Probabilistic and Geometric Depth: Detecting Objects in Perspective
3D object detection is an important capability needed in various practical applications such as driver assistance systems. Monocular 3D detection, as a representative general setting among image-based approaches, provides a more economical solution than conventional settings relying on LiDARs but still yields unsatisfactory results. This paper first presents a systematic study on this problem. We observe that the current monocular 3D detection can be simplified as an instance depth estimation problem: The inaccurate instance depth blocks all the other 3D attribute predictions from improving the overall detection performance. Moreover, recent methods directly estimate the depth based on isolated instances or pixels while ignoring the geometric relations across different objects. To this end, we construct geometric relation graphs across predicted objects and use the graph to facilitate depth estimation. As the preliminary depth estimation of each instance is usually inaccurate in this ill-posed setting, we incorporate a probabilistic representation to capture the uncertainty. It provides an important indicator to identify confident predictions and further guide the depth propagation. Despite the simplicity of the basic idea, our method, PGD, obtains significant improvements on KITTI and nuScenes benchmarks, achieving 1st place out of all monocular vision-only methods while still maintaining real-time efficiency. Code and models will be released at this https URL.
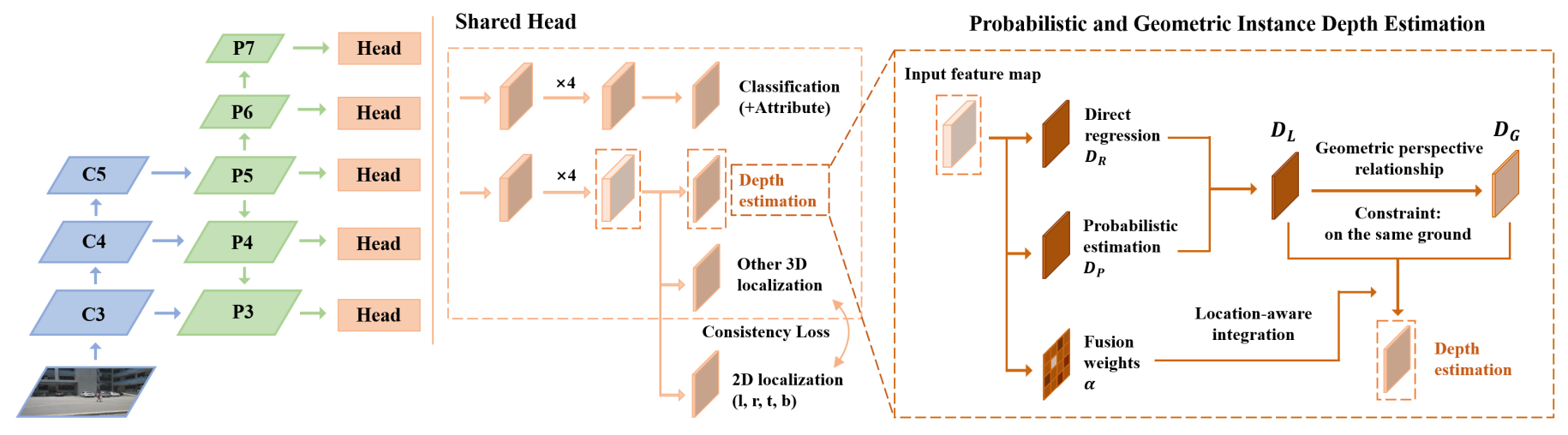
PGD, also can be regarded as FCOS3D++, is a simple yet effective monocular 3D detector. It enhances the FCOS3D baseline by involving local geometric constraints and improving instance depth estimation.
We release the code and model for both KITTI and nuScenes benchmark, which is a good supplement for the original FCOS3D baseline (only supported on nuScenes).
For clean implementation, our preliminary release supports base models with proposed local geometric constraints and the probabilistic depth representation. We will involve the geometric graph part in the future.
A more extensive study based on FCOS3D and PGD is on-going. Please stay tuned.
| Backbone | Lr schd | Mem (GB) | Inf time (fps) | mAP_11 / mAP_40 | Download |
|---|---|---|---|---|---|
| ResNet101 | 4x | 9.07 | 18.33 / 13.23 | model | log |
Detailed performance on KITTI 3D detection (3D/BEV) is as follows, evaluated by AP11 and AP40 metric:
| Easy | Moderate | Hard | |
|---|---|---|---|
| Car (AP11) | 24.09 / 30.11 | 18.33 / 23.46 | 16.90 / 19.33 |
| Car (AP40) | 19.27 / 26.60 | 13.23 / 18.23 | 10.65 / 15.00 |
Note: mAP represents Car moderate 3D strict AP11 / AP40 results. Because of the limited data for pedestrians and cyclists, the detection performance for these two classes is usually unstable. Therefore, we only list car detection results here. In addition, AP40 is a more recommended metric for reference due to its much better stability.
| Backbone | Lr schd | Mem (GB) | mAP | NDS | Download |
|---|---|---|---|---|---|
| ResNet101 w/ DCN | 1x | 9.20 | 31.7 | 39.3 | model | log |
| above w/ finetune | 1x | 9.20 | 34.6 | 41.1 | model | log |
| above w/ tta | 1x | 9.20 | 35.5 | 41.8 | |
| ResNet101 w/ DCN | 2x | 9.20 | 33.6 | 40.9 | model | log |
| above w/ finetune | 2x | 9.20 | 35.8 | 42.5 | model | log |
| above w/ tta | 2x | 9.20 | 36.8 | 43.1 |
@inproceedings{wang2021pgd,
title={{Probabilistic and Geometric Depth: Detecting} Objects in Perspective},
author={Wang, Tai and Zhu, Xinge and Pang, Jiangmiao and Lin, Dahua},
booktitle={Conference on Robot Learning (CoRL) 2021},
year={2021}
}
# For the baseline version
@inproceedings{wang2021fcos3d,
title={{FCOS3D: Fully} Convolutional One-Stage Monocular 3D Object Detection},
author={Wang, Tai and Zhu, Xinge and Pang, Jiangmiao and Lin, Dahua},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
year={2021}
}