diff --git a/docs/tutorial_live-llava.md b/docs/tutorial_live-llava.md
index f4d66f05..87bcf7fe 100644
--- a/docs/tutorial_live-llava.md
+++ b/docs/tutorial_live-llava.md
@@ -2,13 +2,17 @@
!!! abstract "Recommended"
- Follow the chat-based [LLaVA](tutorial_llava.md) and [NanoVLM](tutorial_nano-vlm.md) tutorials and see the [`local_llm`](https://github.com/dusty-nv/jetson-containers/blob/master/packages/llm/local_llm) documentation to familiarize yourself with VLMs and test the models first.
+ Follow the chat-based [LLaVA](tutorial_llava.md) and [NanoVLM](tutorial_nano-vlm.md) tutorials and see the [`local_llm`](https://github.com/dusty-nv/jetson-containers/blob/master/packages/llm/local_llm){:target="_blank"} documentation to familiarize yourself with VLMs and test the models first.
This multimodal agent runs a vision-language model on a live camera feed or video stream, repeatedly applying the same prompts to it:
-This example uses the popular [LLaVA](https://llava-vl.github.io/) model (based on Llama and [CLIP](https://openai.com/research/clip)) and has been quantized with 4-bit precision to be deployed on Jetson Orin. It's using an optimized multimodal pipeline from the [`local_llm`](https://github.com/dusty-nv/jetson-containers/tree/master/packages/llm/local_llm) package and the MLC/TVM inferencing runtime, and acts as a building block for creating always-on edge applications that can trigger user-promptable alerts and actions with the flexibility of VLMs.
+It uses models like [LLaVA](https://llava-vl.github.io/){:target="_blank"} or [VILA](https://github.com/Efficient-Large-Model/VILA){:target="_blank"} (based on Llama and [CLIP](https://openai.com/research/clip)) and has been quantized with 4-bit precision to be deployed on Jetson Orin. This runs an optimized multimodal pipeline from the [`local_llm`](https://github.com/dusty-nv/jetson-containers/tree/master/packages/llm/local_llm){:target="_blank"} package, and acts as a building block for creating event-driven streaming applications that trigger user-promptable alerts and actions with the flexibility of VLMs:
+
+
+
+The interactive web UI supports event filters, alerts, and multimodal [vector DB](tutorial_nanodb.md) integration.
## Running the Live Llava Demo
@@ -39,45 +43,30 @@ This example uses the popular [LLaVA](https://llava-vl.github.io/) model (based
- [`NousResearch/Obsidian-3B-V0.5`](https://huggingface.co/NousResearch/Obsidian-3B-V0.5)
- [`VILA-2.7b`](https://huggingface.co/Efficient-Large-Model/VILA-2.7b), [`VILA-7b`](https://huggingface.co/Efficient-Large-Model/VILA-7b), [`Llava-7b`](https://huggingface.co/liuhaotian/llava-v1.6-vicuna-7b), and [`Obsidian-3B`](https://huggingface.co/NousResearch/Obsidian-3B-V0.5) can run on Orin Nano 8GB
-The [`VideoQuery`](https://github.com/dusty-nv/jetson-containers/blob/master/packages/llm/local_llm/agents/video_query.py) agent processes an incoming camera or video feed on prompts in a closed loop with Llava.
+The [VideoQuery](https://github.com/dusty-nv/jetson-containers/blob/master/packages/llm/local_llm/agents/video_query.py){:target="_blank"} agent processes an incoming camera or video feed on prompts in a closed loop with the VLM. Navigate your browser to `https://:8050` after launching it, and see this [demo walkthrough](https://www.youtube.com/watch?v=dRmAGGuupuE){:target="_blank"} video for pointers on using the web UI.
