The app in question (Critter4Us) lets people reserve animals at a veterinary teaching hospital. The animals are reserved by professors to demonstrate procedures to students, and then to let students practice those procedures. It's similar to scheduling a meeting room, except for weirder business rules (like "No room can be used for daily status meetings more than twice a week.")
Here's a picture of the database tables relevant to reservations:
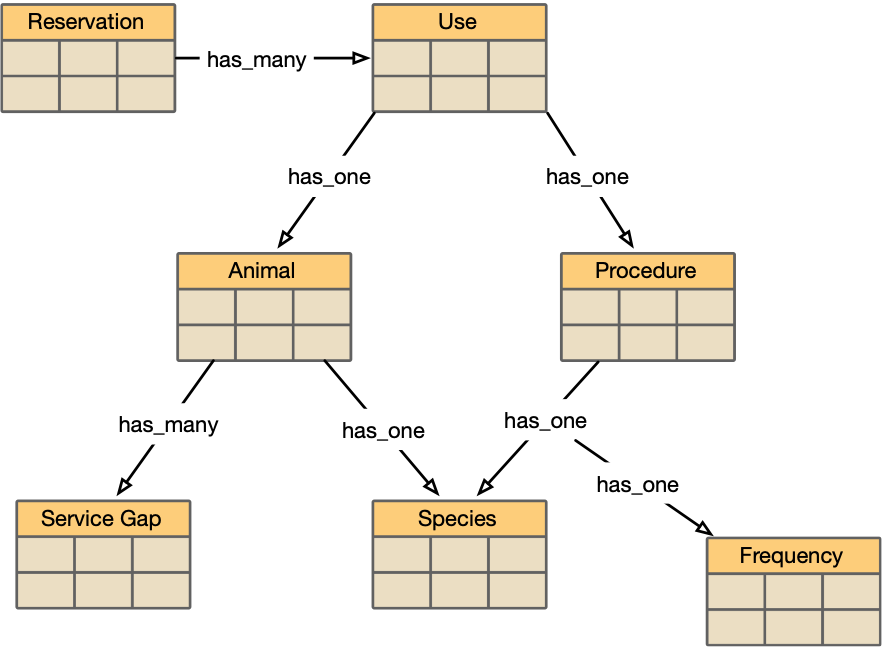
The test data builder for that repo is in Critter4Us's repo_state.ex.
When it comes to automated tests, I generally avoid prepopulating test databases, preferring to have each test or group of tests be completely responsible for setup. That's partly for reasons of test clarity: it's hard for someone coming to a test to know what to assume about existing state. It's partly for maintainability: adding something to the default state can break existing tests in mysterious ways.
For this app, every test can assume the existence of two species (cows and horses) and two procedure frequencies ("once per week" and "unlimited"). Procedure frequencies limit how often a particular animal can be used to demonstrate a particular procedure. (This is for reasons of animal welfare.)
Having these "leaf tables" that don't refer to other tables be predefined is convenient for really simple tests that don't need the mechanism described here.
The functions described below create a repo cache, conventionally
named repo in the code. In its simplest form, the repo cache is an
empty Map. For reservations, the starting repo cache is created with
this function:
def empty_repo(species_id \\ @bovine_id) do
%{species_id: species_id}
endBoth animals and procedures "belong to" a species. Tests almost never depend on which species that is, so by default it's the prepopulated bovine (cow) species. All animals and procedures created hereafter will be bovine. (A test that wanted to populate the database with different species would most likely use a second repo cache.)
Let's start by looking at the definition of an Animal:
schema "animals" do
field :name, TrimmedString
field :span, Datespan
field :available, :boolean, default: true
field :lock_version, :integer, default: 1
belongs_to :species, Schemas.Species
has_many :service_gaps, Schemas.ServiceGap
timestamps()
endWe need a simple way to insert a single animal into the database.
I'm
using ExMachina for that. With ExMachina, the code to create an Animal that's not been
persisted to the database looks like this:
Factory.build(:animal, name: "Daisy")Values not mentioned in the keyword list are given default values. The implementation of the "animal factory" looks like this:
def animal_factory() do
in_service = @earliest_date
out_of_service = @latest_date
span = Datespan.customary(in_service, out_of_service)
%Schemas.Animal{
name: Faker.Cat.name(),
species_id: some_species_id(),
span: span,
}
endNotice that the :name and :species_id fields are given random
values. (Faker.Cat.name, from the Faker package, chooses randomly from a list of plausible
cat names.) Generally, I think that's a good practice. If the test
doesn't declare that a value is relevant (by passing it explicitly
in), let's test the test by making it different every time.
ExMachina also lets you persist the built value to the database:
Factory.insert!(:animal, name: "Daisy")Such a function is the foundation of the terser test-data builder we're building. We could have a different foundation; nothing depends on ExMachina per se.
