+ +
+
+
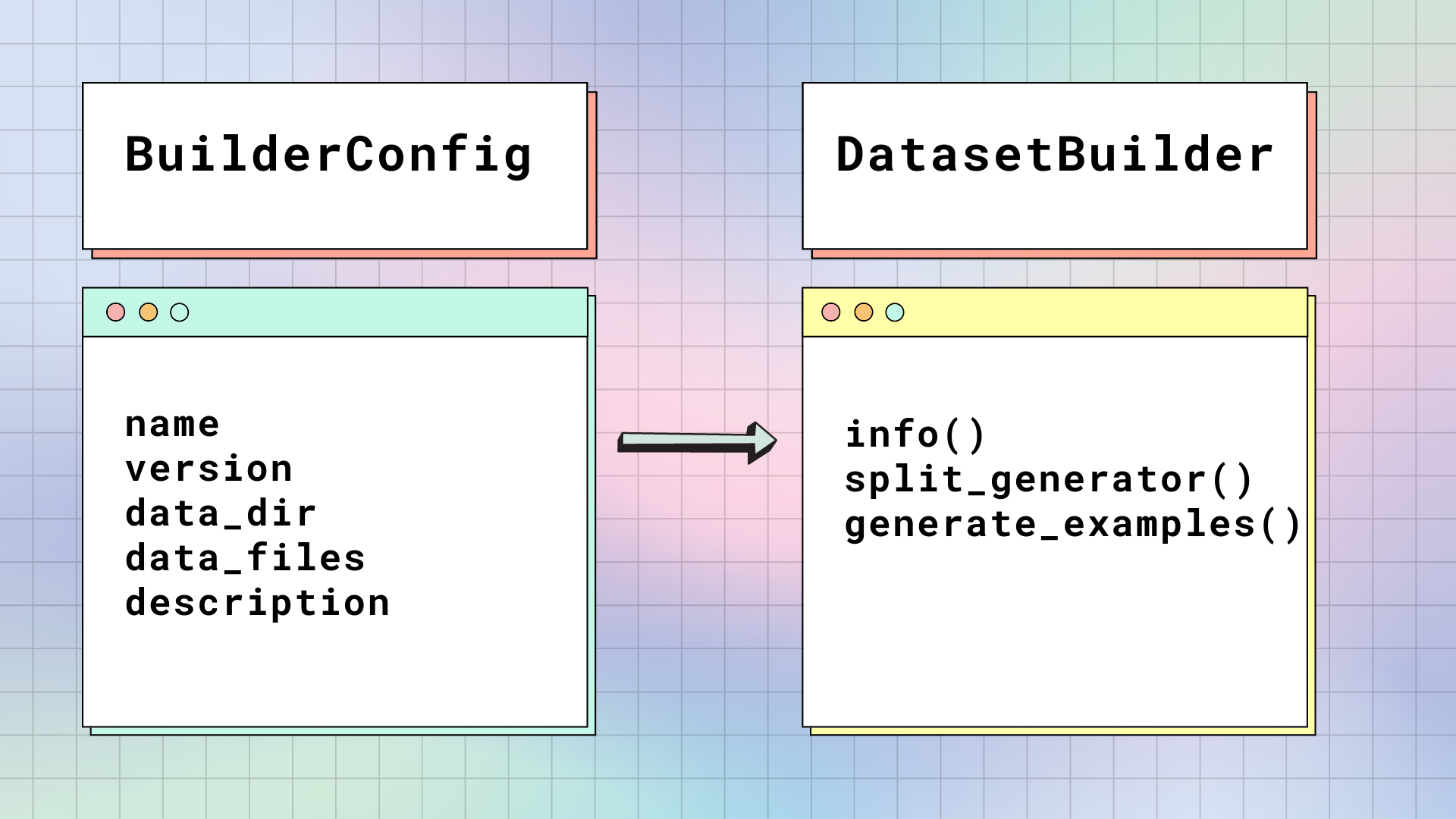
+### BuilderConfig[[datasets-builderconfig]]
+
+[`BuilderConfig`] هي فئة تكوين [`DatasetBuilder`]. يحتوي [`BuilderConfig`] على السمات الأساسية التالية حول مجموعة البيانات:
+
+| السمة | الوصف |
+|---------------|--------------------------------------------------------------|
+| `name` | الاسم المختصر لمجموعة البيانات. |
+| `version` | محدد إصدار مجموعة البيانات. |
+| `data_dir` | يقوم بتخزين المسار إلى مجلد محلي يحتوي على ملفات البيانات. |
+| `data_files` | يقوم بتخزين المسارات إلى ملفات البيانات المحلية. |
+| `description` | وصف مجموعة البيانات. |
+
+إذا كنت تريد إضافة سمات إضافية إلى مجموعة البيانات الخاصة بك مثل تسميات الفئات، فيمكنك إنشاء فئة فرعية من فئة [`BuilderConfig`] الأساسية. هناك طريقتان لملء سمات فئة [`BuilderConfig`] أو الفئة الفرعية:
+
+- تقديم قائمة من مثيلات فئة [`BuilderConfig`] المحددة مسبقًا (أو الفئة الفرعية) في سمة [`DatasetBuilder.BUILDER_CONFIGS`] لمجموعات البيانات.
+- عندما تستدعي [`load_dataset`]`load_dataset`، فإن أي وسيطات كلمات رئيسية ليست خاصة بالطريقة ستستخدم لتعيين السمات المرتبطة لفئة [`BuilderConfig`]. سيؤدي هذا إلى تجاوز السمات المحددة مسبقًا إذا تم تحديد تكوين معين.
+
+يمكنك أيضًا تعيين [`DatasetBuilder.BUILDER_CONFIG_CLASS`] إلى أي فئة فرعية مخصصة من [`BuilderConfig`].
+
+### DatasetBuilder[[datasets-datasetbuilder]]
+
+يصل [`DatasetBuilder`] إلى جميع السمات داخل [`BuilderConfig`] لبناء مجموعة البيانات الفعلية.
+
+
+
+ +
+
+
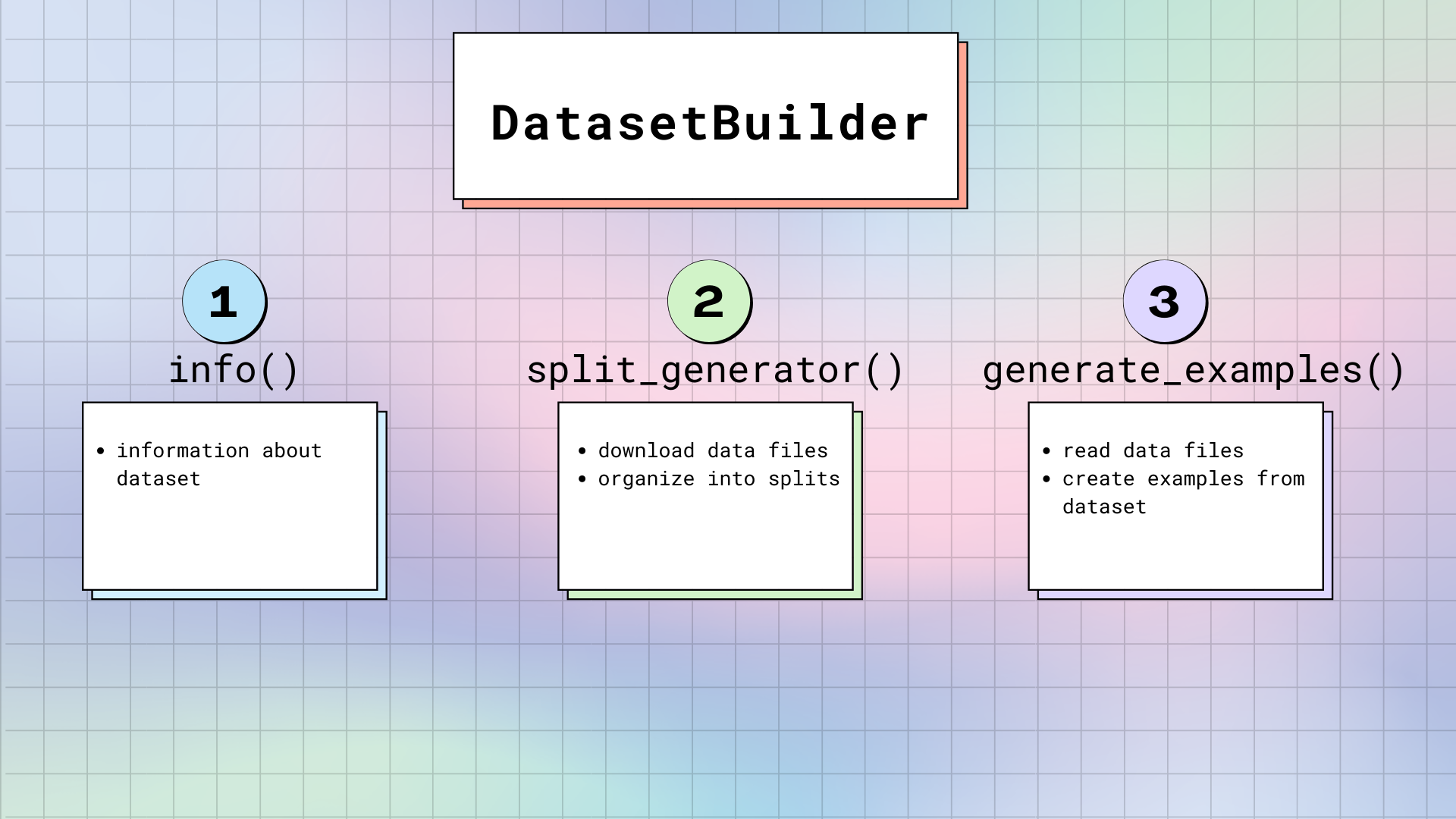
+هناك ثلاث طرق رئيسية في [`DatasetBuilder`]:
+
+1. [`DatasetBuilder._info`] مسؤول عن تحديد سمات مجموعة البيانات. عندما تستدعي `dataset.info`، فإن 🤗 Datasets يعيد المعلومات المخزنة هنا. وبالمثل، يتم أيضًا تحديد [`Features`] هنا. تذكر، [`Features`] هي مثل الهيكل العظمي لمجموعة البيانات. فهو يوفر أسماء وأنواع كل عمود.
