![[rag_guardrails.png]]
After studying how companies deploy generative AI applications, I noticed many similarities in their platforms. This post outlines the common components of a generative AI platform, what they do, and how they are implemented. I try my best to keep the architecture general, but certain applications might deviate. This is what the overall architecture looks like.
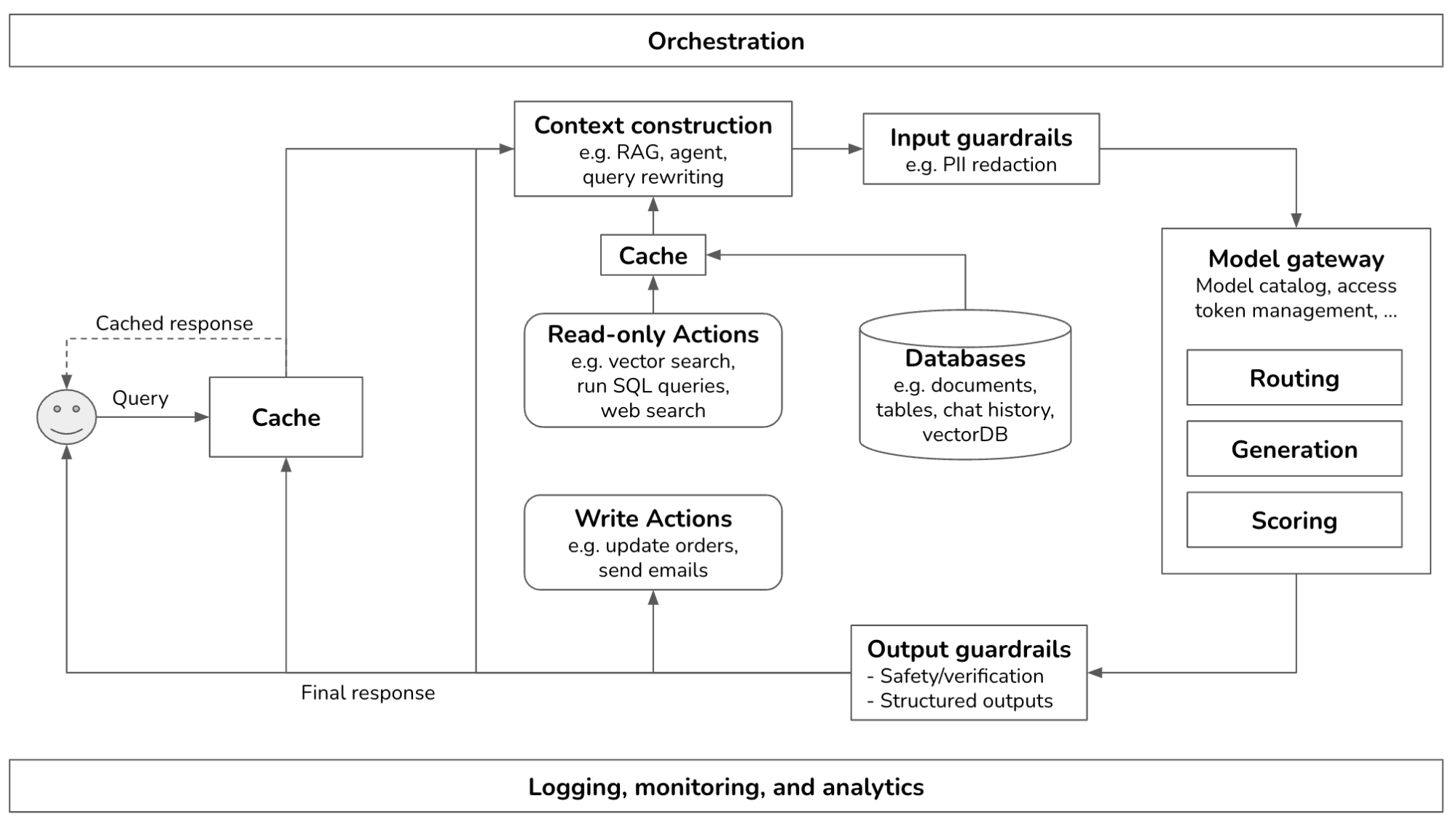
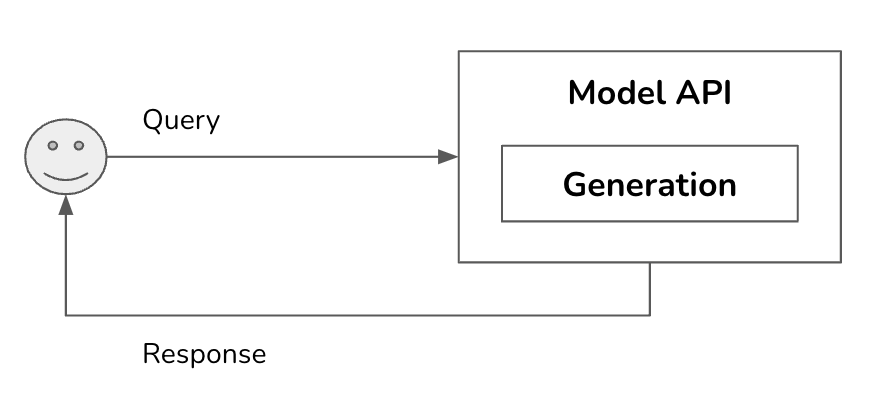
This is a pretty complex system. This post will start from the simplest architecture and progressively add more components. In its simplest form, your application receives a query and sends it to the model. The model generates a response, which is returned to the user. There are no guardrails, no augmented context, and no optimization. The Model API box refers to both third-party APIs (e.g., OpenAI, Google, Anthropic) and self-hosted APIs.
From this, you can add more components as needs arise. The order discussed in this post is common, though you don’t need to follow the exact same order. A component can be skipped if your system works well without it. Evaluation is necessary at every step of the development process.
- Enhance context input into a model by giving the model access to external data sources and tools for information gathering.
- Put in guardrails to protect your system and your users.
- Add model router and gateway to support complex pipelines and add more security.
- Optimize for latency and costs with cache.
- Add complex logic and write actions to maximize your system’s capabilities.
Observability, which allows you to gain visibility into your system for monitoring and debugging, and orchestration, which involves chaining all the components together, are two essential components of the platform. We will discuss them at the end of this post.
» What this post is not «
This post focuses on the overall architecture for deploying AI applications. It discusses what components are needed and considerations when building these components. It’s not about how to build AI applications and, therefore, does NOT discuss model evaluation, application evaluation, prompt engineering, finetuning, data annotation guidelines, or chunking strategies for RAGs. All these topics are covered in my upcoming book AI Engineering.
Table of contents
Step 1. Enhance Context
….RAGs
….RAGs with tabular data
….Agentic RAGs
….Query rewriting
Step 2. Put in Guardrails
….Input guardrails
……..Leaking private information to external APIs
……..Model jailbreaking
….Output guardrails
……..Output quality measurement
……..Failure management
….Guardrail tradeoffs
Step 3. Add Model Router and Gateway
….Router
….Gateway
Step 4. Reduce Latency with Cache
….Prompt cache
….Exact cache
….Semantic cache
Step 5. Add complex logic and write actions
….Complex logic
….Write actions
Observability
….Metrics
….Logs
….Traces
AI Pipeline Orchestration
Conclusion
References and Acknowledgments
The initial expansion of a platform usually involves adding mechanisms to allow the system to augment each query with the necessary information. Gathering the relevant information is called context construction.
Many queries require context to answer. The more relevant information there is in the context, the less the model has to rely on its internal knowledge, which can be unreliable due to its training data and training methodology. Studies have shown that having access to relevant information in the context can help the model generate more detailed responses while reducing hallucinations (Lewis et al., 2020).
For example, given the query “Will Acme’s fancy-printer-A300 print 100pps?”, the model will be able to respond better if it’s given the specifications of fancy-printer-A300. (Thanks Chetan Tekur for the example.)
Context construction for foundation models is equivalent to feature engineering for classical ML models. They serve the same purpose: giving the model the necessary information to process an input.
In-context learning, learning from the context, is a form of continual learning. It enables a model to incorporate new information continually to make decisions, preventing it from becoming outdated. For example, a model trained on last-week data won’t be able to answer questions about this week unless the new information is included in its context. By updating a model’s context with the latest information, e.g. fancy-printer-A300’s latest specifications, the model remains up-to-date and can respond to queries beyond its cut-off date.
The most well-known pattern for context construction is RAG, Retrieval-Augmented Generation. RAG consists of two components: a generator (e.g. a language model) and a retriever, which retrieves relevant information from external sources.
