





library(tidyverse)
-library(stringi)
-library(scales)
-library(gt)library(tidyverse)
+library(stringi)
+library(scales)
+library(gt)library(tidyverse)
-library(stringi)
-library(scales)
-library(gt)library(tidyverse)
+library(stringi)
+library(scales)
+library(gt)I’ll be using the CRAN package repository data returned by tools::CRAN_package_db() to get package and author metadata for the current packages available on CRAN. This returns a data frame with character columns containing most metadata from the DESCRIPTION file of a given R package.
Since this data will change over time, here’s when tools::CRAN_package_db() was run for reference: 2023-05-03.
cran_pkg_db <- tools::CRAN_package_db()
+cran_pkg_db <- tools::CRAN_package_db()
-glimpse(cran_pkg_db)
+glimpse(cran_pkg_db)#> Rows: 19,473
#> Columns: 67
@@ -118,17 +134,57 @@
Wrangle
Since we only care about package and author metadata, a good first step is to remove everything else. This leaves us with a Package field and two author fields: Author and Authors@R. The difference between the two author fields is that Author is an unstructured text field that can contain any text in any format, and Authors@R is a structured text field containing R code that defines authors’ names and roles with the person() function.
-cran_pkg_db <- cran_pkg_db |>
- select(package = Package, authors = Author, authors_r = `Authors@R`) |>
- as_tibble()
+cran_pkg_db <- cran_pkg_db |>
+ select(package = Package, authors = Author, authors_r = `Authors@R`) |>
+ as_tibble()
Here’s a comparison of the two fields, using the dplyr package as an example:
-# Author
-cran_pkg_db |>
- filter(package == "dplyr") |>
- pull(authors) |>
- cat()
+# Author
+cran_pkg_db |>
+ filter(package == "dplyr") |>
+ pull(authors) |>
+ cat()
#> Hadley Wickham [aut, cre] (<https://orcid.org/0000-0003-4757-117X>),
#> Romain François [aut] (<https://orcid.org/0000-0002-2444-4226>),
@@ -137,11 +193,29 @@
#> Davis Vaughan [aut] (<https://orcid.org/0000-0003-4777-038X>),
#> Posit Software, PBC [cph, fnd]
-# Authors@R
-cran_pkg_db |>
- filter(package == "dplyr") |>
- pull(authors_r) |>
- cat()
+# Authors@R
+cran_pkg_db |>
+ filter(package == "dplyr") |>
+ pull(authors_r) |>
+ cat()
#> c(
#> person("Hadley", "Wickham", , "hadley@posit.co", role = c("aut", "cre"),
@@ -179,9 +253,19 @@
From the output above you can see that every package uses the Author field, but not all packages use the Authors@R field. This is unfortunate, because it means that the names and roles of authors need to be extracted from the unstructured text in the Author field for a subset of packages, which is difficult to do and somewhat error-prone. Just for consideration, here’s how many packages don’t use the Authors@R field.
-cran_pkg_db |>
- filter(is.na(authors_r)) |>
- nrow()
+cran_pkg_db |>
+ filter(is.na(authors_r)) |>
+ nrow()
#> [1] 6361
@@ -193,7 +277,43 @@
Extracting from Authors@R
Getting the data we want from the Authors@R field is pretty straightforward. For the packages where this is used, each one has a vector of person objects stored as a character string like:
-mm_string <- "person(\"Michael\", \"McCarthy\", , role = c(\"aut\", \"cre\"))"
+mm_string <- "person(\"Michael\", \"McCarthy\", , role = c(\"aut\", \"cre\"))"
mm_string
@@ -202,18 +322,56 @@
Which can be parsed and evaluated as R code like:
-mm_eval <- eval(parse(text = mm_string))
+mm_eval <- eval(parse(text = mm_string))
-class(mm_eval)
+class(mm_eval)
#> [1] "person"
Then the format() method for the person class can be used to get names and roles into the format I want simply and accurately.
-mm_person <- format(mm_eval, include = c("given", "family"))
-mm_roles <- format(mm_eval, include = c("role"))
-tibble(person = mm_person, roles = mm_roles)
+mm_person <- format(mm_eval, include = c("given", "family"))
+mm_roles <- format(mm_eval, include = c("role"))
+tibble(person = mm_person, roles = mm_roles)
#> # A tibble: 1 × 2
#> person roles
@@ -223,28 +381,130 @@
I’ve wrapped this up into a small helper function, authors_r(), that includes some light tidying steps just to deal with a couple small discrepancies I noticed in a subset of packages.
-# Get names and roles from "person" objects in the Authors@R field
-authors_r <- function(x) {
- # Some light preprocessing is needed to replace the unicode symbol for line
- # breaks with the regular "\n". This is an edge case from at least one
- # package.
- code <- str_replace_all(x, "\\<U\\+000a\\>", "\n")
- persons <- eval(parse(text = code))
- person <- str_trim(format(persons, include = c("given", "family")))
- roles <- format(persons, include = c("role"))
- tibble(person = person, roles = roles)
+# Get names and roles from "person" objects in the Authors@R field
+authors_r <- function(x) {
+ # Some light preprocessing is needed to replace the unicode symbol for line
+ # breaks with the regular "\n". This is an edge case from at least one
+ # package.
+ code <- str_replace_all(x, "\\<U\\+000a\\>", "\n")
+ persons <- eval(parse(text = code))
+ person <- str_trim(format(persons, include = c("given", "family")))
+ roles <- format(persons, include = c("role"))
+ tibble(person = person, roles = roles)
}
Here’s an example of it with dplyr:
-cran_pkg_db |>
- filter(package == "dplyr") |>
- pull(authors_r) |>
- # Normalizing names leads to more consistent results with summary statistics
- # later on, since some people use things like umlauts and accents
- # inconsistently.
- stri_trans_general("latin-ascii") |>
- authors_r()
+cran_pkg_db |>
+ filter(package == "dplyr") |>
+ pull(authors_r) |>
+ # Normalizing names leads to more consistent results with summary statistics
+ # later on, since some people use things like umlauts and accents
+ # inconsistently.
+ stri_trans_general("latin-ascii") |>
+ authors_r()
#> # A tibble: 6 × 2
#> person roles
@@ -274,53 +534,289 @@
Fortunately, regular expressions actually worked pretty well, so this is the solution I settled on. I tried two approaches to this. First I tried to split the names (and roles) up by commas (and eventually other punctuation as I ran into edge cases). This worked alright; there were clearly errors in the data with this method, but since most packages use a simple structure in the Author field it correctly extracted names from most packages.
Second I tried to extract the names (and roles) directly with a regular expression that could match a variety of names. This is the solution I settled on. It still isn’t perfect, but the data is cleaner than with the other method. Regardless, the difference in number of observations between both methods was only in the mid hundreds—so I think any statistics based on this data, although not completely accurate, are still sufficient to get a good idea of the R developer landscape on CRAN.
-# This regex was adapted from <https://stackoverflow.com/a/7654214/16844576>.
-# It's designed to capture a wide range of names, including those with
-# punctuation in them. It's tailored to this data, so I don't know how well
-# it would generalize to other situations, but feel free to try it.
-persons_roles <- r"((\'|\")*[A-Z]([A-Z]+|(\'[A-Z])?[a-z]+|\.)(?:(\s+|\-)[A-Z]([a-z]+|\.?))*(?:(\'?\s+|\-)[a-z][a-z\-]+){0,2}(\s+|\-)[A-Z](\'?[A-Za-z]+(\'[A-Za-z]+)?|\.)(?:(\s+|\-)[A-Za-z]([a-z]+|\.))*(\'|\")*(?:\s*\[(.*?)\])?)"
-# Some packages put the person() code in the wrong field, but it's also
-# formatted incorrectly and throws an error when evaluated, so the best we can
-# do is just extract the whole thing for each person.
-person_objects <- r"(person\((.*?)\))"
+# This regex was adapted from <https://stackoverflow.com/a/7654214/16844576>.
+# It's designed to capture a wide range of names, including those with
+# punctuation in them. It's tailored to this data, so I don't know how well
+# it would generalize to other situations, but feel free to try it.
+persons_roles <- r"((\'|\")*[A-Z]([A-Z]+|(\'[A-Z])?[a-z]+|\.)(?:(\s+|\-)[A-Z]([a-z]+|\.?))*(?:(\'?\s+|\-)[a-z][a-z\-]+){0,2}(\s+|\-)[A-Z](\'?[A-Za-z]+(\'[A-Za-z]+)?|\.)(?:(\s+|\-)[A-Za-z]([a-z]+|\.))*(\'|\")*(?:\s*\[(.*?)\])?)"
+# Some packages put the person() code in the wrong field, but it's also
+# formatted incorrectly and throws an error when evaluated, so the best we can
+# do is just extract the whole thing for each person.
+person_objects <- r"(person\((.*?)\))"
-# Get names and roles from character strings in the Author field
-authors <- function(x) {
- # The Author field is unstructured and there are idiosyncrasies between
- # different packages. The steps here attempt to fix the idiosyncrasies so
- # authors can be extracted with as few errors as possible.
- persons <- x |>
- # Line breaks should be replaced with spaces in case they occur in the
- # middle of a name.
- str_replace_all("\\n|\\<U\\+000a\\>|\\n(?=[:upper:])", " ") |>
- # Periods should always have a space after them so initials will be
- # recognized as part of a name.
- str_replace_all("\\.", "\\. ") |>
- # Commas before roles will keep them from being included in the regex.
- str_remove_all(",(?= \\[)") |>
- # Get persons and their roles.
- str_extract_all(paste0(persons_roles, "|", person_objects)) |>
- unlist() |>
- # Multiple spaces can be replaced with a single space for cleaner names.
- str_replace_all("\\s+", " ")
+# Get names and roles from character strings in the Author field
+authors <- function(x) {
+ # The Author field is unstructured and there are idiosyncrasies between
+ # different packages. The steps here attempt to fix the idiosyncrasies so
+ # authors can be extracted with as few errors as possible.
+ persons <- x |>
+ # Line breaks should be replaced with spaces in case they occur in the
+ # middle of a name.
+ str_replace_all("\\n|\\<U\\+000a\\>|\\n(?=[:upper:])", " ") |>
+ # Periods should always have a space after them so initials will be
+ # recognized as part of a name.
+ str_replace_all("\\.", "\\. ") |>
+ # Commas before roles will keep them from being included in the regex.
+ str_remove_all(",(?= \\[)") |>
+ # Get persons and their roles.
+ str_extract_all(paste0(persons_roles, "|", person_objects)) |>
+ unlist() |>
+ # Multiple spaces can be replaced with a single space for cleaner names.
+ str_replace_all("\\s+", " ")
- tibble(person = persons) |>
- mutate(
- roles = str_extract(person, "\\[(.*?)\\]"),
- person = str_remove(
- str_remove(person, "\\s*\\[(.*?)\\]"),
- "^('|\")|('|\")$" # Some names are wrapped in quotations
+ tibble(person = persons) |>
+ mutate(
+ roles = str_extract(person, "\\[(.*?)\\]"),
+ person = str_remove(
+ str_remove(person, "\\s*\\[(.*?)\\]"),
+ "^('|\")|('|\")$" # Some names are wrapped in quotations
)
)
}
Here’s an example of it with dplyr. If you compare it to the output from authors_r() above you can see the data quality is still good enough for rock ‘n’ roll, but it isn’t perfect; Posit’s roles are no longer defined because the comma in their name cut off the regex before it captured the roles. So there are some edge cases like this that will create measurement error in the person or roles columns, but I don’t think it’s bad enough to invalidate the results.
-cran_pkg_db |>
- filter(package == "dplyr") |>
- pull(authors) |>
- stri_trans_general("latin-ascii") |>
- authors()
+cran_pkg_db |>
+ filter(package == "dplyr") |>
+ pull(authors) |>
+ stri_trans_general("latin-ascii") |>
+ authors()
#> # A tibble: 6 × 2
#> person roles
@@ -340,53 +836,241 @@
Kurt Hornik, Duncan Murdoch and Achim Zeileis published a nice article in The R Journal explaining the roles of R package authors and where they come from. Briefly, they come from the “Relator and Role” codes and terms from MARC (MAchine-Readable Cataloging, Library of Congress, 2012) here: https://www.loc.gov/marc/relators/relaterm.html.
There are a lot of roles there; I just took the ones that were present in the data at the time I wrote this post.
-marc_roles <- c(
- analyst = "anl",
- architecht = "arc",
- artist = "art",
- author = "aut",
- author_in_quotations = "aqt",
- author_of_intro = "aui",
- bibliographic_antecedent = "ant",
- collector = "col",
- compiler = "com",
- conceptor = "ccp",
- conservator = "con",
- consultant = "csl",
- consultant_to_project = "csp",
- contestant_appellant = "cot",
- contractor = "ctr",
- contributor = "ctb",
- copyright_holder = "cph",
- corrector = "crr",
- creator = "cre",
- data_contributor = "dtc",
- degree_supervisor = "dgs",
- editor = "edt",
- funder = "fnd",
- illustrator = "ill",
- inventor = "inv",
- lab_director = "ldr",
- lead = "led",
- metadata_contact = "mdc",
- musician = "mus",
- owner = "own",
- presenter = "pre",
- programmer = "prg",
- project_director = "pdr",
- scientific_advisor = "sad",
- second_party = "spy",
- sponsor = "spn",
- supporting_host = "sht",
- teacher = "tch",
- thesis_advisor = "ths",
- translator = "trl",
- research_team_head = "rth",
- research_team_member = "rtm",
- researcher = "res",
- reviewer = "rev",
- witness = "wit",
- woodcutter = "wdc"
+marc_roles <- c(
+ analyst = "anl",
+ architecht = "arc",
+ artist = "art",
+ author = "aut",
+ author_in_quotations = "aqt",
+ author_of_intro = "aui",
+ bibliographic_antecedent = "ant",
+ collector = "col",
+ compiler = "com",
+ conceptor = "ccp",
+ conservator = "con",
+ consultant = "csl",
+ consultant_to_project = "csp",
+ contestant_appellant = "cot",
+ contractor = "ctr",
+ contributor = "ctb",
+ copyright_holder = "cph",
+ corrector = "crr",
+ creator = "cre",
+ data_contributor = "dtc",
+ degree_supervisor = "dgs",
+ editor = "edt",
+ funder = "fnd",
+ illustrator = "ill",
+ inventor = "inv",
+ lab_director = "ldr",
+ lead = "led",
+ metadata_contact = "mdc",
+ musician = "mus",
+ owner = "own",
+ presenter = "pre",
+ programmer = "prg",
+ project_director = "pdr",
+ scientific_advisor = "sad",
+ second_party = "spy",
+ sponsor = "spn",
+ supporting_host = "sht",
+ teacher = "tch",
+ thesis_advisor = "ths",
+ translator = "trl",
+ research_team_head = "rth",
+ research_team_member = "rtm",
+ researcher = "res",
+ reviewer = "rev",
+ witness = "wit",
+ woodcutter = "wdc"
)
@@ -394,49 +1078,171 @@
Tidying the data
With all the explanations out of the way we can now tidy the data with our helper functions.
-cran_authors <- cran_pkg_db |>
- mutate(
- # Letters with accents, etc. should be normalized so that names including
- # them are picked up by the regex.
- across(c(authors, authors_r), \(.x) stri_trans_general(.x, "latin-ascii")),
- # The extraction functions aren't vectorized so they have to be mapped over.
- # This creates a list column.
- persons = if_else(
- is.na(authors_r),
- map(authors, \(.x) authors(.x)),
- map(authors_r, \(.x) authors_r(.x))
+cran_authors <- cran_pkg_db |>
+ mutate(
+ # Letters with accents, etc. should be normalized so that names including
+ # them are picked up by the regex.
+ across(c(authors, authors_r), \(.x) stri_trans_general(.x, "latin-ascii")),
+ # The extraction functions aren't vectorized so they have to be mapped over.
+ # This creates a list column.
+ persons = if_else(
+ is.na(authors_r),
+ map(authors, \(.x) authors(.x)),
+ map(authors_r, \(.x) authors_r(.x))
)
- ) |>
- select(-c(authors, authors_r)) |>
- unnest(persons) |>
- # If a package only has one author then they must be the author and creator,
- # so it's safe to impute this when it isn't there.
- group_by(package) |>
- mutate(roles = if_else(
- is.na(roles) & n() == 1, "[aut, cre]", roles
- )) |>
- ungroup()
+ ) |>
+ select(-c(authors, authors_r)) |>
+ unnest(persons) |>
+ # If a package only has one author then they must be the author and creator,
+ # so it's safe to impute this when it isn't there.
+ group_by(package) |>
+ mutate(roles = if_else(
+ is.na(roles) & n() == 1, "[aut, cre]", roles
+ )) |>
+ ungroup()
Then add the indicator columns for roles. Note the use of the walrus operator (:=) here to create new columns from the full names of MARC roles on the left side of the walrus, while detecting the MARC codes with str_detect() on the right side. I’m mapping over this because the left side can’t be a vector.
-cran_authors_tidy <- cran_authors |>
- # Add indicator columns for all roles.
- bind_cols(
- map2_dfc(
- names(marc_roles), marc_roles,
- function(.x, .y) {
- cran_authors |>
- mutate(!!.x := str_detect(roles, .y)) |>
- select(!!.x)
+cran_authors_tidy <- cran_authors |>
+ # Add indicator columns for all roles.
+ bind_cols(
+ map2_dfc(
+ names(marc_roles), marc_roles,
+ function(.x, .y) {
+ cran_authors |>
+ mutate(!!.x := str_detect(roles, .y)) |>
+ select(!!.x)
}
)
- ) |>
- # Not everyone's role is known.
- mutate(unknown = is.na(roles))
+ ) |>
+ # Not everyone's role is known.
+ mutate(unknown = is.na(roles))
This all leaves us with a tidy (mostly error free) data frame about R developers and their roles that is ready to explore:
-glimpse(cran_authors_tidy)
+glimpse(cran_authors_tidy)
#> Rows: 52,719
#> Columns: 50
@@ -498,51 +1304,235 @@
R developer statistics
I’ll start with person-level stats, mainly because some of the other stats are further summaries of these statistics. Nothing fancy here, just the number of packages a person has contributed to, role counts, and nominal and percentile rankings. Both the ranking methods used here give every tie the same (smallest) value, so if two people tied for second place both their ranks would be 2, and the next person’s rank would be 4.
