diff --git a/.gitignore b/.gitignore
index 2296323..cc8be8e 100755
--- a/.gitignore
+++ b/.gitignore
@@ -16,6 +16,9 @@ ldm_ae*
data/*
*.pth
.gradio/
+*.bin
+*.safetensors
+*.pkl
# Byte-compiled / optimized / DLL files
__pycache__/
diff --git a/README.md b/README.md
index 2b73a42..1dbbbd0 100644
--- a/README.md
+++ b/README.md
@@ -36,7 +36,7 @@ As a result, Sana-0.6B is very competitive with modern giant diffusion model (e.
## 🔥🔥 News
-- (🔥 New) \[2024/12/18\] `diffusers` supports Sana-LoRA fine-tuning! Sana-LoRA's training and convergence speed is supper fast. [\[Guidance\]](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_sana.md). Thanks to [@paul](https://github.com/sayakpaul).
+- (🔥 New) \[2024/12/18\] `diffusers` supports Sana-LoRA fine-tuning! Sana-LoRA's training and convergence speed is supper fast. [\[Guidance\]](asset/docs/sana_lora_dreambooth.md) or [\[diffusers docs\]](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_sana.md).
- (🔥 New) \[2024/12/13\] `diffusers` has Sana! [All Sana models in diffusers safetensors](https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e) are released and diffusers pipeline `SanaPipeline`, `SanaPAGPipeline`, `DPMSolverMultistepScheduler(with FlowMatching)` are all supported now. We prepare a [Model Card](asset/docs/model_zoo.md) for you to choose.
- (🔥 New) \[2024/12/10\] 1.6B BF16 [Sana model](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16) is released for stable fine-tuning.
- (🔥 New) \[2024/12/9\] We release the [ComfyUI node](https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels) for Sana. [\[Guidance\]](asset/docs/ComfyUI/comfyui.md)
diff --git a/asset/docs/sana_lora_dreambooth.md b/asset/docs/sana_lora_dreambooth.md
index f64749e..e433dbf 100644
--- a/asset/docs/sana_lora_dreambooth.md
+++ b/asset/docs/sana_lora_dreambooth.md
@@ -22,12 +22,6 @@ cd diffusers
pip install -e .
```
-Then cd in the `examples/dreambooth` folder and run
-
-```bash
-pip install -r requirements_sana.txt
-```
-
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
@@ -59,7 +53,7 @@ Let's first download it locally:
```python
from huggingface_hub import snapshot_download
-local_dir = "./dog"
+local_dir = "data/dreambooth/dog"
snapshot_download(
"diffusers/dog-example",
local_dir=local_dir, repo_type="dataset",
@@ -71,14 +65,21 @@ This will also allow us to push the trained LoRA parameters to the Hugging Face
[Here is the Model Card](model_zoo.md) for you to choose the desired pre-trained models and set it to `MODEL_NAME`.
-Now, we can launch training using:
+Now, we can launch training using [file here](../../train_scripts/train_lora.sh):
+
+```bash
+bash train_scripts/train_lora.sh
+```
+
+or you can run it locally:
```bash
-export MODEL_NAME="Efficient-Large-Model/Sana_1600M_1024px_diffusers"
-export INSTANCE_DIR="dog"
+export MODEL_NAME="Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers"
+export INSTANCE_DIR="data/dreambooth/dog"
export OUTPUT_DIR="trained-sana-lora"
-accelerate launch train_dreambooth_lora_sana.py \
+accelerate launch --num_processes 8 --main_process_port 29500 --gpu_ids 0,1,2,3 \
+ train_scripts/train_dreambooth_lora_sana.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
@@ -93,7 +94,7 @@ accelerate launch train_dreambooth_lora_sana.py \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
- --validation_prompt="A photo of sks dog in a bucket" \
+ --validation_prompt="A photo of sks dog in a pond, yarn art style" \
--validation_epochs=25 \
--seed="0" \
--push_to_hub
@@ -125,3 +126,19 @@ We provide several options for optimizing memory optimization:
- `--use_8bit_adam`: When enabled, we will use the 8bit version of AdamW provided by the `bitsandbytes` library.
Refer to the [official documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/sana) of the `SanaPipeline` to know more about the models available under the SANA family and their preferred dtypes during inference.
+
+## Samples
+
+We show some samples during Sana-LoRA fine-tuning process below.
+
+
+ 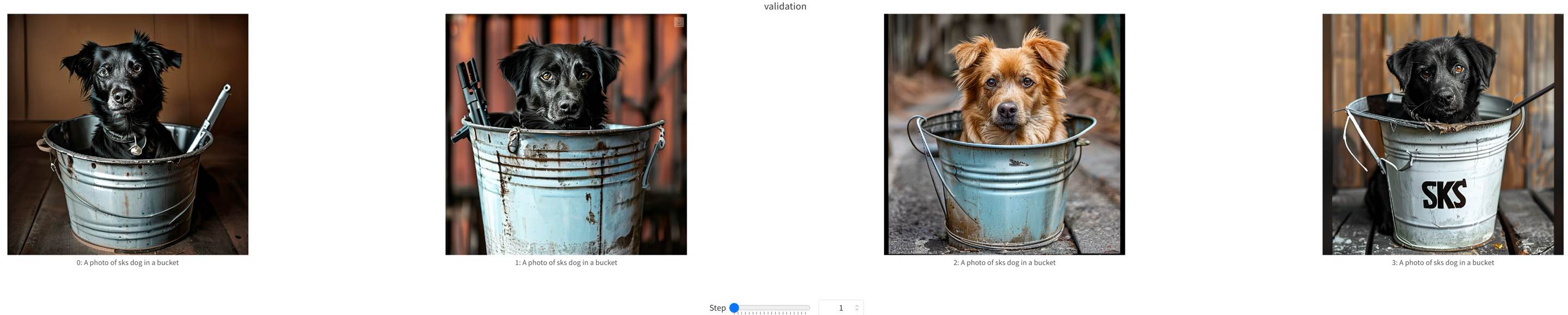 +
+
+ training samples at step=0
+
+
+
+ 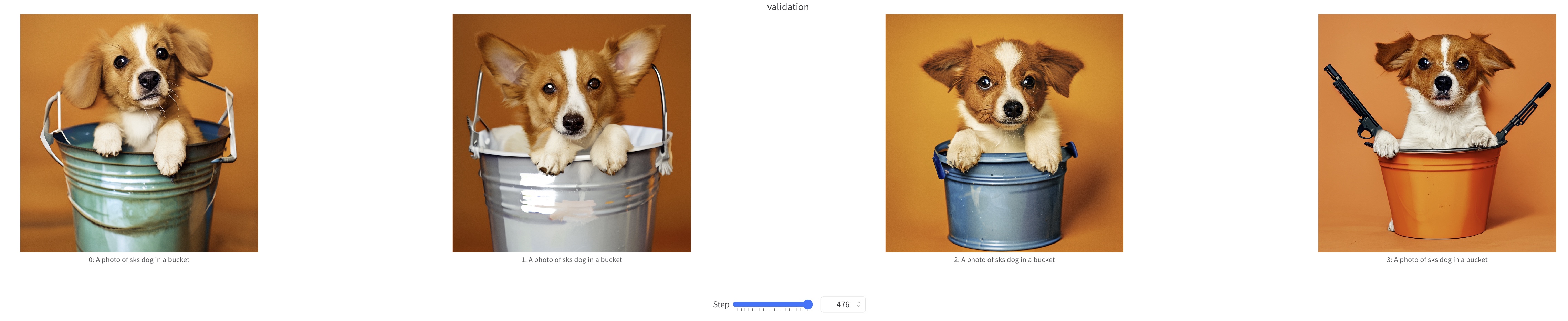 +
+
+ training samples at step=500
+
diff --git a/diffusion/data/datasets/sana_data.py b/diffusion/data/datasets/sana_data.py
index c361805..979d090 100755
--- a/diffusion/data/datasets/sana_data.py
+++ b/diffusion/data/datasets/sana_data.py
@@ -88,7 +88,7 @@ def __init__(
self.logger.info(f"Loading external caption json from: original_filename{external_caption_suffixes}.json")
self.logger.info(f"Loading external clipscore json from: original_filename{external_clipscore_suffixes}.json")
