NOTE: This chapter's code builds off of chapter 2's code.
Up to this point we have assumed that both the model & optimizer fully fit on a single GPU. So each GPU during our training process fully contains a copy of the model and optimizer.
This becomes an issue once the model becomes big enough - either the model itself cannot fit, or the optimizer (which usually contains 1-4x the memory of the model) cannot fit anymore.
Sharding refers to spreading the storage of a combination of: optimizer state, gradients, and/or model parameters across your GPUs. The execution of layers DOES NOT CHANGE.
What this means:
- Each layer of your model still needs to pull the entire layer's parameters/gradients/optimizer states into GPU memory. After the layer is done, then those pieces are resharded.
- There are synchronization costs to un-shard and re-shard before and after each layer.
- Sharding does not reduce the peak memory cost of your biggest layer.
Sharding is a data parallel technique! NOT a model/tensor/pipeline parallel technique.
- PyTorch FullyShardedDataParallel (FSDP)
- Run Command
- Examples of memory usage with different configurations

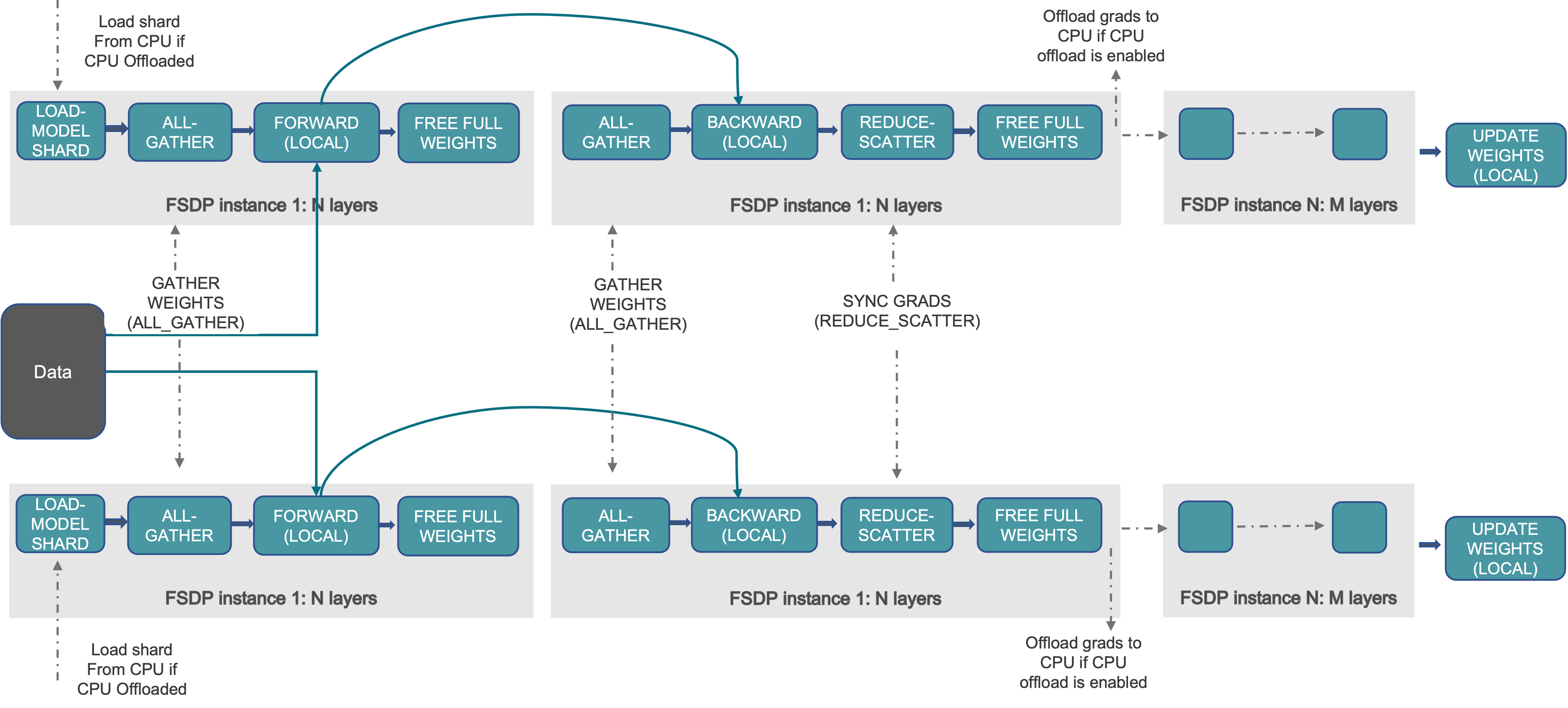
At a high level FSDP works as follow:
- In constructor:
- Shard model parameters and each rank only keeps its own shard
- In forward path:
- Run all_gather to collect all shards from all ranks to recover the full parameter in this FSDP unit
- Run forward computation
- Discard parameter shards it has just collected
- In backward path:
- Run all_gather to collect all shards from all ranks to recover the full parameter in this FSDP unit
- Run backward computation
- Run reduce_scatter to sync gradients
- Discard parameters.
Reference description of the process (from pytorch docs):
References:
- FSDP Internals (Very useful)
- FSDP Docs
- FSDP Tutorial.
This is useful because the meta device does not allocate any memory at all! It makes model initialization extremely fast. You can actually run a lot of the ops with the meta device as well, only the shape will be modified.
This is useful when training large models when we don't want to actually initialize the fully model in memory on each device. We can then use this meta model in conjuction with the FSDP constructor to only initialize the model weights after the model has been sharded across the GPUs.
