在C++编程中,内存分区是指程序在运行时,内存被划分为不同的区域,每个区域用于存储不同类型的数据。这些分区包括栈、堆、全局/静态存储区、常量存储区和代码区。了解这些分区的工作原理和特点,有助于编写高效、安全的代码。
了解内存分区有助于程序员更好地管理内存资源,避免内存泄漏、野指针等问题。此外,理解内存分区还能帮助优化程序性能,减少内存碎片,提高程序的运行效率。
内存分区是C++程序运行的基础,不同的内存分区有不同的生命周期和访问权限。掌握内存分区的知识,可以帮助程序员更好地理解程序的运行机制,编写出更加健壮和高效的代码。
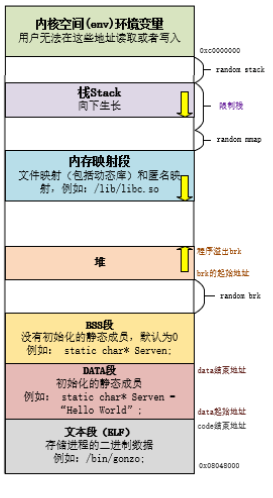
**文本段(ELF):**主要用于存放我们编写的代码,但是不是按照代码文本的形式存放,而是将代码文本编译成二进制代码,存放的是二进制代码,在编译时就已经确定这个区域存放的内容是什么了,并且这个区域是只读区域;
DATA段:这个区域主要用于存放编译阶段(非运行阶段时)就能确定的数据,也就是初始化的静态变量、全局变量和常量,这个区域是可读可写的。这也就是我们通常说的静态存储区;
BSS段:这个区域存放的是未曾初始化的静态变量、全局变量,但是不会存放常量,因为常量在定义的时候就一定会赋值了。未初始化的全局变量和静态变量,编译器在编译阶段都会将其默认为0;
HEAP(堆):这个区域实在运行时使用的,主要是用来存放程序员分配和释放内存,程序结束时操作系统会对其进行回收,(程序员分配内存像malloc、free、new、delete)都是在这个区域进行的;
STACK(栈):存放函数的参数值和局部变量,这个区域的数据是由编译器来自己分配和释放的,只要执行完这个函数,那么这些参数值和变量都会被释放掉;
内核空间(env)环境变量:这个区域是系统内部的区域,我们是不可编辑的;
栈是一种后进先出(LIFO)的数据结构,用于存储函数调用时的局部变量、函数参数和返回地址。栈的内存分配和释放由编译器自动管理,速度非常快。
#include <iostream>
void stackExample() {
int a = 10; // 局部变量a存储在栈上
int b = 20; // 局部变量b存储在栈上
std::cout << "a: " << a << ", b: " << b << std::endl;
// 函数结束时,a和b自动从栈中释放
}
int main() {
stackExample();
return 0;
}代码分析:
a和b是局部变量,存储在栈上。- 当
stackExample函数结束时,a和b会自动从栈中释放。
堆是用于动态内存分配的区域,程序员可以手动申请和释放堆内存。堆的内存管理由程序员负责,因此需要谨慎使用,避免内存泄漏。
#include <iostream>
void heapExample() {
int* p = new int(10); // 在堆上分配一个int类型的内存,并初始化为10
std::cout << "*p: " << *p << std::endl;
delete p; // 释放堆内存
}
int main() {
heapExample();
return 0;
}代码分析:
new int(10)在堆上分配了一个int类型的内存,并初始化为10。delete p释放了堆内存,避免内存泄漏。
全局变量和静态变量存储在全局/静态存储区。这些变量的生命周期贯穿整个程序运行期间,直到程序结束才会被释放。
这个区域有两个段,分别是BSS段和DATA段,均存放着全局变量和静态变量(包括全局静态变量和局部静态变量),其中BSS存放的是程序员编写的未初始化的全局变量和静态变量(这其中C和C++的BSS还有区别,区别就是:C中的BSS段分为高地址和低地址,高地址是存放全局变量,低地址是存放静态未初始化);而DATA存放已经初始化的全局变量、静态变量和常量。
#include <iostream>
int globalVar = 100; // 全局变量存储在全局/静态存储区
void staticExample() {
static int staticVar = 200; // 静态局部变量存储在全局/静态存储区
std::cout << "globalVar: " << globalVar << ", staticVar: " << staticVar << std::endl;
}
int main() {
staticExample();
return 0;
}代码分析:
globalVar是全局变量,存储在全局/静态存储区。staticVar是静态局部变量,也存储在全局/静态存储区,但其作用域仅限于staticExample函数。
常量存储区用于存储常量数据,如字符串常量和 const 修饰的变量。这些数据在程序运行期间不可修改。
#include <iostream>
void constantExample() {
const int constVar = 300; // 常量存储在常量存储区
const char* str = "Hello, World!"; // 字符串常量存储在常量存储区
std::cout << "constVar: " << constVar << ", str: " << str << std::endl;
}
int main() {
constantExample();
return 0;
}代码分析:
constVar是常量,存储在常量存储区。str是字符串常量,也存储在常量存储区。
