各种语言实现代码:Go Java JavaScript Rust
默认使用 Go 语言实现。
算法复杂度是指算法在编写成可执行程序后,运行时所需要的资源,资源包括时间资源和内存资源。算法复杂度分为时间复杂度和空间复杂度。其作用:时间复杂度是指执行算法所需要的运行时间;而空间复杂度是指执行这个算法所需要的内存空间。一个算法的优劣主要从算法的执行时间和所需要占用的存储空间两个方面衡量。
排序是计算机内经常进行的一种操作,其目的是将一组“无序”的序列调整为“有序”的序列。排序分为内部排序和外部排序,如果整个排序过程不需要访问外部存储就能完成,此类排序称为内部排序。相反,如果需要排序的记录数量很大,整个序列的排序过程不可能在内存中完成,此类排序称为外部排序。
快速排序、希尔排序、堆排序、直接选择排序不是稳定的排序算法,而基数排序、冒泡排序、直接插入排序、折半插入排序、归并排序是稳定的排序算法。
重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序错误就把他们交换过来。冒泡排序比较的时间复杂度为 O(n^2),交换的时间复杂度为 O(n^2)。
步骤:
-
从当前元素起,向前依次比较每一对相邻元素,若逆序则交换。
-
对所有元素均重复以上步骤,直至最后一个元素。
示例:
使用冒泡排序将元素为 1, 5, 7, 3, 2, 4, 9, 6, 8 的数组按照从小到大排序。
画图分析:

代码实现:
func bubbleSort(nums []int) {
if nums == nil {
return
}
length := len(nums)
// 外循环为排序趟数,length 个数进行 length - 1 趟
for i := 0; i < length - 1; i++ {
// 内循环为每趟比较的次数,第 i 趟比较 length - i 次
for j := length - 1; j > i; j-- {
// 相邻元素比较比较大小,然后交换位置
if nums[j] < nums[j - 1] {
nums[j], nums[j - 1] = nums[j - 1], nums[j]
}
}
fmt.Printf("第 %d 趟排序结果:%v\n", i + 1, nums)
}
}测试代码:
func TestBubbleSort(t *testing.T) {
nums := []int{1, 5, 7, 3, 2, 4, 9, 6, 8}
fmt.Printf("交换前: %v\n", nums)
bubbleSort(nums)
fmt.Printf("交换后: %v\n", nums)
}运行:
golang/algorithm>go test -v -run ^TestBubbleSort$ ./sort
=== RUN TestBubbleSort
交换前: [1 5 7 3 2 4 9 6 8]
第 1 趟排序结果:[1 2 5 7 3 4 6 9 8]
第 2 趟排序结果:[1 2 3 5 7 4 6 8 9]
第 3 趟排序结果:[1 2 3 4 5 7 6 8 9]
第 4 趟排序结果:[1 2 3 4 5 6 7 8 9]
第 5 趟排序结果:[1 2 3 4 5 6 7 8 9]
第 6 趟排序结果:[1 2 3 4 5 6 7 8 9]
第 7 趟排序结果:[1 2 3 4 5 6 7 8 9]
第 8 趟排序结果:[1 2 3 4 5 6 7 8 9]