-cran_author_pkg_counts <- cran_authors_tidy |>
- group_by(person) |>
- summarise(
- n_packages = n(),
- across(analyst:unknown, function(.x) sum(.x, na.rm = TRUE))
- ) |>
- mutate(
- # Discretizing this for visualization purposes later on
- n_pkgs_fct = case_when(
- n_packages == 1 ~ "One",
- n_packages == 2 ~ "Two",
- n_packages == 3 ~ "Three",
- n_packages >= 4 ~ "Four+"
+cran_author_pkg_counts <- cran_authors_tidy |>
+ group_by(person) |>
+ summarise(
+ n_packages = n(),
+ across(analyst:unknown, function(.x) sum(.x, na.rm = TRUE))
+ ) |>
+ mutate(
+ # Discretizing this for visualization purposes later on
+ n_pkgs_fct = case_when(
+ n_packages == 1 ~ "One",
+ n_packages == 2 ~ "Two",
+ n_packages == 3 ~ "Three",
+ n_packages >= 4 ~ "Four+"
),
- n_pkgs_fct = factor(n_pkgs_fct, levels = c("One", "Two", "Three", "Four+")),
- rank = min_rank(desc(n_packages)),
- percentile = percent_rank(n_packages) * 100,
- .after = n_packages
- ) |>
- arrange(desc(n_packages))
+ n_pkgs_fct = factor(n_pkgs_fct, levels = c("One", "Two", "Three", "Four+")),
+ rank = min_rank(desc(n_packages)),
+ percentile = percent_rank(n_packages) * 100,
+ .after = n_packages
+ ) |>
+ arrange(desc(n_packages))
Here’s an interactive gt table of the person-level stats so you can find yourself, or ask silly questions like how many other authors share a name with you. If you page or search through it you can also get an idea of the data quality (e.g., try “Posit” under the person column and you’ll see that they don’t use a consistent organization name across all packages, which creates some measurement error here).
Code
-cran_author_pkg_counts |>
- select(-n_pkgs_fct) |>
- gt() |>
- tab_header(
- title = "R Developer Contributions",
- subtitle = "CRAN Package Authorships and Roles"
- ) |>
- text_transform(
- \(.x) str_to_title(str_replace_all(.x, "_", " ")),
- locations = cells_column_labels()
- ) |>
- fmt_number(
- columns = percentile
- ) |>
- fmt(
- columns = rank,
- fns = \(.x) label_ordinal()(.x)
- ) |>
- cols_width(everything() ~ px(120)) |>
- opt_interactive(use_sorting = FALSE, use_filters = TRUE)
+cran_author_pkg_counts |>
+ select(-n_pkgs_fct) |>
+ gt() |>
+ tab_header(
+ title = "R Developer Contributions",
+ subtitle = "CRAN Package Authorships and Roles"
+ ) |>
+ text_transform(
+ \(.x) str_to_title(str_replace_all(.x, "_", " ")),
+ locations = cells_column_labels()
+ ) |>
+ fmt_number(
+ columns = percentile
+ ) |>
+ fmt(
+ columns = rank,
+ fns = \(.x) label_ordinal()(.x)
+ ) |>
+ cols_width(everything() ~ px(120)) |>
+ opt_interactive(use_sorting = FALSE, use_filters = TRUE)
@@ -1006,22 +1996,98 @@
Package contributions
The title of this post probably gave this away, but around 90% of R developers have worked on one to three packages, and only around 10% have worked on four or more packages.
-cran_author_pkg_counts |>
- group_by(n_pkgs_fct) |>
- summarise(n_people = n()) |>
- ggplot(mapping = aes(x = n_pkgs_fct, y = n_people)) +
- geom_col() +
- scale_y_continuous(
- sec.axis = sec_axis(
- trans = \(.x) .x / nrow(cran_author_pkg_counts),
- name = "Percent of sample",
- labels = label_percent(),
- breaks = c(0, .05, .10, .15, .70)
+cran_author_pkg_counts |>
+ group_by(n_pkgs_fct) |>
+ summarise(n_people = n()) |>
+ ggplot(mapping = aes(x = n_pkgs_fct, y = n_people)) +
+ geom_col() +
+ scale_y_continuous(
+ sec.axis = sec_axis(
+ trans = \(.x) .x / nrow(cran_author_pkg_counts),
+ name = "Percent of sample",
+ labels = label_percent(),
+ breaks = c(0, .05, .10, .15, .70)
)
- ) +
- labs(
- x = "Package contributions",
- y = "People"
+ ) +
+ labs(
+ x = "Package contributions",
+ y = "People"
)
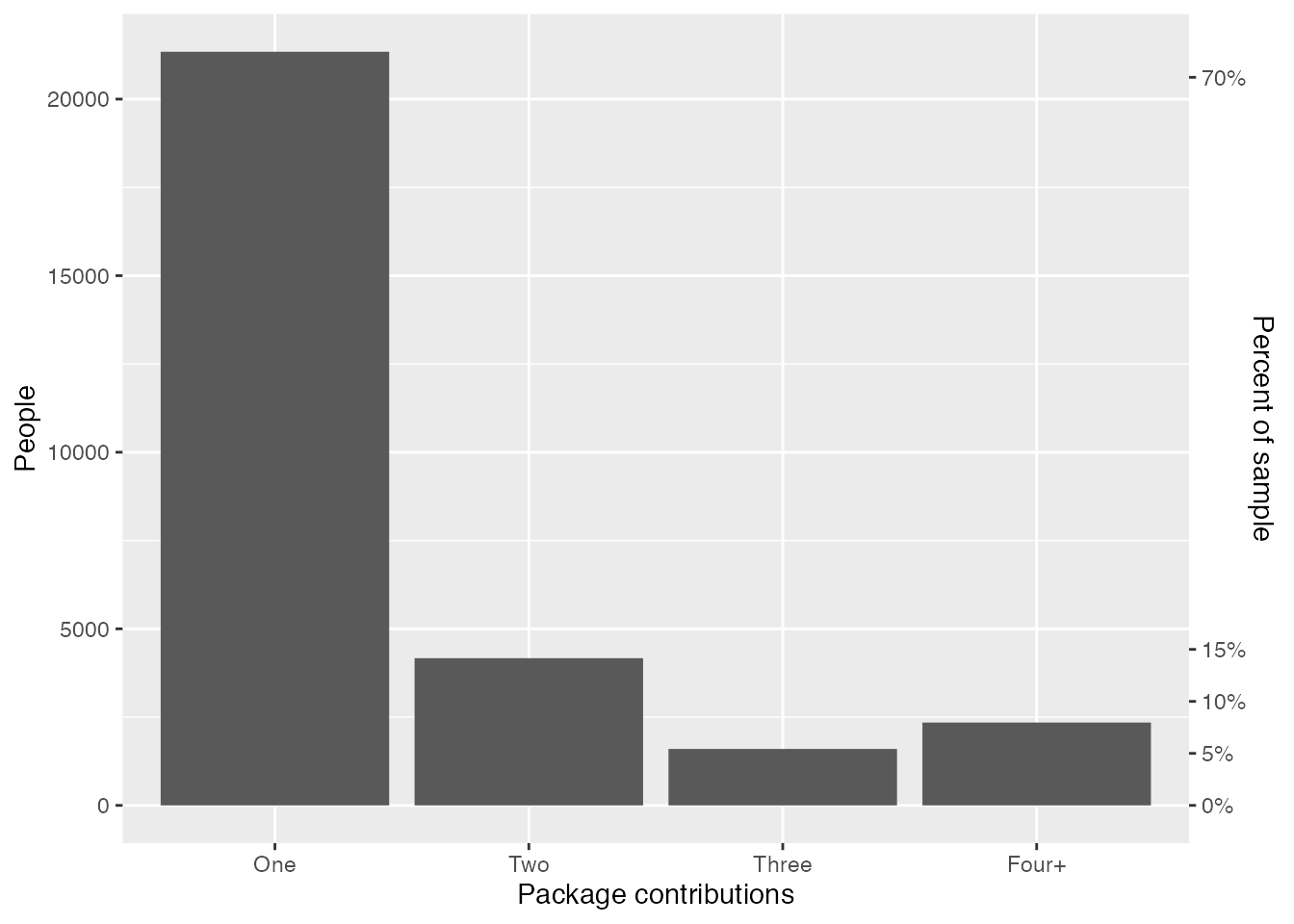
@@ -1029,23 +2095,105 @@
Notably, in the group that have worked on four or more packages, the spread of package contributions is huge. This vast range is mostly driven by people who do R package development as part of their job (e.g., if you look at the cran_author_pkg_counts table above, most of the people at the very top are either professors of statistics or current or former developers from Posit, rOpenSci, or the R Core Team).
-cran_author_pkg_counts |>
- filter(n_pkgs_fct == "Four+") |>
- group_by(rank, n_packages) |>
- summarise(n_people = n()) |>
- ggplot(mapping = aes(x = n_packages, y = n_people)) +
- geom_segment(aes(xend = n_packages, yend = 0)) +
- geom_point() +
- scale_y_continuous(
- sec.axis = sec_axis(
- trans = \(.x) .x / nrow(cran_author_pkg_counts),
- name = "Percent of sample",
- labels = label_percent()
+cran_author_pkg_counts |>
+ filter(n_pkgs_fct == "Four+") |>
+ group_by(rank, n_packages) |>
+ summarise(n_people = n()) |>
+ ggplot(mapping = aes(x = n_packages, y = n_people)) +
+ geom_segment(aes(xend = n_packages, yend = 0)) +
+ geom_point() +
+ scale_y_continuous(
+ sec.axis = sec_axis(
+ trans = \(.x) .x / nrow(cran_author_pkg_counts),
+ name = "Percent of sample",
+ labels = label_percent()
)
- ) +
- labs(
- x = "Package contributions",
- y = "People"
+ ) +
+ labs(
+ x = "Package contributions",
+ y = "People"
)
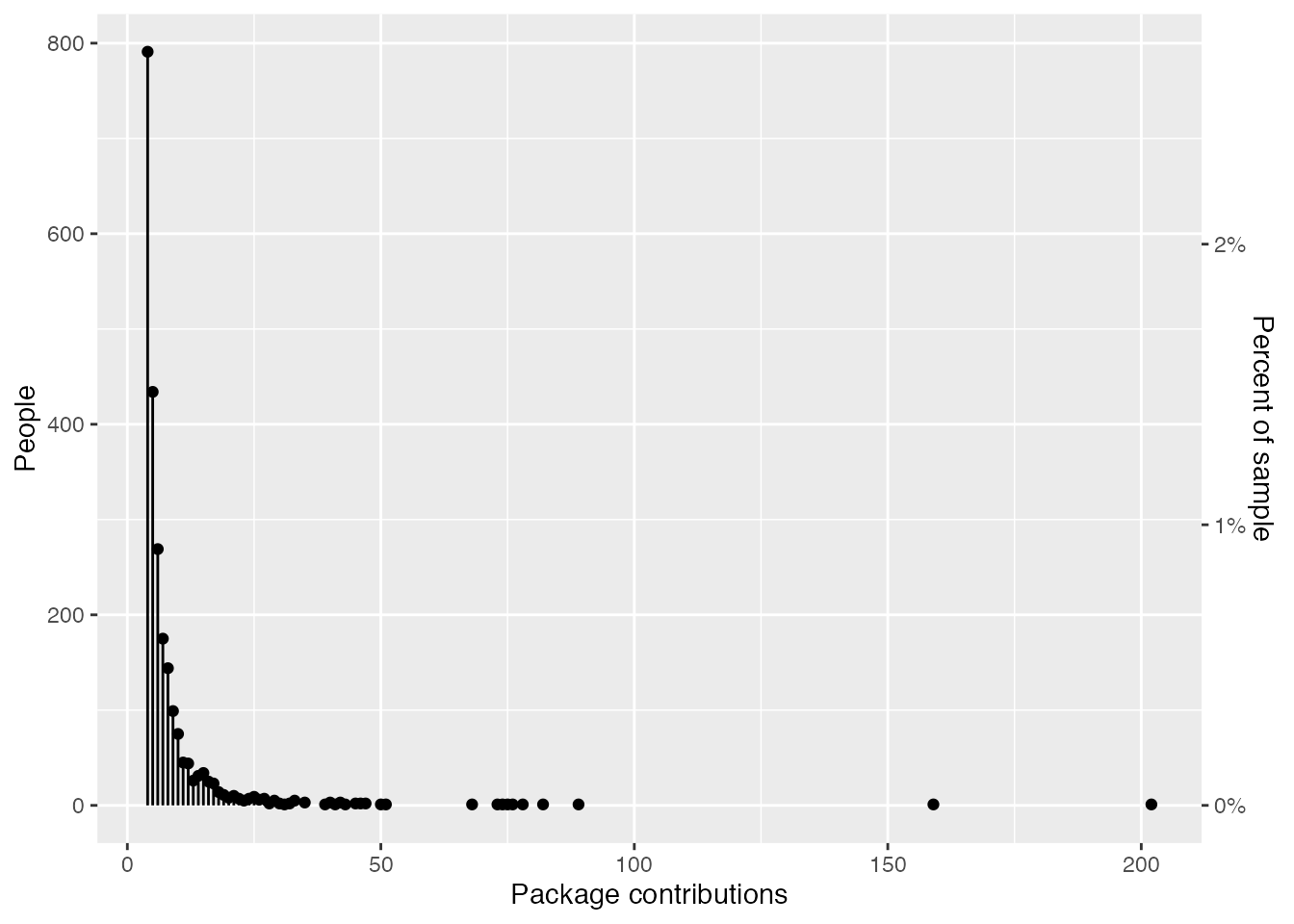
@@ -1053,15 +2201,51 @@
Here are some subsample summary statistics to compliment the plots above.
-cran_author_pkg_counts |>
- group_by(n_packages >= 4) |>
- summarise(
- n_developers = n(),
- n_pkgs_mean = mean(n_packages),
- n_pkgs_sd = sd(n_packages),
- n_pkgs_median = median(n_packages),
- n_pkgs_min = min(n_packages),
- n_pkgs_max = max(n_packages)
+cran_author_pkg_counts |>
+ group_by(n_packages >= 4) |>
+ summarise(
+ n_developers = n(),
+ n_pkgs_mean = mean(n_packages),
+ n_pkgs_sd = sd(n_packages),
+ n_pkgs_median = median(n_packages),
+ n_pkgs_min = min(n_packages),
+ n_pkgs_max = max(n_packages)
)
#> # A tibble: 2 × 7
@@ -1078,14 +2262,44 @@
Not every contribution to an R package involves code. For example, two authors of the wiad package were woodcutters! The package is for wood image analysis, so although it’s surprising a role like that exists, it makes a lot of sense in context. Anyways, neat factoids aside, the point of this section is to look at the distribution of different roles in R package development.
To start, let’s get an idea of how many people were involved in programming-related roles. This won’t be universally true, but most of the time the following roles will involve programming:
-programming_roles <-
- c("author", "creator", "contributor", "compiler", "programmer")
+programming_roles <-
+ c("author", "creator", "contributor", "compiler", "programmer")
Here’s the count:
-cran_author_pkg_counts |>
- filter(if_any(!!programming_roles, \(.x) .x > 0)) |>
- nrow()
+cran_author_pkg_counts |>
+ filter(if_any(!!programming_roles, \(.x) .x > 0)) |>
+ nrow()
#> [1] 24170
@@ -1093,16 +2307,96 @@
There were also 5434 whose role was unknown (either because it wasn’t specified or wasn’t picked up by my regex method). Regardless, most people have been involved in programming-related roles, and although other roles occur they’re relatively rare.
Here’s a plot to compliment this point:
-cran_authors_tidy |>
- summarise(across(analyst:unknown, function(.x) sum(.x, na.rm = TRUE))) |>
- pivot_longer(cols = everything(), names_to = "role", values_to = "n") |>
- arrange(desc(n)) |>
- ggplot(mapping = aes(x = n, y = reorder(role, n))) +
- geom_segment(aes(xend = 0, yend = role)) +
- geom_point() +
- labs(
- x = "Count across packages",
- y = "Role"
+cran_authors_tidy |>
+ summarise(across(analyst:unknown, function(.x) sum(.x, na.rm = TRUE))) |>
+ pivot_longer(cols = everything(), names_to = "role", values_to = "n") |>
+ arrange(desc(n)) |>
+ ggplot(mapping = aes(x = n, y = reorder(role, n))) +
+ geom_segment(aes(xend = 0, yend = role)) +
+ geom_point() +
+ labs(
+ x = "Count across packages",
+ y = "Role"
)
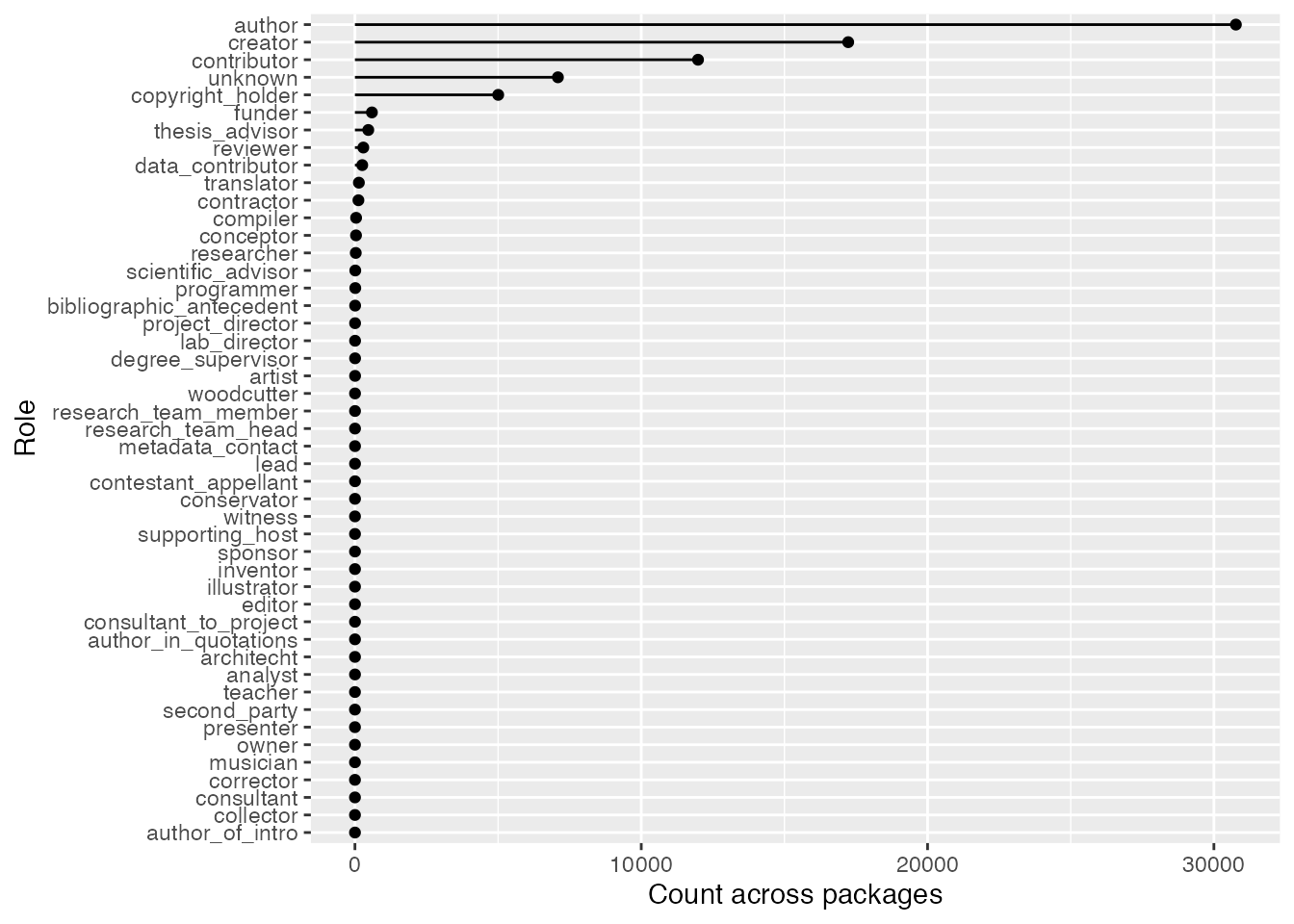
@@ -1116,21 +2410,91 @@
This is why Hadley is on the cover of Glamour magazine and we’re not.