+
+2. [`DatasetBuilder._split_generator`] يقوم بتنزيل ملفات البيانات المطلوبة أو استردادها، وتنظيمها في تقسيمات، وتحديد الحجج المحددة لعملية التوليد. تحتوي هذه الطريقة على [`DownloadManager`] يقوم بتنزيل الملفات أو استردادها من نظام الملفات المحلي. داخل [`DownloadManager`]، توجد طريقة [`DownloadManager.download_and_extract`] تقبل قاموسًا من عناوين URL لملفات البيانات الأصلية، وتقوم بتنزيل الملفات المطلوبة. تتضمن المدخلات المقبولة: عنوان URL أو مسار واحد، أو قائمة/قاموس من عناوين URL أو المسارات. سيتم استخراج أي أنواع ملفات مضغوطة مثل أرشيفات TAR و GZIP و ZIP تلقائيًا.
+
+بمجرد تنزيل الملفات، يقوم [`SplitGenerator`] بتنظيمها في تقسيمات. يحتوي [`SplitGenerator`] على اسم التقسيم، وأي وسيطات كلمات رئيسية يتم توفيرها لطريقة [`DatasetBuilder._generate_examples`]. يمكن أن تكون وسيطات الكلمات الرئيسية محددة لكل تقسيم، وعادة ما تتكون على الأقل من المسار المحلي لملفات البيانات لكل تقسيم.
+
+3. يقوم [`DatasetBuilder._generate_examples`] بقراءة ملفات البيانات لتقسيمها وتحليلها. ثم يقوم بإنتاج أمثلة مجموعة البيانات وفقًا للتنسيق المحدد في `features` من [`DatasetBuilder._info`]. في الواقع، فإن إدخال [`DatasetBuilder._generate_examples`] هو `filepath` المقدم في وسيطات الكلمات الرئيسية للطريقة الأخيرة.
+
+تتم توليد مجموعة البيانات باستخدام مولد Python، والذي لا يحمّل جميع البيانات في الذاكرة. ونتيجة لذلك، يمكن للمولد التعامل مع مجموعات البيانات الكبيرة. ومع ذلك، قبل مسح العينات المولدة إلى ملف مجموعة البيانات على القرص، يتم تخزينها في مؤشر ترابط `ArrowWriter`. وهذا يعني أن العينات المولدة يتم كتابتها على دفعات. إذا كانت عينات مجموعة البيانات تستهلك الكثير من الذاكرة (الصور أو مقاطع الفيديو)، فتأكد من تحديد قيمة منخفضة لسمة `DEFAULT_WRITER_BATCH_SIZE` في [`DatasetBuilder`]. نوصي بعدم تجاوز حجم 200 ميجابايت.
+
+## الحفاظ على السلامة
+
+لضمان اكتمال مجموعة البيانات، سيقوم [`load_dataset`] بإجراء سلسلة من الاختبارات على الملفات التي تم تنزيلها للتأكد من وجود كل شيء. بهذه الطريقة، لن تواجه أي مفاجآت عندما لا يتم إنشاء مجموعة البيانات المطلوبة كما هو متوقع. يتحقق [`load_dataset`] مما يلي:
+
+- عدد التقسيمات في `DatasetDict` المولدة.
+- عدد العينات في كل تقسيم من `DatasetDict` المولدة.
+- قائمة الملفات التي تم تنزيلها.
+- اختبارات SHA256 للملفات التي تم تنزيلها (معطلة افتراضيًا).
+
+إذا لم تمر مجموعة البيانات بالتحقق، فمن المحتمل أن يكون المضيف الأصلي لمجموعة البيانات قد أجرى بعض التغييرات في ملفات البيانات.
+
+
+
+ +
+ +
+
+
+## خريطة
+
+تساعد دالة [`~Dataset.map`] في معالجة مجموعة البيانات بأكملها مرة واحدة. اعتمادًا على نوع النموذج الذي تعمل عليه، ستحتاج إلى تحميل إما [مستخرج الميزات](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoFeatureExtractor) أو [معالج](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoProcessor).
+
+- بالنسبة لنماذج التعرف على الكلام المُدربة مسبقًا، قم بتحميل مستخرج ميزات ومُعلم رموز ودمجهما في معالج:
+
+```py
+>>> from transformers import AutoTokenizer, AutoFeatureExtractor, AutoProcessor
+
+>>> model_checkpoint = "facebook/wav2vec2-large-xlsr-53"
+# بعد تحديد ملف vocab.json، يمكنك إنشاء كائن tokenizer:
+>>> tokenizer = AutoTokenizer("./vocab.json", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|")
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained(model_checkpoint)
+>>> processor = AutoProcessor.from_pretrained(feature_extractor=feature_extractor, tokenizer=tokenizer)
+```
+
+- بالنسبة لنماذج التعرف على الكلام الدقيقة، فأنت بحاجة فقط إلى تحميل معالج:
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
+```
+
+عندما تستخدم [`~Dataset.map`] مع دالة المعالجة المسبقة، قم بتضمين عمود "الصوت" للتأكد من إعادة أخذ عينات بيانات الصوت بالفعل:
+
+```py
+>>> def prepare_dataset(batch):
+... audio = batch["audio"]
+... batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
+... batch["input_length"] = len(batch["input_values"])
+... with processor.as_target_processor():
+... batch["labels"] = processor(batch["sentence"]).input_ids
+... return batch
+>>> dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)
+```
diff --git a/docs/source/ar/cache.mdx b/docs/source/ar/cache.mdx
new file mode 100644
index 00000000000..f9f4d5a4481
--- /dev/null
+++ b/docs/source/ar/cache.mdx
@@ -0,0 +1,80 @@
+# إدارة الذاكرة المؤقتة
+
+عند تنزيل مجموعة بيانات، يتم تخزين بيانات البرنامج النصي للمعالجة والبيانات محليًا على جهاز الكمبيوتر الخاص بك. تسمح الذاكرة المؤقتة لـ 🤗 Datasets بتجنب إعادة تنزيل مجموعة البيانات أو معالجتها كل مرة تستخدمها فيها.
+
+سيوضح هذا الدليل كيفية:
+
+- تغيير دليل الذاكرة المؤقتة.
+- التحكم في كيفية تحميل مجموعة البيانات من الذاكرة المؤقتة.
+- تنظيف ملفات الذاكرة المؤقتة في الدليل.
+- تمكين أو تعطيل التخزين المؤقت.
+
+## دليل الذاكرة المؤقتة
+
+دليل الذاكرة المؤقتة الافتراضي هو `~/.cache/huggingface/datasets`. لتغيير موقع الذاكرة المؤقتة، قم بتعيين متغير البيئة الخاص بـ shell، `HF_DATASETS_CACHE` إلى دليل آخر:
+
+```
+$ export HF_DATASETS_CACHE="/path/to/another/directory"
+```
+
+عند تحميل مجموعة بيانات، لديك أيضًا خيار تغيير المكان الذي يتم فيه تخزين البيانات مؤقتًا. قم بتغيير `cache_dir` المعلمة إلى المسار الذي تريده:
+
+```py
+>>> from datasets import load_dataset
+>>> dataset = load_dataset('LOADING_SCRIPT', cache_dir="PATH/TO/MY/CACHE/DIR")
+```
+
+## وضع التنزيل
+
+بعد تنزيل مجموعة بيانات، يمكنك التحكم في كيفية تحميلها بواسطة [`load_dataset`] مع `download_mode` المعلمة. بشكل افتراضي، سيقوم 🤗 Datasets بإعادة استخدام مجموعة بيانات إذا كانت موجودة. ولكن إذا كنت بحاجة إلى مجموعة البيانات الأصلية دون تطبيق أي وظائف معالجة، فأعد تنزيل الملفات كما هو موضح أدناه:
+
+```py
+>>> from datasets import load_dataset
+>>> dataset = load_dataset('squad', download_mode='force_redownload')
+```
+
+راجع [`DownloadMode`] للحصول على قائمة كاملة بوضعيات التنزيل.
+
+## ملفات ذاكرة التخزين المؤقت
+
+قم بتنظيف ملفات ذاكرة التخزين المؤقت في الدليل باستخدام [`Dataset.cleanup_cache_files`]:
+
+```py
+# Returns the number of removed cache files
+>>> dataset.cleanup_cache_files()
+2
+```
+
+## تمكين أو تعطيل التخزين المؤقت
+
+إذا كنت تستخدم ملف ذاكرة التخزين المؤقت محليًا، فسيتم تلقائيًا إعادة تحميل مجموعة البيانات مع أي تحويلات سابقة قمت بتطبيقها على مجموعة البيانات. قم بتعطيل هذا السلوك عن طريق تعيين الحجة `load_from_cache_file=False` في [`Dataset.map`]:
+
+```py
+>>> updated_dataset = small_dataset.map(add_prefix, load_from_cache_file=False)
+```
+
+في المثال أعلاه، سيقوم 🤗 Datasets بتنفيذ الدالة `add_prefix` على مجموعة البيانات بالكامل مرة أخرى بدلاً من تحميل مجموعة البيانات من حالتها السابقة.
+
+قم بتعطيل التخزين المؤقت على نطاق عالمي باستخدام [`disable_caching`]:
+
+```py
+>>> from datasets import disable_caching
+>>> disable_caching()
+```
+
+عندما تقوم بتعطيل التخزين المؤقت، لن يقوم 🤗 Datasets بإعادة تحميل ملفات ذاكرة التخزين المؤقت عند تطبيق التحويلات على مجموعات البيانات. يجب إعادة تطبيق أي تحويل تقوم بتطبيقه على مجموعة البيانات الخاصة بك.
+
+
+
+
+  +
+
+
+
+[`AudioFolder`] يستخدم [`~datasets.Audio`] لترميز ملفات الصوت، والتي تدعم العديد من تنسيقات ملفات الصوت. يمكنك التحقق من [قائمة] (https://github.com/huggingface/datasets/blob/b5672a956d5de864e6f5550e493527d962d6ae55/src/datasets/packaged_modules/audiofolder/audiofolder.py#L39) من ملحقات الصوت المدعومة.
+
+مثل [`ImageFolder`] ، [`AudioFolder`] سيقوم تلقائيًا بإنشاء ميزات مجموعة البيانات والانقسامات والعلامات بناءً على بنية المجلد.
+
+### إنشاء مجموعة بيانات
+
+لإنشاء مجموعة بيانات باستخدام أي من هذه الأساليب، ما عليك سوى تحديد المسار إلى المجلد الذي يحتوي على بياناتك.
+
+على سبيل المثال، لإنشاء مجموعة بيانات صورة، يمكنك استخدام [`load_dataset`] مع الحجة `imagefolder` :
+
+```بيثون
+>>> من مجموعات البيانات استيراد load_dataset
+
+>>> dataset = load_dataset ("imagefolder"، data_dir = "/ path / to / pokemon")
+```
+
+بالنسبة لمجموعة بيانات الصوت، استخدم `audiofolder` بدلاً من ذلك:
+
+```بيثون
+>>> من مجموعات البيانات استيراد load_dataset
+
+>>> dataset = load_dataset ("audiofolder"، data_dir = "/ path / to / folder")
+```
+
+سيؤدي ذلك إلى تحميل مجموعة البيانات الخاصة بك في [`Dataset`] الكائن، والذي يمكنك بعد ذلك استخدامه للتدريب أو المعالجة أو أي شيء آخر!
