the presidio APIs are called:

After
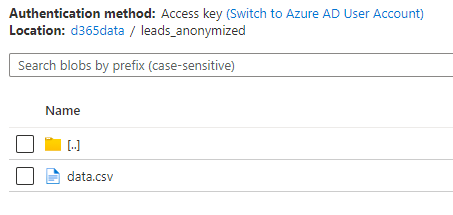
04-AnonymizeSalesLeadshas been called, in the storage account in thed365datacontainer, there will be a folder calledleads_anonymizedthat will contain the anonymized records
-
05-TransformDynamicsDatacalls theDFActivitiesAndLeadsdataflow (description below) that transforms the dynamics data and loads it into Common Data Model output format









This folder contains Pipelines to load and transform data from the New York Taxi dataset hosted on Azure
-
01-StageOpenDatacopies the Taxi Data from the Parquet files in which it is provied into json files. It uses a copy activity to move the data
-
02-TransformTaxiDatacalls theDFMoveTaxiDatadataflow (described below) that transforms the taxi data before loading it to the Synapse Analytics dedicated SQL pool

The solution contains two dataflows that transform the data:
-
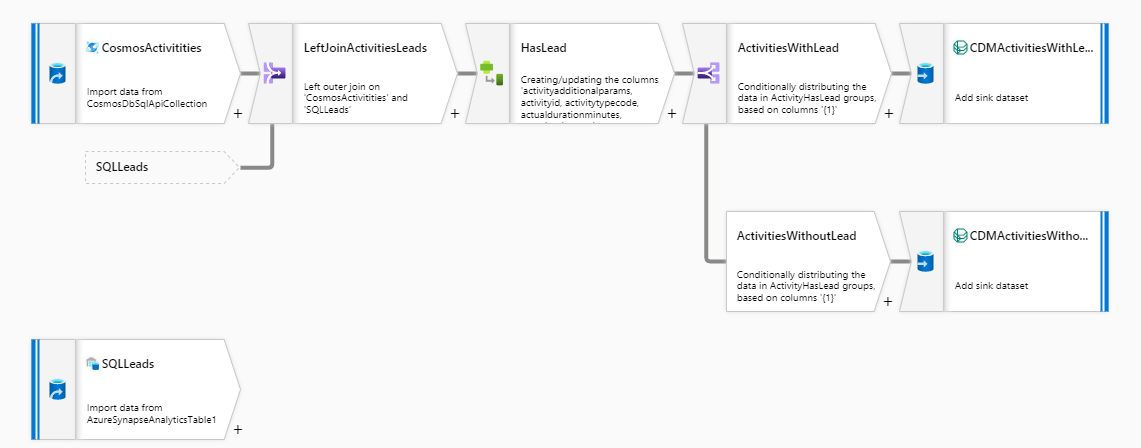
DFActivitiesAndLeadsThis dataflow joins the data from the Dynamics 365 Activites (located in Cosmos DB) and the Dynamics 365 Leads (located in the Azure Synapse Dedicated SQL Pool). It then checks if an activity is associated with a lead or not and writes the activitites with leads and the activities without leads into different folders
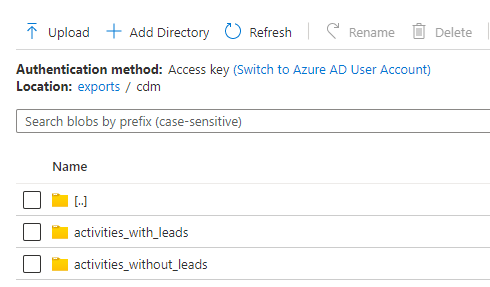
Running this dataflow for the first time will take several minutes as the cluster hosting the dataflow needs to be started. After the dataflow has completed, you will find two folders in the
exportscontainer of your storage account, one containing the activities with leads the other one containing the activities without leads
-
DFMoveTaxiDataloads the taxi data and adds a qualifier about the trip distance as a derived column to the dataset. Then it stores the data in your Azure Synapse Dedicated SQL Pool.
After running this dataflow, you will find a taxidata table in your dedicated synapse pool containg the original data and the distance qualification from the derived column in the dataflow.