-cran_author_pkg_counts |>
- # We don't want organizations or groups here
- filter(!(person %in% c("RStudio", "R Core Team", "Posit Software, PBC"))) |>
- head(20) |>
- select(person, n_packages) |>
- gt() |>
- tab_header(
- title = "Top 20 R Developers",
- subtitle = "Based on number of CRAN package authorships"
- ) |>
- text_transform(
- \(.x) str_to_title(str_replace_all(.x, "_", " ")),
- locations = cells_column_labels()
- ) |>
- cols_width(person ~ px(140))
+cran_author_pkg_counts |>
+ # We don't want organizations or groups here
+ filter(!(person %in% c("RStudio", "R Core Team", "Posit Software, PBC"))) |>
+ head(20) |>
+ select(person, n_packages) |>
+ gt() |>
+ tab_header(
+ title = "Top 20 R Developers",
+ subtitle = "Based on number of CRAN package authorships"
+ ) |>
+ text_transform(
+ \(.x) str_to_title(str_replace_all(.x, "_", " ")),
+ locations = cells_column_labels()
+ ) |>
+ cols_width(person ~ px(140))
@@ -1651,7 +3015,7 @@
-
+
@@ -1666,7 +3030,7 @@
Thanks for reading! I’m Michael, the voice behind Tidy Tales. I am an award winning data scientist and R programmer with the skills and experience to help you solve the problems you care about. You can learn more about me, my consulting services, and my other projects on my personal website.
- Comments
@@ -1675,7 +3039,7 @@
-Session Info
+Session Info
@@ -1733,15 +3097,8 @@ Any of the trademarks, service marks, collective marks, design rights or similar
-
Citation
BibTeX citation:@online{mccarthy2023,
- author = {Michael McCarthy},
- title = {The {Pareto} {Principle} in {R} Package Development},
- date = {2023-05-03},
- url = {https://tidytales.ca/posts/2023-05-03_r-developers},
- langid = {en}
-}
-
For attribution, please cite this work as:
-Michael McCarthy. (2023, May 3). The Pareto Principle in R package
+Citation
For attribution, please cite this work as:
+McCarthy, M. (2023, May 3). The Pareto Principle in R package
development. https://tidytales.ca/posts/2023-05-03_r-developers
.Wrangle
@@ -1766,7 +3123,7 @@ development. h
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
@@ -2012,22 +3369,14 @@ Jan 24, 2023
No matching items
-Artwork
+Artwork
Artwork by Allison Horst.
-Reuse
Citation
BibTeX citation:@online{mccarthy2023,
- author = {Michael McCarthy},
- title = {Reproducible {Data} {Science}},
- date = {2023-01-24},
- url = {https://tidytales.ca/series/2023-01-24_reproducible-data-science},
- langid = {en}
-}
-
For attribution, please cite this work as:
-Michael McCarthy. (2023, January 24). Reproducible Data
-Science. https://tidytales.ca/series/2023-01-24_reproducible-data-science
+Reuse
Citation
For attribution, please cite this work as:
+McCarthy, M. (2023, January 24). Reproducible Data Science. https://tidytales.ca/series/2023-01-24_reproducible-data-science
.Misc
https://tidytales.ca/series/2023-01-24_reproducible-data-science/index.html
@@ -2047,10 +3396,18 @@ Science. Prerequisites
To access the datasets, help pages, and functions that we will use in this code snippet, load the following packages:
-library(ggplot2)
-library(ggdist)
-library(palettes)
-library(forcats)
+library(ggplot2)
+library(ggdist)
+library(palettes)
+library(forcats)
@@ -2109,48 +3466,226 @@ Science.
-
-
-
-
-
Code
-ggplot(likert_scores, aes(x = score, y = item)) +
- stat_slab(
- aes(fill = cut(after_stat(x), breaks = breaks(x))),
- justification = -.2,
- height = 0.7,
- slab_colour = "black",
- slab_linewidth = 0.5,
- trim = TRUE
- ) +
- geom_boxplot(
- width = .2,
- outlier.shape = NA
- ) +
- geom_jitter(width = .1, height = .1, alpha = .3) +
- scale_fill_manual(
- values = pal_ramp(met_palettes$Hiroshige, 5, -1),
- labels = 1:5,
- guide = guide_legend(title = "score", reverse = TRUE)
+ggplot(likert_scores, aes(x = score, y = item)) +
+ stat_slab(
+ aes(fill = cut(after_stat(x), breaks = breaks(x))),
+ justification = -.2,
+ height = 0.7,
+ slab_colour = "black",
+ slab_linewidth = 0.5,
+ trim = TRUE
+ ) +
+ geom_boxplot(
+ width = .2,
+ outlier.shape = NA
+ ) +
+ geom_jitter(width = .1, height = .1, alpha = .3) +
+ scale_fill_manual(
+ values = pal_ramp(met_palettes$Hiroshige, 5, -1),
+ labels = 1:5,
+ guide = guide_legend(title = "score", reverse = TRUE)
)
-ggplot(likert_scores, aes(x = score, y = item)) +
- stat_slab(
- justification = -.2,
- height = 0.7,
- slab_colour = "black",
- slab_linewidth = 0.5,
- trim = FALSE
- ) +
- geom_boxplot(
- width = .2,
- outlier.shape = NA
- ) +
- geom_jitter(width = .1, height = .1, alpha = .3) +
- scale_x_continuous(breaks = 1:5)
+ggplot(likert_scores, aes(x = score, y = item)) +
+ stat_slab(
+ justification = -.2,
+ height = 0.7,
+ slab_colour = "black",
+ slab_linewidth = 0.5,
+ trim = FALSE
+ ) +
+ geom_boxplot(
+ width = .2,
+ outlier.shape = NA
+ ) +
+ geom_jitter(width = .1, height = .1, alpha = .3) +
+ scale_x_continuous(breaks = 1:5)
@@ -2158,7 +3693,7 @@ Science.
-trim = TRUEtrim = TRUE
@@ -2166,7 +3701,7 @@ Science.
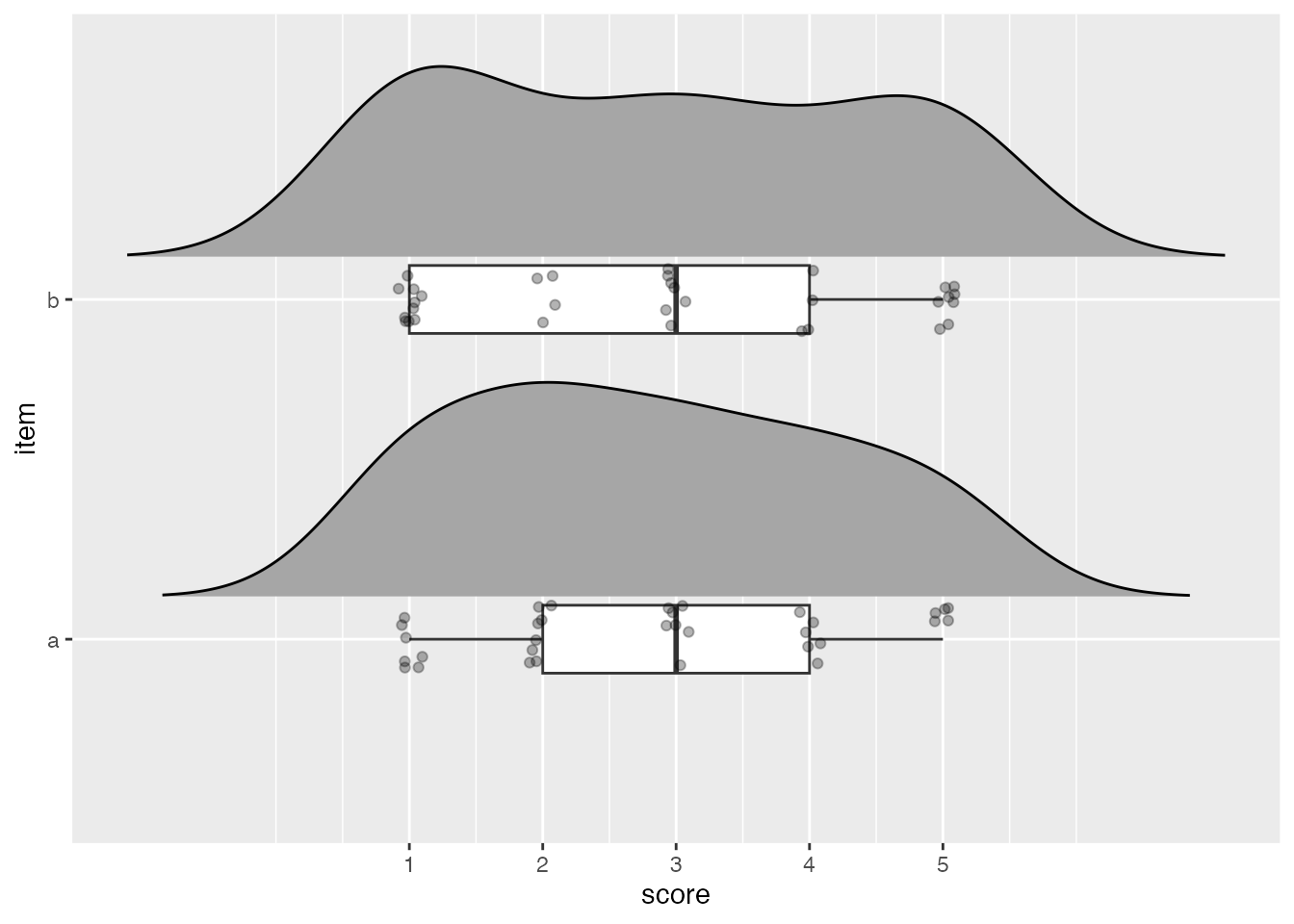
-trim = FALSEtrim = FALSE
First make some data.
-set.seed(123)
+set.seed(123)
-likert_scores <- data.frame(
- item = rep(letters[1:2], times = 33),
- score = sample(1:5, 66, replace = TRUE)
+likert_scores <- data.frame(
+ item = rep(letters[1:2], times = 33),
+ score = sample(1:5, 66, replace = TRUE)
)
It’s straightforward to make density histograms for each item with ggplot2.
-ggplot(likert_scores, aes(x = score, y = after_stat(density))) +
- geom_histogram(
- aes(fill = after_stat(x)),
- bins = 5,
- colour = "black"
- ) +
- scale_fill_gradientn(
- colours = pal_ramp(met_palettes$Hiroshige, 5, -1),
- guide = guide_legend(title = "score", reverse = TRUE)
- ) +
- facet_wrap(vars(fct_rev(item)), ncol = 1)
+ggplot(likert_scores, aes(x = score, y = after_stat(density))) +
+ geom_histogram(
+ aes(fill = after_stat(x)),
+ bins = 5,
+ colour = "black"
+ ) +
+ scale_fill_gradientn(
+ colours = pal_ramp(met_palettes$Hiroshige, 5, -1),
+ guide = guide_legend(title = "score", reverse = TRUE)
+ ) +
+ facet_wrap(vars(fct_rev(item)), ncol = 1)
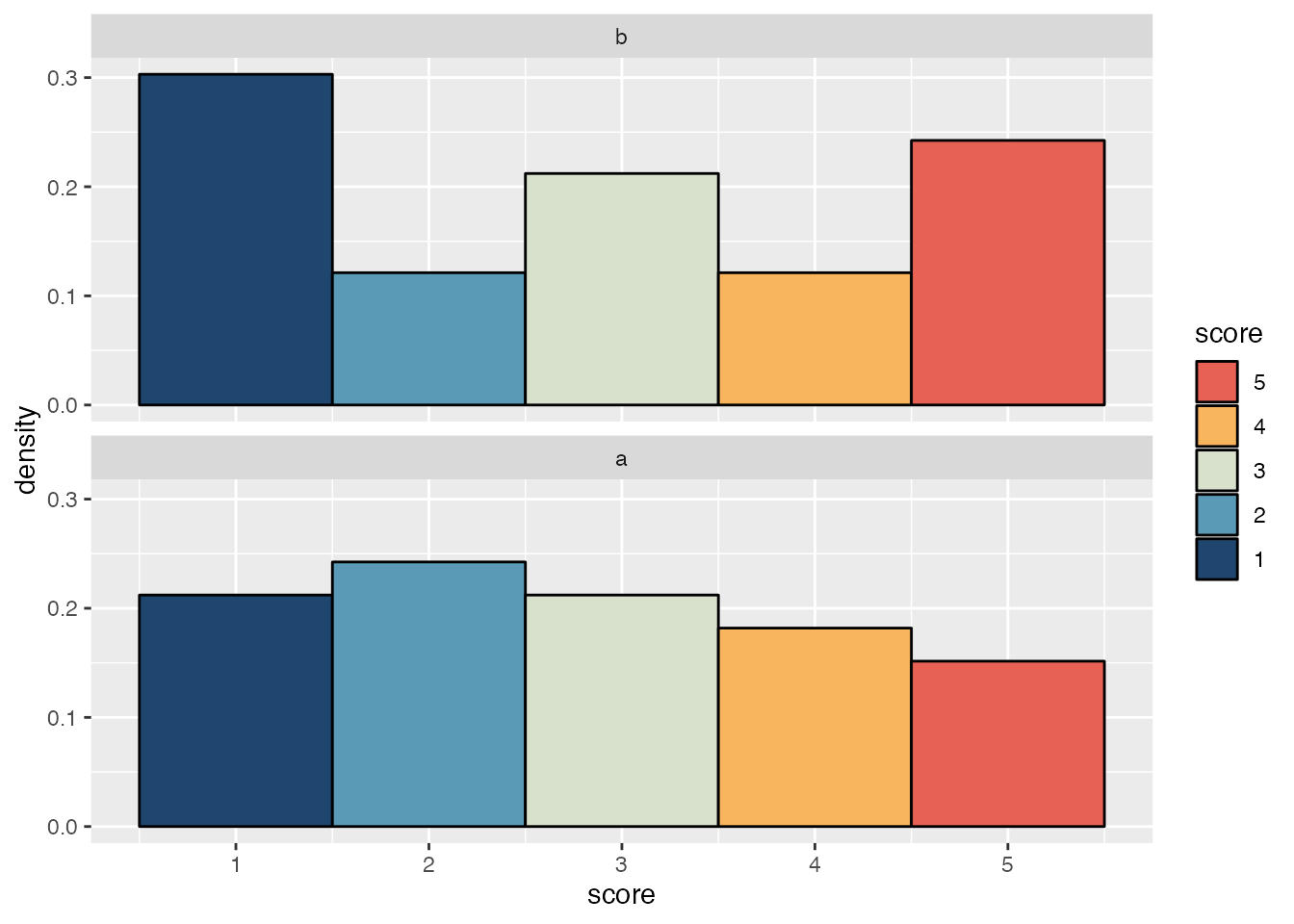
However, the density histograms in this plot can’t be vertically justified to give space for the box and whiskers plot and points used in a typical raincloud plot. For that we need the stat_slab() function from the ggdist package and a small helper function to determine where to put breaks in the histogram.
-#' Set breaks so bins are centred on each score
-#'
-#' @param x A vector of values.
-#' @param width Any value between 0 and 0.5 for setting the width of the bins.
-breaks <- function(x, width = 0.49999999) {
- rep(1:max(x), each = 2) + c(-width, width)
+#' Set breaks so bins are centred on each score
+#'
+#' @param x A vector of values.
+#' @param width Any value between 0 and 0.5 for setting the width of the bins.
+breaks <- function(x, width = 0.49999999) {
+ rep(1:max(x), each = 2) + c(-width, width)
}
The default slab type for stat_slab() is a probability density (or mass) function ("pdf"), but it can also calculate density histograms ("histogram"). To match the appearance of geom_histogram(), the breaks argument needs to be given the location of each bin’s left and right edge; this also necessitates using cut() with the fill aesthetic so the fill breaks correctly align with each bin.
