
TNN:由腾讯优图实验室开源的高性能、轻量级神经网络推理框架,同时拥有跨平台、高性能、模型压缩、代码裁剪等众多突出优势。TNN框架在原有Rapidnet、ncnn框架的基础上进一步加强了移动端设备的支持以及性能优化,同时借鉴了业界主流开源框架高性能和良好拓展性的特性,拓展了对于后台X86, NV GPU的支持。手机端 TNN已经在手Q、微视、P图等众多应用中落地,服务端TNN作为腾讯云AI基础加速框架已为众多业务落地提供加速支持。欢迎大家参与协同共建,促进TNN推理框架进一步完善。
| 人脸检测(blazeface) | 物体检测(yolov5s) | 人脸配准(腾讯优图) | 头发分割(腾讯光影) |
|---|---|---|---|
 模型链接: tflite tnn |
 模型链接: onnx tnn |
 模型链接: tnn |
 模型链接: tnn |
| 姿势估计(腾讯光流) | 姿势估计(blazepose) | 中文字符识别 | 阅读理解 |
|---|---|---|---|
 模型链接: tnn |
 模型链接: tflite tnn |
 模型链接: onnx tnn |
 模型链接: onnx tnn |
中文字符识别demo是chineseocr_lite的TNN实现,是一个超轻量级的中文ocr,支持倾斜、旋转和竖排文字识别。
各个平台对demo的支持情况如下表所示,单击✅标记,便可以跳转至对应demo的入口代码。
| demo | ARM | OpenCL | Metal | Huawei NPU | Apple NPU | X86 | CUDA |
|---|---|---|---|---|---|---|---|
| 人脸检测 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 物体检测 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 人脸配准 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 头发分割 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 姿势估计(腾讯光流) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 姿势估计(blazepose) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 中文字符识别 | ✅ | ✅ | ✅ | ✅ | ✅ | ||
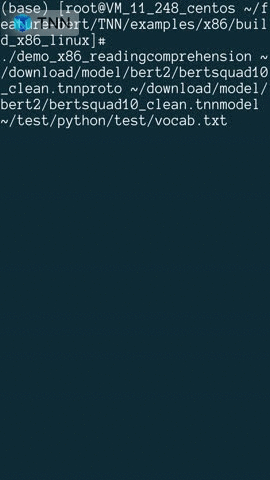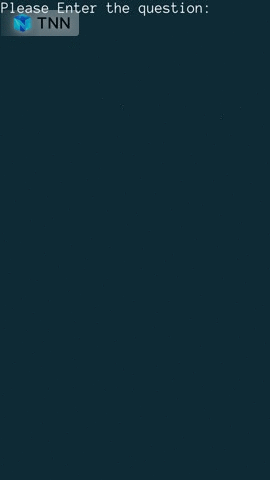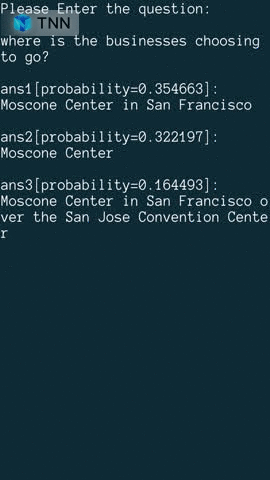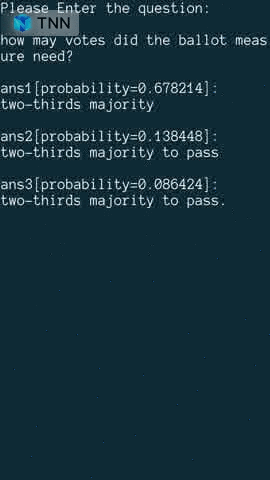
| 阅读理解 | ✅ | ✅ |
使用 TNN 非常简单,如果你有一个已经训练好的模型, 那么一般而言通过以下三个步骤就能完成模型在目标平台上的部署。
-
第一步是把训练好的模型转换成TNN的模型,为此我们提供了丰富的工具来帮助你完成这一步,无论你使用的是 TensorFlow、PyTorch、或者 Caffe,都可以轻松完成转换。 详细的手把手教程可以参见这里如何转换模型。
-
当你完成了模型的转换,第二步就是编译目标平台的 TNN 引擎了,你可以根据自己的目标平台的硬件支持情况,选择 CPU/ARM/OpenCL/Metal/NPU/X86/CUDA 等加速方案。 对于这些平台,TNN 都提供了一键编译的脚本,使用非常方便。详细步骤可以参考这里如何编译TNN。
-
最后一步就是使用编译好的 TNN 引擎进行推理,你可以在自己的应用程序中嵌入对 TNN 的调用,这方面我们提供了丰富而详实的 demo 来帮助你完成。
目前TNN具有的以下特性获得了广泛的好评。
-
计算优化
- 针对不同架构在硬件指令发射、吞吐、延迟、缓存带宽、缓存延迟、寄存器数量等特点,深度优化底层算子,极致利用硬件算力
- 主流硬件平台(CPU: ARMv7, ARMv8,X86 GPU: Mali, Adreno, Apple, NV GPU) 深度调优
- CNN 核心卷积运算通过 Winograd,Tile-GEMM, Direct Conv 等多种算法实现,保证不同参数、计算尺度下高效计算
- Op 融合:离线分析网络计算图,多个小 Op(计算量小、功能较简单)融合运算,减少反复内存读取、kernel 启动等开销
-
低精度优化
- 支持 INT8, FP16 低精度计算,减少模型大小、内存消耗,同时利用硬件低精度计算指令加速计算
- 支持 INT8 Winograd 算法,(输入6bit), 在精度满足要求的情况下,进一步降低模型计算复杂度
- 支持单模型多种精度混合计算,加速计算同时保证模型精度
-
内存优化
- 高效”内存池”实现:通过 DAG 网络计算图分析,实现无计算依赖的节点间复用内存,降低 90% 内存资源消耗
- 跨模型内存复用:支持外部实时指定用于网络内存,实现“多个模型,单份内存”。
-
主流模型实测性能:评测数据
-
TNN架构图:
-
通过 ONNX 支持 TensorFlow, PyTorch, MXNet, Caffe 等多种训练框架,充分利用和融入不断完善的 ONNX 开源生态。当前支持 ONNX 算子100+,覆盖主流CNN, NLP网络。
-
支持主流安卓、iOS、Embedded Linux 操作系统, Windows, Linux,支持 ARM CPU, x86, Mali GPU, Adreno GPU, NV GPU, 达芬奇NPU,RK NPU。
-
模块化设计,将模型解析、计算图构建、优化、底层硬件适配、高性能 kernel 实现各部分抽象隔离,通过 Factory Mode 注册、构建设备,方便接入更多的底层硬件、加速方案。
-
移动端动态库尺寸仅约 400KB,并提供基础图像变换操作,调用简单便捷。跨平台模型统一、调用接口统一,通过单个配置参数快速切换。

TNN参考和借鉴了下列项目:
-
欢迎大家参与,协同共建,打造业界最好的高性能推理框架。
-
技术交流 QQ 群: 913940506 答案:TNN
-
QQ 群二维码:
