実践XAI[説明可能なAI] 機械学習の予測を説明するためのPythonコーディング

私なりのメモ ・決定木によるロジックの場合 過学習を起こしやすい。 決定木の構造を可視化する。 決定木の深さを制限する。
・現行の機械学習アルゴリズムがある。 ・これを、説明可能AIで使えるロジック・ライブラリに置換えて学習をする。https://knowledge.insight-lab.co.jp/aidx/-%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92-shap%E5%88%86%E6%9E%90%E3%82%84%E3%81%A3%E3%81%A6%E3%81%BF%E3%81%9F
SHAP Welcome to the SHAP documentation
簡潔な例
import xgboost
import shap
# train an XGBoost model
X, y = shap.datasets.california()
model = xgboost.XGBRegressor().fit(X, y)
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap.Explainer(model)
shap_values = explainer(X)
# visualize the first prediction's explanation
shap.plots.waterfall(shap_values[0])
waterfallプロット
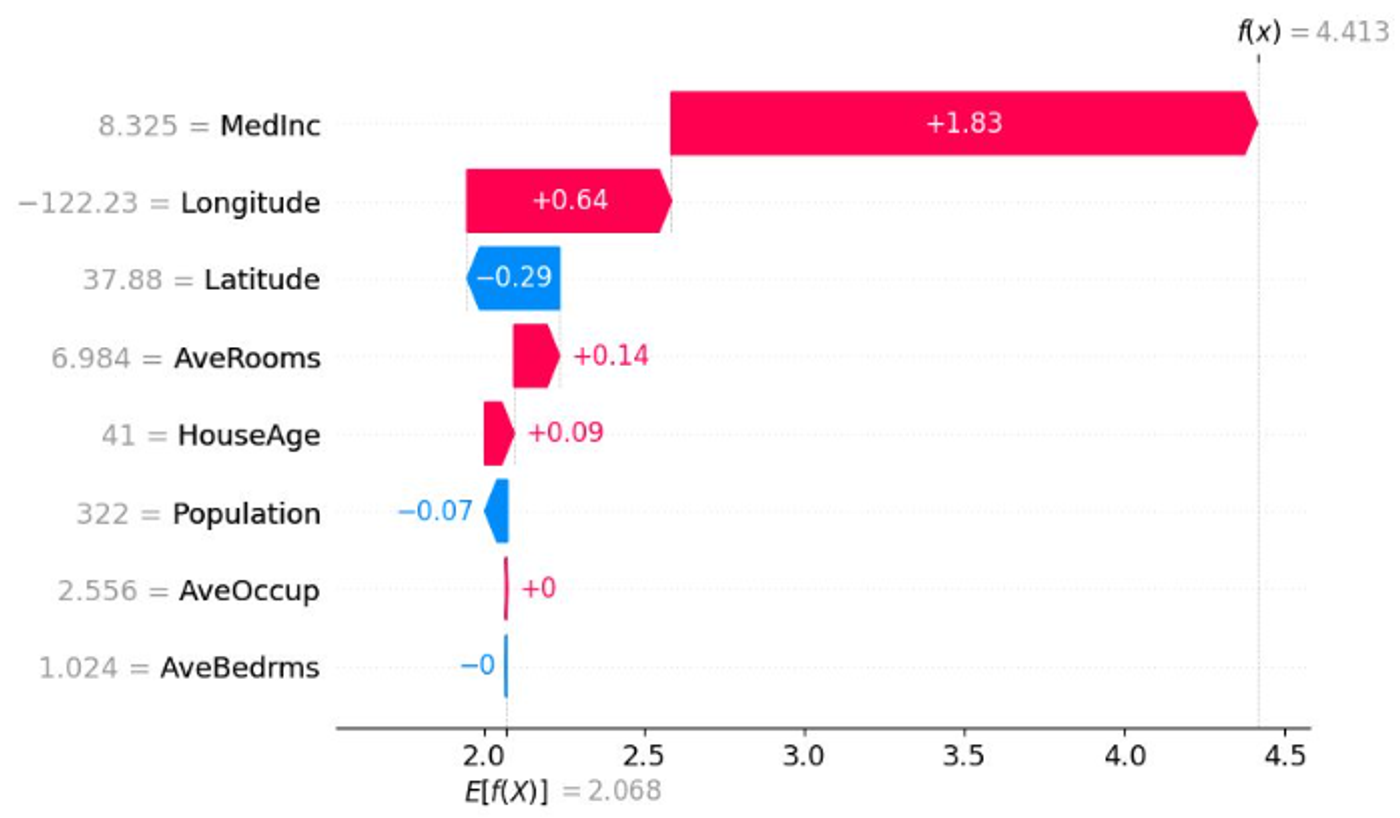
個別のサンプルごとに寄与している程度を表示している。
Deep learning example with GradientExplainer (TensorFlow/Keras/PyTorch models)

仮説: 検出問題よりも分類問題の方が、説明が簡単。
- SHAPの事例の中に画像の分類問題はあるが、検出問題はない。
- Segmentation とSHAPを結びつける例もあるが、一般的ではなさそう。
- 検出事例を分類問題に書き換える。
- 検出枠で画像をcropする。画像の大きさを正規化する。
- この時点でロジックが変わってしまう。ロジックが異なるものに対して説明可能性を求めても、説明になるだろうか?
- Explainable Object Detection - a practical How To
「機械学習システムデザイン」 5.3 データリーク 5.3.1 データリークの主な原因 5.3.1.1 時間相関のあるデータを時間ではなくランダムに分割してしまう。 5.3.1.2 分割する前にスケーリングしてしまう。 5.3.1.3 データからの統計量で欠損値を埋めてしまう 5.3.1.4 分割前のデータの重複に関する処理が不適切 5.3.1.5 グループリーク 5.3.1.6 データ生成プロセスからのリーク 5.3.2 データリークの検出