+
+يمكنك تضمين أي معلومات إضافية حول بياناتك، مثل التعليقات التوضيحية أو النسخ النصية، في ملف `metadata.csv` في المجلد الذي يحتوي على بياناتك. يجب أن يحتوي ملف التعريف على عمود `file_name` يربط ملف الصورة أو الصوت بالبيانات الوصفية المقابلة.
+
+على سبيل المثال، قد يبدو ملف التعريف لمجموعة بيانات بوكيمون على النحو التالي:
+
+```
+file_name، text
+bulbasaur.png، هناك بذرة نبات على ظهره الأيمن منذ اليوم الذي ولد فيه هذا بوكيمون.
+charmander.png، إنه يفضل الأشياء الساخنة.
+سكويرتل. png، عندما يسحب رقبته الطويلة إلى قوقعته، فإنه يرش الماء بقوة شديدة.
+```
+
+لمعرفة المزيد حول [`ImageFolder`] و [`AudioFolder`] ، تحقق من أدلة [ImageFolder] (https://huggingface.co/docs/datasets/image_dataset#imagefolder) و [AudioFolder] (https://huggingface.co/docs/datasets/audio_dataset#audiofolder).
+
+## من ملفات محلية
+
+يمكنك أيضًا إنشاء مجموعة بيانات عن طريق تحديد المسار إلى ملفات البيانات المحلية الخاصة بك مباشرة. هناك طريقتان للقيام بذلك: [`~Dataset.from_generator`] و [`~Dataset.from_dict`] .
+
+### من مولد
+
+إذا كانت لديك وظيفة مولد، فيمكنك استخدام [`~Dataset.from_generator`] لإنشاء مجموعة بيانات. هذا مفيد بشكل خاص لمجموعات البيانات الكبيرة جدًا التي قد لا تناسب الذاكرة، لأن مجموعة البيانات يتم إنشاؤها تدريجيًا على القرص ثم يتم رسمها في الذاكرة.
+
+على سبيل المثال، يمكنك إنشاء مجموعة بيانات بوكيمون على النحو التالي:
+
+```بيثون
+>>> من مجموعات البيانات استيراد Dataset
+>>> ديف gen ():
+... عائد {"بوكيمون": "بلباسور"، "نوع": "عشب"}
+... عائد {"بوكيمون": "سكويرتل"، "نوع": "ماء"}
+>>> ds = Dataset.from_generator (gen)
+>>> ds [0]
+{"بوكيمون": "بلباسور"، "نوع": "عشب"}
+```
+
+إذا كنت تريد استخدام مجموعة بيانات قابلة للتحديد، فيمكنك استخدام [`IterableDataset.from_generator`] بدلاً من ذلك:
+
+```بيثون
+>>> من مجموعات البيانات استيراد IterableDataset
+>>> ds = IterableDataset.from_generator (gen)
+>>> ل example في ds:
+... طباعة (مثال)
+{"بوكيمون": "بلباسور"، "نوع": "عشب"}
+{"بوكيمون": "سكويرتل"، "نوع": "ماء"}
+```
+
+### من القاموس
+
+إذا كانت لديك بياناتك في قاموس، فيمكنك استخدام [`~Dataset.from_dict`] لإنشاء مجموعة بيانات. ببساطة تمرير قاموسك إلى الأسلوب، وسيتم إنشاء مجموعة البيانات الخاصة بك!
+
+على سبيل المثال:
+
+```بيثون
+>>> من مجموعات البيانات استيراد Dataset
+>>> ds = Dataset.from_dict ({'بوكيمون': ['بلباسور'، 'سكويرتل']، 'نوع': ['عشب'، 'ماء']})
+>>> ds [0]
+{"بوكيمون": "بلباسور"، "نوع": "عشب"}
+```
+
+لإنشاء مجموعة بيانات صورة أو صوت، يمكنك ربط [`~Dataset.cast_column`] الأسلوب [`~Dataset.from_dict`] . على سبيل المثال، لإنشاء مجموعة بيانات صوت، حدد العمود والنوع [`Audio`] :
+
+```بيثون
+>>> audio_dataset = Dataset.from_dict ({'audio': ['path / to / audio_1'،... 'path / to / audio_n']}). cast_column ('audio', Audio ())
+```
+
+## الخطوات التالية
+
+لم نذكر ذلك في البرنامج التعليمي، ولكن يمكنك أيضًا إنشاء مجموعة بيانات باستخدام نص برمجي تحميل. يعد هذا خيارًا أكثر كثافة في التعليمات البرمجية، ولكنه قد يكون مفيدًا في بعض الحالات النادرة. لمعرفة المزيد، راجع أدلة نص البرنامج النصي لتحميل [الصورة] (https://huggingface.co/docs/datasets/main/en/image_dataset#loading-script) و [الصوت] (https://huggingface.co/docs/datasets/main/en/audio_dataset) و [النص] (https://huggingface.co/docs/datasets/main/en/dataset_script).
+
+الآن بعد أن عرفت كيفية إنشاء مجموعة بيانات، فكر في مشاركتها على Hub حتى يتمكن المجتمع أيضًا من الاستفادة من عملك! انتقل إلى القسم التالي لمعرفة كيفية مشاركة مجموعة البيانات الخاصة بك.
\ No newline at end of file
diff --git a/docs/source/ar/dataset_card.mdx b/docs/source/ar/dataset_card.mdx
new file mode 100644
index 00000000000..40b30f47e6f
--- /dev/null
+++ b/docs/source/ar/dataset_card.mdx
@@ -0,0 +1,28 @@
+# إنشاء بطاقة مجموعة بيانات
+
+يجب أن تحتوي كل مجموعة بيانات على بطاقة مجموعة بيانات لتعزيز الاستخدام المسؤول وإعلام المستخدمين بأي تحيزات محتملة داخل مجموعة البيانات. استلهمت هذه الفكرة من بطاقات النموذج التي اقترحتها [Mitchell, 2018](https://arxiv.org/abs/1810.03993).
+
+تساعد بطاقات مجموعة البيانات المستخدمين على فهم محتويات مجموعة البيانات وسياق استخدامها وكيفية إنشائها وأي اعتبارات أخرى يجب أن يكون المستخدم على دراية بها.
+
+من السهل إنشاء بطاقة مجموعة بيانات ويمكن القيام بذلك في بضع خطوات فقط:
+
+1. انتقل إلى مستودع مجموعة البيانات الخاصة بك على [Hub](https://hf.co/new-dataset) وانقر على **إنشاء بطاقة مجموعة بيانات** لإنشاء ملف `README.md` جديد في مستودعك.
+
+2. استخدم واجهة مستخدم **Metadata** لتحديد العلامات التي تصف مجموعة البيانات الخاصة بك. يمكنك إضافة ترخيص ولغة وpretty_name وtask_categories وsize_categories وأي علامات أخرى تعتقد أنها ذات صلة. تساعد هذه العلامات المستخدمين على اكتشاف والعثور على مجموعة البيانات الخاصة بك على Hub.
+
+
+
+  +
+  +
+
+
+
+
+
+ +
+
+
+قبل أن نلقي نظرة على خريطة العمق، يجب علينا أولاً تحويل نوع البيانات الخاص بها إلى `uint8` باستخدام `.convert('RGB')` لأن PIL لا يمكنه عرض صور `float32`. الآن، الق نظرة على خريطة العمق المقابلة:
+
+```py
+>>> example["depth_map"].convert("RGB")
+```
+
+
+
+ +
+
+
+إنها سوداء تمامًا! ستحتاج إلى إضافة بعض الألوان إلى خريطة العمق لتصورها بشكل صحيح. للقيام بذلك، يمكننا إما تطبيق الألوان تلقائيًا أثناء العرض باستخدام `plt.imshow()` أو إنشاء خريطة عمق ملونة باستخدام `plt.cm` ثم عرضها. في هذا المثال، استخدمنا الأخيرة، حيث يمكننا حفظ/كتابة خريطة العمق الملونة لاحقًا. (تم أخذ الأداة المساعدة أدناه من [مستودع FastDepth](https://github.com/dwofk/fast-depth/blob/master/utils.py)).
+
+```py
+>>> import numpy as np
+>>> import matplotlib.pyplot as plt
+
+>>> cmap = plt.cm.viridis
+
+>>> def colored_depthmap(depth, d_min=None, d_max=None):
+... if d_min is None:
+... d_min = np.min(depth)
+... if d_max is None:
+... d_max = np.max(depth)
+... depth_relative = (depth - d_min) / (d_max - d_min)
+... return 255 * cmap(depth_relative)[:,:,:3]
+
+>>> def show_depthmap(depth_map):
+... if not isinstance(depth_map, np.ndarray):
+... depth_map = np.array(depth_map)
+... if depth_map.ndim == 3:
+... depth_map = depth_map.squeeze()
+
+... d_min = np.min(depth_map)
+... d_max = np.max(depth_map)
+... depth_map = colored_depthmap(depth_map, d_min, d_max)
+
+... plt.imshow(depth_map.astype("uint8"))
+... pltMultiplier
+... plt.axis("off")
+... plt.show()
+
+>>> show_depthmap(example["depth_map"])
+```
+
+
+
+ +
+
+
+يمكنك أيضًا تصور العديد من الصور المختلفة وخرائط العمق المقابلة لها.
+
+```py
+>>> def merge_into_row(input_image, depth_target):
+... if not isinstance(input_image, np.ndarray):
+... input_image = np.array(input_image)
+...
+... d_min = np.min(depth_target)
+... d_max = np.max(depth_target)
+... depth_target_col = colored_depthmap(depth_target, d_min, d_max)
+... img_merge = np.hstack([input_image, depth_target_col])
+...
+... return img_merge
+
+>>> random_indices = np.random.choice(len(train_dataset), 9).tolist()
+>>> plt.figure(figsize=(15, 6))
+>>> for i, idx in enumerate(random_indices):
+... example = train_dataset[idx]
+... ax = plt.subplot(3, 3, i + 1)
+... image_viz = merge_into_row(
+... example["image"], example["depth_map"]
+... )
+... plt.imshow(image_viz.astype("uint8"))
+... plt.axis("off")
+```
+
+
+
+ +
+
+
+الآن، قم بتطبيق بعض التحسينات باستخدام `albumentations`. تتضمن تحولات التعزيز ما يلي:
+
+* الانعكاس الأفقي العشوائي
+* القص العشوائي
+* السطوع العشوائي والتباين
+* تصحيح غاما العشوائي
+* التشبع العشوائي للصبغة
+
+```py
+>>> import albumentations as A
+
+>>> crop_size = (448, 576)
+>>> transforms = [
+... A.HorizontalFlip(p=0.5),
+... A.RandomCrop(crop_size[0], crop_size[1]),
+... A.RandomBrightnessContrast(),
+... A.RandomGamma(),
+... A.HueSaturationValue()
+... ]
+```
+
+بالإضافة إلى ذلك، حدد خريطة إلى الاسم المستهدف بشكل أفضل.
+
+```py
+>>> additional_targets = {"depth": "mask"}
+>>> aug = A.Compose(transforms=transforms, additional_targets=additional_targets)
+```
+
+مع `additional_targets` المحددة، يمكنك تمرير خرائط العمق المستهدفة إلى وسيط `depth` من `aug` بدلاً من `mask`. ستلاحظ هذا التغيير في دالة `apply_transforms()` المحددة أدناه.
+
+قم بإنشاء دالة لتطبيق التحول على الصور وكذلك خرائط العمق الخاصة بها:
+
+```py
+>>> def apply_transforms(examples):
+... transformed_images, transformed_maps = [], []
+... for image, depth_map in zip(examples["image"], examples["depth_map"]):
+... image, depth_map = np.array(image), np.array(depth_map)
+... transformed = aug(image=image, depth=depth_map)
+... transformed_images.append(transformed["image"])
+... transformed_maps.append(transformed["depth"])
+...
+... examples["pixel_values"] = transformed_images
+... examples["labels"] = transformed_maps
+... return examples
+```
+
+استخدم وظيفة [`~Dataset.set_transform`] لتطبيق التحول أثناء التنقل على دفعات من مجموعة البيانات لتقليل استخدام مساحة القرص:
+
+```py
+>>> train_dataset.set_transform(apply_transforms)
+```
+
+يمكنك التحقق من أن التحول قد عمل عن طريق الفهرسة في `pixel_values` و`labels` لصورة مثال:
+
+```py
+>>> example = train_dataset[index]
+
+>>> plt.imshow(example["pixel_values"])
+>>> plt.axis("off")
+>>> plt.show()
+```
+
+
+
+ +
+
+
+قم بتصور نفس التحول على خريطة العمق المقابلة للصورة:
+
+```py
+>>> show_depthmap(example["labels"])
+```
+
+
+
+ +
+
+
+يمكنك أيضًا تصور عدة عينات تدريبية عن طريق إعادة استخدام `random_indices` السابقة:
+
+```py
+>>> plt.figure(figsize=(15, 6))
+
+>>> for i, idx in enumerate(random_indices):
+... ax = plt.subplot(3, 3, i + 1)
+... example = train_dataset[idx]
+... image_viz = merge_into_row(
+... example["pixel_values"], example["labels"]
+... )
+... plt.imshow(image_viz.astype("uint8"))
+... plt.axis("off")
+```
+
+
+
+ +
+
\ No newline at end of file
diff --git a/docs/source/ar/faiss_es.mdx b/docs/source/ar/faiss_es.mdx
new file mode 100644
index 00000000000..01146751497
--- /dev/null
+++ b/docs/source/ar/faiss_es.mdx
@@ -0,0 +1,133 @@
+# فهرس البحث
+
+[FAISS](https://github.com/facebookresearch/faiss) و [Elasticsearch](https://www.elastic.co/elasticsearch/) يتيحان إمكانية البحث عن أمثلة في مجموعة بيانات. يمكن أن يكون هذا مفيدًا عندما تريد استرداد أمثلة محددة من مجموعة بيانات ذات صلة بمهمة معالجة اللغات الطبيعية الخاصة بك. على سبيل المثال، إذا كنت تعمل على مهمة "الأسئلة والأجوبة المفتوحة المجال"، فقد ترغب في إرجاع الأمثلة ذات الصلة فقط بالإجابة على سؤالك.
+
+سيوضح هذا الدليل كيفية إنشاء فهرس لمجموعة البيانات الخاصة بك يسمح بالبحث فيها.
+
+## FAISS
+
+يسترد FAISS المستندات بناءً على تشابه تمثيلاتها المتجهية. في هذا المثال، ستقوم بتوليد التمثيلات المتجهية باستخدام نموذج [DPR](https://huggingface.co/transformers/model_doc/dpr.html).
+
+1. قم بتنزيل نموذج DPR من 🤗 Transformers:
+
+ ```py
+ >>> from transformers import DPRContextEncoder, DPRContextEncoderTokenizer
+ >>> import torch
+ >>> torch.set_grad_enabled(False)
+ >>> ctx_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
+ >>> ctx_tokenizer = DPRContextEncoderTokenizer.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
+ ```
+
+2. قم بتحميل مجموعة البيانات واحسب التمثيلات المتجهية:
+
+ ```py
+ >>> from datasets import load_dataset
+ >>> ds = load_dataset('crime_and_punish', split='train[:100]')
+ >>> ds_with_embeddings = ds.map(lambda example: {'embeddings': ctx_encoder(**ctx_tokenizer(example["line"], return_tensors="pt"))[0][0].numpy()})
+ ```
+
+3. قم بإنشاء الفهرس باستخدام [`Dataset.add_faiss_index`]:
+
+ ```py
+ >>> ds_with_embeddings.add_faiss_index(column='embeddings')
+ ```
+
+4. الآن يمكنك استعلام مجموعة البيانات الخاصة بك باستخدام فهرس `embeddings`. قم بتحميل نموذج DPR Question Encoder، وابحث عن سؤال باستخدام [`Dataset.get_nearest_examples`]:
+
+ ```py
+ >>> from transformers import DPRQuestionEncoder, DPRQuestionEncoderTokenizer
+ >>> q_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
+ >>> q_tokenizer = DPRQuestionEncoderTokenizer.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
+
+ >>> question = "Is it serious ?"
+ >>> question_embedding = q_encoder(**q_tokenizer(question, return_tensors="pt"))[0][0].numpy()
+ >>> scores, retrieved_examples = ds_with_embeddings.get_nearest_examples('embeddings', question_embedding, k=10)
+ >>> retrieved_examples["line"][0]
+ '_that_ serious? It is not serious at all. It’s simply a fantasy to amuse\r\n'
+ ```
+
+5. يمكنك الوصول إلى الفهرس باستخدام [`Dataset.get_index`] واستخدامه لعمليات خاصة، على سبيل المثال، استعلامه باستخدام `range_search`:
+
+ ```py
+ >>> faiss_index = ds_with_embeddings.get_index('embeddings').faiss_index
+ >>> limits, distances, indices = faiss_index.range_search(x=question_embedding.reshape(1, -1), thresh=0.95)
+ ```
+
+6. عندما تنتهي من الاستعلام، احفظ الفهرس على القرص باستخدام [`Dataset.save_faiss_index`]:
+
+ ```py
+ >>> ds_with_embeddings.save_faiss_index('embeddings', 'my_index.faiss')
+ ```
+
+7. أعد تحميله لاحقًا باستخدام [`Dataset.load_faiss_index`]:
+
+ ```py
+ >>> ds = load_dataset('crime_and_punish', split='train[:100]')
+ >>> ds.load_faiss_index('embeddings', 'my_index.faiss')
+ ```
+
+## Elasticsearch
+
+على عكس FAISS، يسترد Elasticsearch المستندات بناءً على تطابقات دقيقة.
+
+ابدأ تشغيل Elasticsearch على جهازك، أو راجع [دليل تثبيت Elasticsearch](https://www.elastic.co/guide/en/elasticsearch/reference/current/setup.html) إذا لم يكن لديك بالفعل.
+
+1. قم بتحميل مجموعة البيانات التي تريد إنشاء فهرس لها:
+
+ ```py
+ >>> from datasets import load_dataset
+ >>> squad = load_dataset('squad', split='validation')
+ ```
+
+2. قم ببناء الفهرس باستخدام [`Dataset.add_elasticsearch_index`]:
+
+ ```py
+ >>> squad.add_elasticsearch_index("context", host="localhost", port="9200")
+ ```
+
+3. بعد ذلك، يمكنك استعلام فهرس `context` باستخدام [`Dataset.get_nearest_examples`]:
+
+ ```py
+ >>> query = "machine"
+ >>> scores, retrieved_examples = squad.get_nearest_examples("context", query, k=10)
+ >>> retrieved_examples["title"][0]
+ 'Computational_complexity_theory'
+ ```
+
+4. إذا كنت تريد إعادة استخدام الفهرس، فقم بتعريف معلمة `es_index_name` عند بناء الفهرس:
+
+ ```py
+ >>> from datasets import load_dataset
+ >>> squad = load_dataset('squad', split='validation')
+ >>> squad.add_elasticsearch_index("context", host="localhost", port="9200", es_index_name="hf_squad_val_context")
+ >>> squad.get_index("context").es_index_name
+ hf_squad_val_context
+ ```
+
+5. أعد تحميله لاحقًا باستخدام اسم الفهرس عند استدعاء [`Dataset.load_elasticsearch_index`]:
+
+ ```py
+ >>> from datasets import load_dataset
+ >>> squad = load_dataset('squad', split='validation')
+ >>> squad.load_elasticsearch_index("context", host="localhost", port="9200", es_index_name="hf_squad_val_context")
+ >>> query = "machine"
+ >>> scores, retrieved_examples = squad.get_nearest_examples("context", query, k=10)
+ ```
+
+لاستخدامات Elasticsearch المتقدمة، يمكنك تحديد تكوينك الخاص باستخدام إعدادات مخصصة:
+
+ ```py
+ >>> import elasticsearch as es
+ >>> import elasticsearch.helpers
+ >>> from elasticsearch import Elasticsearch
+ >>> es_client = Elasticsearch([{"host": "localhost", "port": "9200"}]) # العميل الافتراضي
+ >>> es_config = {
+ ... "settings": {
+ ... "number_of_shards": 1,
+ ... "analysis": {"analyzer": {"stop_standard": {"type": "standard", "stopwords": "_english_"}}},
+ ... },
+ ... "mappings": {"properties": {"text": {"type": "text", "analyzer": "standard", "similarity": "BM25"}}},
+ ... } # التهيئة الافتراضية
+ >>> es_index_name = "hf_squad_context" # اسم الفهرس في Elasticsearch
+ >>> squad.add_elasticsearch_index("context", es_client=es_client, es_config=es_config, es_index_name=es_index_name)
+ ```
\ No newline at end of file
diff --git a/docs/source/ar/filesystems.mdx b/docs/source/ar/filesystems.mdx
new file mode 100644
index 00000000000..feb90656fc5
--- /dev/null
+++ b/docs/source/ar/filesystems.mdx
@@ -0,0 +1,221 @@
+# التخزين السحابي
+🤗 Datasets تدعم الوصول إلى مزودي التخزين السحابي من خلال تطبيقات FileSystem الخاصة بـ `fsspec`.