交换后: [1 2 3 4 5 6 7 8 9]优化
在上例排序输出结果中,我们发现第 4 趟排序完成后,结果已经是有序的。我们可以对冒泡排序进行优化,有时候如果被比较的元素已经是一个有序的,就不需要进行比较。
优化代码:
// 在某次循环中,如果发现没有发生交换,则终止循环
func optimizeBubbleSort(nums []int) {
if nums == nil {
return
}
length := len(nums)
isChange := false // 标记是否发生交换
for i := 0; i < length - 1; i++ {
for j := length - 1; j > i; j-- {
if nums[j] < nums[j - 1] {
nums[j], nums[j - 1] = nums[j - 1], nums[j]
isChange = true // 发生交换
}
}
fmt.Printf("第 %d 趟排序结果:%v\n", i + 1, nums)
if !isChange {
break // 跳出循环,终止比较
} else {
isChange = false // 重置
}
}
}测试代码:
func TestBubbleSort(t *testing.T) {
nums2 := []int{1, 5, 7, 3, 2, 4, 9, 6, 8}
fmt.Printf("优化前: %v\n", nums2)
optimizeBubbleSort(nums2)
fmt.Printf("优化后: %v\n", nums2)
}运行:
golang/algorithm>go test -v -run ^TestBubbleSort$ ./sort
=== RUN TestBubbleSort
优化前: [1 5 7 3 2 4 9 6 8]
第 1 趟排序结果:[1 2 5 7 3 4 6 9 8]
第 2 趟排序结果:[1 2 3 5 7 4 6 8 9]
第 3 趟排序结果:[1 2 3 4 5 7 6 8 9]
第 4 趟排序结果:[1 2 3 4 5 6 7 8 9]
第 5 趟排序结果:[1 2 3 4 5 6 7 8 9]
优化后: [1 2 3 4 5 6 7 8 9]此时少比较了 3 次。
第一次从待排序的数据元素中选出最小(或最大)的一个元素,默认为第一个元素,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。选择排序比较的时间复杂度为 O(n^2),交换的时间复杂度为 O(n)。交换次数比冒泡排序少多了,n 值较小时,选择排序比冒泡排序快。
步骤:
- 假定第一元素为最大或最小的元素。
- 找出最大或最小的元素的小标,循环 length - 1 次。
- 每次循环完成后将最大值或最小值和本次循环的第一个元素交换。
示例:
使用选择排序将元素为 3, 5, 7, 1, 2, 4, 9, 6, 8 的数组按照从小到大排序。
画图分析:
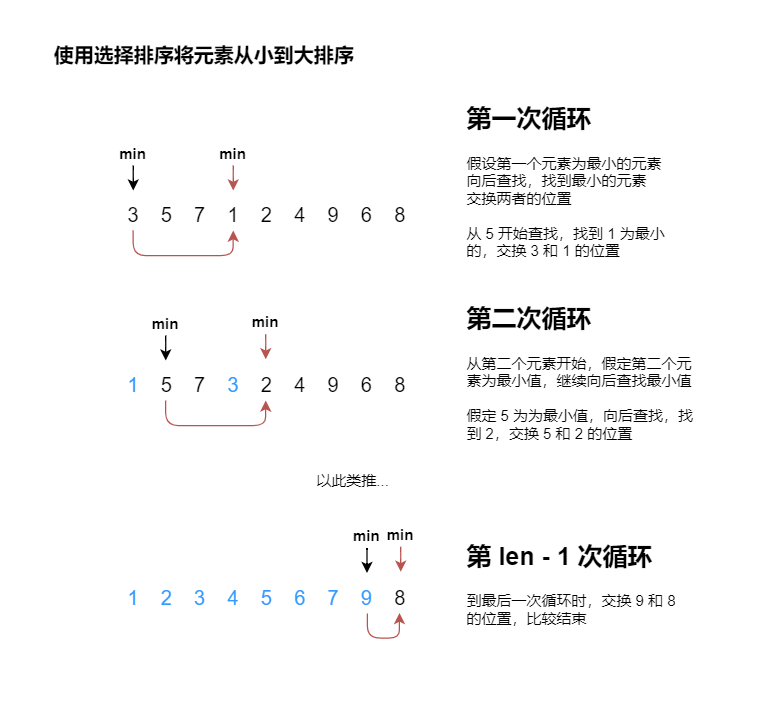
代码实现:
func selectSort(nums []int) {
if nums == nil {
return
}
length := len(nums)
for i := 0; i < length - 1; i++ {
// 记录最小值的下标
