For running LLM benchmarks, see the MLC container documentation.
+
Small Language Models (SLM)
+
+
+
Small language models are generally defined as having fewer than 7B parameters (Llama-7B shown for reference)
+For more data and info about running these models, see the SLM tutorial and MLC container documentation.
+
Vision Language Models (VLM)
+
+
+
This measures the end-to-end pipeline performance for continuous streaming like with Live Llava.
+For more data and info about running these models, see the NanoVLM tutorial.
For running vector database benchmarks, see the NanoDB container documentation.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/buy.md.bak b/buy.md.bak
new file mode 100644
index 00000000..e4d72ec1
--- /dev/null
+++ b/buy.md.bak
@@ -0,0 +1,21 @@
+---
+hide:
+ - navigation
+ - toc
+---
+
+# Buy
+
+Get your Jetson developer kit to try generative AIs in your own local environment.
+
+!!! note
+
+ The availablility and the price of Jetson developer kits vary depending on your region. Please click "Jetson Store" button to find out the availability on the page next.
+
+
+| | Product | Action |
+|-|-|-|
+| |
Jetson AGX Orin 64GB Developer Kit
AI Perf: 275 TOPS
GPU: NVIDIA Ampere architecture with 2048 NVIDIA CUDA cores and 64 tensor cores
CPU: 12-core Arm Cortex-A78AE v8.2 64-bit CPU 3MB L2 + 6MB L3
Below, you'll find a collection of guides, tutorials, and articles contributed by the community showcasing the implementation of generative AI on the Jetson platform.
Toshihiko Aoki has created a prompt generator for stable-diffusion-webui that translates Japanese queries into English using a fine-tuned GPT-2 NMT model before feeding them into Stable Diffusion. Check out the full guide on GitHub under to-aoki/ja-tiny-sd-webui, including the training dataset and LoRA building!
Vy Pham has created a novel denoising pipeline using a custom trained Transformer-based diffusion model and GAN upscaler for image enhancement, running on Jetson AGX Orin. It runs interactively in a Streamlit web UI for photo capturing and the processing of images and videos. Great work!
Nurgaliyev Shakhizat demonstrates a locally-hosted Blind Assistant Device running on Jetson AGX Orin 64GB Developer Kit for realtime image-to-speech translation:
See how DIY robotics legend Dave Niewinski from davesarmoury.com brings GLaDOS to life using Jetson AGX Orin, running LLMs onboard alongside object + depth tracking, and RIVA ASR/TTS with a custom-trained voice model for speech recognition and synthesis! Using Unitree Z1 arm with 3D printing and StereoLabs ZED2.
Seeed Studio has announced the launch of the Local Voice Chatbot, an NVIDIA Riva- and LLaMa-2-based large language model (LLM) chatbot with voice recognition capabilities — running entirely locally on NVIDIA Jetson devices, including the company's own reComputer range. Follow the step-by-step guide on the Seeed Studio wiki.
Watch this webinar about deploying LLMs, VLMs, ViTs, and vector databases onboard Jetson Orin for building next-generation applications using Generative AI:
JetsonHacks publishes an insightful video that walks developers through the typical steps for running generative AI models on Jetson following this site's tutorials. The video shows the interaction with the LLaVA model.
Nurgaliyev Shakhizat demonstrates Vision2Audio running on Jetson AGX Orin 64GB Developer Kit to harness the power of LLaVA to help visually impaired people:
Michael Yuan's guide demonstrating how to set up the Jetson AGX Orin 64GB Developer Kit specifically for large language model (LLM) inference, highlighting the crucial role of GPUs and the cost-effectiveness of the Jetson AGX Orin for LLM tasks.
JetsonHacks has a in-depth tutorial on how to use jetson-containers and even show text-generation-webui and stable-diffusion-webui containers in action!
JetsonHacks gives a nice introduction to NVIDIA RIVA SDK and demonstrate its automated speech recognition (ASR) capability on Jetson Orin Nano Developer Kit.
Learn how to harness the power of Multimodal AI by running Microsoft JARVIS on an Jetson AGX Orin 64GB Developer Kit, enabling a wide range of AI tasks with ChatGPT-like capabilities, image generation, and more, in this comprehensive guide by Paul DeCarlo.
Hello AI World is an in-depth tutorial series for DNN-based inference and training of image classification, object detection, semantic segmentation, and more. It is built on the jetson-inference library using TensorRT for optimized performance on Jetson.
+
+
It's highly recommended to familiarize yourself with the concepts of machine learning and computer vision before diving into the more advanced topics of generative AI here on the Jetson AI Lab. Many of these models will prove useful to have during your development.
The Jetson AI Lab Research Group is a global collective for advancing open-source Edge ML, open to anyone to join and collaborate with others from the community and leverage each other's work. Our goal is using advanced AI for good in real-world applications in accessible and responsible ways. By coordinating together as a group, we can keep up with the rapidly evolving pace of AI and more quickly arrive at deploying intelligent multimodal agents and autonomous robots into the field.
+
There are virtual meetings that anyone is welcome to join, offline discussion on the Jetson Projects forum, and guidelines for upstreaming open-source contributions.
+
+
Next Meeting - 5/1
+
The next team meeting is on Wednesday, May 1st at 9am PST. View the recording from the last meeting below.
+
+
+
+
Topics of Interest
+
These are some initial research topics for us to discuss and investigate. This list will vary over time as experiments evolve and the SOTA progresses:
+
+
+
• Controller LLMs for dynamic pipeline code generation
+
• Fine-tuning LLM/VLM onboard Jetson AGX Orin 64GB
+
+
+
• HomeAssistant.io integration for smart home [1] [2]
+
• Continuous multi-image VLM streaming and change detection
• Diffusion models for image processing and enhancement
+
• Time Series Forecasting with Transformers [1] [2]
+
+
+
• Guidance, grammars, and guardrails for constrained output
+
• Inline LLM function calling / plugins from API definitions
+
+
+
• ML DevOps, edge deployment, and orchestration
+
• Robotics, IoT, and cyberphysical systems integration
+
+
+
+
New topics can be raised to the group either during the meetings or on the forums (people are welcome to work on whatever they want of course)
+
Contribution Guidelines
+
+
+
When experiments are successful, ideally the results will be packaged in such a way that they are easily reusable for others to integrate into their own projects:
Ongoing technical discussions are encouraged to occur on the forums or GitHub Issues, with status updates on projects given during the meetings.
+
Meeting Schedule
+
We'll aim to meet monthly or bi-weekly as a team in virtual meetings that anyone is welcome to join and speak during. We'll discuss the latest updates and experiments that we want to explore. Please remain courteous to others during the calls. We'll stick around after for anyone who has questions or didn't get the chance to be heard.
+
+
Wednesday, May 1 at 9am PST (5/1/24)
+
+
Teams Invite and Agenda will be posted here.
+
+
+
+
+
The agenda will be posted beforehand. Post to the forum to add agenda items. The meetings will be recorded so anyone unable to attend live can watch them after.
On the agenda\, we will discuss the latest updates\, G
+ TC recap\, and experiments that we want to explore.
\;
Anyone is welcome to j
+ oin and speak. Please remain courteous of others during the call\, and sta
+ y muted if you aren’\;t speaking.
+ \; We’\;ll stick around after for anyone who has questions or
+ didn't get the chance to be heard. \; <
+ /span>This meeting will be recorded and posted afterwards for anyone unabl
+ e to attend.
\;
<
+ div style='margin-bottom:.25in\;overflow:hidden'>
For running LLM benchmarks, see the MLC container documentation.
"},{"location":"benchmarks.html#small-language-models-slm","title":"Small Language Models (SLM)","text":"
Small language models are generally defined as having fewer than 7B parameters (Llama-7B shown for reference) For more data and info about running these models, see the SLM tutorial and MLC container documentation.
"},{"location":"benchmarks.html#vision-language-models-vlm","title":"Vision Language Models (VLM)","text":"
This measures the end-to-end pipeline performance for continuous streaming like with Live Llava. For more data and info about running these models, see the NanoVLM tutorial.
Below, you'll find a collection of guides, tutorials, and articles contributed by the community showcasing the implementation of generative AI on the Jetson platform.
"},{"location":"community_articles.html#github-japanese-nmt-translation-for-stable-diffusion-2-23-2024","title":"GitHub Japanese NMT Translation for Stable Diffusion (2-23-2024)","text":"
Toshihiko Aoki has created a prompt generator for stable-diffusion-webui that translates Japanese queries into English using a fine-tuned GPT-2 NMT model before feeding them into Stable Diffusion. Check out the full guide on GitHub under to-aoki/ja-tiny-sd-webui, including the training dataset and LoRA building!
Your browser does not support the video tag."},{"location":"community_articles.html#github-jetbot-voice-to-action-tools-empowering-your-ros2-robot-with-voice-control-2-17-2024","title":"GitHub JetBot Voice to Action Tools: Empowering Your ROS2 Robot with Voice Control (2-17-2024)","text":"
Jen Hung Ho created ROS2 nodes for ASR/TTS on Jetson Nano that can can be used to control JetBot, including customizable voice commands and the execution of advanced actions. Check it out on GitHub under Jen-Hung-Ho/ros2_jetbot_tools and Jen-Hung-Ho/ros2_jetbot_voice and on the forums here.
"},{"location":"community_articles.html#hackster-clearwater-underwater-image-enhancement-with-generative-ai-2-16-2024","title":"Hackster ClearWater: Underwater Image Enhancement with Generative AI (2-16-2024)","text":"
Vy Pham has created a novel denoising pipeline using a custom trained Transformer-based diffusion model and GAN upscaler for image enhancement, running on Jetson AGX Orin. It runs interactively in a Streamlit web UI for photo capturing and the processing of images and videos. Great work!
Your browser does not support the video tag."},{"location":"community_articles.html#hackster-ai-powered-application-for-the-blind-and-visually-impaired-12-13-2023","title":"Hackster AI-Powered Application for the Blind and Visually Impaired (12-13-2023)","text":"
Nurgaliyev Shakhizat demonstrates a locally-hosted Blind Assistant Device running on Jetson AGX Orin 64GB Developer Kit for realtime image-to-speech translation:
\u00a0 Find more resources about this project here: [Hackster] [GitHub]
"},{"location":"community_articles.html#daves-armoury-bringing-glados-to-life-with-robotics-and-ai-2-8-2024","title":"Dave's Armoury Bringing GLaDOS to life with Robotics and AI (2-8-2024)","text":"
See how DIY robotics legend Dave Niewinski from davesarmoury.com brings GLaDOS to life using Jetson AGX Orin, running LLMs onboard alongside object + depth tracking, and RIVA ASR/TTS with a custom-trained voice model for speech recognition and synthesis! Using Unitree Z1 arm with 3D printing and StereoLabs ZED2.
\u00a0 Find more resources about this project here: [Forums] [GitHub]
"},{"location":"community_articles.html#hackster-seeed-studios-local-voice-chatbot-puts-a-speech-recognizing-llama-2-llm-on-your-jetson-2-7-2024","title":"Hackster Seeed Studio's Local Voice Chatbot Puts a Speech-Recognizing LLaMa-2 LLM on Your Jetson (2-7-2024)","text":"
Seeed Studio has announced the launch of the Local Voice Chatbot, an NVIDIA Riva- and LLaMa-2-based large language model (LLM) chatbot with voice recognition capabilities \u2014 running entirely locally on NVIDIA Jetson devices, including the company's own reComputer range. Follow the step-by-step guide on the Seeed Studio wiki.
"},{"location":"community_articles.html#youtube-genai-nerds-react-insider-look-at-nvidias-newest-generative-ai-2-6-2024","title":"YouTube GenAI Nerds React - Insider Look at NVIDIA's Newest Generative AI (2-6-2024)","text":"
Watch this panel about the latest trends & tech in edge AI, featuring Kerry Shih from OStream, Jim Benson from JetsonHacks, and Dusty from NVIDIA.
"},{"location":"community_articles.html#nvidia-bringing-generative-ai-to-life-with-nvidia-jetson-11-7-2023","title":"NVIDIA Bringing Generative AI to Life with NVIDIA Jetson (11-7-2023)","text":"
Watch this webinar about deploying LLMs, VLMs, ViTs, and vector databases onboard Jetson Orin for building next-generation applications using Generative AI:
"},{"location":"community_articles.html#jetsonhacks-jetson-ai-labs-generative-ai-playground-10-31-2023","title":"JetsonHacks Jetson AI Labs \u2013 Generative AI Playground (10-31-2023)","text":"
JetsonHacks publishes an insightful video that walks developers through the typical steps for running generative AI models on Jetson following this site's tutorials. The video shows the interaction with the LLaVA model.