-ggplot(likert_scores, aes(x = score, y = item)) +
- stat_slab(
- # Divide fill into five equal bins
- aes(fill = cut(after_stat(x), breaks = 5)),
- slab_type = "histogram",
- breaks = \(x) breaks(x),
- # Justify the histogram upwards
- justification = -.2,
- # Reduce the histogram's height so it doesn't cover geoms from other items
- height = 0.7,
- # Add black outlines because they look nice
- slab_colour = "black",
- outline_bars = TRUE,
- slab_linewidth = 0.5
- ) +
- geom_boxplot(
- width = .2,
- # Hide outliers since the raw data will be plotted
- outlier.shape = NA
- ) +
- geom_jitter(width = .1, height = .1, alpha = .3) +
- # Cutting the fill into bins puts it on a discrete scale
- scale_fill_manual(
- values = pal_ramp(met_palettes$Hiroshige, 5, -1),
- labels = 1:5,
- guide = guide_legend(title = "score", reverse = TRUE)
+ggplot(likert_scores, aes(x = score, y = item)) +
+ stat_slab(
+ # Divide fill into five equal bins
+ aes(fill = cut(after_stat(x), breaks = 5)),
+ slab_type = "histogram",
+ breaks = \(x) breaks(x),
+ # Justify the histogram upwards
+ justification = -.2,
+ # Reduce the histogram's height so it doesn't cover geoms from other items
+ height = 0.7,
+ # Add black outlines because they look nice
+ slab_colour = "black",
+ outline_bars = TRUE,
+ slab_linewidth = 0.5
+ ) +
+ geom_boxplot(
+ width = .2,
+ # Hide outliers since the raw data will be plotted
+ outlier.shape = NA
+ ) +
+ geom_jitter(width = .1, height = .1, alpha = .3) +
+ # Cutting the fill into bins puts it on a discrete scale
+ scale_fill_manual(
+ values = pal_ramp(met_palettes$Hiroshige, 5, -1),
+ labels = 1:5,
+ guide = guide_legend(title = "score", reverse = TRUE)
)
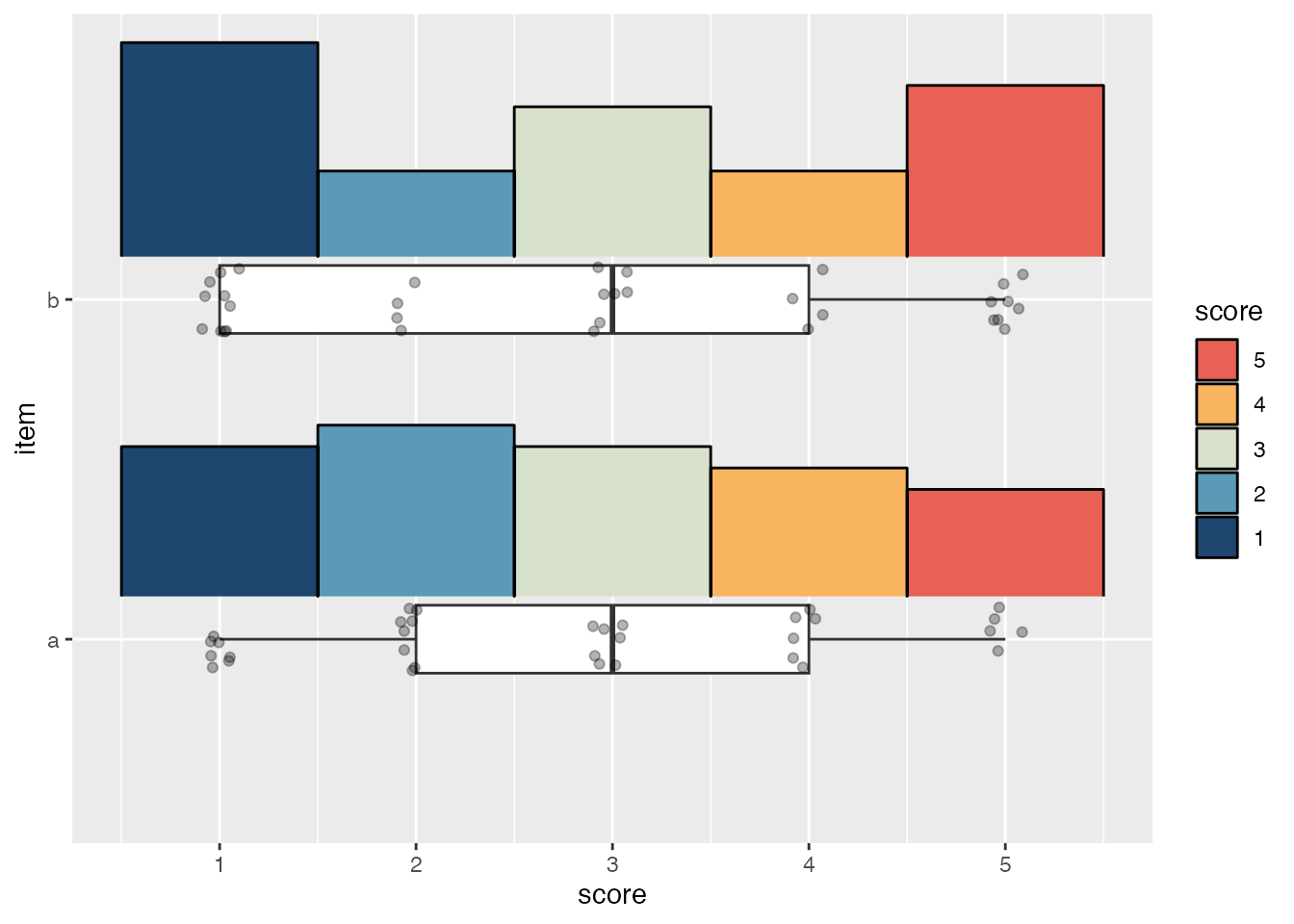
@@ -2253,7 +4058,7 @@ Science.
+
@@ -2268,7 +4073,7 @@ Science. consulting services, and my other projects on my personal website.
- Comments
+Comments
@@ -2277,7 +4082,7 @@ Science. Session Info
+Session Info
@@ -2332,16 +4137,8 @@ Any of the trademarks, service marks, collective marks, design rights or similar
It also makes it difficult to get the fill breaks right, hence the lack of any fill colours in the trim = FALSE example.↩︎
-Reuse
Citation
BibTeX citation:@online{mccarthy2023,
- author = {Michael McCarthy},
- title = {Histogram Raincloud Plots},
- date = {2023-01-19},
- url = {https://tidytales.ca/snippets/2023-01-19_ggdist-histogram-rainclouds},
- langid = {en}
-}
-
For attribution, please cite this work as:
-Michael McCarthy. (2023, January 19). Histogram raincloud
-plots. https://tidytales.ca/snippets/2023-01-19_ggdist-histogram-rainclouds
+Reuse
Citation
For attribution, please cite this work as:
+McCarthy, M. (2023, January 19). Histogram raincloud plots. https://tidytales.ca/snippets/2023-01-19_ggdist-histogram-rainclouds
.Visualize
{ggplot2}
@@ -2362,35 +4159,165 @@ plots. Prerequisites
To access the datasets, help pages, and functions that we will use in this code snippet, load the following packages:
-library(ggplot2)
-library(patchwork)
+library(ggplot2)
+library(patchwork)
Then make some data and ggplot2 plots to be used in the patchwork.
-huron <- data.frame(year = 1875:1972, level = as.vector(LakeHuron))
-h <- ggplot(huron, aes(year))
+huron <- data.frame(year = 1875:1972, level = as.vector(LakeHuron))
+h <- ggplot(huron, aes(year))
-h1 <- h +
- geom_ribbon(aes(ymin = level - 1, ymax = level + 1), fill = "grey70") +
- geom_line(aes(y = level))
+h1 <- h +
+ geom_ribbon(aes(ymin = level - 1, ymax = level + 1), fill = "grey70") +
+ geom_line(aes(y = level))
-h2 <- h + geom_area(aes(y = level))
+h2 <- h + geom_area(aes(y = level))
Shared x-axis labels
We set the bottom margin to 0 so the tag is in the same vertical position that the x-axis would otherwise be in.
-# Create the patchwork, dropping the x-axis labels from the plots, and setting
-# the margins
-h_patch <- h1 + h2 & xlab(NULL) & theme(plot.margin = margin(5.5, 5.5, 0, 5.5))
+# Create the patchwork, dropping the x-axis labels from the plots, and setting
+# the margins
+h_patch <- h1 + h2 & xlab(NULL) & theme(plot.margin = margin(5.5, 5.5, 0, 5.5))
-# Use the tag label as an x-axis label
-wrap_elements(panel = h_patch) +
- labs(tag = "year") +
- theme(
- plot.tag = element_text(size = rel(1)),
- plot.tag.position = "bottom"
+# Use the tag label as an x-axis label
+wrap_elements(panel = h_patch) +
+ labs(tag = "year") +
+ theme(
+ plot.tag = element_text(size = rel(1)),
+ plot.tag.position = "bottom"
)
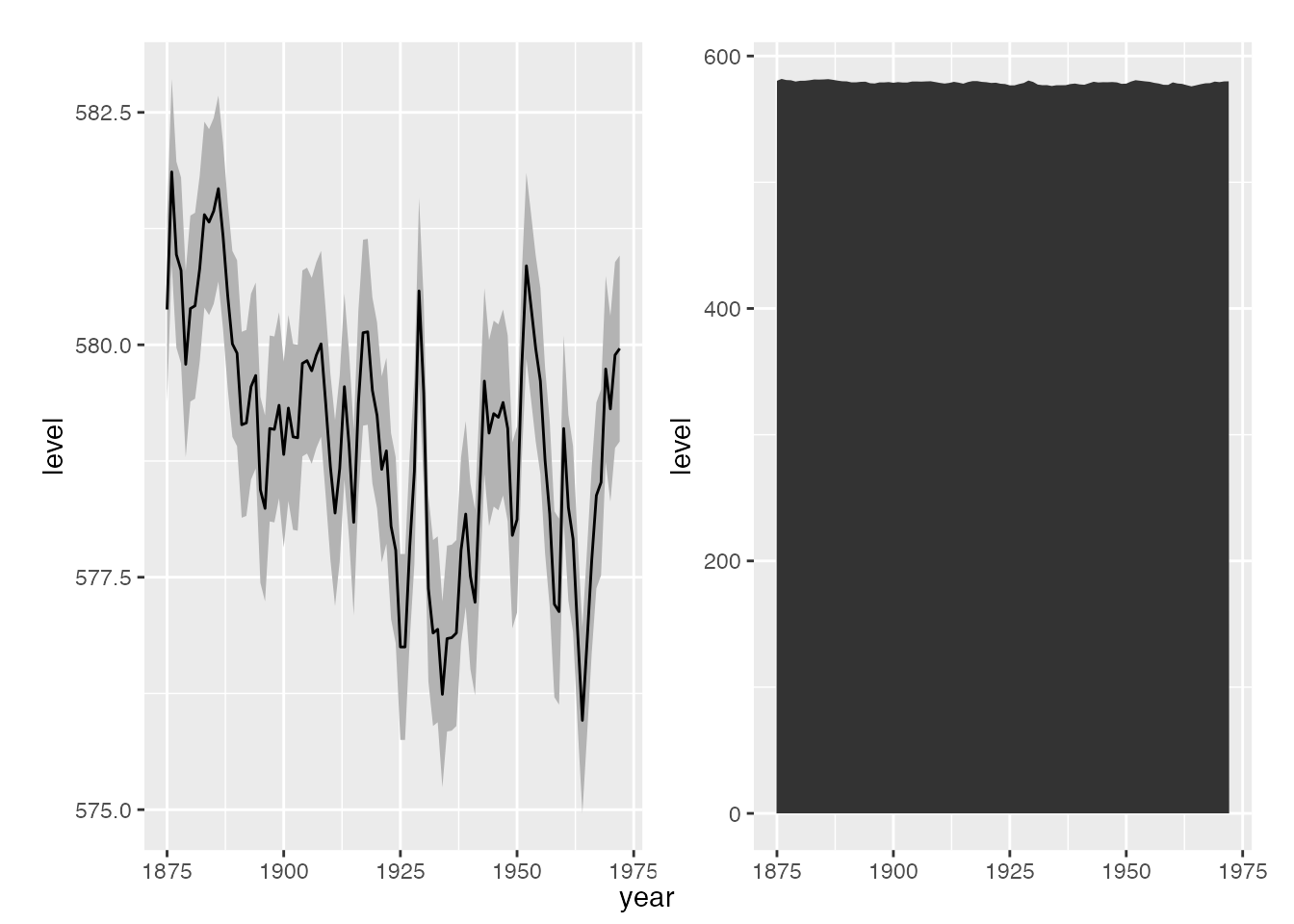
@@ -2401,16 +4328,80 @@ plots. Shared y-axis labels
We set the left margin to 0 so the tag is in the same horizontal position that the y-axis would otherwise be in.
-# Create the patchwork, dropping the y-axis labels from the plots, and setting
-# the margins
-h_patch <- h1 / h2 & ylab(NULL) & theme(plot.margin = margin(5.5, 5.5, 5.5, 0))
+# Create the patchwork, dropping the y-axis labels from the plots, and setting
+# the margins
+h_patch <- h1 / h2 & ylab(NULL) & theme(plot.margin = margin(5.5, 5.5, 5.5, 0))
-# Use the tag label as a y-axis label
-wrap_elements(h_patch) +
- labs(tag = "level") +
- theme(
- plot.tag = element_text(size = rel(1), angle = 90),
- plot.tag.position = "left"
+# Use the tag label as a y-axis label
+wrap_elements(h_patch) +
+ labs(tag = "level") +
+ theme(
+ plot.tag = element_text(size = rel(1), angle = 90),
+ plot.tag.position = "left"
)
@@ -2421,32 +4412,144 @@ plots. Shared axis labels without using patchwork
Elio Campitelli shared a solution on Mastodon that accomplishes the same results as above, but without patchwork. It uses the magic tilde notation to create functions in the data argument of each geom that adds a grouping variable var that can be faceted on.
-h <- ggplot(huron, aes(year)) +
- geom_ribbon(
- data = ~ transform(.x, var = "a"),
- aes(ymin = level - 1, ymax = level + 1),
- fill = "grey70"
- ) +
- geom_line(data = ~ transform(.x, var = "a"), aes(y = level)) +
- geom_area(data = ~ transform(.x, var = "b"), aes(y = level)) +
- # Since we don't care about the facet strips here, we can remove them.
- theme(
- strip.text = element_blank(),
- strip.background = element_blank()
+h <- ggplot(huron, aes(year)) +
+ geom_ribbon(
+ data = ~ transform(.x, var = "a"),
+ aes(ymin = level - 1, ymax = level + 1),
+ fill = "grey70"
+ ) +
+ geom_line(data = ~ transform(.x, var = "a"), aes(y = level)) +
+ geom_area(data = ~ transform(.x, var = "b"), aes(y = level)) +
+ # Since we don't care about the facet strips here, we can remove them.
+ theme(
+ strip.text = element_blank(),
+ strip.background = element_blank()
)
Facet by rows for a shared x-axis.
-h +
- facet_wrap(vars(var), scales = "free_y")
+h +
+ facet_wrap(vars(var), scales = "free_y")
Facet by columns for a shared y-axis.
-h +
- facet_wrap(vars(var), scales = "free_y", ncol = 1)
+h +
+ facet_wrap(vars(var), scales = "free_y", ncol = 1)
@@ -2456,7 +4559,7 @@ plots.
+
@@ -2471,7 +4574,7 @@ plots. consulting services, and my other projects on my personal website.
- Comments
+Comments
@@ -2480,7 +4583,7 @@ plots. Session Info
+Session Info
@@ -2528,16 +4631,9 @@ Any of the trademarks, service marks, collective marks, design rights or similar
-
Reuse
Citation
BibTeX citation:@online{mccarthy2022,
- author = {Michael McCarthy},
- title = {Shared Axis Labels in Patchwork Plots},
- date = {2022-12-22},
- url = {https://tidytales.ca/snippets/2022-12-22_patchwork-shared-axis-labels},
- langid = {en}
-}
-
For attribution, please cite this work as:
-Michael McCarthy. (2022, December 22). Shared axis labels in
-patchwork plots. https://tidytales.ca/snippets/2022-12-22_patchwork-shared-axis-labels
+Reuse
Citation
For attribution, please cite this work as:
+McCarthy, M. (2022, December 22). Shared axis labels in patchwork
+plots. https://tidytales.ca/snippets/2022-12-22_patchwork-shared-axis-labels
.Visualize
{ggplot2}
@@ -2579,7 +4675,11 @@ $(function(){
To make it easy for anyone to make their own colour palette package. Colour palette packages made with palettes exist solely for the purpose of distributing colour palettes and get access to all the features of palettes for free.
If you just want to jump in and start using palettes, you can install it from CRAN with:
-install.packages("palettes")
+install.packages("palettes")
The package website is the best place to start: https://mccarthy-m-g.github.io/palettes/index.html
If you want to learn more about why you should be using palettes, read on to learn more about the motivation of the package and how it makes working with colour vectors and colour palettes easy and fun for everyone.

-Hellboy promo poster by Mike Mignola
+Hellboy promo poster by Mike Mignola
So how does one make a colour palette package in R? My answer now is to read the Creating a colour palette package vignette and make it with palettes. My answer then was to read the source code of several other colour palette packages, then reimplement the relevant functions in BPRDcolours. Not a great answer, but it’s the approach everyone else was using.
@@ -2605,7 +4705,9 @@ $(function(){
Just show me some colour palettes already!
Okay, okay.
-library(palettes)
+library(palettes)
Colour classes in palettes come in two forms:
@@ -2615,7 +4717,23 @@ $(function(){
Colour vectors can be thought of as a base type for colours, and colour palettes are just (named) lists of colour vectors. To illustrate, let’s use some colours from the MetBrewer package.
pal_colour() is a nice way to create a colour vector.
-java <- pal_colour(c("#663171", "#cf3a36", "#ea7428", "#e2998a", "#0c7156"))
+java <- pal_colour(c("#663171", "#cf3a36", "#ea7428", "#e2998a", "#0c7156"))
java
#> <palettes_colour[5]>
#> • #663171
@@ -2627,9 +4745,27 @@ $(function(){
pal_palette() is a nice way to create named colour palettes.
-metbrewer_palettes <- pal_palette(
- egypt = c("#dd5129", "#0f7ba2", "#43b284", "#fab255"),
- java = java
+metbrewer_palettes <- pal_palette(
+ egypt = c("#dd5129", "#0f7ba2", "#43b284", "#fab255"),
+ java = java
)
metbrewer_palettes
#> <palettes_palette[2]>
@@ -2651,7 +4787,9 @@ $(function(){
plot() is a nice way to showcase colour vectors and colour palettes. The appearance of the plot depends on the input.
-plot(metbrewer_palettes)
+plot(metbrewer_palettes)

@@ -2659,7 +4797,11 @@ $(function(){
Casting and coercion methods are also available to turn other objects (like character vectors or lists) into colour vectors and colour palettes.
You can even cast colour vectors and colour palettes into tibbles.
-metbrewer_tbl <- as_tibble(metbrewer_palettes)
+metbrewer_tbl <- as_tibble(metbrewer_palettes)
metbrewer_tbl
#> # A tibble: 9 × 2
#> palette colour
@@ -2677,9 +4819,19 @@ $(function(){
This is useful if you want to wrangle the colours with dplyr.
-library(dplyr)
+library(dplyr)
-metbrewer_tbl <- slice(metbrewer_tbl, -8)
+metbrewer_tbl <- slice(metbrewer_tbl, -8)
metbrewer_tbl
#> # A tibble: 8 × 2
#> palette colour
@@ -2696,12 +4848,28 @@ $(function(){
Then go back to a colour palette with the deframe() function from tibble.
-library(tibble)
+library(tibble)
-metbrewer_tbl %>%
- group_by(palette) %>%
- summarise(pal_palette(colour)) %>%
- deframe()
+metbrewer_tbl %>%
+ group_by(palette) %>%
+ summarise(pal_palette(colour)) %>%
+ deframe()
#> <palettes_palette[2]>
#> $egypt
#> <palettes_colour[4]>
@@ -2723,17 +4891,67 @@ $(function(){
What about ggplot2 plots?
Just use one of the scale_ functions!
