各种语言实现代码:Go Java JavaScript Rust
默认使用 Go 语言实现。
链表是一种物理存储单元上非连续、非顺序,但是在逻辑上是顺序的存储结构。链表的每个结点包括两个部分,一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域,链表使用一个 head 指针来指向第一个表头的结点,而最后一个结点的指针指向 NULL。由于链表不必须按顺序存储,所以链表在插入的时候比线性顺序表快得多,但是查找或者访问某个节点则比线性表和顺序表要慢。链表有很多种不同的类型:单向链表,双向链表以及循环链表。

单向链表是链表的一种,其特点是链表的链接方向是单向的,对链表的访问要从头部开始。
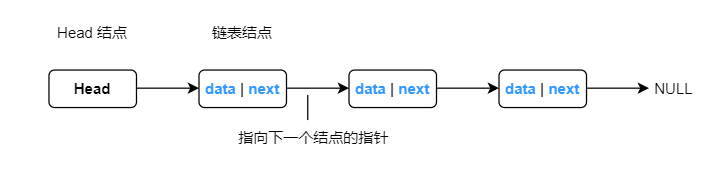
我们的都知道水浒传里面有梁山英雄排名,以梁山英雄排名为例,用单向链表来写一个示例。

首先定义一个结构体用来存储数据和下一个指针:
type HeroNode struct {
no int // 编号
name string // 姓名
nickname string // 昵称
next *HeroNode // 下一个结点
}
func NewHeroNode(no int, name, nickname string) *HeroNode {
return &HeroNode {
no: no,
name: name,
nickname: nickname,
}
}为了方便查看内容,定义函数用来输出:
// 打印单链表结点内容
func printHeadNodeInfo(headNode *HeroNode) {
if headNode.next == nil {
fmt.Println("该链表没有结点")
return
}
tempNode := headNode.next
info := "["
for tempNode != nil {
info += fmt.Sprintf("{no:%v, name:%s, nickname:%s}",
tempNode.no, tempNode.name, tempNode.nickname)
tempNode = tempNode.next
}
info += "]"
fmt.Println(info)
}尾部插入
单向链表是从 head 结点开始,形成一条链状,最后一个结点的指针是 NULL。在尾部插入,通过 head 结点找到最后一个结点,然后将新的结点插入到最后一个结点即可。
实现如下:
// 在链表尾部插入,通过 head 找到链表的尾部
func insertAtTail(headNode *HeroNode, newNode *HeroNode) {
lastNode := headNode
// 下一个结点不为空继续循环
for lastNode.next != nil {
// 将下一个结点赋值给当前结点
lastNode = lastNode.next
}
// 将当前结点插入到链表的最后一个结点
lastNode.next = newNode
}编写测试方法,然后运行:
func TestInsertAtTail(t *testing.T) {
// 创建 head 结点,head 结点不包含数据
headNode := new(HeroNode)
// 创建第一个结点
heroNode1 := NewHeroNode(1, "宋江", "呼保义")
// 创建第二个结点
heroNode2 := NewHeroNode(2, "卢俊义", "玉麒麟")
// 创建第三个结点
heroNode3 := NewHeroNode(3, "吴用", "智多星")
// 将结点添加到链表尾部
insertAtTail(headNode, heroNode1)
insertAtTail(headNode, heroNode2)
insertAtTail(headNode, heroNode3)
printHeadNodeInfo(headNode)
}运行:
golang\datastructure>go test -v -run ^TestInsertAtTail$ ./linkedlist/single
=== RUN TestInsertAtTail
[{no:1, name:宋江, nickname:呼保义}{no:2, name:卢俊义, nickname:玉麒麟}{no:3, name:吴用, nickname:智多星}]顺序插入
上例中实现了尾部插入,如果要按照某种顺序插入,在插入结点的时候找到合适的结点,然后将该结点的下一个结点指向要插入的结点。下面是一个按照 no 升序的顺序插入实现:
// 按照 no 升序插入,通过 head 找到合适的插入位置
func sortInsertByNo(headNode *HeroNode, newNode *HeroNode) {