"},{"location":"community_articles.html#hackster-vision2audio-giving-the-blind-an-understanding-through-ai-10-15-2023","title":"Hackster Vision2Audio - Giving the blind an understanding through AI (10-15-2023)","text":"
Nurgaliyev Shakhizat demonstrates Vision2Audio running on Jetson AGX Orin 64GB Developer Kit to harness the power of LLaVA to help visually impaired people:
"},{"location":"community_articles.html#nvidia-generative-ai-models-at-the-edge-10-19-2023","title":"NVIDIA Generative AI Models at the Edge (10-19-2023)","text":"
Follow this walkthrough of the Jetson AI Lab tutorials along with coverage of the latest features and advances coming to JetPack 6 and beyond:
\u00a0 Technical Blog - https://developer.nvidia.com/blog/bringing-generative-ai-to-life-with-jetson/
"},{"location":"community_articles.html#medium-how-to-set-up-your-jetson-device-for-llm-inference-and-fine-tuning-10-02-2023","title":"Medium How to set up your Jetson device for LLM inference and fine-tuning (10-02-2023)","text":"
Michael Yuan's guide demonstrating how to set up the Jetson AGX Orin 64GB Developer Kit specifically for large language model (LLM) inference, highlighting the crucial role of GPUs and the cost-effectiveness of the Jetson AGX Orin for LLM tasks.
"},{"location":"community_articles.html#hackster-getting-started-with-ai-on-nvidia-jetson-agx-orin-dev-kit-09-16-2023","title":"Hackster Getting Started with AI on Nvidia Jetson AGX Orin Dev Kit (09-16-2023)","text":"
Nurgaliyev Shakhizat demonstrates llamaspeak on Jetson AGX Orin 64GB Developer Kit in this Hackster post:
"},{"location":"community_articles.html#hackster-new-ai-tool-is-generating-a-lot-of-buzz-09-13-2023","title":"Hackster New AI Tool Is Generating a Lot of Buzz (09-13-2023)","text":"
Nick Bild provides an insightful introduction to the Jetson Generative AI Playground:
"},{"location":"community_articles.html#jetsonhacks-use-these-jetson-docker-containers-tutorial-09-04-2023","title":"JetsonHacks Use These! Jetson Docker Containers Tutorial (09-04-2023)","text":"
JetsonHacks has a in-depth tutorial on how to use jetson-containers and even show text-generation-webui and stable-diffusion-webui containers in action!
"},{"location":"community_articles.html#hackster-llama-2-llms-w-nvidia-jetson-and-textgeneration-web-ui-08-17-2023","title":"Hackster LLaMa 2 LLMs w/ NVIDIA Jetson and textgeneration-web-ui (08-17-2023)","text":"
Paul DeCarlo demonstrates 13B and 70B parameter LLama 2 models running locally on Jetson AGX Orin 64GB Developer Kit in this Hackster post:
"},{"location":"community_articles.html#hackster-running-a-chatgpt-like-llm-llama2-on-a-nvidia-jetson-cluster-08-14-2023","title":"Hackster Running a ChatGPT-Like LLM-LLaMA2 on a Nvidia Jetson Cluster (08-14-2023)","text":"
Discover how to run a LLaMA-2 7B model on an NVIDIA Jetson cluster in this insightful tutorial by Nurgaliyev Shakhizat:
"},{"location":"community_articles.html#jetsonhacks-speech-ai-on-nvidia-jetson-tutorial-08-07-2023","title":"JetsonHacks Speech AI on NVIDIA Jetson Tutorial (08-07-2023)","text":"
JetsonHacks gives a nice introduction to NVIDIA RIVA SDK and demonstrate its automated speech recognition (ASR) capability on Jetson Orin Nano Developer Kit.
"},{"location":"community_articles.html#hackster-llm-based-multimodal-ai-w-azure-open-ai-nvidia-jetson-07-12-2023","title":"Hackster LLM based Multimodal AI w/ Azure Open AI & NVIDIA Jetson (07-12-2023)","text":"
Learn how to harness the power of Multimodal AI by running Microsoft JARVIS on an Jetson AGX Orin 64GB Developer Kit, enabling a wide range of AI tasks with ChatGPT-like capabilities, image generation, and more, in this comprehensive guide by Paul DeCarlo.
"},{"location":"community_articles.html#hackster-how-to-run-a-chatgpt-like-llm-on-nvidia-jetson-board-06-13-2023","title":"Hackster How to Run a ChatGPT-Like LLM on NVIDIA Jetson board (06-13-2023)","text":"
Nurgaliyev Shakhizat explores voice AI assistant on Jetson using FastChat and VoskAPI.
"},{"location":"getting-started.html","title":"Getting started","text":""},{"location":"hello_ai_world.html","title":"Hello AI World","text":"
Hello AI World is an in-depth tutorial series for DNN-based inference and training of image classification, object detection, semantic segmentation, and more. It is built on the jetson-inference library using TensorRT for optimized performance on Jetson.
It's highly recommended to familiarize yourself with the concepts of machine learning and computer vision before diving into the more advanced topics of generative AI here on the Jetson AI Lab. Many of these models will prove useful to have during your development.
HELLO AI WORLD >> https://github.com/dusty-nv/jetson-inference
"},{"location":"research.html","title":"Jetson AI Lab Research Group","text":"
The Jetson AI Lab Research Group is a global collective for advancing open-source Edge ML, open to anyone to join and collaborate with others from the community and leverage each other's work. Our goal is using advanced AI for good in real-world applications in accessible and responsible ways. By coordinating together as a group, we can keep up with the rapidly evolving pace of AI and more quickly arrive at deploying intelligent multimodal agents and autonomous robots into the field.
There are virtual meetings that anyone is welcome to join, offline discussion on the Jetson Projects forum, and guidelines for upstreaming open-source contributions.
Next Meeting - 5/1
The next team meeting is on Wednesday, May 1st at 9am PST. View the recording from the last meeting below.
"},{"location":"research.html#topics-of-interest","title":"Topics of Interest","text":"
These are some initial research topics for us to discuss and investigate. This list will vary over time as experiments evolve and the SOTA progresses:
\u2022 Controller LLMs for dynamic pipeline code generation \u2022 Fine-tuning LLM/VLM onboard Jetson AGX Orin 64GB \u2022 HomeAssistant.io integration for smart home [1] [2] \u2022 Continuous multi-image VLM streaming and change detection \u2022 Recurrent LLM architectures (Mamba, RKVW, ect) [1] \u2022 Lightweight low-memory streaming ASR/TTS models \u2022 Diffusion models for image processing and enhancement \u2022 Time Series Forecasting with Transformers [1] [2] \u2022 Guidance, grammars, and guardrails for constrained output \u2022 Inline LLM function calling / plugins from API definitions \u2022 ML DevOps, edge deployment, and orchestration \u2022 Robotics, IoT, and cyberphysical systems integration
New topics can be raised to the group either during the meetings or on the forums (people are welcome to work on whatever they want of course)
When experiments are successful, ideally the results will be packaged in such a way that they are easily reusable for others to integrate into their own projects:
Open-source libraries & code on GitHub
Models on HuggingFace Hub
Containers provided by jetson-containers
Discussions on the Jetson Projects forum
Documentation & tutorials on Jetson AI Lab
Hackster.io for hardware-centric builds
Ongoing technical discussions are encouraged to occur on the forums or GitHub Issues, with status updates on projects given during the meetings.
We'll aim to meet monthly or bi-weekly as a team in virtual meetings that anyone is welcome to join and speak during. We'll discuss the latest updates and experiments that we want to explore. Please remain courteous to others during the calls. We'll stick around after for anyone who has questions or didn't get the chance to be heard.
Wednesday, May 1 at 9am PST (5/1/24)
Teams Invite and Agenda will be posted here.
The agenda will be posted beforehand. Post to the forum to add agenda items. The meetings will be recorded so anyone unable to attend live can watch them after.
Below are shown some of the sustaining members of the group who have been working on generative AI in edge computing:
Dustin Franklin, NVIDIA Principal Engineer | Pittsburgh, PA (jetson-inference, jetson-containers) Nurgaliyev Shakhizat Institute of Smart Systems and AI | Kazakhstan (Assistive Devices, Vision2Audio, HPEC Clusters) Kris Kersey, Kersey Fabrications Embedded Software Engineer | Atlanta, GA (The OASIS Project, AR/VR, 3D Fabrication) Johnny N\u00fa\u00f1ez Cano PhD Researcher in CV/AI | Barcelona, Spain (Recurrent LLMs, Pose & Behavior Analysis) Doruk S\u00f6nmez, Open Zeka Intelligent Video Analytics Engineer | Turkey (NVIDIA DLI Certified Instructor, IVA, VLM) Akash James, Spark Cognition AI Architect, UC Berkeley Researcher | Oakland (NVIDIA AI Ambassador, Personal Assistants) Mieszko Syty, MS/1 Design AI/ML Engineer | Warsaw, Poland (LLM, Home Assistants, ML DevOps) Jim Benson, JetsonHacks DIY Extraordinaire | Los Angeles, CA (AI in Education, RACECAR/J) Chitoku Yato, NVIDIA Jetson AI DevTech | Santa Clara, CA (JetBot, JetRacer, MinDisk, Containers) Dana Sheahen, NVIDIA DLI Curriculum Developer | Santa Clara, CA (AI in Education, Jetson AI Fundamentals) Sammy Ochoa, NVIDIA Jetson AI DevTech | Austin, TX (Metropolis Microservices) John Welsh, NVIDIA (NanoOWL, NanoSAM, JetBot, JetRacer, torch2trt, trt_pose, Knowledge Distillation) Dave Niewinski Dave's Armoury | Waterloo, Ontario (GLaDOS, Fetch, Offroad La-Z-Boy, KUKA Bot) Gary Hilgemann, REBOTNIX CEO & AI Roboticist | L\u00fcnen, Germany (GUSTAV, SPIKE, VisionTools, GenAI) Elaine Wu, Seeed Studio AI & Robotics Partnerships | Shenzhen, China (reComputer, YOLOv8, LocalJARVIS, Voice Bot) Patty Delafuente, NVIDIA Data Scientist & UMBC PhD Student | MD (AI in Education, DLI Robotics Teaching Kit) Song Han, MIT HAN Lab NVIDIA Research | Cambridge, MA (Efficient Large Models, AWQ, VILA) Bryan Hughes, Mimzy AI Founder, Entrepreneur | SF Bay Area (Multimodal Assistants, AI at the Edge) Tianqi Chen, CMU Catalyst OctoML, CTO | Seattle, WA (MLC, Apache TVM, XGBoost) Michael Gr\u00fcner, RidgeRun Team Lead / Architect | Costa Rica (Embedded Vision & AI, Multimedia) Jesse Flot, CMU Robotics Academy Co-Director | Pittsburgh, PA (Applied AI & Robotics, Autonomy Foundations) Paul DeCarlo, Microsoft Professor | University of Houston (Azure IoT, Video Analytics, Microsoft JARVIS) Mike Hansen, Nabu Casa Voice Engineering Lead | Urbandale, Iowa (Home Assistant, Piper TTS, Wyoming) Lakshantha Dissanayake, Ultralytics Embedded CV Engineer | Vancouver, BC (YOLOv8, TensorRT, DeepStream) Kerry Shih, OStream Founder, CEO | Los Angeles, CA (GenRunner, GenAI Nerds) Ziad Youssfi, CMU ECE Professor | Pittsburgh, PA (ML in Robotics & Embedded Systems) Walter Lucetti, Stereolabs Robotics & Vision Engineer | Paris, France (MyzharBot, ROS2, GStreamer) Raffaello Bonghi, NVIDIA AI & Robotics Engineer | Manchester, UK (Nanosaur, Panther, jetson-stats)"},{"location":"tips_ram-optimization.html","title":"RAM Optimization","text":"
Running a LLM requires a huge RAM space.
Especially if you are on Jetson Orin Nano that only has 8GB of RAM, it is crucial to leave as much RAM space available for models.
Here we share a couple of ways to optimize the system RAM usage.
"},{"location":"tips_ram-optimization.html#disabling-the-desktop-gui","title":"Disabling the Desktop GUI","text":"
If you use your Jetson remotely through SSH, you can disable the Ubuntu desktop GUI. This will free up extra memory that the window manager and desktop uses (around ~800MB for Unity/GNOME).
You can disable the desktop temporarily, run commands in the console, and then re-start the desktop when desired:
$ sudo init 3 # stop the desktop\n# log your user back into the console (Ctrl+Alt+F1, F2, ect)\n$ sudo init 5 # restart the desktop\n
If you wish to make this persistent across reboots, you can use the following commands to change the boot-up behavior:
If you're building containers or working with large models, it's advisable to mount SWAP (typically correlated with the amount of memory in the board). Run these commands to disable ZRAM and create a swap file:
If you have NVMe SSD storage available, it's preferred to allocate the swap file on the NVMe SSD.
Once you have your Jetson set up by flashing the latest Jetson Linux (L4T) BSP on it or by flashing the SD card with the whole JetPack image, before embarking on testing out all the great generative AI application using jetson-containers, you want to make sure you have a huge storage space for all the containers and the models you will download.
We are going to show how you can install SSD on your Jetson, and set it up for Docker.
Unplug power and any peripherals from the Jetson developer kit.
Physically install an NVMe SSD card on the carrier board of your Jetson developer kit, making sure to properly seat the connector and secure with the screw.
Reconnect any peripherals, and then reconnect the power supply to turn on the Jetson developer kit.
Once the system is up, verify that your Jetson identifies a new memory controller on PCI bus:
Note: If you used an NVIDIA-supplied SD card image to flash your SD card, all necessary JetPack components (including nvidia-containers) and Docker are already pre-installed, so this step can be skipped.
If you flash Jetson Linux (L4T) R36.2 (JetPack 6.0 DP) on your Jetson using SDK Manager, and install nvidia-container using apt, on JetPack 6.0 it no longer automatically installs Docker.
Therefore, you need to run the following to manually install Docker and set it up.
Our tutorials are divided into categories roughly based on model modality, the type of data to be processed or generated.
"},{"location":"tutorial-intro.html#text-llm","title":"Text (LLM)","text":"text-generation-webui Interact with a local AI assistant by running a LLM with oobabooga's text-generaton-webui llamaspeak Talk live with Llama using Riva ASR/TTS, and chat about images with Llava! Small LLM (SLM) Deploy Small Language Models (SLM) with reduced memory usage and higher throughput. API Examples Learn how to write Python code for doing LLM inference using popular APIs."},{"location":"tutorial-intro.html#text-vision-vlm","title":"Text + Vision (VLM)","text":"
Give your locally running LLM an access to vision!
Mini-GPT4 Mini-GPT4, an open-source model that demonstrate vision-language capabilities. LLaVA Large Language and Vision Assistant, multimodal model that combines a vision encoder and LLM for visual and language understanding. Live LLaVA Run multimodal models interactively on live video streams over a repeating set of prompts. NanoVLM Use mini vision/language models and the optimized multimodal pipeline for live streaming."},{"location":"tutorial-intro.html#image-generation","title":"Image Generation","text":"Stable Diffusion Run AUTOMATIC1111's stable-diffusion-webui to generate images from prompts Stable Diffusion XL A newer ensemble pipeline consisting of a base model and refiner that results in significantly enhanced and detailed image generation capabilities."},{"location":"tutorial-intro.html#vision-transformers-vit","title":"Vision Transformers (ViT)","text":"EfficientVIT MIT Han Lab's EfficientViT, Multi-Scale Linear Attention for High-Resolution Dense Prediction NanoOWL OWL-ViT optimized to run real-time on Jetson with NVIDIA TensorRT NanoSAM NanoSAM, SAM model variant capable of running in real-time on Jetson SAM Meta's SAM, Segment Anything model TAM TAM, Track-Anything model, is an interactive tool for video object tracking and segmentation"},{"location":"tutorial-intro.html#vector-database","title":"Vector Database","text":"NanoDB Interactive demo to witness the impact of Vector Database that handles multimodal data"},{"location":"tutorial-intro.html#audio","title":"Audio","text":"AudioCraft Meta's AudioCraft, to produce high-quality audio and music Whisper OpenAI's Whisper, pre-trained model for automatic speech recognition (ASR)"},{"location":"tutorial-intro.html#metropolis-microservices","title":"Metropolis Microservices","text":"First Steps Get Metropolis Microservices up & running on Jetson with NVStreamer and AI NVR capabilities."},{"location":"tutorial-intro.html#about-nvidia-jetson","title":"About NVIDIA Jetson","text":"
Note
We are mainly targeting Jetson Orin generation devices for deploying the latest LLMs and generative AI models.
Jetson AGX Orin 64GB Developer Kit Jetson AGX Orin Developer Kit Jetson Orin Nano Developer Kit GPU 2048-core NVIDIA Ampere architecture GPU with 64 Tensor Cores 1024-core NVIDIA Ampere architecture GPU with 32 Tensor Cores RAM(CPU+GPU) 64GB 32GB 8GB Storage 64GB eMMC (+ NVMe SSD) microSD card (+ NVMe SSD)"},{"location":"tutorial_api-examples.html","title":"Tutorial - API Examples","text":"
It's good to know the code for generating text with LLM inference, and ancillary things like tokenization, chat templates, and prompting. On this page we give Python examples of running various LLM APIs, and their benchmarks.
What you need
One of the following Jetson devices:
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB) Jetson Orin NX (16GB) Jetson Orin Nano (8GB)\u26a0\ufe0f
Running one of the following versions of JetPack:
JetPack 5 (L4T r35) JetPack 6 (L4T r36)
Sufficient storage space (preferably with NVMe SSD).
The HuggingFace Transformers API is the de-facto API that models are released for, often serving as the reference implementation. It's not terribly fast, but it does have broad model support, and also supports quantization (AutoGPTQ, AWQ). This uses streaming:
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer\nfrom threading import Thread\n\nmodel_name='meta-llama/Llama-2-7b-chat-hf'\nmodel = AutoModelForCausalLM.from_pretrained(model_name, device_map='cuda')\n\ntokenizer = AutoTokenizer.from_pretrained(model_name)\nstreamer = TextIteratorStreamer(tokenizer)\n\nprompt = [{'role': 'user', 'content': 'Can I get a recipe for French Onion soup?'}]\ninputs = tokenizer.apply_chat_template(\n prompt,\n add_generation_prompt=True,\n return_tensors='pt'\n).to(model.device)\n\nThread(target=lambda: model.generate(inputs, max_new_tokens=256, streamer=streamer)).start()\n\nfor text in streamer:\n print(text, end='', flush=True)\n
To run this (it can be found here), you can mount a directory containing the script or your jetson-containers directory:
jetson-containers run --volume $PWD/packages/llm:/mount --workdir /mount \\\n$(autotag l4t-text-generation) \\\npython3 transformers/test.py\n
We use the l4t-text-generation container because it includes the quantization libraries in addition to Transformers, for running the quanztized versions of the models like TheBloke/Llama-2-7B-Chat-GPTQ
"},{"location":"tutorial_live-llava.html","title":"Tutorial - Live LLaVA","text":"
Recommended
Follow the chat-based LLaVA and NanoVLM tutorials to familiarize yourself with vision/language models and test the models first.
This multimodal agent runs a vision-language model on a live camera feed or video stream, repeatedly applying the same prompts to it:
It uses models like LLaVA or VILA (based on Llama and CLIP) and has been quantized with 4-bit precision to be deployed on Jetson Orin. This runs an optimized multimodal pipeline from the NanoLLM library, including event filters and alerts, and multimodal RAG:
"},{"location":"tutorial_live-llava.html#running-the-live-llava-demo","title":"Running the Live Llava Demo","text":"
What you need
One of the following Jetson devices:
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB) Jetson Orin NX (16GB) Jetson Orin Nano (8GB)\u26a0\ufe0f
Running one of the following versions of JetPack:
JetPack 6 (L4T r36.x)
Sufficient storage space (preferably with NVMe SSD).
22GB for nano_llm container image
Space for models (>10GB)
Follow the chat-based LLaVA and NanoVLM tutorials first.
VILA-2.7b, VILA-7b, Llava-7b, and Obsidian-3B can run on Orin Nano 8GB
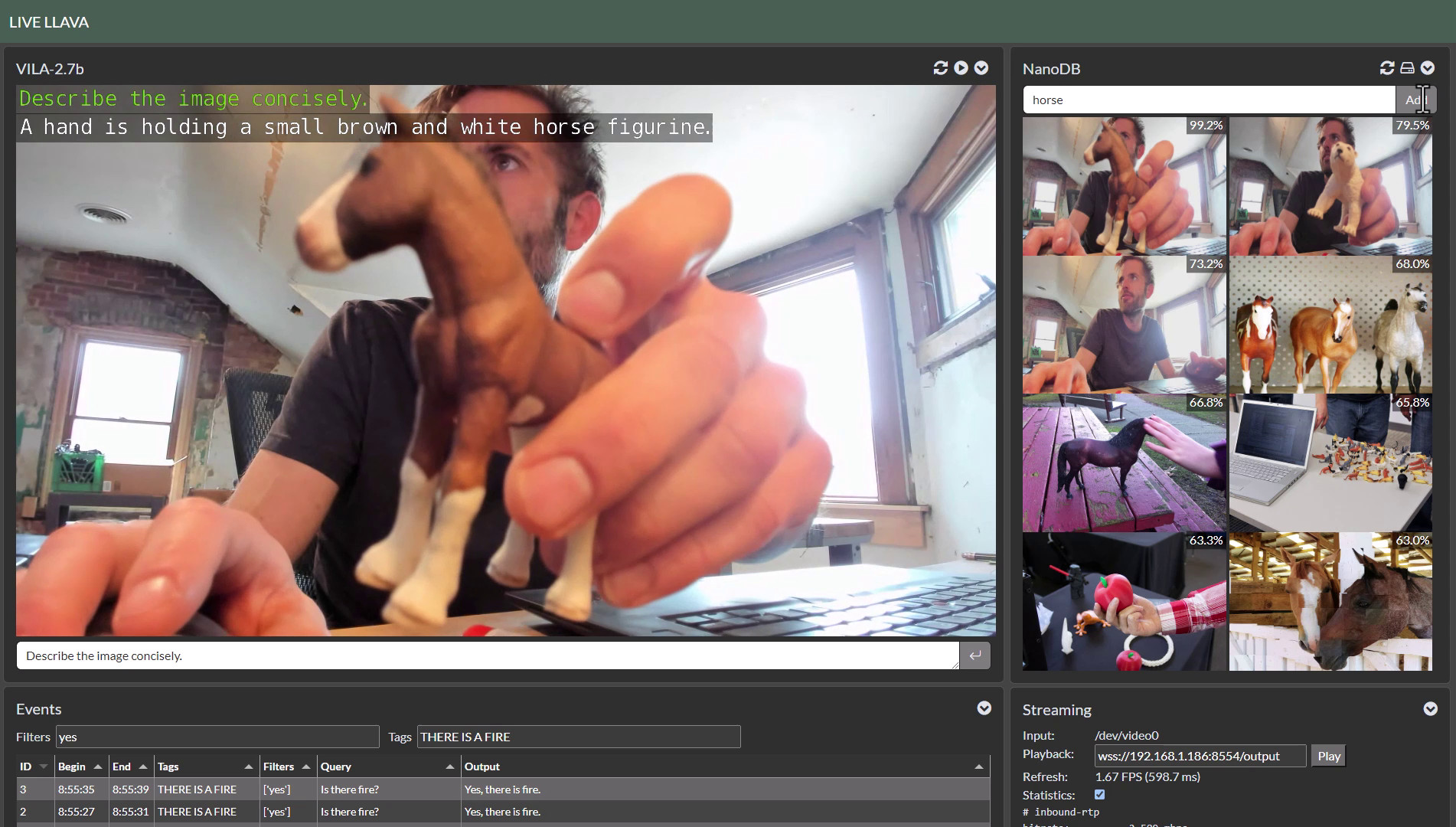
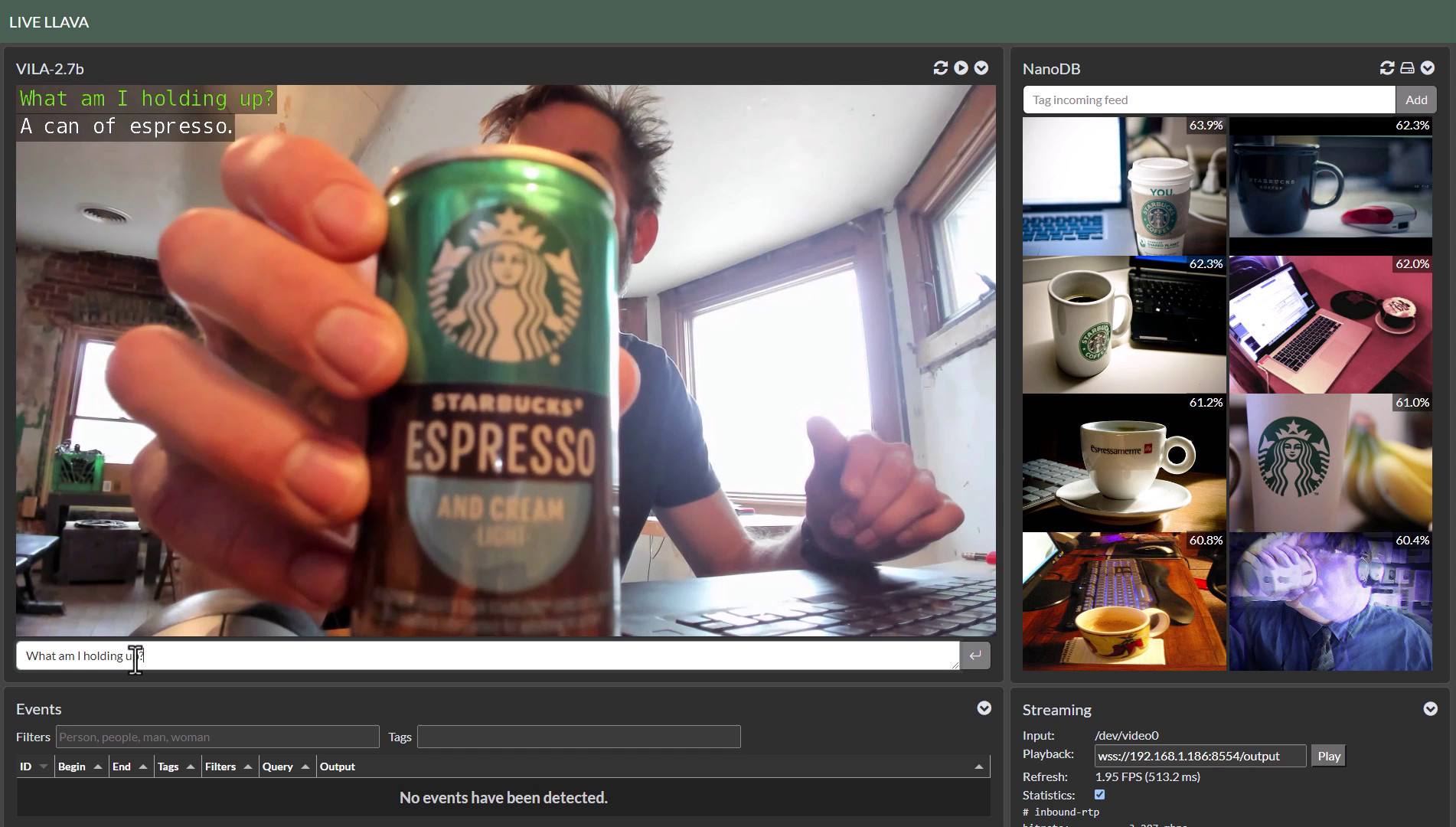
The VideoQuery agent applies prompts to the incoming video feed with the VLM. Navigate your browser to https://<IP_ADDRESS>:8050 after launching it with your camera (Chrome is recommended with chrome://flags#enable-webrtc-hide-local-ips-with-mdns disabled)
This uses jetson_utils for video I/O, and for options related to protocols and file formats, see Camera Streaming and Multimedia. In the example above, it captures a V4L2 USB webcam connected to the Jetson (under the device /dev/video0) and outputs a WebRTC stream.
"},{"location":"tutorial_live-llava.html#processing-a-video-file-or-stream","title":"Processing a Video File or Stream","text":"
The example above was running on a live camera, but you can also read and write a video file or network stream by substituting the path or URL to the --video-input and --video-output command-line arguments like this:
jetson-containers run \\\n-v /path/to/your/videos:/mount\n $(autotag nano_llm) \\\npython3 -m nano_llm.agents.video_query --api=mlc \\\n--model Efficient-Large-Model/VILA-2.7b \\\n--max-new-tokens 32 \\\n--video-input /mount/my_video.mp4 \\\n--video-output /mount/output.mp4 \\\n--prompt \"What does the weather look like?\"\n
This example processes and pre-recorded video (in MP4, MKV, AVI, FLV formats with H.264/H.265 encoding), but it also can input/output live network streams like RTP, RTSP, and WebRTC using Jetson's hardware-accelerated video codecs.
If you launch the VideoQuery agent with the --nanodb flag along with a path to your NanoDB database, it will perform reverse-image search on the incoming feed against the database by re-using the CLIP embeddings generated by the VLM.
To enable this mode, first follow the NanoDB tutorial to download, index, and test the database. Then launch VideoQuery like this:
LLaVA is a popular multimodal vision/language model that you can run locally on Jetson to answer questions about image prompts and queries. Llava uses the CLIP vision encoder to transform images into the same embedding space as its LLM (which is the same as Llama architecture). Below we cover different methods to run Llava on Jetson, with increasingly optimized performance:
Go to Chat tab, drag and drop an image into the Drop Image Here area, and your question in the text area and hit Generate:
"},{"location":"tutorial_llava.html#result","title":"Result","text":""},{"location":"tutorial_llava.html#2-run-from-the-terminal-with-llavaservecli","title":"2. Run from the terminal with llava.serve.cli","text":"
What you need
One of the following Jetson:
Jetson AGX Orin 64GB Jetson AGX Orin (32GB)
Running one of the following versions of JetPack:
JetPack 5 (L4T r35.x) JetPack 6 (L4T r36.x)
Sufficient storage space (preferably with NVMe SSD).
6.1GB for llava container
14GB for Llava-7B (or 26GB for Llava-13B)
This example uses the upstream Llava repo to run the original, unquantized Llava models from the command-line. It uses more memory due to using FP16 precision, and is provided mostly as a reference for debugging. See the Llava container readme for more info.
Unquantized 13B may run only on Jetson AGX Orin 64GB due to memory requirements.
"},{"location":"tutorial_llava.html#3-quantized-gguf-models-with-llamacpp","title":"3. Quantized GGUF models with llama.cpp","text":"
What you need
One of the following Jetson devices:
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB) Jetson Orin NX (16GB)
Running one of the following versions of JetPack:
JetPack 5 (L4T r35.x) JetPack 6 (L4T r36.x)
llama.cpp is one of the faster LLM API's, and can apply a variety of quantization methods to Llava to reduce its memory usage and runtime. Despite its name, it uses CUDA. There are pre-quantized versions of Llava-1.5 available in GGUF format for 4-bit and 5-bit:
mys/ggml_llava-v1.5-7b
mys/ggml_llava-v1.5-13b
jetson-containers run --workdir=/opt/llama.cpp/bin $(autotag llama_cpp:gguf) \\\n/bin/bash -c './llava-cli \\\n --model $(huggingface-downloader mys/ggml_llava-v1.5-13b/ggml-model-q4_k.gguf) \\\n --mmproj $(huggingface-downloader mys/ggml_llava-v1.5-13b/mmproj-model-f16.gguf) \\\n --n-gpu-layers 999 \\\n --image /data/images/hoover.jpg \\\n --prompt \"What does the sign say\"'\n
Quantization Bits Response Tokens/sec Memory Q4_K 4 The sign says \"Hoover Dam, Exit 9.\" 10.17 9.2 GB Q5_K 5 The sign says \"Hoover Dam exit 9.\" 9.73 10.4 GB
A lower temperature like 0.1 is recommended for better quality (--temp 0.1), and if you omit --prompt it will describe the image:
jetson-containers run --workdir=/opt/llama.cpp/bin $(autotag llama_cpp:gguf) \\\n/bin/bash -c './llava-cli \\\n --model $(huggingface-downloader mys/ggml_llava-v1.5-13b/ggml-model-q4_k.gguf) \\\n --mmproj $(huggingface-downloader mys/ggml_llava-v1.5-13b/mmproj-model-f16.gguf) \\\n --n-gpu-layers 999 \\\n --image /data/images/lake.jpg'\n\nIn this image, a small wooden pier extends out into a calm lake, surrounded by tall trees and mountains. The pier seems to be the only access point to the lake. The serene scene includes a few boats scattered across the water, with one near the pier and the others further away. The overall atmosphere suggests a peaceful and tranquil setting, perfect for relaxation and enjoying nature.\n
You can put your own images in the mounted jetson-containers/data directory. The C++ code for llava-cli can be found here. The llama-cpp-python bindings also support Llava, however they are significantly slower from Python for some reason (potentially pre-processing)
"},{"location":"tutorial_llava.html#4-optimized-multimodal-pipeline-with-nanovlm","title":"4. Optimized Multimodal Pipeline with NanoVLM","text":"
What's Next
This section got too long and was moved to the NanoVLM page - check it out there for performance optimizations, mini VLMs, and live streaming!
17# First steps with Metropolis Microservices for Jetson
NVIDIA Metropolis Microservices for Jetson simplifies the development of vision AI applications, offering a suite of customizable, cloud-native tools. Before diving into this tutorial, ensure you've filled out the Metropolis Microservices for Jetson Early Access form to gain the necessary access to launch the services. This step is crucial as it enables you to utilize all the features and capabilities discussed in this guide.
Perfect for both newcomers and experts, this tutorial provides straightforward steps to kick-start your edge AI projects. Whether you're a student or an ecosystem partner working on a use case, this guide offers a straightforward start for every skill level.
Ok, let's start by installing NVIDIA Jetson Services:
sudo apt install nvidia-jetson-services\n
Let's add some performance hacks that will be needed to run the demo faster and without streaming artifacts:
If you don't have the Orin at max performance, you can use these two commands, a reboot is needed after:
sudo nvpmodel -m 0 \nsudo jetson_clocks\n
After these two commands, a reboot is needed if your Jetson wasn't already in high-performance mode. These are optional, but they fine-tune your network buffers to ensure smoother streaming by optimizing how much data can be sent and received:
Here it will ask for your API Key, and the organization name, to get those you need to login into NGC and generate an API key here.
You should then paste the API key and use the organization name you are using. You can also press [Enter] to select the default values for the remaining options. After this, you should get the message:
Successfully saved NGC configuration to /home/jetson/.ngc/config\n
"},{"location":"tutorial_mmj.html#2-download-and-launch-nvstreamer","title":"2. Download and launch NVStreamer","text":""},{"location":"tutorial_mmj.html#_1","title":"First Steps","text":"
First, we need to install NVStreamer, an app that streams the videos MMJs will need to run AI on them. Follow this NVStreamer Link (In the top-left, click Download files.zip)
"},{"location":"tutorial_mmj.html#4-download-some-sample-videos-and-upload-them-to-nvstreamer","title":"4. Download some sample videos and upload them to NVStreamer","text":"
Download them from here.
unzip files.zip\n
Ok, now, this is important to understand, there are 2 web interfaces:
The NVStream Streamer Dashboard, running in: http://localhost:31000
The NVStreamer Camera Management Dashboard, running in: http://localhost:31000
So, first we need to upload the file in the Streamer interface, it looks like this:
There, go to File Upload, and drag and drop the file in the upload squared area.
After uploading it, go to the Dashboad option of the left menu, and copy the RTSP URL of the video you just uploaded, you will need it for the Camera Management Dashboard.
Now jump to the Camera Management Dashboard (http://localhost:30080/vst), it looks like this:
Go to the Camera Management option of the menu, then use the Add device manually option, and paste the RTSP URL, add the name of your video to the Name and Location text boxes, so it will be displayed on top of the stream.
Finally, click in the Live Streams option of the left menu, and you should be able to watch your video stream.
"},{"location":"tutorial_mmj.html#5-watch-rtsp-ai-processed-streaming-from-vlc","title":"5. Watch RTSP AI processed streaming from VLC","text":"
Open VLC from another computer (localhost doesn't work here), and point to your Jetson Orin's IP address (you should be in the same network, or not having a firewal to access).
The easiest way to get Jetson's ip is launching:
ifconfig\n
And checking the IP of the interface (usually wlan0, inet IP).
Then go to rtsp://[JETSON_IP]:8555/ds-test using VLC like this:
NanoLLM is a lightweight, high-performance library using optimized inferencing APIs for quantized LLM\u2019s, multimodality, speech services, vector databases with RAG, and web frontends. It's used to build many of the responsive, low-latency agents featured on this site.
It provides similar APIs to HuggingFace, backed by highly-optimized inference libraries and quantization tools:
from nano_llm import NanoLLM\n\nmodel = NanoLLM.from_pretrained(\n \"meta-llama/Llama-2-7b-hf\", # HuggingFace repo/model name, or path to HF model checkpoint\n api='mlc', # supported APIs are: mlc, awq, hf\n api_token='hf_abc123def', # HuggingFace API key for authenticated models ($HUGGINGFACE_TOKEN)\n quantization='q4f16_ft' # q4f16_ft, q4f16_1, q8f16_0 for MLC, or path to AWQ weights\n)\n\nresponse = model.generate(\"Once upon a time,\", max_new_tokens=128)\n\nfor token in response:\n print(token, end='', flush=True)\n
Here's an index of the various tutorials & examples using NanoLLM on Jetson AI Lab:
Benchmarks Benchmarking results for LLM, SLM, VLM using MLC/TVM backend API Examples Python code examples for completion and multi-turn chat Llamaspeak Talk verbally with LLMs using low-latency ASR/TTS speech models Small LLM (SLM) Focus on language models with reduced footprint (7B params and below) Live LLaVA Realtime live-streaming vision/language models on recurring prompts Nano VLM Efficient multimodal pipeline with one-shot RAG support"},{"location":"tutorial_nano-vlm.html","title":"NanoVLM - Efficient Multimodal Pipeline","text":"
We saw in the previous LLaVA tutorial how to run vision-language models through tools like text-generation-webui and llama.cpp. In a similar vein to the SLM page on Small Language Models, here we'll explore optimizing VLMs for reduced memory usage and higher performance that reaches interactive levels (like in Liva LLava). These are great for fitting on Orin Nano and increasing the framerate.
There are 3 model families currently supported: Llava, VILA, and Obsidian (mini VLM)
This FPS measures the end-to-end pipeline performance for continuous streaming like with Live Llava (on yes/no question)
\u2022 \u00a0 These models all use CLIP ViT-L/14@336px for the vision encoder. \u2022 \u00a0 Jetson Orin Nano 8GB runs out of memory trying to run Llava-13B.
VILA-2.7b, VILA-7b, Llava-7b, and Obsidian-3B can run on Orin Nano 8GB
The optimized NanoLLM library uses MLC/TVM for quantization and inference provides the highest performance. It efficiently manages the CLIP embeddings and KV cache. You can find Python code for the chat program used in this example here.
This starts an interactive console-based chat with Llava, and on the first run the model will automatically be downloaded from HuggingFace and quantized using MLC and W4A16 precision (which can take some time). See here for command-line options.
You'll end up at a >> PROMPT: in which you can enter the path or URL of an image file, followed by your question about the image. You can follow-up with multiple questions about the same image. Llava does not understand multiple images in the same chat, so when changing images, first reset the chat history by entering clear or reset as the prompt. VILA supports multiple images (area of active research)
\u2022 \u00a0 The model responses are with 4-bit quantization enabled, and are truncated to 128 tokens for brevity. \u2022 \u00a0 These chat questions and images are from /data/prompts/images.json (found in jetson-containers)
When prompted, these models can also output in constrained JSON formats (which the LLaVA authors cover in their LLaVA-1.5 paper), and can be used to programatically query information about the image:
jetson-containers run $(autotag nano_llm) \\\n python3 -m nano_llm.chat --api=mlc \\\n --model liuhaotian/llava-v1.5-13b \\\n --prompt '/data/images/hoover.jpg' \\\n --prompt 'extract any text from the image as json'\n\n{\n \"sign\": \"Hoover Dam\",\n \"exit\": \"2\",\n \"distance\": \"1 1/2 mile\"\n}\n
"},{"location":"tutorial_nanodb.html#how-to-start","title":"How to start","text":""},{"location":"tutorial_nanodb.html#download-coco","title":"Download COCO","text":"
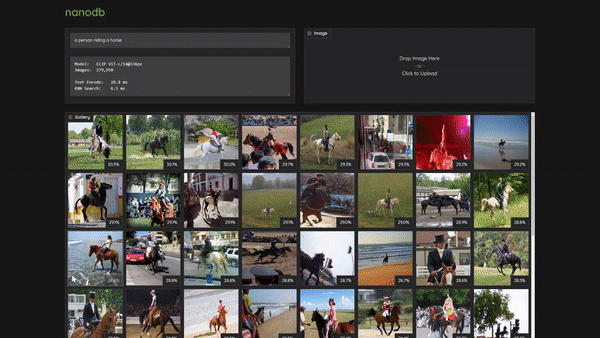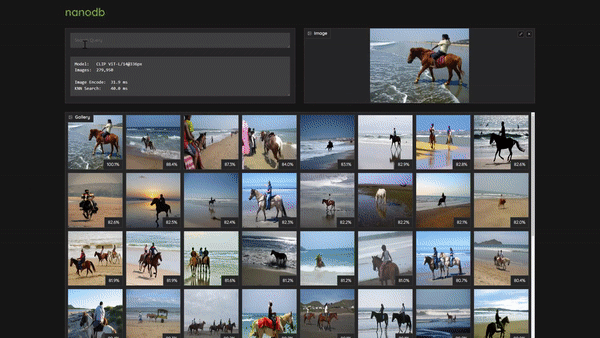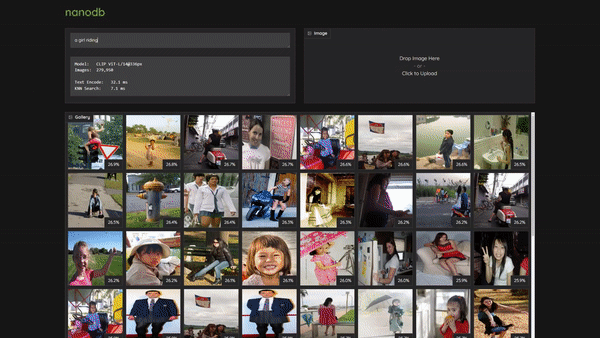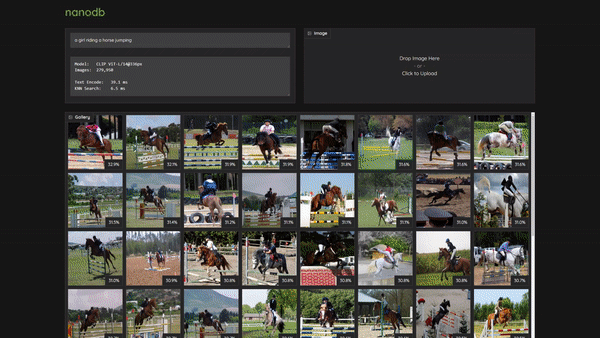
This will take a few hours on AGX Orin. Once the database has loaded and completed any start-up operations , it will drop down to a > prompt from which the user can run search queries. You can quickly check the operation by typing your query on this prompt:
Then navigate your browser to http://<IP_ADDRESS>:7860, and you can enter text search queries as well as drag/upload images:
To use the dark theme, navigate to http://<IP_ADDRESS>:7860/?__theme=dark instead"},{"location":"tutorial_slm.html","title":"Tutorial - Small Language Models (SLM)","text":"
Small Language Models (SLMs) represent a growing class of language models that have <7B parameters - for example StableLM, Phi-2, and Gemma-2B. Their smaller memory footprint and faster performance make them good candidates for deploying on Jetson Orin Nano. Some are very capable with abilities at a similar level as the larger models, having been trained on high-quality curated datasets.
This tutorial shows how to run optimized SLMs with quantization using the NanoLLM library and MLC/TVM backend. You can run these models through tools like text-generation-webui and llama.cpp as well, just not as fast - and since the focus of SLMs is reduced computational and memory requirements, here we'll use the most optimized path available. Those shown below have been profiled:
\u2022 \u00a0 The HuggingFace Open LLM Leaderboard is a collection of multitask benchmarks including reasoning & comprehension, math, coding, history, geography, ect. \u2022 \u00a0 The model's memory footprint includes 4-bit weights and KV cache at full context length (factor in extra for process overhead, library code, ect) \u2022 \u00a0 The Chat Model is the instruction-tuned variant for chatting with in the commands below, as opposed to the base completion model.
Based on user interactions, the recommended models to try are stabilityai/stablelm-zephyr-3b and princeton-nlp/Sheared-LLaMA-2.7B-ShareGPT, for having output quality on par with Llama-2-7B and well-optimized neural architectures. These models have also been used as the base for various fine-tunes (for example Nous-Capybara-3B-V1.9) and mini VLMs. Others may not be particularly coherent.
"},{"location":"tutorial_slm.html#chatting-with-slms","title":"Chatting with SLMs","text":"
What you need
One of the following Jetson devices:
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB) Jetson Orin NX (16GB) Jetson Orin Nano (8GB)
Running one of the following versions of JetPack:
JetPack 6 (L4T r36.x)
Sufficient storage space (preferably with NVMe SSD).
The nano_llm.chat program will automatically download and quantize models from HuggingFace like those listed in the table above:
jetson-containers run $(autotag nano_llm) \\\npython3 -m nano_llm.chat --api=mlc \\\n--model princeton-nlp/Sheared-LLaMA-2.7B-ShareGPT\n
\u2022 \u00a0 For models requiring authentication, use --env HUGGINGFACE_TOKEN=<YOUR-ACCESS-TOKEN> \u2022 \u00a0 Press Ctrl+C twice in succession to exit (once will interrupt bot output)
This will enter into interactive mode where you chat back and forth using the keyboard (entering reset will clear the chat history)
During testing, you can specify prompts on the command-line that will run sequentially:
jetson-containers run $(autotag nano_llm) \\\npython3 -m nano_llm.chat --api=mlc \\\n--model stabilityai/stablelm-zephyr-3b \\\n--max-new-tokens 512 \\\n--prompt 'hi, how are you?' \\\n--prompt 'whats the square root of 900?' \\\n--prompt 'can I get a recipie for french onion soup?'\n
You can also load JSON files containing prompt sequences, like with --prompt /data/prompts/qa.json (the output of which is below)
\u2022 \u00a0 The model responses are with 4-bit quantization, and are truncated to 256 tokens for brevity. \u2022 \u00a0 These chat questions are from /data/prompts/qa.json (found in jetson-containers)
Stable Diffusion XL is a newer ensemble pipeline consisting of a base model and refiner that results in significantly enhanced and detailed image generation capabilities. All told, SDXL 1.0 has 6.6 billion model parameters, in comparison to 0.98 billion for the original SD 1.5 model.
What you need
One of the following Jetson devices (SDXL requires >= ~13GB memory)
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB)
Running one of the following versions of JetPack:
JetPack 5 (L4T r35.x) JetPack 6 (L4T r36.x)
Sufficient storage space (preferably with NVMe SSD).
6.8GB for container image
12.4GB for SDXL models
Have followed the previous stable-diffusion-webui tutorial and have the webserver container running.
Stable Diffusion XL is supported through AUTOMATIC1111's stable-diffusion-webui with some additional settings. First you need to download the SDXL models to your jetson-containers data directory (which is automatically mounted into the container)
# run these outside of container, and replace CONTAINERS_DIR with the path to the jetson-containers repo on your device\nCONTAINERS_DIR=/path/to/your/jetson-containers\nMODEL_DIR=$CONTAINERS_DIR/data/models/stable-diffusion/models/Stable-diffusion/\n\nsudo chown -R $USER $MODEL_DIR\n\nwget -P $MODEL_DIR https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors\nwget -P $MODEL_DIR https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0.safetensors\n
It's assumed that you already have the stable-diffusion-webui container and webserver running from the previous tutorial.
After the models have finished downloading, click the \ud83d\udd04 button to refresh the model list in the web UI. Select sd_xl_base_1.0.safetensors from the Stable Diffusion checkpoint drop-down:
Then under the Generation tab, expand the Refiner section, and select sd_xl_refiner_1.0.safetensors from the drop-down:
Guidance on other relevant settings:
Change the width/height to 1024x1024. SDXL works best at higher resolutions, and using 512x512 often results in more simplistic/cartoonish content. Changing image resolutions impacts the actual scene contents of the image, not just the details.
The refiner's Switch at setting dictates the step at which the refiner takes over from the base model. At this point, additional subject content will no longer be added to the scene, but rather its details further refined in the image.
Typical Sampling steps are between 20-40 and Switch at is between 0.7-0.9. This takes experimentation to find the best combination for the characteristics of your desired output.
Extensive negative prompts are not as necessary in the same way as SD 1.5 was (e.g. low quality, jpeg artifacts, blurry, ect)
CFG Scale controls how closely the model conforms to your prompt versus how creative it is.
When you get a good image, remember to save your random seed and settings so you can re-generate it later!
photograph of a friendly robot alongside a person climbing a mountain (seed 1576166644, steps 25, switch @ 0.8, cfg scale 15)
a girl and a boy building a friendly robot in their basement workshop (seed 642273464, steps 25, switch @ 0.9, cfg scale 7)
small friendly robots playing games with people, in a futuristic Tokyo central park gardens with cherry blossoms and water, coy fish swimming in the water, sunshine (seed 642273464, steps 40, switch @ 0.8, cfg scale 7)
small friendly robots playing games with people in a futuristic New York City Central Park in autumn, water (seed 642273464, steps 25, switch @ 0.8, cfg scale 7)
Want to explore using Python APIs to run diffusion models directly? See jetson-containers/stable-diffusion.
Let's run AUTOMATIC1111's stable-diffusion-webui on NVIDIA Jetson to generate images from our prompts!
What you need
One of the following Jetson devices:
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB) Jetson Orin NX (16GB) Jetson Orin Nano (8GB)
Running one of the following versions of JetPack:
JetPack 5 (L4T r35.x) JetPack 6 (L4T r36.x)
Sufficient storage space (preferably with NVMe SSD).
6.8GB for container image
4.1GB for SD 1.5 model
"},{"location":"tutorial_stable-diffusion.html#setup-a-container-for-stable-diffusion-webui","title":"Setup a container for stable-diffusion-webui","text":"
The jetson-containers project provides pre-built Docker images for stable-diffusion-webui. You can clone the repo to use its utilities that will automatically pull/start the correct container for you, or you can do it manually.
JetsonHacks provides an informative walkthrough video on jetson-containers, showcasing the usage of both the stable-diffusion-webui and text-generation-webui. You can find the complete article with detailed instructions here.
"},{"location":"tutorial_stable-diffusion.html#how-to-start","title":"How to start","text":"
Use jetson-containers run and autotag tools to automatically pull or build a compatible container image:
jetson-containers run $(autotag stable-diffusion-webui)\n
The container has a default run command (CMD) that will automatically start the webserver like this:
Interact with a local AI assistant by running a LLM with oobabooga's text-generaton-webui on NVIDIA Jetson!
What you need
One of the following Jetson devices:
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB) Jetson Orin NX (16GB) Jetson Orin Nano (8GB)\u26a0\ufe0f1
Running one of the following versions of JetPack:
JetPack 5 (L4T r35.x) JetPack 6 (L4T r36.x)
Sufficient storage space (preferably with NVMe SSD).
6.2GB for container image
Spaces for models
"},{"location":"tutorial_text-generation.html#set-up-a-container-for-text-generation-webui","title":"Set up a container for text-generation-webui","text":"
The jetson-containers project provides pre-built Docker images for text-generation-webui along with all of the loader API's built with CUDA enabled (llama.cpp, ExLlama, AutoGPTQ, Transformers, ect). You can clone the repo to use its utilities that will automatically pull/start the correct container for you, or you can do it manually.
JetsonHacks provides an informative walkthrough video on jetson-containers, showcasing the usage of both the stable-diffusion-webui and text-generation-webui. You can find the complete article with detailed instructions here.
"},{"location":"tutorial_text-generation.html#how-to-start","title":"How to start","text":"
Use jetson-containers run and autotag tools to automatically pull or build a compatible container image:
jetson-containers run $(autotag text-generation-webui)\n
The container has a default run command (CMD) that will automatically start the webserver like this:
From within the web UI, select Model tab and navigate to \"Download model or LoRA\" section.
You can find text generation models on Hugging Face Hub, then enter the Hugging Face username/model path (which you can have copied to your clipboard from the Hub). Then click the Download button.
"},{"location":"tutorial_text-generation.html#model-selection-for-jetson-orin-nano","title":"Model selection for Jetson Orin Nano","text":"
Jetson Orin Nano Developer Kit has only 8GB RAM for both CPU (system) and GPU, so you need to pick a model that fits in the RAM size - see the Model Size section below. The 7B models with 4-bit quantization are the ones to use on Jetson Orin Nano. Make sure you go through the RAM optimization steps before attempting to load such model on Jetson Orin Nano.
"},{"location":"tutorial_text-generation.html#load-a-model","title":"Load a model","text":"
After you have downloaded a model, click the \ud83d\udd04 button to refresh your model list, and select the model you want to use.
For a GGUF model, remember to
Set n-gpu-layers to 128
Set n_gqa to 8 if you using Llama-2-70B (on Jetson AGX Orin 64GB)
If you're using a Llama model fine-tuned for chat, like the models listed above (except for LLaMA-30b), you need to use the oobabooga Instruct mode and set the template. On the Parameters tab, go to the Instruction Template sub-tab, then select Llama-v2 from the Instruction Template drop-down (or Vicuna, Guanaco, ect if you are using one of those models)
For the base text completion models (like LLaMA-30b), use the Default or Notebook tab.
Selecting the right chat template will make sure the model is being prompted correctly - you can also change the system prompt in the Context box to alter the agent's personality and behavior. There are a lot of other settings under the Generation tab, like the maximum length it should output per reply, and token sampling parameters like temperature and top_p for controlling randomness.
Then change back to the Chat tab, and under the mode section, make sure Instruct is selected (confusingly, not chat mode). Then you can start chatting with the LLM!
"},{"location":"tutorial_text-generation.html#results","title":"Results","text":""},{"location":"tutorial_text-generation.html#things-to-do-with-your-llm","title":"Things to do with your LLM","text":"
Here are some common test prompts for coding, math, history ect. You can also ask it about geography, travel, nature, recipies, fixing things, general life advice, and practically everything else. Also Llama-2 is quite playful and likes to play games to test its logic abilities!
>> What games do you like to play?\n\nI'm a large language model, so I can play text-based games and answer questions on a wide variety of topics. Here are some game ideas:\n\n- 20 Questions: You or I can think of an object, and the other player tries to guess what it is by asking up to 20 yes-or-no questions. The goal is to guess the object in as few questions as possible.\n- Hangman: I can think of a word or phrase and you try to guess it by suggesting letters. Each incorrect guess will bring the hangman one step closer to being complete!\n- Word association: I'll give you a word and you have to come up with a word that is related to it. We can keep playing back and forth as long as you'd like!\n- Trivia: I can provide questions on a wide range of topics, from history to science to pop culture. See how many questions you can answer correctly!\n- Storytelling: I can start telling a story and then stop at a cliffhanger. You can then try to guess what happens next or even take over the storytelling and continue it in your own\n- Jokes: I love to tell jokes and make people laugh with my \"Dad humor\"! Knock knock! *giggles*\n
Model size Jetson AGX Orin 64GB Jetson AGX Orin 32GB Jetson Orin Nano 8GB 70B model \u2705 30B model \u2705 \u2705 13B model \u2705 \u2705 7B model \u2705 \u2705 \u2705
Want to explore using Python APIs to run LLMs directly? See jetson-containers for its LLM related packages and containers.
Limited to 7B model (4-bit quantized).\u00a0\u21a9
Whisper repo comes with demo Jupyter notebooks, which you can find under /notebooks/ directory.
jetson-containers also adds one convenient notebook (record-and-transcribe.ipynb) to record your audio sample on Jupyter notebook in order to run transcribe on your recorded audio.
At the end you should see a summary like the following.
AVERAGE of 2 runs:\n encoder --- 0.062 sec\n latency --- 0.083 sec\nMemory consumption : 3419.68 MB\n
"},{"location":"vit/tutorial_efficientvit.html#check-the-outputresult","title":"Check the output/result","text":"
The output image file (of the last inference result) is stored as /data/benchmarks/efficientvit_sam_demo.png.
It is stored under /data/ directory that is mounted from the Docker host. So you can go back to your host machine, and check jetson-containers/data/benchmark/ directory.
"},{"location":"vit/tutorial_nanoowl.html#how-to-start","title":"How to start","text":"
Use the jetson-containers run and autotag commands to automatically pull or build a compatible container image.
jetson-containers run $(autotag nanoowl)\n
"},{"location":"vit/tutorial_nanoowl.html#how-to-run-the-tree-prediction-live-camera-example","title":"How to run the tree prediction (live camera) example","text":"
Ensure you have a camera device connected
ls /dev/video*\n
If no video device is found, exit from the container and check if you can see a video device on the host side.
Launch the demo
cd examples/tree_demo\npython3 tree_demo.py ../../data/owl_image_encoder_patch32.engine\n
Info
If it fails to find or load the TensorRT engine file, build the TensorRT engine for the OWL-ViT vision encoder on your Jetson device.
The result is saved under /opt/nanosam/data/basic_usage_out.jpg.
To check on your host machine, you can copy that into /data directory of the container where that is mounted from the host.
cp data/basic_usage_out.jpg /data/\n
Then you can go to your host system, and find the file under jetson-containers/data/basic_usage_out.jpg
"},{"location":"vit/tutorial_nanosam.html#results","title":"Results","text":""},{"location":"vit/tutorial_sam.html","title":"Tutorial - SAM (Segment Anything)","text":"
Let's run Meta's SAM on NVIDIA Jetson.
What you need
One of the following Jetson devices:
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB) Jetson Orin NX (16GB) Jetson Orin Nano (8GB)\u26a0\ufe0f1
Running one of the following versions of JetPack:
JetPack 5 (L4T r35.x) JetPack 6 (L4T r36.x)
Sufficient storage space (preferably with NVMe SSD).
"},{"location":"vit/tutorial_tam.html#how-to-start","title":"How to start","text":"
Use the jetson-containers run and autotag commands to automatically pull or build a compatible container image.
jetson-containers run $(autotag tam)\n
The container has a default run command (CMD) that will automatically start TAM's web server.
Open your browser and access http://<IP_ADDRESS>:12212.
"},{"location":"vit/tutorial_tam.html#tam-web-ui","title":"TAM web UI","text":"
Check out the official tutorial to learn how to operate the web UI.
"},{"location":"vit/tutorial_tam.html#results","title":"Results","text":""},{"location":"vit/tutorial_tam.html#troubleshooting","title":"Troubleshooting","text":""},{"location":"vit/tutorial_tam.html#filenotfounderror-errno-2-no-such-file-or-directory-checkpointse2fgvi-hq-cvpr22pth","title":"FileNotFoundError: [Errno 2] No such file or directory: './checkpoints/E2FGVI-HQ-CVPR22.pth'","text":"
You may find the TAM app fails to download a checkpoint file E2FGVI-HQ-CVPR22.pth.
Downloading checkpoints from Google Drive... tips: If you cannot see the progress bar, please try to download it manuall and put it in the checkpointes directory. E2FGVI-HQ-CVPR22.pth: https://github.com/MCG-NKU/E2FGVI(E2FGVI-HQ model)\nAccess denied with the following error:\n\n Cannot retrieve the public link of the file. You may need to change\n the permission to 'Anyone with the link', or have had many accesses. \n\nYou may still be able to access the file from the browser:\n\n https://drive.google.com/uc?id=10wGdKSUOie0XmCr8SQ2A2FeDe-mfn5w3 \n
You can manually download the checkpoint file on your Docker host machine.
cd jetson-containers/\npip install gdown\nsource ~/.profile\ngdown https://drive.google.com/uc?id=10wGdKSUOie0XmCr8SQ2A2FeDe-mfn5w3 \nmv E2FGVI-HQ-CVPR22.pth ./data/models/tam/\n
Especially if you are on Jetson Orin Nano that only has 8GB of RAM, it is crucial to leave as much RAM space available for models.
+
Here we share a couple of ways to optimize the system RAM usage.
+
Disabling the Desktop GUI
+
If you use your Jetson remotely through SSH, you can disable the Ubuntu desktop GUI.
+This will free up extra memory that the window manager and desktop uses (around ~800MB for Unity/GNOME).
+
You can disable the desktop temporarily, run commands in the console, and then re-start the desktop when desired:
+
$ sudo init 3 # stop the desktop
+# log your user back into the console (Ctrl+Alt+F1, F2, ect)
+$ sudo init 5 # restart the desktop
+
+
If you wish to make this persistent across reboots, you can use the following commands to change the boot-up behavior:
+
+
+
To disable desktop on boot
+
sudo systemctl set-default multi-user.target
+
+
+
+
To enable desktop on boot
+
sudo systemctl set-default graphical.target
+
+
+
+
Disabling misc services
+
sudo systemctl disable nvargus-daemon.service
+
+
Mounting Swap
+
If you're building containers or working with large models, it's advisable to mount SWAP (typically correlated with the amount of memory in the board). Run these commands to disable ZRAM and create a swap file:
+
+
If you have NVMe SSD storage available, it's preferred to allocate the swap file on the NVMe SSD.
Once you have your Jetson set up by flashing the latest Jetson Linux (L4T) BSP on it or by flashing the SD card with the whole JetPack image, before embarking on testing out all the great generative AI application using jetson-containers, you want to make sure you have a huge storage space for all the containers and the models you will download.
+
We are going to show how you can install SSD on your Jetson, and set it up for Docker.
+
SSD
+
Physical installation
+
+
Unplug power and any peripherals from the Jetson developer kit.
+
Physically install an NVMe SSD card on the carrier board of your Jetson developer kit, making sure to properly seat the connector and secure with the screw.
+
Reconnect any peripherals, and then reconnect the power supply to turn on the Jetson developer kit.
+
+
Once the system is up, verify that your Jetson identifies a new memory controller on PCI bus:
Finally, change the ownership of the /ssd directory.
+
sudochown${USER}:${USER}/ssd
+
+
+
+
Docker
+
+
+
Install nvidia-container package.
+
+
Note: If you used an NVIDIA-supplied SD card image to flash your SD card, all necessary JetPack components (including nvidia-containers) and Docker are already pre-installed, so this step can be skipped.
+
+
sudoaptupdate
+sudoaptinstall-ynvidia-container
+
+
+
JetPack 6.0 DP users
+
If you flash Jetson Linux (L4T) R36.2 (JetPack 6.0 DP) on your Jetson using SDK Manager, and install nvidia-container using apt, on JetPack 6.0 it no longer automatically installs Docker.
+
Therefore, you need to run the following to manually install Docker and set it up.
It's good to know the code for generating text with LLM inference, and ancillary things like tokenization, chat templates, and prompting. On this page we give Python examples of running various LLM APIs, and their benchmarks.
+
+
What you need
+
+
+
One of the following Jetson devices:
+
Jetson AGX Orin (64GB)
+Jetson AGX Orin (32GB)
+Jetson Orin NX (16GB)
+Jetson Orin Nano (8GB)⚠️
Sufficient storage space (preferably with NVMe SSD).
+
+
22GB for l4t-text-generation container image
+
Space for models (>10GB)
+
+
+
+
+
Transformers
+
The HuggingFace Transformers API is the de-facto API that models are released for, often serving as the reference implementation. It's not terribly fast, but it does have broad model support, and also supports quantization (AutoGPTQ, AWQ). This uses streaming:
+
fromtransformersimportAutoModelForCausalLM,AutoTokenizer,TextIteratorStreamer
+fromthreadingimportThread
+
+model_name='meta-llama/Llama-2-7b-chat-hf'
+model=AutoModelForCausalLM.from_pretrained(model_name,device_map='cuda')
+
+tokenizer=AutoTokenizer.from_pretrained(model_name)
+streamer=TextIteratorStreamer(tokenizer)
+
+prompt=[{'role':'user','content':'Can I get a recipe for French Onion soup?'}]
+inputs=tokenizer.apply_chat_template(
+ prompt,
+ add_generation_prompt=True,
+ return_tensors='pt'
+).to(model.device)
+
+Thread(target=lambda:model.generate(inputs,max_new_tokens=256,streamer=streamer)).start()
+
+fortextinstreamer:
+ print(text,end='',flush=True)
+
+
To run this (it can be found here), you can mount a directory containing the script or your jetson-containers directory:
We use the l4t-text-generation container because it includes the quantization libraries in addition to Transformers, for running the quanztized versions of the models like TheBloke/Llama-2-7B-Chat-GPTQ
Follow the chat-based LLaVA and NanoVLM tutorials to familiarize yourself with vision/language models and test the models first.
+
+
This multimodal agent runs a vision-language model on a live camera feed or video stream, repeatedly applying the same prompts to it:
+
+
It uses models like LLaVA or VILA (based on Llama and CLIP) and has been quantized with 4-bit precision to be deployed on Jetson Orin. This runs an optimized multimodal pipeline from the NanoLLM library, including event filters and alerts, and multimodal RAG:
+
+
+
Running the Live Llava Demo
+
+
What you need
+
+
+
One of the following Jetson devices:
+
Jetson AGX Orin (64GB)
+Jetson AGX Orin (32GB)
+Jetson Orin NX (16GB)
+Jetson Orin Nano (8GB)⚠️
The VideoQuery agent applies prompts to the incoming video feed with the VLM. Navigate your browser to https://<IP_ADDRESS>:8050 after launching it with your camera (Chrome is recommended with chrome://flags#enable-webrtc-hide-local-ips-with-mdns disabled)
This uses jetson_utils for video I/O, and for options related to protocols and file formats, see Camera Streaming and Multimedia. In the example above, it captures a V4L2 USB webcam connected to the Jetson (under the device /dev/video0) and outputs a WebRTC stream.
+
Processing a Video File or Stream
+
The example above was running on a live camera, but you can also read and write a video file or network stream by substituting the path or URL to the --video-input and --video-output command-line arguments like this:
+
jetson-containersrun\
+-v/path/to/your/videos:/mount
+$(autotagnano_llm)\
+python3-mnano_llm.agents.video_query--api=mlc\
+--modelEfficient-Large-Model/VILA-2.7b\
+--max-new-tokens32\
+--video-input/mount/my_video.mp4\
+--video-output/mount/output.mp4\
+--prompt"What does the weather look like?"
+
+
This example processes and pre-recorded video (in MP4, MKV, AVI, FLV formats with H.264/H.265 encoding), but it also can input/output live network streams like RTP, RTSP, and WebRTC using Jetson's hardware-accelerated video codecs.
+
NanoDB Integration
+
If you launch the VideoQuery agent with the --nanodb flag along with a path to your NanoDB database, it will perform reverse-image search on the incoming feed against the database by re-using the CLIP embeddings generated by the VLM.
+
To enable this mode, first follow the NanoDB tutorial to download, index, and test the database. Then launch VideoQuery like this:
LLaVA is a popular multimodal vision/language model that you can run locally on Jetson to answer questions about image prompts and queries. Llava uses the CLIP vision encoder to transform images into the same embedding space as its LLM (which is the same as Llama architecture). Below we cover different methods to run Llava on Jetson, with increasingly optimized performance:
Sufficient storage space (preferably with NVMe SSD).
+
+
6.1GB for llava container
+
14GB for Llava-7B (or 26GB for Llava-13B)
+
+
+
+
+
This example uses the upstream Llava repo to run the original, unquantized Llava models from the command-line. It uses more memory due to using FP16 precision, and is provided mostly as a reference for debugging. See the Llava container readme for more info.
llama.cpp is one of the faster LLM API's, and can apply a variety of quantization methods to Llava to reduce its memory usage and runtime. Despite its name, it uses CUDA. There are pre-quantized versions of Llava-1.5 available in GGUF format for 4-bit and 5-bit:
You can put your own images in the mounted jetson-containers/data directory. The C++ code for llava-cli can be found here. The llama-cpp-python bindings also support Llava, however they are significantly slower from Python for some reason (potentially pre-processing)
+
4. Optimized Multimodal Pipeline with NanoVLM
+
+
What's Next
+
This section got too long and was moved to the NanoVLM page - check it out there for performance optimizations, mini VLMs, and live streaming!
17# First steps with Metropolis Microservices for Jetson
+
NVIDIA Metropolis Microservices for Jetson simplifies the development of vision AI applications, offering a suite of customizable, cloud-native tools. Before diving into this tutorial, ensure you've filled out the Metropolis Microservices for Jetson Early Access form to gain the necessary access to launch the services. This step is crucial as it enables you to utilize all the features and capabilities discussed in this guide.
+
Perfect for both newcomers and experts, this tutorial provides straightforward steps to kick-start your edge AI projects. Whether you're a student or an ecosystem partner working on a use case, this guide offers a straightforward start for every skill level.
+
+
0. Install NVIDIA Jetson Services:
+
Ok, let's start by installing NVIDIA Jetson Services:
+
sudo apt install nvidia-jetson-services
+
+
Let's add some performance hacks that will be needed to run the demo faster and without streaming artifacts:
+
+
+
If you don't have the Orin at max performance, you can use these two commands, a reboot is needed after:
+
sudo nvpmodel -m 0
+sudo jetson_clocks
+
+
+
+
After these two commands, a reboot is needed if your Jetson wasn't already in high-performance mode.
+These are optional, but they fine-tune your network buffers to ensure smoother streaming by optimizing how much data can be sent and received:
+
+Here it will ask for your API Key, and the organization name, to get those you need to login into NGC and generate an API key here.
+
You should then paste the API key and use the organization name you are using. You can also press [Enter] to select the default values for the remaining options. After this, you should get the message:
+
Successfully saved NGC configuration to /home/jetson/.ngc/config
+
First, we need to install NVStreamer, an app that streams the videos MMJs will need to run AI on them. Follow this NVStreamer Link (In the top-left, click Download files.zip)
So, first we need to upload the file in the Streamer interface, it looks like this:
+
+
+
+
There, go to File Upload, and drag and drop the file in the upload squared area.
+
After uploading it, go to the Dashboad option of the left menu, and copy the RTSP URL of the video you just uploaded, you will need it for the Camera Management Dashboard.
+
Now jump to the Camera Management Dashboard (http://localhost:30080/vst), it looks like this:
+
+
+
+
Go to the Camera Management option of the menu, then use the Add device manually option, and paste the RTSP URL, add the name of your video to the Name and Location text boxes, so it will be displayed on top of the stream.
+
Finally, click in the Live Streams option of the left menu, and you should be able to watch your video stream.
+
+
+
+
5. Watch RTSP AI processed streaming from VLC
+
Open VLC from another computer (localhost doesn't work here), and point to your Jetson Orin's IP address (you should be in the same network, or not having a firewal to access).
+
The easiest way to get Jetson's ip is launching:
+
ifconfig
+
+And checking the IP of the interface (usually wlan0, inet IP).
+
Then go to rtsp://[JETSON_IP]:8555/ds-test using VLC like this:
+
+
+
+
6. Android app
+
There is an Android app that allows you to track events and create areas of interest to monitor, you can find it on Google Play as AI NVR.
+
+
+
Here is a quick walkthough where you can see how to:
+
+
Add the IP address of the Jetson
+
Track current events
+
Add new areas of interest
+
Add tripwire to track the flux and direction of events
NanoLLM is a lightweight, high-performance library using optimized inferencing APIs for quantized LLM’s, multimodality, speech services, vector databases with RAG, and web frontends. It's used to build many of the responsive, low-latency agents featured on this site.
+
+
It provides similar APIs to HuggingFace, backed by highly-optimized inference libraries and quantization tools:
+
fromnano_llmimportNanoLLM
+
+model=NanoLLM.from_pretrained(
+ "meta-llama/Llama-2-7b-hf",# HuggingFace repo/model name, or path to HF model checkpoint
+ api='mlc',# supported APIs are: mlc, awq, hf
+ api_token='hf_abc123def',# HuggingFace API key for authenticated models ($HUGGINGFACE_TOKEN)
+ quantization='q4f16_ft'# q4f16_ft, q4f16_1, q8f16_0 for MLC, or path to AWQ weights
+)
+
+response=model.generate("Once upon a time,",max_new_tokens=128)
+
+fortokeninresponse:
+ print(token,end='',flush=True)
+
+
Resources
+
Here's an index of the various tutorials & examples using NanoLLM on Jetson AI Lab:
We saw in the previous LLaVA tutorial how to run vision-language models through tools like text-generation-webui and llama.cpp. In a similar vein to the SLM page on Small Language Models, here we'll explore optimizing VLMs for reduced memory usage and higher performance that reaches interactive levels (like in Liva LLava). These are great for fitting on Orin Nano and increasing the framerate.
+
There are 3 model families currently supported: Llava, VILA, and Obsidian (mini VLM)
+
VLM Benchmarks
+
+
+
This FPS measures the end-to-end pipeline performance for continuous streaming like with Live Llava (on yes/no question)
+
+
+
+
• These models all use CLIP ViT-L/14@336px for the vision encoder.
+• Jetson Orin Nano 8GB runs out of memory trying to run Llava-13B.
+
+
Multimodal Chat
+
+
What you need
+
+
+
One of the following Jetson devices:
+
Jetson AGX Orin (64GB)
+Jetson AGX Orin (32GB)
+Jetson Orin NX (16GB)
+Jetson Orin Nano (8GB)⚠️
The optimized NanoLLM library uses MLC/TVM for quantization and inference provides the highest performance. It efficiently manages the CLIP embeddings and KV cache. You can find Python code for the chat program used in this example here.
This starts an interactive console-based chat with Llava, and on the first run the model will automatically be downloaded from HuggingFace and quantized using MLC and W4A16 precision (which can take some time). See here for command-line options.
+
You'll end up at a >> PROMPT: in which you can enter the path or URL of an image file, followed by your question about the image. You can follow-up with multiple questions about the same image. Llava does not understand multiple images in the same chat, so when changing images, first reset the chat history by entering clear or reset as the prompt. VILA supports multiple images (area of active research)
+
Automated Prompts
+
During testing, you can specify prompts on the command-line that will run sequentially:
+
jetson-containers run $(autotag nano_llm) \
+ python3 -m nano_llm.chat --api=mlc \
+ --model liuhaotian/llava-v1.6-vicuna-7b \
+ --max-context-len 768 \
+ --max-new-tokens 128 \
+ --prompt '/data/images/hoover.jpg' \
+ --prompt 'what does the road sign say?' \
+ --prompt 'what kind of environment is it?' \
+ --prompt 'reset' \
+ --prompt '/data/images/lake.jpg' \
+ --prompt 'please describe the scene.' \
+ --prompt 'are there any hazards to be aware of?'
+
• The model responses are with 4-bit quantization enabled, and are truncated to 128 tokens for brevity.
+• These chat questions and images are from /data/prompts/images.json (found in jetson-containers)
+
JSON
+
When prompted, these models can also output in constrained JSON formats (which the LLaVA authors cover in their LLaVA-1.5 paper), and can be used to programatically query information about the image:
+
jetson-containers run $(autotag nano_llm) \
+ python3 -m nano_llm.chat --api=mlc \
+ --model liuhaotian/llava-v1.5-13b \
+ --prompt '/data/images/hoover.jpg' \
+ --prompt 'extract any text from the image as json'
+
+{
+ "sign": "Hoover Dam",
+ "exit": "2",
+ "distance": "1 1/2 mile"
+}
+
+
Web UI
+
To use this through a web browser instead, see the llamaspeak tutorial:
+
+
Live Streaming
+
These models can also be used with the Live Llava agent for continuous streaming - just substitute the desired model name below:
This will take a few hours on AGX Orin. Once the database has loaded and completed any start-up operations , it will drop down to a > prompt from which the user can run search queries. You can quickly check the operation by typing your query on this prompt:
Small Language Models (SLMs) represent a growing class of language models that have <7B parameters - for example StableLM, Phi-2, and Gemma-2B. Their smaller memory footprint and faster performance make them good candidates for deploying on Jetson Orin Nano. Some are very capable with abilities at a similar level as the larger models, having been trained on high-quality curated datasets.
+
+
This tutorial shows how to run optimized SLMs with quantization using the NanoLLM library and MLC/TVM backend. You can run these models through tools like text-generation-webui and llama.cpp as well, just not as fast - and since the focus of SLMs is reduced computational and memory requirements, here we'll use the most optimized path available. Those shown below have been profiled:
+
SLM Benchmarks
+
+
+
+
+
+
• The HuggingFace Open LLM Leaderboard is a collection of multitask benchmarks including reasoning & comprehension, math, coding, history, geography, ect.
+• The model's memory footprint includes 4-bit weights and KV cache at full context length (factor in extra for process overhead, library code, ect)
+• The Chat Model is the instruction-tuned variant for chatting with in the commands below, as opposed to the base completion model.
+
+
Based on user interactions, the recommended models to try are stabilityai/stablelm-zephyr-3b and princeton-nlp/Sheared-LLaMA-2.7B-ShareGPT, for having output quality on par with Llama-2-7B and well-optimized neural architectures. These models have also been used as the base for various fine-tunes (for example Nous-Capybara-3B-V1.9) and mini VLMs. Others may not be particularly coherent.
