![]() +
+ ![]()
 +
+ 
 +
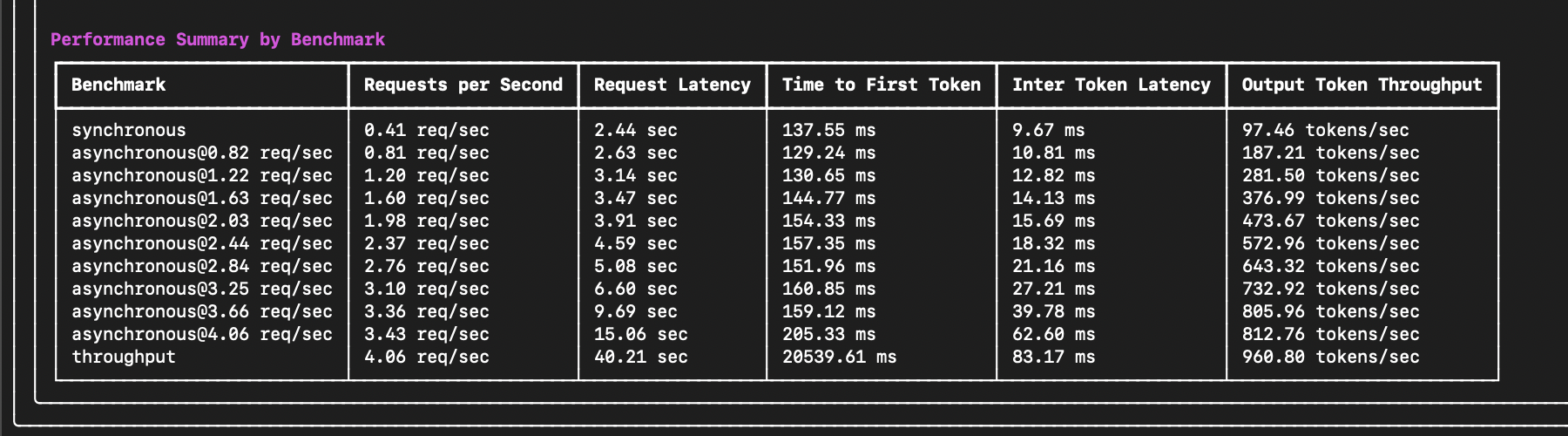
+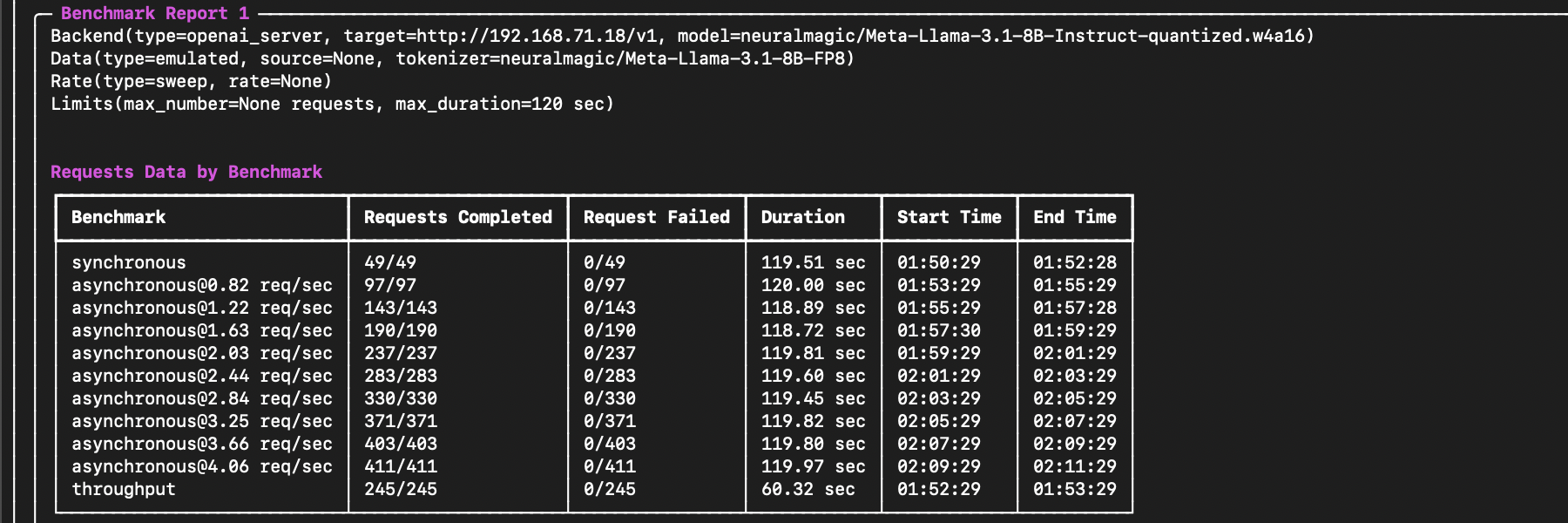 The end of the output will include important performance summary metrics such as request latency, time to first token (TTFT), inter-token latency (ITL), and more:
-
The end of the output will include important performance summary metrics such as request latency, time to first token (TTFT), inter-token latency (ITL), and more:
- +
+ #### 4. Use the Results
diff --git a/src/guidellm/core/report.py b/src/guidellm/core/report.py
index b6791e4..c48eed5 100644
--- a/src/guidellm/core/report.py
+++ b/src/guidellm/core/report.py
@@ -147,19 +147,15 @@ def _create_benchmark_report_data_tokens_summary(
for benchmark in report.benchmarks_sorted:
table.add_row(
_benchmark_rate_id(benchmark),
- f"{benchmark.prompt_token_distribution.mean:.2f}",
+ f"{benchmark.prompt_token:.2f}",
", ".join(
f"{percentile:.1f}"
- for percentile in benchmark.prompt_token_distribution.percentiles(
- [1, 5, 50, 95, 99]
- )
+ for percentile in benchmark.prompt_token_percentiles
),
- f"{benchmark.output_token_distribution.mean:.2f}",
+ f"{benchmark.output_token:.2f}",
", ".join(
f"{percentile:.1f}"
- for percentile in benchmark.output_token_distribution.percentiles(
- [1, 5, 50, 95, 99]
- )
