VQA(Visual Question Answering)指的是,给机器一张图片和一个开放式的的自然语言问题,要求机器输出自然语言答案。答案可以是以下任何形式:短语、单词、 (yes/no)、从几个可能的答案中选择正确答案。VQA是一个典型的多模态问题,融合了CV与NLP的技术,计算机需要同时学会理解图像和文字。为了回答某些复杂问题,计算机还需要了解常识,基于常识进行推理(common-sense resoning)。正因如此,直到相关技术取得突破式发展的2015年,VQA的概念才被正式提出。
VQA是一个非常新颖的研究方向,可以将此概念与文本QA和Image Captioning、以及对象检测进行对比。
文本QA即纯文本回答,计算机根据文本形式的材料回答问题。与之相比,VQA把材料换成了图片形式。目的在于测试计算机对图片内容的理解。事实上,视觉问答被认为是一种视觉图灵测试,用来评估目前的机器学习模型在多大程度上实现了最终的通用人工智能。与此同时,VQA也引入了一系列新的问题:(1)图像是更高维度的数据,比纯文本具有更多的噪声。(2)文本是结构化的,也具备一定的语法规则,而图像则不然。(3)文本本身即是对真实世界的高度抽象,而图像的抽象程度较低,可以展现更丰富的信息,同时也更难被计算机“理解”。
Image Captioning算法的目标是生成给定图像的自然语言描述。它是一项非常广泛的任务,可能涉及描述复杂的属性对象关系,以提供图像的详细说明。与Image Captioning这种看图说话的任务相比,VQA的难度也显得更大。因为Image Captioning更像是把图像“翻译”成文本,只需把图像内容映射成文本再加以结构化整理即可,而VQA需要更好地理解图像内容并进行一定的推理,有时甚至还需要借助外部的知识库。 然而,VQA的评估方法更为简单,因为答案往往是客观并简短的,很容易与ground truth对比判断是否准确,不像Image Captioning需要对长句子做评估。
与VQA相关的还有一个任务—对象检测。对象检测对特定语义概念(如汽车或人)涉及的每个实例放置边界框进行定位。该任务只需要对图像中的主导对象进行分类,不需要理解其空间位置或在较大场景中的角色(VQA需要)。
VQA任务定义如下:
给机器输入一张图片和一个跟这幅图片相关的问题,机器需要根据图片信息对问题进行回答。训练阶段,需要先在一个由图像 ,问题
,答案
组成的三元组集
上训练一个模型。测试阶段,给该预训练模型输入一张新的图像和一个新的问题,要求模型能够预测正确的答案。设模型参数为
,则该任务的目标为求取)。
对于open-Ended问题,机器的输出是自然语言(算法需要生成一个字符串来回答问题)。对于multi-choice问题,机器挑选出正确答案。它们包括计算机视觉中的许多子问题,例如,对象识别 - 图像中有什么?对象检测 - 图像中是否有猫?属性分类 - 猫是什么颜色的? 场景分类 - 阳光明媚吗? 计数 - 图像中有多少只猫?
除此之外,还有许多更复杂的问题可以提出,例如问题关于物体之间的空间关系(猫和沙发之间是什么?)和常识性推理问题(女孩为什么哭?)。强大的VQA系统必须能够解决各种各样的经典计算机视觉任务以及需要推理图像的能力。
VQA相关扩展任务有:(1)图像集问答 (2)视频问答 (3)图像文本问答 (4)图表QA (5)360度图像VQA
(1)open-Ended:
1)simple accuracy:要求算法输出需要和the ground truth answer完全匹配,此种评估方法过于严格。
2)Modified WUPS:通过计算预测答案和标准答案之间的语义距离来衡量两者的不同,该值是0到1之间的数字。根据找到公共包含者需要遍历语义树的距离来分配分数。主要用于DAQUAR 和COCO-QA数据集。
根据两个单词在一个分类树中的最长公共子序列来计算相似性。如果预测单词和标准答案单词的相似性低于设定的阈值则候选答案的评分为0。WUPS的另一个主要问题是它只适用于严格的语义概念(几乎都是单个单词)。WUPS不能用于短语或句子答案(VQA数据集和Visual7W)。
3)Consensus Metric:针对每个问题,独立的收集多个ground truth answer(如:VQA、 DAQUAR-consensus)。DAQUAR-consensus每个问题由5个人提供答案。数据集的创建者提出了两种使用这些答案的方法,他们称为平均共识和最小共识。为了达成平均共识,最终分数会偏重于将更高的分数给予注释者提供的流行答案。为了达成最小共识,答案需要至少有一个注释者达成共识。
对于VQA数据集,注释者为每个问题生成了十个答案。精确度指标的变化形式为

其中n是与算法具有相同答案的注释者总数。
4)Manual Evaluation:两个标准,确定答案是否由人为产生,不管答案是否正确。 第二个度量标准使用三分制的答案进行评分,该分数为完全错误(0),部分正确(1)和完全正确(2)。
(2) multi-choice:
多项式选择任务(部分的VQA Dataset, Visual7W, and Visual Genome.),通常使用simple accuracy指标来评估,如果算法做出正确的选择,它就会得到正确的答案。。
目前,VQA涉及的数据集主要可以分为两类,一类是自然图像,用于图像内容理解研究(如DAQUAR、COCO-QA等);一类是合成图像,用于图像中的关系推理研究(如:CLEVER系列等)。
介绍:最早也是最小的VQA数据集,包含了6795张训练数据和5673张测试数据,所有图像来自于数据集NYU-DepthV2 Dataset,只包含室内场景。该数据集质量较差,一些图像杂乱无章,分辨率低,而且问答对具有明显的语法错误,这使得正确回答问题变得非常困难,即使人类也只能取得50.2%的准确率。
参考文献:M. Malinowski and M. Fritz, \A multi-world approach to question answering about realworld scenes based on uncertain input," in Advances in Neural Information Processing Systems (NIPS), 2014.
介绍:QA pairs是由NLP算法生成的,图像来自COCO数据集,一共有78736个训练QA pairs和38948个测试QA pairs,大部分的问题是关于图像中的目标(69.84%),其他问题是关于颜色(16.59%),计数(7.47%),位置(6.10%)。所有问题的答案都是一个单词,只有435个独一无二的答案。数据集最大的缺点在于QA pairs是用NLP算法生成的,是将长句子划分成短句子处理的,这就忽视了句子中的语法和从句问题,算法结果不够智能;另外,数据集只有4类问题。
下载地址:http://www.cs.toronto.edu/~mren/imageqa/data/cocoqa/
参考文献:M. Ren, R. Kiros, and R. Zemel, \Exploring models and data for image questionanswering," in Advances in Neural Information Processing Systems (NIPS), 2015.