This particular app uses a custom version of ExMachina's insert!
because it maintains separate tables for different veterinary
institutions (using Postgres schemas). You'll see
Factory.sql_insert!(...), which just means "insert
into the test institution.")
In the finished version of the Critter4Us test builder, here's the simplest way to create an animal:
empty_repo()
|> animal("bossie")After this, the test is allowed to assume that an Animal named
"bossie" exists, but nothing else.
The simplest implementation of animal would look like this:
alias EctoTestDataBuilder, as: B
def animal(repo, animal_name) do
animal =
Factory.sql_insert!(:animal,
name: animal_name, species_id: repo.species_id)
B.Schema.put(repo, :animal, name, animal)
endIt might seem better to use Animal (an aliased module name) instead
of the completely different atom :animal. That would work for the
repo cache, but ExMachina requires the lowercase atom.
When nothing matters about a value but that it exists, it's often convenient to have it be created when it's first mentioned. For example, this:
repo =
empty_repo()
|> animal("bossie")
|> animal("jake")
|> procedure("haltering")
|> procedure("bandaging")
|> reservation_for(["bossie", "jake"], ["haltering", "bandaging"])... is more conveniently written like this:
repo =
empty_repo()
|> reservation_for(["bossie", "jake"], ["haltering", "bandaging"])We'll see the implementation of reservation_for later, but for now
let's make the animal(name) function do nothing if the named animal
already exists. That looks like this:
def animal(repo, animal_name) do
B.Schema.create_if_needed(repo, :animal, animal_name, fn ->
Factory.sql_insert!(:animal,
name: animal_name, species_id: repo.species_id)
end)
create_if_needed will return either an unchanged repo or one that
now contains a new animal with the given name.
It's extremely common for a test that sets up an animal in the database to later refer to that animal's primary key. That can be done like this:
B.Schema.get(repo, "bossie").idHowever, that's way too wordy. Instead, animal is implemented such that
each animal is available via a top-level map key:
repo.bossie.idThat's done like this:
def animal(repo, animal_name) do
schema = :animal
repo
|> B.Schema.create_if_needed(repo, schema, animal_name, fn ->
Factory.sql_insert!(schema,
name: animal_name, species_id: repo.species_id)
end)
|> B.Repo.shorthand(schema: schema, name: animal_name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
endIn product code, you might leave a value's association fields unloaded
for the sake of efficiency. In test code, I think you should almost
always load the associations. So the next version of the animal
function looks like this:
def animal(repo, animal_name, opts \\ []) do
schema = :animal
B.Schema.create_if_needed(repo, schema, animal_name, fn ->
animal =
Factory.sql_insert!(schema,
name: animal_name, species_id: repo.species_id)
reloader(schema, animal)
^^^^^^^^^^^^^^^^^^^^^^^^
end)
|> B.Repo.shorthand(schema: schema, name: animal_name)
endreloader is a function that takes a value and reloads that
value. (It takes a whole value because I don't want this builder
support code to assume anything about the primary key, or even that
there is one.)
You have to provide the reloader function, which will typically look
something like this:
defp reloader(:procedure, value),
do: ...
defp reloader(:animal, value),
do: ...
defp reloader(_, value), do: valueAs we'll soon see, reloader has other uses.
ExMachina provides default values for all fields in an Animal but
allows those to be overridden with keyword arguments:
Factory.insert!(:animal, name: "bossie", species_id: 3)So the animal function could take keyword arguments and just pass
them onto Factory.insert!. I have a mild preference for having the
builder function control its own options because it's often convenient
to synthesize schema fields (and thus ExMachina options) from
them. For example, animals have a date range during which they're
available. Much of the time, all that matters is the beginning
date. So the :span field's value (always a Datespan) is synthesized
from animal's available: option, which may be a Date or a
Datespan.
Option-handling looks like this:
@doc """
Shorthand: yes, fully loaded: yes
Options:
* `available`: A `Date` or `Datespan`. A `Date` is converted
to a "customary" `Datespan` with endpoint `@latest_date`.
"""
def animal(repo, animal_name, opts \\ []) do
schema = :animal
builder_map = B.Schema.combine_opts(opts, animal_defaults())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
B.Schema.create_if_needed(repo, schema, animal_name, fn ->
factory_opts =
animal_factory_opts(repo, animal_name, builder_map)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
animal = Factory.sql_insert!(schema, factory_opts)
^^^^^^^^^^^^
reloader(schema, animal)
end)
|> B.Repo.shorthand(schema: schema, name: animal_name)
end
defp animal_defaults(), do: %{available: @earliest_date}
defp animal_factory_opts(repo, name, builder_map) do
[name: name,
span: compute_span(builder_map.available),
species_id: repo.species_id]
endB.Schema.combine_opts is like Enum.into except that it complains if
the first argument contains extra keys. I make a lot of typos.
