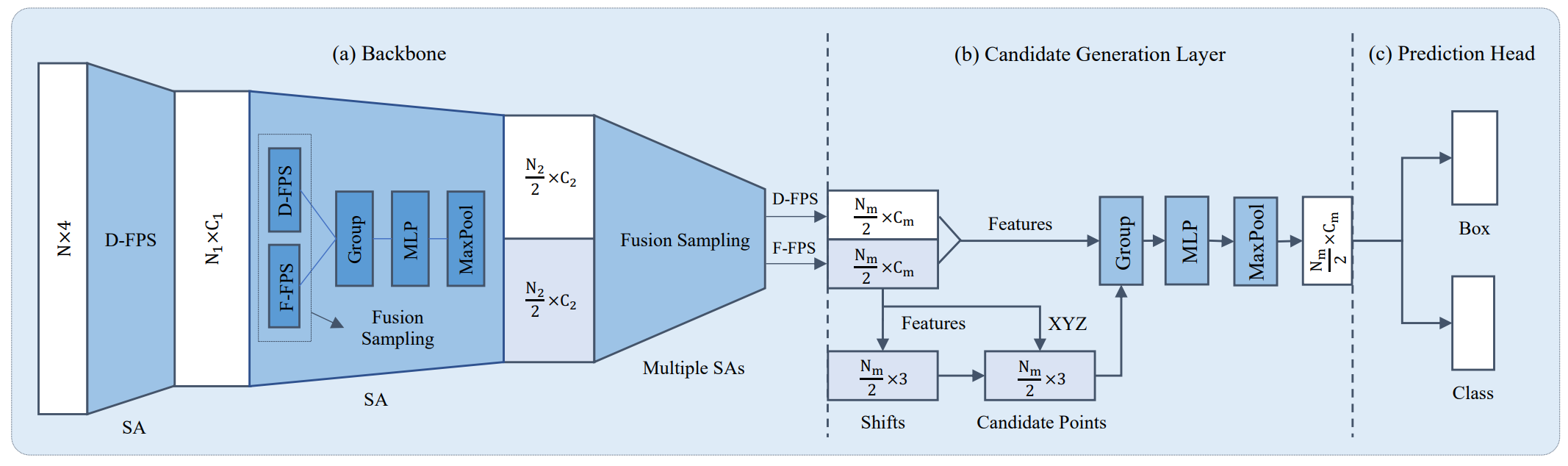
Currently, there have been many kinds of voxel-based 3D single stage detectors, while point-based single stage methods are still underexplored. In this paper, we first present a lightweight and effective point-based 3D single stage object detector, named 3DSSD, achieving a good balance between accuracy and efficiency. In this paradigm, all upsampling layers and refinement stage, which are indispensable in all existing point-based methods, are abandoned to reduce the large computation cost. We novelly propose a fusion sampling strategy in downsampling process to make detection on less representative points feasible. A delicate box prediction network including a candidate generation layer, an anchor-free regression head with a 3D center-ness assignment strategy is designed to meet with our demand of accuracy and speed. Our paradigm is an elegant single stage anchor-free framework, showing great superiority to other existing methods. We evaluate 3DSSD on widely used KITTI dataset and more challenging nuScenes dataset. Our method outperforms all state-of-the-art voxel-based single stage methods by a large margin, and has comparable performance to two stage point-based methods as well, with inference speed more than 25 FPS, 2x faster than former state-of-the-art point-based methods.
We implement 3DSSD and provide the results and checkpoints on KITTI datasets.
Some settings in our implementation are different from the official implementation, which bring marginal differences to the performance on KITTI datasets in our experiments. To simplify and unify the models of our implementation, we skip them in our models. These differences are listed as below:
- We keep the scenes without any object while the official code skips these scenes in training. In the official implementation, only 3229 and 3394 samples are used as training and validation sets, respectively. In our implementation, we keep using 3712 and 3769 samples as training and validation sets, respectively, as those used for all the other models in our implementation on KITTI datasets.
- We do not modify the decay of
batch normalizationduring training. - While using
DataBaseSamplerfor data augmentation, the official code uses road planes as reference to place the sampled objects while we do not. - We perform detection using LIDAR coordinates while the official code uses camera coordinates.
| Backbone | Class | Lr schd | Mem (GB) | Inf time (fps) | mAP | Download |
|---|---|---|---|---|---|---|
| PointNet2SAMSG | Car | 72e | 4.7 | 78.58(81.27)1 | model | log |
[1]: We report two different 3D object detection performance here. 78.58mAP is evaluated by our evaluation code and 81.27mAP is evaluated by the official development kit (so as that used in the paper and official code of 3DSSD ). We found that the commonly used Python implementation of rotate_iou which is used in our KITTI dataset evaluation, is different from the official implementation in KITTI benchmark.
@inproceedings{yang20203dssd,
author = {Zetong Yang and Yanan Sun and Shu Liu and Jiaya Jia},
title = {3DSSD: Point-based 3D Single Stage Object Detector},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year = {2020}
}