```bash
-./run.sh \
- -e SSL_KEY=/data/key.pem -e SSL_CERT=/data/cert.pem \
- $(./autotag local_llm) \
+./run.sh $(./autotag local_llm) \
python3 -m local_llm.agents.video_query --api=mlc --verbose \
- --model liuhaotian/llava-v1.5-7b \
+ --model Efficient-Large-Model/VILA-2.7b \
--max-context-len 768 \
--max-new-tokens 32 \
--video-input /dev/video0 \
- --video-output webrtc://@:8554/output \
- --prompt "How many fingers am I holding up?"
+ --video-output webrtc://@:8554/output
```
-> Refer to [Enabling HTTPS/SSL](https://github.com/dusty-nv/jetson-containers/tree/master/packages/llm/local_llm#enabling-httpsssl) to generate self-signed SSL certificates for enabling client-side browser webcams.
-
-This uses [`jetson_utils`](https://github.com/dusty-nv/jetson-utils) for video I/O, and for options related to protocols and file formats, see [Camera Streaming and Multimedia](https://github.com/dusty-nv/jetson-inference/blob/master/docs/aux-streaming.md). In the example above, it captures a V4L2 USB webcam connected to the Jetson (`/dev/video0`) and outputs a WebRTC stream that can be viewed from a browser at `https://HOSTNAME:8554`. When HTTPS/SSL is enabled, it can also capture from the browser's webcam.
-### Changing the Prompt
-
-The `--prompt` can be specified multiple times, and changed at runtime by pressing the number of the prompt followed by enter on the terminal's keyboard (for example, 1 + Enter for the first prompt). These are the default prompts when no `--prompt` is specified:
-
-1. Describe the image concisely.
-2. How many fingers is the person holding up?
-3. What does the text in the image say?
-4. There is a question asked in the image. What is the answer?
-
-Future versions of this demo will have the prompts dynamically editable from the web UI.
+This uses [jetson_utils](https://github.com/dusty-nv/jetson-utils) for video I/O, and for options related to protocols and file formats, see [Camera Streaming and Multimedia](https://github.com/dusty-nv/jetson-inference/blob/master/docs/aux-streaming.md). In the example above, it captures a V4L2 USB webcam connected to the Jetson (`/dev/video0`) and outputs a WebRTC stream that can be viewed from a browser at `https://HOSTNAME:8554`. When HTTPS/SSL is enabled, it can also capture from the browser's webcam.
### Processing a Video File or Stream
-The example above was running on a live camera, but you can also read and write a [video file or stream](https://github.com/dusty-nv/jetson-inference/blob/master/docs/aux-streaming.md) by substituting the path or URL to the `--video-input` and `--video-output` command-line arguments like this:
+The example above was running on a live camera, but you can also read and write a [video file or network stream](https://github.com/dusty-nv/jetson-inference/blob/master/docs/aux-streaming.md) by substituting the path or URL to the `--video-input` and `--video-output` command-line arguments like this:
```bash
./run.sh \
-v /path/to/your/videos:/mount
$(./autotag local_llm) \
python3 -m local_llm.agents.video_query --api=mlc --verbose \
- --model liuhaotian/llava-v1.5-7b \
+ --model Efficient-Large-Model/VILA-2.7b \
--max-new-tokens 32 \
--video-input /mount/my_video.mp4 \
--video-output /mount/output.mp4 \
@@ -86,5 +75,25 @@ The example above was running on a live camera, but you can also read and write
This example processes and pre-recorded video (in MP4, MKV, AVI, FLV formats with H.264/H.265 encoding), but it also can input/output live network streams like [RTP](https://github.com/dusty-nv/jetson-inference/blob/master/docs/aux-streaming.md#rtp), [RTSP](https://github.com/dusty-nv/jetson-inference/blob/master/docs/aux-streaming.md#rtsp), and [WebRTC](https://github.com/dusty-nv/jetson-inference/blob/master/docs/aux-streaming.md#webrtc) using Jetson's hardware-accelerated video codecs.