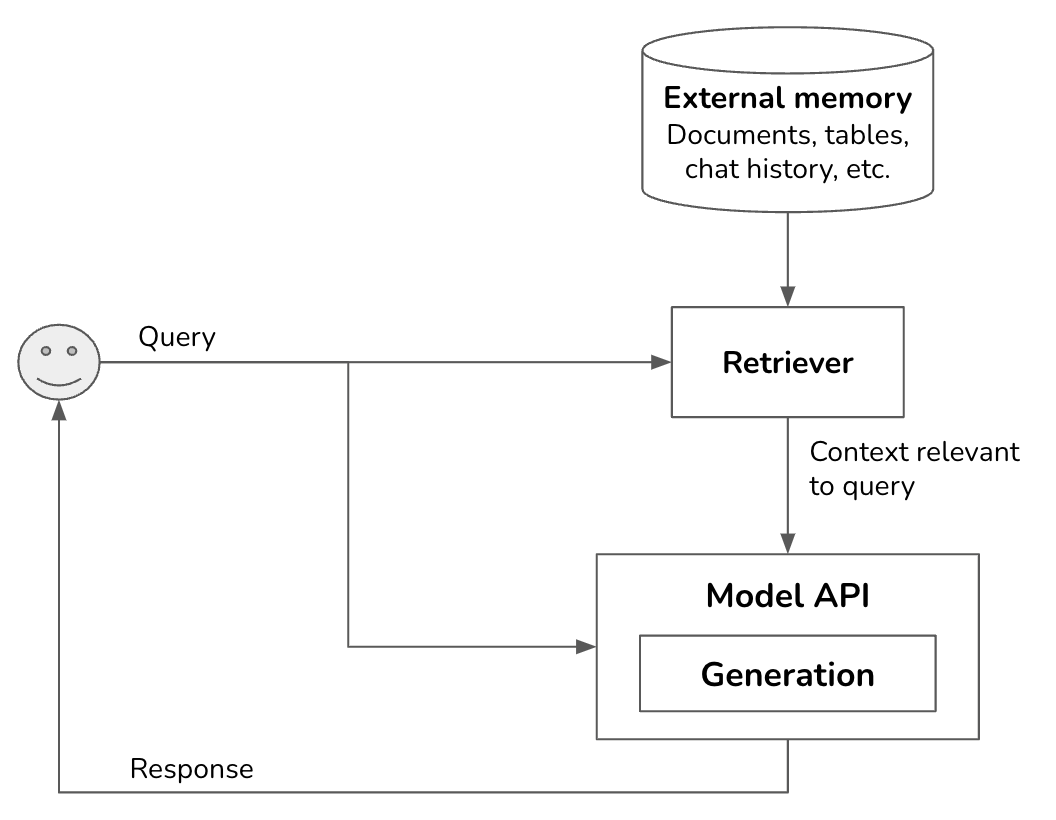
Retrieval isn’t unique to RAGs. It’s the backbone of search engines, recommender systems, log analytics, etc. Many retrieval algorithms developed for traditional retrieval systems can be used for RAGs.
External memory sources typically contain unstructured data, such as memos, contracts, news updates, etc. They can be collectively called documents. A document can be 10 tokens or 1 million tokens. Naively retrieving whole documents can cause your context to be arbitrarily long. RAG typically requires documents to be split into manageable chunks, which can be determined from the model’s maximum context length and your application’s latency requirements. To learn more about chunking and the optimal chunk size, see Pinecone, Langchain, Llamaindex, and Greg Kamradt’s tutorials.
Once data from external memory sources has been loaded and chunked, retrieval is performed using two main approaches.
-
Term-based retrieval
This can be as simple as keyword search. For example, given the query “transformer”, fetch all documents containing this keyword. More sophisticated algorithms include BM25 (which leverages TF-IDF) and Elasticsearch (which leverages inverted index).Term-based retrieval is usually used for text data, but it also works for images and videos that have text metadata such as titles, tags, captions, comments, etc.
-
Embedding-based retrieval (also known as vector search)
You convert chunks of data into embedding vectors using an embedding model such as BERT, sentence-transformers, and proprietary embedding models provided by OpenAI or Google. Given a query, the data whose vectors are closest to the query embedding, as determined by the vector search algorithm, is retrieved.Vector search is usually framed as nearest-neighbor search, using approximate nearest neighbor (ANN) algorithms such as FAISS (Facebook AI Similarity Search), Google’s ScaNN, Spotify’s ANNOY, and hnswlib (Hierarchical Navigable Small World).
The ANN-benchmarks website compares different ANN algorithms on multiple datasets using four main metrics, taking into account the tradeoffs between indexing and querying.- Recall: the fraction of the nearest neighbors found by the algorithm.
- Query per second (QPS): the number of queries the algorithm can handle per second. This is crucial for high-traffic applications.
- Build time: the time required to build the index. This metric is important especially if you need to frequently update your index (e.g. because your data changes).
- Index size: the size of the index created by the algorithm, which is crucial for assessing its scalability and storage requirements.
This works with not just text documents, but also images, videos, audio, and code. Many teams even try to summarize SQL tables and dataframes and then use these summaries to generate embeddings for retrieval.
Term-based retrieval is much faster and cheaper than embedding-based retrieval. It can work well out of the box, making it an attractive option to start. Both BM25 and Elasticsearch are widely used in the industry and serve as formidable baselines for more complex retrieval systems. Embedding-based retrieval, while computationally expensive, can be significantly improved over time to outperform term-based retrieval.
A production retrieval system typically combines several approaches. Combining term-based retrieval and embedding-based retrieval is called hybrid search.
One common pattern is sequential. First, a cheap, less precise retriever, such as a term-based system, fetches candidates. Then, a more precise but more expensive mechanism, such as k-nearest neighbors, finds the best of these candidates. The second step is also called reranking.
For example, given the term “transformer”, you can fetch all documents that contain the word transformer, regardless of whether they are about the electric device, the neural architecture, or the movie. Then you use vector search to find among these documents those that are actually related to your transformer query.
Context reranking differs from traditional search reranking in that the exact position of items is less critical. In search, the rank (e.g., first or fifth) is crucial. In context reranking, the order of documents still matters because it affects how well a model can process them. Models might better understand documents at the beginning and end of the context, as suggested by the paper Lost in the middle (Liu et al., 2023). However, as long as a document is included, the impact of its order is less significant compared to in search ranking.
Another pattern is ensemble. Remember that a retriever works by ranking documents by their relevance scores to the query. You use multiple retrievers to fetch candidates at the same time, then combine these different rankings together to generate a final ranking.
External data sources can also be structured, such as dataframes or SQL tables. Retrieving data from an SQL table is significantly different from retrieving data from unstructured documents. Given a query, the system works as follows.
- Text-to-SQL: Based on the user query and the table schemas, determine what SQL query is needed.
- SQL execution: Execute the SQL query.
- Generation: Generate a response based on the SQL result and the original user query.
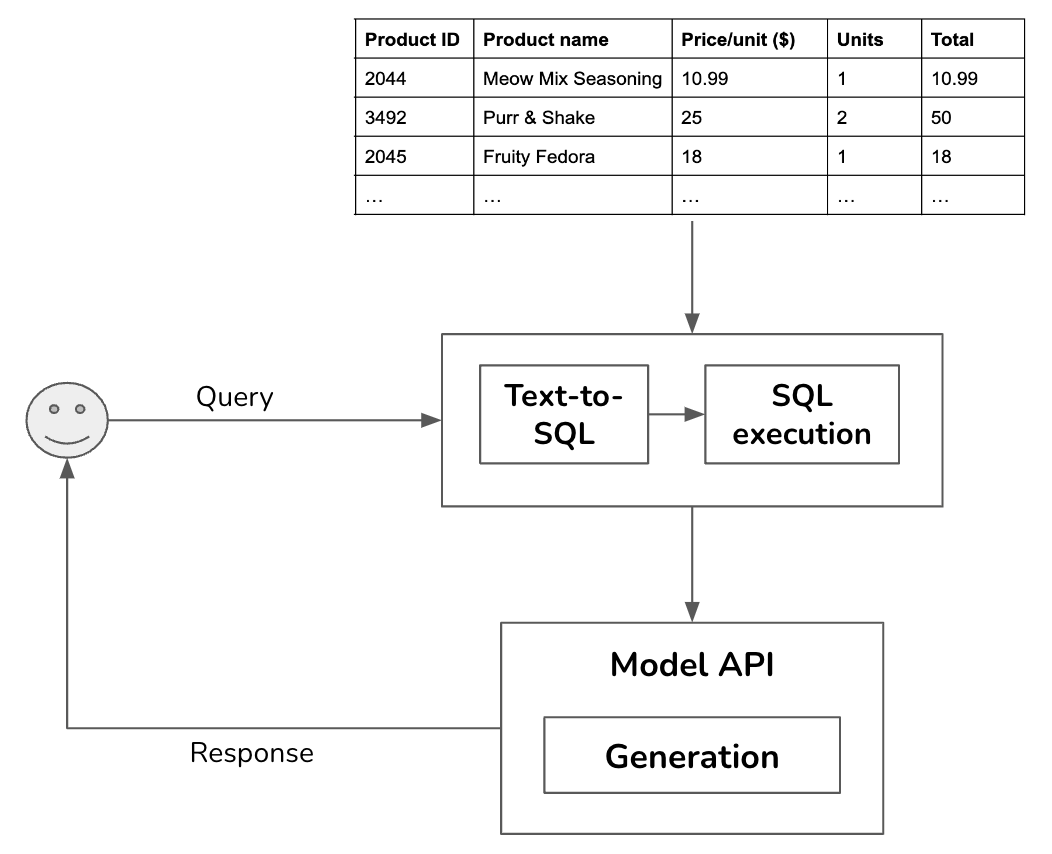
For the text-to-SQL step, if there are many available tables whose schemas can’t all fit into the model context, you might need an intermediate step to predict what tables to use for each query. Text-to-SQL can be done by the same model used to generate the final response or one of many specialized text-to-SQL models.