介绍:基于COCO的一个数据集。数据集的QA都是人类生成的,最初是中文数据集,现在也提供了英文版本,FM-IQA 允许回答是一个句子。作者建议人类专家来判断生成的答案是否由人类提供,并以0~2的分数对答案的质量进行评估。 下载地址:
参考文献:H. Gao, J. Mao, J. Zhou, Z. Huang, L. Wang, and W. Xu, \Are you talking to a machine? Dataset and methods for multilingual image question answering," in Advances in Neural Information Processing Systems (NIPS), 2015.
介绍:图像来源是YFCC100M和COCO数据集,包含图像108077张和1700000个QA Pairs(平均每张图片17个QA Pairs),问题类型是6W(what, where, how, when, who, why)。包含两种模式:
- free-form method:可以针对图像提出任意问题;人类标注者通常会趋向于提出类似的问题。
- regionspecific method:针对图像的指定区域提问;
- Free form QA: What does the sky look like?
- Region based QA: What color is the horse?
该数据集答案非常多样化,并且没有是否问题。
在Visual Genome中出现频率最高的1000个答案只覆盖了数据集中所有答案的65%,而对于CoCo-VQA,它们覆盖了82%,对于数据CoCo-VQA,它们覆盖了100%。Visual Genome的长尾分布也可以在答案的长度上观察到。只有57%的答案是单个单词,相比之下,COCO-VQA有88%的答案,COCO-QA有100%的答案,DAQUAR有90%的答案。答案的多样性使得开放式评估更具挑战性。
下载地址:http://visualgenome.org/api/v0/api_home.html
参考文献:Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Li Fei-Fei. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comp. Vis., 123(1):32–73, 2017.
介绍:是Visual Genome数据集的一个子集,7W 指的是 "What, Where, How, When, Who, Why, Which."。数据规模:有47300张图像和139868个QA pairs。包含两类问题,‘telling’问题和Visual Genome一样,答案是基于文本。‘pointing’类型是以“which”开头的问题,要求算法在可选的多个候选答案中,选择正确的边界框。数据集不包含是否问题。
下载地址:http://web.stanford.edu/~yukez/visual7w/
参考文献:Yuke Zhu, Oliver Groth, Michael Bernstein, and Li Fei-Fei. Visual7w: Grounded question answering in images. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016.
介绍:该数据集由两部分组成:COCO-VQA 和 SYNTH-VQA;前者为真实图像(来自COCO数据集的204,721张图像),后者为合成卡通图像(50,000张)。VQA Dataset 为为每幅图片提供了三个问题,每个问题有十个答案。
COCO-VQA :该数据集比较大,共包含614,163 数据,其中,训练数据248,349个, 验证数据121,512,测试数据244,302 个。
SYNTH-VQA由 50,000 个合成场景组成,包含 100 多个不同的对象、30 种不同的动物模型和20个人类卡通模型。该数据集有15w问题对, 每个场景 3 个问题, 每个问题 10 个答案。通过使用合成图像,可以创建更多样化、更平衡的数据集。
SYNTH-VQA 和 COCO-VQA 包含open-ended 和multiple-choice两种格式。VQAv1有很多语言偏见(bias),有些问题过于主观而无法得到正确的答案,有些问题通常不需要图像就能得到好的(或可能的)答案。还有些问题寻求解释或冗长的描述,而数据集提供的答案非常不可信。
下载地址:https://visualqa.org/vqa_v1_download.html
参考文献:S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh. VQA: Visual question answering. In ICCV, 2015.
介绍:人工标注的开放式问答数据集,相较于VQAv1尽量减少了语言偏见(为每个问题补充了图片,为同一问题提供了不同答案的相似图像对),但是仍存在一些偏见。目前VQA自然数据集的基准一般是VQAv2。
下载地址:https://visualqa.org/download.html
参考文献:Y. Goyal, T. Khot, D. Summers-Stay, D. Batra, and D. Parikh. Making the V in VQA matter: Elevating the role of image understanding in Visual Question Answering. In CVPR, 2017.
介绍:人工标注的数据集,为了减少数据集类别偏见,将问题分成了12类具有明显差异的类别。实现了细致的任务驱动评估,包含跨问题类型的泛化的评估指标。
下载地址:
参考文献:K. Kafle and C. Kanan. An analysis of visual question answering algorithms. In ICCV, 2017.
介绍:该数据集对VQAv1进行了重新切分,使其可以用来研究语言的组合性问题。
参考文献: A. Agrawal, A. Kembhavi, D. Batra, and D. Parikh. C-vqa: A compositional split of the visual question answering (vqa) v1.0 dataset. CoRR, abs/1704.08243, 2017.
介绍:对VQAv2数据集进行重新组织,以确保每类问题的答案在训练集和测试集中具有不同的分布,以此克服训练集带来的偏差。
参考文献: A. Agrawal, D. Batra, D. Parikh, and A. Kembhavi. Don’t just assume; look and answer: Overcoming priors for visual question answering. In CVPR, 2018.~
介绍:该数据集为合成数据集,是由一些简单的几何形状构成的视觉场景。数据集中的问题总是需要一长串的推理过程,为了对推理能力进行详细评估,所有问题分为了5类:属性查询(querying attribute),属性比较(comparing attributes),存在性(existence),计数(counting),整数比较(integer comparison)。所有的问题都是程序生成的。该数据集的人为标注数据子集为CLEVR-Humans,
下载地址:
参考文献:J. Johnson, B. Hariharan, L. van der Maaten, L. Fei-Fei, C. L. Zitnick, and R. Girshick. CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning. In CVPR, 2017.
介绍:该数据集用于测试模型对于未知概念组合的处理能力和旧概念组合的记忆能力。数据集由两部分组成:CoGenT-A和CoGenT-B。里面的数据是一些特殊形状+颜色的组合。如果模型在CoGenT-A上训练,在CoGenT-B上无需微调就表现良好,则表示模型对新组合泛化能力较强。如果模型在CoGenT-B上微调后,在CoGenT-A上仍然表现良好,表示模型记忆旧概念组合的能力较优。平均而言,此数据集上的问题比大多数CVQA中问题都复杂。
下载地址:
参考文献:
一个用于对现实世界的图像进行视觉推理与综合回答的全新数据集 GQA,该数据集包含高达 20M 的各种日常生活图像,主要源自于 COCO 和 Flickr。每张图像都与图中的物体、属性与关系的场景图(scene graph)相关。此外,每个问题都与其语义的结构化表示相关联,功能程序上指定必须采取一定的推理步骤才能进行回答。
GQA 数据集的许多问题涉及多种推理技巧、空间理解以及多步推理,比起人们先前常用的视觉回答数据集,更具有挑战性。他们保证了数据集的平衡性,严格控制不同问题组的答案分布,以防止人们通过语言和世界先验知识进行有据猜测。
参考文献:Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
接下来介绍三个其他类型数据集。前两个是知识库相关的,第三个是解决与图片中文本有关的VQA问题。
介绍:知识库是基于DBpedia,图片来源于COCO,每张图会有3-5个QA pairs,总计有2402个问题,每个问题都是从23种模板里面选择的。
参考文献:P. Wang, Q. Wu, C. Shen, A. v. d. Hengel, and A. Dick. Explicit knowledge-based reasoning for visual question answering. arXiv preprint arXiv:1511.02570, 2015
介绍:该数据集不仅有图像和QA pairs,还有外部知识(extra knowledge),知识库有193, 449个事实句子,包含图像2190张,问题5826个,整个数据集分成了5个train/test集,每个集合包含1100张训练图像和1090张测试图像,分别有2927和2899个问题,问题总共可以分成32类。
参考文献:Peng Wang, Qi Wu, Chunhua Shen, Anthony Dick, and Anton van den Hengel. FVQA: Fact-based visual question answering. IEEE Trans. Pattern Anal. Mach. Intell., pages 1–1, 2017.