tempNode := headNode
for {
if tempNode.next == nil { // 最后一个结点,跳出循环
break
} else if tempNode.next.no > newNode.no { // newNode 结点应该插入到 tempNode 后面
break
} else if tempNode.next.no == newNode.no {
panic("no 相等不能插入") // no 相等不能插入
}
tempNode = tempNode.next
}
// tempNode 的下一个结点插入到 newNode 的下一个结点
newNode.next = tempNode.next
// newNode 结点插入到 tempNode 的下一个结点
tempNode.next = newNode
}对比尾部插入,测试代码如下:
func TestSortInsertByNo(t *testing.T) {
// 创建结点,用来做尾部插入
head := new(HeroNode)
node1 := NewHeroNode(1, "宋江", "呼保义")
node2 := NewHeroNode(2, "卢俊义", "玉麒麟")
node3 := NewHeroNode(3, "吴用", "智多星")
insertAtTail(head, node1)
insertAtTail(head, node3) // 将第三个结点插入到第二个位置
insertAtTail(head, node2)
fmt.Println("尾部插入的结果:")
printHeadNodeInfo(head)
// 创建 head 结点
headNode := new(HeroNode)
// 创建第一个结点
heroNode1 := NewHeroNode(1, "宋江", "呼保义")
// 创建第二个结点
heroNode2 := NewHeroNode(2, "卢俊义", "玉麒麟")
// 创建第三个结点
heroNode3 := NewHeroNode(3, "吴用", "智多星")
// 将结点按照 no 升序插入
sortInsertByNo(headNode, heroNode1)
sortInsertByNo(headNode, heroNode3)
sortInsertByNo(headNode, heroNode2)
fmt.Println("按照 no 升序插入的结果:")
printHeadNodeInfo(headNode)
}运行:
golang/datastructure>go test -v -run ^TestSortInsertByNo$ ./linkedlist/single
=== RUN TestSortInsertByNo
尾部插入的结果:
[{no:1, name:宋江, nickname:呼保义}{no:3, name:吴用, nickname:智多星}{no:2, name:卢俊义, nickname:玉麒麟}]
按照 no 升序插入的结果:
[{no:1, name:宋江, nickname:呼保义}{no:2, name:卢俊义, nickname:玉麒麟}{no:3, name:吴用, nickname:智多星}]可以看出使用顺序插入,插入节点时对代码调用顺序无关,其链表元素的顺序总是有序的。
单向链表删除
对于删除,先找到需要删除的结点,然后将需要删除的结点的上一个结点的下一个结点指针指向该删除结点的下一个结点。
实现如下:
// 删除指定结点
func deleteNode(headNode *HeroNode, node *HeroNode) {
tempNode := headNode
for tempNode.next != nil {
if tempNode.next.no == node.no {
// 将下一个结点的下一个结点,链接到被删除结点的上一个结点
tempNode.next = tempNode.next.next
return
}
tempNode = tempNode.next
}
}编写测试方法:
func TestDeleteNode(t *testing.T) {
// 创建结点
headNode := new(HeroNode)
heroNode1 := NewHeroNode(1, "宋江", "呼保义")
heroNode2 := NewHeroNode(2, "卢俊义", "玉麒麟")
heroNode3 := NewHeroNode(3, "吴用", "智多星")
heroNode4 := NewHeroNode(4, "公孙胜", "入云龙")
heroNode5 := NewHeroNode(5, "关胜", "大刀")
// 插入结点
insertAtTail(headNode, heroNode1)
