文档布局检测(Document Layout Detection)是指识别和分析文档中的布局结构,包括文本、图像、表格、标题、段落等元素的位置和关系。这项技术在文档处理、信息提取、文档分类和文档理解等任务中非常重要。
以下是文档布局检测的一些关键方面和方法:
- 文档分类:根据文档的布局结构自动分类文档类型(如合同、报告、简历等)。
- 信息提取:从文档中提取特定信息(如姓名、地址、日期等)。
- 文档理解:理解文档的结构和内容,用于文档摘要、问答系统等。
- 文档转换:将扫描的纸质文档转换为可编辑的电子文档。
- 光学字符识别(OCR):识别文档中的文本内容。
- 图像处理:检测文档中的图像、表格等非文本元素。
- 布局分析:分析文档的布局结构,识别标题、段落、表格等元素。
- 机器学习:使用机器学习模型(如深度学习)来识别和分类文档中的不同元素。
- 基于规则的方法:通过预定义的规则和模板来识别文档布局。适用于结构化文档,但灵活性较差。
- 基于模板匹配的方法:使用预定义的模板来匹配文档布局。适用于特定类型的文档,但需要大量模板。
- 基于机器学习的方法:使用机器学习模型(如卷积神经网络CNN、循环神经网络RNN)来学习文档布局特征。适用于复杂和多样化的文档。
- 基于深度学习的方法:使用深度学习模型(如Transformer、BERT)来处理文档布局检测任务。适用于大规模和复杂的文档。
- 文档多样性:不同类型的文档(如合同、报告、简历)具有不同的布局结构。
- 噪声和干扰:文档中可能包含噪声(如水印、模糊)和干扰(如手写体、复杂背景)。
- 多语言支持:需要支持多种语言的文档布局检测。
- 实时处理:在某些应用场景中,需要实时处理大量文档。
- Tesseract OCR:一个开源的OCR引擎,支持多种语言和文档格式。
- OpenCV:一个开源的计算机视觉库,用于图像处理和文档布局检测。
- LayoutParser:一个用于文档布局分析的开源库,支持多种文档格式和布局检测任务。
- DocBank:一个用于文档布局检测的数据集,包含大量标注的文档图像。
- 多模态融合:结合文本、图像、表格等多种模态的信息,提高文档布局检测的准确性。
- 自适应学习:通过自适应学习方法,自动调整模型以适应不同类型的文档。
- 实时处理:开发高效的实时处理算法,满足大规模文档处理的需求。
主要是通过YOLO V8来实现布局检测。
使用DocKayNet数据集进行训练。DocLayNet 是一个用于文档布局检测的大型数据集,专门设计用于训练和评估文档布局分析模型。该数据集包含了大量标注的文档图像,涵盖了多种文档类型和布局结构。DocLayNet 数据集包含了多种类型的文档,如合同、报告、简历、表格、发票等。数据集中的文档具有不同的布局结构,包括文本、图像、表格、标题、段落等元素。每个文档图像都包含了详细的标注信息,包括文本框、图像框、表格框等的位置和类别。
需要先将coco数据格式转换为YOLO V8需要的格式。
import numpy as np
import os # for handling the directory
import json
dataset_folder = "/data/bocheng/data/DocLayNet/base_dataset"
def create_folder(path):
if not os.path.exists(path):
os.makedirs(path)
train_label_folder = os.path.join(dataset_folder, "train", "labels")
test_label_folder = os.path.join(dataset_folder, "test", "labels")
create_folder(train_label_folder)
create_folder(test_label_folder)
val_label_folder = os.path.join(dataset_folder, "val", "labels")
create_folder(val_label_folder)
classes = [
"Caption",
"Footnote",
"Formula",
"List-item",
"Page-footer",
"Page-header",
"Picture",
"Section-header",
"Table",
"Text",
"Title",
]
# Take in a json file for each image, convert it into txt file
import json
from pathlib import Path
import numpy as np
def convert_coco_json_to_txt(json_path: str, output_dir: str) -> None:
"""convert coco format to yolov8 format
Args:
json_path (str): _description_
output_dir (str): _description_
"""
# Import json
with open(json_path) as f:
fn = Path(output_dir) # folder name
data = json.load(f)
# Write labels file
h, w, f = (
data["metadata"]["coco_height"],
data["metadata"]["coco_width"],
data["metadata"]["page_hash"],
)
bboxes = []
for obj in data["form"]:
# The COCO box format is [top left x, top left y, width, height]
box = np.array(obj["box"], dtype=np.float64)
box[:2] += box[2:] / 2 # xy top-left corner to center
box[[0, 2]] /= w # normalize x
box[[1, 3]] /= h # normalize y
if box[2] <= 0 or box[3] <= 0: # if w <= 0 and h <= 0
continue
cls = classes.index(obj["category"]) # class
box = [cls] + box.tolist()
if box not in bboxes:
bboxes.append(box)
# Write
with open((fn / f).with_suffix(".txt"), "a") as file:
for i in range(len(bboxes)):
line = (*(bboxes[i]),) # cls, box or segments
file.write(("%g " * len(line)).rstrip() % line + "\n")
# Define folder directories for train/val/test
train_folder = os.path.join(dataset_folder, "train")
val_folder = os.path.join(dataset_folder, "val")
test_folder = os.path.join(dataset_folder, "test")
folders = [train_folder, val_folder, test_folder]
label_folders = [train_label_folder, val_label_folder, test_label_folder]
# Generate txt files from json files
for folder, label_folder in zip(folders, label_folders):
for _, _, json_file in os.walk(os.path.join(folder, "annotations")):
for f in json_file:
convert_coco_json_to_txt(
os.path.join(folder, "annotations", f), label_folder
)import numpy as np
import os # for handling the directory
import json
dataset_folder = "/data/bocheng/data/DocLayNet/base_dataset"
def create_folder(path):
if not os.path.exists(path):
os.makedirs(path)
train_label_folder = os.path.join(dataset_folder, "train", "labels")
test_label_folder = os.path.join(dataset_folder, "test", "labels")
create_folder(train_label_folder)
create_folder(test_label_folder)
val_label_folder = os.path.join(dataset_folder, "val", "labels")
create_folder(val_label_folder)
classes = [
"Caption",
"Footnote",
"Formula",
"List-item",
"Page-footer",
"Page-header",
"Picture",
"Section-header",
"Table",
"Text",
"Title",
]
# Take in a json file for each image, convert it into txt file
import json
from pathlib import Path
import numpy as np
def convert_coco_json_to_txt(json_path: str, output_dir: str) -> None:
"""convert coco format to yolov8 format
Args:
json_path (str): _description_
output_dir (str): _description_
"""
# Import json
with open(json_path) as f:
fn = Path(output_dir) # folder name
data = json.load(f)
# Write labels file
h, w, f = (
data["metadata"]["coco_height"],
data["metadata"]["coco_width"],
data["metadata"]["page_hash"],
)
bboxes = []
for obj in data["form"]:
# The COCO box format is [top left x, top left y, width, height]
box = np.array(obj["box"], dtype=np.float64)
box[:2] += box[2:] / 2 # xy top-left corner to center
box[[0, 2]] /= w # normalize x
box[[1, 3]] /= h # normalize y
if box[2] <= 0 or box[3] <= 0: # if w <= 0 and h <= 0
continue
cls = classes.index(obj["category"]) # class
box = [cls] + box.tolist()
if box not in bboxes:
bboxes.append(box)
# Write
with open((fn / f).with_suffix(".txt"), "a") as file:
for i in range(len(bboxes)):
line = (*(bboxes[i]),) # cls, box or segments
file.write(("%g " * len(line)).rstrip() % line + "\n")
# Define folder directories for train/val/test
train_folder = os.path.join(dataset_folder, "train")
val_folder = os.path.join(dataset_folder, "val")
test_folder = os.path.join(dataset_folder, "test")
folders = [train_folder, val_folder, test_folder]
label_folders = [train_label_folder, val_label_folder, test_label_folder]
# Generate txt files from json files
for folder, label_folder in zip(folders, label_folders):
for _, _, json_file in os.walk(os.path.join(folder, "annotations")):
for f in json_file:
convert_coco_json_to_txt(
os.path.join(folder, "annotations", f), label_folder
)训练测试数据按要求的格式准备好后,使用ultralytics库进行模型训练就变得很简单了。
- 训练
from ultralytics import YOLO
model_path = "/data/bocheng/pretrained_model/yolo/yolov8n.pt"
model = YOLO(model_path)
model.train(
task="detect",
data="/data/bocheng/dev/mylearn/CV-Learning/DocumentLayout/yolov8_doclayney/yolov8_doclaynet.yaml",
epochs=100,
imgsz=640,
batch=32,
resume=True,
device=[0],
)- 预测
from ultralytics import YOLO
from pprint import pprint
from pathlib import Path
model_path = "./runs/detect/train/weights/best.pt"
model = YOLO(model_path)
image_path = Path("./data/test.png")
results = model.predict(source=image_path.absolute())
output_dir = Path("./runs/detect/test/output")
output_dir.mkdir(parents=True, exist_ok=True)
if results:
result = results[0]
save_path = output_dir / image_path
result.save(output_dir / image_path.name)
pprint(f"Detection result saved to {save_path}")
else:
pprint("No detection results found.")