示例如下:
为了解决与图片中文本有关的VQA问题,研究者基于Open Images抽取了TextVQA数据集,该数据集需要识别文本才能回答问题。该数据集有28,408 张图像,45,336 个问题 ( 37,912 ),453,360 个答案 ( 26,263 )。每张图像 1-2 个问题,每个问题 10 个答案,问题的平均长度为 7.18 个单词,答案的平均长度为 1.58 个单词
下载地址:
参考文献:Towards VQA Models That Can Read(https://arxiv.org/pdf/1904.08920v2.pdf)
现有的视觉问答方法可以概括为如下三步:(1)将输入图像和输入问题,分别转换为对应的特征表示。(2)对两种模态的特征进行融合,得到图片和问题的联合信息。(3)最后把得到的联合特征送入到分类器中从预定义的候选答案集中推断最可能的答案,或者送入到解码循环神经网络中(Decoder RNN)来直接生成答案。
对于图像特征,大多数算法使用在ImageNet上经过预训练的CNN,常见示例为VGGNet,ResNet和GoogLeNet。问题特征化,包括词袋(BOW),长期短期记忆(LSTM)编码器,门控递归单元(GRU)等。

各种模型在集成图像特征和问题特征上有所不同。有(1)贝叶斯方法,使用贝叶斯模型,利用问题图像-答案特征分布预测答案。(2)借助神经网络,在神经网络框架中使用双线性池或相关机制(如简单机制,使用串联,逐元素乘法或逐元素加法集成,输入给线性分类器和神经网络)。(3)注意力机制:根据相对重要性自适应的缩放局部特征,关注特征从全局变为局部。(4)组合模型,将VQA任务分解为一系列子问题。
总体来说,目前VQA方法主要有两种,一种是单一模型方法,该方法针对不同的问题-图像对使用同一个模型。另外一种是模块化方法,注重组合推理,通过对问题解析,将VQA任务分解为一系列子问题,针对不同的子任务设计不同的模块。
使用贝叶斯模型利用问题图像-答案特征分布预测答案。首先对问题和图像进行特征化处理,在此基础上对问题和图像特征进行共现统计建模,来得出有关正确答案的推论。
两个主要的贝叶斯VQA框架已探索对这些关系进行建模。2014年,NIPS会议上,M. Malinowski and M. Fritz提出了第一个VQA贝叶斯框架。 作者使用语义分割来识别图像中的对象及其位置。 然后,对贝叶斯算法进行了训练,以对物体的空间关系进行建模,该算法用于计算每个答案的概率。 这是最早的VQA算法,但是效果不如基线模型,部分原因是它依赖于不完美的语义分割结果。[文章](M. Malinowski and M. Fritz, "A multi-world approach to question answering about real- world scenes based on uncertain input," in Advances in Neural Information Processing Systems (NIPS), 2014.)
2015年,同样的会议上,M. Ren, R. Kiros, and R. Zemel提出了一种非常不同的贝叶斯模型。 该模型利用了一个事实,即仅使用问题就可以预测答案的类型。 例如,“花是什么颜色?”将由模型分配为颜色问题,从本质上将开放式问题转变为多项选择题。 为此,该模型使用了二次判别分析的变体,该模型对给定问题特征和答案类型的图像特征概率进行了建模。 [文章](M. Ren, R. Kiros, and R. Zemel, "Exploring models and data for image question answering," in Advances in Neural Information Processing Systems (NIPS), 2015.)
该方法的特点是在共同的特征空间学习图像和问题的嵌入,然后将它们一起喂入预测答案的分类器或者生成器。Joint embedding是处理多模态问题时的经典思路,在这里指对图像和问题进行联合编码。该方法的示意图为:
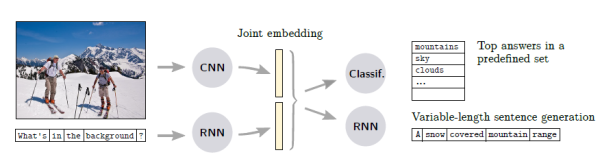
首先,图像和问题分别由CNN和RNN进行第一次编码得到各自的特征,问题embedding和图像embedding,随后共同输入到另一个编码器中得到joint embedding,最后通过解码器输出答案。 值得注意的是,有的工作把VQA视为序列生成问题,而有的则把VQA简化为一个答案范围可预知的分类问题。在前者的设定下,解码器是一个RNN,输出长度不等的序列;后者的解码器则是一个分类器,从预定义的词汇表中选择答案。
其中,比较经典的方法是Neural-Image-QA,使用了encoder-decoder架构来生成答案,该模型被认为是基线方法。后续又有该方法的各种变体,比如VIS+LSTM”、2-VIS+BLSTM”等。不同之处在于提取特征的方式,两种特征交互机制,以及预测答案的方式。
Multimodal QA方法的encoder和decoder使用了完全不同的参数,并且CNN的图像特征是以时间步为单位传送的。DPPnet学习了一个能够根据问题自适应确定权重的神经网络,用以解决VQA问题。
为了获得图像和问题之间更细粒度的交互,一些研究人员采用了复杂的融合策略— Bilinear pooling method(双线性池化),利用外积(outer-product)对两者进行更复杂的交互。比较经典的方法有MCB和MLB。
MCB(Multimodal Compact Bilinear pooling)近似估计图像和文本特征之间的外积(将其用于预测哪些空间特征与问题相关),允许两种模态之间进行更深层的交互。
多模态低秩双线性池(MLB):该方案使用Hadamard乘积和线性映射来实现近似双线性池。该方法是为了解决MCB的计算代价提出来的。
当与空间视觉注意力机制一起使用时,MLB在VQA上可与MCB媲美,但具有较低的计算复杂度并使用参数较少的神经网络。
直接使用全局(整个图像)特征来表示视觉输入,会引入无关或者冗余信息。VQA 中,使用基于空间的 Attention 机制来创建特定区域的 CNN 特征,使得模型只关注于输入的特定部分(图片和/或问题)。Attention 背后的基本思想是,图像中的某些视觉区域和问题中的某些单词对于回答给定的问题比其他区域或单词更能提供更多的信息。相关的工作表明,加入attention机制能获得明显的提升,从直观上也比较容易理解:在attention机制的作用下,模型在根据图像和问题进行推断时不得不强制判断“该往哪看”,比起原本盲目地全局搜索,模型能够更有效地捕捉关键图像部位。

该图说明了将注意力引入VQA系统的一种常用方法。 CNN中的卷积层输出K×K×N特征张量,对应于N个特征图。引入attention的一种方法是通过抑制或增强不同空间位置处的特征。 通过将问题特征与这些局部图像特征结合,可以计算出每个网格位置的权重因子,从而确定空间位置与问题的相关性,然后可以将其用于计算注意力加权的图像特征。
一般有两种方法对局部区域建模,一种是类似语义分割的方式,生成边缘框(Edge Boxes ),对每个框生成特征。一种是使用均匀网格(Uniform Grid)把图像分成若干区域,然后利用 CNN 生成每个网格区域的图像特征,然后计算每个区域与问题中每个词的相关度得到 Attention 权重矩阵。
1)The Focus Regions for VQA
使用Edge boxes生成图像的边界框。使用CNN从这些box中提取特征。
将这些CNN特征,问题特征以及多项选择答案输入VQA系统。
模型为每个候选答案产生一个分数,经过排序后得到最终答案。打分部分由一个全连接层完成。
2)FDA
模型建议仅使用与问题相关的对象objects的区域。 VQA系统输入带标签的边界框列表。
在训练期间,对象标签和边界框从COCO注释中获得。 测试时,使用ResNet 对每个边界框进行分类来获得标签。
随后,使用word2vec 计算问题中的单词与对象标签之间的相似度。 只要相似度大于 0.5 则认为是相关的。图像序列(分数大于0.5的box)和问题分别使用 LSTM 建模,得到特征后送入全连接层分类得到答案。在最后一个时间步,模型还输入了图像的全局特征,用于访问全局以及局部特征。