代码区用于存储程序的二进制代码,即程序的指令。代码区是只读的,程序运行时不能修改。
#include <iostream>
void codeExample() {
std::cout << "This is a function in the code area." << std::endl;
}
int main() {
codeExample();
return 0;
}代码分析:
codeExample函数的二进制代码存储在代码区。- 代码区是只读的,程序运行时不能修改。
- 速度快:栈的内存分配和释放由编译器自动管理,速度非常快。
- 生命周期短:栈上的变量在函数结束时自动释放。
- 大小有限:栈的大小通常较小,不适合存储大量数据。
- 灵活性高:堆内存可以动态分配和释放,适合存储大小不确定的数据。
- 生命周期长:堆上的变量需要手动释放,生命周期由程序员控制。
- 速度较慢:堆内存的分配和释放速度较慢,且容易产生内存碎片。
- 生命周期长:全局变量和静态变量的生命周期贯穿整个程序运行期间。
- 作用域广:全局变量可以在整个程序中访问,静态变量的作用域取决于其定义位置。
- 初始化:全局变量和静态变量在程序启动时自动初始化。
- 只读:常量存储区中的数据不可修改。
- 生命周期长:常量数据的生命周期贯穿整个程序运行期间。
- 安全性高:常量数据不可修改,提高了程序的安全性。
- 只读:代码区存储程序的二进制代码,不可修改。
- 生命周期长:代码区的生命周期贯穿整个程序运行期间。
- 安全性高:代码区不可修改,防止程序被恶意篡改。
#include <iostream>
void stackUsageExample() {
int a = 10; // 局部变量a存储在栈上
int b = 20; // 局部变量b存储在栈上
std::cout << "a: " << a << ", b: " << b << std::endl;
// 函数结束时,a和b自动从栈中释放
}
int main() {
stackUsageExample();
return 0;
}int a = 10;:在栈上分配一个int类型的变量a,并初始化为10。int b = 20;:在栈上分配一个int类型的变量b,并初始化为20。std::cout << "a: " << a << ", b: " << b << std::endl;:输出变量a和b的值。- 函数
stackUsageExample结束时,a和b会自动从栈中释放。
#include <iostream>
void heapUsageExample() {
int* p = new int(10); // 在堆上分配一个int类型的内存,并初始化为10
std::cout << "*p: " << *p << std::endl;
delete p; // 释放堆内存
}
int main() {
heapUsageExample();
return 0;
}int* p = new int(10);:在堆上分配一个int类型的内存,并初始化为10,将地址赋值给指针p。std::cout << "*p: " << *p << std::endl;:输出指针p所指向的值。delete p;:释放堆内存,避免内存泄漏。
#include <iostream>
int globalVar = 100; // 全局变量存储在全局/静态存储区
void staticUsageExample() {
static int staticVar = 200; // 静态局部变量存储在全局/静态存储区
std::cout << "globalVar: " << globalVar << ", staticVar: " << staticVar << std::endl;
}
int main() {
staticUsageExample();
return 0;
}int globalVar = 100;:定义一个全局变量globalVar,存储在全局/静态存储区。static int staticVar = 200;:定义一个静态局部变量staticVar,存储在全局/静态存储区。std::cout << "globalVar: " << globalVar << ", staticVar: " << staticVar << std::endl;:输出globalVar和staticVar的值。
#include <iostream>
void constantUsageExample() {
const int constVar = 300; // 常量存储在常量存储区
const char* str = "Hello, World!"; // 字符串常量存储在常量存储区
std::cout << "constVar: " << constVar << ", str: " << str << std::endl;
}
int main() {
constantUsageExample();
return 0;
}const int constVar = 300;:定义一个常量constVar,存储在常量存储区。const char* str = "Hello, World!";:定义一个字符串常量str,存储在常量存储区。std::cout << "constVar: " << constVar << ", str: " << str << std::endl;:输出constVar和str的值。
#include <iostream>