-
+### NanoDB Integration
+
+If you launch the [VideoQuery](https://github.com/dusty-nv/jetson-containers/blob/master/packages/llm/local_llm/agents/video_query.py){:target="_blank"} agent with the `--nanodb` flag along with a path to your NanoDB database, it will perform reverse-image search on the incoming feed against the database by re-using the CLIP embeddings generated by the VLM.
+
+To enable this mode, first follow the [**NanoDB tutorial**](tutorial_nanodb.md) to download, index, and test the database. Then launch VideoQuery like this:
+
+```bash
+./run.sh $(./autotag local_llm) \
+ python3 -m local_llm.agents.video_query --api=mlc --verbose \
+ --model Efficient-Large-Model/VILA-2.7b \
+ --max-context-len 768 \
+ --max-new-tokens 32 \
+ --video-input /dev/video0 \
+ --video-output webrtc://@:8554/output \
+ --nanodb /data/nanodb/coco/2017
+```
+
+You can also tag incoming images and add them to the database using the panel in the web UI.
+
+
+
diff --git a/docs/tutorial_nano-vlm.md b/docs/tutorial_nano-vlm.md
index d759f65e..090c0a57 100644
--- a/docs/tutorial_nano-vlm.md
+++ b/docs/tutorial_nano-vlm.md
@@ -120,8 +120,11 @@ These models can also be used with the [Live Llava](tutorial_live-llava.md) agen
--max-context-len 768 \
--max-new-tokens 32 \
--video-input /dev/video0 \
- --video-output webrtc://@:8554/output \
- --prompt "How many fingers am I holding up?"
+ --video-output webrtc://@:8554/output
```
-
-
+
+
+
+
+
+
diff --git a/docs/tutorial_nanodb.md b/docs/tutorial_nanodb.md
index 9e338799..67b00154 100644
--- a/docs/tutorial_nanodb.md
+++ b/docs/tutorial_nanodb.md
@@ -1,6 +1,6 @@
# Tutorial - NanoDB
-Let's run [NanoDB](https://github.com/dusty-nv/jetson-containers/blob/master/packages/vectordb/nanodb/README.md)'s interactive demo to witness the impact of Vector Database that handles multimodal data.
+Let's run [NanoDB](https://github.com/dusty-nv/jetson-containers/blob/master/packages/vectordb/nanodb/README.md){:target="_blank"}'s interactive demo to witness the impact of Vector Database that handles multimodal data.
@@ -11,6 +11,7 @@ Let's run [NanoDB](https://github.com/dusty-nv/jetson-containers/blob/master/pac
Jetson AGX Orin (64GB)Jetson AGX Orin (32GB)Jetson Orin NX (16GB)
+ Jetson Orin Nano (8GB)
2. Running one of the following versions of [JetPack](https://developer.nvidia.com/embedded/jetpack):
@@ -19,7 +20,8 @@ Let's run [NanoDB](https://github.com/dusty-nv/jetson-containers/blob/master/pac
3. Sufficient storage space (preferably with NVMe SSD).
- - `7.0GB` for container image
+ - `16GB` for container image
+ - `40GB` for MS COCO dataset
4. Clone and setup [`jetson-containers`](https://github.com/dusty-nv/jetson-containers/blob/master/docs/setup.md){:target="_blank"}:
@@ -32,35 +34,49 @@ Let's run [NanoDB](https://github.com/dusty-nv/jetson-containers/blob/master/pac
## How to start
-### Download your data
+### Download COCO
-Just for an example, let's just use MS COCO dataset.
+Just for an example, let's use MS COCO dataset:
```
cd jetson-containers
-mkdir data/datasets/coco/
-cd data/datasets/coco
+mkdir -p data/datasets/coco/2017
+cd data/datasets/coco/2017
+
wget http://images.cocodataset.org/zips/train2017.zip
+wget http://images.cocodataset.org/zips/val2017.zip
+wget http://images.cocodataset.org/zips/unlabeled2017.zip
+
unzip train2017.zip
+unzip val2017.zip
+unzip unlabeled2017.zip
+```
+
+### Download Index
+
+You can download a pre-indexed NanoDB that was already prepared over the COCO dataset from [here](https://nvidia.box.com/shared/static/icw8qhgioyj4qsk832r4nj2p9olsxoci.gz):
+
```
+cd jetson-containers/data
+wget https://nvidia.box.com/shared/static/icw8qhgioyj4qsk832r4nj2p9olsxoci.gz -O nanodb_coco_2017.tar.gz
+tar -xzvf nanodb_coco_2017.tar.gz
+```
+
+This allow you to skip the [indexing process](#indexing-data) in the next step, and jump to starting the [Web UI](#interactive-web-ui).