与使用Edge Boxes 相比,堆叠注意力网络(SAN)和动态内存网络(DMN)都使用了CNN特征图空间网格中的视觉特征。
1)[SAN](Z. Yang, X. He, J. Gao, L. Deng, and A. J. Smola, "Stacked attention networks for image question answering," in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.)
模型提取 VGG19 最后一个 Pooling 层的 feature map 作为区域特征,其大小为 14*14*512。相当于把原始 448*448 的图像均匀划分为 14*14 个网格(grid),每个网格使用一个 512 维的向量表示其特征。
Attention 层:主要作用是计算每个网格与问题的相关度。在得到每个网格与问题的相关度后,对所有网格进行加权求和,从而得到整个图像加权后的全局特征;然后将此特征向量与问题特征向量组合在一起,通过softmax层以预测答案。
堆叠 Attention:对于复杂的问题,单一的 Attention 层并不足以定位正确的答案预测区域。本文使用多个 Attention 层迭代上述过程,从而使系统能够对图像中多个对象之间的复杂关系进行建模。
2)空间记忆网络(SMem)
在空间记忆网络模型中使用了类似的注意机制,区别在于本文计算的是问题中的每个词在每个网格的关注度。 用单词引导的注意力来预测注意力分布,然后用于计算图像区域的视觉特征嵌入的加权和。
作者探索了两种不同的模型。 One-Hop Model 使用整合后的问题特征和加权视觉特征来预测答案。 Two-Hop Model 中将整合后的问题和加权视觉特征循环回注意力机制中,从而细化注意力分布。
3)动态内存网络(DMN)
提出了使用CNN特征图合并空间注意力的另一种方法。
DMN由input模块,episodic memory模块和answering模块组成。
DMN已成功用于文本QA。文本问答的输入为一系列可能与问题相关的情景句子(上下文),而视觉问答的输入为网格划分后的图像,每一块网格作为可能与问题相关的情景。episodic memory模块用于提取输入中的相关事实;每次迭代时更新内部记忆单元;应答模块通过整合最终的记忆单元与问题的表示来生成答案(RNN)。
4)层次协同注意力模型(HieCoAtten)
将注意力同时应用于图像和问题,来共同推理这两种不同的信息流。
该模型的视觉注意力方法类似于空间记忆网络中使用的方法。此外,进一步细化了问题,基于词、短语、句子三个层级分别构建 Attention 权重。
基于这种分层的问题表示,作者提出了两种不同的注意力机制parallel co-attention 和 alternative co-attention。parallel co-attention同时关注问题和图像。alternative co-attention是在关注问题或图像之间交替进行。这种方法允许彼此确定单词相关性和特定图像区域的相关性。最终的答案通过由低到高依次融合三个层级的特征来预测。
5)互相注意力模型(DAN)
本文的主要思想是允许问题于图像互相 Attention,从而直接关注关键词或关键区域。
为了实现这一点,本文先将图像特征和问题特征整合为记忆向量(按位乘),然后利用该记忆向量分别对问题和图像构建 Attention 向量。该过程可以递归的进行,下一轮的输入为上一轮得到两个 Attention 向量,但是作者建议迭代 2 次即可。
性能及缺陷:注意力机制能够改善提取全局特征的模型性能。最近的研究表明,注意力机制尽管能够提高VQA的总体精度,但是对于二值类问题却没有任何提升,一种假说是二值类问题需要更长的推理,这类问题的解决还需要进一步研究。
一些复杂的问题可能需要多个推理步骤,Compositional Models的核心思想是试图通过一系列子步骤解决VQA问题。
这方面的一个典型代表是Andreas等人的Neural Module Networks。Neural Module Network(神经模块网络)使用外部解析器来寻找问题中的子问题,其最大的特点是根据问题的类型动态组装模块来产生答案。

NMN 框架将 VQA 视为由独立的子网络执行的一系列子任务。每个子网络执行一个定义良好的任务。比如 find [X], describe [X], measure [X], transform[X] 等模块。这些模块必须组装成一个有意义的布局;该模型使用一个自然语言解析器来发现问题中的子问题,同时用于推断子任务需要的布局。
比如 "What color is the tie?" 模型首先利用parser对问题进行语法解析,接着判断出可能会执行 find[tie] 模块和 describe[color] 模块。然后判断出这两个模块的连接方式。最终,模型的推理过程是,先把注意力集中到tie上,然后对其color进行分类,得出答案。
2)Dynamic Memory Networks

而在另一个例子中,当面对 Is there a red shape above a circle? 这种更为复杂的问题时,模型选择的模块也自动变得复杂了许多。另一个典型代表是Xiong等人的Dynamic Memory Networks。该网络由四个主要的模块构成,分别是表征图像的input module、表征问题的question module、作为内存的episodic memory module和产生答案的answer module。 模型运作过程如下图。此网络在之前介绍过,不再重复。

3)Recurrent Answering Units RAU模型可以在不依赖外部语言分析器的情况下隐式地执行组合推理。模型中使用了多个可以解决VQA子任务的独立应答单元。 这些应答单元以 RNN 方式排列。每个应答单元都配备了一种注意力机制和一个分类器。 模型利用类似门机制的方式来自动选择由哪些模块回答问题。
4)TRRNet(TRRNet: Tiered Relation Reasoning for Compositional Visual Question Answering: ECCV 2020)
提出了一种分层注意网络进行关系推理。TRR网络由一系列TRR单元组成。每个TRR单元都可以分解为四部分。
root attention :对象级的attention。
attention passing :进行对象级的attention的映射并产生成对关系
leaf attention:关系级的attention
a message passing module:汇总对象attention和关系attention,并传递至下一阶段。
建立了一个策略网络,输入自然语言问题,选择合适的推理步骤,输出推理。
虽然VQA要解决的是看图回答问题的任务,但实际上,很多问题往往需要具备一定的先验知识才能回答。例如,为了回答“图上有多少只哺乳动物”这样的问题,模型必须得知道“哺乳动物”的定义,而不是单纯理解图像内容。因此,把知识库加入VQA模型中就成了一个很有前景的研究方向。涉及范围可以从常识到专题,目前已有的外部知识库包括:DBpedia、Freebase、YAGO、OpenIE、NELL、WebChild、ConceptNet。
1) Ahab
首先用CNN提取视觉概念,然后结合DBpedia中相似的概念,再学习image-question到queries的过程,通过总结查询结果来获得最终答案。
2)利用外部知识的联合嵌入模型
首先用CNN提取图像的语义属性,然后从DBpedia检索相关属性的外部知识,将检索到的知识用Doc2Vec嵌入到词向量中,最后将词向量传入到LSTM网络,对问题进行解释并生成答案。该工作的模型框架如下。

模型虽然看似复杂,但理解起来不外乎以下几个要点:
- 红色部分表示,对图像进行多标签分类,得到图像标签(attribute)。
- 绿色部分表示,利用上述图像标签生成多个图像描述(caption),将这一组图像描述编码。
- 以上三项同时输入到一个Seq2Seq模型中作为其初始状态,然后该Seq2Seq模型将问题进行编码,解码出最终答案,并用MLE的方法进行训练。