+يمكنك حفظ وتحميل مجموعات البيانات من أي تخزين سحابي بطريقة Pythonic.
+الق نظرة على الجدول التالي لبعض أمثلة مزودي التخزين السحابي المدعومين:
+
+| مزود التخزين | تطبيق نظام الملفات |
+| ------------ | ------------------- |
+| Amazon S3 | [s3fs](https://s3fs.readthedocs.io/en/latest/) |
+| Google Cloud Storage | [gcsfs](https://gcsfs.readthedocs.io/en/latest/) |
+| Azure Blob/DataLake | [adlfs](https://github.com/fsspec/adlfs) |
+| Dropbox | [dropboxdrivefs](https://github.com/MarineChap/dropboxdrivefs) |
+| Google Drive | [gdrivefs](https://github.com/intake/gdrivefs) |
+| Oracle Cloud Storage | [ocifs](https://ocifs.readthedocs.io/en/latest/) |
+
+سيوضح لك هذا الدليل كيفية حفظ وتحميل مجموعات البيانات باستخدام أي تخزين سحابي.
+فيما يلي أمثلة على S3 و Google Cloud Storage و Azure Blob Storage و Oracle Cloud Object Storage.
+
+## قم بإعداد نظام ملفات التخزين السحابي الخاص بك
+
+### Amazon S3
+
+1. قم بتثبيت تطبيق نظام ملفات S3:
+
+```
+>>> pip install s3fs
+```
+
+2. حدد بيانات اعتمادك
+
+لاستخدام اتصال مجهول، استخدم `anon=True`.
+وإلا، قم بتضمين `aws_access_key_id` و `aws_secret_access_key` كلما تفاعلت مع دلو S3 خاص.
+
+```py
+>>> storage_options = {"anon": True} # للاتصال المجهول
+# أو استخدم بيانات اعتمادك
+>>> storage_options = {"key": aws_access_key_id, "secret": aws_secret_access_key} # للدلوات الخاصة
+# أو استخدم جلسة botocore
+>>> import aiobotocore.session
+>>> s3_session = aiobotocore.session.AioSession(profile="my_profile_name")
+>>> storage_options = {"session": s3_session}
+```
+
+3. قم بإنشاء مثيل نظام الملفات الخاص بك
+
+```py
+>>> import s3fs
+>>> fs = s3fs.S3FileSystem(**storage_options)
+```
+
+### Google Cloud Storage
+
+1. قم بتثبيت تطبيق Google Cloud Storage:
+
+```
+>>> conda install -c conda-forge gcsfs
+# أو قم بالتثبيت باستخدام pip
+>>> pip install gcsfs
+```
+
+2. حدد بيانات اعتمادك
+
+```py
+>>> storage_options={"token": "anon"} # للاتصال المجهول
+# أو استخدم بيانات اعتمادك الافتراضية لـ gcloud أو من خدمة بيانات Google
+>>> storage_options={"project": "my-google-project"}
+# أو استخدم بيانات اعتمادك من مكان آخر، راجع الوثائق على https://gcsfs.readthedocs.io/
+>>> storage_options={"project": "my-google-project", "token": TOKEN}
+```
+
+3. قم بإنشاء مثيل نظام الملفات الخاص بك
+
+```py
+>>> import gcsfs
+>>> fs = gcsfs.GCSFileSystem(**storage_options)
+```
+
+### Azure Blob Storage
+
+1. قم بتثبيت تطبيق Azure Blob Storage:
+
+```
+>>> conda install -c conda-forge adlfs
+# أو قم بالتثبيت باستخدام pip
+>>> pip install adlfs
+```
+
+2. حدد بيانات اعتمادك
+
+```py
+>>> storage_options = {"anon": True} # للاتصال المجهول
+# أو استخدم بيانات اعتمادك
+>>> storage_options = {"account_name": ACCOUNT_NAME, "account_key": ACCOUNT_KEY} # لنظام الملفات من الجيل الثاني
+# أو استخدم بيانات اعتمادك مع نظام الملفات من الجيل الأول
+>>> storage_options={"tenant_id": TENANT_ID, "client_id": CLIENT_ID, "client_secret": CLIENT_SECRET}
+```
+
+3. قم بإنشاء مثيل نظام الملفات الخاص بك
+
+```py
+>>> import adlfs
+>>> fs = adlfs.AzureBlobFileSystem(**storage_options)
+```
+
+### Oracle Cloud Object Storage
+
+1. قم بتثبيت تطبيق نظام ملفات OCI:
+
+```
+>>> pip install ocifs
+```
+
+2. حدد بيانات اعتمادك
+
+```py
+>>> storage_options = {"config": "~/.oci/config", "region": "us-ashburn-1"}
+```
+
+3. قم بإنشاء مثيل نظام الملفات الخاص بك
+
+```py
+>>> import ocifs
+>>> fs = ocifs.OCIFileSystem(**storage_options)
+```
+
+## قم بتحميل وحفظ مجموعات البيانات الخاصة بك باستخدام نظام ملفات التخزين السحابي الخاص بك
+
+### قم بتنزيل وإعداد مجموعة بيانات في التخزين السحابي
+
+يمكنك تنزيل وإعداد مجموعة بيانات في التخزين السحابي الخاص بك من خلال تحديد `output_dir` عن بعد في `download_and_prepare`.
+لا تنس استخدام `storage_options` المحددة مسبقًا والتي تحتوي على بيانات اعتمادك للكتابة في تخزين سحابي خاص.
+
+تعمل طريقة `download_and_prepare` في خطوتين:
+
+1. أولاً، يقوم بتنزيل ملفات البيانات الخام (إن وجدت) في ذاكرة التخزين المؤقت المحلية الخاصة بك. يمكنك تعيين دليل ذاكرة التخزين المؤقت الخاصة بك من خلال تمرير `cache_dir` إلى [`load_dataset_builder`]
+
+2. ثم يقوم بتوليد مجموعة البيانات بتنسيق Arrow أو Parquet في التخزين السحابي الخاص بك من خلال التكرار فوق ملفات البيانات الخام.
+
+قم بتحميل برنامج بناء مجموعة بيانات من Hugging Face Hub (راجع [كيفية التحميل من Hugging Face Hub](./loading#hugging-face-hub)):
+
+```py
+>>> output_dir = "s3://my-bucket/imdb"
+>>> builder = load_dataset_builder("imdb")
+>>> builder.download_and_prepare(output_dir, storage_options=storage_options, file_format="parquet")
+```
+
+استخدم ملفات البيانات الخاصة بك (راجع [كيفية تحميل الملفات المحلية والبعيدة](./loading#local-and-remote-files)):
+
+```py
+>>> data_files = {"train": ["path/to/train.csv"]}
+>>> output_dir = "s3://my-bucket/imdb"
+>>> builder = load_dataset_builder("csv", data_files=data_files)
+>>> builder.download_and_prepare(output_dir, storage_options=storage_options, file_format="parquet")
+```
+
+من المستحسن بشدة حفظ الملفات بتنسيق Parquet المضغوط لتحسين عمليات الإدخال/الإخراج من خلال تحديد `file_format="parquet"`.
+وإلا، يتم حفظ مجموعة البيانات كملف Arrow غير مضغوط.
+
+يمكنك أيضًا تحديد حجم الشرائح باستخدام `max_shard_size` (الحجم الافتراضي هو 500 ميجابايت):
+
+```py
+>>> builder.download_and_prepare(output_dir, storage_options=storage_options, file_format="parquet", max_shard_size="1GB")
+```
+
+#### Dask
+
+Dask هي مكتبة حوسبة متوازية ولديها واجهة برمجة تطبيقات تشبه pandas للعمل مع مجموعات بيانات Parquet الأكبر من ذاكرة الوصول العشوائي بشكل متوازي.
+يمكن لـ Dask استخدام عدة خيوط أو عمليات على جهاز واحد، أو مجموعة من الأجهزة لمعالجة البيانات بشكل متواز.
+يدعم Dask البيانات المحلية ولكن أيضًا البيانات من التخزين السحابي.
+
+لذلك، يمكنك تحميل مجموعة بيانات محفوظة كملفات Parquet مجزأة في Dask باستخدام:
+
+```py
+import dask.dataframe as dd
+
+df = dd.read_parquet(output_dir, storage_options=storage_options)
+
+# أو إذا كانت مجموعة البيانات الخاصة بك مقسمة إلى train/valid/test
+df_train = dd.read_parquet(output_dir + f"/{builder.name}-train-*.parquet", storage_options=storage_options)
+df_valid = dd.read_parquet(output_dir + f"/{builder.name}-validation-*.parquet", storage_options=storage_options)
+df_test = dd.read_parquet(output_dir + f"/{builder.name}-test-*.parquet", storage_options=storage_options)
+```
+
+يمكنك معرفة المزيد حول أطر بيانات dask في [وثائقهم](https://docs.dask.org/en/stable/dataframe.html).
+
+## حفظ مجموعات البيانات المسلسلة
+
+بعد معالجة مجموعة البيانات الخاصة بك، يمكنك حفظها في التخزين السحابي الخاص بك باستخدام [`Dataset.save_to_disk`]:
+
+```py
+# حفظ encoded_dataset إلى Amazon S3
+>>> encoded_dataset.save_to_disk("s3://my-private-datasets/imdb/train", storage_options=storage_options)
+# حفظ encoded_dataset إلى Google Cloud Storage
+>>> encoded_dataset.save_to_disk("gcs://my-private-datasets/imdb/train", storage_options=storage_options)
+# حفظ encoded_dataset إلى Microsoft Azure Blob/DataLake
+>>> encoded_dataset.save_to_disk("adl://my-private-datasets/imdb/train", storage_options=storage_options)
+```
+
+
+
+ +
+
+
+الآن قم بتطبيق بعض التحسينات باستخدام `albumentations`. ستقوم بقص الصورة بشكل عشوائي، وقلبها أفقيًا، وتعديل سطوعها.
+
+```py
+>>> import cv2
+>>> import albumentations
+>>> import numpy as np
+
+>>> transform = albumentations.Compose([
+... albumentations.RandomCrop(width=256, height=256),
+... albumentpartum.HorizontalFlip(p=0.5),
+... albumentations.RandomBrightnessContrast(p=0.2),
+... ])
+```
+
+قم بإنشاء دالة لتطبيق التحويل على الصور:
+
+```py
+>>> def transforms(examples):
+... examples["pixel_values"] = [
+... transform(image=np.array(image))["image"] for image in examples["image"]
+... ]
+...