### Indexing Data
-First, we need to build the index by scanning your dataset directory.
+If you didn't download the [NanoDB index](#download-index) for COCO from above, we need to build the index by scanning your dataset directory:
```
-cd jetson-containers
-./run.sh -v ${PWD}/data/datasets/coco:/my_dataset $(./autotag nanodb) \
+./run.sh $(./autotag nanodb) \
python3 -m nanodb \
- --scan /my_dataset \
- --path /my_dataset/nanodb \
+ --scan /data/datasets/coco/2017 \
+ --path /data/nanodb/coco/2017 \
--autosave --validate
```
-This will take about 2 hours.
-
-Once the database has loaded and completed any start-up operations , it will drop down to a `> ` prompt from which the user can run search queries.
-You can quickly check the operation by typing your query on this prompt.
+This will take a few hours on AGX Orin. Once the database has loaded and completed any start-up operations , it will drop down to a `> ` prompt from which the user can run search queries. You can quickly check the operation by typing your query on this prompt:
```
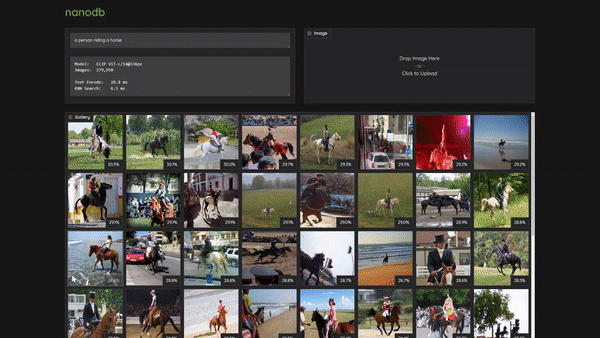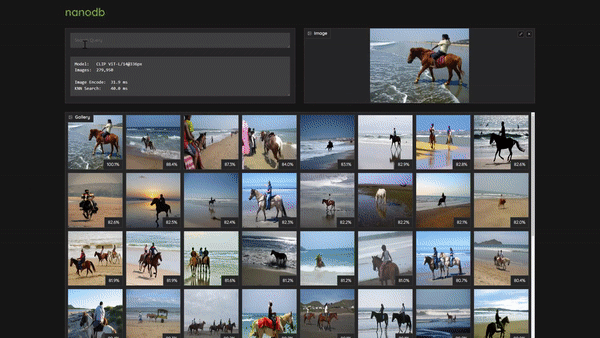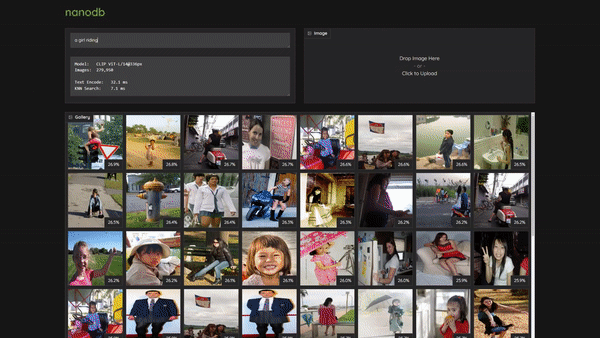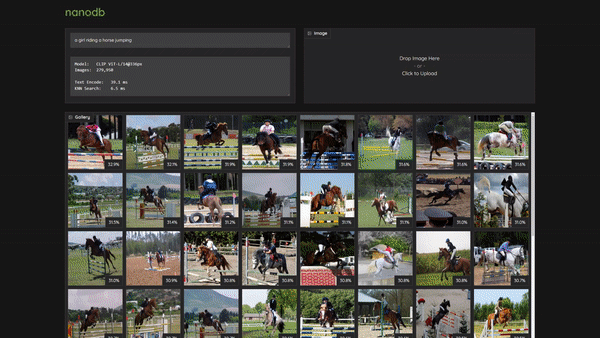
> a girl riding a horse
@@ -75,22 +91,20 @@ You can quickly check the operation by typing your query on this prompt.
