BlueHash 算法文档 - English Version
BlueHash 算法是一种自定义的加密哈希函数,旨在生成具有不同位数(128,256 和 512 位)且安全的哈希值。它利用多个回合的转换,包括状态更新、置换函数和常量生成,这些都有助于最终哈希输出的独特性和安全性。
本文档提供了该算法核心组件的解释,包括状态大小、回合次数、常量生成和状态更新转换。文中还提供了描述每一步过程的数学公式。
use std::fmt::Write;
use BlueHash::{BlueHashCore, Digest, DigestSize};
fn main() {
// 测试数据
let test_data = b"Hello, world! This is a test message for BlueHash";
// 初始化 BlueHash128 哈希器
let mut hasher128 = BlueHashCore::new(DigestSize::Bit128);
hasher128.update(test_data);
let result128 = hasher128.finalize();
println!("BlueHash128 Result: {}", to_hex_string(&result128));
// 初始化 BlueHash256 哈希器
let mut hasher256 = BlueHashCore::new(DigestSize::Bit256);
hasher256.update(test_data);
let result256 = hasher256.finalize();
println!("BlueHash256 Result: {}", to_hex_string(&result256));
// 初始化 BlueHash512 哈希器
let mut hasher512 = BlueHashCore::new(DigestSize::Bit512);
hasher512.update(test_data);
let result512 = hasher512.finalize();
println!("BlueHash512 Result: {}", to_hex_string(&result512));
}
/// 将字节数组转换为十六进制字符串
fn to_hex_string(bytes: &[u8]) -> String {
let mut hex = String::new();
for byte in bytes {
write!(&mut hex, "{:02x}", byte).unwrap();
}
hex
}BlueHash128 Result: 882864a37a8994e12161d27dfa340df0
BlueHash256 Result: 94cf55cae663dce02e08c3a5660e55ef2e08c3a5660e55ef2e08c3a5660e55ef
BlueHash512 Result: aa9501014ff3013643de6edbcf9d7a4543de6edbcf9d7a4543de6edbcf9d7a4543de6edbcf9d7a4543de6edbcf9d7a4543de6edbcf9d7a4543de6edbcf9d7a45
BlueHash 算法使用固定的状态大小,并根据所需的输出大小选择不同的摘要长度。
- 状态大小:25 个 64 位字(即 ( STATE_SIZE = 25 ))。
- 摘要长度:根据摘要大小,可能是 128位,256位 或 512 位。
每个摘要大小的轮次数和输出长度如下:
generate_constants 函数为每个哈希转换回合生成一个独特的常量。常量是基于多个因素生成的,包括回合号、输入数据和预定义常量。
常量的生成公式如下:
其中:
- ( p ) 是一个固定的质数常量。
- ( r ) 是轮次。
round_factor是回合号的一个函数。extra_prime是一个较大的质数常量。noise是由输入数据和回合号生成的噪声。hash_length是最终摘要的长度。
这样确保了每个回合都有一个独特的常量,增强了哈希过程的安全性和随机性。
update 和 permute 函数实现了算法的核心转换逻辑。每个回合都涉及使用当前回合常量更新状态,并应用各种按位操作来实现扩散和混淆。
状态 state[i] 在轮次 r 时的更新公式如下:
其中:
state[i]是状态数组的第 ( i ) 个元素。local vars是从邻近状态值派生出的变量。<<和>>分别表示按位左移和右移。⊕表示按位异或操作。&表示按位与操作。
这种转换确保了每个回合的哈希函数引入非线性混合,有助于实现扩散(小的输入变化导致大的输出变化)和混淆(输出与输入之间没有明显的关系)。
最终的哈希通过从所有回合转换完成后提取内部状态的位来生成。最终的摘要是通过从状态中提取 64 位的块并将其转换为字节来生成的。
生成最终摘要的公式为:
其中:
digest[j]是最终哈希的第 ( j ) 个字节。state[j / 8 \mod STATE_SIZE]表示从状态数组中获取的值。