insertAtTail(headNode, heroNode2)
insertAtTail(headNode, heroNode3)
insertAtTail(headNode, heroNode4)
insertAtTail(headNode, heroNode5)
fmt.Println("删除前:")
printHeadNodeInfo(headNode)
// 删除 no 为 2 的结点
deleteNode(headNode, heroNode2)
fmt.Println("删除 no 为 2 的结点后:")
printHeadNodeInfo(headNode)
// 删除 no 为 3, 4 的结点
deleteNode(headNode, heroNode3)
deleteNode(headNode, heroNode4)
fmt.Println("删除 no 为 3,4 的结点后:")
printHeadNodeInfo(headNode)
}运行:
golang/datastructure>go test -v -run ^TestDeleteNode$ ./linkedlist/single
=== RUN TestDeleteNode
删除前:
[{no:1, name:宋江, nickname:呼保义}{no:2, name:卢俊义, nickname:玉麒麟}{no:3, name:吴用, nickname:智多星}{no:4, name:公孙胜, nickname:入云龙}{no:5, name:关胜, nickname:大刀}]
删除 no 为 2 的结点后:
[{no:1, name:宋江, nickname:呼保义}{no:3, name:吴用, nickname:智多星}{no:4, name:公孙胜, nickname:入云龙}{no:5, name:关胜, nickname:大刀}]
删除 no 为 3,4 的结点后:
[{no:1, name:宋江, nickname:呼保义}{no:5, name:关胜, nickname:大刀}]遍历链表,统计出了头结点以外的结点,头结点不存储数据。
- 遍历结点数
- 定义一个长度遍历,每遍历一次长度 +1
func getNodeLength(headNode *Node) int {
// 头结点为空,返回 0
if headNode == nil {
return 0
}
var length = 0
node := headNode.next
for node != nil {
length++
node = node.next
}
return length
}快慢指针
- 定义快指针 fast 和 慢指针 slow
- 快慢指针的初始值指向头结点
- 快指针先走 index 步
- 慢指针开始走直到快指针指向了末尾结点
- 此时慢指针就是倒数第 n 个结点
func getLastIndexNode(headNode *Node, index int) *Node {
// 头结点为空,index 小于等于 0 返回空
if headNode == nil || index <= 0 {
return nil
}
fast := headNode
slow := headNode
i := index
length := 0
for fast != nil {
length++
if i > 0 {
fast = fast.next
i--
continue
}
// 快慢指针同时走
fast = fast.next
slow = slow.next
}
// index 超过了链表的长度
if index > length {
return nil
}
return slow
}遍历
- 获取链表结点数 length
- 遍历到 length - n 个结点
- 然后返回
func getLastIndexNode(headNode *Node, index int) *Node {
// 头结点为空,返回空
if headNode == nil {
return nil
}
length := getNodeLength(headNode)
if index <= 0 || index > length {
return nil
}
lastNode := headNode.next
for i := 0; i < length - index; i++ {
lastNode = lastNode.next
}
return lastNode
}- 定义一个新的头结点 reverseHead
- 遍历链表,每遍历一个结点,将其取出,放在新的头结点 reverseHead 的后面
- 最后将头结点的 next 结点指向 reverseHead 的 next 结点
func reverseNode(headNode *Node) {