| ECCV 2020 | Reducing Language Biases in Visual Question Answering with Visually-Grounded Question Encoder | 下载地址 | 针对VQA模型的language bias。提出 Visually Grounded Question Encoder (VGQE)方法,在对问题进行encoder时同时使用了问题和图像特征,生成具有visually-grounded的问题编码。 | VQA-CPv2、VQAv2 | 联合嵌入 |
|---|---|---|---|---|---|
| ECCV 2020 | Semantic Equivalent Adversarial Data Augmentation for Visual Question Answering | 下载地址 | 解决的是VQA的数据扩充问题。提出了一个VQA中图像和文本对抗样本增强的方法。且增强的样本能够保留语义正确性。https://github.com/zaynmi/seada-vqa | VQAv2 | |
| ECCV 2020 | Visual Question Answering on Image Sets | 下载地址 | 引入了一个图像集可视化问答(ISVQA)任务,介绍了两个ISVQA数据集,建立了新的基线。 | ISVQA datasets for indoor and outdoor scenes | |
| ECCV 2020 | VQA-LOL: Visual Question Answering under the Lens of Logic | 下载地址 | 为了回答多个问题的逻辑组合(negation, conjunction,and disjunction),提出LOL模型,该模型同时使用了question-attention 和 logic-attention(用以理解问题中的逻辑连接词)和 Fr´echet-Compatibility损失函数(确保问题答案逻辑一致)。 | VQA v2 Test-Standard。并构建了VQA-Compose 和VQA-Supplement | attention |
| ECCV 2020 | TRRNet: Tiered Relation Reasoning for Compositional Visual Question Answering | 下载地址 | 提出一种分层关系推理方法,该方法可以根据语言表示动态选择对象级别的候选对象并产生关系对。提高了网络计算效率,改善了关系推理性能。建立了一个策略网络,根据问题的复杂性和当前的推理状态采取适当的推理步骤。 | VQAv2(Test-dev、Test-std) | 组合模型 |
| ECCV 2020 | Spatially Aware Multimodal Transformers for TextVQA | 下载地址 | TextVQA任务:利用图片中的文字进行推理,回答问题。现有方法对空间关系的利用非常有限,且依赖全连接的transformer结构来隐式的学习出现在图像中的空间结构特征。与之相反,我们提出了一个创新性的空间注意的自注意力层,以此来让每一个图像中出现的实体可以通过空间图来只关注与之相邻的实体。具体来说,在transformer的多头自注意力层中,每一个头都只关注关系中的一个子集关系。该方法有两个优点:(1) 每个头只考虑局部上下文,而不是把注意力分散到所有实体;(2) 我们避免了模型学习到多余的特征。 | ST-VQA | |
| CVPR 2020 | Multi-Modal Graph Neural Network for Joint Reasoning on Vision and Scene Text | 下载地址 | TextVQA任务:要想让模型理解图片场景中单词的含义,仅仅诉诸于词表有限的预训练单词嵌入表示是远远不够的。一个理想的模型应该能够根据场景中周围丰富的多模态的信息推测出这些单词的信息。多模态图神经网络(Multi-Modal Graph Neural Network,MM-GNN),它可以捕获图片当中各种模态的信息来推理出未知单词的含义。模型首先用三个不同模态的子图来分别表示图像中物体的视觉信息,文本的语言信息,以及数字型文本的数值信息。然后,引入三种图网络聚合器(aggregator),它们引导不同模态的消息从一个图传递到另一个图中,从而利用各个模态的上下文信息完善多模态图中各个节点的特征表示。这些更新后的节点特征进而帮助后续的问答模块。 | TextVQA dataset | |
| CVPR 2020 | On the General Value of Evidence, and Bilingual Scene-Text Visual Question Answering | 下载地址 | TextVQA任务:VQA现在的问题还是在于泛化性。他们是学习图像数据和文本数据之间一种内在的巧合关联,而不是深层关系。本文提出一种新的数据集—EST-VQA数据集数据集,EST-VQA是首个中英双语数据集。并且引入了一种基于事实的评估方法。 | EST-VQA | |
| CVPR 2020 | In Defense of Grid Features for Visual Question Answering | 下载地址 | 作者重新审视网格特征,以替代视觉和语言任务中广泛使用的bottom-up region特征。作者提出了网格化的特征输入,速度要比区域特征要快,达到良好的效果,值得借鉴。 | VQA 2.0 test-std | |
| CVPR 2020 | Counterfactual Samples Synthesizing for Robust Visual Question Answering | 下载地址 | 作者提出了一种与模型无关的反事实样本合成(CSS)训练方案。 CSS通过掩盖图像中的关键对象或问题中的单词并分配不同的真实答案来生成大量反事实训练样本。在使用互补样本(即原始样本和生成的样本)进行训练后,VQA模型被迫专注于所有关键对象和单词,从而显着提高了视觉可解释性和问题敏感性能力。参考:https://blog.csdn.net/xiasli123/article/details/106098825 | VQA-CP v2 | |
| CVPR 2020 | Counterfactual Vision and Language Learning | 下载地址 | 为了应对数据集中的偏差(为得到更好的泛化),作者在通过生成一组反事实的例子来扩充训练数据,利用结构性因果模型进行反事实评估,以制定替代方案。该样本生成策略消除了传统的条件独立性假设。 | VQA v2 validation、VQA-CP | |
| CVPR 2020 | Iterative Answer Prediction With Pointer-Augmented Multimodal Transformers for TextVQA | 下载地址 | 现有的TextVQA方法大多基于两种模式之间的自定义成对融合机制,并将TextVQA转换为分类任务,限制为单个预测步骤。在这项工作中,我们提出了一种新的基于多模态Transformer架构的TextVQA任务模型,该架构具有丰富的图像文本表示。模型通过将不同的模式嵌入到一个共同的语义空间中来自然地融合不同的模式,在这个语义空间中,self-attention被应用到模式间和模式内。此外,通过动态pointer network实现了答案的迭代解码,允许模型通过多步预测来形成答案。 | TextVQA 、OCR-VQA、ST-VQA | |