self.logger.info(f"external caption clipscore threshold: {clip_thr}, temperature: {clip_thr_temperature}")
- self.logger.info(f"T5 max token length: {self.max_length}")
+ self.logger.info(f"Text max token length: {self.max_length}")
def getdata(self, idx):
data = self.dataset[idx]
@@ -288,7 +288,7 @@ def __init__(
self.logger.info(f"Loading external caption json from: original_filename{external_caption_suffixes}.json")
self.logger.info(f"Loading external clipscore json from: original_filename{external_clipscore_suffixes}.json")
self.logger.info(f"external caption clipscore threshold: {clip_thr}, temperature: {clip_thr_temperature}")
- self.logger.info(f"T5 max token length: {self.max_length}")
+ self.logger.info(f"Text max token length: {self.max_length}")
self.logger.warning(f"Sort the dataset: {sort_dataset}")
def _initialize_dataset(self, num_replicas, sort_dataset):
diff --git a/train_scripts/train_dreambooth_lora_sana.py b/train_scripts/train_dreambooth_lora_sana.py
new file mode 100644
index 0000000..42b2e38
--- /dev/null
+++ b/train_scripts/train_dreambooth_lora_sana.py
@@ -0,0 +1,1537 @@
+#!/usr/bin/env python
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import argparse
+import copy
+import itertools
+import logging
+import math
+import os
+import random
+import shutil
+import warnings
+from pathlib import Path
+
+import diffusers
+import numpy as np
+import torch
+import torch.utils.checkpoint
+import transformers
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import DistributedDataParallelKwargs, ProjectConfiguration, set_seed
+from diffusers import AutoencoderDC, FlowMatchEulerDiscreteScheduler, SanaPipeline, SanaTransformer2DModel
+from diffusers.optimization import get_scheduler
+from diffusers.training_utils import (
+ cast_training_params,
+ compute_density_for_timestep_sampling,
+ compute_loss_weighting_for_sd3,
+ free_memory,
+)
+from diffusers.utils import check_min_version, convert_unet_state_dict_to_peft, is_wandb_available
+from diffusers.utils.hub_utils import load_or_create_model_card, populate_model_card
+from diffusers.utils.torch_utils import is_compiled_module
+from huggingface_hub import create_repo, upload_folder
+from huggingface_hub.utils import insecure_hashlib
+from peft import LoraConfig, set_peft_model_state_dict
+from peft.utils import get_peft_model_state_dict
+from PIL import Image
+from PIL.ImageOps import exif_transpose
+from torch.utils.data import Dataset
+from torchvision import transforms
+from torchvision.transforms.functional import crop
+from tqdm.auto import tqdm
+from transformers import AutoTokenizer, Gemma2Model
+
+if is_wandb_available():
+ import wandb
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.32.0.dev0")
+
+logger = get_logger(__name__)
+
+
+def save_model_card(
+ repo_id: str,
+ images=None,
+ base_model: str = None,
+ instance_prompt=None,
+ validation_prompt=None,
+ repo_folder=None,
+):
+ widget_dict = []
+ if images is not None:
+ for i, image in enumerate(images):
+ image.save(os.path.join(repo_folder, f"image_{i}.png"))
+ widget_dict.append(
+ {"text": validation_prompt if validation_prompt else " ", "output": {"url": f"image_{i}.png"}}
+ )
+
+ model_description = f"""
+# Sana DreamBooth LoRA - {repo_id}
+
+
+
+## Model description
+
+These are {repo_id} DreamBooth LoRA weights for {base_model}.
+
+The weights were trained using [DreamBooth](https://dreambooth.github.io/) with the [Sana diffusers trainer](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_sana.md).
+
+
+## Trigger words
+
+You should use `{instance_prompt}` to trigger the image generation.
+
+## Download model
+
+[Download the *.safetensors LoRA]({repo_id}/tree/main) in the Files & versions tab.
+
+## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
+
+```py
+TODO
+```
+
+For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
+
+## License
+
+TODO
+"""
+ model_card = load_or_create_model_card(
+ repo_id_or_path=repo_id,
+ from_training=True,
+ license="other",
+ base_model=base_model,
+ prompt=instance_prompt,
+ model_description=model_description,
+ widget=widget_dict,
+ )
+ tags = [
+ "text-to-image",
+ "diffusers-training",
+ "diffusers",
+ "lora",
+ "sana",
+ "sana-diffusers",
+ "template:sd-lora",
+ ]
+
+ model_card = populate_model_card(model_card, tags=tags)
+ model_card.save(os.path.join(repo_folder, "README.md"))
+
+
+def log_validation(
+ pipeline,
+ args,
+ accelerator,
+ pipeline_args,
+ epoch,
+ is_final_validation=False,
+):
+ logger.info(
+ f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
+ f" {args.validation_prompt}."