+ for percentile in benchmark.output_token_percentiles
),
)
logger.debug("Created data tokens summary table for the report.")
@@ -181,7 +177,7 @@ def _create_benchmark_report_dist_perf_summary(
"Benchmark",
"Request Latency [1%, 5%, 10%, 50%, 90%, 95%, 99%] (sec)",
"Time to First Token [1%, 5%, 10%, 50%, 90%, 95%, 99%] (ms)",
- "Inter Token Latency [1%, 5%, 10%, 50%, 90% 95%, 99%] (ms)",
+ "Inter Token Latency [1%, 5%, 10%, 50%, 90%, 95%, 99%] (ms)",
title="[magenta]Performance Stats by Benchmark[/magenta]",
title_style="bold",
title_justify="left",
@@ -193,21 +189,15 @@ def _create_benchmark_report_dist_perf_summary(
_benchmark_rate_id(benchmark),
", ".join(
f"{percentile:.2f}"
- for percentile in benchmark.request_latency_distribution.percentiles(
- [1, 5, 10, 50, 90, 95, 99]
- )
+ for percentile in benchmark.request_latency_percentiles
),
", ".join(
f"{percentile * 1000:.1f}"
- for percentile in benchmark.ttft_distribution.percentiles(
- [1, 5, 10, 50, 90, 95, 99]
- )
+ for percentile in benchmark.time_to_first_token_percentiles
),
", ".join(
f"{percentile * 1000:.1f}"
- for percentile in benchmark.itl_distribution.percentiles(
- [1, 5, 10, 50, 90, 95, 99]
- )
+ for percentile in benchmark.inter_token_latency_percentiles
),
)
logger.debug("Created distribution performance summary table for the report.")