+... return examples
+```
+
+استخدم وظيفة [`~Dataset.set_transform`] لتطبيق التحويل أثناء التنقل على دفعات من مجموعة البيانات لتقليل مساحة القرص المستخدمة:
+
+```py
+>>> dataset.set_transform(transforms)
+```
+
+يمكنك التحقق من نجاح التحويل عن طريق الفهرسة في `pixel_values` للمثال الأول:
+
+```py
+>>> import numpy as np
+>>> import matplotlib.pyplot as plt
+
+>>> img = dataset["train"][0]["pixel_values"]
+>>> plt.imshow(img)
+```
+
+
+
+ +
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs/source/ar/installation.md b/docs/source/ar/installation.md
new file mode 100644
index 00000000000..690877fa7ed
--- /dev/null
+++ b/docs/source/ar/installation.md
@@ -0,0 +1,110 @@
+## التثبيت
+
+قبل البدء، ستحتاج إلى إعداد بيئة العمل الخاصة بك وتثبيت الحزم المناسبة. تم اختبار 🤗 Datasets على **Python 3.7+**.
+
+
+
+
+الدورات التعليمية
+تعلم الأساسيات واعتد على تحميل مجموعة البيانات والوصول إليها ومعالجتها. ابدأ من هنا إذا كنت تستخدم 🤗 Datasets لأول مرة!
+ + +أدلة كيفية الاستخدام
+أدلة عملية لمساعدتك في تحقيق هدف محدد. الق نظرة على هذه الأدلة لمعرفة كيفية استخدام 🤗 Datasets لحل المشكلات الواقعية.
+ + +الأدلة المفاهيمية
+تفسيرات عالية المستوى لبناء فهم أفضل للموضوعات المهمة مثل تنسيق البيانات الأساسي والذاكرة المؤقتة وكيفية إنشاء مجموعات البيانات.
+ + +المرجع
+الأوصاف الفنية لكيفية عمل فئات 🤗 Datasets والأساليب.
+ +
+ +
+
+
+مع `albumentations`، يمكنك تطبيق تحولات تؤثر على الصورة مع تحديث `bboxes` وفقًا لذلك. في هذه الحالة، تتم إعادة تحجيم الصورة إلى (480، 480)، والانعكاس الأفقي، وزيادة السطوع.
+
+```py
+>>> import albumentations
+>>> import numpy as np
+
+>>> transform = albumentations.Compose([
+... albumentations.Resize(480, 480),
+... albument太阳公ipations.HorizontalFlip(p=1.0),
+... albumentations.RandomBrightnessContrast(p=1.0),
+... ], bbox_params=albumentations.BboxParams(format='coco', label_fields=['category']))
+
+>>> image = np.array(example['image'])
+>>> out = transform(
+... image=image,
+... bboxes=example['objects']['bbox'],
+... category=example['objects']['category'],
+... )
+```
+
+الآن، عند تصور النتيجة، يجب أن تكون الصورة معكوسة، ولكن يجب أن تكون `bboxes` في الأماكن الصحيحة.
+
+```py
+>>> image = torch.tensor(out['image']).permute(2, 0, 1)
+>>> boxes_xywh = torch.stack([torch.tensor(x) for x in out['bboxes']])
+>>> boxes_xyxy = box_convert(boxes_xywh, 'xywh', 'xyxy')
+>>> labels = [categories.int2str(x) for x in out['category']]
+>>> to_pil_image(
+... draw_bounding_boxes(
+... image,
+... boxes_xyxy,
+... colors='red',
+... labels=labels
+... )
+... )
+```
+
+
+
+ +
+
+
+قم بإنشاء دالة لتطبيق التحويل على دفعة من الأمثلة:
+
+```py
+>>> def transforms(examples):
+... images, bboxes, categories = [], [], []
+... for image, objects in zip(examples['image'], examples['objects']):
+... image = np.array(image.convert("RGB"))
+... out = transform(
+... image=image,
+... bboxes=objects['bbox'],
+... category=objects['category']
+... )
+... images.append(torch.tensor(out['image']).permute(2, 0, 1))
+... bboxes.append(torch.tensor(out['bboxes']))
+... categories.append(out['category'])
+... return {'image': images, 'bbox': bboxes, 'category': categories}
+```
+
+استخدم وظيفة [`~Dataset.set_transform`] لتطبيق التحويل أثناء التنقل، والذي يستهلك مساحة أقل على القرص. قد تعيد عشوائية زيادة البيانات صورة مختلفة إذا قمت بالوصول إلى نفس المثال مرتين. إنه مفيد بشكل خاص عند تدريب نموذج لعدة حقبات.
+
+```py
+>>> ds['train'].set_transform(transforms)
+```
+
+يمكنك التحقق من عمل التحويل عن طريق تصور المثال العاشر:
+
+```py
+>>> example = ds['train'][10]
+>>> to_pil_image(
+... draw_bounding_boxes(
+... example['image'],
+... box_convert(example['bbox'], 'xywh', 'xyxy'),
+... colors='red',
+... labels=[categories.int2str(x) for x in example['category']]
+... )
+... )
+```
+
+
+ +
+
+
+
+
+
+
+
+الصوت
+أعد أخذ عينات من مجموعة بيانات صوتية وجعلها جاهزة لنموذج لتصنيف نوع المشكلة المصرفية التي يتصل بها المتحدث.
+ +الرؤية
+تطبيق زيادة البيانات على مجموعة بيانات صورة وجعلها جاهزة لنموذج لتشخيص المرض في نباتات الفاصوليا.
+ +NLP
+قم برمزية مجموعة بيانات وتحضيرها لنموذج لتحديد ما إذا كان زوج من الجمل لهما نفس المعنى.
+ +
+ +
+
+
+وبالمثل، يمكنك التحقق من قناع التجزئة المقابل:
+
+```py
+>>> dataset[index]["annotation"]
+```
+
+
+
+ +
+
+
+يمكننا أيضًا إضافة [لوحة ألوان](https://github.com/tensorflow/models/blob/3f1ca33afe3c1631b733ea7e40c294273b9e406d/research/deeplab/utils/get_dataset_colormap.py#L51) على قناع التجزئة ووضعه فوق الصورة الأصلية لتصور مجموعة البيانات:
+
+بعد تحديد لوحة الألوان، يجب أن تكون جاهزًا لعرض بعض الطبقات.
+
+```py
+>>> import matplotlib.pyplot as plt
+
+>>> def visualize_seg_mask(image: np.ndarray, mask: np.ndarray):
+ color_seg = np.zeros((mask.shape[0], mask.shape[1], 3), dtype=np.uint8)
+ palette = np.array(create_ade20k_label_colormap())
+ for label, color in enumerate(palette):
+ color_seg[mask == label, :] = color
+ color_seg = color_seg[..., ::-1] # تحويل إلى BGR
+
+ img = np.array(image) * 0.5 + color_seg * 0.5 # عرض الصورة مع خريطة التجزئة
+ img = img.astype(np.uint8)
+
+ plt.figure(figsize=(15, 10))
+ plt.imshow(img)
+ plt.axis("off")
+ plt.show()
+
+
+>>> visualize_seg_mask(
+ np.array(dataset[index]["image"]),
+ np.array(dataset[index]["annotation"])
+)
+```
+
+
+
+ +
+
+
+الآن قم بتطبيق بعض التحسينات باستخدام `albumentations`. أولاً، ستقوم بإعادة تحجيم الصورة وتعديل سطوعها.
+
+```py
+>>> import albumentations
+
+>>> transform = albumentations.Compose(
+ [
+ albumentations.Resize(256, 256),
+ albumentations.RandomBrightnessContrast(brightness_limit=0.3, contrast_limit=0.3, p=0.5),
+ ]
+)
+```
+
+قم بإنشاء دالة لتطبيق التحويل على الصور:
+
+```py
+>>> def transforms(examples):
+ transformed_images, transformed_masks = [], []
+
+ for image, seg_mask in zip(examples["image"], examples["annotation"]):
+ image, seg_mask = np.array(image), np.array(seg_mask)
+ transformed = transform(image=image, mask=seg_mask)
+ transformed_images.append(transformed["image"])
+ transformed_masks.append(transformed["mask"])
+
+ examples["pixel_values"] = transformed_images
+ examples["label"] = transformed_masks
+ return examples
+```
+
+استخدم وظيفة [`~Dataset.set_transform`] لتطبيق التحويل أثناء التنقل على دفعات من مجموعة البيانات لتقليل مساحة القرص المستخدمة:
+
+```py
+>>> dataset.set_transform(transforms)
+```
+
+يمكنك التحقق من نجاح التحويل عن طريق الفهرسة في `pixel_values` و`label` لمثال:
+
+```py
+>>> image = np.array(dataset[index]["pixel_values"])
+>>> mask = np.array(dataset[index]["label"])
+
+>>> visualize_seg_mask(image, mask)
+```
+
+
+
+ +
+
+
+في هذا الدليل، استخدمت `albumentations` لزيادة مجموعة البيانات. من الممكن أيضًا استخدام `torchvision` لتطبيق بعض التحولات المماثلة.
+
+```py
+>>> from torchvision.transforms import Resize, ColorJitter, Compose
+
+>>> transformation_chain = Compose([
+ Resize((256, 256)),
+ ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)
+])
+>>> resize = Resize((256, 256))
+
+>>> def train_transforms(example_batch):
+ example_batch["pixel_values"] = [transformation_chain(x) for x in example_batch["image"]]
+ example_batch["label"] = [resize(x) for x in example_batch["annotation"]]
+ return example_batch
+
+>>> dataset.set_transform(train_transforms)
+
+>>> image = np.array(dataset[index]["pixel_values"])
+>>> mask = np.array(dataset[index]["label"])
+
+>>> visualize_seg_mask(image, mask)
+```
+
+
+
+ +
+
+
+
+
+ +
+
+
+### تحميل مجموعة البيانات
+
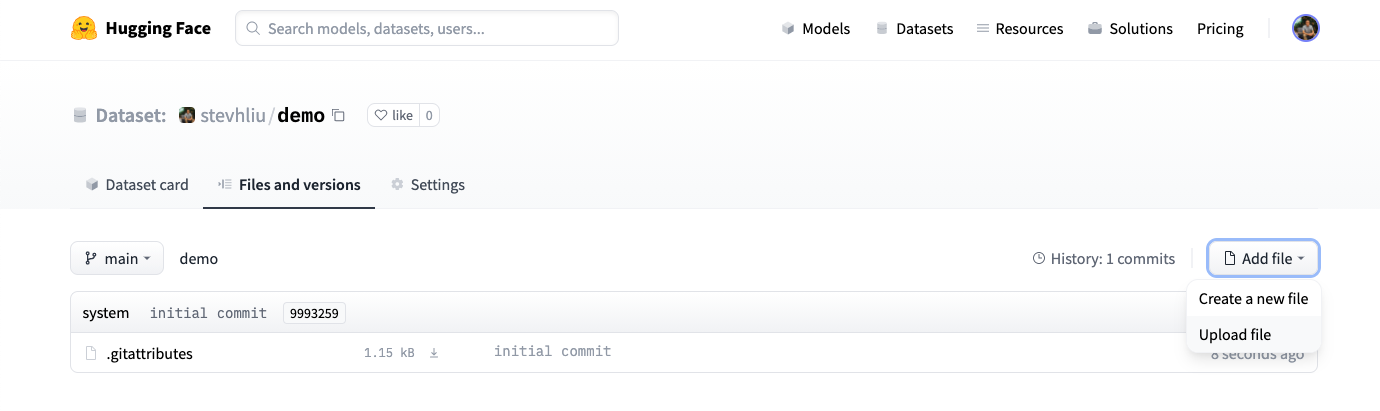
+1. بمجرد إنشاء مستودع، انتقل إلى علامة التبويب **الملفات والإصدارات** لإضافة ملف. حدد **إضافة ملف** لتحميل ملفات مجموعة البيانات الخاصة بك. ندعم العديد من ملحقات البيانات النصية والصوتية والصور مثل `.csv` و `.mp3` و `.jpg` من بين العديد من الآخرين. بالنسبة لملحقات البيانات النصية مثل `.csv` و `.json` و `.jsonl` و `.txt`، نوصي بضغطها قبل تحميلها إلى Hub (إلى ملحق ملف `.zip` أو `.gz` على سبيل المثال).