minIndex := i
for j := i + 1; j < length; j++ {
if nums[minIndex] > nums[j] {
// 修改最小值下标
minIndex = j
}
}
// 优化:判断是否需要交换
if minIndex != i {
nums[i], nums[minIndex] = nums[minIndex], nums[i]
}
}
}测试代码:
func TestSelectSort(t *testing.T) {
nums := []int{3, 5, 7, 1, 2, 4, 9, 6, 8}
fmt.Printf("排序前: %v\n", nums)
selectSort(nums)
fmt.Printf("排序后: %v\n", nums)
}运行:
golang/algorithm>go test -v -run ^TestSelectSort$ ./sort
=== RUN TestSelectSort
排序前: [3 5 7 1 2 4 9 6 8]
排序后: [1 2 3 4 5 6 7 8 9]插入排序,一般也被称为直接插入排序。对于少量元素的排序,它是一个有效的算法。插入排序是一种最简单的排序方法,它的基本思想是将一个记录插入到已经排好序的有序表中,从而一个新的、记录数增 1 的有序表。在其实现过程使用双层循环,外层循环对除了第一个元素之外的所有元素,内层循环对当前元素前面有序表进行待插入位置查找,并进行移动 。插入排序最坏的情况是待排序数组是逆序的,此时需要比较次数最多,时间复杂度为O(n^2),最好的情况是待排序的数组是有序的,时间复杂度为O(n)。
步骤:
- 从第二个元素开始循环,循环到元素末尾,左边分为有序列表,右边分为无序列表。
- 将右边无序列表的第一个元素,标记为要插入的值(insertValue),并记录要插入的位置(insertIndex)。
- 依次和左边的无序列表中的元素比较,如果顺序颠倒,则将有序列表中当前被比较的元素后移,同时修改 insertIndex。
- 最后将 insertValue 插入到 insertIndex 位置。
示例:
使用插入排序将元素为 5, 1, 7, 3, 2, 4, 9, 6, 8 的数组按照从小到大排序。
画图分析:

代码实现:
func insertSort(nums []int) {
if nums == nil {
return
}
for i := 1; i < len(nums); i++ {
// 要插入的下标
insertIndex := i - 1
// 保存插入的值
insertValue := nums[i]
// 从小到大
for insertIndex >= 0 && nums[insertIndex] > insertValue {
// 元素后移
nums[insertIndex + 1] = nums[insertIndex]
// 下标前移
insertIndex--
}
// 优化:判断如果当前位置发生移动,就插入
if insertIndex + 1 != i {
// 插入
nums[insertIndex + 1] = insertValue
}
}
}测试代码:
func TestInsertSort(t *testing.T) {
nums := []int{5, 1, 7, 3, 2, 4, 9, 6, 8}