An important source of data is the Internet. A web search tool like Google or Bing API can give the model access to a rich, up-to-date resource to gather relevant information for each query. For example, given the query “Who won Oscar this year?”, the system searches for information about the latest Oscar and uses this information to generate the final response to the user.
Term-based retrieval, embedding-based retrieval, SQL execution, and web search are actions that a model can take to augment its context. You can think of each action as a function the model can call. A workflow that can incorporate external actions is also called agentic. The architecture then looks like this.
» Action vs. tool «
A tool allows one or more actions. For example, a people search tool might allow two actions: search by name and search by email. However, the difference is minimal, so many people use action and tool interchangeably.
» Read-only actions vs. write actions «
Actions that retrieve information from external sources but don’t change their states are read-only actions. Giving a model write actions, e.g. updating the values in a table, enables the model to perform more tasks but also poses more risks, which will be discussed later.
Often, a user query needs to be rewritten to increase the likelihood of fetching the right information. Consider the following conversation.
User: When was the last time John Doe bought something from us?
AI: John last bought a Fruity Fedora hat from us two weeks ago, on January 3, 2030.
User: How about Emily Doe?
The last question, “How about Emily Doe?”, is ambiguous. If you use this query verbatim to retrieve documents, you’ll likely get irrelevant results. You need to rewrite this query to reflect what the user is actually asking. The new query should make sense on its own. The last question should be rewritten to “When was the last time Emily Doe bought something from us?”
Query rewriting is typically done using other AI models, using a prompt similar to “Given the following conversation, rewrite the last user input to reflect what the user is actually asking.”

Query rewriting can get complicated, especially if you need to do identity resolution or incorporate other knowledge. If the user asks “How about his wife?”, you will first need to query your database to find out who his wife is. If you don’t have this information, the rewriting model should acknowledge that this query isn’t solvable instead of hallucinating a name, leading to a wrong answer.
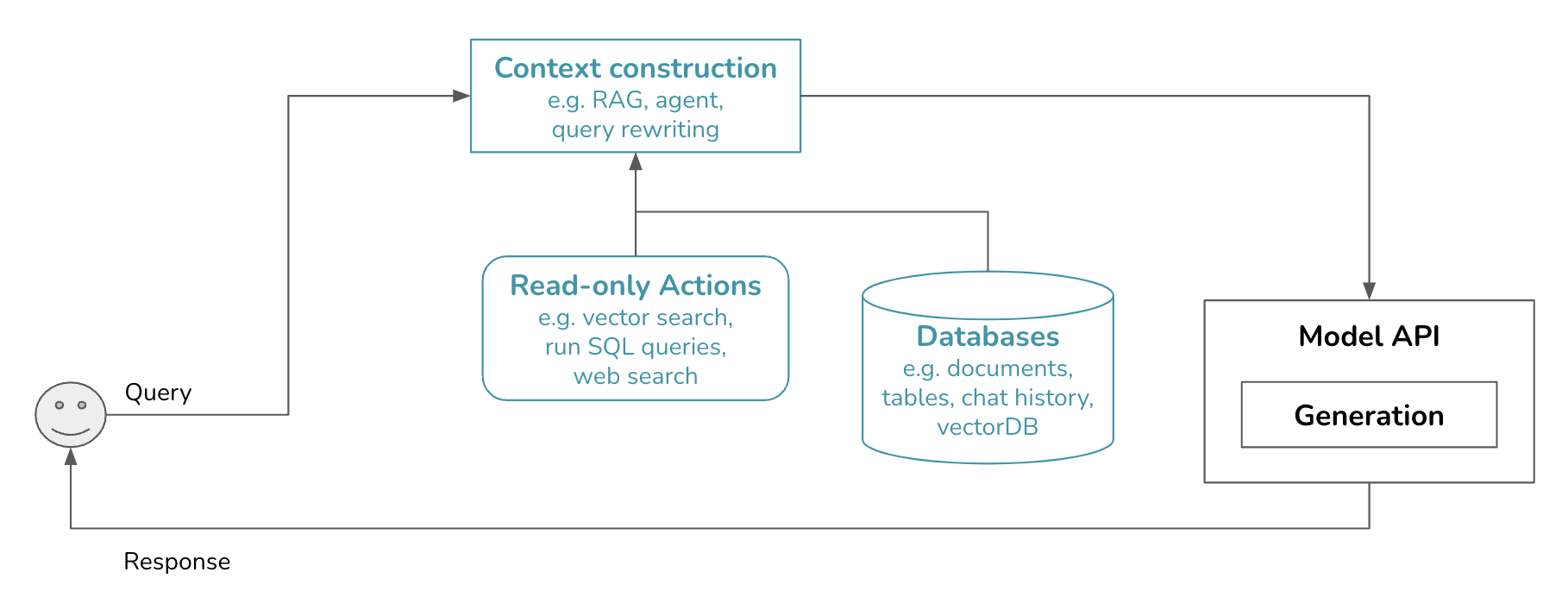
Guardrails help reduce AI risks and protect not just your users but also you, the developers. They should be placed whenever there is potential for failures. This post discusses two types of guardrails: input guardrails and output guardrails.
Input guardrails are typically protection against two types of risks: leaking private information to external APIs, and executing bad prompts that compromise your system (model jailbreaking).
This risk is specific to using external model APIs when you need to send your data outside your organization. For example, an employee might copy the company’s secret or a user’s private information into a prompt and send it to wherever the model is hosted.
One of the most notable early incidents was when Samsung employees put Samsung’s proprietary information into ChatGPT, accidentally leaking the company’s secrets. It’s unclear how Samsung discovered this leak and how the leaked information was used against Samsung. However, the incident was serious enough for Samsung to ban ChatGPT in May 2023.
There’s no airtight way to eliminate potential leaks when using third-party APIs. However, you can mitigate them with guardrails. You can use one of the many available tools that automatically detect sensitive data. What sensitive data to detect is specified by you. Common sensitive data classes are:
- Personal information (ID numbers, phone numbers, bank accounts).
- Human faces.
- Specific keywords and phrases associated with the company’s intellectual properties or privileged information.
Many sensitive data detection tools use AI to identify potentially sensitive information, such as determining if a string resembles a valid home address. If a query is found to contain sensitive information, you have two options: block the entire query or remove the sensitive information from it. For instance, you can mask a user’s phone number with the placeholder [PHONE NUMBER]. If the generated response contains this placeholder, use a PII reversible dictionary that maps this placeholder to the original information so that you can unmask it, as shown below.

It’s become an online sport to try to jailbreak AI models, getting them to say or do bad things. While some might find it amusing to get ChatGPT to make controversial statements, it’s much less fun if your customer support chatbot, branded with your name and logo, does the same thing. This can be especially dangerous for AI systems that have access to tools. Imagine if a user finds a way to get your system to execute an SQL query that corrupts your data.
To combat this, you should first put guardrails on your system so that no harmful actions can be automatically executed. For example, no SQL queries that can insert, delete, or update data can be executed without human approval. The downside of this added security is that it can slow down your system.
To prevent your application from making outrageous statements it shouldn’t be making, you can define out-of-scope topics for your application. For example, if your application is a customer support chatbot, it shouldn’t answer political or social questions. A simple way to do so is to filter out inputs that contain predefined phrases typically associated with controversial topics, such as “immigration” or “antivax”. More sophisticated algorithms use AI to classify whether an input is about one of the pre-defined restricted topics.
If harmful prompts are rare in your system, you can use an anomaly detection algorithm to identify unusual prompts.
AI models are probabilistic, making their outputs unreliable. You can put in guardrails to significantly improve your application’s reliability. Output guardrails have two main functionalities:
- Evaluate the quality of each generation.
- Specify the policy to deal with different failure modes.
To catch outputs that fail to meet your standards, you need to understand what failures look like. Here are examples of failure modes and how to catch them.
-
Empty responses.
-
Malformatted responses that don’t follow the expected output format. For example, if the application expects JSON and the generated response has a missing closing bracket. There are validators for certain formats, such as regex, JSON, and Python code validators. There are also tools for constrained sampling such as guidance, outlines, and instructor.
-
Toxic responses, such as those that are racist or sexist. These responses can be caught using one of many toxicity detection tools.
-
Factual inconsistent responses hallucinated by the model. Hallucination detection is an active area of research with solutions such as SelfCheckGPT (Manakul et al., 2023) and SAFE, Search Engine Factuality Evaluator (Wei et al., 2024). You can mitigate hallucinations by providing models with sufficient context and prompting techniques such as chain-of-thought. Hallucination detection and mitigation are discussed further in my upcoming book AI Engineering.
-
Responses that contain sensitive information. This can happen in two scenarios.
- Your model was trained on sensitive data and regurgitates it back.
- Your system retrieves sensitive information from your internal database to enrich its context, and then it passes this sensitive information on to the response.
This failure mode can be prevented by not training your model on sensitive data and not allowing it to retrieve sensitive data in the first place. Sensitive data in outputs can be detected using the same tools used for input guardrails.