+
+لا يتم تتبع ملحقات الملفات النصية افتراضيًا بواسطة Git LFS، وإذا كانت أكبر من 10 ميجابايت، فلن يتم الالتزام بها وتحميلها. الق نظرة على ملف `.gitattributes` في مستودعك للحصول على قائمة كاملة بملحقات الملفات التي يتم تتبعها. بالنسبة لهذا البرنامج التعليمي، يمكنك استخدام ملفات `.csv` التوضيحية التالية لأنها صغيرة: train.csv، test.csv.
+
+
+
+ +
+
+
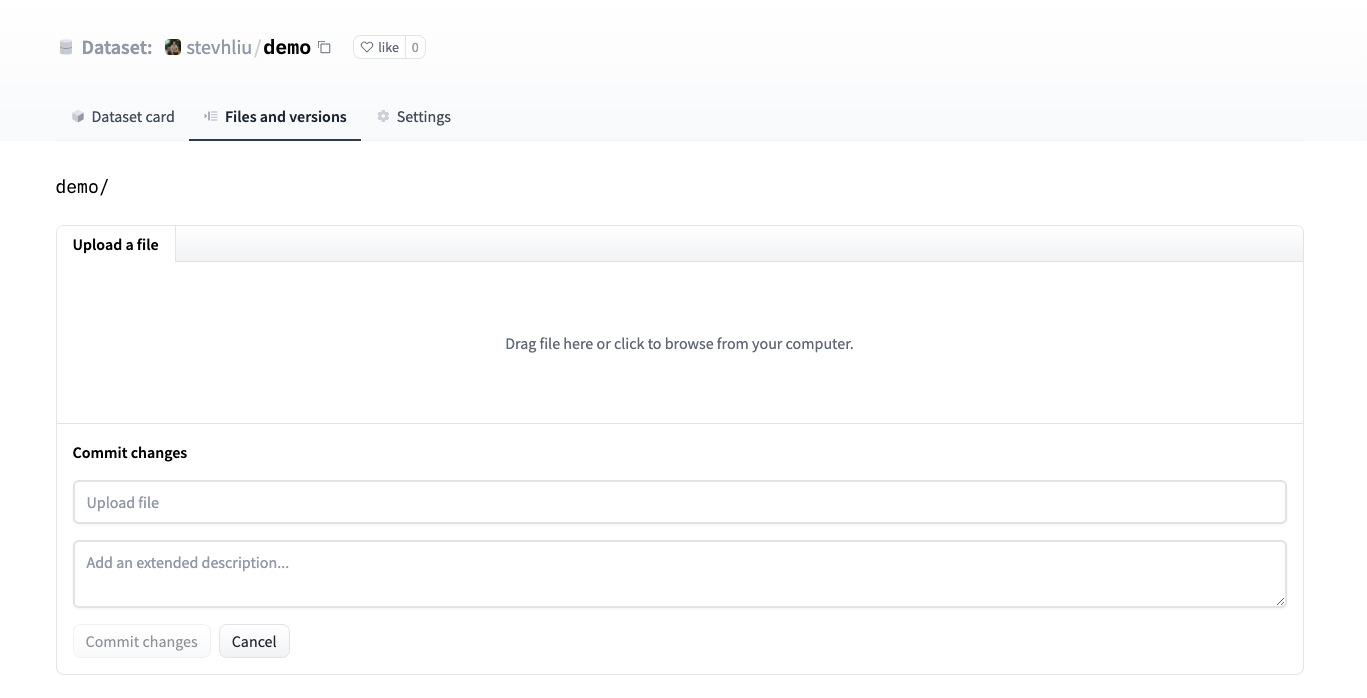
+2. اسحب ملفات مجموعة البيانات الخاصة بك وأضف رسالة ارتكاب وصفية موجزة.
+
+
+
+ +
+
+
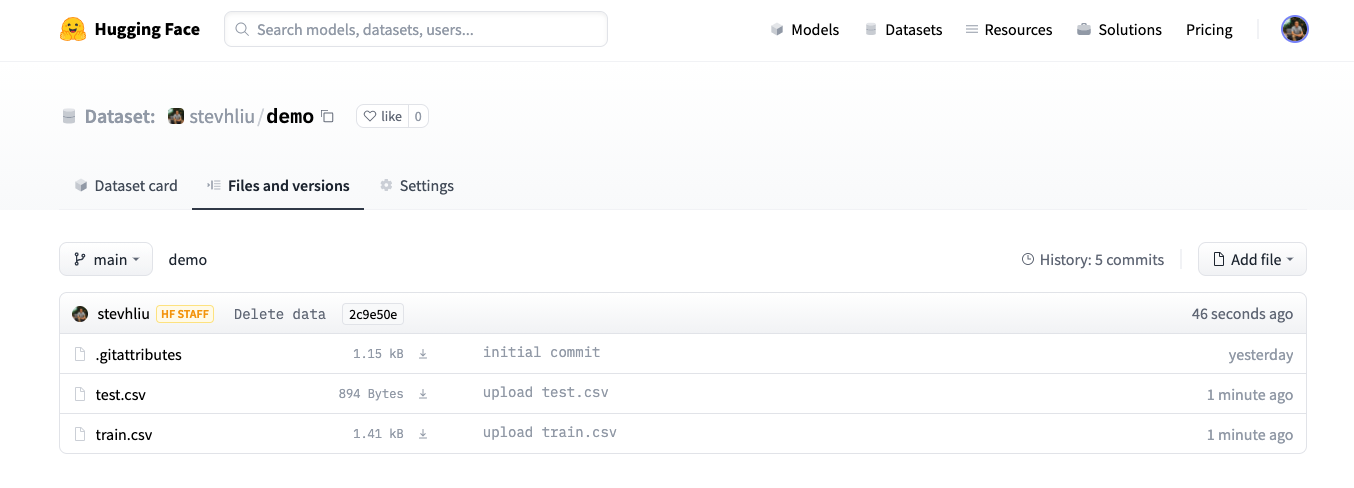
+3. بعد تحميل ملفات مجموعة البيانات الخاصة بك، يتم تخزينها في مستودع مجموعة البيانات الخاصة بك.
+
+
+
+ +
+
+
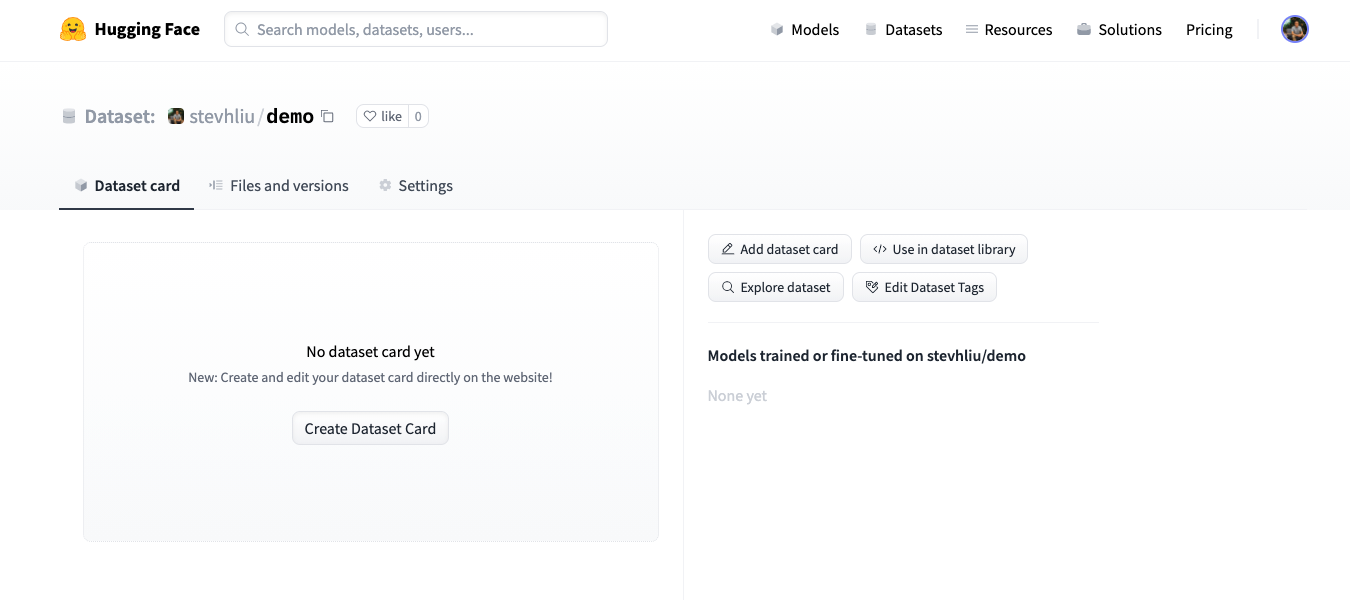
+### إنشاء بطاقة مجموعة بيانات
+
+إن إضافة بطاقة مجموعة بيانات أمر قيم للغاية لمساعدة المستخدمين في العثور على مجموعة البيانات الخاصة بك وفهم كيفية استخدامها بشكل مسؤول.
+
+1. انقر فوق **إنشاء بطاقة مجموعة بيانات** لإنشاء بطاقة مجموعة بيانات. يقوم هذا الزر بإنشاء ملف `README.md` في مستودعك.