fmt.Printf("排序前: %v\n", nums)
insertSort(nums)
fmt.Printf("排序后: %v\n", nums)
}运行:
golang/algorithm>go test -v -run ^TestInsertSort$ ./sort
=== RUN TestInsertSort
排序前: [5 1 7 3 2 4 9 6 8]
排序后: [1 2 3 4 5 6 7 8 9]快速排序是对冒泡排序的一种改进。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
步骤:
- 获取最中间的元素,然后分别将左边和右边的元素分别和最中间的元素进行比较。
- 左边找出比中间大的元素,右边找出比中间小的元素,交换左右的位置。
- 一次比较完成后,将左边和右边分别递归重复以上操作。
示例:
使用快速排序将元素为 5, 1, 8, 3, 7, 2, 9, 4, 6 的数组按照从小到大排序。
画图分析:

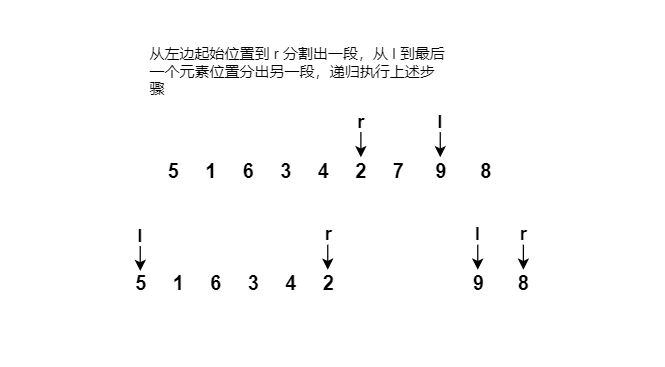
代码实现:
func quickSort(nums []int, start, end int) {
l := start
r := end
// 获取最中间的元素
centerValue := nums[(start + end) / 2]
for l < r {
// 从左边找出比中间元素大的元素值
for nums[l] < centerValue {
l++
}
// 从右边找出比中间元素小的值
for nums[r] > centerValue {
r--
}
if l >= r {
break
}
// 交换左边和右边的值
nums[l], nums[r] = nums[r], nums[l]
// 交换后,nums[l] 的值等于 centerValue,r 前移
if nums[l] == centerValue {
r--
}
// 交换后,nums[r] 的值等于 centerValue,l 后移
if nums[r] == centerValue {
l++
}
}
// 避免死递归
if l == r {
l++
r--
}
if start < r {
quickSort(nums, start, r)
}
if end > l {
quickSort(nums, l, end)
}
}测试代码:
func TestQuickSort(t *testing.T) {
nums := []int{5, 1, 8, 3, 7, 2, 9, 4, 6}
fmt.Printf("排序前: %v\n", nums)
quickSort(nums, 0, len(nums) - 1)
fmt.Printf("排序后: %v\n", nums)
}运行:
golang/algorithm>go test -v -run ^TestQuickSort$ ./sort
=== RUN TestQuickSort
排序前: [5 1 8 3 7 2 9 4 6]
排序后: [1 2 3 4 5 6 7 8 9]希尔排序 (Shell's Sort) 是直接插入排序算法的一种更高效的改进版本。希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至 1 时,整个文件恰被分成一组,算法便终止。
步骤:
- 计算出步长 step,step = length / 2。
- 从 step 开始,循环到 length。
- 将循环开始时的元素和比当前大 step 的元素进行比较。
- 发现逆序则进行交换。
示例:
使用希尔排序将元素为 5, 1, 7, 3, 2, 4, 9, 6, 8 的数组按照从小到大排序。
画图分析:
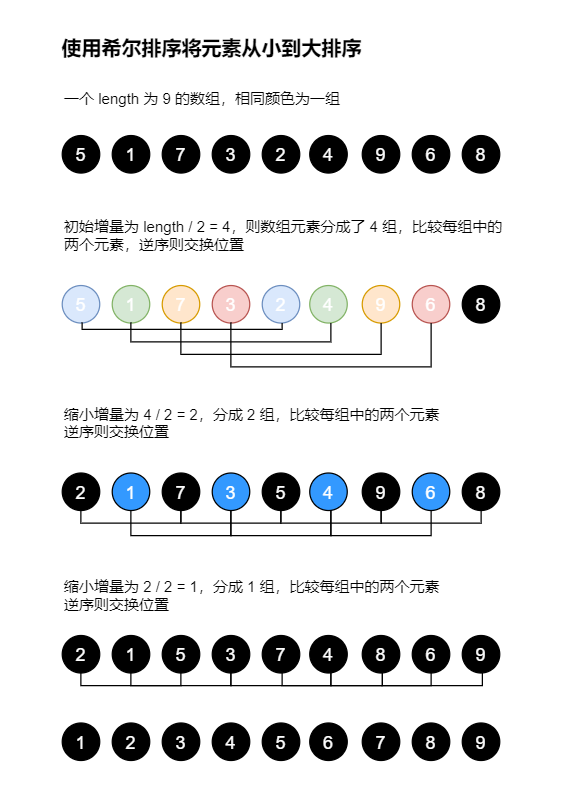
代码实现:
// 交换法
func shellSort(nums []int) {
if nums == nil {
return
}
length := len(nums)
// 控制步长
for step := length / 2; step > 0; step /= 2 {
for i := step; i < length; i++ {
for j := i - step; j >= 0 && nums[j] > nums[j + step]; j -= step {
// 前面的数比后面的数大,进行交换
nums[j], nums[j + step] = nums[j + step], nums[j]
}
}
}
}测试代码:
func TestShellSort(t *testing.T) {
nums := []int{5, 1, 7, 3, 2, 4, 9, 6, 8}
fmt.Printf("排序前: %v\n", nums)
shellSort(nums)
fmt.Printf("排序后: %v\n", nums)
}运行:
golang/algorithm>go test -v -run ^TestShellSort$ ./sort
=== RUN TestShellSort
排序前: [5 1 7 3 2 4 9 6 8]
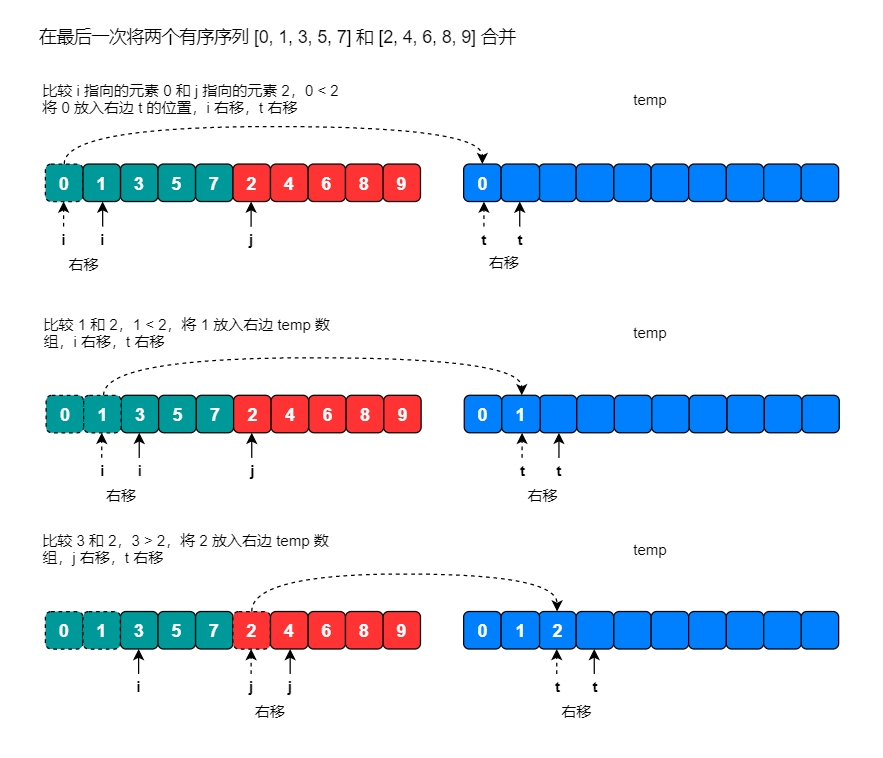
排序后: [1 2 3 4 5 6 7 8 9]归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
步骤:
- 将要排序的序列,从中间开始递归分解。
- 分解到子序列只有一个元素,然后开始合并。
- 创建一个临时序列,大小为本次需要合并的两个有序序列长度之和。
- 设定两个下标,初始位置分别为两个有序序列的下标。
- 比较两个小标指向的元素,将较小的元素放入临时序列,并移动下标。
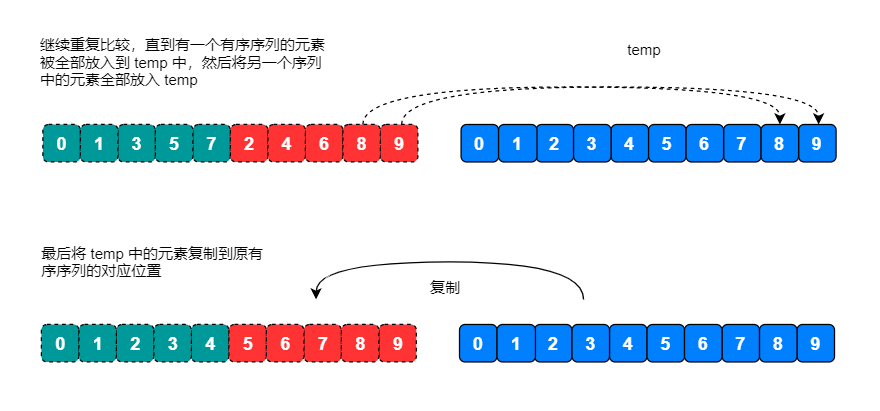
- 重复第 5 步,直到有一个下标超出序列尾部。
- 将另一个序列中剩余的元素保存当前顺序放入临时序列中。
- 最后将临时序列复制到原始序列对应的位置。
示例:
使用归并排序将元素为 5, 0, 1, 7, 3, 2, 4, 9, 6, 8 的数组按照从小到大排序。
画图分析:
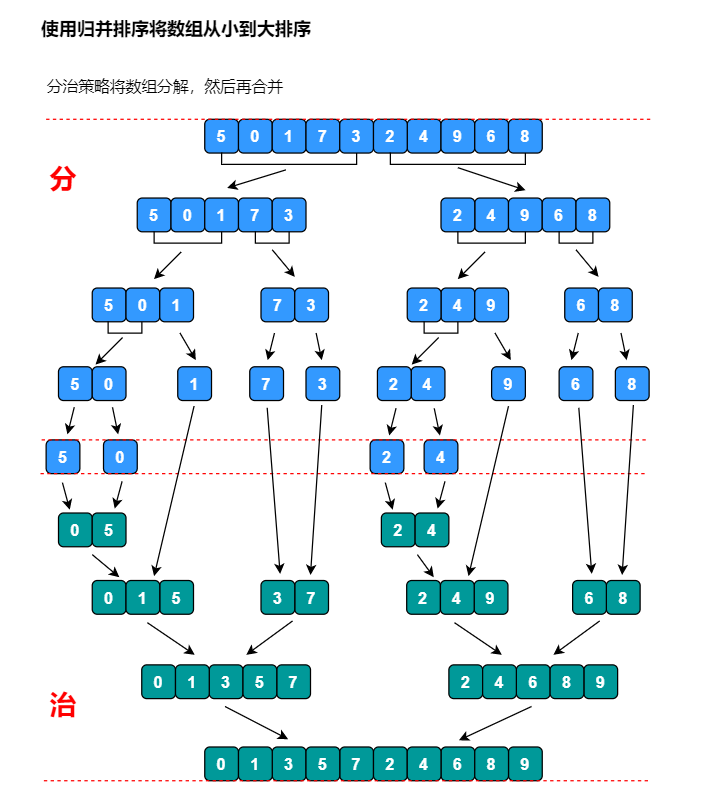
代码实现:
func mergeSort(nums[] int) {
if nums == nil {
return
}
decompose(nums, 0, len(nums) - 1)
}
// 分解
// start: 开始下标
// end: 结束下标
func decompose(nums[] int, start, end int) {
if start < end {
mid := (start + end) / 2