* index=104819 /data/datasets/coco/2017/train2017/000000515895.jpg similarity=0.285491943359375
```
-You can press ++ctrl+c++ to exit from the app and the container.
+You can press ++ctrl+c++ to exit. For more info about the various options available, see the [NanoDB container](https://github.com/dusty-nv/jetson-containers/blob/master/packages/vectordb/nanodb/README.md){:target="_blank"} documentation.
-### Interactive web UI
+## Interactive Web UI
-Spin up the Gradio server.
+Spin up the Gradio server:
```
-cd jetson-containers
-./run.sh -v ${PWD}/data/datasets/coco:/my_dataset $(./autotag nanodb) \
+./run.sh $(./autotag nanodb) \
python3 -m nanodb \
- --path /my_dataset/nanodb \
+ --path /data/nanodb/coco/2017 \
--server --port=7860
```
-You can use your PC (or any machine) that can access your Jetson via a network, and navigate your browser to `http://:7860`
-
-You can enter text search queries as well as drag/upload images.
+Then navigate your browser to `http://:7860`, and you can enter text search queries as well as drag/upload images:
+> To use the dark theme, navigate to `http://:7860/?__theme=dark` instead

 @@ -11,6 +11,7 @@ Let's run [NanoDB](https://github.com/dusty-nv/jetson-containers/blob/master/pac
Jetson AGX Orin (64GB)
Jetson AGX Orin (32GB)
Jetson Orin NX (16GB)
+ Jetson Orin Nano (8GB)
2. Running one of the following versions of [JetPack](https://developer.nvidia.com/embedded/jetpack):
@@ -19,7 +20,8 @@ Let's run [NanoDB](https://github.com/dusty-nv/jetson-containers/blob/master/pac
3. Sufficient storage space (preferably with NVMe SSD).
- - `7.0GB` for container image
+ - `16GB` for container image
+ - `40GB` for MS COCO dataset
4. Clone and setup [`jetson-containers`](https://github.com/dusty-nv/jetson-containers/blob/master/docs/setup.md){:target="_blank"}:
@@ -32,35 +34,49 @@ Let's run [NanoDB](https://github.com/dusty-nv/jetson-containers/blob/master/pac
## How to start
-### Download your data
+### Download COCO
-Just for an example, let's just use MS COCO dataset.
+Just for an example, let's use MS COCO dataset:
```
cd jetson-containers
-mkdir data/datasets/coco/
-cd data/datasets/coco
+mkdir -p data/datasets/coco/2017
+cd data/datasets/coco/2017
+
wget http://images.cocodataset.org/zips/train2017.zip
+wget http://images.cocodataset.org/zips/val2017.zip
+wget http://images.cocodataset.org/zips/unlabeled2017.zip
+
unzip train2017.zip
+unzip val2017.zip
+unzip unlabeled2017.zip
+```
+
+### Download Index
+
+You can download a pre-indexed NanoDB that was already prepared over the COCO dataset from [here](https://nvidia.box.com/shared/static/icw8qhgioyj4qsk832r4nj2p9olsxoci.gz):
+
```
+cd jetson-containers/data
+wget https://nvidia.box.com/shared/static/icw8qhgioyj4qsk832r4nj2p9olsxoci.gz -O nanodb_coco_2017.tar.gz
+tar -xzvf nanodb_coco_2017.tar.gz
+```
+
+This allow you to skip the [indexing process](#indexing-data) in the next step, and jump to starting the [Web UI](#interactive-web-ui).
