By Logan Cerkovnik and Anil Murty
There has been a proliferation of LLM services over the last several months and it’s great to see some of these be made available open source. Ollama is one of the early solutions that gained a significant amount of popularity among developers and has helped many developers accelerate their AI application development using open source AI models. A more recent solution is vLLM - that aims to overcome some of the limitations of Ollama. This post delves into what vLLM is and when and why developers should consider using it. Lastly it also demonstrates how you can run vLLM easily on Akash Network
vLLM is an LLM server implementation first introduced in a paper last year. Its primary objective was to make LLM inference faster for multiuser services. What vLLM does also achieve is overcoming two of the limitations of Ollama. vLLM enables you to serve more than 1 user at a time, natively, without having to proxy user requests between multiple GPUs. It also allows easy switching of models back and forth, without blocking users from accessing their specific model.
The main change vLLM makes is adding Paged Attention to LMM model by swapping out all the transformer attention modules for Paged Attention which implements attention more efficiently. The authors of vLLm describe Page Attention as, “PageAttention’s memory sharing greatly reduces the memory overhead of complex sampling algorithms, such as parallel sampling and beam search, cutting their memory usage by up to 55%. This can translate into up to 2.2x improvement in throughput”. You can read more about the technical details of paged attention on the vllm blog at https://blog.vllm.ai/2023/06/20/vllm.html. Today, the current server implementation has gone beyond just Paged Attention and will soon support speculative encoding approaches. Other open source alternatives to vLLM include HuggingFace’s TGI and the sglang engine with its Radix Attention implementation. The only drawback to using vLLM is that it doesn’t support all of the super low quantization methods and file formats such as GGUF. If you haven’t used GGUF before in llama.cpp-based tools like ollama then you should note that most people actively try to avoid using models with quantization lower than the 4bit (Q4) quantization due to performance issues. The good news is that most models are available in GPTQ or AWQ quantization formats that are supported by vLLM.

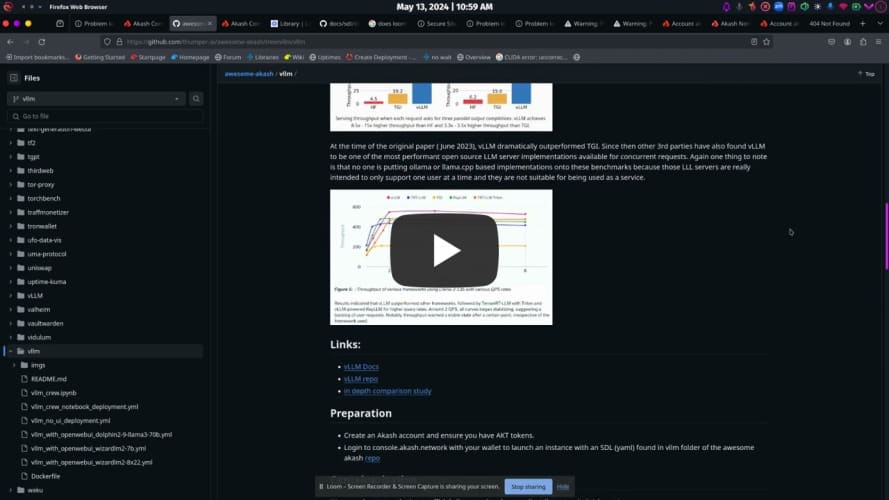
At the time of the original paper ( June 2023), vLLM dramatically outperformed TGI. Since then other 3rd parties have also found vLLM to be one of the most performant open source LLM server implementations available for concurrent requests. Again one thing to note is that no one is putting ollama or llama.cpp based implementations onto these benchmarks because those LLL servers are really intended to only support one user at a time and they are not suitable for being used as a service.

- Create an Akash account and ensure you have AKT tokens.
- Login to console.akash.network with your wallet to launch an instance with an SDL (yaml) found in vllm folder of the awesome akash repo
We are going to use the latest official vllm container image: vllm/vllm-openai:v0.4.0.post1.
You can also build your own image using the Dockerfile in the root of the vllm repo.
Note: you should never use latest as a tag for your containers in Akash SDL and that if you have a new model you should check if it has official vLLM support and note the date to make sure the container has been pushed since support has been added.
- Create a Deployment Configuration: Create a YAML file for your VLLM deployment, including Docker configurations, resource requirements, and port exposures. See the example below which you should be able to copy and paste into Akash Console.
- Deploy: Use Akash Console to deploy your application, which matches you with a suitable provider based on your deployment specifications.
- Use LLM UI : After deployment, utilize the Akash Console field to find the IP address of the service and you should be good to go.