if headNode == nil || headNode.next == nil {
return
}
// 定义新的头结点
reverseHead := &Node{}
current := headNode.next
var next *Node
for current != nil {
// 保存当前结点的下一个结点
next = current.next
// 将 reverseHead 结点的下一个结点放在当前结点的下一个结点
current.next = reverseHead.next
// 当前结点放在 reverseHead 后面
reverseHead.next = current
// 移动当前结点
current = next
}
// 将头结点的 next 结点指向 reverseHead 的 next 结点
headNode.next = reverseHead.next
}反向遍历
1.先将链表反转
2.遍历打印
问题:破坏了链表原来的结构
使用栈
1.遍历链表
2.将每一个结点压入栈中
3.遍历栈元素,将其打印输出
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向前一个和后一个结点。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前一个结点和后一个结点。
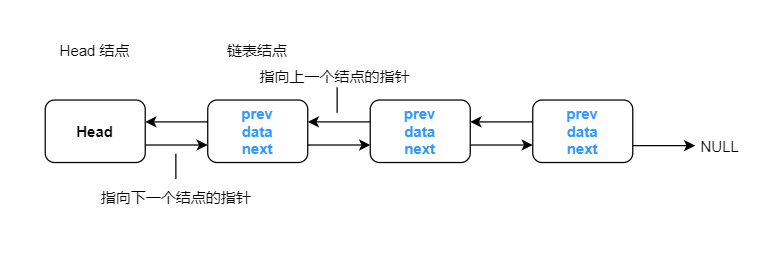
双向链表相比于单向链表有以下优点:
- 单向链表只能向后查找,双向链表可以向前或向后查找
- 单向链表是通过查找到被删除结点的上一个结点来删除,双向链表则是自我删除
接下来使用双向链表来实现上面梁山英雄排名的示例。
定义一个结构体用来存储数据和两个结点指针:
type HeroNode struct {
no int // 编号
name string // 姓名
nickname string // 昵称
prev *HeroNode // 上一个结点
next *HeroNode // 下一个结点
}
func NewHeroNode(no int, name, nickname string) *HeroNode {
return &HeroNode {
no: no,
name: name,
nickname: nickname,
}
}为了方便查看内容,定义函数用来输出:
// 打印链表结点内容
func printHeadNodeInfo(headNode *HeroNode) {
if headNode.next == nil {
fmt.Println("该链表没有结点")
return
}
tempNode := headNode.next
info := "["
for tempNode != nil {
info += fmt.Sprintf("{no:%v, name:%s, nickname:%s}",
tempNode.no, tempNode.name, tempNode.nickname)
tempNode = tempNode.next
}
info += "]"
fmt.Println(info)
}尾部插入
和单向链表一样,通过 head 结点找到最后一个结点,然后将尾部结点的下一个指针结点指向新的结点,新结点的上一个结点指针指向尾部结点。
实现如下:
// 在链表尾部插入,通过 head 找到链表的尾部
func insertAtTail(headNode *HeroNode, newNode *HeroNode) {
lastNode := headNode
// 下一个结点不为空继续循环
for lastNode.next != nil {
// 将下一个结点赋值给当前结点
lastNode = lastNode.next
}
// 将当前结点插入到链表的最后一个结点
lastNode.next = newNode
// 将新结点的上一个结点指向当前结点
newNode.prev = lastNode
}编写测试函数:
func TestInsertAtTail(t *testing.T) {
// 创建 head 结点,head 结点不包含数据
headNode := new(HeroNode)
// 创建第一个结点
heroNode1 := NewHeroNode(3, "吴用", "智多星")
// 创建第二个结点
heroNode2 := NewHeroNode(6, "林冲", "豹子头")
// 创建第三个结点
heroNode3 := NewHeroNode(7, "秦明", "霹雳火")
// 将结点添加到链表尾部
insertAtTail(headNode, heroNode1)
insertAtTail(headNode, heroNode2)
insertAtTail(headNode, heroNode3)
printHeadNodeInfo(headNode)