with torch.device("meta"):
model = AutoModelForCausalLM.from_config(config, torch_dtype=dtype)Here is our FSDP constructor, let's explore each of these arguments in more detail. ALL of the options here have an impact on throughput, memory usage, and peak memory usage.
model = FullyShardedDataParallel(
model,
device_id=local_rank,
sync_module_states=True,
auto_wrap_policy=wrap_policy,
sharding_strategy=ShardingStrategy.FULL_SHARD,
cpu_offload=CPUOffload(offload_params=args.cpu_offload == "on"),
)In most cases, if you just want to apply reset_parameters() - you actually don't have to specify this parameter. However some models (e.g. Llama 2/3.1) have modules that do not implement reset_parameters().
It is suggested that you implement them manually. Here is what we do for our llama models:
from transformers.models.llama.modeling_llama import LlamaRMSNorm, LlamaRotaryEmbedding
# fixes for reset_parameters not existing
LlamaRMSNorm.reset_parameters = lambda self: torch.nn.init.ones_(self.weight)
LlamaRotaryEmbedding.reset_parameters = lambda _: NoneThe recommended way to perform this is to load the checkpoint onto a single rank (e.g. rank 0), and then use the sync_module_states=True to synchronize all the shards.
Loading a checkpoint heavily depends on what library you use. If you are using transformers, you can specify a device map to ensure large models can be stored in a combination of disk/cpu/gpu memory on a single rank.
To quote the docs on this:
If True, then each FSDP module will broadcast module parameters and buffers from rank 0 to ensure that they are replicated across ranks (adding communication overhead to this constructor). This can help load state_dict checkpoints via load_state_dict in a memory efficient way. See FullStateDictConfig for an example of this.
By default if you don't specify an auto_wrap_policy, FSDP will be equivalent to DDP. So you need to specify this!
Basically anything that is wrapped by FSDP will be sharded. The auto_wrap_policy takes a module and returns a boolean about whether to wrap it.
In this chapter we use the size_based_auto_wrap_policy in torch.distributed.fsdp.wrap.py, which applies FSDP to a module if the parameters in its subtree exceed 100M numel.