I separate out the animal_defaults and animal_factory_opts because they're by
far the most likely parts of animal to change, so I want to make
them easy to find.
Animals may have one or more associated service gaps. For example, some horses might be on pasture for the summer.
schema "service_gaps" do
field :animal_id, :id
field :span, Datespan
field :reason, :string
end(In this case, :animal_id isn't marked as a foreign key because I
never want to go from a ServiceGap to its Animal.)
Because a ServiceGap can't be created before the Animal it belongs
to, the repo has to be created like this:
repo =
empty_repo()
|> animal("bossie", ...)
|> service_gap_for("bossie", ...)
^^^^^^^^^^^^^^^^^^^^^^^^^The implementation looks much the same as animal's. Let me draw
attention to one line:
def service_gap_for(repo, animal_name, opts \\ []) do
schema = :service_gap
builder_map = B.Schema.combine_opts(opts, service_gap_defaults())
repo
|> B.Schema.create_if_needed(schema, builder_map.name, fn ->
factory_opts =
service_gap_factory_opts(repo, animal_name, builder_map)
Factory.sql_insert!(schema, factory_opts)
end)
|> B.Repo.shorthand(schema: schema, name: builder_map.name)
|> reload_animal(animal_name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
end
That line fully reloads the animal using the multi-schema reloader function. The
intermediate function (reload_animal) looks like this:
defp reload_animal(repo, animal_name) do
B.Repo.fully_load(repo,
&reloader/2,
schema: :animal, name: animal_name)
endB.Repo.fully_load first finds the animal value, passes it to the
reloader, and then redoes the shorthand for that animal (if
any). Cache consistency!
service_gap_for takes a name for the animal, but none (by default)
for the service gap. It has to have a name to be put in the repo
cache, so one is generated in the defaults:
defp service_gap_defaults do
%{starting: @earliest_date, ending: @latest_date,
reason: Factory.unique(:reason),
name: Factory.unique(:service_gap)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
}
end... and then used to create the ServiceGap value:
repo
|> B.Schema.create_if_needed(schema, builder_map.name, fn ->
^^^^^^^^^^^^^^^^
factory_opts = service_gap_factory_opts(repo, animal_name, builder_map)
Factory.sql_insert!(schema, factory_opts)
end)ExMachina's unique will make sure no two default service gaps will
have the same name. A name can be provided, though:
|> service_gap_for("bossie", name: "sg")service_gap_for installs that name as shorthand, really just for consistency
with other schemas. The generated names get shorthand too, just out of laziness.
The foreign key to the Animal is generated from the repo by looking
up the given animal_name:
defp service_gap_factory_opts(repo, animal_name, builder_map) do
span =
Datespan.customary(builder_map.starting, builder_map.ending)
animal_id = B.Schema.get(repo, schema, name).id
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[animal_id: animal_id, span: span, reason: builder_map.reason]
endWith this library, tests and test support don't work much with ids. Names are more convenient because you choose them, not the database, so you don't have to store them and pass them all over the place.
Notice that the value returned from Factory.sql_insert! is not
reloaded. (Indeed, reloader(:procedure, ...) does nothing.) Because
a ServiceGap has no associations, there's no need to reload.
Let's now consider reservation_for:
repo =
empty_repo()
|> procedure("haltering", frequency: "twice per week")
|> reservation_for(["bossie", "daisy"], ["haltering"], date: @wed)As we saw above, it creates "bossie" and
"daisy" for you. How, exactly? Like this:
def reservation_for(repo, animal_names, procedure_names, opts \\ []) do
schema = :reservation
builder_map = B.Schema.combine_opts(opts, reservation_defaults())
repo
|> procedures(procedure_names)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
|> animals(animal_names)
^^^^^^^^^^^^^^^^^^^^^
|> B.Schema.create_if_needed(schema, builder_map.name, fn ->
factory_opts = reservation_factory_opts(builder_map)
reservation =
ReservationFocused.reserved!(
repo.species_id, animal_names, procedure_names, factory_opts)
reloader(schema, reservation)
end)
|> B.Repo.shorthand(schema: schema, name: builder_map.name)
endprocedures and animals just add a list of uninteresting animals to
the repo cache (unless they already exist). Because this is a common operation,
there's a macro to write their code:
require B.Macro
B.Macro.make_plural_builder(:procedures, from: :procedure)
B.Macro.make_plural_builder(:animals, from: :animal)The body of create_if_needed uses a function,
ReservationFocused.reserved!, that predates this style of test
building. So that code is not as cleanly matched to this package as
I'd like. I'll eventually clean it up.
I hope this lets you copy, paste, and tweak your way to your app-specific test data builder. This package was very much created by me "scratching my own itch," so I encourage you to suggest additions.