}运行:
golang/datastructure>go test -v -run ^TestInsertAtTail$ ./linkedlist/double
=== RUN TestInsertAtTail
[{no:3, name:吴用, nickname:智多星}{no:6, name:林冲, nickname:豹子头}{no:7, name:秦明, nickname:霹雳火}]双向链表删除
双链表删除可以和单链表一样,只是在去掉被删除的节点后,需要将该删除结点的上下两个结点链接起来,实现如下:
// 删除指定结点
func deleteNode(headNode *HeroNode, node *HeroNode) {
tempNode := headNode.next
for tempNode != nil {
if tempNode.no == node.no {
// 将查找到的结点的上一个结点的下一个结点指针指向当前结点的下一个结点
tempNode.prev.next = tempNode.next
// 最后一个结点的 next 指向空
if tempNode.next != nil {
// 将查找到的结点的下一个结点的上一个结点指针指向当前指针的上一个结点
tempNode.next.prev = tempNode.prev
}
return
}
tempNode = tempNode.next
}
}编写测试代码:
func TestDeleteNode(t *testing.T) {
// 创建结点
headNode := new(HeroNode)
heroNode1 := NewHeroNode(1, "宋江", "呼保义")
heroNode2 := NewHeroNode(2, "卢俊义", "玉麒麟")
heroNode3 := NewHeroNode(3, "吴用", "智多星")
heroNode4 := NewHeroNode(4, "公孙胜", "入云龙")
heroNode5 := NewHeroNode(5, "关胜", "大刀")
// 插入结点
insertAtTail(headNode, heroNode1)
insertAtTail(headNode, heroNode2)
insertAtTail(headNode, heroNode3)
insertAtTail(headNode, heroNode4)
insertAtTail(headNode, heroNode5)
fmt.Println("删除前:")
printHeadNodeInfo(headNode)
// 删除 no 为 2 的结点
deleteNode(headNode, heroNode2)
fmt.Println("删除 no 为 2 的结点后:")
printHeadNodeInfo(headNode)
// 删除 no 为 3, 4 的结点
deleteNode(headNode, heroNode3)
deleteNode(headNode, heroNode4)
fmt.Println("删除 no 为 3,4 的结点后:")
printHeadNodeInfo(headNode)
}运行:
golang/datastructure>go test -v -run ^TestDeleteNode$ ./linkedlist/double
=== RUN TestDeleteNode
删除前:
[{no:1, name:宋江, nickname:呼保义}{no:2, name:卢俊义, nickname:玉麒麟}{no:3, name:吴用, nickname:智多星}{no:4, name:公孙胜, nickname:入云龙}{no:5, name:关胜, nickname:大刀}]
删除 no 为 2 的结点后:
[{no:1, name:宋江, nickname:呼保义}{no:3, name:吴用, nickname:智多星}{no:4, name:公孙胜, nickname:入云龙}{no:5, name:关胜, nickname:大刀}]
删除 no 为 3,4 的结点后:
[{no:1, name:宋江, nickname:呼保义}{no:5, name:关胜, nickname:大刀}]循环链表的特点是表中最后一个结点的指针域指向头结点,整个链表形成一个环。
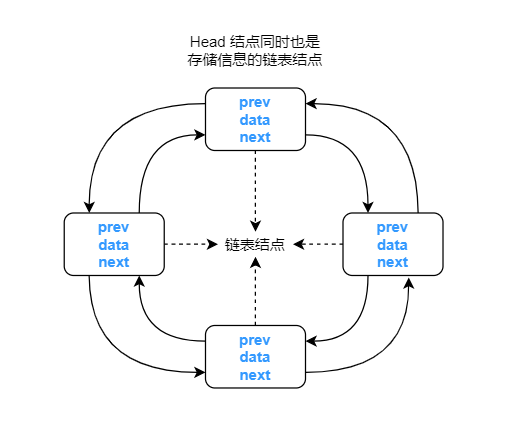
下面创建一个双向的循环链表结构体:
type PersonNode struct {
no int
name string
prev *PersonNode
next *PersonNode
}定义函数用来输出:
// 打印循环链表的信息
func printRoundNodeInfo(headNode *PersonNode) {