### Indexing Data
-First, we need to build the index by scanning your dataset directory.
+If you didn't download the [NanoDB index](#download-index) for COCO from above, we need to build the index by scanning your dataset directory:
```
-cd jetson-containers
-./run.sh -v ${PWD}/data/datasets/coco:/my_dataset $(./autotag nanodb) \
+./run.sh $(./autotag nanodb) \
python3 -m nanodb \
- --scan /my_dataset \
- --path /my_dataset/nanodb \
+ --scan /data/datasets/coco/2017 \
+ --path /data/nanodb/coco/2017 \
--autosave --validate
```
-This will take about 2 hours.
-
-Once the database has loaded and completed any start-up operations , it will drop down to a `> ` prompt from which the user can run search queries.
@@ -11,6 +11,7 @@ Let's run [NanoDB](https://github.com/dusty-nv/jetson-containers/blob/master/pac
Jetson AGX Orin (64GB)
Jetson AGX Orin (32GB)
Jetson Orin NX (16GB)
+ Jetson Orin Nano (8GB)
2. Running one of the following versions of [JetPack](https://developer.nvidia.com/embedded/jetpack):
@@ -19,7 +20,8 @@ Let's run [NanoDB](https://github.com/dusty-nv/jetson-containers/blob/master/pac
3. Sufficient storage space (preferably with NVMe SSD).
- - `7.0GB` for container image
+ - `16GB` for container image
+ - `40GB` for MS COCO dataset
4. Clone and setup [`jetson-containers`](https://github.com/dusty-nv/jetson-containers/blob/master/docs/setup.md){:target="_blank"}:
@@ -32,35 +34,49 @@ Let's run [NanoDB](https://github.com/dusty-nv/jetson-containers/blob/master/pac
## How to start
-### Download your data
+### Download COCO
-Just for an example, let's just use MS COCO dataset.
+Just for an example, let's use MS COCO dataset:
```
cd jetson-containers
-mkdir data/datasets/coco/
-cd data/datasets/coco
+mkdir -p data/datasets/coco/2017
+cd data/datasets/coco/2017
+
wget http://images.cocodataset.org/zips/train2017.zip
+wget http://images.cocodataset.org/zips/val2017.zip
+wget http://images.cocodataset.org/zips/unlabeled2017.zip
+
unzip train2017.zip
+unzip val2017.zip
+unzip unlabeled2017.zip
+```
+
+### Download Index
+
+You can download a pre-indexed NanoDB that was already prepared over the COCO dataset from [here](https://nvidia.box.com/shared/static/icw8qhgioyj4qsk832r4nj2p9olsxoci.gz):
+
```
+cd jetson-containers/data
+wget https://nvidia.box.com/shared/static/icw8qhgioyj4qsk832r4nj2p9olsxoci.gz -O nanodb_coco_2017.tar.gz
+tar -xzvf nanodb_coco_2017.tar.gz
+```
+
+This allow you to skip the [indexing process](#indexing-data) in the next step, and jump to starting the [Web UI](#interactive-web-ui).
### Indexing Data
-First, we need to build the index by scanning your dataset directory.
+If you didn't download the [NanoDB index](#download-index) for COCO from above, we need to build the index by scanning your dataset directory:
```
-cd jetson-containers
-./run.sh -v ${PWD}/data/datasets/coco:/my_dataset $(./autotag nanodb) \
+./run.sh $(./autotag nanodb) \
python3 -m nanodb \
- --scan /my_dataset \
- --path /my_dataset/nanodb \
+ --scan /data/datasets/coco/2017 \
+ --path /data/nanodb/coco/2017 \
--autosave --validate
```
-This will take about 2 hours.
-
-Once the database has loaded and completed any start-up operations , it will drop down to a `> ` prompt from which the user can run search queries.