+ )
+ pipeline.text_encoder = pipeline.text_encoder.to(torch.bfloat16)
+ pipeline = pipeline.to(accelerator.device)
+ pipeline.set_progress_bar_config(disable=True)
+
+ # run inference
+ generator = torch.Generator(device=accelerator.device).manual_seed(args.seed) if args.seed else None
+
+ images = [pipeline(**pipeline_args, generator=generator).images[0] for _ in range(args.num_validation_images)]
+
+ for tracker in accelerator.trackers:
+ phase_name = "test" if is_final_validation else "validation"
+ if tracker.name == "tensorboard":
+ np_images = np.stack([np.asarray(img) for img in images])
+ tracker.writer.add_images(phase_name, np_images, epoch, dataformats="NHWC")
+ if tracker.name == "wandb":
+ tracker.log(
+ {
+ phase_name: [
+ wandb.Image(image, caption=f"{i}: {args.validation_prompt}") for i, image in enumerate(images)
+ ]
+ }
+ )
+
+ del pipeline
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+
+ return images
+
+
+def parse_args(input_args=None):
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--variant",
+ type=str,
+ default=None,
+ help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help=(
+ "The name of the Dataset (from the HuggingFace hub) containing the training data of instance images (could be your own, possibly private,"
+ " dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
+ " or to a folder containing files that 🤗 Datasets can understand."
+ ),
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The config of the Dataset, leave as None if there's only one config.",
+ )
+ parser.add_argument(
+ "--instance_data_dir",
+ type=str,
+ default=None,
+ help=("A folder containing the training data. "),
+ )
+
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ default=None,
+ help="The directory where the downloaded models and datasets will be stored.",
+ )
+
+ parser.add_argument(
+ "--image_column",
+ type=str,
+ default="image",
+ help="The column of the dataset containing the target image. By "
+ "default, the standard Image Dataset maps out 'file_name' "
+ "to 'image'.",
+ )
+ parser.add_argument(
+ "--caption_column",
+ type=str,
+ default=None,
+ help="The column of the dataset containing the instance prompt for each image",
+ )
+
+ parser.add_argument("--repeats", type=int, default=1, help="How many times to repeat the training data.")
+
+ parser.add_argument(
+ "--class_data_dir",
+ type=str,
+ default=None,
+ required=False,
+ help="A folder containing the training data of class images.",
+ )
+ parser.add_argument(
+ "--instance_prompt",
+ type=str,
+ default=None,
+ required=True,
+ help="The prompt with identifier specifying the instance, e.g. 'photo of a TOK dog', 'in the style of TOK'",
+ )
+ parser.add_argument(
+ "--class_prompt",
+ type=str,
+ default=None,
+ help="The prompt to specify images in the same class as provided instance images.",
+ )
+ parser.add_argument(
+ "--max_sequence_length",
+ type=int,
+ default=300,
+ help="Maximum sequence length to use with with the Gemma model",
+ )
+ parser.add_argument(
+ "--complex_human_instruction",
+ type=str,
+ default=None,
+ help="Instructions for complex human attention: https://github.com/NVlabs/Sana/blob/main/configs/sana_app_config/Sana_1600M_app.yaml#L55.",
+ )
+ parser.add_argument(
+ "--validation_prompt",
+ type=str,
+ default=None,
+ help="A prompt that is used during validation to verify that the model is learning.",
+ )
+ parser.add_argument(
+ "--num_validation_images",
+ type=int,
+ default=4,
+ help="Number of images that should be generated during validation with `validation_prompt`.",
+ )
+ parser.add_argument(
+ "--validation_epochs",
+ type=int,
+ default=50,
+ help=(
+ "Run dreambooth validation every X epochs. Dreambooth validation consists of running the prompt"
+ " `args.validation_prompt` multiple times: `args.num_validation_images`."
+ ),
+ )
+ parser.add_argument(
+ "--rank",
+ type=int,
+ default=4,
+ help=("The dimension of the LoRA update matrices."),
+ )
+ parser.add_argument(
+ "--with_prior_preservation",
+ default=False,
+ action="store_true",
+ help="Flag to add prior preservation loss.",
+ )
+ parser.add_argument("--prior_loss_weight", type=float, default=1.0, help="The weight of prior preservation loss.")
+ parser.add_argument(
+ "--num_class_images",
+ type=int,
+ default=100,
+ help=(
+ "Minimal class images for prior preservation loss. If there are not enough images already present in"
+ " class_data_dir, additional images will be sampled with class_prompt."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="sana-dreambooth-lora",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument(
+ "--random_flip",
+ action="store_true",
+ help="whether to randomly flip images horizontally",
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images.")
+ parser.add_argument("--num_train_epochs", type=int, default=1)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints can be used both as final"
+ " checkpoints in case they are better than the last checkpoint, and are also suitable for resuming"
+ " training using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=("Max number of checkpoints to store."),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--lr_num_cycles",
+ type=int,
+ default=1,
+ help="Number of hard resets of the lr in cosine_with_restarts scheduler.",
+ )
+ parser.add_argument("--lr_power", type=float, default=1.0, help="Power factor of the polynomial scheduler.")
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=0,
+ help=(
+ "Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
+ ),
+ )
+ parser.add_argument(
+ "--weighting_scheme",
+ type=str,
+ default="none",
+ choices=["sigma_sqrt", "logit_normal", "mode", "cosmap", "none"],
+ help=('We default to the "none" weighting scheme for uniform sampling and uniform loss'),
+ )
+ parser.add_argument(
+ "--logit_mean", type=float, default=0.0, help="mean to use when using the `'logit_normal'` weighting scheme."
+ )
+ parser.add_argument(
+ "--logit_std", type=float, default=1.0, help="std to use when using the `'logit_normal'` weighting scheme."
+ )
+ parser.add_argument(
+ "--mode_scale",
+ type=float,
+ default=1.29,
+ help="Scale of mode weighting scheme. Only effective when using the `'mode'` as the `weighting_scheme`.",
+ )
+ parser.add_argument(
+ "--optimizer",
+ type=str,
+ default="AdamW",
+ help=('The optimizer type to use. Choose between ["AdamW", "prodigy"]'),
+ )
+
+ parser.add_argument(
+ "--use_8bit_adam",
+ action="store_true",
+ help="Whether or not to use 8-bit Adam from bitsandbytes. Ignored if optimizer is not set to AdamW",
+ )
+
+ parser.add_argument(
+ "--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam and Prodigy optimizers."