if headNode.next == nil {
fmt.Println("该循环链表没有节点")
return
}
tempNode := headNode
info := "["
for {
info += fmt.Sprintf("{no:%v, name:%s}",
tempNode.no, tempNode.name)
// 表示最后一个结点
if tempNode.next == headNode {
break
}
tempNode = tempNode.next
}
info += "]"
fmt.Println(info)
}尾部插入
循环链表和非循环链表的头结点不一样,循环链表的头结点会存储第一个结点信息并且本身作为第一个结点,插入结点方法如下:
// 插入结点
func insertNode(headNode *PersonNode, newNode *PersonNode) {
// 判断是否是第一次插入
if headNode.next == nil {
headNode.no = newNode.no
headNode.name = newNode.name
headNode.prev = headNode
headNode.next = headNode
return
}
lastNode := headNode
// 下一个结点不等于头结点继续循环
for lastNode.next != headNode {
lastNode = lastNode.next
}
// 将新结点添加到链表末尾
lastNode.next = newNode
newNode.prev = lastNode
// 将新结点下一个结点指针指向头结点
newNode.next = headNode
headNode.prev = newNode
}编写测试函数代码:
func TestInsertNode(t *testing.T) {
// 创建 head 结点,head 结点不初始化数据,等到添加了第一个结点后才初始化数据
headNode := &PersonNode{}
// 创建第一个结点
personNode1 := &PersonNode{no: 1, name: "张三"}
// 创建第二个结点
personNode2 := &PersonNode{no: 2, name: "李四"}
// 创建第三个结点
personNode3 := &PersonNode{no: 3, name: "王五"}
// 插入结点
insertNode(headNode, personNode1)
insertNode(headNode, personNode2)
insertNode(headNode, personNode3)
printRoundNodeInfo(headNode)
}运行:
golang/datastructure>go test -v -run ^TestInsertNode$ ./linkedlist/round
=== RUN TestInsertNode
[{no:1, name:张三}{no:2, name:李四}{no:3, name:王五}]删除结点
双向循环链表的头结点存储了第一个结点信息,也要作为判断是否要被删除的结点。遍历结点,当结点的下一个结点指针等于头结点就说明遍历完成,循环链表的删除有可能会删除头结点,当头结点被删除后,头结点就不在链表中,需要返回一个新的头结点,实现如下:
// 删除指定结点,返回头结点
func deleteNode(headNode *PersonNode, node *PersonNode) *PersonNode {
// 没有结点 或者 只有一个头结点
if headNode.next == nil || headNode.next == headNode {
// 头结点就是要删除的结点
if headNode.no == node.no {
headNode.next = nil
headNode.prev = nil
}
return headNode
}
tempNode := headNode.next
isExist := false
for {
if tempNode == headNode { // 最后一个结点
if tempNode.no == node.no {
isExist = true
// 头结点删除了,将头结点的下一个结点作为头结点
headNode = headNode.next
}
break
} else if tempNode.no == node.no {
isExist = true
break
}
tempNode = tempNode.next
}
// 存在需要删除的结点
if isExist {
// 将查找到的结点的上一个结点的下一个结点指针指向当前结点的下一个结点
tempNode.prev.next = tempNode.next