| CVPR 2020 | Towards Causal VQA: Revealing and Reducing Spurious Correlations by Invariant and Covariant Semantic Editing | 下载地址 | 尽管视觉问答(VQA)取得了巨大的成功,但VQA模型已经被证明对问题中的语言变化非常脆弱。由于模型和数据集的缺陷,目前的模型通常依赖于相关性,而不是因果的w.r.t.数据预测。在本文中,我们提出了一种新的方法来分析和衡量语义视觉变化的最新模型的稳健性,并提出了使模型更健壮地对抗虚假相关性的方法。我们的方法执行自动语义图像处理和模型预测一致性测试,以量化模型的鲁棒性,并生成合成数据来解决这些问题。我们对三种不同的、最先进的VQA模型和不同的问题类型进行分析,特别关注具有挑战性的计数问题。此外,我们还表明,使用我们编辑的数据,模型可以显著地提高对不一致预测的鲁棒性。最后,我们表明结果还可以转化为最新模型的真实错误案例,从而提高了整体性能。 | 提出的合成数据集:IV-VQA and CV-VQA. | |
| CVPR 2020 | SQuINTing at VQA Models: Introspecting VQA Models with Sub-Questions | 下载地址 | 模型答对了问题,但是可能并没有理解图像,这体现在对问题的回答存在不一致性。本文提出一个数据集,将VQA任务中的问题分为两类:Reasoning、Perception。其中,Perception类问题是Reasoning类问题的子问题(前提)。并提出了一种称为子问题重要性感知网络调整(SQuINT)的方法,该方法鼓励模型在回答Reasoning问题和Perception子问题时关注图像的相同部分。 | VQAv1 、VQAv2 | |
| CVPR 2020 | TA-Student VQA: Multi-Agents Training by Self-Questioning | 下载地址 | 目的:增强训练数据的多样性。 分类:(1)standard deep learning models、(2)attention-based deep learning techniques、(3)non-deep learning approaches、(4)Knowledge base support methods |
VQA-v2 | |
| CVPR 2020 | VQA with No Questions-Answers Training | 下载地址 | 没有看明白。 方法包含两步:(1)使用基于序列的LSTM模型将问题映射为graph。(2)循环应答过程:遵循graph,在image中搜索有效的assignment。调用相关子过程并进行集成信息提供答案。在每个步骤中,设置处理节点,并根据节点的要求检查object(使用mask R-CNN提取)。 分类(1)end-to-end methods:1)improving the image-question fused features;2)attention mechanisms for selecting important features;3)applying pre-trained networks (2)integrated external prior knowledge:1)generating a query to a knowledge database;2)fusing it in the representation;3)using a textual image description;4)by added loss terms (3)dynamic networks:1)based on the dependency parsing of the question 2)supervised answering program learning |
CLEVR test set | 组合模型?? |
| CVPR 2020 | Webly Supervised Knowledge Embedding Model for Visual Reasoning | 下载地址 | 如何利用网络有标签图像构建强大而有效的知识嵌入模型,进行有限标记数据下的视觉推理任务。 | GQA , CLEVR | |
| CVPR 2020 | Differentiable Adaptive Computation Time for Visual Reasoning | 下载地址 | 该方法能够实现自适应计算,端到端可微。且可与多个网络结合使用。我们将其应用于mac架构,提高了计算性能。 这个是算法上的改进,不算是模型!!! |
||
| ACL 2020 | A negative case analysis of visual grounding methods for VQA | 下载地址 | 提供适当的、人类视觉线索并非必要;随机的、无关线索也会导致类似的改进。基于此观察,我们提出了一个简单的正则化方案(不需要任何外部注释)。该方法在VQA-CPv21上实现了接近最先进水平的性能。资料:https://github.com/erobic/negative_analysis_of_grounding | VQACPv2和VQAv2 | attention-based |
| ACL 2020 | Cross-Modality Relevance for Reasoning on Language and Vision | [下载地址] | 本文用于处理学习和推理语言和视觉数据的相关下游任务的挑战,如视觉问题回答(VQA)和自然语言的视觉推理(NLVR)。 作者设计了一个新颖的跨模态关联模型,用端到端框架在目标任务的监督下学习各种输入模态组件之间的关联表示,这比仅仅重塑原始表示空间更易于推广到未观测的数据。除了对文本实体和视觉实体之间的相关性进行建模外,作者还对文本中的实体关系和图像中的对象关系之间的高阶相关性进行建模。本文提出的方法使用公共基准,在两个不同的语言和视觉任务上显示出具有竞争力的性能,并改进了最新发布的结果。NLVR任务学习的输入空间对齐及其相关表示提高了VQA任务的训练效率。 https://blog.csdn.net/qq_40945404/article/details/109287702 |
VQAv2 | 深度学习-联合嵌入表示 |
| ACL 2020 | Aligned Dual Channel Graph Convolutional Network for Visual Question Answering | 下载地址 | 同时捕捉图像的实体关系和问题单词间的句法依存关系,提出了一个双通道图卷积网络。由三模块构成,I-GCN捕捉image中对象间关系, Q-GCN捕捉单词间句法依存关系,注意对齐模块用于对齐图像表示和问题表示。 | VQA-v2 and VQA-CP-v2 | attention?图卷积? |
| AAAI 2020 | Multi‐Question Learning for Visual Question Answering | 下载地址 | 有关视频序列的多问题学习,视频介绍:https://yq.aliyun.com/live/2073 | ||
| AAAI 2020 | Explanation vs Attention: A Two-Player Game to Obtain Attention for VQA | 下载地址 | 在本文中,作者旨在提高对视觉问题解答(VQA)任务的关注。提供监督以引起注意是一项挑战。作者所做的观察是,通过类激活映射(特别是Grad-CAM)获得的视觉解释(旨在解释各种网络的性能)可以形成一种监管手段。但是,由于注意力图的分布和Grad-CAM的分布不同,因此不适合将其直接用作监督形式。相反,作者建议使用区分器,以区分视觉解释和注意图的样本。使用注意力区域的对抗训练作为注意力和解释之间的两人游戏,可以使注意力图和视觉解释的分布更加接近。重要的是,我们观察到,提供这种监管手段还可以使注意力图与人的注意力更加紧密相关,从而大大改善了基线堆叠注意力网络(SAN)模型。这也导致VQA任务的等级相关度量得到了很好的改善。该方法也可以与最近基于MCB的方法结合使用,从而获得一致的改进。作者还提供了与其他学习分布方式的比较,例如基于相关比对(Coral),最大平均差异(MMD)和均方误差(MSE)损失,并观察到对抗损失优于学习注意图的其他形式。结果的可视化也证实了我们的假设,即使用这种形式的监督可以改善注意力图。参考:https://blog.csdn.net/xiasli123/article/details/104112250 | VQA-v1 and VQA-v2 | attention? |