+ )
+ parser.add_argument(
+ "--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam and Prodigy optimizers."
+ )
+ parser.add_argument(
+ "--prodigy_beta3",
+ type=float,
+ default=None,
+ help="coefficients for computing the Prodigy stepsize using running averages. If set to None, "
+ "uses the value of square root of beta2. Ignored if optimizer is adamW",
+ )
+ parser.add_argument("--prodigy_decouple", type=bool, default=True, help="Use AdamW style decoupled weight decay")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-04, help="Weight decay to use for unet params")
+ parser.add_argument(
+ "--adam_weight_decay_text_encoder", type=float, default=1e-03, help="Weight decay to use for text_encoder"
+ )
+
+ parser.add_argument(
+ "--lora_layers",
+ type=str,
+ default=None,
+ help=(
+ 'The transformer modules to apply LoRA training on. Please specify the layers in a comma seperated. E.g. - "to_k,to_q,to_v" will result in lora training of attention layers only'
+ ),
+ )
+
+ parser.add_argument(
+ "--adam_epsilon",
+ type=float,
+ default=1e-08,
+ help="Epsilon value for the Adam optimizer and Prodigy optimizers.",
+ )
+
+ parser.add_argument(
+ "--prodigy_use_bias_correction",
+ type=bool,
+ default=True,
+ help="Turn on Adam's bias correction. True by default. Ignored if optimizer is adamW",
+ )
+ parser.add_argument(
+ "--prodigy_safeguard_warmup",
+ type=bool,
+ default=True,
+ help="Remove lr from the denominator of D estimate to avoid issues during warm-up stage. True by default. "
+ "Ignored if optimizer is adamW",
+ )
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--allow_tf32",
+ action="store_true",
+ help=(
+ "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
+ " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
+ ),
+ )
+ parser.add_argument(
+ "--cache_latents",
+ action="store_true",
+ default=False,
+ help="Cache the VAE latents",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="tensorboard",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default=None,
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
+ " 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
+ " flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
+ ),
+ )
+ parser.add_argument(
+ "--upcast_before_saving",
+ action="store_true",
+ default=False,
+ help=(
+ "Whether to upcast the trained transformer layers to float32 before saving (at the end of training). "
+ "Defaults to precision dtype used for training to save memory"
+ ),
+ )
+ parser.add_argument(
+ "--offload",
+ action="store_true",
+ help="Whether to offload the VAE and the text encoder to CPU when they are not used.",
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+
+ if input_args is not None:
+ args = parser.parse_args(input_args)
+ else:
+ args = parser.parse_args()
+
+ if args.dataset_name is None and args.instance_data_dir is None:
+ raise ValueError("Specify either `--dataset_name` or `--instance_data_dir`")
+
+ if args.dataset_name is not None and args.instance_data_dir is not None:
+ raise ValueError("Specify only one of `--dataset_name` or `--instance_data_dir`")
+
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.with_prior_preservation:
+ if args.class_data_dir is None:
+ raise ValueError("You must specify a data directory for class images.")
+ if args.class_prompt is None:
+ raise ValueError("You must specify prompt for class images.")
+ else:
+ # logger is not available yet
+ if args.class_data_dir is not None:
+ warnings.warn("You need not use --class_data_dir without --with_prior_preservation.")
+ if args.class_prompt is not None:
+ warnings.warn("You need not use --class_prompt without --with_prior_preservation.")
+
+ return args
+
+
+class DreamBoothDataset(Dataset):
+ """
+ A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
+ It pre-processes the images.
+ """
+
+ def __init__(
+ self,
+ instance_data_root,
+ instance_prompt,
+ class_prompt,
+ class_data_root=None,
+ class_num=None,
+ size=1024,
+ repeats=1,
+ center_crop=False,
+ ):
+ self.size = size
+ self.center_crop = center_crop
+
+ self.instance_prompt = instance_prompt
+ self.custom_instance_prompts = None
+ self.class_prompt = class_prompt
+
+ # if --dataset_name is provided or a metadata jsonl file is provided in the local --instance_data directory,
+ # we load the training data using load_dataset
+ if args.dataset_name is not None:
+ try:
+ from datasets import load_dataset
+ except ImportError:
+ raise ImportError(
+ "You are trying to load your data using the datasets library. If you wish to train using custom "
+ "captions please install the datasets library: `pip install datasets`. If you wish to load a "
+ "local folder containing images only, specify --instance_data_dir instead."
+ )
+ # Downloading and loading a dataset from the hub.
+ # See more about loading custom images at
+ # https://huggingface.co/docs/datasets/v2.0.0/en/dataset_script
+ dataset = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ cache_dir=args.cache_dir,
+ )
+ # Preprocessing the datasets.
+ column_names = dataset["train"].column_names
+
+ # 6. Get the column names for input/target.
+ if args.image_column is None:
+ image_column = column_names[0]
+ logger.info(f"image column defaulting to {image_column}")
+ else:
+ image_column = args.image_column
+ if image_column not in column_names:
+ raise ValueError(
+ f"`--image_column` value '{args.image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
+ )
+ instance_images = dataset["train"][image_column]
+
+ if args.caption_column is None:
+ logger.info(
+ "No caption column provided, defaulting to instance_prompt for all images. If your dataset "
+ "contains captions/prompts for the images, make sure to specify the "
+ "column as --caption_column"
+ )
+ self.custom_instance_prompts = None
+ else:
+ if args.caption_column not in column_names:
+ raise ValueError(
+ f"`--caption_column` value '{args.caption_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
+ )
+ custom_instance_prompts = dataset["train"][args.caption_column]
+ # create final list of captions according to --repeats
+ self.custom_instance_prompts = []
+ for caption in custom_instance_prompts:
+ self.custom_instance_prompts.extend(itertools.repeat(caption, repeats))
+ else:
+ self.instance_data_root = Path(instance_data_root)
+ if not self.instance_data_root.exists():
+ raise ValueError("Instance images root doesn't exists.")