// 将查找到的结点的下一个结点的上一个结点指针指向当前指针的上一个结点
tempNode.next.previous = tempNode.prev
}
return headNode
}编写测试删除结点的函数:
func TestDeleteNode(t *testing.T) {
// 创建结点
headNode := &PersonNode{}
personNode1 := &PersonNode{no: 1, name: "张三"}
personNode2 := &PersonNode{no: 2, name: "李四"}
personNode3 := &PersonNode{no: 3, name: "王五"}
personNode4 := &PersonNode{no: 4, name: "赵六"}
personNode5 := &PersonNode{no: 5, name: "孙七"}
// 插入结点
insertNode(headNode, personNode1)
insertNode(headNode, personNode2)
insertNode(headNode, personNode3)
insertNode(headNode, personNode4)
insertNode(headNode, personNode5)
fmt.Println("删除前:")
printRoundNodeInfo(headNode)
// 删除 no 为 2 的结点
headNode = deleteNode(headNode, personNode2)
fmt.Println("删除 no 为 2 的结点后:")
printRoundNodeInfo(headNode)
newNode := &PersonNode{no: 6, name: "周八"}
insertNode(headNode, newNode)
fmt.Println("插入新结点:")
printRoundNodeInfo(headNode)
// 删除 no 为 1,3 的结点
headNode = deleteNode(headNode, personNode1)
headNode = deleteNode(headNode, personNode3)
fmt.Println("删除 no 为 1,3 的结点后:")
printRoundNodeInfo(headNode)
}运行:
golang/datastructure>go test -v -run ^TestDeleteNode$ ./linkedlist/round
=== RUN TestDeleteNode
删除前:
[{no:1, name:张三}{no:2, name:李四}{no:3, name:王五}{no:4, name:赵六}{no:5, name:孙七}]
删除 no 为 2 的结点后:
[{no:1, name:张三}{no:3, name:王五}{no:4, name:赵六}{no:5, name:孙七}]
插入新结点:
[{no:1, name:张三}{no:3, name:王五}{no:4, name:赵六}{no:5, name:孙七}{no:6, name:周八}]
删除 no 为 1,3 的结点后:
[{no:4, name:赵六}{no:5, name:孙七}{no:6, name:周八}]设编号为 1,2,...n 的 n 个人围坐一圈,约定编号为 k(1<=k<=n) 的人从 1 开始报数,数到 m 的那个人出列,它的下一位又从 1 开始报数,数到 m 的那个人又出列,依次类推,直到所有人出列为止,由此产生一个出队编号的序列。
提示:用一个不带头节点的循环链表来处理 Josephu 问题:先构成一个有 n 个结点的单循环链表,然后由 k 节点起从 1 开始计数,计到 m 时,对应节点的人从链表中删除,然后再从被删除节点的下一个节点又从 1 开始计数,直到链表中留下最后一个节点。
假设有 5 个人,从第 1 个人开始,每次数到第 3 个人就出列,画图分析如下:
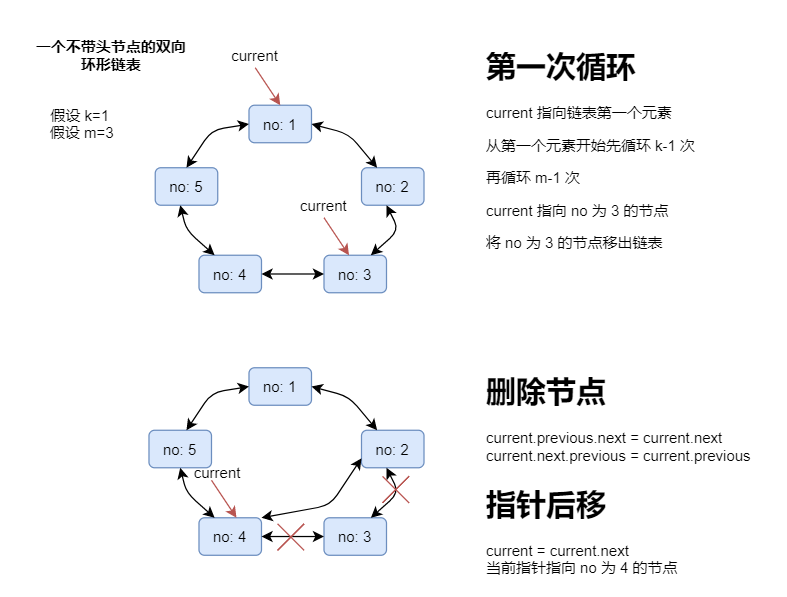
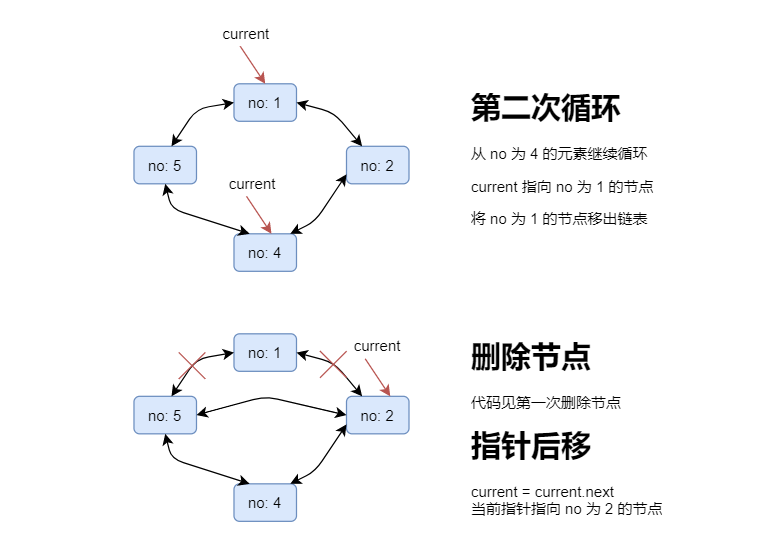
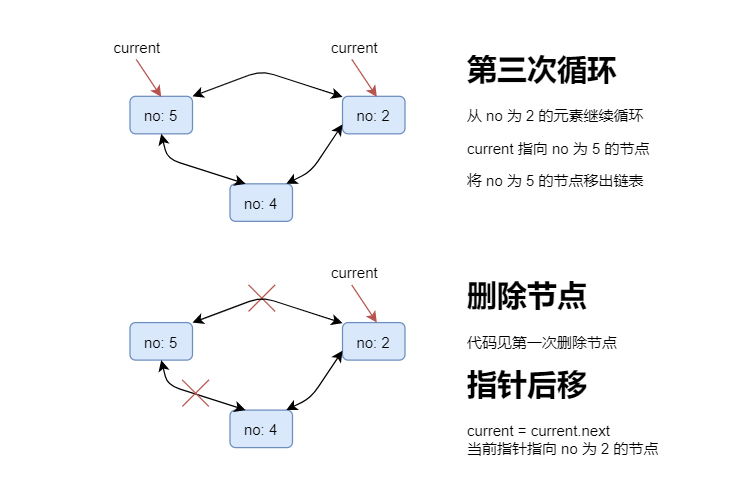
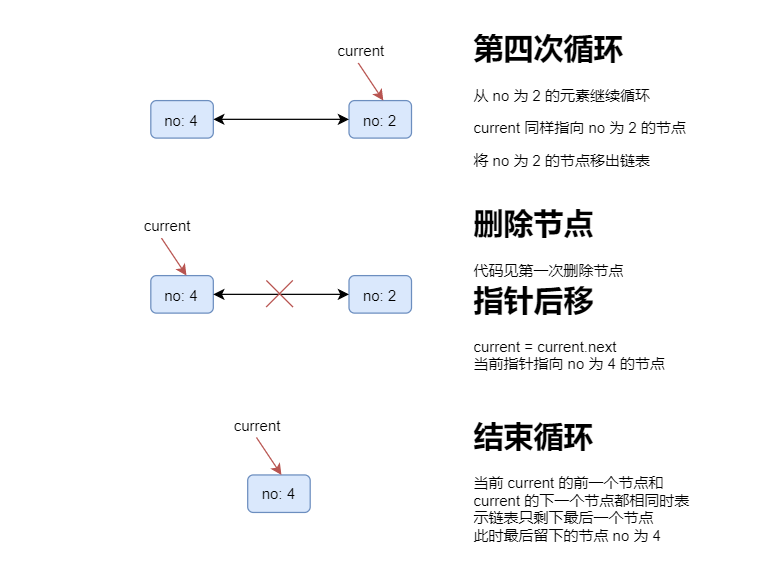
代码实现
创建结构体:
type Person struct {
no int // 编号
prev *Person // 上一个人
next *Person // 下一个人
}
type PersonLinkedList struct {
first *Person // 第一个小孩
length int // 小孩的数量
}定义初始化函数:
func NewBoyLinkedList(count int) *PersonLinkedList {