We expose this onto the cli via the argument --numel-to-wrap
import functools
from torch.distributed.fsdp.wrap import size_based_auto_wrap_policy
auto_wrap_policy = functools.partial(
size_based_auto_wrap_policy, min_num_params=int(args.numel_to_wrap)
)There are other provided wrap policies, like transformer_auto_wrap_policy which can wrap specific classes.
FSDP fully implements everything you can do with deepspeed! Here's how the stages align:
| FSDP ShardingStrategy | DeepSpeed ZeRO Stage | Shard Optimizer states | Shard Gradients | Shard Parameters |
|---|---|---|---|---|
FULL_SHARD |
3 | ✅ | ✅ | ✅ |
SHARD_GRAD_OP |
2 | ✅ | ✅ | ❌ |
NO_SHARD (DDP) |
0 | ❌ | ❌ | ❌ |
HYBRID_SHARD |
ZeRO++ 3 | ✅ (intra-node) | ✅ (intra-node) | ✅ (intra-node) |
If True, then this offloads gradients to CPU as well, meaning that the optimizer step runs on CPU.
This option heavily reduces memory requirements - at the cost of a lot of compute and memory bandwidth. The forward & backward pass runs on the GPU, then gradients are offloaded to CPU and the optimizer runs on the CPU.
Note that this option will NOT reduce peak GPU memory requirements - each layer will still be fully executed in the GPU. However there may be more memory for each layer to use as more memory is stored in the CPU.
Since model parameters may be sharded across GPUs, we need to do checkpointing a little bit differently. The fastest and least memory intensive will be sharded checkpoints, which will just save whatever shard the GPU currently has. Sharded checkpoints are what we recommend.
Here are the imports you need to do this:
from torch.distributed.checkpoint.state_dict import (
get_state_dict,
set_state_dict,
StateDictOptions,
)
from torch.distributed.checkpoint import load, saveAdditionally, we are going to set up our StateDictOptions, because it is used multiple places:
# NOTE: full_state_dict=False means we will be saving sharded checkpoints.
ckpt_opts = StateDictOptions(full_state_dict=False, cpu_offload=True)If we were to set full_state_dict=True, then we'd be doing full state dicts.
A notable difference to normal checkpoint is that we have to save on every rank, because we are doing sharded checkpoints, we need all the shards from every rank.
if state["global_step"] % args.ckpt_freq == 0:
dist.barrier()
# NOTE: we have to call this on ALL ranks
sharded_model_state, sharded_optimizer_state = get_state_dict(
model, optimizer, options=ckpt_opts
)
save(
dict(model=sharded_model_state, optimizer=sharded_optimizer_state),
checkpoint_id=exp_dir / "checkpoint",
)torch.distributed.checkpoint.state_dict.get_state_dict() takes in a normal model/optimizer and extracts a state dict that contains the sharded checkpoints.
Then we just call torch.distributed.checkpoint.state_dict_saver.save() to save this sharded checkpoint.
After this runs, the directory you specify will contain a file per rank!
Loading a sharded checkpoint is a little bit more complicated, since we have to convert back and forth between various formats for the checkpoints.
First, we call torch.distributed.checkpoint.state_dict.get_state_dict(), just like we did in saving a checkpoint. This will construct the sharded checkpoint dictionaries just like they were constructed when saving:
sharded_model_state, sharded_optimizer_state = get_state_dict(
model, optimizer, options=ckpt_opts
)Next we call the opposite of save, torch.distributed.checkpoint.state_dict_loader.load(). At this point the sharded state dicts will contain exactly what we saved earlier.