+
+ instance_images = [Image.open(path) for path in list(Path(instance_data_root).iterdir())]
+ self.custom_instance_prompts = None
+
+ self.instance_images = []
+ for img in instance_images:
+ self.instance_images.extend(itertools.repeat(img, repeats))
+
+ self.pixel_values = []
+ train_resize = transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR)
+ train_crop = transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size)
+ train_flip = transforms.RandomHorizontalFlip(p=1.0)
+ train_transforms = transforms.Compose(
+ [
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+ for image in self.instance_images:
+ image = exif_transpose(image)
+ if not image.mode == "RGB":
+ image = image.convert("RGB")
+ image = train_resize(image)
+ if args.random_flip and random.random() < 0.5:
+ # flip
+ image = train_flip(image)
+ if args.center_crop:
+ y1 = max(0, int(round((image.height - args.resolution) / 2.0)))
+ x1 = max(0, int(round((image.width - args.resolution) / 2.0)))
+ image = train_crop(image)
+ else:
+ y1, x1, h, w = train_crop.get_params(image, (args.resolution, args.resolution))
+ image = crop(image, y1, x1, h, w)
+ image = train_transforms(image)
+ self.pixel_values.append(image)
+
+ self.num_instance_images = len(self.instance_images)
+ self._length = self.num_instance_images
+
+ if class_data_root is not None:
+ self.class_data_root = Path(class_data_root)
+ self.class_data_root.mkdir(parents=True, exist_ok=True)
+ self.class_images_path = list(self.class_data_root.iterdir())
+ if class_num is not None:
+ self.num_class_images = min(len(self.class_images_path), class_num)
+ else:
+ self.num_class_images = len(self.class_images_path)
+ self._length = max(self.num_class_images, self.num_instance_images)
+ else:
+ self.class_data_root = None
+
+ self.image_transforms = transforms.Compose(
+ [
+ transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, index):
+ example = {}
+ instance_image = self.pixel_values[index % self.num_instance_images]
+ example["instance_images"] = instance_image
+
+ if self.custom_instance_prompts:
+ caption = self.custom_instance_prompts[index % self.num_instance_images]
+ if caption:
+ example["instance_prompt"] = caption
+ else:
+ example["instance_prompt"] = self.instance_prompt
+
+ else: # custom prompts were provided, but length does not match size of image dataset
+ example["instance_prompt"] = self.instance_prompt
+
+ if self.class_data_root:
+ class_image = Image.open(self.class_images_path[index % self.num_class_images])
+ class_image = exif_transpose(class_image)
+
+ if not class_image.mode == "RGB":
+ class_image = class_image.convert("RGB")
+ example["class_images"] = self.image_transforms(class_image)
+ example["class_prompt"] = self.class_prompt
+
+ return example
+
+
+def collate_fn(examples, with_prior_preservation=False):
+ pixel_values = [example["instance_images"] for example in examples]
+ prompts = [example["instance_prompt"] for example in examples]
+
+ # Concat class and instance examples for prior preservation.
+ # We do this to avoid doing two forward passes.
+ if with_prior_preservation:
+ pixel_values += [example["class_images"] for example in examples]
+ prompts += [example["class_prompt"] for example in examples]
+
+ pixel_values = torch.stack(pixel_values)
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+
+ batch = {"pixel_values": pixel_values, "prompts": prompts}
+ return batch
+
+
+class PromptDataset(Dataset):
+ "A simple dataset to prepare the prompts to generate class images on multiple GPUs."
+
+ def __init__(self, prompt, num_samples):
+ self.prompt = prompt
+ self.num_samples = num_samples
+
+ def __len__(self):
+ return self.num_samples
+
+ def __getitem__(self, index):
+ example = {}
+ example["prompt"] = self.prompt
+ example["index"] = index
+ return example
+
+
+def main(args):
+ if args.report_to == "wandb" and args.hub_token is not None:
+ raise ValueError(
+ "You cannot use both --report_to=wandb and --hub_token due to a security risk of exposing your token."
+ " Please use `huggingface-cli login` to authenticate with the Hub."
+ )
+
+ if torch.backends.mps.is_available() and args.mixed_precision == "bf16":
+ # due to pytorch#99272, MPS does not yet support bfloat16.
+ raise ValueError(
+ "Mixed precision training with bfloat16 is not supported on MPS. Please use fp16 (recommended) or fp32 instead."
+ )
+
+ logging_dir = Path(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
+ kwargs = DistributedDataParallelKwargs(find_unused_parameters=True)
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ project_config=accelerator_project_config,
+ kwargs_handlers=[kwargs],
+ )
+
+ # Disable AMP for MPS.
+ if torch.backends.mps.is_available():
+ accelerator.native_amp = False
+
+ if args.report_to == "wandb":
+ if not is_wandb_available():
+ raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ transformers.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ transformers.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Generate class images if prior preservation is enabled.
+ if args.with_prior_preservation:
+ class_images_dir = Path(args.class_data_dir)
+ if not class_images_dir.exists():
+ class_images_dir.mkdir(parents=True)
+ cur_class_images = len(list(class_images_dir.iterdir()))
+
+ if cur_class_images < args.num_class_images:
+ pipeline = SanaPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ torch_dtype=torch.float32,
+ revision=args.revision,
+ variant=args.variant,
+ )
+ pipeline.text_encoder = pipeline.text_encoder.to(torch.bfloat16)
+ pipeline.transformer = pipeline.transformer.to(torch.float16)
+ pipeline.set_progress_bar_config(disable=True)
+
+ num_new_images = args.num_class_images - cur_class_images
+ logger.info(f"Number of class images to sample: {num_new_images}.")
+
+ sample_dataset = PromptDataset(args.class_prompt, num_new_images)
+ sample_dataloader = torch.utils.data.DataLoader(sample_dataset, batch_size=args.sample_batch_size)
+
+ sample_dataloader = accelerator.prepare(sample_dataloader)
+ pipeline.to(accelerator.device)
+
+ for example in tqdm(
+ sample_dataloader, desc="Generating class images", disable=not accelerator.is_local_main_process
+ ):
+ images = pipeline(example["prompt"]).images
+
+ for i, image in enumerate(images):
+ hash_image = insecure_hashlib.sha1(image.tobytes()).hexdigest()
+ image_filename = class_images_dir / f"{example['index'][i] + cur_class_images}-{hash_image}.jpg"
+ image.save(image_filename)
+
+ del pipeline
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name,
+ exist_ok=True,
+ private=True,
+ ).repo_id
+
+ # Load the tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.pretrained_model_name_or_path,
+ subfolder="tokenizer",
+ revision=args.revision,
+ )
+
+ # Load scheduler and models
+ noise_scheduler = FlowMatchEulerDiscreteScheduler.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="scheduler"
+ )
+ noise_scheduler_copy = copy.deepcopy(noise_scheduler)
+ text_encoder = Gemma2Model.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision, variant=args.variant
+ )
+ vae = AutoencoderDC.from_pretrained(
+ args.pretrained_model_name_or_path,
+ subfolder="vae",
+ revision=args.revision,
+ variant=args.variant,
+ )
+ transformer = SanaTransformer2DModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="transformer", revision=args.revision, variant=args.variant
+ )
+
+ # We only train the additional adapter LoRA layers
+ transformer.requires_grad_(False)
+ vae.requires_grad_(False)
+ text_encoder.requires_grad_(False)
+
+ # Initialize a text encoding pipeline and keep it to CPU for now.
+ text_encoding_pipeline = SanaPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ vae=None,
+ transformer=None,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ )
+
+ # For mixed precision training we cast all non-trainable weights (vae, text_encoder and transformer) to half-precision
+ # as these weights are only used for inference, keeping weights in full precision is not required.
+ weight_dtype = torch.float32
+ if accelerator.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif accelerator.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ if torch.backends.mps.is_available() and weight_dtype == torch.bfloat16:
+ # due to pytorch#99272, MPS does not yet support bfloat16.
+ raise ValueError(
+ "Mixed precision training with bfloat16 is not supported on MPS. Please use fp16 (recommended) or fp32 instead."
+ )
+
+ # VAE should always be kept in fp32 for SANA (?)
+ vae.to(dtype=torch.float32)
+ transformer.to(accelerator.device, dtype=weight_dtype)
+ # because Gemma2 is particularly suited for bfloat16.
+ text_encoder.to(dtype=torch.bfloat16)
+
+ if args.gradient_checkpointing:
+ transformer.enable_gradient_checkpointing()
+
+ if args.lora_layers is not None:
+ target_modules = [layer.strip() for layer in args.lora_layers.split(",")]
+ else:
+ target_modules = ["to_k", "to_q", "to_v"]
+
+ # now we will add new LoRA weights the transformer layers
+ transformer_lora_config = LoraConfig(
+ r=args.rank,
+ lora_alpha=args.rank,
+ init_lora_weights="gaussian",
+ target_modules=target_modules,
+ )
+ transformer.add_adapter(transformer_lora_config)
+
+ def unwrap_model(model):
+ model = accelerator.unwrap_model(model)
+ model = model._orig_mod if is_compiled_module(model) else model
+ return model
+
+ # create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
+ def save_model_hook(models, weights, output_dir):
+ if accelerator.is_main_process:
+ transformer_lora_layers_to_save = None
+
+ for model in models:
+ if isinstance(model, type(unwrap_model(transformer))):
+ transformer_lora_layers_to_save = get_peft_model_state_dict(model)
+ else:
+ raise ValueError(f"unexpected save model: {model.__class__}")
+
+ # make sure to pop weight so that corresponding model is not saved again
+ weights.pop()
+
+ SanaPipeline.save_lora_weights(
+ output_dir,
+ transformer_lora_layers=transformer_lora_layers_to_save,
+ )
+
+ def load_model_hook(models, input_dir):
+ transformer_ = None
+
+ while len(models) > 0:
+ model = models.pop()
+
+ if isinstance(model, type(unwrap_model(transformer))):
+ transformer_ = model
+ else:
+ raise ValueError(f"unexpected save model: {model.__class__}")
+
+ lora_state_dict = SanaPipeline.lora_state_dict(input_dir)
+
+ transformer_state_dict = {
+ f'{k.replace("transformer.", "")}': v for k, v in lora_state_dict.items() if k.startswith("transformer.")
+ }
+ transformer_state_dict = convert_unet_state_dict_to_peft(transformer_state_dict)
+ incompatible_keys = set_peft_model_state_dict(transformer_, transformer_state_dict, adapter_name="default")
+ if incompatible_keys is not None:
+ # check only for unexpected keys
+ unexpected_keys = getattr(incompatible_keys, "unexpected_keys", None)
+ if unexpected_keys:
+ logger.warning(
+ f"Loading adapter weights from state_dict led to unexpected keys not found in the model: "
+ f" {unexpected_keys}. "
+ )
+
+ # Make sure the trainable params are in float32. This is again needed since the base models
+ # are in `weight_dtype`. More details:
+ # https://github.com/huggingface/diffusers/pull/6514#discussion_r1449796804
+ if args.mixed_precision == "fp16":
+ models = [transformer_]
+ # only upcast trainable parameters (LoRA) into fp32
+ cast_training_params(models)
+
+ accelerator.register_save_state_pre_hook(save_model_hook)
+ accelerator.register_load_state_pre_hook(load_model_hook)
+
+ # Enable TF32 for faster training on Ampere GPUs,
+ # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
+ if args.allow_tf32 and torch.cuda.is_available():
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Make sure the trainable params are in float32.
+ if args.mixed_precision == "fp16":
+ models = [transformer]
+ # only upcast trainable parameters (LoRA) into fp32
+ cast_training_params(models, dtype=torch.float32)
+
+ transformer_lora_parameters = list(filter(lambda p: p.requires_grad, transformer.parameters()))
+
+ # Optimization parameters
+ transformer_parameters_with_lr = {"params": transformer_lora_parameters, "lr": args.learning_rate}
+ params_to_optimize = [transformer_parameters_with_lr]
+
+ # Optimizer creation
+ if not (args.optimizer.lower() == "prodigy" or args.optimizer.lower() == "adamw"):
+ logger.warning(
+ f"Unsupported choice of optimizer: {args.optimizer}.Supported optimizers include [adamW, prodigy]."
+ "Defaulting to adamW"
+ )
+ args.optimizer = "adamw"
+
+ if args.use_8bit_adam and not args.optimizer.lower() == "adamw":
+ logger.warning(
+ f"use_8bit_adam is ignored when optimizer is not set to 'AdamW'. Optimizer was "
+ f"set to {args.optimizer.lower()}"
+ )
+
+ if args.optimizer.lower() == "adamw":
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
+ )
+
+ optimizer_class = bnb.optim.AdamW8bit
+ else:
+ optimizer_class = torch.optim.AdamW
+
+ optimizer = optimizer_class(
+ params_to_optimize,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ if args.optimizer.lower() == "prodigy":
+ try:
+ import prodigyopt
+ except ImportError:
+ raise ImportError("To use Prodigy, please install the prodigyopt library: `pip install prodigyopt`")
+
+ optimizer_class = prodigyopt.Prodigy
+
+ if args.learning_rate <= 0.1:
+ logger.warning(
+ "Learning rate is too low. When using prodigy, it's generally better to set learning rate around 1.0"
+ )
+
+ optimizer = optimizer_class(
+ params_to_optimize,
+ betas=(args.adam_beta1, args.adam_beta2),
+ beta3=args.prodigy_beta3,
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ decouple=args.prodigy_decouple,
+ use_bias_correction=args.prodigy_use_bias_correction,
+ safeguard_warmup=args.prodigy_safeguard_warmup,
+ )
+
+ # Dataset and DataLoaders creation:
+ train_dataset = DreamBoothDataset(
+ instance_data_root=args.instance_data_dir,
+ instance_prompt=args.instance_prompt,
+ class_prompt=args.class_prompt,
+ class_data_root=args.class_data_dir if args.with_prior_preservation else None,
+ class_num=args.num_class_images,
+ size=args.resolution,
+ repeats=args.repeats,
+ center_crop=args.center_crop,
+ )
+
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset,
+ batch_size=args.train_batch_size,
+ shuffle=True,
+ collate_fn=lambda examples: collate_fn(examples, args.with_prior_preservation),
+ num_workers=args.dataloader_num_workers,
+ )
+
+ def compute_text_embeddings(prompt, text_encoding_pipeline):
+ text_encoding_pipeline = text_encoding_pipeline.to(accelerator.device)
+ with torch.no_grad():
+ prompt_embeds, prompt_attention_mask, _, _ = text_encoding_pipeline.encode_prompt(
+ prompt,
+ max_sequence_length=args.max_sequence_length,
+ complex_human_instruction=args.complex_human_instruction,
+ )
+ if args.offload:
+ text_encoding_pipeline = text_encoding_pipeline.to("cpu")
+ return prompt_embeds, prompt_attention_mask
+
+ # If no type of tuning is done on the text_encoder and custom instance prompts are NOT
+ # provided (i.e. the --instance_prompt is used for all images), we encode the instance prompt once to avoid
+ # the redundant encoding.
+ if not train_dataset.custom_instance_prompts:
+ instance_prompt_hidden_states, instance_prompt_attention_mask = compute_text_embeddings(
+ args.instance_prompt, text_encoding_pipeline
+ )
+
+ # Handle class prompt for prior-preservation.
+ if args.with_prior_preservation:
+ class_prompt_hidden_states, class_prompt_attention_mask = compute_text_embeddings(
+ args.class_prompt, text_encoding_pipeline
+ )
+
+ # Clear the memory here
+ if not train_dataset.custom_instance_prompts:
+ del text_encoder, tokenizer
+ free_memory()
+
+ # If custom instance prompts are NOT provided (i.e. the instance prompt is used for all images),
+ # pack the statically computed variables appropriately here. This is so that we don't
+ # have to pass them to the dataloader.
+ if not train_dataset.custom_instance_prompts:
+ prompt_embeds = instance_prompt_hidden_states
+ prompt_attention_mask = instance_prompt_attention_mask
+ if args.with_prior_preservation:
+ prompt_embeds = torch.cat([prompt_embeds, class_prompt_hidden_states], dim=0)
+ prompt_attention_mask = torch.cat([prompt_attention_mask, class_prompt_attention_mask], dim=0)
+
+ vae_config_scaling_factor = vae.config.scaling_factor
+ if args.cache_latents:
+ latents_cache = []
+ vae = vae.to("cuda")
+ for batch in tqdm(train_dataloader, desc="Caching latents"):
+ with torch.no_grad():
+ batch["pixel_values"] = batch["pixel_values"].to(accelerator.device, non_blocking=True, dtype=vae.dtype)
+ latents_cache.append(vae.encode(batch["pixel_values"]).latent)
+
+ if args.validation_prompt is None:
+ del vae
+ free_memory()
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps * accelerator.num_processes,
+ num_cycles=args.lr_num_cycles,
+ power=args.lr_power,
+ )
+
+ # Prepare everything with our `accelerator`.
+ transformer, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ transformer, optimizer, train_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ tracker_name = "dreambooth-sana-lora"
+ accelerator.init_trackers(tracker_name, config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num batches each epoch = {len(train_dataloader)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ global_step = 0
+ first_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the mos recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ initial_global_step = 0
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ initial_global_step = global_step
+ first_epoch = global_step // num_update_steps_per_epoch
+
+ else:
+ initial_global_step = 0
+
+ progress_bar = tqdm(
+ range(0, args.max_train_steps),
+ initial=initial_global_step,
+ desc="Steps",
+ # Only show the progress bar once on each machine.
+ disable=not accelerator.is_local_main_process,
+ )
+
+ def get_sigmas(timesteps, n_dim=4, dtype=torch.float32):
+ sigmas = noise_scheduler_copy.sigmas.to(device=accelerator.device, dtype=dtype)
+ schedule_timesteps = noise_scheduler_copy.timesteps.to(accelerator.device)
+ timesteps = timesteps.to(accelerator.device)
+ step_indices = [(schedule_timesteps == t).nonzero().item() for t in timesteps]
+
+ sigma = sigmas[step_indices].flatten()
+ while len(sigma.shape) < n_dim:
+ sigma = sigma.unsqueeze(-1)
+ return sigma
+
+ for epoch in range(first_epoch, args.num_train_epochs):
+ transformer.train()
+
+ for step, batch in enumerate(train_dataloader):
+ models_to_accumulate = [transformer]
+ with accelerator.accumulate(models_to_accumulate):
+ prompts = batch["prompts"]
+
+ # encode batch prompts when custom prompts are provided for each image -
+ if train_dataset.custom_instance_prompts:
+ prompt_embeds, prompt_attention_mask = compute_text_embeddings(prompts, text_encoding_pipeline)
+
+ # Convert images to latent space
+ if args.cache_latents:
+ model_input = latents_cache[step]
+ else:
+ vae = vae.to(accelerator.device)
+ pixel_values = batch["pixel_values"].to(dtype=vae.dtype)
+ model_input = vae.encode(pixel_values).latent
+ if args.offload:
+ vae = vae.to("cpu")
+ model_input = model_input * vae_config_scaling_factor
+ model_input = model_input.to(dtype=weight_dtype)
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(model_input)
+ bsz = model_input.shape[0]
+
+ # Sample a random timestep for each image
+ # for weighting schemes where we sample timesteps non-uniformly
+ u = compute_density_for_timestep_sampling(
+ weighting_scheme=args.weighting_scheme,
+ batch_size=bsz,
+ logit_mean=args.logit_mean,
+ logit_std=args.logit_std,
+ mode_scale=args.mode_scale,
+ )
+ indices = (u * noise_scheduler_copy.config.num_train_timesteps).long()
+ timesteps = noise_scheduler_copy.timesteps[indices].to(device=model_input.device)
+
+ # Add noise according to flow matching.