+
+
+
+ +
+
+
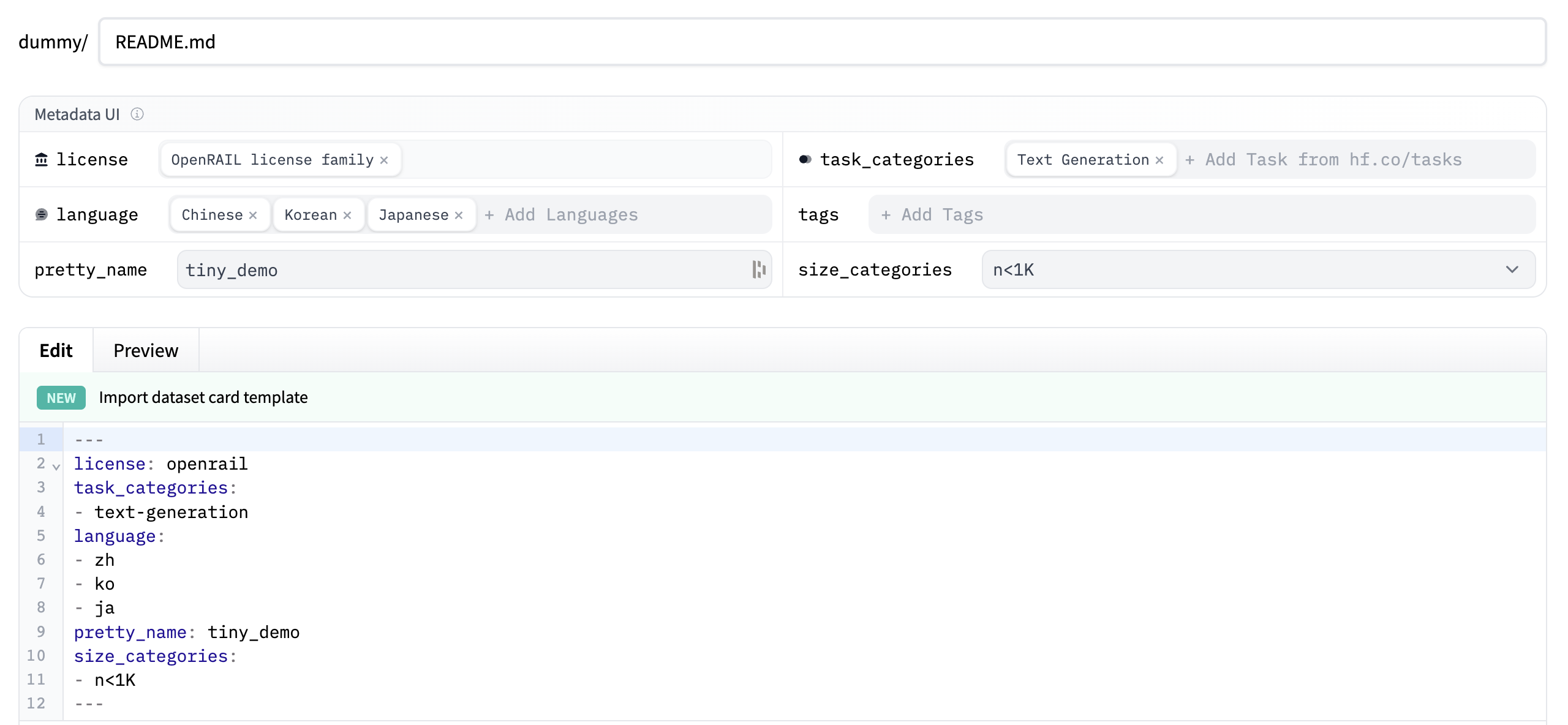
+2. في الأعلى، سترى **واجهة المستخدم للبيانات الوصفية** مع العديد من الحقول للاختيار من بينها مثل الترخيص واللغة وفئات المهام. هذه هي أهم العلامات لمساعدة المستخدمين على اكتشاف مجموعة البيانات الخاصة بك على Hub. عندما تحدد خيارًا من كل حقل، سيتم إضافتها تلقائيًا إلى أعلى بطاقة مجموعة البيانات.
+
+يمكنك أيضًا الاطلاع على [مواصفات بطاقة مجموعة البيانات](https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1)، والتي تحتوي على مجموعة كاملة من (ولكن غير مطلوبة) خيارات العلامات مثل `annotations_creators`، لمساعدتك في اختيار العلامات المناسبة.
+
+
+
+ +
+
+
+3. انقر فوق الرابط **استيراد قالب بطاقة مجموعة البيانات** في أعلى المحرر لإنشاء قالب بطاقة مجموعة بيانات تلقائيًا. تعد تعبئة القالب طريقة رائعة لتقديم مجموعة البيانات الخاصة بك إلى المجتمع ومساعدة المستخدمين على فهم كيفية استخدامها. للحصول على مثال مفصل لما يجب أن تبدو عليه بطاقة مجموعة البيانات الجيدة، راجع [بطاقة مجموعة بيانات CNN DailyMail](https://huggingface.co/datasets/cnn_dailymail).
+
+### تحميل مجموعة البيانات
+
+بمجرد تخزين مجموعة البيانات الخاصة بك على Hub، يمكن لأي شخص تحميلها باستخدام الدالة [`load_dataset`] :
+
+```py
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("stevhliu/demo")
+```
+
+## التحميل باستخدام Python
+
+يمكن للمستخدمين الذين يفضلون تحميل مجموعة بيانات برمجيًا استخدام مكتبة [huggingface_hub](https://huggingface.co/docs/huggingface_hub/index). تسمح هذه المكتبة للمستخدمين بالتفاعل مع Hub من Python.
+
+1. ابدأ بتثبيت المكتبة:
+
+```bash
+pip install huggingface_hub
+```
+
+2. لتحميل مجموعة بيانات على Hub في Python، يلزمك تسجيل الدخول إلى حساب Hugging Face الخاص بك:
+
+```bash
+huggingface-cli login
+```
+
+3. استخدم الدالة [`push_to_hub()`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.DatasetDict.push_to_hub) لمساعدتك في إضافة ملف والالتزام به ودفعه إلى مستودعك:
+
+```py
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("stevhliu/demo")
+# dataset = dataset.map(...) # قم بجميع معالجتك هنا
+>>> dataset.push_to_hub("stevhliu/processed_demo")
+```
+
+لجعل مجموعة البيانات الخاصة بك خاصة، قم بتعيين المعلمة `private` على `True`. لن يعمل هذا المعلمة إلا إذا كنت تقوم بإنشاء مستودع للمرة الأولى.
+
+```py
+>>> dataset.push_to_hub("stevhliu/private_processed_demo", private=True)
+```
+
+لإضافة تكوين جديد (أو مجموعة فرعية) إلى مجموعة بيانات أو لإضافة تقسيم جديد (التدريب/التحقق/الاختبار)، يرجى الرجوع إلى وثائق [`Dataset.push_to_hub`] .
+
+### الخصوصية
+
+لا يمكن الوصول إلى مجموعة البيانات الخاصة إلا من قبلك. وبالمثل، إذا قمت بمشاركة مجموعة بيانات داخل مؤسستك، فيمكن لأعضاء المنظمة أيضًا الوصول إلى مجموعة البيانات.
+
+قم بتحميل مجموعة بيانات خاصة عن طريق توفير رمز المصادقة الخاص بك لمعلمة `token` :
+
+```py
+>>> from datasets import load_dataset
+
+# تحميل مجموعة بيانات فردية خاصة
+>>> dataset = load_dataset("stevhliu/demo", token=True)
+
+# تحميل مجموعة بيانات منظمة خاصة
+>>> dataset = load_dataset("organization/dataset_name"، token=True)
+```
+
+## ماذا بعد؟
+
+تهانينا، لقد أكملت البرامج التعليمية! 🥳
+
+من هنا، يمكنك:
+
+- تعرف على المزيد حول كيفية استخدام وظائف 🤗 Datasets الأخرى [لمعالجة مجموعة البيانات](process) الخاصة بك.
+- [قم بتشغيل مجموعات البيانات الكبيرة](stream) دون تنزيلها محليًا.
+- [حدد تقسيمات مجموعة البيانات وتكويناتها](repository_structure) ومشاركة مجموعة البيانات الخاصة بك مع المجتمع.
+
+إذا كان لديك أي أسئلة حول 🤗 Datasets، فلا تتردد في الانضمام إلى المجتمع وسؤاله على [المنتدى](https://discuss.huggingface.co/c/datasets/10).
\ No newline at end of file
diff --git a/docs/source/ar/use_dataset.mdx b/docs/source/ar/use_dataset.mdx
new file mode 100644
index 00000000000..0d41bbd79d4
--- /dev/null
+++ b/docs/source/ar/use_dataset.mdx
@@ -0,0 +1,203 @@
+# معالجة مسبقة
+
+بالإضافة إلى تحميل مجموعات البيانات، يتمثل الهدف الرئيسي الآخر لـ 🤗 Datasets في تقديم مجموعة متنوعة من وظائف المعالجة المسبقة لتحويل مجموعة البيانات إلى تنسيق مناسب للتدريب مع إطار عمل التعلم الآلي الخاص بك.
+
+هناك العديد من الطرق الممكنة لمعالجة مجموعة البيانات مسبقًا، وكل ذلك يعتمد على مجموعة البيانات المحددة الخاصة بك. في بعض الأحيان، قد تحتاج إلى إعادة تسمية عمود، وفي أحيان أخرى، قد تحتاج إلى إلغاء تسطيح الحقول المضمنة. يوفر 🤗 Datasets طريقة للقيام بمعظم هذه الأشياء. ولكن في جميع حالات المعالجة المسبقة تقريبًا، اعتمادًا على طريقة مجموعة البيانات الخاصة بك، ستحتاج إلى:
+
+- رموز نصية لمجموعة بيانات نصية.
+- إعادة أخذ عينات من مجموعة بيانات صوتية.
+- تطبيق تحويلات على مجموعة بيانات الصور.
+
+تتمثل خطوة المعالجة المسبقة الأخيرة عادةً في تعيين تنسيق مجموعة البيانات الخاصة بك ليكون متوافقًا مع تنسيق الإدخال المتوقع لإطار عمل التعلم الآلي الخاص بك.
+
+في هذا البرنامج التعليمي، ستحتاج أيضًا إلى تثبيت مكتبة 🤗 Transformers:
+
+```bash
+pip install transformers
+```
+
+احصل على مجموعة بيانات من اختيارك واتبع التعليمات!
+
+## رموز نصية
+
+لا يمكن للنماذج معالجة النص الخام، لذلك ستحتاج إلى تحويل النص إلى أرقام. توفر عملية الرمزية طريقة للقيام بذلك من خلال تقسيم النص إلى كلمات فردية تسمى *الرموز*. يتم تحويل الرموز في النهاية إلى أرقام.
+
+
+