使用Gradio来进行可视化看看,输入一张文档页面的图片,输出标注后的图片。
from ultralytics import YOLO
from gradio import Interface
import gradio as gr
model_path = "./runs/detect/train/weights/best.pt"
# 加载模型
model = YOLO(model_path) # 假设 best.pt 存放在当前目录下
def detect_objects(image):
# 使用模型进行预测
results = model.predict(source=image)
if results:
return results[0].plot() # 返回带有标注的图像
else:
return "No detections found."
iface = Interface(
fn=detect_objects,
inputs=gr.Image(type="pil"), # 输入类型为PIL图像
outputs=gr.Image(), # 输出也为图像
title="Document Layoutment",
description="Upload an image and see the layout detected by the YOLO model.",
)
# 启动 Gradio 应用
iface.launch(server_name="0.0.0.0")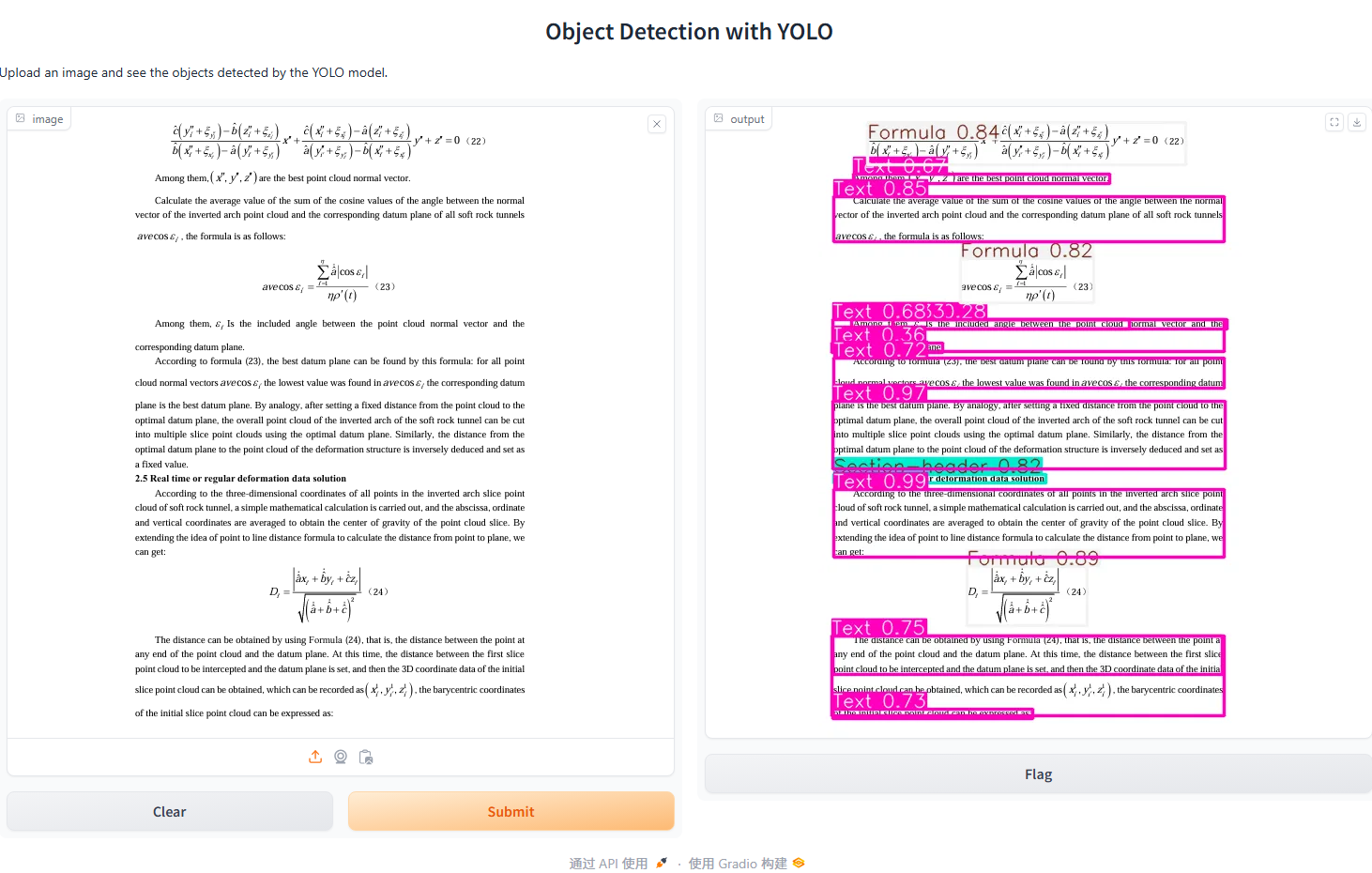
以上代码均在:ai-master/DocLayout at main · chongzicbo/ai-master (github.com)
文章合集:chongzicbo/ReadWriteThink: 博学而笃志,切问而近思 (github.com)
