FreeAnchor: Learning to Match Anchors for Visual Object Detection
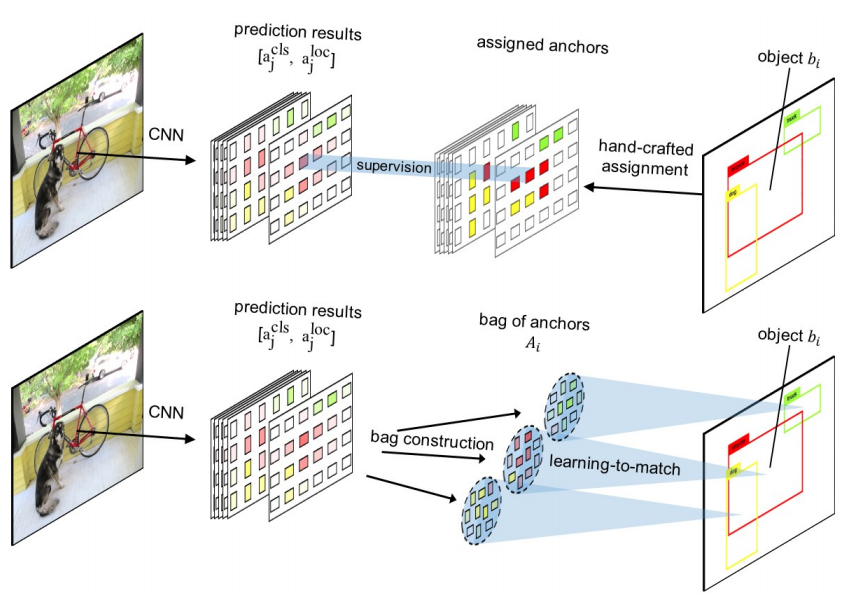
Modern CNN-based object detectors assign anchors for ground-truth objects under the restriction of object-anchor Intersection-over-Unit (IoU). In this study, we propose a learning-to-match approach to break IoU restriction, allowing objects to match anchors in a flexible manner. Our approach, referred to as FreeAnchor, updates hand-crafted anchor assignment to “free" anchor matching by formulating detector training as a maximum likelihood estimation (MLE) procedure. FreeAnchor targets at learning features which best explain a class of objects in terms of both classification and localization. FreeAnchor is implemented by optimizing detection customized likelihood and can be fused with CNN-based detectors in a plug-and-play manner. Experiments on COCO demonstrate that FreeAnchor consistently outperforms the counterparts with significant margins.
We implement FreeAnchor in 3D detection systems and provide their first results with PointPillars on nuScenes dataset.
With the implemented FreeAnchor3DHead, a PointPillar detector with a big backbone (e.g., RegNet-3.2GF) achieves top performance
on the nuScenes benchmark.
As in the baseline config, we only need to replace the head of an existing one-stage detector to use FreeAnchor head.
Since the config is inherit from a common detector head, _delete_=True is necessary to avoid conflicts.
The hyperparameters are specifically tuned according to the original paper.
_base_ = [
'../_base_/models/hv_pointpillars_fpn_lyft.py',
'../_base_/datasets/nus-3d.py', '../_base_/schedules/schedule_2x.py',
'../_base_/default_runtime.py'
]
model = dict(
pts_bbox_head=dict(
_delete_=True,
type='FreeAnchor3DHead',
num_classes=10,
in_channels=256,
feat_channels=256,
use_direction_classifier=True,
pre_anchor_topk=25,
bbox_thr=0.5,
gamma=2.0,
alpha=0.5,
anchor_generator=dict(
type='AlignedAnchor3DRangeGenerator',
ranges=[[-50, -50, -1.8, 50, 50, -1.8]],
scales=[1, 2, 4],
sizes=[
[2.5981, 0.8660, 1.], # 1.5 / sqrt(3)
[1.7321, 0.5774, 1.], # 1 / sqrt(3)
[1., 1., 1.],
[0.4, 0.4, 1],
],
custom_values=[0, 0],
rotations=[0, 1.57],
reshape_out=True),
assigner_per_size=False,
diff_rad_by_sin=True,
dir_offset=-0.7854, # -pi / 4
bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder', code_size=9),
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=0.8),
loss_dir=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.2)),
# model training and testing settings
train_cfg = dict(
pts=dict(code_weight=[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.25, 0.25])))| Backbone | FreeAnchor | Lr schd | Mem (GB) | Inf time (fps) | mAP | NDS | Download |
|---|---|---|---|---|---|---|---|
| FPN | ✗ | 2x | 17.1 | 40.0 | 53.3 | model | log | |
| FPN | ✓ | 2x | 16.3 | 43.82 | 54.86 | model | log | |
| RegNetX-400MF-FPN | ✗ | 2x | 17.3 | 44.8 | 56.4 | model | log | |
| RegNetX-400MF-FPN | ✓ | 2x | 17.6 | 48.3 | 58.65 | model | log | |
| RegNetX-1.6GF-FPN | ✓ | 2x | 24.3 | 52.04 | 61.49 | model | log | |
| RegNetX-1.6GF-FPN* | ✓ | 3x | 24.4 | 52.69 | 62.45 | model | log | |
| RegNetX-3.2GF-FPN | ✓ | 2x | 29.4 | 52.4 | 61.94 | model | log | |
| RegNetX-3.2GF-FPN* | ✓ | 3x | 29.2 | 54.23 | 63.41 | model | log |
Note: Models noted by * means it is trained using stronger augmentation with vertical flip under bird-eye-view, global translation, and larger range of global rotation.
@inproceedings{zhang2019freeanchor,
title = {{FreeAnchor}: Learning to Match Anchors for Visual Object Detection},
author = {Zhang, Xiaosong and Wan, Fang and Liu, Chang and Ji, Rongrong and Ye, Qixiang},
booktitle = {Neural Information Processing Systems},
year = {2019}
}