When I wanted to migrate that program to sequence signal data, I found that @register_model("mbt2018") The compress and decompress methods of class JointAutoregressiveHierarchicalPriors are very complex #294
Comments
|
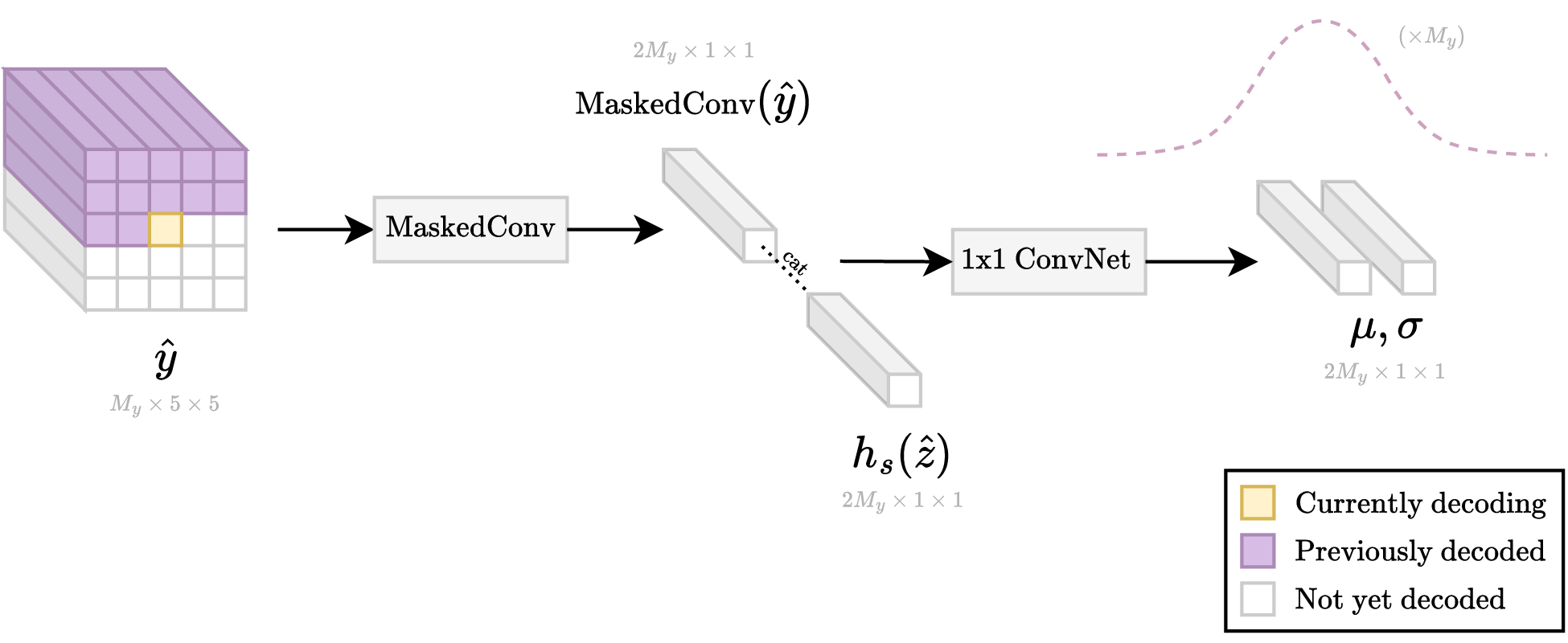
The autoregression portion requires a loop of many steps at runtime. This is because the needed information for decoding only becomes available as the tensor is being decoded pixel-by-pixel from top-left to bottom-right. In contrast, during training, all the information about the tensor is immediately available, so that "decoding" can be done in one small step.
Also, previous models contain some amount of code for runtime decoding too, but it's hidden inside the
|
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
When I wanted to migrate that program to sequence signal data, I found that
The compress and decompress methods of class
are very complex. Why is it so complex compared to the compress function and the decompress function of the previous models?
Also, do I have to train the aux loss very small to get similar results for the forward function and the compress and decompress functions?
Thank you very much for your answer!
The text was updated successfully, but these errors were encountered: