(简体中文/EN)
这是一个使用 Wav2CLIP 和 VQGAN-CLIP 从任何歌曲中生成人工智能音乐视频和图片的项目,我们大一立项项目组取名为 MetaMusic,寓意着通过音乐可以实现的多元化转换与含义表达。
基本代码使用了VQGAN-CLIP,音频的 CLIP 嵌入则使用了Wav2CLIP。经后来阅读文献中了解到,本项目思路与Music2Video有着异曲同工之处,并且我们在其中做出了不少原创性的修改与优化。
有关此机制的技术论文,请参阅以下图片:
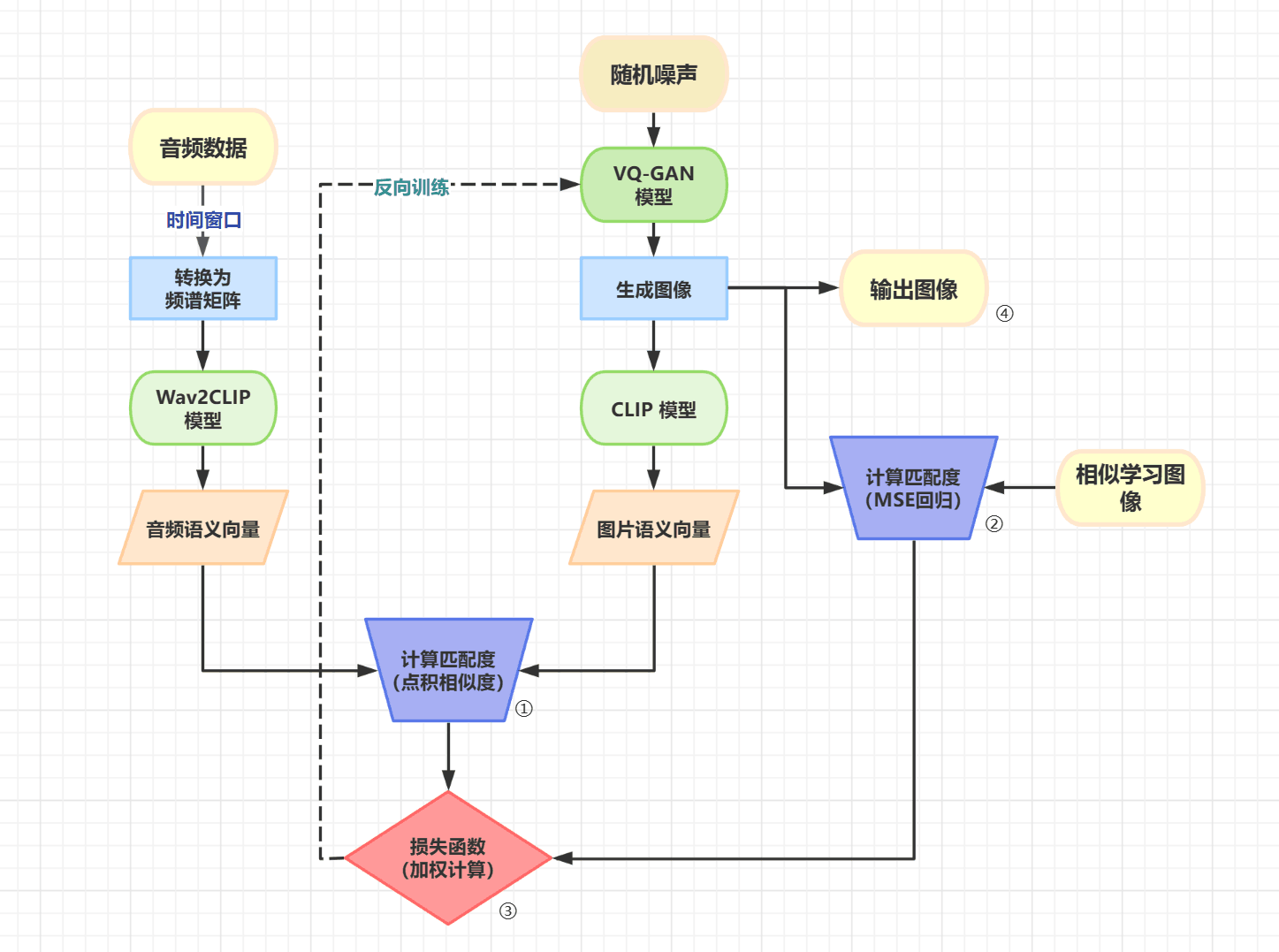
[×]已经尝试过接入 AudioClip 模型,由于训练数据集过于贴近现实的声音识别,对音乐效果不佳[×]已经尝试过接入其他 VQ-GAN 模型,由于 ImageNet 数据集过于写实的缘故,并不是很贴近于歌曲情感图像绘制,效果不佳[×]已经尝试过对整个项目实现 CLIP-guided Diffusion 模型改造,但是由于视频生成效率过低,导致视频生成时间大大增加,视频模块采用过大模型逐帧生成的方案暂时被搁置[√]对代码进行兼容性改造,并对部分模型进行混合精度运算降低显存占用[√]将两套系统成功封装为 API,可以实现简易调用[√]实现 gradio 的可视化界面[ ]尝试自己整理数据集训练 Wav2Clip 模型(或可能 VQ-GAN)[ ]继续尝试其他包括但不限于 Diffusion 架构的图像生成模型,接入 MetaMusic 印象图生成模块

本模型目前理论支持的设备环境为:
- Windows(已验证)/ Linux(未验证)系统
- Nvidia 支持 CUDA 的显卡 / CPU 均可
由于此模型代码可能需要一些时间,并且可能存在兼容性问题,配置可能不会很顺利,请谨慎操作,祝你成功!
此示例使用Anaconda管理虚拟 Python 环境。
- 为 VQGAN-CLIP 创建一个新的虚拟 Python 环境:
conda create --name metamusic python=3.9
conda activate metamusic-
其次,前往CUDA Toolkit - Free Tools and Training | NVIDIA Developer下载自己英伟达显卡所支持的 CUDA 与 cudnn 版本(一般 30 系列以上直接下载 cuda12 即可)
-
接着,在新环境中安装 Pytorch:
前往 Start Locally | PyTorch 网站选择适合自己电脑的 pytorch 版本,复制链接下载安装(我使用的是 cu118 版本)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118-
安装必要的系统支持库,包括但不限于 ffmpeg, MSVC 等工具包,并配置好系统环境变量
-
安装其他所需的 Python 包:
pip install ftfy regex tqdm omegaconf pytorch-lightning IPython kornia imageio imageio-ffmpeg einops torch_optimizer wav2clip- 此外,还需要克隆所需的存储库:
git clone 'https://github.com/SMARK2022/MetaMusic.git'-
由于版本兼容性问题,推荐使用包含版本号的
requirements.txt文件进行安装。并且,需要使用 pip 从网上再次单独安装taming-transformers -
您还需要至少一个预训练的 VQGAN 模型。(经测试,VQ-GAN ImageNet 16384 比较推荐)
mkdir checkpoints
wget -o checkpoints/vqgan_imagenet_f16_16384.yaml 'https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887/files/?p=%2Fconfigs%2Fmodel.yaml&dl=1'
wget -o checkpoints/vqgan_imagenet_f16_16384.ckpt 'https://heibox.uni-heidelberg.de/d/a7530b09fed84f80a887/files/?p=%2Fckpts%2Flast.ckpt&dl=1'有关 VQGAN 预训练模型的更多信息,包括下载链接,请参阅https://github.com/CompVis/taming-transformers#overview-of-pretrained-models。
默认情况下,期望将模型.yaml 和.ckpt 文件放在checkpoints目录中。
有关数据集和模型的更多信息,请参阅https://github.com/CompVis/taming-transformers。
-
要从音乐生成印象图/视频,可以直接运行
gradiogui.py这个可视化文件,在网页端上指定您的音乐。 -
如果需要精细化的参数调整,则可以根据需要使用
api_picture或者api_video中的两个不同的 API。
example:
import api_picture
api_picture.generate(filemusic=....mp3, ...):音乐印象图的模型与流程正在尝试优化中,效果有待提升。
此外,整个视频生成时间可能有些长,请耐心等待(大概耗时 2h 左右)
@misc{unpublished2021clip,
title = {CLIP: Connecting Text and Images},
author = {Alec Radford, Ilya Sutskever, Jong Wook Kim, Gretchen Krueger, Sandhini Agarwal},
year = {2021}
}@misc{esser2020taming,
title={Taming Transformers for High-Resolution Image Synthesis},
author={Patrick Esser and Robin Rombach and Björn Ommer},
year={2020},
eprint={2012.09841},
archivePrefix={arXiv},
primaryClass={cs.CV}
}@article{wu2021wav2clip,
title={Wav2CLIP: Learning Robust Audio Representations From CLIP},
author={Wu, Ho-Hsiang and Seetharaman, Prem and Kumar, Kundan and Bello, Juan Pablo},
journal={arXiv preprint arXiv:2110.11499},
year={2021}
}