+ # zt = (1 - texp) * x + texp * z1
+ sigmas = get_sigmas(timesteps, n_dim=model_input.ndim, dtype=model_input.dtype)
+ noisy_model_input = (1.0 - sigmas) * model_input + sigmas * noise
+
+ # Predict the noise residual
+ model_pred = transformer(
+ hidden_states=noisy_model_input,
+ encoder_hidden_states=prompt_embeds,
+ encoder_attention_mask=prompt_attention_mask,
+ timestep=timesteps,
+ return_dict=False,
+ )[0]
+
+ # these weighting schemes use a uniform timestep sampling
+ # and instead post-weight the loss
+ weighting = compute_loss_weighting_for_sd3(weighting_scheme=args.weighting_scheme, sigmas=sigmas)
+
+ # flow matching loss
+ target = noise - model_input
+
+ if args.with_prior_preservation:
+ # Chunk the noise and model_pred into two parts and compute the loss on each part separately.
+ model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0)
+ target, target_prior = torch.chunk(target, 2, dim=0)
+
+ # Compute prior loss
+ prior_loss = torch.mean(
+ (weighting.float() * (model_pred_prior.float() - target_prior.float()) ** 2).reshape(
+ target_prior.shape[0], -1
+ ),
+ 1,
+ )
+ prior_loss = prior_loss.mean()
+
+ # Compute regular loss.
+ loss = torch.mean(
+ (weighting.float() * (model_pred.float() - target.float()) ** 2).reshape(target.shape[0], -1),
+ 1,
+ )
+ loss = loss.mean()
+
+ if args.with_prior_preservation:
+ # Add the prior loss to the instance loss.
+ loss = loss + args.prior_loss_weight * prior_loss
+
+ accelerator.backward(loss)
+ if accelerator.sync_gradients:
+ params_to_clip = transformer.parameters()
+ accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+
+ if accelerator.is_main_process:
+ if global_step % args.checkpointing_steps == 0:
+ # _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
+ if args.checkpoints_total_limit is not None:
+ checkpoints = os.listdir(args.output_dir)
+ checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
+ checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
+
+ # before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
+ if len(checkpoints) >= args.checkpoints_total_limit:
+ num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
+ removing_checkpoints = checkpoints[0:num_to_remove]
+
+ logger.info(
+ f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
+ )
+ logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
+
+ for removing_checkpoint in removing_checkpoints:
+ removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
+ shutil.rmtree(removing_checkpoint)
+
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+ accelerator.log(logs, step=global_step)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ if accelerator.is_main_process:
+ if args.validation_prompt is not None and epoch % args.validation_epochs == 0:
+ # create pipeline
+ pipeline = SanaPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ transformer=accelerator.unwrap_model(transformer),
+ revision=args.revision,
+ variant=args.variant,
+ torch_dtype=torch.float32,
+ )
+ pipeline_args = {
+ "prompt": args.validation_prompt,
+ "complex_human_instruction": args.complex_human_instruction,
+ }
+ images = log_validation(
+ pipeline=pipeline,
+ args=args,
+ accelerator=accelerator,
+ pipeline_args=pipeline_args,
+ epoch=epoch,
+ )
+ free_memory()
+
+ images = None
+ del pipeline
+
+ # Save the lora layers
+ accelerator.wait_for_everyone()
+ if accelerator.is_main_process:
+ transformer = unwrap_model(transformer)
+ if args.upcast_before_saving:
+ transformer.to(torch.float32)
+ else:
+ transformer = transformer.to(weight_dtype)
+ transformer_lora_layers = get_peft_model_state_dict(transformer)
+
+ SanaPipeline.save_lora_weights(
+ save_directory=args.output_dir,
+ transformer_lora_layers=transformer_lora_layers,
+ )
+
+ # Final inference
+ # Load previous pipeline
+ pipeline = SanaPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ revision=args.revision,
+ variant=args.variant,
+ torch_dtype=torch.float32,
+ )
+ pipeline.transformer = pipeline.transformer.to(torch.float16)
+ # load attention processors
+ pipeline.load_lora_weights(args.output_dir)
+
+ # run inference
+ images = []
+ if args.validation_prompt and args.num_validation_images > 0:
+ pipeline_args = {
+ "prompt": args.validation_prompt,
+ "complex_human_instruction": args.complex_human_instruction,
+ }
+ images = log_validation(
+ pipeline=pipeline,
+ args=args,
+ accelerator=accelerator,
+ pipeline_args=pipeline_args,
+ epoch=epoch,
+ is_final_validation=True,
+ )
+
+ if args.push_to_hub:
+ save_model_card(
+ repo_id,
+ images=images,
+ base_model=args.pretrained_model_name_or_path,
+ instance_prompt=args.instance_prompt,
+ validation_prompt=args.validation_prompt,
+ repo_folder=args.output_dir,
+ )
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ images = None
+ del pipeline
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ main(args)
diff --git a/train_scripts/train_lora.sh b/train_scripts/train_lora.sh
new file mode 100644
index 0000000..3ed034b
--- /dev/null
+++ b/train_scripts/train_lora.sh
@@ -0,0 +1,26 @@
+#! /bin/bash
+
+export MODEL_NAME="Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers"
+export INSTANCE_DIR="data/dreambooth/dog"
+export OUTPUT_DIR="trained-sana-lora"
+
+accelerate launch --num_processes 4 --main_process_port 29500 --gpu_ids 0,1,2,3 \
+ train_scripts/train_dreambooth_lora_sana.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --instance_data_dir=$INSTANCE_DIR \
+ --output_dir=$OUTPUT_DIR \
+ --mixed_precision="bf16" \
+ --instance_prompt="a photo of sks dog" \
+ --resolution=1024 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=4 \
+ --use_8bit_adam \
+ --learning_rate=1e-4 \
+ --report_to="wandb" \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --max_train_steps=500 \
+ --validation_prompt="A photo of sks dog in a pond, yarn art style" \
+ --validation_epochs=25 \
+ --seed="0" \
+ --push_to_hub