| AAAI 2020 | Overcoming Language Priors in VQA via Decomposed Linguistic Representations | 下载地址 | 基于语言注意力的VQA方法。通过学习问题的分解语言表示来克服语言偏见。使用language attention模块,将问题解析为三个短语表示:type 表示, object 表示, 和concept 表示 type 表示:可以用来识别问题类型以及可能的答案集合。将基于语言的概念发现与基于视觉的概念验证进行解耦 object 表示:可以聚焦于image的相关region。concept 表示通过参与region进行验证并推断答案。该方法用参与区域推断答案,并从答案推理过程中进行验证。因此,问题和答案之间的肤浅联系不能在回答过程中占据主导地位,模型必须利用图像来推断答案。 参考:https://blog.csdn.net/BierOne/article/details/104566242 分类:(1)The holistic methods:use a single model for different question-image pairs:(2)The modular methods:focus on compositional reasoning, devise different modules for different sub-tasks and perform better in the synthetic VQA datasets首先将问题解析为模块布局,然后执行模块来推断答案。 |
VQA-CP v2 test | attention? |
| AAAI 2020 | Unified Vision-Language Pre-Training for Image Captioning and VQA | 下载地址 | 本文提出了一种统一的视觉语言预训练(VLP)模型。(1)可以同时对视觉语言生成和理解任务进行微调(使用同样的pre-trained models,参数共享),(2)使用一个共享的多层transformer网络进行编码和解码。现有方法的编码器和解码器均使用单独的模型来实现。VLP模型在大量的图片-问题对上进行预训练,它在两项任务上使用了无监督学习目标:双向和seq2seq视觉语言mask预测。这两个任务仅在预测条件的上下文中不同。通过对共享transformer网络使用特定的self-attention masks来控制。据我们所知,VLP是第一个在视觉语言生成和理解任务方面都取得最新成果的模型。代码:https://github.com/LuoweiZhou/VLP | VQA 2.0 (Test-Standard) | 深度学习??pre-trained models+fine-tune |
| AAAI 2020 | Re-Attention for Visual Question Answering | 下载地址 | 答案中也包含了丰富的信息,可以帮助我们描述图像,生成精确的attention maps。为此建立了一个re-attention框架。1)首先通过计算特征空间中每个对象、词的对的相似度来关联图像和问题;2)根据答案,学习的模型重新关注图像中相应的视觉对象,并重建初始注意力图以产生一致的结果。 分类:(1)Fusion-based methods :1)利用现有融合方法;2)推理问题和图像之间的复杂交互,3)利用图来探索理解问题图像的过程(2)attention-based 1)visual attention mechanisms ;3)fco-attentin based methods |
VQA v2 | attention |
| WACV2020 | Deep Bayesian Network for Visual Qu | 下载地址 | 用一个深度贝叶斯网络来生成视觉问题。 | ||
| WACV2020 | Robust Explanations for Visual Question Answering | 下载地址 | 生成鲁棒的解释(抵抗图像扰动) | VQA-X:解释数据集 | |
| WACV2020 | Visual Question Answering on 360◦ Images | 下载地址 | 引入了一个新任务,VQA 360◦。并收集了第一个该任务的数据集 | VQA 360◦数据集 | |
| WACV2020 | LEAF-QA: Locate, Encode & Attend for Figure Question Answering | 下载地址 | 图表QA(Charts/figures),并引入了一个新的数据集LEAF-QA。介绍了评估方法。 | LEAF-QA | |
| WACV2020 | Answering Questions about Data Visualizations using Efficient Bimodal Fusion | 下载地址 | 图表问答(CQA)是一种新兴的问答系统可视问答(VQA)任务,其中一个算法必须回答有关数据可视化的问题,例如条形图图表、饼图和折线图。提出了一个CQA算法——图像和语言的并行递归融合(PReFIL)。 PReFIL首先学习双模态嵌入,通过融合问题和图像特征,智能地汇总这些学习的嵌入以回答问题。之前的比较好的方法是:FigureQA和DVQA | ||
| ACL2019 | Generating Question Relevant Captions to Aid Visual Question Answering | 下载地址 | 作者把Image caption和VQA结合起来,为VQA中的图片生成与问题相关的描述。因为两个任务需要连接语言和视觉的共同知识体系。阶段一:以在线方式训练model来生成与问题相关的字幕。阶段二:VQA模型使用第一阶段生成的字幕进行微调,以预测答案。 | VQA v2. | attention?h还是别的?? |
| ACL2019 | Psycholinguistics meets Continual Learning: Measuring Catastrophic Forgetting in Visual Question Answering | 下载地址 | 当心理语言学遇见持续学习: 衡量视觉问答中的灾难性遗忘。 作者设计了一系列的实验,衡量VQA问题中的灾难性遗忘。 任务的难度和顺序很重要,都会影响遗忘。目前两种著名的持续学习方法仅可以在有限程度上减轻遗忘问题。 |
CLEVR | 没太看懂 |
| ACL2019 | Improving Visual Question Answering by Referring to Generated Paragraph Captions | 下载地址 | 将段落字幕和对应的图像一起作为输入,在此基础上回答问题。包含三层融合,通过交叉注意(early融合)对输入进行融合以提取相关信息,然后以共识的形式再次融合(late融合),最终期望的答案被给予额外的分数以增加被选择的机会(later融合)。段落标题通过RL来自动生成。 | Visual Genome | attention |
| ACL2019 | Multi-grained Attention with Object-level Grounding for Visual Question Answering | 下载地址 | 粗粒度的注意力机制倾向于在小物体上以及不常见的概念上失败。提出一种多粒度注意力机制来融合图像-问题信息。对于问题,不仅仅利用词汇编码信息,利用ELMO的句子级的编码信息。更加精细的关联视觉区域和问题。第一次将elmo引入VQA任务中。 | VQA v2 test-dev和 test-std | attention |