load(
dict(model=sharded_model_state, optimizer=sharded_optimizer_state),
checkpoint_id=exp_dir / "checkpoint",
)Finally, we need to apply these sharded checkpoint state dicts to the actual model parameters in our last step, with torch.distributed.checkpoint.state_dict.set_state_dict():
set_state_dict(
model,
optimizer,
model_state_dict=sharded_model_state,
optim_state_dict=sharded_optimizer_state,
options=ckpt_opts,
)If you want to convert between formats (like sharded to full state dict), pytorch has a set of utilities for this already. Find the guide here:
https://pytorch.org/tutorials/recipes/distributed_checkpoint_recipe.html#formats
Same command as normal:
cd distributed-training-guide/04-sharding-fsdp
export TORCHELASTIC_ERROR_FILE=../error.json
export OMP_NUM_THREADS=1
export HF_HOME=../.cache
torchrun --standalone \
--nnodes 1 \
--nproc-per-node gpu \
--redirects 3 \
--log-dir ../logs \
train_llm.py \
--experiment-name fsdp \
--dataset-name tatsu-lab/alpaca \
--model-name openai-community/gpt2 \
--cpu-offload onpeak GPU memory: The highest GPU memory allocated at any point during a single training loop iteration (during forward/backward/step)valley GPU memory: The GPU memory allocated at the end of a single training loop iteration (after forward/backward/step)
| GPUs | --numel-to-wrap | --cpu-offload | --batch-size | valley/peak GPU memory (per GPU) |
|---|---|---|---|---|
| 8xA100 (80GB) | 100_000_000 | off | 10 | 8GB / 74GB |
| 8xA100 (80GB) | 100_000_000 | on | 10 | 1.4GB / 68.7GB |
Wrapped model architecture
```python
FullyShardedDataParallel(
(_fsdp_wrapped_module): LlamaForCausalLM(
(model): FullyShardedDataParallel(
(_fsdp_wrapped_module): LlamaModel(
(embed_tokens): FullyShardedDataParallel(
(_fsdp_wrapped_module): Embedding(32000, 4096)
)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): FullyShardedDataParallel(
(_fsdp_wrapped_module): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLU()
)
)
(input_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
(post_attention_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
)
)
(norm): LlamaRMSNorm((4096,), eps=1e-05)
(rotary_emb): LlamaRotaryEmbedding()
)
)
(lm_head): FullyShardedDataParallel(
(_fsdp_wrapped_module): Linear(in_features=4096, out_features=32000, bias=False)
)
)
)
```
We actually need to use --cpu-offload on in this case - we can fit the model in memory, but the forward/backward/step passes don't fit, even with batch size 1.
| GPUs | --numel-to-wrap | --cpu-offload | --batch-size | valley/peak GPU memory (per GPU) |
|---|---|---|---|---|
| 8xA100 (80GB) | 100_000_000 | on | 2 | 0.3GB / 72.3 GB |
Wrapped model architecture
```python
FullyShardedDataParallel(
(_fsdp_wrapped_module): LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): FullyShardedDataParallel(
(_fsdp_wrapped_module): Embedding(32000, 8192)
)
(layers): ModuleList(
(0-79): 80 x LlamaDecoderLayer(
(self_attn): FullyShardedDataParallel(
(_fsdp_wrapped_module): LlamaSdpaAttention(
(q_proj): Linear(in_features=8192, out_features=8192, bias=False)
(k_proj): Linear(in_features=8192, out_features=1024, bias=False)
(v_proj): Linear(in_features=8192, out_features=1024, bias=False)
(o_proj): Linear(in_features=8192, out_features=8192, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
)
(mlp): LlamaMLP(
(gate_proj): FullyShardedDataParallel(
(_fsdp_wrapped_module): Linear(in_features=8192, out_features=28672, bias=False)
)
(up_proj): FullyShardedDataParallel(
(_fsdp_wrapped_module): Linear(in_features=8192, out_features=28672, bias=False)
)
(down_proj): FullyShardedDataParallel(
(_fsdp_wrapped_module): Linear(in_features=28672, out_features=8192, bias=False)
)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((8192,), eps=1e-05)
(post_attention_layernorm): LlamaRMSNorm((8192,), eps=1e-05)
)
)
(norm): LlamaRMSNorm((8192,), eps=1e-05)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): FullyShardedDataParallel(
(_fsdp_wrapped_module): Linear(in_features=8192, out_features=32000, bias=False)
)
)
)
```