GitHub - yihui-he/resnet-cifar10-caffe: ResNet-20/32/44/56/110 on CIFAR-10 with Caffe
~/caffe/build/tools/caffe test -gpu 0 -iterations 100 -model resnet-20/trainval.prototxt -weights resnet-20/snapshot/solver_iter_64000.caffemodel| Model | Acc | Claimed Acc |
|---|---|---|
| https://github.com/yihui-he/resnet-cifar10-caffe/releases/download/1.0/resnet20_iter_64000.caffemodel | 91.4% | 0.9125 |
| https://github.com/yihui-he/resnet-cifar10-caffe/releases/download/1.0/resnet32_iter_64000.caffemodel | 92.48% | 0.9248999999999999 |
| ResNet-44 | % | 0.9283 |
| https://github.com/yihui-he/resnet-cifar10-caffe/releases/download/1.0/resnet56_iter_64000.caffemodel | 92.9% | 0.9303 |
| ResNet-110 | % | 0.9339 |
If you find the code useful in your research, please consider citing:
@InProceedings{He_2017_ICCV,
author = {He, Yihui and Zhang, Xiangyu and Sun, Jian},
title = {Channel Pruning for Accelerating Very Deep Neural Networks},
booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
month = {Oct},
year = {2017}
}
#build caffe
git clone https://github.com/yihui-he/resnet-cifar10-caffe
./download_cifar.sh
./train.sh [GPUs] [NET]
#eg., ./train.sh 0 resnet-20
#find logs at resnet-20/logsspecify caffe path in cfgs.py and use plot.py to generate beautful loss plots.
python plot.py PATH/TO/LOGSResults are consistent with original paper. seems there’s no much difference between resnet-20 and plain-20. However, from the second plot, you can see that plain-110 have difficulty to converge.
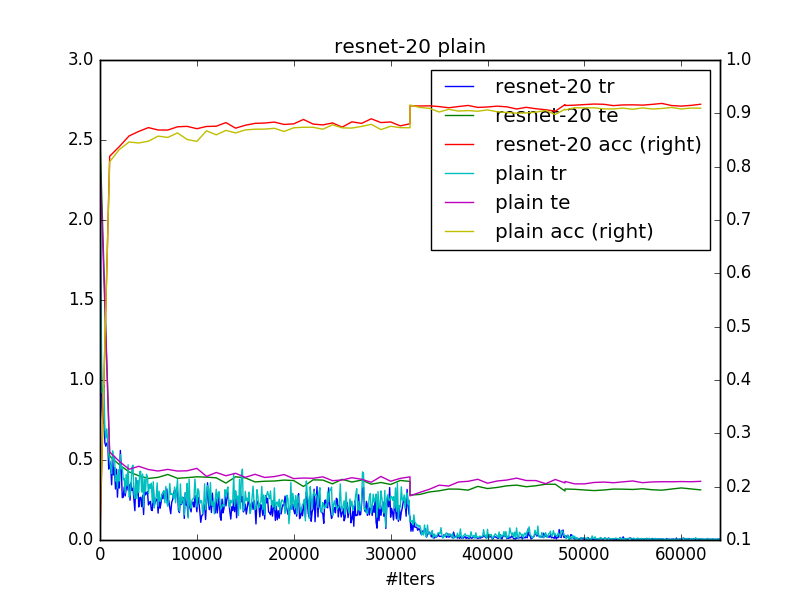
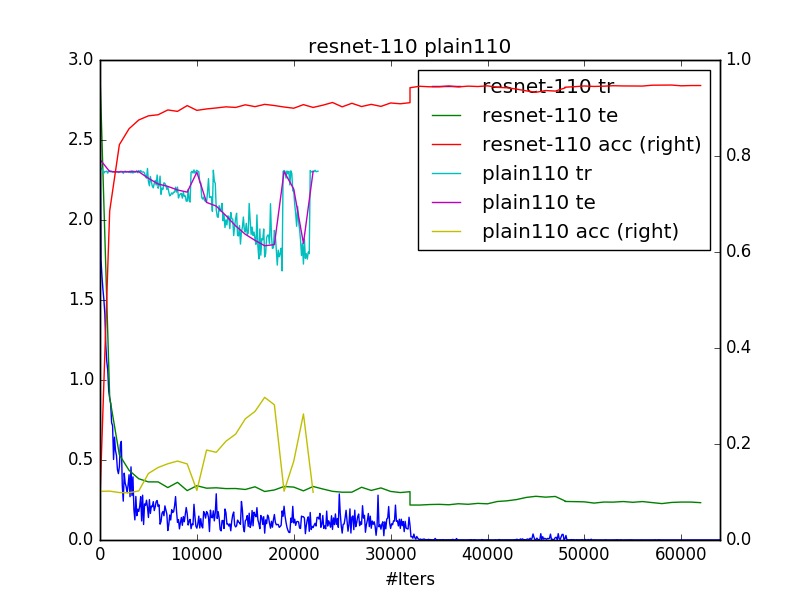
use net_generator.py to generate solver.prototxt and trainval.prototxt, you can generate resnet or plain net of depth 20/32/44/56/110, or even deeper if you want. you just need to change n according to depth=6n+2
./create_cifar.shcreate 4 pixel padded training LMDB and testing LMDB, then create a soft link ln -s cifar-10-batches-py in this folder. - get cifar10 python version - use data_utils.py to generate 4 pixel padded training data and testing data. Horizontal flip and random crop are performed on the fly while training.