- Use LLM API : After deployment, utilize the Akash Console field to find the IP address of the vllm service and add the uri and api key variables to whatever client you are using. E.g. "http://localhost:8000/v1"
You can find an example of using crewai in the vllm_crew_notebook_deployment.yml
Below is a code snippet using langchain in python
import os
os.environ["OPENAI_API_KEY"]="MYPASSWORD"
#if inside akash service
os.environ["OPENAI_API_BASE"]="http://vllm:8000/v1"
#if outside akash service update as needed based on provider, the port will change for every new deployment
os.environ["OPENAI_API_BASE"]="https://provider.hurricane.akash.pub:31816/v1"
#update for your model name
os.environ["OPENAI_MODEL_NAME"] = "MaziyarPanahi/WizardLM-2-7B-AWQ"
from langchain_community.llms import VLLMOpenAI
llm = VLLMOpenAI(
openai_api_key="MYPASSWORD",
openai_api_base="http://vllm:8000/v1",
model_name="MaziyarPanahi/WizardLM-2-7B-AWQ",
)
or
print(llm.invoke("Rome is"))The vLLM server is designed to be compatible with the OpenAI API, allowing you to use it as a drop-in replacement for applications using the OpenAI API.
This Repo contains 4 example vllm yamls One example without a user interface and 3 with the awesome openwebui tool
- vllm_no_ui_deployment.yml a basic example without a user interface
- vllm_with_openwebui_dolphin2-9-llama3-70b.yml a l
- vllm_with_openwebui_mistral7b.yml
- vllm_with_openwebui_wizardlm2-8x22.yml
- vllm_crew_notebook_deployment.yml
The vLLM server supports the following OpenAI API endpoints:
- List models
- Create chat completion
- Create completion
Sizing LLM Server resources for a particular application can be challenging because of the impact of model choice, quantization of that model, GPU hardware, and usage pattern ( human being vs agent). Anyscale ( the company behind Ray) has released a great LLM benchmarking tool called llmperf that is worth using for benchmarking your use case with your specific application requirements. Aside from using this tool, it has been reported that a single Nvidia A100 GPU can support between 10-20 concurrent users for 7B parameter Mistral model with AWQ on vLLM with lower throughput for other server options. Larger models will have lower throughput. There are also a lot of performance improvements going from 1 to 2 GPUs in a vLLM server, but this effect diminishes rapidly.
If you don't see the model in the open web ui drop down it usually means you chose a model that was too large for GPU, too large for disk space, or has a bad huggingface repo entered into the deployment. You can usually verify which issue is is from the logs. You will usually have to redeploy the deployment to change these parameters.
Steps to Troubleshoot
- Read the logs for the vllm container and the UI container
- Check that the model weights are downloading correctly and can be loaded into VRAM
- Check the model size is smaller than VRAM and container disk space
- Check the huggingface model repo to make sure the repo and author are correct
- Check the huggingface repo model type and make sure its not GGUF and is compatible with VLLM (GPTQ, AWQ, GGML, Safetensors etc)
- Make sure that the model is officially supported by vLLM
- Check the environment variables for setting the
VLLM_API_KEYandOPENAI_API_KEYSenvironment variables match - Check that the the
HUGGING_FACE_HUB_TOKENis set for downloading models - if using the api externally make sure you have updated the url to use the deployer endpoint variable which can be done by setting
OPENAI_API_BASE - if you have checked all of these and still have problems than open a issue in the awesome-akash repo and tag @rakataprime. In the issue, please provide your logs and deployment used with the huggingface token and other secrets set to XXXXXXXXXXXX.
- VLLM supported files formats include : GPTQ, AWQ, GGML(squeezelm ), and pytorch pth/bin and safetensors files
- VLLM DOES NOT SUPPORT GGUF files
- Check to make sure the base foundation model is supported here
- Make sure that the file size is smaller than the VRAM of the GPU with a little buffer room. Try to make sure the model files fit within 90% of the Total VRAM.
- Make sure the vllm container has a large of disk space to store the model weights.
- If you are doing something funny with really large context lengths you can use the tools below to help estimate VRAM utilization.
- Remember that really large models like Grok sometimes require multiple gpus. the max number of gpus supported by this vllm example is 8 gpus or 640Gb VRAM for a100
- If you needed more than 8 gpus you can use a larger ray cluster instead, but this is beyond the scope of this example. you can contact [email protected] for asistance if you need help with this.
vLLM may be one of the best open source LLM servers available today,for most applications with multiple users. We hope this blog makes it easier for people to use vLLM in their applications on Akash. If you have any questions or are looking for some assistance feel free to reach out to [email protected]