-
Brand-risk responses, such as responses that mischaracterize your company or your competitors. An example is when Grok, a model trained by X, generated a response suggesting that Grok was trained by OpenAI, causing the Internet to suspect X of stealing OpenAI’s data. This failure mode can be mitigated with keyword monitoring. Once you’ve identified outputs concerning your brands and competitors, you can either block these outputs, pass them onto human reviewers, or use other models to detect the sentiment of these outputs to ensure that only the right sentiments are returned.
-
Generally bad responses. For example, if you ask the model to write an essay and that essay is just bad, or if you ask the model for a low-calorie cake recipe and the generated recipe contains an excessive amount of sugar. It’s become a popular practice to use AI judges to evaluate the quality of models’ responses. These AI judges can be general-purpose models (think ChatGPT, Claude) or specialized scorers trained to output a concrete score for a response given a query.
AI models are probabilistic, which means that if you try a query again, you might get a different response. Many failures can be mitigated using a basic retry logic. For example, if the response is empty, try again X times or until you get a non-empty response. Similarly, if the response is malformatted, try again until the model generates a correctly formatted response.
This retry policy, however, can incur extra latency and cost. One retry means 2x the number of API calls. If the retry is carried out after failure, the latency experienced by the user will double. To reduce latency, you can make calls in parallel. For example, for each query, instead of waiting for the first query to fail before retrying, you send this query to the model twice at the same time, get back two responses, and pick the better one. This increases the number of redundant API calls but keeps latency manageable.
It’s also common to fall back on humans to handle tricky queries. For example, you can transfer a query to human operators if it contains specific key phrases. Some teams use a specialized model, potentially trained in-house, to decide when to transfer a conversation to humans. One team, for instance, transfers a conversation to human operators when their sentiment analysis model detects that the user is getting angry. Another team transfers a conversation after a certain number of turns to prevent users from getting stuck in an infinite loop.
Reliability vs. latency tradeoff: While acknowledging the importance of guardrails, some teams told me that latency is more important. They decided not to implement guardrails because they can significantly increase their application’s latency. However, these teams are in the minority. Most teams find that the increased risks are more costly than the added latency.
Output guardrails might not work well in the stream completion mode. By default, the whole response is generated before shown to the user, which can take a long time. In the stream completion mode, new tokens are streamed to the user as they are generated, reducing the time the user has to wait to see the response. The downside is that it’s hard to evaluate partial responses, so unsafe responses might be streamed to users before the system guardrails can determine that they should be blocked.
Self-hosted vs. third-party API tradeoff: Self-hosting your models means that you don’t have to send your data to a third party, reducing the need for input guardrails. However, it also means that you must implement all the necessary guardrails yourself, rather than relying on the guardrails provided by third-party services.
Our platform now looks like this. Guardrails can be independent tools or parts of model gateways, as discussed later. Scorers, if used, are grouped under model APIs since scorers are typically AI models, too. Models used for scoring are typically smaller and faster than models used for generation.
As applications grow in complexity and involve more models, two types of tools emerged to help you work with multiple models: routers and gateways.
An application can use different models to respond to different types of queries. Having different solutions for different queries has several benefits. First, this allows you to have specialized solutions, such as one model specialized in technical troubleshooting and another specialized in subscriptions. Specialized models can potentially perform better than a general-purpose model. Second, this can help you save costs. Instead of routing all queries to an expensive model, you can route simpler queries to cheaper models.
A router typically consists of an intent classifier that predicts what the user is trying to do. Based on the predicted intent, the query is routed to the appropriate solution. For example, for a customer support chatbot, if the intent is:
- To reset a password –> route this user to the page about password resetting.
- To correct a billing mistake –> route this user to a human operator.
- To troubleshoot a technical issue –> route this query to a model finetuned for troubleshooting.
An intent classifier can also help your system avoid out-of-scope conversations. For example, you can have an intent classifier that predicts whether a query is out of the scope. If the query is deemed inappropriate (e.g. if the user asks who you would vote for in the upcoming election), the chatbot can politely decline to engage using one of the stock responses (“As a chatbot, I don’t have the ability to vote. If you have questions about our products, I’d be happy to help.”) without wasting an API call.
If your system has access to multiple actions, a router can involve a next-action predictor to help the system decide what action to take next. One valid action is to ask for clarification if the query is ambiguous. For example, in response to the query “Freezing,” the system might ask, “Do you want to freeze your account or are you talking about the weather?” or simply say, “I’m sorry. Can you elaborate?”
Intent classifiers and next-action predictors can be general-purpose models or specialized classification models. Specialized classification models are typically much smaller and faster than general-purpose models, allowing your system to use multiple of them without incurring significant extra latency and cost.
When routing queries to models with varying context limits, the query’s context might need to be adjusted accordingly. Consider a query of 1,000 tokens that is slated for a model with a 4K context limit. The system then takes an action, e.g. web search, that brings back 8,000-token context. You can either truncate the query’s context to fit the originally intended model or route the query to a model with a larger context limit.
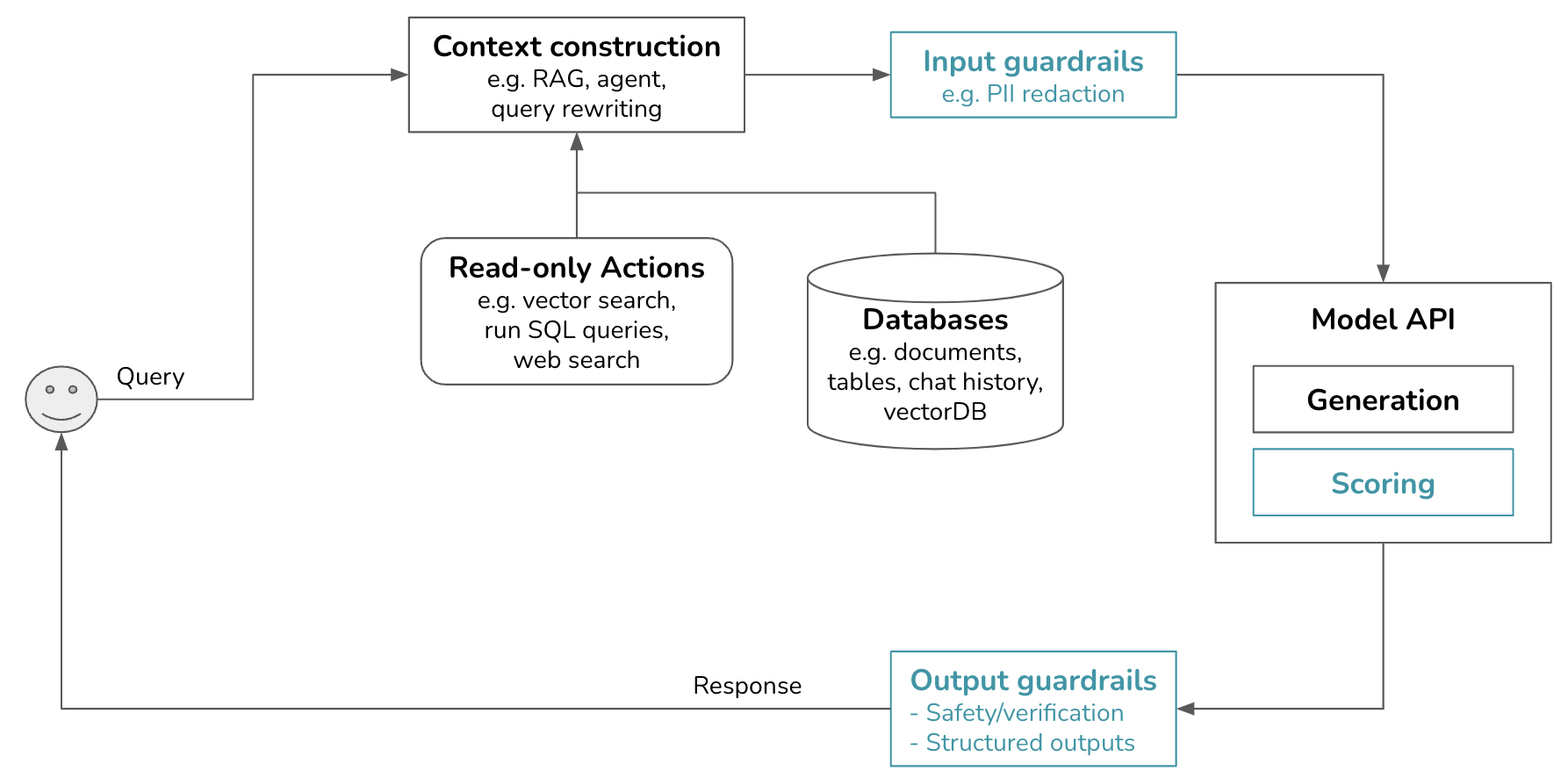
A model gateway is an intermediate layer that allows your organization to interface with different models in a unified and secure manner. The most basic functionality of a model gateway is to enable developers to access different models – be it self-hosted models or models behind commercial APIs such as OpenAI or Google – the same way. A model gateway makes it easier to maintain your code. If a model API changes, you only need to update the model gateway instead of having to update all applications that use this model API.