结果字节被连接起来,形成最终的哈希值,这是 finalize 函数的输出。
BlueHash 算法的安全性基于以下原则:
- 唯一性:每个回合使用的常量都取决于回合号、输入数据和一系列质数。这确保了没有两个回合产生相同的转换。
- 抗碰撞性:每回合的非线性转换和状态变量的混合使得计算上很难找到两个不同的输入产生相同的哈希输出。
- 扩散与混淆:状态更新函数中使用的按位操作(异或、与、移位)确保了输入的小变化会导致哈希值的大幅变化,这是一个好的加密哈希函数的核心。
遵循这些原则,BlueHash 被设计为一种强大的加密哈希函数,能够抵抗如碰撞查找和预映像攻击等攻击。
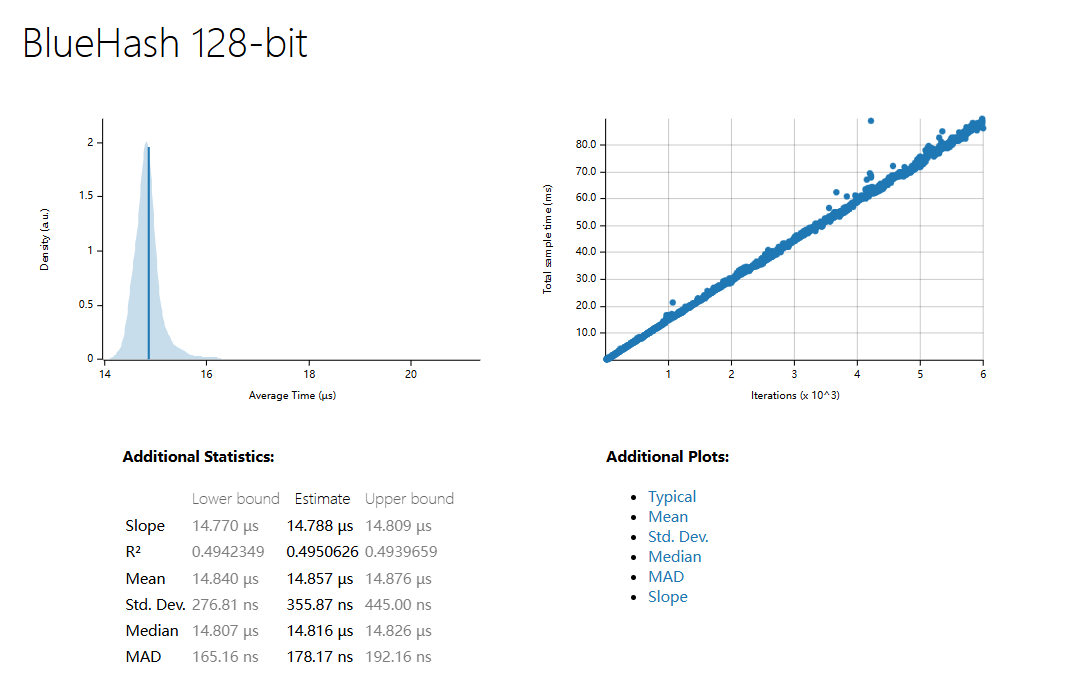
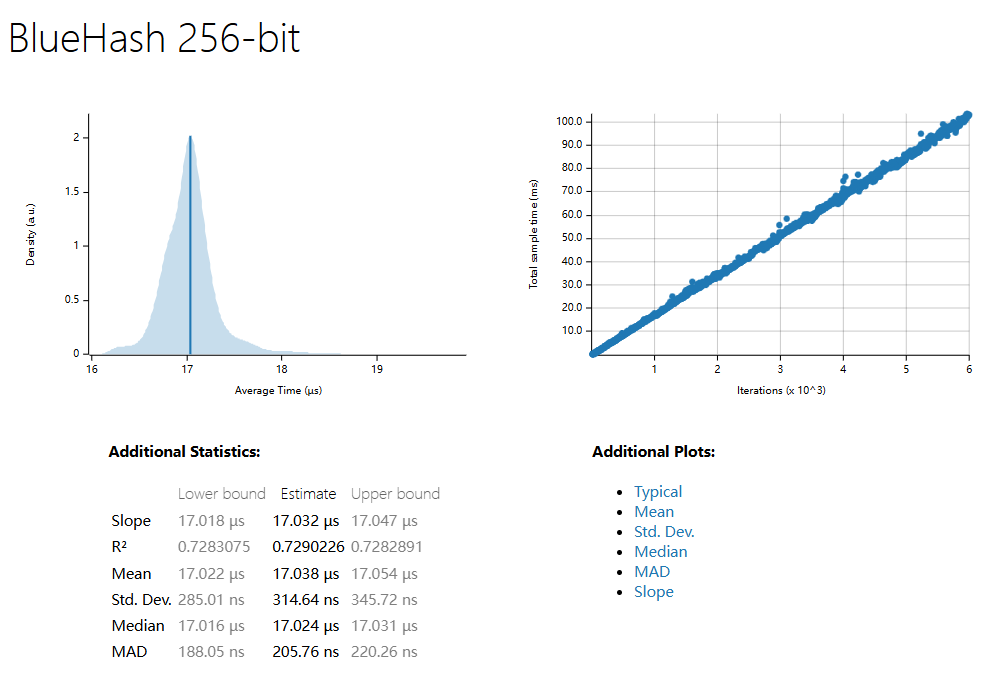
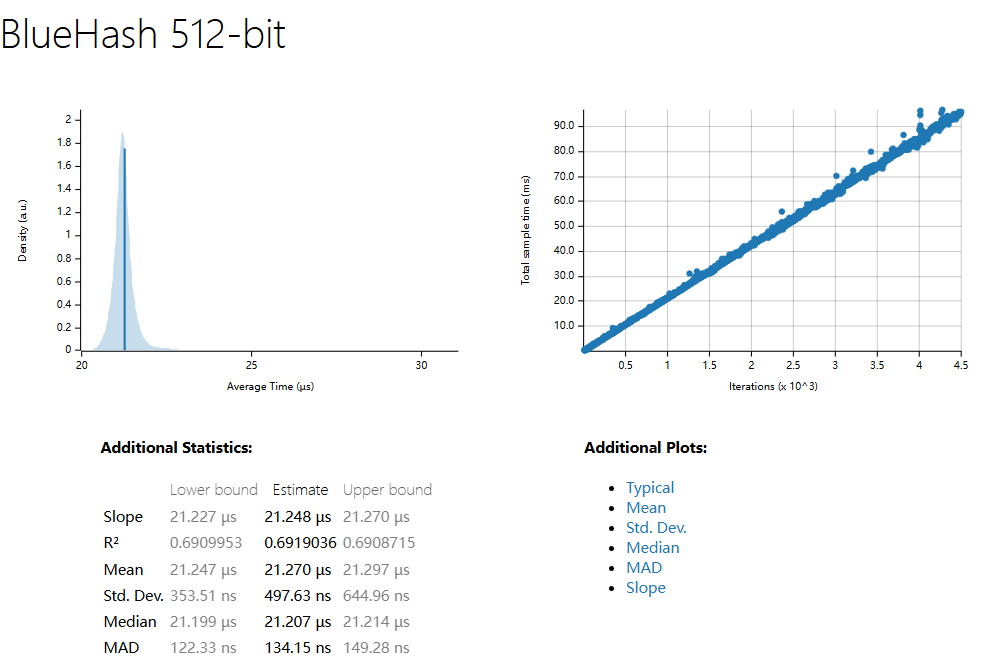
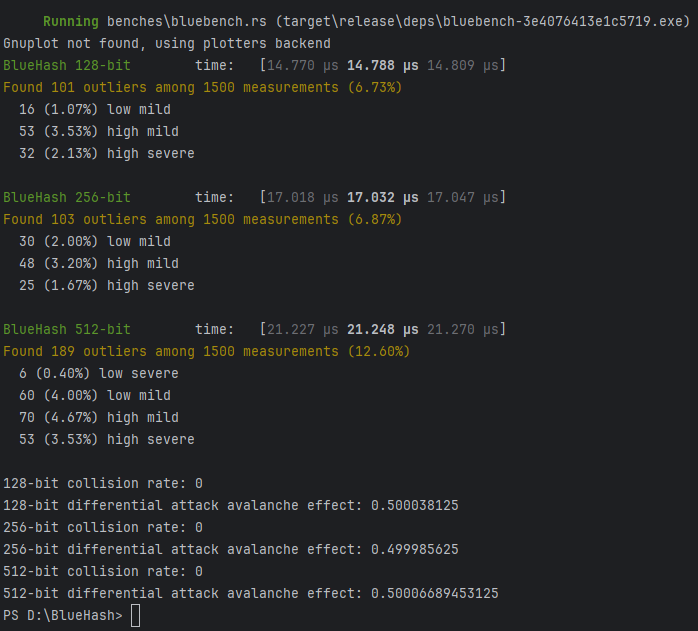
| 1500 Sample | SHA3 256 | SHA3 512 | BlueHash 128 | BlueHash 256 | BlueHash 512 |
|---|---|---|---|---|---|
| R^2 | 0.7966978 | 0.7135882 | 0.4950626 | 0.7290226 | 0.6919036 |
| Mean | 334.45 ns | 336.50 ns | 838.63 µs | 1.0267 ms | 1.3917 ms |
| std. Dev | 19.989 ns | 14.845 ns | 23.557 µs | 20.248 µs | 31.998 µs |