if count < 1 {
fmt.Printf("链表至少需要一个元素")
return nil
}
personLinkedList := PersonLinkedList{first: nil, length: count}
// 初始化小孩,构成双向环形链表
var prev = personLinkedList.first
for i := 1; i <= count; i++ {
person := &Person{no: i}
if i == 1 {
// 初始化 First 节点
personLinkedList.first = person
personLinkedList.first.next = personLinkedList.first
personLinkedList.first.prev = personLinkedList.first
// 将 prev 指向 First 节点,继续下一次循环
prev = personLinkedList.first
continue
}
prev.next = person
person.prev = prev
// 新增加的节点的下一个节点指向第一节点
person.next = personLinkedList.first
// 第一个节点的上一个节点指向新增加的节点
personLinkedList.first.prev = person
prev = person
}
return &personLinkedList
}显示所有人的编号方法:
func (personLinkedList *PersonLinkedList) ShowPersons() {
if personLinkedList.first == nil {
return
}
if personLinkedList.first == personLinkedList.first.next {
fmt.Printf("num:%d\n", personLinkedList.first.no)
return
}
current := personLinkedList.first
for {
fmt.Printf("num:%d\n", current.no)
current = current.next
if current == personLinkedList.first {
break
}
}
}报数方法:
func (personLinkedList *PersonLinkedList) Count(start, num int) {
if start < 1 || start > personLinkedList.length {
fmt.Printf("start 不能小于 1 或者不能大于 %d\n", personLinkedList.length)
return
}
if num > personLinkedList.length {
fmt.Printf("num 不能大于元素个数: %d\n", personLinkedList.length)
return
}
current := personLinkedList.first
// 循环 start - 1 次
for i := 1; i <= start-1; i++ {
current = current.next
}
for {
// 表示只有一个节点
if current.prev == current && current.next == current {
break
}
// 循环 num - 1 次
for i := 1; i <= num-1; i++ {
current = current.next
}
// 删除元素
current.previous.next = current.next
current.next.prev = current.prev
fmt.Printf("出队人的编号: %d\n", current.no)
current = current.next
}
fmt.Printf("最后留下人的编号: %d\n", current.no)
}测试代码如下:
func TestJoseph(t *testing.T) {
personLinkedList := NewBoyLinkedList(5)
personLinkedList.ShowPersons()
personLinkedList.Count(1, 3)
}运行:
golang/datastructure>go test -v -run ^TestJoseph$ ./linkedlist/joseph
=== RUN TestJoseph
num:1
num:2
num:3
num:4
num:5
出队人的编号: 3
出队人的编号: 1
出队人的编号: 5
出队人的编号: 2
最后留下人的编号: 4