In its simplest form, a model gateway is a unified wrapper that looks like the following code example. This example is to give you an idea of how a model gateway might be implemented. It’s not meant to be functional as it doesn’t contain any error checking or optimization.
import google.generativeai as genai
import openai
def openai_model(input_data, model_name, max_tokens):
openai.api_key = os.environ["OPENAI_API_KEY"]
response = openai.Completion.create(
engine=model_name,
prompt=input_data,
max_tokens=max_tokens
)
return {"response": response.choices[0].text.strip()}
def gemini_model(input_data, model_name, max_tokens):
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
model = genai.GenerativeModel(model_name=model_name)
response = model.generate_content(input_data, max_tokens=max_tokens)
return {"response": response["choices"][0]["message"]["content"]}
@app.route('/model', methods=['POST'])
def model_gateway():
data = request.get_json()
model_type = data.get("model_type")
model_name = data.get("model_name")
input_data = data.get("input_data")
max_tokens = data.get("max_tokens")
if model_type == "openai":
result = openai_model(input_data, model_name, max_tokens)
elif model_type == "gemini":
result = gemini_model(input_data, model_name, max_tokens)
return jsonify(result)
A model gateway is access control and cost management. Instead of giving everyone who wants access to the OpenAI API your organizational tokens, which can be easily leaked, you only give people access to the model gateway, creating a centralized and controlled point of access. The gateway can also implement fine-grained access controls, specifying which user or application should have access to which model. Moreover, the gateway can monitor and limit the usage of API calls, preventing abuse and managing costs effectively.
A model gateway can also be used to implement fallback policies to overcome rate limits or API failures (the latter is unfortunately common). When the primary API is unavailable, the gateway can route requests to alternative models, retry after a short wait, or handle failures in other graceful manners. This ensures that your application can operate smoothly without interruptions.
Since requests and responses are already flowing through the gateway, it’s a good place to implement other functionalities such as load balancing, logging, and analytics. Some gateway services even provide caching and guardrails.
Given that gateways are relatively straightforward to implement, there are many off-the-shelf gateways. Examples include Portkey’s gateway, MLflow AI Gateway, WealthSimple’s llm-gateway, TrueFoundry, Kong, and Cloudflare.
With the added gateway and routers, our platform is getting more exciting. Like scoring, routing is also in the model gateway. Like models used for scoring, models used for routing are typically smaller than models used for generation.
When I shared this post with my friend Eugene Yan, he said that cache is perhaps the most underrated component of an AI platform. Caching can significantly reduce your application’s latency and cost.
Cache techniques can also be used during training, but since this post is about deployment, I’ll focus on cache for inference. Some common inference caching techniques include prompt cache, exact cache, and semantic cache. Prompt cache are typically implemented by the inference APIs that you use. When evaluating an inference library, it’s helpful to understand what cache mechanism it supports.
KV cache for the attention mechanism is out of scope for this discussion.
Many prompts in an application have overlapping text segments. For example, all queries can share the same system prompt. A prompt cache stores these overlapping segments for reuse, so you only need to process them once. A common overlapping text segment in different prompts is the system prompt. Without prompt cache, your model needs to process the system prompt with every query. With prompt cache, it only needs to process the system prompt once for the first query.
For applications with long system prompts, prompt cache can significantly reduce both latency and cost. If your system prompt is 1000 tokens and your application generates 1 million model API calls today, a prompt cache will save you from processing approximately 1 billion repetitive input tokens a day! However, this isn’t entirely free. Like KV cache, prompt cache size can be quite large and require significant engineering effort.
Prompt cache is also useful for queries that involve long documents. For example, if many of your user queries are related to the same long document (such as a book or a codebase), this long document can be cached for reuse across queries.
Since its introduction in November 2023 by Gim et al., prompt cache has already been incorporated into model APIs. Google announced that Gemini APIs will offer this functionality in June 2024 under the name context cache. Cached input tokens are given a 75% discount compared to regular input tokens, but you’ll have to pay extra for cache storage (as of writing, $1.00 / 1 million tokens per hour). Given the obvious benefits of prompt cache, I wouldn’t be surprised if it becomes as popular as KV cache.
While llama.cpp also has prompt cache, it seems to only cache whole prompts and work for queries in the same chat session. Its documentation is limited, but my guess from reading the code is that in a long conversation, it caches the previous messages and only processes the newest message.
If prompt cache and KV cache are unique to foundation models, exact cache is more general and straightforward. Your system stores processed items for reuse later when the exact items are requested. For example, if a user asks a model to summarize a product, the system checks the cache to see if a summary of this product is cached. If yes, fetch this summary. If not, summarize the product and cache the summary.
Exact cache is also used for embedding-based retrieval to avoid redundant vector search. If an incoming query is already in the vector search cache, fetch the cached search result. If not, perform a vector search for this query and cache the result.
Cache is especially appealing for queries that require multiple steps (e.g. chain-of-thought) and/or time-consuming actions (e.g. retrieval, SQL execution, or web search).
An exact cache can be implemented using in-memory storage for fast retrieval. However, since in-memory storage is limited, a cache can also be implemented using databases like PostgreSQL, Redis, or tiered storage to balance speed and storage capacity. Having an eviction policy is crucial to manage the cache size and maintain performance. Common eviction policies include Least Recently Used (LRU), Least Frequently Used (LFU), and First In, First Out (FIFO).
How long to cache a query depends on how likely this query is to be called again. User-specific queries such as “What’s the status of my recent order” are less likely to be reused by other users, and therefore, shouldn’t be cached. Similarly, it makes less sense to cache time-sensitive queries such as “How’s the weather?” Some teams train a small classifier to predict whether a query should be cached.
Unlike exact cache, semantic cache doesn’t require the incoming query to be identical to any of the cached queries. Semantic cache allows the reuse of similar queries. Imagine one user asks “What’s the capital of Vietnam?” and the model generates the answer “Hanoi”. Later, another user asks “What’s the capital city of Vietnam?”, which is the same question but with the extra word “city”. The idea of semantic cache is that the system can reuse the answer “Hanoi” instead of computing the new query from scratch.
Semantic cache only works if you have a reliable way to determine if two queries are semantically similar. One common approach is embedding-based similarity, which works as follows:
- For each query, generate its embedding using an embedding model.
- Use vector search to find the cached embedding closest to the current query embedding. Let’s say this similarity score is X.
- If X is less than the similarity threshold you set, the cached query is considered the same as the current query, and the cached results are returned. If not, process this current query and cache it together with its embedding and results.
This approach requires a vector database to store the embeddings of cached queries.
Compared to other caching techniques, semantic cache’s value is more dubious because many of its components are prone to failure. Its success relies on high-quality embeddings, functional vector search, and a trustworthy similarity metric. Setting the right similarity threshold can also be tricky and require a lot of trial and error. If the system mistakes the incoming query as being similar to another query, the returned response, fetched from the cache, will be incorrect.
In addition, semantic cache can be time-consuming and compute-intensive, as it involves a vector search. The speed and cost of this vector search depend on the size of your database of cached embeddings.
Semantic cache might still be worth it if the cache hit rate is high, meaning that a good portion of queries can be effectively answered by leveraging the cached results. However, before incorporating the complexities of semantic cache, make sure to evaluate the efficiency, cost, and performance risks associated with it.
With the added cache systems, the platform looks as follows. KV cache and prompt cache are typically implemented by model API providers, so they aren’t shown in this image. If I must visualize them, I’d put them in the Model API box. There’s a new arrow to add generated responses to the cache.