void codeUsageExample() {
std::cout << "This is a function in the code area." << std::endl;
}
int main() {
codeUsageExample();
return 0;
}void codeUsageExample() { ... }:定义一个函数codeUsageExample,其二进制代码存储在代码区。std::cout << "This is a function in the code area." << std::endl;:输出一条消息。codeUsageExample();:调用函数codeUsageExample。
- 局部变量:函数内部的局部变量通常存储在栈上,生命周期与函数调用一致。
- 函数调用:函数调用时的参数和返回地址也存储在栈上。
- 快速分配:栈的内存分配和释放速度非常快,适合存储生命周期短的数据。
- 动态内存分配:当需要动态分配内存时(如数组大小不确定),可以使用堆。
- 大内存需求:当需要存储大量数据时,堆是一个合适的选择。
- 手动管理:堆内存需要手动管理,适合需要精确控制内存生命周期的场景。
- 全局变量:需要在整个程序中共享的变量可以存储在全局/静态存储区。
- 静态变量:需要在函数调用之间保持状态的变量可以使用静态变量。
- 程序生命周期:全局变量和静态变量的生命周期贯穿整个程序运行期间。
- 常量数据:不可修改的数据(如字符串常量、
const变量)可以存储在常量存储区。 - 安全性:常量存储区中的数据不可修改,适合存储程序中的常量配置。
- 共享数据:常量数据可以在整个程序中共享,避免重复存储。
- 程序指令:代码区存储程序的二进制代码,是程序运行的基础。
- 只读保护:代码区是只读的,防止程序被恶意篡改。
- 优化性能:代码区的访问速度较快,适合存储程序的核心逻辑。
优点:
- 速度快:栈的内存分配和释放由编译器自动管理,速度非常快。
- 简单易用:栈的使用无需手动管理内存,减少了出错的可能性。
- 局部性:栈上的数据通常具有较好的局部性,有利于缓存命中。
缺点:
- 大小有限:栈的大小通常较小,不适合存储大量数据。
- 生命周期短:栈上的变量在函数结束时自动释放,不适合存储需要长期存在的数据。
- 不可扩展:栈的大小在程序启动时固定,无法动态扩展。
优点:
- 灵活性高:堆内存可以动态分配和释放,适合存储大小不确定的数据。
- 生命周期长:堆上的变量需要手动释放,生命周期由程序员控制。
- 大内存需求:堆适合存储大量数据,不受栈大小的限制。
缺点:
- 速度较慢:堆内存的分配和释放速度较慢,且容易产生内存碎片。
- 手动管理:堆内存需要手动管理,容易导致内存泄漏和野指针问题。
- 复杂性高:堆的使用需要谨慎,增加了程序的复杂性。
优点:
- 生命周期长:全局变量和静态变量的生命周期贯穿整个程序运行期间。
- 作用域广:全局变量可以在整个程序中访问,静态变量的作用域取决于其定义位置。
- 初始化:全局变量和静态变量在程序启动时自动初始化。
缺点:
- 占用内存:全局变量和静态变量在整个程序运行期间占用内存,可能导致内存浪费。
- 可维护性差:全局变量的广泛作用域可能导致代码的可维护性变差。
- 线程安全问题:全局变量在多线程环境中可能导致线程安全问题。
优点:
- 只读保护:常量存储区中的数据不可修改,提高了程序的安全性。
- 共享数据:常量数据可以在整个程序中共享,避免重复存储。
- 生命周期长:常量数据的生命周期贯穿整个程序运行期间。
缺点:
- 不可修改:常量存储区中的数据不可修改,限制了其灵活性。
- 内存占用:常量数据在整个程序运行期间占用内存,可能导致内存浪费。
优点:
- 只读保护:代码区存储程序的二进制代码,不可修改,防止程序被恶意篡改。
- 生命周期长:代码区的生命周期贯穿整个程序运行期间。
- 优化性能:代码区的访问速度较快,适合存储程序的核心逻辑。
缺点:
- 不可修改:代码区的内容不可修改,限制了程序的动态性。
- 内存占用:代码区在整个程序运行期间占用内存,可能导致内存浪费。
- 及时释放内存:在使用堆内存时,确保在不再需要时及时释放内存。
- 使用智能指针:使用智能指针(如
std::unique_ptr和std::shared_ptr)自动管理堆内存,避免内存泄漏。
- 栈用于小数据:将生命周期短、数据量小的变量存储在栈上。
- 堆用于大数据:将生命周期长、数据量大的变量存储在堆上。
- 减少全局变量:尽量减少全局变量的使用,避免代码的可维护性变差。
- 使用静态局部变量:在需要保持状态的函数中使用静态局部变量,而不是全局变量。
- 共享常量数据:将常量数据存储在常量存储区,避免重复存储。
- 使用
const修饰符:使用const修饰符声明常量,提高程序的安全性。
- 减少代码冗余:优化代码结构,减少冗余代码,提高代码区的利用率。
- 使用内联函数:对于短小的函数,使用内联函数减少函数调用的开销。
C++内存分区是程序运行的基础,不同的内存分区有不同的特点和适用场景。掌握内存分区的知识,可以帮助程序员更好地管理内存资源,编写高效、安全的代码。在实际编程中,应根据不同的需求选择合适的内存分区,避免内存泄漏和性能问题。
随着计算机硬件和软件技术的不断发展,内存管理也在不断演进。未来的内存管理可能会更加智能化,自动化内存管理工具和技术的应用将更加广泛。此外,随着多核处理器和并行计算的普及,内存管理的并发性和线程安全性也将成为重要的研究方向。通过不断学习和实践,我们可以更好地应对未来内存管理的挑战,编写出更加高效、健壮的程序。