-library(ggplot2)
+library(ggplot2)
-hiroshige <- pal_colour(c(
- "#1e466e", "#376795", "#528fad", "#72bcd5", "#aadce0",
- "#ffe6b7", "#ffd06f", "#f7aa58", "#ef8a47", "#e76254"
+hiroshige <- pal_colour(c(
+ "#1e466e", "#376795", "#528fad", "#72bcd5", "#aadce0",
+ "#ffe6b7", "#ffd06f", "#f7aa58", "#ef8a47", "#e76254"
))
-ggplot(faithfuld, aes(waiting, eruptions, fill = density)) +
- geom_raster() +
- coord_cartesian(expand = FALSE) +
- scale_fill_palette_c(hiroshige)
+ggplot(faithfuld, aes(waiting, eruptions, fill = density)) +
+ geom_raster() +
+ coord_cartesian(expand = FALSE) +
+ scale_fill_palette_c(hiroshige)
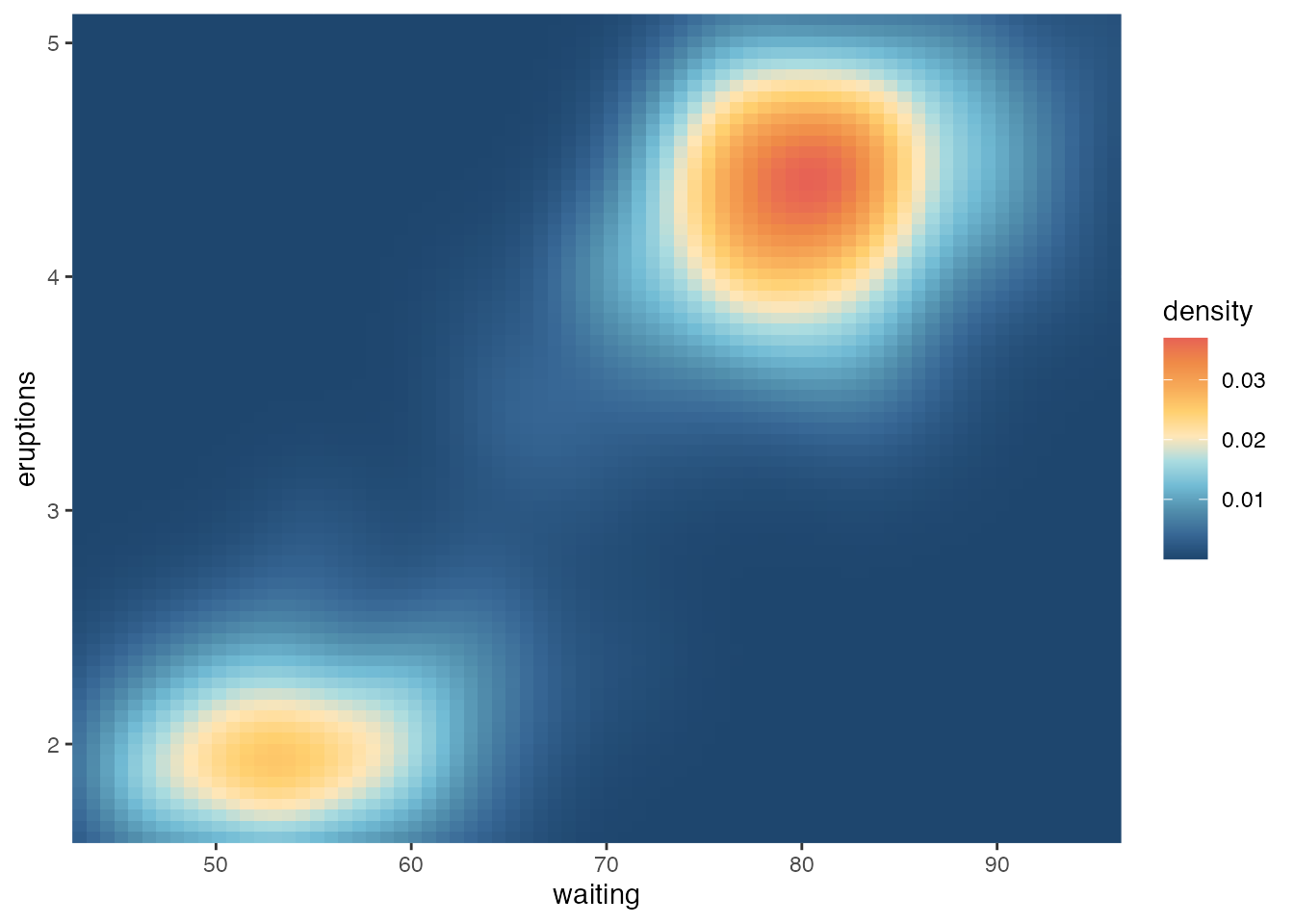
@@ -2755,15 +4973,12 @@ $(function(){
- Make a better hex sticker (looking for help on this one!)
If you have other suggestions or requests, please file an issue on GitHub.
-
-
-
-
+
@@ -2778,7 +4993,7 @@ $(function(){
Thanks for reading! I’m Michael, the voice behind Tidy Tales. I am an award winning data scientist and R programmer with the skills and experience to help you solve the problems you care about. You can learn more about me, my consulting services, and my other projects on my personal website.
- Comments
+Comments
@@ -2787,7 +5002,7 @@ $(function(){
-Session Info
+Session Info
@@ -2837,15 +5052,8 @@ Any of the trademarks, service marks, collective marks, design rights or similar
-
Citation
BibTeX citation:@online{mccarthy2022,
- author = {Michael McCarthy},
- title = {Introducing the Palettes Package},
- date = {2022-12-20},
- url = {https://tidytales.ca/posts/2022-12-20_palettes},
- langid = {en}
-}
-
For attribution, please cite this work as:
-Michael McCarthy. (2022, December 20). Introducing the palettes
+Citation
For attribution, please cite this work as:
+McCarthy, M. (2022, December 20). Introducing the palettes
package. https://tidytales.ca/posts/2022-12-20_palettes
.Visualize
@@ -2870,38 +5078,170 @@ package. https://t
Prerequisites
To access the datasets, help pages, and functions that we will use in this code snippet, load the following packages:
-library(tidyverse)
-library(ggdist)
-library(geomtextpath)
+library(tidyverse)
+library(ggdist)
+library(geomtextpath)
Directly labeling lineribbons
First make some data.
-set.seed(1234)
-n = 5000
+set.seed(1234)
+n = 5000
-df <- tibble(
- .draw = 1:n,
- intercept = rnorm(n, 3, 1),
- slope = rnorm(n, 1, 0.25),
- x = list(-4:5),
- y = map2(intercept, slope, ~ .x + .y * -4:5)
-) %>%
- unnest(c(x, y))
+df <- tibble(
+ .draw = 1:n,
+ intercept = rnorm(n, 3, 1),
+ slope = rnorm(n, 1, 0.25),
+ x = list(-4:5),
+ y = map2(intercept, slope, ~ .x + .y * -4:5)
+) %>%
+ unnest(c(x, y))
Then plot it.
-df %>%
- group_by(x) %>%
- median_qi(y, .width = c(.50, .80, .95)) %>%
- ggplot(aes(x = x, y = y, ymin = .lower, ymax = .upper)) +
- # Hide the line from geom_lineribbon() by setting `size = 0`
- geom_lineribbon(size = 0) +
- scale_fill_brewer() +
- # Replace the hidden line with a labelled line
- geom_textline(label = "label")
+df %>%
+ group_by(x) %>%
+ median_qi(y, .width = c(.50, .80, .95)) %>%
+ ggplot(aes(x = x, y = y, ymin = .lower, ymax = .upper)) +
+ # Hide the line from geom_lineribbon() by setting `size = 0`
+ geom_lineribbon(size = 0) +
+ scale_fill_brewer() +
+ # Replace the hidden line with a labelled line
+ geom_textline(label = "label")
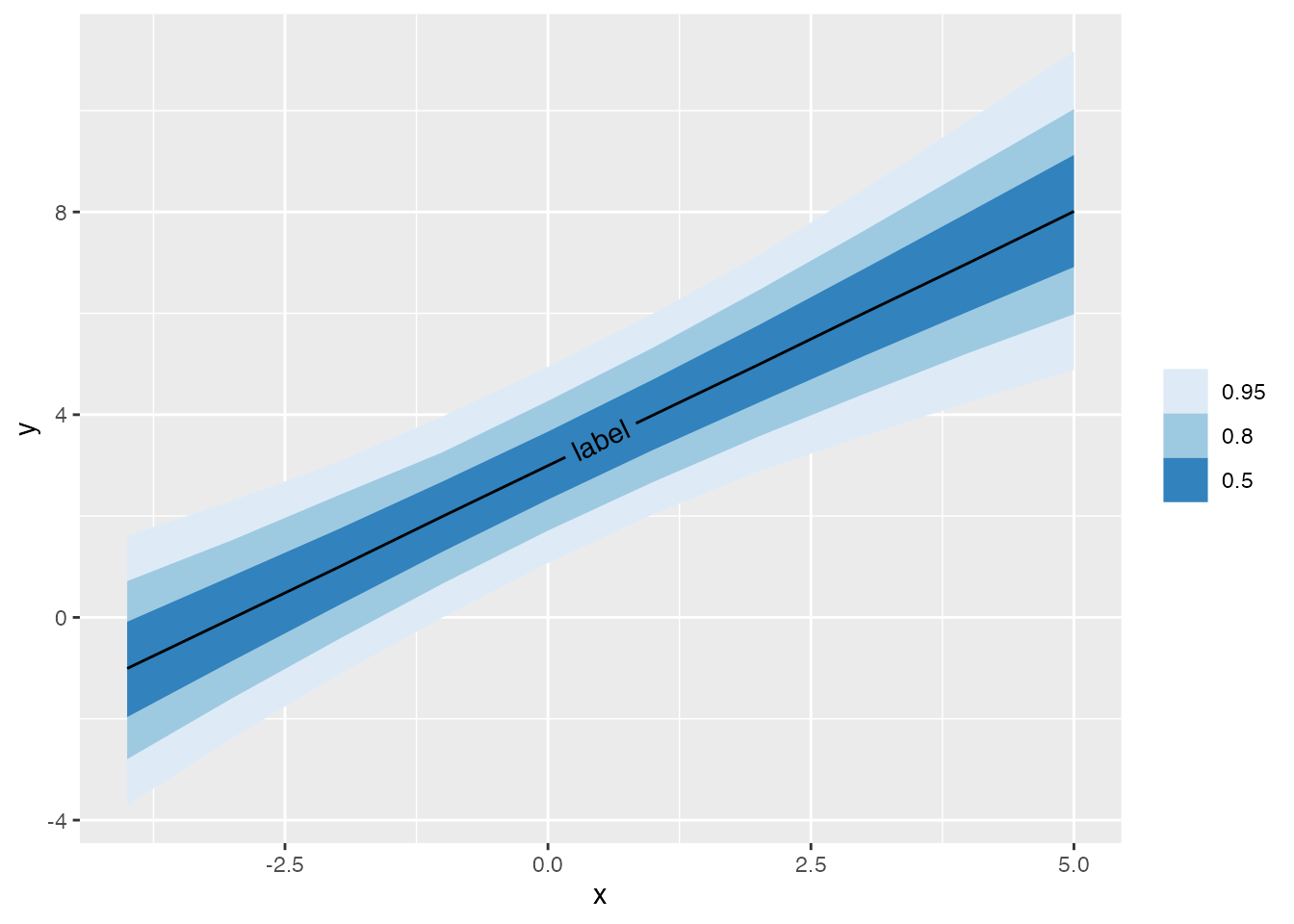
@@ -2911,7 +5251,7 @@ package. https://t
-
+
@@ -2926,7 +5266,7 @@ package. https://t
Thanks for reading! I’m Michael, the voice behind Tidy Tales. I am an award winning data scientist and R programmer with the skills and experience to help you solve the problems you care about. You can learn more about me, my consulting services, and my other projects on my personal website.
- Comments
+Comments
@@ -2935,7 +5275,7 @@ package. https://t
-Session Info
+Session Info
@@ -2992,15 +5332,8 @@ Any of the trademarks, service marks, collective marks, design rights or similar
-
Reuse
Citation
BibTeX citation:@online{mccarthy2022,
- author = {Michael McCarthy},
- title = {Directly Labeling Ggdist Lineribbons with Geomtextpath},
- date = {2022-10-29},
- url = {https://tidytales.ca/snippets/2022-10-29_geomtextpath-with-ggdist},
- langid = {en}
-}
-
For attribution, please cite this work as:
-Michael McCarthy. (2022, October 29). Directly labeling ggdist
+Reuse
Citation
For attribution, please cite this work as:
+McCarthy, M. (2022, October 29). Directly labeling ggdist
lineribbons with geomtextpath. https://tidytales.ca/snippets/2022-10-29_geomtextpath-with-ggdist
.Visualize
@@ -3026,7 +5359,7 @@ lineribbons with geomtextpath.

-In-game screenshot from Borderlands 3.
+In-game screenshot from Borderlands 3.
@@ -3045,7 +5378,7 @@ lineribbons with geomtextpath.
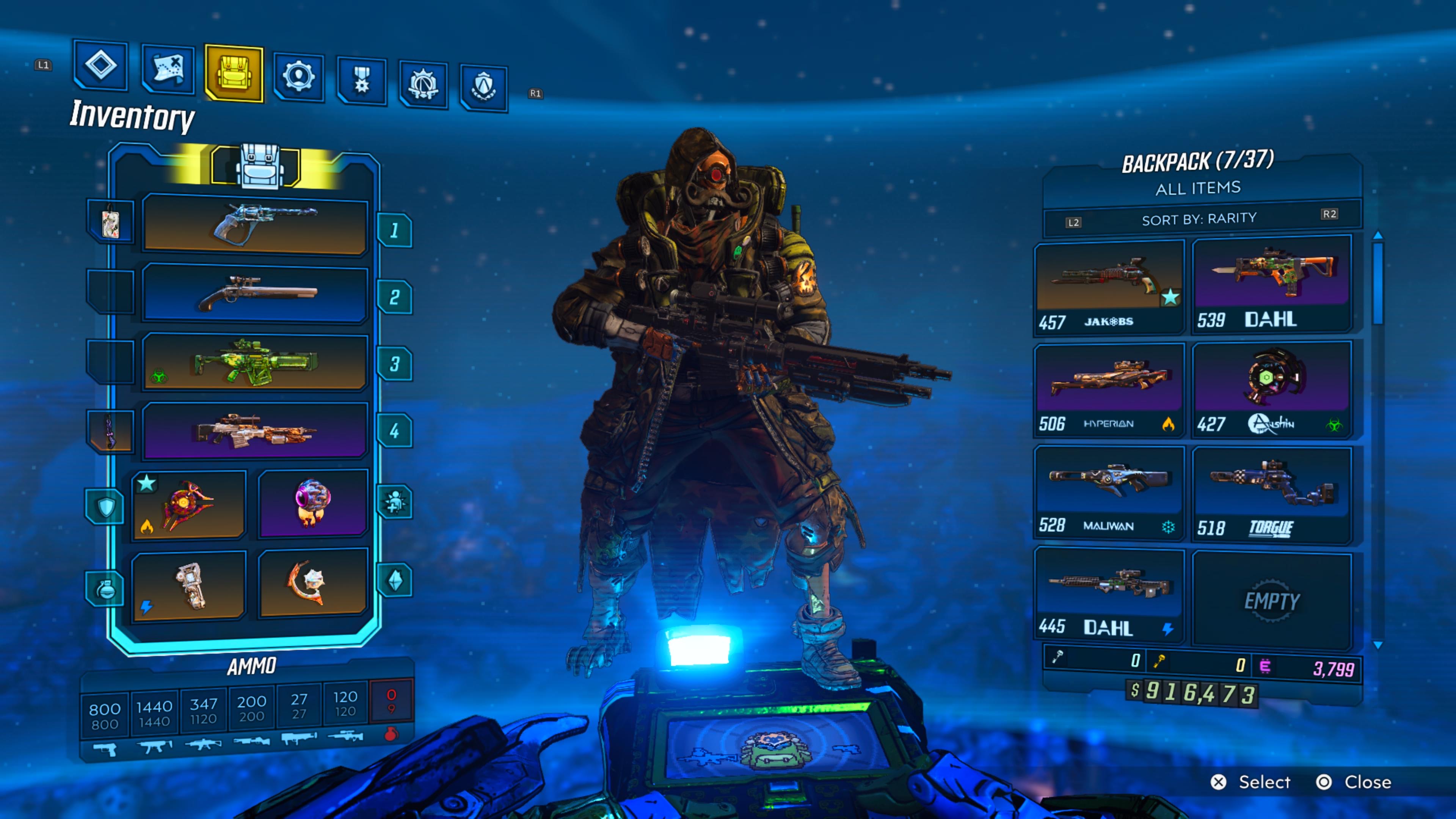
-The ECHO-3 in-game menu in Borderlands 3.
+The ECHO-3 in-game menu in Borderlands 3.
@@ -3057,7 +5390,7 @@ lineribbons with geomtextpath.

-Loot in Borderlands (guns, grenades, shields, etc.) are colour categorized by the rarity with which they can be found in containers or dropped by defeated enemies. From left to right the categories are: Common, Uncommon, Rare, Epic, Legendary.
+Loot in Borderlands (guns, grenades, shields, etc.) are colour categorized by the rarity with which they can be found in containers or dropped by defeated enemies. From left to right the categories are: Common, Uncommon, Rare, Epic, Legendary.
@@ -3077,16 +5410,38 @@ lineribbons with geomtextpath.
Prerequisites
-library(tidyverse)
-library(glue)
-library(lubridate)
-library(magick)
-library(ggdist)
+library(tidyverse)
+library(glue)
+library(lubridate)
+library(magick)
+library(ggdist)
I’ll be using Steam player data for my plot. The data contains statistics for the average and peak number of players playing a variety of games each month from July 2012 to February 2022. You can download this data with the Data Source code in the appendix, or from Tidy Tuesday with tidytuesdayR::tt_load("2021-03-16").
-# Load the weekly data
-games <- read_csv(here("data", "2021-03-16_games.csv"))
+# Load the weekly data
+games <- read_csv(here("data", "2021-03-16_games.csv"))
games
@@ -3102,11 +5457,27 @@ lineribbons with geomtextpath. Wrangle
I only want data from the mainline Borderlands titles for my plot, so let’s get those.
-# Filter to mainline Borderlands titles available in the data. The first game
-# is not available in the dataset so filtering based on the title and digit
-# works fine here.
-borderlands <- games %>%
- filter(str_detect(gamename, "Borderlands[[:space:]][[:digit:]]"))
+# Filter to mainline Borderlands titles available in the data. The first game
+# is not available in the dataset so filtering based on the title and digit
+# works fine here.
+borderlands <- games %>%
+ filter(str_detect(gamename, "Borderlands[[:space:]][[:digit:]]"))
borderlands
@@ -3120,10 +5491,24 @@ lineribbons with geomtextpath.
-# Summarize how much data exists for each Borderlands title
-borderlands %>%
- group_by(gamename) %>%
- summarise(count = n())
+# Summarize how much data exists for each Borderlands title
+borderlands %>%
+ group_by(gamename) %>%
+ summarise(count = n())
@@ -3135,20 +5520,80 @@ lineribbons with geomtextpath.
-# Wrangle date data into a date-time object to prepare for filtering
-borderlands <- borderlands %>%
- mutate(date = glue("{year}-{month}"),
- date = parse_date_time(date, "ym"),
- .after = gamename)
+# Wrangle date data into a date-time object to prepare for filtering
+borderlands <- borderlands %>%
+ mutate(date = glue("{year}-{month}"),
+ date = parse_date_time(date, "ym"),
+ .after = gamename)
-# Filter Borderlands 2 data down to only its first year of release to make
-# comparisons with Borderlands 3 more appropriate. There is no need to filter
-# by date for Borderlands 3 since only its first year of data are available in
-# the dataset.