decompose(nums, start, mid) // 左边
decompose(nums, mid + 1, end) // 右边
merge(nums, start, mid, end)
}
}
// 合并
// left: 左边有序序列起始下标
// mid: 中间下标
// right: 右边有序序列起始下标
func merge(nums[] int, left, mid, right int) {
temp := make([]int, right - left + 1) // 临时保存元素的数组
i := left // 左边有序序列的起始下标
j := mid + 1 // 右边有序列表的起始下标
t := 0 // temp 当前下标
// 先把左右两边有序列表中的数据,取出来比较,然后将较小的元素放入 temp 中
for i <= mid && j <= right {
if nums[i] <= nums[j] {
temp[t] = nums[i]
i++
} else {
temp[t] = nums[j]
j++
}
t++
}
// 将剩余的左边或右边有序序列中的元素全部放入 temp 中
for i <= mid { // 左边序列还有元素
temp[t] = nums[i]
i++
t++
}
for j <= right { // 右边序列还有元素
temp[t] = nums[j]
j++
t++
}
// 将 temp 数组中的元素拷贝到 nums 中
t = 0
for left <= right {
nums[left] = temp[t]
left++
t++
}
}测试代码:
func TestMergeSort(t *testing.T) {
nums := []int{5, 0, 1, 7, 3, 2, 4, 9, 6, 8}
fmt.Printf("排序前: %v\n", nums)
mergeSort(nums)
fmt.Printf("排序后: %v\n", nums)
}运行:
golang/algorithm>go test -v -run ^TestMergeSort$ ./sort
=== RUN TestMergeSort
排序前: [5 0 1 7 3 2 4 9 6 8]
排序后: [0 1 2 3 4 5 6 7 8 9]基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或 bin sort,顾名思义,它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用,基数排序法是属于稳定性的排序。
步骤:
- 创建一个二维数组,数组长度为 10,并初始化 10 个一维数组,每个一维数组的长度为待排序数组的长度。
- 遍历待排序的数组,从最低位开始,求出每个元素的个位数作为二维数组的下标,将其放入到二维数组对应的数组中。
- 从二维数组中依次取出所有元素放入原数组中。
- 重复步骤 2,依次计算个位、十位、百位等,作为下标,直到待排序数组中的最大位数。
示例:
使用基数排序将元素为 5, 1, 7, 13, 21, 32, 9, 66, 8, 20 的数组按照从小到大排序。
画图分析:

代码实现:
func radixSort(nums[] int) {
if nums == nil {
return
}
max := nums[0] // 最大位的元素