| Median | 333.74 ns | 334.67 ns | 834.35 µs | 1.0234 ms | 1.3859 ms |
| MAD | 3.5463 ns | 2.8191 ns | 10.953 µs | 12.335 µs | 17.597 µs |
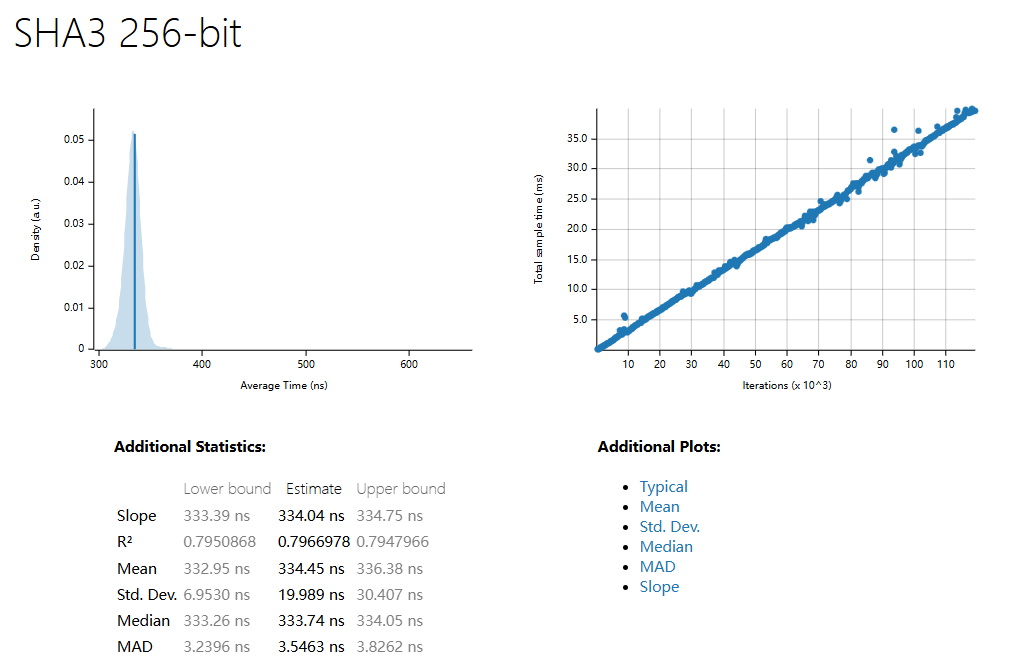
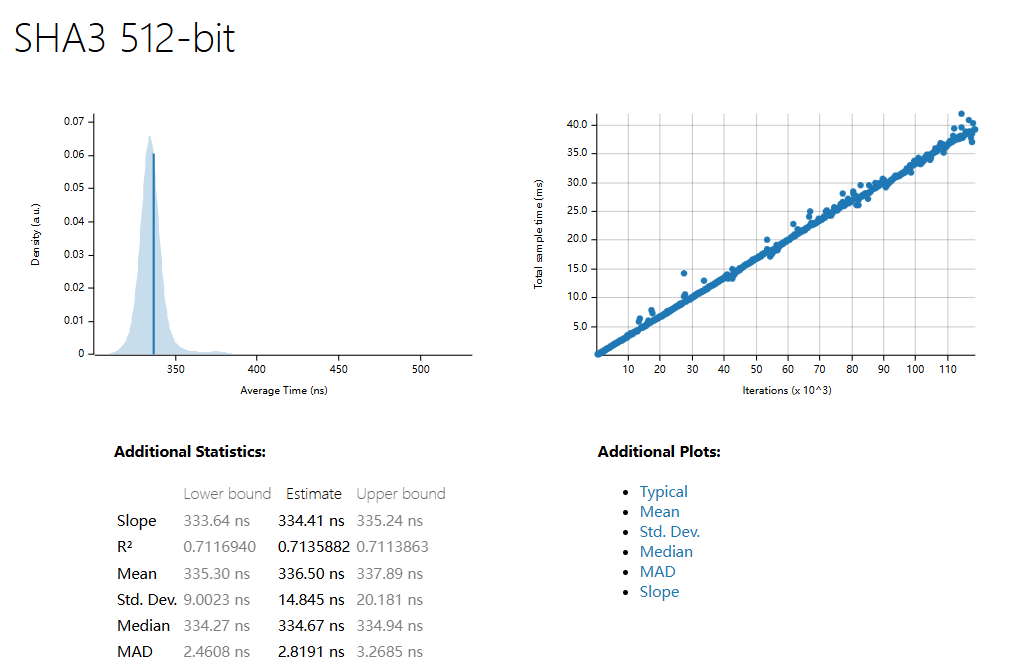
-
抗量子攻击: 通过 LWE 噪声和恒定生成机制,可能可以更好地抵御量子攻击。
-
更高的随机性和复杂性: 利用动态生成常数,增加哈希算法的不可预测性。这增加了攻破的复杂性,并使算法更能抵御差分攻击。
-
更强的状态更新和替换: 通过更多样化的比特运算和混合运算,提高了对传统攻击和量子攻击的抵御能力。
-
增强的噪声生成机制: 添加 LWE 噪声不仅能提高安全性,还能增强防御能力,尤其是针对量子计算的防御能力。
-
灵活性: 可根据不同的哈希长度灵活调整轮数和其他参数,在确保安全的同时优化性能。
-
较高的性能开销: 多轮复杂计算运算和 LWE 噪声生成会增加计算开销,可能会影响大数据处理的效率。
-
更高的内存消耗: 更多的本地变量和状态存储要求可能会导致低内存环境下的性能瓶颈。
-
缺乏标准化和审计: 与 SHA2 或 SHA3 摘要算法相比,BlueHash 缺乏广泛的安全审计。
BlueHash 算法是一种自定义的加密哈希函数,利用多个回合的复杂转换生成不同长度的安全哈希。它使用固定的状态大小、基于回合的转换和常量生成来确保最终输出的独特性和安全性。
 |
 |
 |
|---|