-borderlands <- borderlands %>%
- filter(gamename == "Borderlands 2" &
- date %within% interval(ymd("2012--09-01"), ymd("2013--08-01")) |
- gamename == "Borderlands 3")
+# Filter Borderlands 2 data down to only its first year of release to make
+# comparisons with Borderlands 3 more appropriate. There is no need to filter
+# by date for Borderlands 3 since only its first year of data are available in
+# the dataset.
+borderlands <- borderlands %>%
+ filter(gamename == "Borderlands 2" &
+ date %within% interval(ymd("2012--09-01"), ymd("2013--08-01")) |
+ gamename == "Borderlands 3")
borderlands
@@ -3162,10 +5607,32 @@ lineribbons with geomtextpath.
-# This code is sufficient since the data is in reverse chronological order.
-borderlands <- borderlands %>%
- group_by(gamename) %>%
- mutate(since_release = 11:0, .after = month)
+# This code is sufficient since the data is in reverse chronological order.
+borderlands <- borderlands %>%
+ group_by(gamename) %>%
+ mutate(since_release = 11:0, .after = month)
borderlands
@@ -3179,8 +5646,16 @@ lineribbons with geomtextpath.
-borderlands %>%
- summarise(quantile = quantile(peak))
+borderlands %>%
+ summarise(quantile = quantile(peak))
@@ -3192,13 +5667,73 @@ lineribbons with geomtextpath.
-borderlands <- borderlands %>%
- mutate(rarity = case_when(
- between(peak, 0, 19999) ~ "white",
- between(peak, 20000, 39999) ~ "green",
- between(peak, 40000, 59999) ~ "blue",
- between(peak, 60000, 79999) ~ "purple",
- between(peak, 80000, 150000) ~ "orange"
+borderlands <- borderlands %>%
+ mutate(rarity = case_when(
+ between(peak, 0, 19999) ~ "white",
+ between(peak, 20000, 39999) ~ "green",
+ between(peak, 40000, 59999) ~ "blue",
+ between(peak, 60000, 79999) ~ "purple",
+ between(peak, 80000, 150000) ~ "orange"
))
@@ -3208,23 +5743,123 @@ lineribbons with geomtextpath.
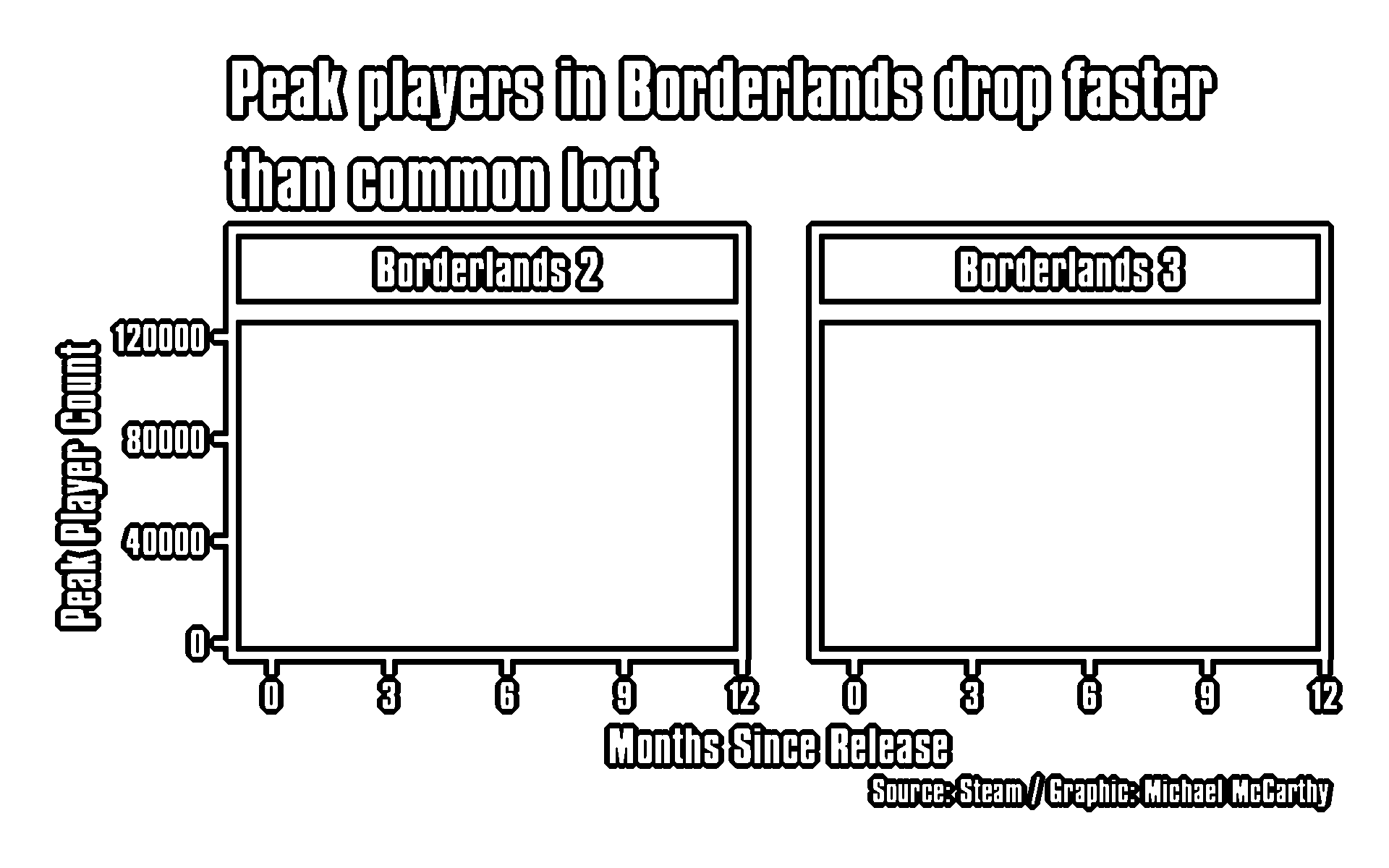
-outline_plot <- ggplot(borderlands, aes(since_release, peak)) +
- facet_wrap(vars(gamename)) +
- labs(
- x = "Months Since Release",
- y = "Peak Player Count",
- title = "Peak players in Borderlands drop faster\nthan common loot",
- caption = "Source: Steam / Graphic: Michael McCarthy"
- ) +
- theme_bw() +
- theme(
- text = element_text(family = "Compacta Bold", colour = "black"),
- axis.text = element_text(colour = "black"),
- axis.line = element_blank(),
- panel.grid.major = element_blank(),
- panel.grid.minor = element_blank(),
- panel.border = element_rect(colour = "black", fill = NA),
- strip.background = element_rect(fill = "white", colour = "black")
+outline_plot <- ggplot(borderlands, aes(since_release, peak)) +
+ facet_wrap(vars(gamename)) +
+ labs(
+ x = "Months Since Release",
+ y = "Peak Player Count",
+ title = "Peak players in Borderlands drop faster\nthan common loot",
+ caption = "Source: Steam / Graphic: Michael McCarthy"
+ ) +
+ theme_bw() +
+ theme(
+ text = element_text(family = "Compacta Bold", colour = "black"),
+ axis.text = element_text(colour = "black"),
+ axis.line = element_blank(),
+ panel.grid.major = element_blank(),
+ panel.grid.minor = element_blank(),
+ panel.border = element_rect(colour = "black", fill = NA),
+ strip.background = element_rect(fill = "white", colour = "black")
)
outline_plot
@@ -3234,28 +5869,140 @@ lineribbons with geomtextpath.
-blue <- "#08283c"
-light_blue <- "#115190"
-baby_blue <- "#a7e5ff"
-indigo <- "#cef8ff"
+blue <- "#08283c"
+light_blue <- "#115190"
+baby_blue <- "#a7e5ff"
+indigo <- "#cef8ff"
-colour_plot <- outline_plot +
- theme(
- text = element_text(colour = "white"),
- # Axis
- axis.text = element_text(colour = indigo),
- axis.ticks = element_line(colour = light_blue),
- # Panel
- panel.grid.major.y = element_line(colour = light_blue),
- panel.grid.minor.y = element_line(colour = light_blue),
- panel.border = element_rect(colour = light_blue, fill = NA),
- panel.background = element_rect(fill = blue, colour = light_blue),
- # Plot
- plot.title = element_text(colour = "#fff01a"),
- plot.background = element_rect(fill = "pink"),
- # Strip
- strip.text = element_text(colour = baby_blue),
- strip.background = element_rect(fill = "#00378f", colour = light_blue)
+colour_plot <- outline_plot +
+ theme(
+ text = element_text(colour = "white"),
+ # Axis
+ axis.text = element_text(colour = indigo),
+ axis.ticks = element_line(colour = light_blue),
+ # Panel
+ panel.grid.major.y = element_line(colour = light_blue),
+ panel.grid.minor.y = element_line(colour = light_blue),
+ panel.border = element_rect(colour = light_blue, fill = NA),
+ panel.background = element_rect(fill = blue, colour = light_blue),
+ # Plot
+ plot.title = element_text(colour = "#fff01a"),
+ plot.background = element_rect(fill = "pink"),
+ # Strip
+ strip.text = element_text(colour = baby_blue),
+ strip.background = element_rect(fill = "#00378f", colour = light_blue)
)
colour_plot
@@ -3265,102 +6012,732 @@ lineribbons with geomtextpath.
-# Create plot used for the outline
-file <- tempfile(fileext = '.png')
-ragg::agg_png(file, width = 1920, height = 1200, res = 300, units = "px", scaling = 0.5)
-outline_plot +
- geom_col(fill = "white") +
- stat_ccdfinterval(fill = "white", point_alpha = 0) +
- theme(
- # Axis
- axis.title = element_text(size = 36),
- axis.text = element_text(size = 28),
- axis.text.x = element_text(margin = margin(5, 0, 5, 0, "pt")),
- axis.text.y = element_text(margin = margin(0, 5, 0, 5, "pt")),
- axis.line = element_line(size = 0),
- axis.ticks = element_line(size = 2),
- axis.ticks.length = unit(10, "pt"),
- # Panel
- panel.border = element_rect(size = 0),
- panel.background = element_rect(colour = "black", size = 5),
- panel.spacing = unit(3, "lines"),
- # Plot
- plot.title = element_text(size = 56),
- plot.margin = unit(c(40, 40, 40, 40), "pt"),
- # Strip
- strip.text = element_text(size = 36, margin = margin(0.5,0,0.5,0, "cm")),
- strip.background = element_rect(size = 5),
- # Caption
- plot.caption = element_text(size = 24)
+# Create plot used for the outline
+file <- tempfile(fileext = '.png')
+ragg::agg_png(file, width = 1920, height = 1200, res = 300, units = "px", scaling = 0.5)
+outline_plot +
+ geom_col(fill = "white") +
+ stat_ccdfinterval(fill = "white", point_alpha = 0) +
+ theme(
+ # Axis
+ axis.title = element_text(size = 36),
+ axis.text = element_text(size = 28),
+ axis.text.x = element_text(margin = margin(5, 0, 5, 0, "pt")),
+ axis.text.y = element_text(margin = margin(0, 5, 0, 5, "pt")),
+ axis.line = element_line(size = 0),
+ axis.ticks = element_line(size = 2),
+ axis.ticks.length = unit(10, "pt"),
+ # Panel
+ panel.border = element_rect(size = 0),
+ panel.background = element_rect(colour = "black", size = 5),
+ panel.spacing = unit(3, "lines"),
+ # Plot
+ plot.title = element_text(size = 56),
+ plot.margin = unit(c(40, 40, 40, 40), "pt"),
+ # Strip
+ strip.text = element_text(size = 36, margin = margin(0.5,0,0.5,0, "cm")),
+ strip.background = element_rect(size = 5),
+ # Caption
+ plot.caption = element_text(size = 24)
)
-invisible(dev.off())
+invisible(dev.off())
For the actual post-processing, I detect the edges of all the plot elements, then dilate them outwards. Finally the white areas in the plot are made transparent, so all that’s left is the black outlines. To demonstrate, I’ve created a blank white image here and flattened the outline plot on top of it.
-plot_outline_layer <- image_read(file) %>%
- image_convert(type="Grayscale") %>%
- image_negate() %>%
- image_threshold("white", "5%") %>%
- image_morphology('EdgeOut', "Diamond", iterations = 6) %>%
- image_morphology('Dilate', "Diamond", iterations = 1) %>%
- image_negate() %>%
- image_transparent("white", fuzz = 7)
+plot_outline_layer <- image_read(file) %>%
+ image_convert(type="Grayscale") %>%
+ image_negate() %>%
+ image_threshold("white", "5%") %>%
+ image_morphology('EdgeOut', "Diamond", iterations = 6) %>%
+ image_morphology('Dilate', "Diamond", iterations = 1) %>%
+ image_negate() %>%
+ image_transparent("white", fuzz = 7)
-image_flatten(c(image_blank(1920, 1200, color = "white"), plot_outline_layer))
+image_flatten(c(image_blank(1920, 1200, color = "white"), plot_outline_layer))
Next the colour plot, which just needs to be scaled up with the bars added to it, then saved to a temporary file. Here I’ve used CCDF bars with a gradient, courtesy of the ggdist package, going from black to colour to match the gradients in the ECHO-3 in-game menu in Borderlands 3. It’s a bit tacky, and there isn’t an easy way to add gradients to any other plot elements, but it fits the theme.
-file <- tempfile(fileext = '.png')
-ragg::agg_png(file, width = 1920, height = 1200, res = 300, units = "px", scaling = 0.5)
-colour_plot +
- # First a solid fill column
- geom_col(aes(fill = rarity)) +
- # Then use a ccdfinterval to create a vertical gradient over top the solid
- # fill
- stat_ccdfinterval(
- aes(fill = rarity, fill_ramp = stat(y)),
- fill_type = "gradient",
- show.legend = FALSE,
- point_alpha = 0
- ) +
- scale_fill_identity() +
- scale_fill_ramp_continuous(
- from = "black",
- range = c(0.8, 1),
- limits = c(0, 15000)
- ) +
- expand_limits(y = 0) +
- # Finally add a black outline over top of everything
- geom_col(fill = NA, colour = "black", size = 1) +
- theme(
- # Axis
- axis.title = element_text(size = 36),
- axis.text = element_text(size = 28),
- axis.text.x = element_text(margin = margin(5, 0, 5, 0, "pt")),
- axis.text.y = element_text(margin = margin(0, 5, 0, 5, "pt")),
- axis.line = element_line(size = 0),
- axis.ticks = element_line(size = 2),
- axis.ticks.length = unit(10, "pt"),
- # Panel
- panel.border = element_rect(size = 0),
- panel.background = element_rect(size = 5),
- panel.spacing = unit(3, "lines"),
- # Plot
- plot.title = element_text(size = 56),
- plot.margin = unit(c(40, 40, 40, 40), "pt"),
- plot.background = element_rect(fill = "pink"),
- # Strip
- strip.text = element_text(size = 36, margin = margin(0.5,0,0.5,0, "cm")),
- strip.background = element_rect(size = 5),
- # Caption
- plot.caption = element_text(size = 24)
+file <- tempfile(fileext = '.png')
+ragg::agg_png(file, width = 1920, height = 1200, res = 300, units = "px", scaling = 0.5)
+colour_plot +
+ # First a solid fill column
+ geom_col(aes(fill = rarity)) +
+ # Then use a ccdfinterval to create a vertical gradient over top the solid
+ # fill
+ stat_ccdfinterval(
+ aes(fill = rarity, fill_ramp = stat(y)),
+ fill_type = "gradient",
+ show.legend = FALSE,
+ point_alpha = 0
+ ) +
+ scale_fill_identity() +
+ scale_fill_ramp_continuous(
+ from = "black",
+ range = c(0.8, 1),
+ limits = c(0, 15000)
+ ) +
+ expand_limits(y = 0) +
+ # Finally add a black outline over top of everything
+ geom_col(fill = NA, colour = "black", size = 1) +
+ theme(
+ # Axis
+ axis.title = element_text(size = 36),
+ axis.text = element_text(size = 28),
+ axis.text.x = element_text(margin = margin(5, 0, 5, 0, "pt")),
+ axis.text.y = element_text(margin = margin(0, 5, 0, 5, "pt")),
+ axis.line = element_line(size = 0),
+ axis.ticks = element_line(size = 2),
+ axis.ticks.length = unit(10, "pt"),
+ # Panel
+ panel.border = element_rect(size = 0),
+ panel.background = element_rect(size = 5),
+ panel.spacing = unit(3, "lines"),
+ # Plot
+ plot.title = element_text(size = 56),
+ plot.margin = unit(c(40, 40, 40, 40), "pt"),
+ plot.background = element_rect(fill = "pink"),
+ # Strip
+ strip.text = element_text(size = 36, margin = margin(0.5,0,0.5,0, "cm")),
+ strip.background = element_rect(size = 5),
+ # Caption
+ plot.caption = element_text(size = 24)
)
-invisible(dev.off())
+invisible(dev.off())
-plot_fill_layer <- image_read(file)
+plot_fill_layer <- image_read(file)
plot_fill_layer
@@ -3369,8 +6746,22 @@ lineribbons with geomtextpath.
-plot_layer <- image_composite(plot_fill_layer, plot_outline_layer) %>%
- image_transparent("pink", fuzz = 7)
+plot_layer <- image_composite(plot_fill_layer, plot_outline_layer) %>%
+ image_transparent("pink", fuzz = 7)
plot_layer
@@ -3379,12 +6770,38 @@ lineribbons with geomtextpath.
-background_layer <- image_read(
- here("posts", "2022-09-29_borderlands", "images", "plot-background.png")
-) %>%
- image_colorize(50, "black")
+background_layer <- image_read(
+ here("posts", "2022-09-29_borderlands", "images", "plot-background.png")
+) %>%
+ image_colorize(50, "black")
-final_graphic <- image_composite(background_layer, plot_layer)
+final_graphic <- image_composite(background_layer, plot_layer)
This plot isn’t going to win any awards (unless it’s for an ugly plots contest), but it does show that you can do some pretty cool programmatic image processing of your plots (or any other images) with the magick package.
@@ -3402,7 +6819,7 @@ lineribbons with geomtextpath.
+
@@ -3417,7 +6834,7 @@ lineribbons with geomtextpath. consulting services, and my other projects on my personal website.
- Comments
+Comments
@@ -3426,7 +6843,7 @@ lineribbons with geomtextpath. Session Info
+Session Info
@@ -3473,26 +6890,19 @@ lineribbons with geomtextpath. Data
+Data
Download the data used in this post.
-Fair Dealing
+Fair Dealing
Any of the trademarks, service marks, collective marks, design rights or similar rights that are mentioned, used, or cited in this article are the property of their respective owners. They are used here as fair dealing for the purpose of education in accordance with section 29 of the Copyright Act and do not infringe copyright.
-Citation
BibTeX citation:@online{mccarthy2022,
- author = {Michael McCarthy},
- title = {Tales from the {Borderlands}},
- date = {2022-09-29},
- url = {https://tidytales.ca/posts/2022-09-29_borderlands},
- langid = {en}
-}
-
For attribution, please cite this work as:
-Michael McCarthy. (2022, September 29). Tales from the
-Borderlands. https://tidytales.ca/posts/2022-09-29_borderlands
+Citation
For attribution, please cite this work as:
+McCarthy, M. (2022, September 29). Tales from the Borderlands.