for _, num := range nums {
if max < num {
max = num
}
}
maxLength := len(strconv.Itoa(max))
// var bucket [10][len(nums)]int
var bucket [10][]int // 桶数组,二维数组中的元素使用切片替代
for i := 0; i < 10; i++ {
bucket[i] = make([]int, len(nums)) // 初始化切片长度
}
var order [10]int // 存放每个桶真实存放数据的长度
n := 1 // 控制元素的位数
for i := 0 ; i < maxLength; i++ {
for _, num := range nums {
bucketIndex := num / n % 10 // 计算桶的下表
bucket[bucketIndex][order[bucketIndex]] = num
order[bucketIndex]++ // 尾下标 + 1
}
numIndex := 0
// 从桶数组中依次取出所有元素放入原数组
for i, bucketLength := range order {
if bucketLength != 0 {
for j := 0 ; j < bucketLength; j++ {
nums[numIndex] = bucket[i][j]
numIndex++
}
order[i] = 0 // 重置当前桶下标
}
}
n *= 10
}
}测试代码:
func TestRadixSort(t *testing.T) {
nums := []int{5, 1, 7, 13, 21, 32, 9, 66, 8, 20}
fmt.Printf("排序前: %v\n", nums)
radixSort(nums)
fmt.Printf("排序后: %v\n", nums)
}运行:
golang/algorithm>go test -v -run ^TestRadixSort$ ./sort
=== RUN TestRadixSort
排序前: [5 1 7 13 21 32 9 66 8 20]
排序后: [1 5 7 8 9 13 20 21 32 66]| 排序算法 | 平均 | 最好 | 最坏 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡 | O(n^2) | O(n) | O(n^2) | O(1) | 稳定 |
| 选择 | O(n^2) | O(n) | O(n^2) | O(1) | 不稳定 |
| 插入 | O(n^2) | O(n) | O(n^2) | O(1) | 稳定 |
| 快速 | O(nlog2n) | O(nlog2n) | O(n^2) | O(nlog2n) | 不稳定 |
| 希尔 | O(n^3/2) | O(n) | O(n^2) | O(1) | 不稳定 |
| 归并 | O(nlog2n) | O(nlog2n) | O(nlog2n) | O(n) | 稳定 |
| 基数 | O(d(n+radix)) | O(d(n+radix)) | O(d(n+radix)) | O(rd+n) | 稳定 |
| 堆排 | O(nlog2n) | O(nlog2n) | O(nlog2n) | O(1) | 不稳定 |