| ICCV 2019 | Compact Trilinear Interaction for Visual Question Answering | 下载地址 | 作者认为在视觉问题解答(VQA)中,答案与问题含义和视觉内容有很大的关联。 因此,为了有选择地利用图像,问题和答案信息,我们提出了一种新颖的三线性交互模型,该模型同时学习了这三个输入之间的高级关联。 此外,为了克服交互的复杂性,我们引入了基于多模态张量的PARALIND分解,该分解有效地参数化了三个输入之间的三线性交互。 此外,知识蒸馏是首次应用于自由形式的开放式VQA。 它不仅用于减少计算成本和所需的内存,还用于将知识从三线性交互模型转移到双线性交互模型。参考:https://blog.csdn.net/xiasli123/article/details/104026986?utm_medium=distribute.pc_feed_404.none-task-blog-searchFromBaidu-7.nonecase&depth_1-utm_source=distribute.pc_feed_404.none-task-blog-searchFromBaidu-7.nonecas | Visual7W、 VQA-2.0 、 TDIUC | attention |
| ICCV 2019 | Scene Text Visual Question Answering | 下载地址 | 提出了一个新的数据集ST-VQA,图像的文本问答,并给出了一系列评价标准。 | ST-VQA, | |
| ICCV 2019 | Multi-modality Latent Interaction Network for Visual Question Answering | 下载地址 | 作者认为,现有的视觉问答方法大多是对单个视觉区域和单词之间的关系进行建模,不足以正确回答问题。从人的角度来看,回答视觉问题需要理解视觉和语言的摘要。为此在本论文中,作者提出了多模态潜在交互模块(MLI)来解决此问题。这样的MLI模块可以堆叠多个阶段,以对单词和图像区域两种模式之间的复杂和潜在关系进行建模,实验表明在VQA v2.0数据集上,此方法更具有竞争性的性能。参考:https://blog.csdn.net/xiasli123/article/details/102899201参考:https://blog.csdn.net/z704630835/article/details/108451399 | VQA v2.0 、TDIUC [20]. | 关系推理,这个文章什么方法,没看出来?普通架构??多模块堆叠? |
| ICCV 2019 | Relation-Aware Graph Attention Network for Visual Question Answering | 下载地址 | 该论文很敏锐地意识到,物体的视觉关系可以分为三大类,用不同的graph对这三种关系建模,然后综合起来。文章的模型针对每一种关系都分别训练了一个relation encoder,然后在inference阶段将三个encoder进行综合,形成一个ensemble model,最终预测答案的概率为:。https://zhuanlan.zhihu.com/p/63207928 | “GCN + Attention”。建模关系?? | |
| ICCV 2019 | Why Does a Visual Question Have Different Answers | [下载地址] | 视觉问答就是回答关于图像的一个问题。目前存在的一个挑战是,不同的人会对同一个问题做出不同的答案。据我们所知,这是第一篇尝试理解为什么会这样的原因。作者提出了9种可能原因的分类,然后制作了两个有标签的数据集,数据集包含45000个视觉问题,并体现了导致不同答案的原因。最后作者提出了一个新的问题,即直接从一个视觉问题来预测哪个原因会导致答案的不同,并为此提出了一个新的算法。实验证明了该算法在两个数据集上的优势。 参考:https://blog.csdn.net/z704630835/article/details/102957414 | VQA-CP v2 | |
| NeurIPS 2019 | RUBi: Reducing Unimodal Biases for Visual Question Answering | 下载地址 | 语言偏见:简单的说,相较于“查看图像-检测香蕉-评估香蕉颜色”这样的流程,建立关键词“what, color, bananas”与答案"yellow"之间的关联更简单。 作者提出了一种新的策略用以减少这种偏见,叫做RUBi。强制VQA模型使用了两个输入模块,而不是依赖问题和答案之间的统计规律。作者使用一个问题模型(question-only model)来捕捉语言偏见。它能够动态调整损失,来补偿偏见。最后作者基于VQA-CP v2进行了验证,作者提出的模型效果明显胜过当前最好模型。参考:https://blog.csdn.net/z704630835/article/details/102496091/ 它降低了最具偏见的例子的重要性,例如 |
VQA-CP v2 |
目前的高性能VQA模型,实际上利用的是语言的偏见(bias)和表面关系(superficial correlations),并没有真正的理解图像的内容。目前专家学者们主要从以下两个方面解决这个问题,1)数据集本身的优化。2)模型算法的改进。
- https://blog.csdn.net/z704630835/article/details/99844183 用于视觉问答VQA常用的数据集
- https://blog.csdn.net/xiasli123/article/details/103926020
- https://www.sohu.com/a/396692942_500659
- https://www.ershicimi.com/p/50f1b4d0959fcaee534dc3328f2e2290 视频问答兴起,多跳问答热度衰退,92篇论文看智能问答的发展趋势
- https://github.com/jokieleung/awesome-visual-question-answering#survey
- https://heary.cn/posts/VQA-%E8%BF%91%E4%BA%94%E5%B9%B4%E8%A7%86%E8%A7%89%E9%97%AE%E7%AD%94%E9%A1%B6%E4%BC%9A%E8%AE%BA%E6%96%87%E5%88%9B%E6%96%B0%E7%82%B9%E7%AC%94%E8%AE%B0/ VQA-近五年视觉问答顶会论文创新点笔记
- https://cloud.tencent.com/developer/article/1090332 【专知荟萃21】视觉问答VQA知识资料全集(入门/进阶/论文/综述/视频/专家,附查看)
- http://cache.baiducontent.com/c?m=eKifVlYD99opzJwIj9LjP3yHSUyuAz7cfCirqsrc1fIXJNNyWky-nwa0n6x2r95IRIpg37SzBnfvAzfrL7G-MPxZxxt2jwoamMzzr1CcCYStrxwfGrTGSgPgIaui1owYVRYf7ZsPbNUQFgO56ivvkzIueuw1FeurIjCRe0l6BI-hli3m65qh7m03NFSIhNZP&p=9f7ed400a4934eac58eadc2d0214c9&newp=9f769a479c9818c343bd9b7d0d118b231610db2151d4d6126b82c825d7331b001c3bbfb423281b06d1ce7d6506ac4f5aecf53673330923a3dda5c91d9fb4c57479c27c6d1c07&s=428fca9bc1921c25&user=baidu&fm=sc&query=visual+grounding&qid=fd2737db00013022&p1=3 从 Vision 到 Language 再到 Action,万字漫谈三年跨域信息融合研究
- http://kugwzk.info/index.php/archives/3350 ACL 2019 RC&QA扫读
- https://blog.csdn.net/z704630835/category_9595847.html 视觉问答阅读