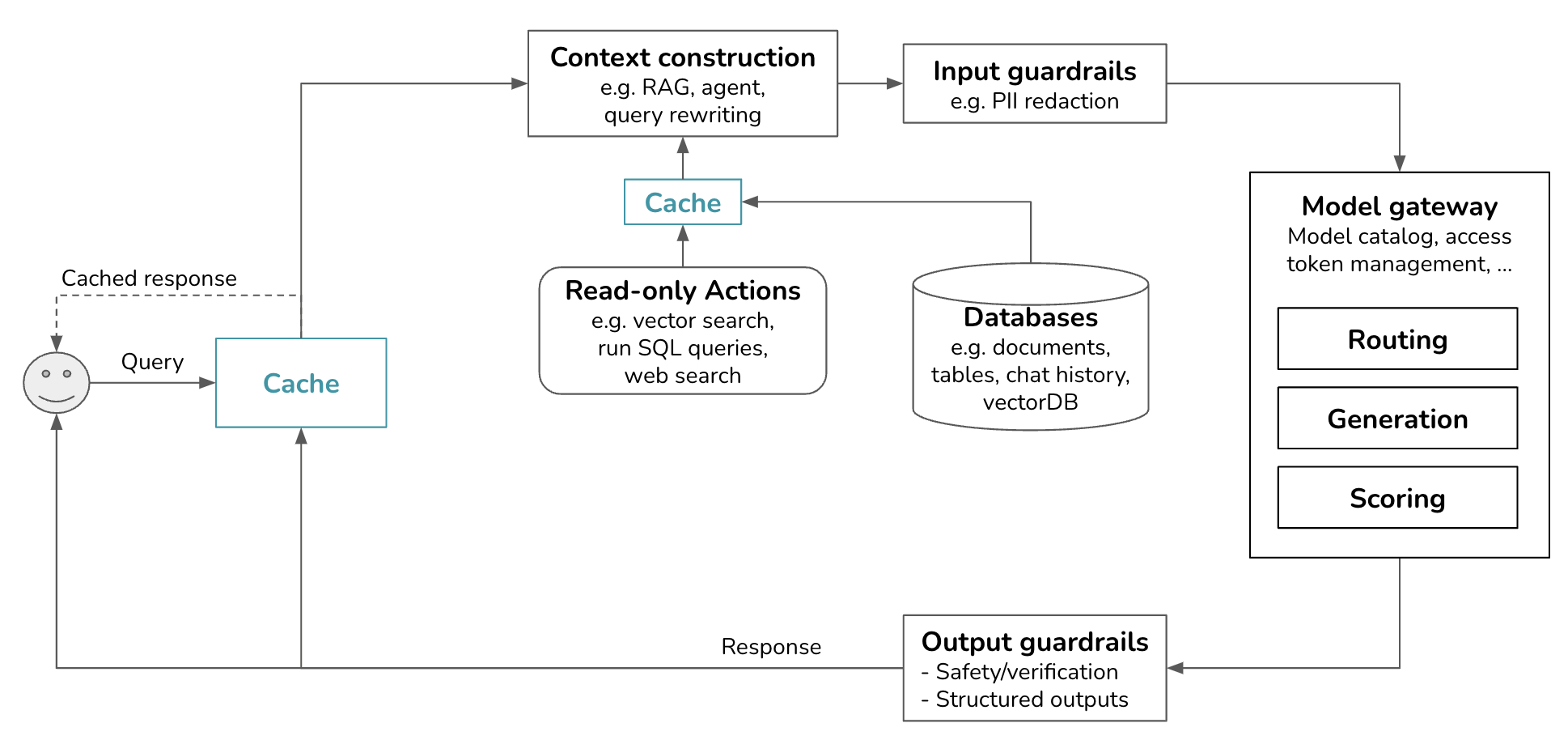
The applications we’ve discussed so far have fairly simple flows. The outputs generated by foundation models are mostly returned to users (unless they don’t pass the guardrails). However, an application flow can be more complex with loops and conditional branching. A model’s outputs can also be used to invoke write actions, such as composing an email or placing an order.
Outputs from a model can be conditionally passed onto another model or fed back to the same model as part of the input to the next step. This goes on until a model in the system decides that the task has been completed and that a final response should be returned to the user.
This can happen when you give your system the ability to plan and decide what to do next. As an example, consider the query “Plan a weekend itinerary for Paris.” The model might first generate a list of potential activities: visiting the Eiffel Tower, having lunch at a café, touring the Louvre, etc. Each of these activities can then be fed back into the model to generate more detailed plans. For instance, “visiting the Eiffel Tower” could prompt the model to generate sub-tasks like checking the opening hours, buying tickets, and finding nearby restaurants. This iterative process continues until a comprehensive and detailed itinerary is created.
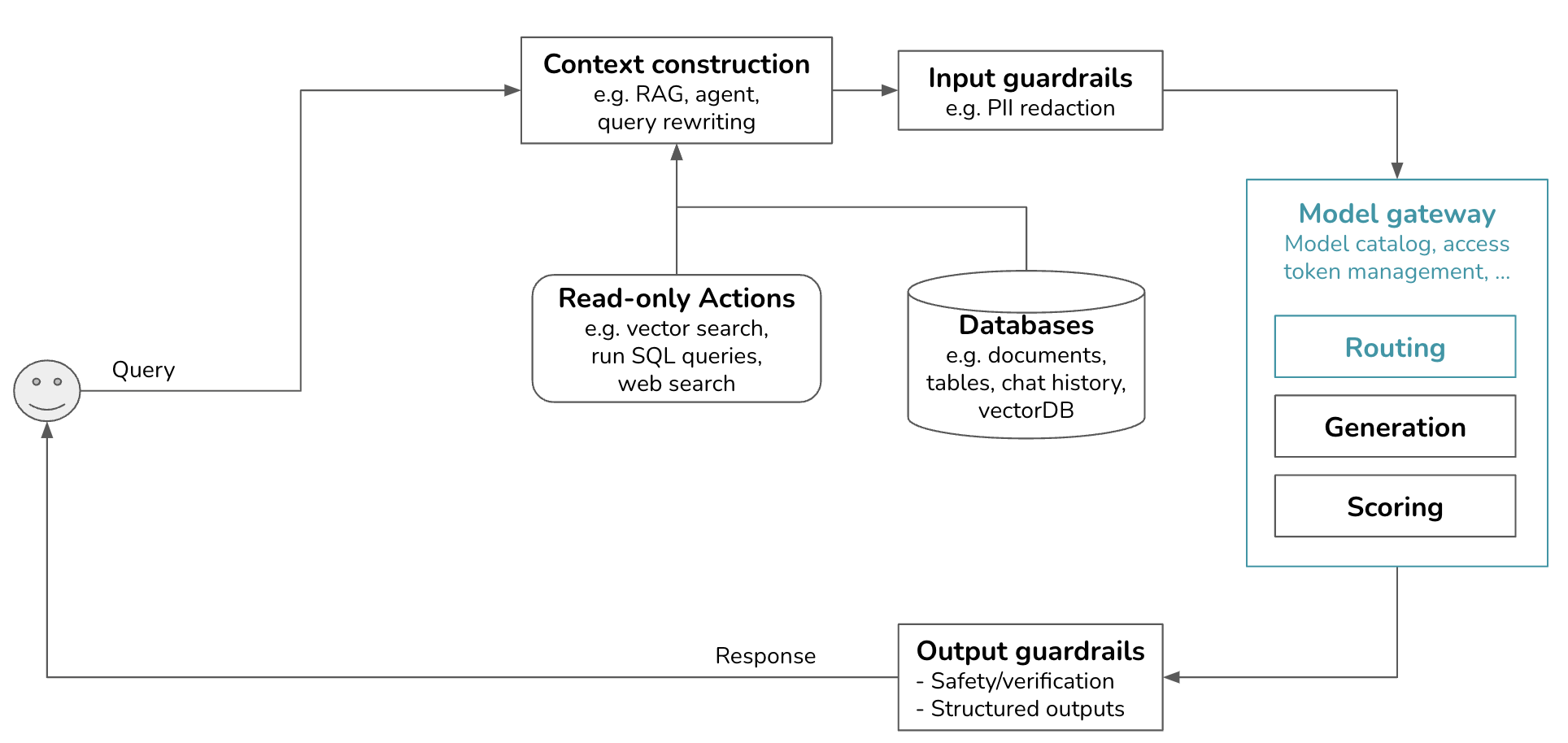
Our infrastructure now has an arrow pointing the generated response back to context construction, which in turn feeds back to models in the model gateway.
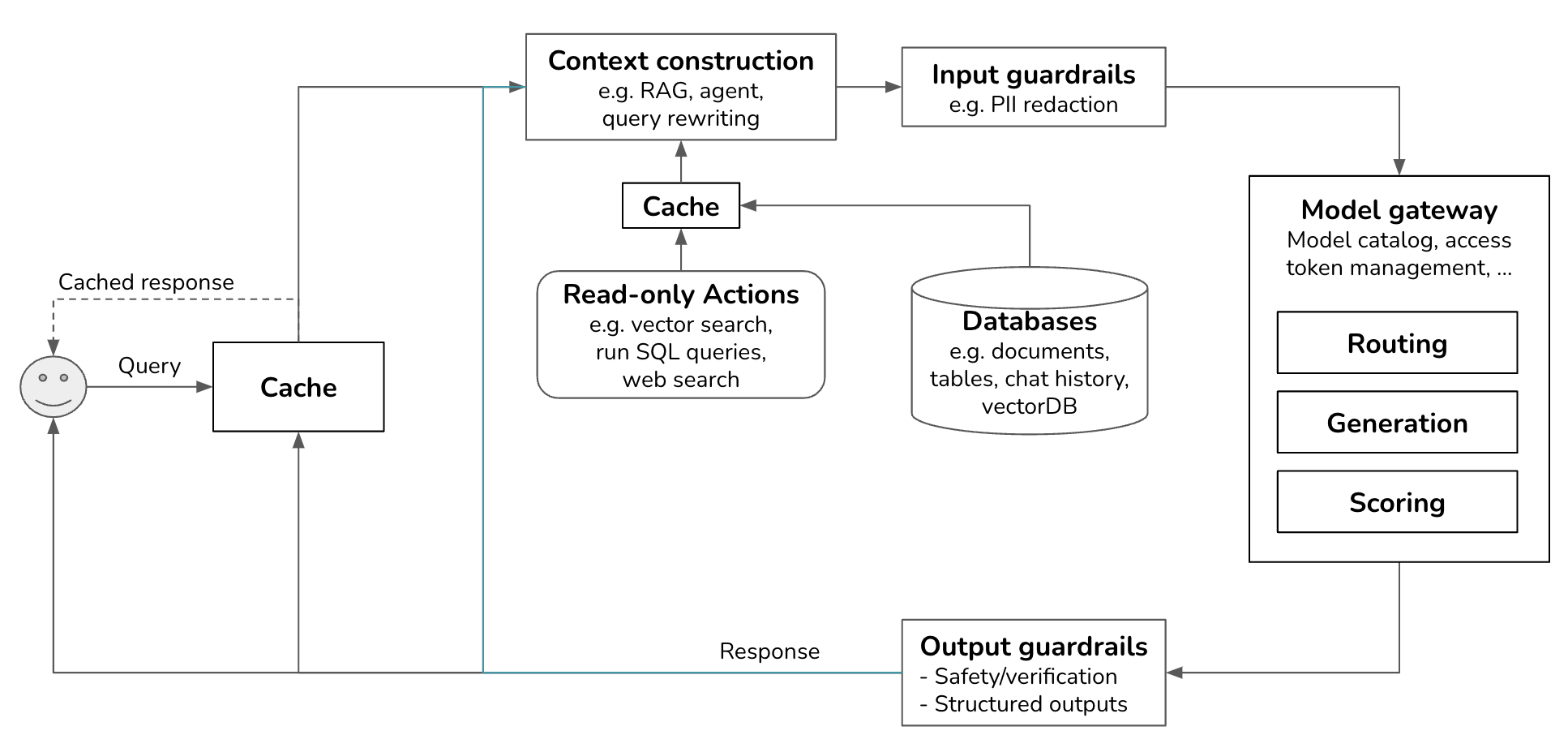
Actions used for context construction are read-only actions. They allow a model to read from its data sources to gather context. But a system can also write actions, making changes to the data sources and the world. For example, if the model outputs: “send an email to X with the message Y”, the system will invoke the action send_email(recipient=X, message=Y).