+
Chatting with SLMs
+
+
What you need
+
+
+
One of the following Jetson devices:
+
Jetson AGX Orin (64GB)
+Jetson AGX Orin (32GB)
+Jetson Orin NX (16GB)
+Jetson Orin Nano (8GB)
• For models requiring authentication, use --env HUGGINGFACE_TOKEN=<YOUR-ACCESS-TOKEN>
+• Press Ctrl+C twice in succession to exit (once will interrupt bot output)
+
+
This will enter into interactive mode where you chat back and forth using the keyboard (entering reset will clear the chat history)
+
+
Automated Prompts
+
During testing, you can specify prompts on the command-line that will run sequentially:
+
jetson-containersrun$(autotagnano_llm)\
+python3-mnano_llm.chat--api=mlc\
+--modelstabilityai/stablelm-zephyr-3b\
+--max-new-tokens512\
+--prompt'hi, how are you?'\
+--prompt'whats the square root of 900?'\
+--prompt'can I get a recipie for french onion soup?'
+
+
You can also load JSON files containing prompt sequences, like with --prompt /data/prompts/qa.json (the output of which is below)
+
Results
+
+
+
• The model responses are with 4-bit quantization, and are truncated to 256 tokens for brevity.
+• These chat questions are from /data/prompts/qa.json (found in jetson-containers)
Stable Diffusion XL is a newer ensemble pipeline consisting of a base model and refiner that results in significantly enhanced and detailed image generation capabilities. All told, SDXL 1.0 has 6.6 billion model parameters, in comparison to 0.98 billion for the original SD 1.5 model.
+
+
+
What you need
+
+
+
One of the following Jetson devices (SDXL requires >= ~13GB memory)
Sufficient storage space (preferably with NVMe SSD).
+
+
6.8GB for container image
+
12.4GB for SDXL models
+
+
+
+
Have followed the previous stable-diffusion-webui tutorial and have the webserver container running.
+
+
+
+
Downloading SDXL Models
+
Stable Diffusion XL is supported through AUTOMATIC1111's stable-diffusion-webui with some additional settings. First you need to download the SDXL models to your jetson-containers data directory (which is automatically mounted into the container)
+
# run these outside of container, and replace CONTAINERS_DIR with the path to the jetson-containers repo on your device
+CONTAINERS_DIR=/path/to/your/jetson-containers
+MODEL_DIR=$CONTAINERS_DIR/data/models/stable-diffusion/models/Stable-diffusion/
+
+sudochown-R$USER$MODEL_DIR
+
+wget-P$MODEL_DIRhttps://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors
+wget-P$MODEL_DIRhttps://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0.safetensors
+
After the models have finished downloading, click the 🔄 button to refresh the model list in the web UI. Select sd_xl_base_1.0.safetensors from the Stable Diffusion checkpoint drop-down:
+
+
Then under the Generation tab, expand the Refiner section, and select sd_xl_refiner_1.0.safetensors from the drop-down:
+
+
Guidance on other relevant settings:
+
+
Change the width/height to 1024x1024. SDXL works best at higher resolutions, and using 512x512 often results in more simplistic/cartoonish content. Changing image resolutions impacts the actual scene contents of the image, not just the details.
+
The refiner's Switch at setting dictates the step at which the refiner takes over from the base model. At this point, additional subject content will no longer be added to the scene, but rather its details further refined in the image.
+
Typical Sampling steps are between 20-40 and Switch at is between 0.7-0.9. This takes experimentation to find the best combination for the characteristics of your desired output.
+
Extensive negative prompts are not as necessary in the same way as SD 1.5 was (e.g. low quality, jpeg artifacts, blurry, ect)
+
CFG Scale controls how closely the model conforms to your prompt versus how creative it is.
+
+
When you get a good image, remember to save your random seed and settings so you can re-generate it later!
+
Results
+
+
+
+photograph of a friendly robot alongside a person climbing a mountain (seed 1576166644, steps 25, switch @ 0.8, cfg scale 15)
+
+
+
+a girl and a boy building a friendly robot in their basement workshop (seed 642273464, steps 25, switch @ 0.9, cfg scale 7)
+
+
+
+small friendly robots playing games with people, in a futuristic Tokyo central park gardens with cherry blossoms and water, coy fish swimming in the water, sunshine (seed 642273464, steps 40, switch @ 0.8, cfg scale 7)
+
+
+
+small friendly robots playing games with people in a futuristic New York City Central Park in autumn, water (seed 642273464, steps 25, switch @ 0.8, cfg scale 7)
Sufficient storage space (preferably with NVMe SSD).
+
+
6.8GB for container image
+
4.1GB for SD 1.5 model
+
+
+
+
+
Setup a container for stable-diffusion-webui
+
The jetson-containers project provides pre-built Docker images for stable-diffusion-webui. You can clone the repo to use its utilities that will automatically pull/start the correct container for you, or you can do it manually.
JetsonHacks provides an informative walkthrough video on jetson-containers, showcasing the usage of both the stable-diffusion-webui and text-generation-webui. You can find the complete article with detailed instructions here.
+
+
+
How to start
+
Use jetson-containers run and autotag tools to automatically pull or build a compatible container image:
+
jetson-containers run $(autotag stable-diffusion-webui)
+
+
The container has a default run command (CMD) that will automatically start the webserver like this:
Sufficient storage space (preferably with NVMe SSD).
+
+
6.2GB for container image
+
Spaces for models
+
+
+
+
+
Set up a container for text-generation-webui
+
The jetson-containers project provides pre-built Docker images for text-generation-webui along with all of the loader API's built with CUDA enabled (llama.cpp, ExLlama, AutoGPTQ, Transformers, ect). You can clone the repo to use its utilities that will automatically pull/start the correct container for you, or you can do it manually.
JetsonHacks provides an informative walkthrough video on jetson-containers, showcasing the usage of both the stable-diffusion-webui and text-generation-webui. You can find the complete article with detailed instructions here.
+
+
+
How to start
+
Use jetson-containers run and autotag tools to automatically pull or build a compatible container image:
+
jetson-containers run $(autotag text-generation-webui)
+
+
The container has a default run command (CMD) that will automatically start the webserver like this:
From within the web UI, select Model tab and navigate to "Download model or LoRA" section.
+
You can find text generation models on Hugging Face Hub, then enter the Hugging Face username/model path (which you can have copied to your clipboard from the Hub). Then click the Download button.
+
GGUF models
+
The fastest oobabooga model loader to use is currently llama.cpp with 4-bit quantized GGUF models.
+
You can download a single model file for a particular quantization, like *.Q4_K_M.bin. Input the file name and hit Download button.
Jetson Orin Nano Developer Kit has only 8GB RAM for both CPU (system) and GPU, so you need to pick a model that fits in the RAM size - see the Model Size section below. The 7B models with 4-bit quantization are the ones to use on Jetson Orin Nano. Make sure you go through the RAM optimization steps before attempting to load such model on Jetson Orin Nano.
+
+
Load a model
+
After you have downloaded a model, click the 🔄 button to refresh your model list, and select the model you want to use.
+
For a GGUF model, remember to
+
+
Set n-gpu-layers to 128
+
Set n_gqa to 8 if you using Llama-2-70B (on Jetson AGX Orin 64GB)
+
+
Then click the Load button.
+
Chat Template
+
If you're using a Llama model fine-tuned for chat, like the models listed above (except for LLaMA-30b), you need to use the oobabooga Instruct mode and set the template. On the Parameters tab, go to the Instruction Template sub-tab, then select Llama-v2 from the Instruction Template drop-down (or Vicuna, Guanaco, ect if you are using one of those models)
+
+
For the base text completion models (like LLaMA-30b), use the Default or Notebook tab.
+
+
Selecting the right chat template will make sure the model is being prompted correctly - you can also change the system prompt in the Context box to alter the agent's personality and behavior. There are a lot of other settings under the Generation tab, like the maximum length it should output per reply, and token sampling parameters like temperature and top_p for controlling randomness.
+
Then change back to the Chat tab, and under the mode section, make sure Instruct is selected (confusingly, not chat mode). Then you can start chatting with the LLM!
+
Results
+
+
Things to do with your LLM
+
Here are some common test prompts for coding, math, history ect. You can also ask it about geography, travel, nature, recipies, fixing things, general life advice, and practically everything else. Also Llama-2 is quite playful and likes to play games to test its logic abilities!
+
>> What games do you like to play?
+
+I'm a large language model, so I can play text-based games and answer questions on a wide variety of topics. Here are some game ideas:
+
+- 20 Questions: You or I can think of an object, and the other player tries to guess what it is by asking up to 20 yes-or-no questions. The goal is to guess the object in as few questions as possible.
+- Hangman: I can think of a word or phrase and you try to guess it by suggesting letters. Each incorrect guess will bring the hangman one step closer to being complete!
+- Word association: I'll give you a word and you have to come up with a word that is related to it. We can keep playing back and forth as long as you'd like!
+- Trivia: I can provide questions on a wide range of topics, from history to science to pop culture. See how many questions you can answer correctly!
+- Storytelling: I can start telling a story and then stop at a cliffhanger. You can then try to guess what happens next or even take over the storytelling and continue it in your own
+- Jokes: I love to tell jokes and make people laugh with my "Dad humor"! Knock knock! *giggles*
+
+
Model size tested
+
With llama.cpp, GGUF model, 4-bit quantization:
+
+
+
+
Model size
+
Jetson AGX Orin 64GB
+
Jetson AGX Orin 32GB
+
Jetson Orin Nano 8GB
+
+
+
+
+
70B model
+
✅
+
+
+
+
+
30B model
+
✅
+
✅
+
+
+
+
13B model
+
✅
+
✅
+
+
+
+
7B model
+
✅
+
✅
+
✅
+
+
+
+
+
Want to explore using Python APIs to run LLMs directly?
+See jetson-containers for its LLM related packages and containers.
Use run.sh and autotag script to automatically pull or build a compatible container image.
+
jetson-containers run $(autotag whisper)
+
+
The container has a default run command (CMD) that will automatically start the Jupyter Lab server, with SSL enabled.
+
Open your browser and access https://<IP_ADDRESS>:8888.
+
+
Attention
+
Note it is https (not http).
+
HTTPS (SSL) connection is needed to allow ipywebrtc widget to have access to your microphone (for record-and-transcribe.ipynb).
+
+
You will see a warning message like this.
+
+
Press "Advanced" button and then click on "Proceed to (unsafe)" link to proceed to the Jupyter Lab web interface.
+
+
+
The default password for Jupyter Lab is nvidia.
+
+
Run Jupyter notebooks
+
Whisper repo comes with demo Jupyter notebooks, which you can find under /notebooks/ directory.
+
jetson-containers also adds one convenient notebook (record-and-transcribe.ipynb) to record your audio sample on Jupyter notebook in order to run transcribe on your recorded audio.
+
+
record-and-transcribe.ipynb
+
This notebook is to let you record your own audio sample using your PC's microphone and apply Whisper's medium model to transcribe the audio sample.
+
It uses Jupyter notebook/lab's ipywebrtc extension to record an audio sample on your web browser.
+
+
+
Attention
+
When you click the ⏺ botton, your web browser may show a pop-up to ask you to allow it to use your microphone. Be sure to allow the access.
+
+
+Final check
+
Once done, if you click on the "⚠ Not secure" part in the URL bar, you should see something like this.
+
+
+
+
Result
+
Once you go through all the steps, you should see the transcribe result in text like this.
The downloaded checkpoint file is stored on the /data/ directory that is mounted from the Docker host.
+
+
Run benchmark script
+
cd /opt/efficientvit
+python3 ./benchmark.py
+
+
At the end you should see a summary like the following.
+
AVERAGE of 2 runs:
+ encoder --- 0.062 sec
+ latency --- 0.083 sec
+Memory consumption : 3419.68 MB
+
+
Check the output/result
+
The output image file (of the last inference result) is stored as /data/benchmarks/efficientvit_sam_demo.png.
+
It is stored under /data/ directory that is mounted from the Docker host.
+So you can go back to your host machine, and check jetson-containers/data/benchmark/ directory.
FileNotFoundError: [Errno 2] No such file or directory: './checkpoints/E2FGVI-HQ-CVPR22.pth'
+
You may find the TAM app fails to download a checkpoint file E2FGVI-HQ-CVPR22.pth.
+
Downloading checkpoints from Google Drive... tips: If you cannot see the progress bar, please try to download it manuall and put it in the checkpointes directory. E2FGVI-HQ-CVPR22.pth: https://github.com/MCG-NKU/E2FGVI(E2FGVI-HQ model)
+Access denied with the following error:
+
+ Cannot retrieve the public link of the file. You may need to change
+ the permission to 'Anyone with the link', or have had many accesses.
+
+You may still be able to access the file from the browser:
+
+ https://drive.google.com/uc?id=10wGdKSUOie0XmCr8SQ2A2FeDe-mfn5w3
+
+
You can manually download the checkpoint file on your Docker host machine.
 |
|  |
| 









 +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  + Nurgaliyev Shakhizat - Vision2Audio: Blind Assistant Device
+
+ Nurgaliyev Shakhizat - Vision2Audio: Blind Assistant Device
+ _iHRjaZTew3.gif "ClearWater: Underwater Image Enhancement with Generative AI") + Vy Pham - ClearWater: Underwater Image Enhancement with Generative AI
+
+ Vy Pham - ClearWater: Underwater Image Enhancement with Generative AI
+  + Toshihiko Aoki - Japanese NMT Translation for Stable Diffusion
+
+ Toshihiko Aoki - Japanese NMT Translation for Stable Diffusion
+  +
+  +
+