+https://tidytales.ca/posts/2022-09-29_borderlands
.Wrangle
.Visualize
@@ -3520,7 +6930,7 @@ Borderlands. ht
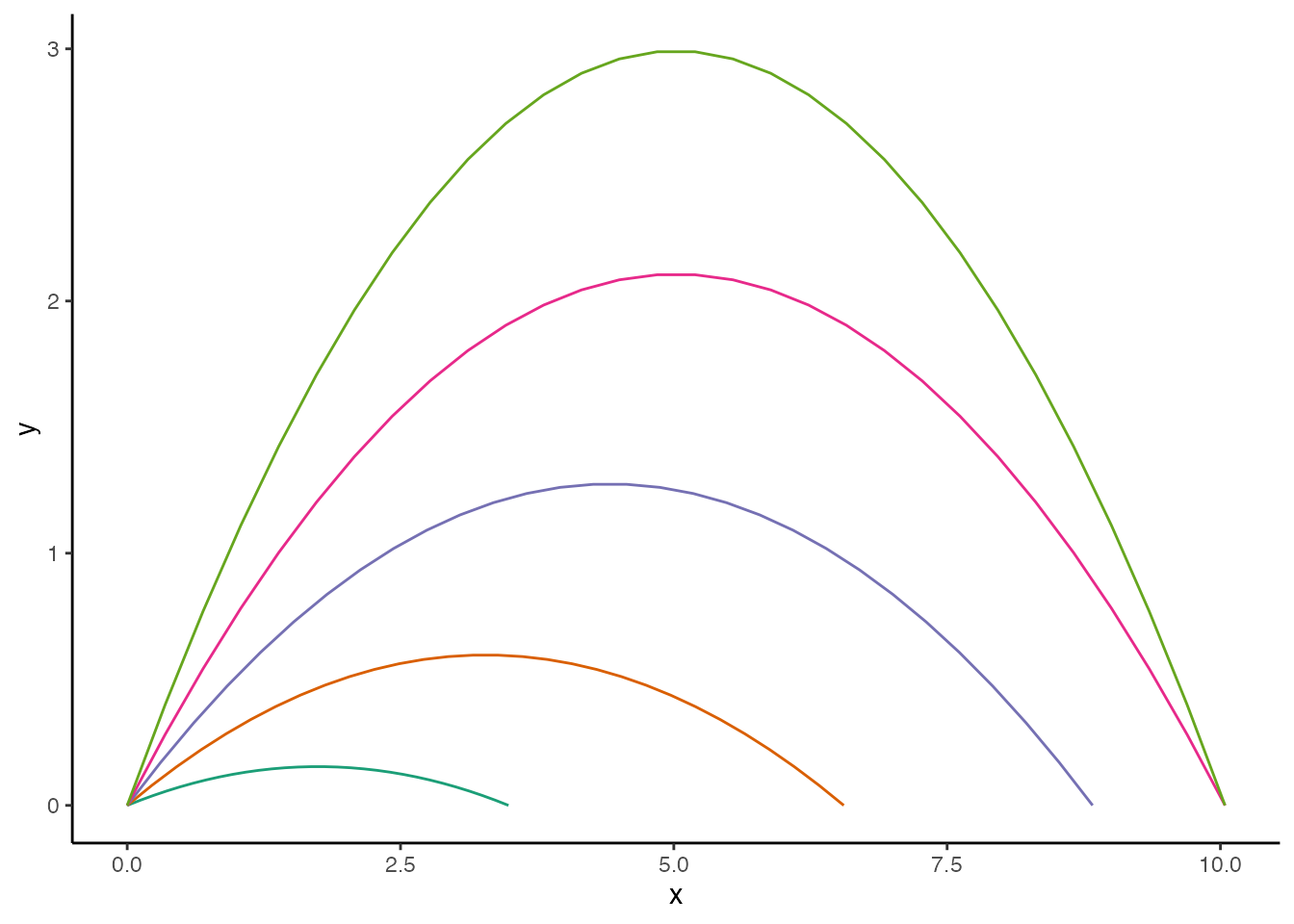
-Projectile motion of an object launched at the same height and velocity but different angles. The symmetrical U-shaped curve of each trajectory is known as a parabola.
+Projectile motion of an object launched at the same height and velocity but different angles. The symmetrical U-shaped curve of each trajectory is known as a parabola.
@@ -3541,12 +6951,24 @@ Borderlands. ht
Prerequisites
-library(tidyverse)
-library(gganimate)
-library(ggh4x)
-library(formattable)
-library(emojifont)
-library(glue)
+library(tidyverse)
+library(gganimate)
+library(ggh4x)
+library(formattable)
+library(emojifont)
+library(glue)
I’ll be simulating data for my plot by turning the equations for projectile motion into R functions. You can download this data with the Data Source link in the appendix. The sources I used for the equations can also be found in the appendix.
@@ -3560,16 +6982,52 @@ Borderlands. ht
,%20%5Ctextrm%7B%20and%7D%20%5C%5C%0AV_y%20&=%20V%20%5Ctimes%20%5Csin(%5Calpha),%0A%5Cend%7Balign*%7D%0A)
where 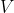 is the initial velocity and
is the initial velocity and 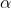 is the launch angle. Horizontal and vertical velocity can be computed in R with the following functions.
is the launch angle. Horizontal and vertical velocity can be computed in R with the following functions.
-velocity_x <- function(velocity, angle) {
- # Degrees need to be converted to radians in cos() since that is what the
- # function uses
- velocity * cos(angle * (pi/180))
+velocity_x <- function(velocity, angle) {
+ # Degrees need to be converted to radians in cos() since that is what the
+ # function uses
+ velocity * cos(angle * (pi/180))
}
-velocity_y <- function(velocity, angle) {
- # Degrees need to be converted to radians in sin() since that is what the
- # function uses
- velocity * sin(angle * (pi/180))
+velocity_y <- function(velocity, angle) {
+ # Degrees need to be converted to radians in sin() since that is what the
+ # function uses
+ velocity * sin(angle * (pi/180))
}
@@ -3579,8 +7037,34 @@ Borderlands. ht
%20%5Cdiv%20g,%0A)
where  is the vertical velocity,
is the vertical velocity, 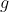 is the force of gravity, and
is the force of gravity, and 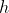 , is the initial height the object is launched from. Time of flight is the time from when the object is launched to the time the object reaches the surface. It can be computed in R with the following function.
, is the initial height the object is launched from. Time of flight is the time from when the object is launched to the time the object reaches the surface. It can be computed in R with the following function.
-flight_time <- function(velocity_y, height, gravity = 9.80665) {
- ( velocity_y + sqrt(velocity_y^2 + 2 * gravity * height) ) / gravity
+flight_time <- function(velocity_y, height, gravity = 9.80665) {
+ ( velocity_y + sqrt(velocity_y^2 + 2 * gravity * height) ) / gravity
}
@@ -3590,8 +7074,36 @@ Borderlands. ht

where  is the horizontal velocity and
is the horizontal velocity and 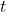 is the time of flight. The range of the projectile is the total horizontal distance travelled during the time of flight. It can be computed in R with the following function.
is the time of flight. The range of the projectile is the total horizontal distance travelled during the time of flight. It can be computed in R with the following function.
-distance <- function(velocity_x, velocity_y, height, gravity = 9.80665) {
- velocity_x * ( velocity_y + sqrt(velocity_y^2 + 2 * gravity * height) ) /
+distance <- function(velocity_x, velocity_y, height, gravity = 9.80665) {
+ velocity_x * ( velocity_y + sqrt(velocity_y^2 + 2 * gravity * height) ) /
gravity
}
@@ -3602,8 +7114,28 @@ Borderlands. ht
,%0A)
where is the initial height, is the vertical velocity, and is the force of gravity. The maximum height is reached when  . It can be computed in R with the following function.
. It can be computed in R with the following function.
-height_max <- function(velocity_y, height, gravity = 9.80665) {
- height + velocity_y^2 / (2 * gravity)
+height_max <- function(velocity_y, height, gravity = 9.80665) {
+ height + velocity_y^2 / (2 * gravity)
}
@@ -3611,57 +7143,221 @@ Borderlands. ht
Projectile motion calculator
Now to wrap all the components into a single function that will calculate the result for each component based on a set of parameters given to it. These results can then be used to determine the position and velocity of the projectile at any point in time during its trajectory, which I want to return as a data frame that can be used for plotting.
-#' nframes and fps can be used to animate the trajectory as close to real time as possible.
-#' There will be some rounding error though so it won't be exactly the same as the flight
-#' time.
-projectile_motion <- function(velocity, angle, height, gravity = 9.80665, nframes = 30) {
+#' nframes and fps can be used to animate the trajectory as close to real time as possible.
+#' There will be some rounding error though so it won't be exactly the same as the flight
+#' time.
+projectile_motion <- function(velocity, angle, height, gravity = 9.80665, nframes = 30) {
- # Velocity components
- vx <- velocity_x(velocity, angle)
- vy <- velocity_y(velocity, angle)
- # Flight components
- t <- flight_time(vy, height, gravity)
- d <- distance(vx, vy, height, gravity)
- # Max height components
- hm <- height_max(vy, height, gravity)
- th <- vy / gravity
- hd <- vx * th
+ # Velocity components
+ vx <- velocity_x(velocity, angle)
+ vy <- velocity_y(velocity, angle)
+ # Flight components
+ t <- flight_time(vy, height, gravity)
+ d <- distance(vx, vy, height, gravity)
+ # Max height components
+ hm <- height_max(vy, height, gravity)
+ th <- vy / gravity
+ hd <- vx * th
- # Calculate the position of the projectile in 2D space at a given point in
- # time to approximate its trajectory over time
- x_pos <- map_dbl(seq(0, t, length = nframes), ~ {
- vx * .x
+ # Calculate the position of the projectile in 2D space at a given point in
+ # time to approximate its trajectory over time
+ x_pos <- map_dbl(seq(0, t, length = nframes), ~ {
+ vx * .x
})
- y_pos <- map_dbl(seq(0, t, length = nframes), ~ {
- height + ( vy * .x + 0.5 * -gravity * .x^2 )
+ y_pos <- map_dbl(seq(0, t, length = nframes), ~ {
+ height + ( vy * .x + 0.5 * -gravity * .x^2 )
})
- # Calculate the vertical velocity of the projectile at a given point in time
- vy_t <- map_dbl(seq(0, t, length = nframes), ~ {
- vy - gravity * .x
+ # Calculate the vertical velocity of the projectile at a given point in time
+ vy_t <- map_dbl(seq(0, t, length = nframes), ~ {
+ vy - gravity * .x
})
- trajectory <- data.frame(
- x = x_pos,
- y = y_pos,
- vx = vx,
- vy = vy_t,
- second = seq(0, t, length = nframes)
+ trajectory <- data.frame(
+ x = x_pos,
+ y = y_pos,
+ vx = vx,
+ vy = vy_t,
+ second = seq(0, t, length = nframes)
)
- # Return a list with all calculated values
- list(
- velocity_x = vx,
- velocity_y = vy,
- flight_time = t,
- distance = d,
- max_height = hm,
- max_height_time = th,
- max_height_dist = hd,
- trajectory = trajectory,
- nframes = nframes,
- fps = nframes/t
+ # Return a list with all calculated values
+ list(
+ velocity_x = vx,
+ velocity_y = vy,
+ flight_time = t,
+ distance = d,
+ max_height = hm,
+ max_height_time = th,
+ max_height_dist = hd,
+ trajectory = trajectory,
+ nframes = nframes,
+ fps = nframes/t
)
}
@@ -3682,11 +7378,29 @@ Borderlands. ht
nframes which represents how many points in time to record in the trajectory data frame.projectile_motion(
- velocity = 11.4,
- angle = 52.1,
- height = 18,
- nframes = 10
+projectile_motion(
+ velocity = 11.4,
+ angle = 52.1,
+ height = 18,
+ nframes = 10
)
#> $velocity_x
@@ -3742,45 +7456,165 @@ Borderlands. ht
Given the inspiration for this post, a space themed simulation seems appropriate. Here I want to test how the gravity of each planet in our solar system influences projectile motion, given a projectile is launched with the same velocity, angle, and height.
First I need to construct a named vector of the gravity of each planet in our solar system. NASA provides these values came as ratios of each planet’s gravity relative to Earth, so I had to multiply each one by Earth’s gravity to get the units correct.
-# All values are in metres per second
-planets <- c(
- mercury = 3.7069137,
- venus = 8.8946315,
- earth = 9.80665,
- moon = 1.6279039,
- mars = 3.697107,
- jupiter = 23.143694,
- saturn = 8.9828914,
- uranus = 8.7181118,
- neptune = 10.983448,
- pluto = 0.6962721
+# All values are in metres per second
+planets <- c(
+ mercury = 3.7069137,
+ venus = 8.8946315,
+ earth = 9.80665,
+ moon = 1.6279039,
+ mars = 3.697107,
+ jupiter = 23.143694,
+ saturn = 8.9828914,
+ uranus = 8.7181118,
+ neptune = 10.983448,
+ pluto = 0.6962721
)
Then I can create a named list of projectile motion calculations, one for each planet. Each planet has its own list of output from projectile_motion(), so the resulting list of projectile motion calculations is actually a list of lists. This can be tidied into a tibble to make it easier to work with.
-# Calculate projectile motion for each planet, given the same velocity,
-# angle, and height
-planets_pm <- map(planets, ~{
- projectile_motion(
- velocity = 20,
- angle = 45,
- height = 35,
- gravity = .x,
- nframes = 100)
+# Calculate projectile motion for each planet, given the same velocity,
+# angle, and height
+planets_pm <- map(planets, ~{
+ projectile_motion(
+ velocity = 20,
+ angle = 45,
+ height = 35,
+ gravity = .x,
+ nframes = 100)
})
-# Tidying the list of lists into a tibble makes it easier to work with. Note
-# that the trajectory column is a list column since it contains the trajectory
-# data frame for each planet.
-planets_df <- planets_pm %>%
- enframe() %>%
- unnest_wider(value) %>%
- rename(planet = name)
+# Tidying the list of lists into a tibble makes it easier to work with. Note
+# that the trajectory column is a list column since it contains the trajectory
+# data frame for each planet.
+planets_df <- planets_pm %>%
+ enframe() %>%
+ unnest_wider(value) %>%
+ rename(planet = name)
-planets_trajectory <- planets_df %>%
- select(planet, trajectory) %>%
- unnest(trajectory) %>%
- mutate(planet = factor(planet, levels = names(planets)))
+planets_trajectory <- planets_df %>%
+ select(planet, trajectory) %>%
+ unnest(trajectory) %>%
+ mutate(planet = factor(planet, levels = names(planets)))
@@ -3791,110 +7625,393 @@ Borderlands. ht
A simple trajectory
This is the same simple trajectory I showed the output for earlier, only with more frames to make the animation smoother.
-simple_trajectory <- projectile_motion(
- velocity = 11.4,
- angle = 52.1,
- height = 18,
- nframes = 100
+simple_trajectory <- projectile_motion(
+ velocity = 11.4,
+ angle = 52.1,
+ height = 18,
+ nframes = 100
)
-# Assign the data frame and max height parameters to objects to make the plot
-# code easier to read
-df <- simple_trajectory$trajectory
-max_height_dist <- simple_trajectory$max_height_dist
-max_height_time <- simple_trajectory$max_height_time
-max_height <- simple_trajectory$max_height
+# Assign the data frame and max height parameters to objects to make the plot
+# code easier to read
+df <- simple_trajectory$trajectory
+max_height_dist <- simple_trajectory$max_height_dist
+max_height_time <- simple_trajectory$max_height_time
+max_height <- simple_trajectory$max_height
I’m going to build the plot for this simple trajectory up in chunks to make the code easier to understand. The foundation of the plot is fairly standard. The only unusual thing here are the group aesthetics in geom_line() and geom_point(). These are used to tell gganimate which rows in the data correspond to the same graphic element.
-p <- ggplot(df, aes(x = x, y = y)) +
- geom_line(
- aes(group = 1),
- linetype = "dashed",
- colour = "red",
- alpha = 0.5
- ) +
- geom_point(aes(group = 1), size = 2)
+p <- ggplot(df, aes(x = x, y = y)) +
+ geom_line(
+ aes(group = 1),
+ linetype = "dashed",
+ colour = "red",
+ alpha = 0.5
+ ) +
+ geom_point(aes(group = 1), size = 2)
For the data I simulated, the projectile starts with a positive vertical velocity. However, at its maximum height, the vertical velocity of the projectile becomes 0 m/s for a brief moment, as it stops rising and starts falling. This happens Because gravity is constantly influencing the vertical velocity of the projectile. This is an important and interesting piece of information I want to communicate in my plot. This can be accomplished subtly by displaying the vertical velocity of the projectile at each point in time, or more overtly using a text annotation. I’m going to do both.
First the text annotation. I’m using geom_curve() to draw an arrow between the annotation and the point at which the projectile is at its maximum height, and geom_text() to draw the annotation. I’ve supplied each geom with its own data frame containing a second column whose sole value corresponds to the time the projectile reaches its maximum height. This will control when the annotation appears in the animation. I’ve also given the pair a different group aesthetic from geom_line() and geom_point().
-p <- p +
- geom_curve(
- data = data.frame(
- second = max_height_time
+p <- p +
+ geom_curve(
+ data = data.frame(
+ second = max_height_time
),
- aes(
- xend = max_height_dist,
- yend = max_height + 0.2,
- x = max_height_dist + 2,
- y = max_height + 2,
- group = 2
+ aes(
+ xend = max_height_dist,
+ yend = max_height + 0.2,
+ x = max_height_dist + 2,
+ y = max_height + 2,
+ group = 2
),
- curvature = 0.45,
- angle = 105,
- ncp = 15,
- arrow = arrow(length = unit(0.1,"cm"), type = "closed")
- ) +
- geom_text(
- data = data.frame(
- second = max_height_time
+ curvature = 0.45,
+ angle = 105,
+ ncp = 15,
+ arrow = arrow(length = unit(0.1,"cm"), type = "closed")
+ ) +
+ geom_text(
+ data = data.frame(
+ second = max_height_time
),
- aes(
- x = max_height_dist + 2.4,
- y = max_height + 2,
- group = 2
+ aes(
+ x = max_height_dist + 2.4,
+ y = max_height + 2,
+ group = 2
),
- hjust = "left",
- lineheight = 1,
- family = "serif",
- label = str_c(
- "At its maximum height, the vertical velocity \n",
- "of the projectile is 0 m/s for a brief moment, \n",
- "as it stops rising and starts falling."
+ hjust = "left",
+ lineheight = 1,
+ family = "serif",
+ label = str_c(
+ "At its maximum height, the vertical velocity \n",
+ "of the projectile is 0 m/s for a brief moment, \n",
+ "as it stops rising and starts falling."