Write actions make a system vastly more capable. They can enable you to automate the whole customer outreach workflow: researching potential customers, finding their contacts, drafting emails, sending first emails, reading responses, following up, extracting orders, updating your databases with new orders, etc.
However, the prospect of giving AI the ability to automatically alter our lives is frightening. Just as you shouldn’t give an intern the authority to delete your production database, you shouldn’t allow an unreliable AI to initiate bank transfers. Trust in the system’s capabilities and its security measures is crucial. You need to ensure that the system is protected from bad actors who might try to manipulate it into performing harmful actions.
AI systems are vulnerable to cyber attacks like other software systems, but they also have another weakness: prompt injection. Prompt injection happens when an attacker manipulates input prompts into a model to get it to express undesirable behaviors. You can think of prompt injection as social engineering done on AI instead of humans.
A scenario that many companies fear is that they give an AI system access to their internal databases, and attackers trick this system into revealing private information from these databases. If the system has write access to these databases, attackers can trick the system into corrupting the data.
Any organization that wants to leverage AI needs to take safety and security seriously. However, these risks don’t mean that AI systems should never be given the ability to act in the real world. AI systems can fail, but humans can fail too. If we can get people to trust a machine to take us up into space, I hope that one day, securities will be sufficient for us to trust autonomous AI systems.
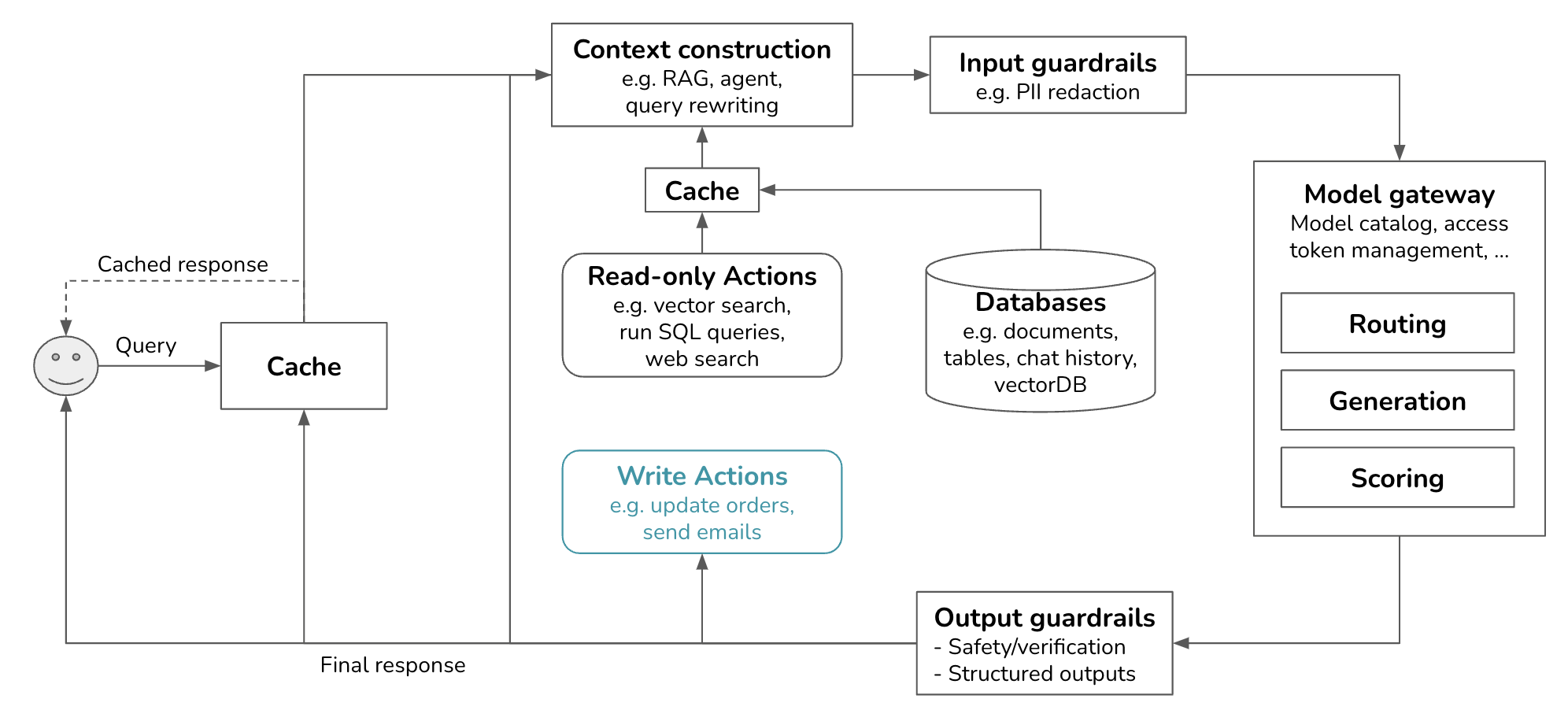
While I have placed observability in its own section, it should be integrated into the platform from the beginning rather than added later as an afterthought. Observability is crucial for projects of all sizes, and its importance grows with the complexity of the system.
This section provides the least information compared to the others. It’s impossible to cover all the nuances of observability in a blog post. Therefore, I will only give a brief overview of the three pillars of monitoring: logs, traces, and metrics. I won’t go into specifics or cover user feedback, drift detection, and debugging.
When discussing monitoring, most people think of metrics. What metrics to track depends on what you want to track about your system, which is application-specific. However, in general, there are two types of metrics you want to track: model metrics and system metrics.
System metrics tell you the state of your overall system. Common metrics are throughput, memory usage, hardware utilization, and service availability/uptime. System metrics are common to all software engineering applications. In this post, I’ll focus on model metrics.
Model metrics assess your model’s performance, such as accuracy, toxicity, and hallucination rate. Different steps in an application pipeline also have their own metrics. For example, in a RAG application, the retrieval quality is often evaluated using context relevance and context precision. A vector database can be evaluated by how much storage it needs to index the data and how long it takes to query the data
There are various ways a model’s output can fail. It’s crucial to identify these issues and develop metrics to monitor them. For example, you might want to track how often your model times out, returns empty responses or produces malformatted responses. If you’re worried about your model revealing sensitive information, find a way to track that too.
Length-related metrics such as query, context, and response length are helpful for understanding your model’s behaviors. Is one model more verbose than another? Are certain types of queries more likely to result in lengthy answers? They are especially useful for detecting changes in your application. If the average query length suddenly decreases, it could indicate an underlying issue that needs investigation.
Length-related metrics are also important for tracking latency and costs, as longer contexts and responses typically increase latency and incur higher costs.
Tracking latency is essential for understanding the user experience. Common latency metrics include:
- Time to First Token (TTFT): The time it takes for the first token to be generated.
- Time Between Tokens (TBT): The interval between each token generation.
- Tokens Per Second (TPS): The rate at which tokens are generated.
- Time Per Output Token (TPOT): The time it takes to generate each output token.
- Total Latency: The total time required to complete a response.
You’ll also want to track costs. Cost-related metrics are the number of queries and the volume of input and output tokens. If you use an API with rate limits, tracking the number of requests per second is important to ensure you stay within your allocated limits and avoid potential service interruptions.
When calculating metrics, you can choose between spot checks and exhaustive checks. Spot checks involve sampling a subset of data to quickly identify issues, while exhaustive checks evaluate every request for a comprehensive performance view. The choice depends on your system’s requirements and available resources, with a combination of both providing a balanced monitoring strategy.
When computing metrics, ensure they can be broken down by relevant axes, such as users, releases, prompt/chain versions, prompt/chain types, and time. This granularity helps in understanding performance variations and identifying specific issues.
Since this blog post is getting long and I’ve written at length about logs in Designing Machine Learning Systems, I will be quick here. The philosophy for logging is simple: log everything. Log the system configurations. Log the query, the output, and the intermediate outputs. Log when a component starts, ends, when something crashes, etc. When recording a piece of log, make sure to give it tags and IDs that can help you know where in the system this log comes from.
Logging everything means that the amount of logs you have can grow very quickly. Many tools for automated log analysis and log anomaly detection are powered by AI.
While it’s impossible to manually process logs, it’s useful to manually inspect your production data daily to get a sense of how users are using your application. Shankar et al. (2024) found that the developers’ perceptions of what constitutes good and bad outputs change as they interact with more data, allowing them to both rewrite their prompts to increase the chance of good responses and update their evaluation pipeline to catch bad responses.
Trace refers to the detailed recording of a request’s execution path through various system components and services. In an AI application, tracing reveals the entire process from when a user sends a query to when the final response is returned, including the actions the system takes, the documents retrieved, and the final prompt sent to the model. It should also show how much time each step takes and its associated cost, if measurable. As an example, this is a visualization of a Langsmith trace.
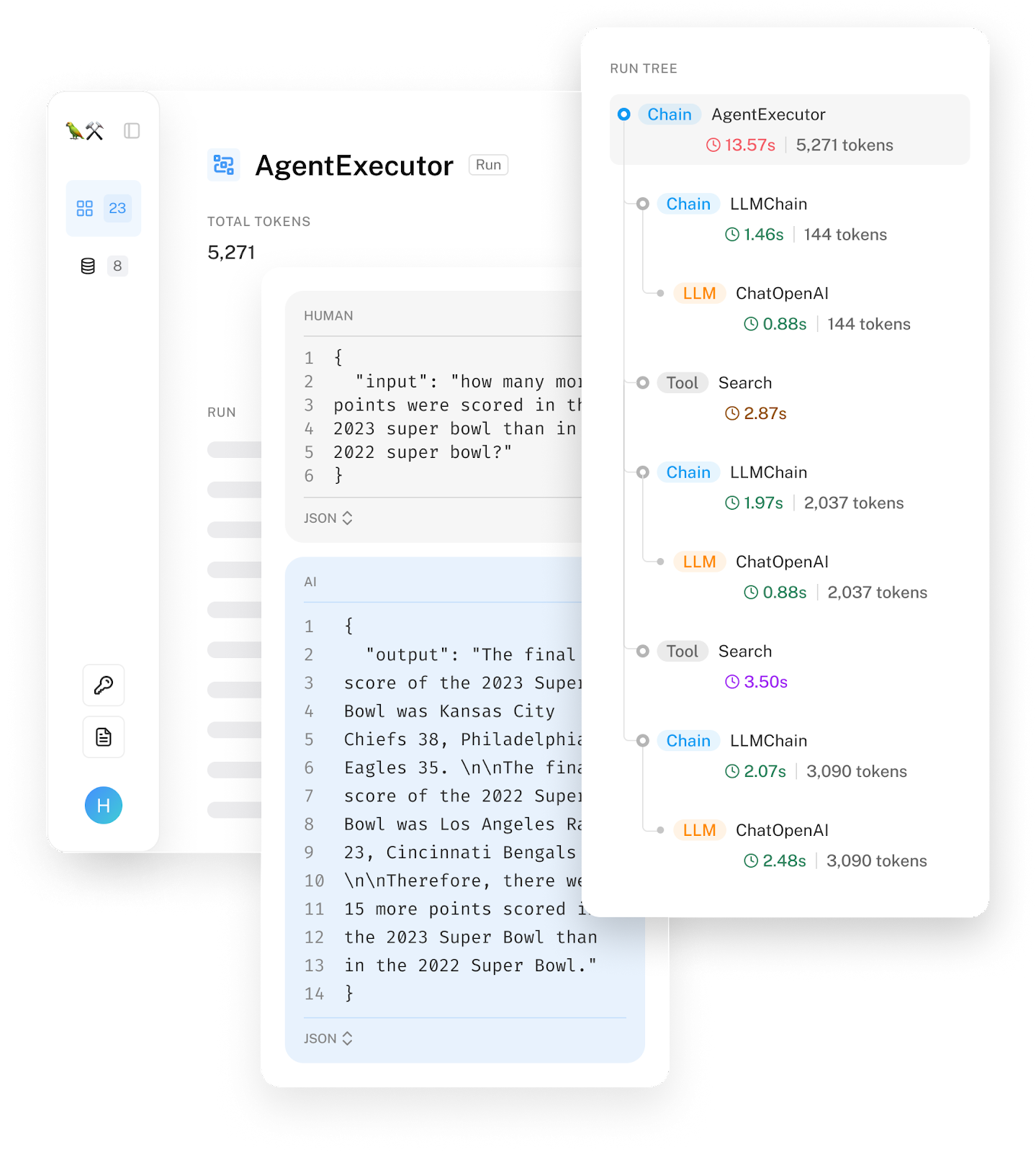
Ideally, you should be able to trace each query’s transformation through the system step-by-step. If a query fails, you should be able to pinpoint the exact step where it went wrong: whether it was incorrectly processed, the retrieved context was irrelevant, or the model generated a wrong response.
An AI application can get fairly complex, consisting of multiple models, retrieving data from many databases, and having access to a wide range of tools. An orchestrator helps you specify how these different components are combined (chained) together to create an end-to-end application flow.
At a high level, an orchestrator works in two steps: components definition and chaining (also known as pipelining).
-
Components Definition
You need to tell the orchestrator what components your system uses, such as models (including models for generation, routing, and scoring), databases from which your system can retrieve data, and actions that your system can take. Direct integration with model gateways can help simplify model onboarding, and some orchestrator tools want to be gateways. Many orchestrators also support integration with tools for evaluation and monitoring. -
Chaining (or pipelining)
You tell the orchestrator the sequence of steps your system takes from receiving the user query until completing the task. In short, chaining is just function composition. Here’s an example of what a pipeline looks like.- Process the raw query.
- Retrieve the relevant data based on the processed query.
- The original query and the retrieved data are combined to create a prompt in the format expected by the model.
- The model generates a response based on the prompt.
- Evaluate the response.
- If the response is considered good, return it to the user. If not, route the query to a human operator.
The orchestrator is responsible for passing data between steps and can provide toolings that help ensure that the output from the current step is in the format expected by the next step.
When designing the pipeline for an application with strict latency requirements, try to do as much in parallel as possible. For example, if you have a routing component (deciding where to send a query to) and a PII removal component, they can do both at the same time.
There are many AI orchestration tools, including LangChain, LlamaIndex, Flowise, Langflow, and Haystack. Each tool has its own APIs so I won’t show the actual code here.
While it’s tempting to jump straight to an orchestration tool when starting a project, start building your application without one first. Any external tool brings added complexity. An orchestrator can abstract away critical details of how your system works, making it hard to understand and debug your system.
As you advance to the later stages of your application development process, you might decide that an orchestrator can make your life easier. Here are three aspects to keep in mind when evaluating orchestrators.
- Integration and extensibility
Evaluate whether the orchestrator supports the components you’re already using or might adopt in the future. For example, if you want to use a Llama model, check if the orchestrator supports that. Given how many models, databases, and frameworks there are, it’s impossible for an orchestrator to support everything. Therefore, you’ll also need to consider an orchestrator’s extensibility. If it doesn’t support a specific component, how hard it is to change that? - Support for complex pipelines
As your applications grow in complexity, you might need to manage intricate pipelines involving multiple steps and conditional logic. An orchestrator that supports advanced features like branching, parallel processing, and error handling will help you manage these complexities efficiently. - Ease of use, performance, and scalability
Consider the user-friendliness of the orchestrator. Look for intuitive APIs, comprehensive documentation, and strong community support, as these can significantly reduce the learning curve for you and your team. Avoid orchestrators that initiate hidden API calls or introduce latency to your applications. Additionally, ensure that the orchestrator can scale effectively as the number of applications, developers, and traffic grows.
This post started with a basic architecture and then gradually added components to address the growing application complexities. Each addition brings its own set of benefits and challenges, requiring careful consideration and implementation.
While the separation of components is important to keep your system modular and maintainable, this separation is fluid. There are many overlaps between components. For example, a model gateway can share functionalities with guardrails. Cache can be implemented in different components, such as in vector search and inference services.
This post is much longer than I intended it to be, and yet there are many details I haven’t been able to explore further, especially around observability, context construction, complex logic, cache, and guardrails. I’ll dive deeper into all these components in my upcoming book AI Engineering.
This post also didn’t discuss how to serve models, assuming that most people will be using models provided by third-party APIs. AI Engineering will also have a chapter dedicated to inference and model optimization.
Special thanks to Luke Metz, Alex Li, Chetan Tekur, Kittipat “Bot” Kampa, Hien Luu, and Denys Linkov for feedback on the early versions of this post. Their insights greatly improved the content. Any remaining errors are my own.
I read many case studies shared by companies on how they adopted generative AI, and here are some of my favorites.
- Musings on Building a Generative AI Product (LinkedIn, 2024)
- How we built Text-to-SQL at Pinterest (Pinterest, 2024)
- From idea to reality: Elevating our customer support through generative AI (Vimeo, 2023)
- A deep dive into the world’s smartest email AI (Shortwave, 2023)
- LLM-powered data classification for data entities at scale (Grab, 2023)
- From Predictive to Generative - How Michelangelo Accelerates Uber’s AI Journey (Uber, 2024)