)
)
Second the vertical velocity. I’m displaying this in the plot’s subtitle along with the time elapsed since the projectile was launched. The displayed values are updated each frame using the value returned by the expression enclosed in glue braces for a frame. The variable frame_along is made available by gganimate::transition_along() (see below) and gives the position on the along-dimension (time in seconds in this case) that a frame corresponds to. Here I’m using frame_along to display the elapsed time, and to index the data frame df for the vertical velocity at a given second. The latter is a slight workaround because vy cannot be accessed directly in the glue braces.
-p <- p +
- labs(
- title = str_c(
- "Projectile motion of an object launched with ",
- #" <br> ",
- "a speed of 11.4 m/s at an angle of 52.1°"
+p <- p +
+ labs(
+ title = str_c(
+ "Projectile motion of an object launched with ",
+ #" <br> ",
+ "a speed of 11.4 m/s at an angle of 52.1°"
),
- subtitle = str_c(
- "Time: ",
- "{formattable(frame_along, digits = 2, format = 'f')}s",
- "\n",
- "Vertical velocity = ",
- "{formattable(df$vy[df$second == frame_along], digits = 2, format = 'f')}",
- " m/s"
+ subtitle = str_c(
+ "Time: ",
+ "{formattable(frame_along, digits = 2, format = 'f')}s",
+ "\n",
+ "Vertical velocity = ",
+ "{formattable(df$vy[df$second == frame_along], digits = 2, format = 'f')}",
+ " m/s"
),
- x = "Distance (m)",
- y = "Height (m)",
- caption = "Graphic: Michael McCarthy"
+ x = "Distance (m)",
+ y = "Height (m)",
+ caption = "Graphic: Michael McCarthy"
)
Now for theming. I wanted something minimalistic with a scientific feel—the classic theme paired with truncated axes courtesy of ggh4x does this nicely. Finally, I originally planned to use element_markdown() from ggtext to enable markdown text in the subtitle of the plot so that vertical velocity could be written like  ; however, this caused issues with the text spacing when rendering the animation to video, so I opted not to.1
; however, this caused issues with the text spacing when rendering the animation to video, so I opted not to.1
-p <- p +
- guides(x = "axis_truncated", y = "axis_truncated") +
- theme_classic(base_family = "serif")
+p <- p +
+ guides(x = "axis_truncated", y = "axis_truncated") +
+ theme_classic(base_family = "serif")
And finally, the animation code. Yes, that’s it. Animations can be tweaked and spiced up with other functions in gganimate, but I ran into issues making the ones I wanted to use work with transition_reveal().
Just a note: The behaviour of transition_reveal() shown here was broken in v1.0.8 of gganimate.
-anim <- p +
- transition_reveal(second)
+anim <- p +
+ transition_reveal(second)
anim
-
-
-

@@ -3903,88 +8020,405 @@ Borderlands. ht
Now to test how the gravity of each planet in our solar system influences projectile motion. As a reminder, I already simulated the projectile motion data in planets_trajectory, so now it’s just a matter of plotting it.
Since the simulation is space themed, the plot should be too. Instead of using a simple point to represent the projectile, I’m going to use Font Awesome’s rocket icon by way of the emojifont package. To make it extra, I’ll also add propulsion and rotation to the rocket’s animation.
-# Make it so the propulsion is only present for first half of animation, so it
-# looks like the rockets are launching.
-rocket_propulsion <- planets_trajectory %>%
- group_by(planet) %>%
- mutate(retain = rep(c(TRUE, FALSE), each = 50)) %>%
- ungroup() %>%
- mutate(x = case_when(
- retain == FALSE ~ NA_real_,
- TRUE ~ x
+# Make it so the propulsion is only present for first half of animation, so it
+# looks like the rockets are launching.
+rocket_propulsion <- planets_trajectory %>%
+ group_by(planet) %>%
+ mutate(retain = rep(c(TRUE, FALSE), each = 50)) %>%
+ ungroup() %>%
+ mutate(x = case_when(
+ retain == FALSE ~ NA_real_,
+ TRUE ~ x
))
The plotting code is mostly boilerplate, but I’ve added comments to highlight a few noteworthy points.
-p <- ggplot(planets_trajectory, aes(x = x, y = y)) +
- geom_line(
- aes(colour = planet, group = planet),
- linetype = "dashed",
- alpha = 0.5,
- # Change the key glyph in the legend to a point, to represent a planet
- key_glyph = "point"
- ) +
- geom_point(
- data = rocket_propulsion,
- aes(group = planet),
- colour = "orange"
- ) +
- # Change the angle at different frames to rotate the rocket
- geom_text(
- aes(colour = planet, group = planet, label = fontawesome("fa-rocket")),
- family='fontawesome-webfont',
- angle = rep(seq(0, 45, length = 100), 10),
- size = 6,
- # There is no rocket key glyph, so override this too
- key_glyph = "point"
- ) +
- scale_color_manual(
- values = c(
- "#97979F",
- "#BBB7AB",
- "#8CB1DE",
- "#DAD9D7",
- "#E27B58",
- "#C88B3A",
- "#C5AB6E",
- "#93B8BE",
- "#6081FF",
- "#4390BA"
+p <- ggplot(planets_trajectory, aes(x = x, y = y)) +
+ geom_line(
+ aes(colour = planet, group = planet),
+ linetype = "dashed",
+ alpha = 0.5,
+ # Change the key glyph in the legend to a point, to represent a planet
+ key_glyph = "point"
+ ) +
+ geom_point(
+ data = rocket_propulsion,
+ aes(group = planet),
+ colour = "orange"
+ ) +
+ # Change the angle at different frames to rotate the rocket
+ geom_text(
+ aes(colour = planet, group = planet, label = fontawesome("fa-rocket")),
+ family='fontawesome-webfont',
+ angle = rep(seq(0, 45, length = 100), 10),
+ size = 6,
+ # There is no rocket key glyph, so override this too
+ key_glyph = "point"
+ ) +
+ scale_color_manual(
+ values = c(
+ "#97979F",
+ "#BBB7AB",
+ "#8CB1DE",
+ "#DAD9D7",
+ "#E27B58",
+ "#C88B3A",
+ "#C5AB6E",
+ "#93B8BE",
+ "#6081FF",
+ "#4390BA"
)
- ) +
- labs(
- title = str_c(
- "projectile motion of an object launched on different planets in our solar system"
+ ) +
+ labs(
+ title = str_c(
+ "projectile motion of an object launched on different planets in our solar system"
),
- x = "distance (m)",
- y = "height (m)",
- caption = "graphic: michael mccarthy"
- ) +
- guides(
- x = "axis_truncated",
- y = "axis_truncated",
- colour = guide_legend(title.vjust = .7, nrow = 1, label.position = "bottom")
- ) +
- theme_classic(base_family = "mono") +
- theme(
- text = element_text(colour = "white"),
- axis.text = element_text(colour = "white"),
- rect = element_rect(fill = "black"),
- panel.background = element_rect(fill = "black"),
- axis.ticks = element_line(colour = "white"),
- axis.line = element_line(colour = "white"),
- legend.position = "top",
- legend.justification = "left"
+ x = "distance (m)",
+ y = "height (m)",
+ caption = "graphic: michael mccarthy"
+ ) +
+ guides(
+ x = "axis_truncated",
+ y = "axis_truncated",
+ colour = guide_legend(title.vjust = .7, nrow = 1, label.position = "bottom")
+ ) +
+ theme_classic(base_family = "mono") +
+ theme(
+ text = element_text(colour = "white"),
+ axis.text = element_text(colour = "white"),
+ rect = element_rect(fill = "black"),
+ panel.background = element_rect(fill = "black"),
+ axis.ticks = element_line(colour = "white"),
+ axis.line = element_line(colour = "white"),
+ legend.position = "top",
+ legend.justification = "left"
)
Finally, the animation code. The shadow_wake() function is applied to the orange points used for rocket propulsion to really sell the effect.
-anim <- p +
- transition_reveal(second) +
- shadow_wake(wake_length = 0.1, size = 2, exclude_layer = c(1, 3))
-
-
-
+anim <- p +
+ transition_reveal(second) +
+ shadow_wake(wake_length = 0.1, size = 2, exclude_layer = c(1, 3))

@@ -3994,7 +8428,7 @@ Borderlands. ht
-
+
@@ -4009,7 +8443,7 @@ Borderlands. ht
Thanks for reading! I’m Michael, the voice behind Tidy Tales. I am an award winning data scientist and R programmer with the skills and experience to help you solve the problems you care about. You can learn more about me, my consulting services, and my other projects on my personal website.
- Comments
+Comments
@@ -4018,7 +8452,7 @@ Borderlands. ht
-Session Info
+Session Info
@@ -4095,15 +8529,8 @@ Any of the trademarks, service marks, collective marks, design rights or similar
I didn’t look into it too deeply, but I’m guessing it’s related to this issue in ggtext. If you render to a gif instead you won’t have this issue and can use ggtext as normal.↩︎
-Citation
BibTeX citation:@online{mccarthy2022,
- author = {Michael McCarthy},
- title = {On Motion},
- date = {2022-06-16},
- url = {https://tidytales.ca/posts/2022-06-16_projectile-motion},
- langid = {en}
-}
-
For attribution, please cite this work as:
-Michael McCarthy. (2022, June 16). On motion. https://tidytales.ca/posts/2022-06-16_projectile-motion
+Citation
For attribution, please cite this work as:
+McCarthy, M. (2022, June 16). On motion. https://tidytales.ca/posts/2022-06-16_projectile-motion
.Simulate
.Visualize
@@ -4129,12 +8556,26 @@ Michael McCarthy. (2022, June 16). On motion. Prerequisites
To access the datasets, help pages, and functions that we will use in this code snippet, load the following packages:
-library(lavaan)
-library(semTools)
+library(lavaan)
+library(semTools)
And read in the data:
-social_exchanges <- read.csv(here("data", "2021-11-01_social-exchanges.csv"))
+social_exchanges <- read.csv(here("data", "2021-11-01_social-exchanges.csv"))
The data contains simulated values for several indicators of positive and negative social exchanges, measured on two occasions (w1 and w2). There are three continuous indicators that measure perceived companionship (vst1, vst2, vst3), and three binary indicators that measure unwanted advice (unw1, unw2, unw3). The data and some of the examples come from Longitudinal Structural Equation Modeling: A Comprehensive Introduction by Jason Newsom.
@@ -4142,70 +8583,208 @@ Michael McCarthy. (2022, June 16). On motion. Configural Invariance
Using the lavaan package.
-configural_model_lav <- ("
- # Measurement model
- w1comp =~ w1vst1 + w1vst2 + w1vst3
- w2comp =~ w2vst1 + w2vst2 + w2vst3
-
- # Variances and covariances
- w2comp ~~ w1comp
- w1comp ~~ w1comp
- w2comp ~~ w2comp
+configural_model_lav <- ("
+ # Measurement model
+ w1comp =~ w1vst1 + w1vst2 + w1vst3
+ w2comp =~ w2vst1 + w2vst2 + w2vst3
+
+ # Variances and covariances
+ w2comp ~~ w1comp
+ w1comp ~~ w1comp
+ w2comp ~~ w2comp
- w1vst1 ~~ w1vst1
- w1vst2 ~~ w1vst2
- w1vst3 ~~ w1vst3
- w2vst1 ~~ w2vst1
- w2vst2 ~~ w2vst2
- w2vst3 ~~ w2vst3
+ w1vst1 ~~ w1vst1
+ w1vst2 ~~ w1vst2
+ w1vst3 ~~ w1vst3
+ w2vst1 ~~ w2vst1
+ w2vst2 ~~ w2vst2
+ w2vst3 ~~ w2vst3
- w1vst1 ~~ w2vst1
- w1vst2 ~~ w2vst2
- w1vst3 ~~ w2vst3
-")
+ w1vst1 ~~ w2vst1
+ w1vst2 ~~ w2vst2
+ w1vst3 ~~ w2vst3
+")
-configural_model_lav_fit <- sem(configural_model_lav, data = social_exchanges)
+configural_model_lav_fit <- sem(configural_model_lav, data = social_exchanges)
Using the semTools package.
-# First, define the configural model, using the repeated measures factors and
-# indicators.
-configural_model_smt <- ("
- # Measurement model
- w1comp =~ w1vst1 + w1vst2 + w1vst3
- w2comp =~ w2vst1 + w2vst2 + w2vst3
-")
+# First, define the configural model, using the repeated measures factors and
+# indicators.
+configural_model_smt <- ("
+ # Measurement model
+ w1comp =~ w1vst1 + w1vst2 + w1vst3
+ w2comp =~ w2vst1 + w2vst2 + w2vst3
+")
-# Second, create a named list indicating which factors are actually the same
-# latent variable measured repeatedly.
-longitudinal_factor_names <- list(
- comp = c("w1comp", "w2comp")
+# Second, create a named list indicating which factors are actually the same
+# latent variable measured repeatedly.
+longitudinal_factor_names <- list(
+ comp = c("w1comp", "w2comp")
)
-# Third, generate the lavaan model syntax using semTools.
-configural_model_smt <- measEq.syntax(
- configural.model = configural_model_smt,
- longFacNames = longitudinal_factor_names,
- ID.fac = "std.lv",
- ID.cat = "Wu.Estabrook.2016",
- data = social_exchanges
+# Third, generate the lavaan model syntax using semTools.
+configural_model_smt <- measEq.syntax(
+ configural.model = configural_model_smt,
+ longFacNames = longitudinal_factor_names,
+ ID.fac = "std.lv",
+ ID.cat = "Wu.Estabrook.2016",
+ data = social_exchanges
)
-configural_model_smt <- as.character(configural_model_smt)
+configural_model_smt <- as.character(configural_model_smt)
-# Finally, fit the model using lavaan.
-configural_model_smt_fit <- sem(configural_model_smt, data = social_exchanges)
+# Finally, fit the model using lavaan.
+configural_model_smt_fit <- sem(configural_model_smt, data = social_exchanges)
Compare lavaan and semTools fit measures.
Configural invariance is met if the model fits well, indicators load on the same factors, and loadings are all of acceptable magnitude. An alternative way of testing longitudinal configural invariance is to fit separate confirmatory factor models at each time point; configural invariance is met if the previously stated criteria hold and the measure has the same factor structure at each time point.
-fitMeasures(configural_model_lav_fit, c("chisq", "df", "pvalue", "cfi", "rmsea"))
+fitMeasures(configural_model_lav_fit, c("chisq", "df", "pvalue", "cfi", "rmsea"))
#> chisq df pvalue cfi rmsea
#> 9.911 5.000 0.078 0.997 0.041
-fitMeasures(configural_model_smt_fit, c("chisq", "df", "pvalue", "cfi", "rmsea"))
+fitMeasures(configural_model_smt_fit, c("chisq", "df", "pvalue", "cfi", "rmsea"))
#> chisq df pvalue cfi rmsea
#> 9.911 5.000 0.078 0.997 0.041
@@ -4216,52 +8795,156 @@ Michael McCarthy. (2022, June 16). On motion. Weak Invariance
Using the lavaan package.
-weak_model_lav <- ("
- # Measurement model
- w1comp =~ w1vst1 + a*w1vst2 + b*w1vst3 # Factor loading equality constraint
- w2comp =~ w2vst1 + a*w2vst2 + b*w2vst3 # Factor loading equality constraint
+weak_model_lav <- ("
+ # Measurement model
+ w1comp =~ w1vst1 + a*w1vst2 + b*w1vst3 # Factor loading equality constraint
+ w2comp =~ w2vst1 + a*w2vst2 + b*w2vst3 # Factor loading equality constraint
- # Variances and covariances
- w2comp ~~ w1comp
- w1comp ~~ w1comp
- w2comp ~~ w2comp
+ # Variances and covariances
+ w2comp ~~ w1comp
+ w1comp ~~ w1comp
+ w2comp ~~ w2comp
- w1vst1 ~~ w1vst1
- w1vst2 ~~ w1vst2
- w1vst3 ~~ w1vst3
- w2vst1 ~~ w2vst1
- w2vst2 ~~ w2vst2
- w2vst3 ~~ w2vst3
+ w1vst1 ~~ w1vst1
+ w1vst2 ~~ w1vst2
+ w1vst3 ~~ w1vst3
+ w2vst1 ~~ w2vst1
+ w2vst2 ~~ w2vst2
+ w2vst3 ~~ w2vst3
- w1vst1 ~~ w2vst1
- w1vst2 ~~ w2vst2
- w1vst3 ~~ w2vst3
-")
+ w1vst1 ~~ w2vst1
+ w1vst2 ~~ w2vst2
+ w1vst3 ~~ w2vst3
+")
-weak_model_lav_fit <- sem(weak_model_lav, social_exchanges)
+weak_model_lav_fit <- sem(weak_model_lav, social_exchanges)
Using the semTools package.
-weak_model_smt <- measEq.syntax(
- configural.model = configural_model_smt,
- longFacNames = longitudinal_factor_names,
- ID.fac = "std.lv",
- ID.cat = "Wu.Estabrook.2016",
- long.equal = c("loadings"),
- data = social_exchanges
+weak_model_smt <- measEq.syntax(
+ configural.model = configural_model_smt,
+ longFacNames = longitudinal_factor_names,
+ ID.fac = "std.lv",
+ ID.cat = "Wu.Estabrook.2016",
+ long.equal = c("loadings"),
+ data = social_exchanges
)
-weak_model_smt <- as.character(weak_model_smt)
+weak_model_smt <- as.character(weak_model_smt)
-weak_model_smt_fit <- sem(weak_model_smt, data = social_exchanges)
+weak_model_smt_fit <- sem(weak_model_smt, data = social_exchanges)
Compare lavaan and semTools fit measures.
-fitMeasures(weak_model_lav_fit, c("chisq", "df", "pvalue", "cfi", "rmsea"))
+fitMeasures(weak_model_lav_fit, c("chisq", "df", "pvalue", "cfi", "rmsea"))
#> chisq df pvalue cfi rmsea
#> 12.077 7.000 0.098 0.997 0.036
-fitMeasures(weak_model_smt_fit, c("chisq", "df", "pvalue", "cfi", "rmsea"))
+fitMeasures(weak_model_smt_fit, c("chisq", "df", "pvalue", "cfi", "rmsea"))
#> chisq df pvalue cfi rmsea
#> 12.077 7.000 0.098 0.997 0.036
@@ -4269,7 +8952,9 @@ Michael McCarthy. (2022, June 16). On motion.
-lavTestLRT(configural_model_lav_fit, weak_model_lav_fit)
+lavTestLRT(configural_model_lav_fit, weak_model_lav_fit)
@@ -4287,46 +8972,140 @@ Michael McCarthy. (2022, June 16). On motion.
Equality tests of factor variances should only be conducted when all factor loadings also are constrained to be equal over time. When all non-referent loadings are set equal in the constrained model, the chi-square is the same regardless of the referent.
-strong_model_lav <- ("
- # Measurement model
- w1comp =~ w1vst1 + a*w1vst2 + b*w1vst3 # Factor loading equality constraint
- w2comp =~ w2vst1 + a*w2vst2 + b*w2vst3 # Factor loading equality constraint
+
Comments