diff --git a/src/guidellm/core/result.py b/src/guidellm/core/result.py
index f218784..aebd176 100644
--- a/src/guidellm/core/result.py
+++ b/src/guidellm/core/result.py
@@ -2,7 +2,7 @@
from typing import Any, Dict, List, Literal, Optional, Union
from loguru import logger
-from pydantic import Field
+from pydantic import Field, computed_field
from guidellm.core.distribution import Distribution
from guidellm.core.request import TextGenerationRequest
@@ -221,6 +221,7 @@ def __iter__(self):
"""
return iter(self.results)
+ @computed_field # type: ignore[misc]
@property
def request_count(self) -> int:
"""
@@ -231,6 +232,7 @@ def request_count(self) -> int:
"""
return len(self.results)
+ @computed_field # type: ignore[misc]
@property
def error_count(self) -> int:
"""
@@ -241,6 +243,7 @@ def error_count(self) -> int:
"""
return len(self.errors)
+ @computed_field # type: ignore[misc]
@property
def total_count(self) -> int:
"""
@@ -251,6 +254,7 @@ def total_count(self) -> int:
"""
return self.request_count + self.error_count
+ @computed_field # type: ignore[misc]
@property
def start_time(self) -> Optional[float]:
"""
@@ -264,6 +268,7 @@ def start_time(self) -> Optional[float]:
return self.results[0].start_time
+ @computed_field # type: ignore[misc]
@property
def end_time(self) -> Optional[float]:
"""
@@ -277,6 +282,7 @@ def end_time(self) -> Optional[float]:
return self.results[-1].end_time
+ @computed_field # type: ignore[misc]
@property
def duration(self) -> float:
"""
@@ -290,6 +296,7 @@ def duration(self) -> float:
return self.end_time - self.start_time
+ @computed_field # type: ignore[misc]
@property
def completed_request_rate(self) -> float:
"""
@@ -303,6 +310,7 @@ def completed_request_rate(self) -> float:
return len(self.results) / self.duration
+ @computed_field # type: ignore[misc]
@property
def request_latency(self) -> float:
"""
@@ -332,6 +340,19 @@ def request_latency_distribution(self) -> Distribution:
]
)
+ @computed_field # type: ignore[misc]
+ @property
+ def request_latency_percentiles(self) -> List[float]:
+ """
+ Get standard percentiles of request latency in seconds.
+
+ :return: List of percentile request latency in seconds
+ :rtype: List[float]
+ """
+ return self.request_latency_distribution.percentiles([1, 5, 10, 50, 90, 95, 99])
+
+
+ @computed_field # type: ignore[misc]
@property
def time_to_first_token(self) -> float:
"""
@@ -361,6 +382,20 @@ def ttft_distribution(self) -> Distribution:
]
)
+ @computed_field # type: ignore[misc]
+ @property
+ def time_to_first_token_percentiles(self) -> List[float]:
+ """
+ Get standard percentiles for time taken to decode the first token
+ in milliseconds.
+
+ :return: List of percentile time taken to decode the first token
+ in milliseconds.
+ :rtype: List[float]
+ """
+ return self.ttft_distribution.percentiles([1, 5, 10, 50, 90, 95, 99])
+
+ @computed_field # type: ignore[misc]
@property
def inter_token_latency(self) -> float:
"""
@@ -388,6 +423,18 @@ def itl_distribution(self) -> Distribution:
]
)
+ @computed_field # type: ignore[misc]
+ @property
+ def inter_token_latency_percentiles(self) -> List[float]:
+ """
+ Get standard percentiles for the time between tokens in milliseconds.
+
+ :return: List of percentiles for the average time between tokens.
+ :rtype: List[float]
+ """
+ return self.itl_distribution.percentiles([1, 5, 10, 50, 90, 95, 99])
+
+ @computed_field # type: ignore[misc]
@property
def output_token_throughput(self) -> float:
"""
@@ -403,6 +450,17 @@ def output_token_throughput(self) -> float:
return total_tokens / self.duration
+ @computed_field # type: ignore[misc]
+ @property
+ def prompt_token(self) -> float:
+ """
+ Get the average number of prompt tokens.
+
+ :return: The average number of prompt tokens.
+ :rtype: float
+ """
+ return self.prompt_token_distribution.mean
+
@property
def prompt_token_distribution(self) -> Distribution:
"""
@@ -413,6 +471,28 @@ def prompt_token_distribution(self) -> Distribution:
"""
return Distribution(data=[result.prompt_token_count for result in self.results])
+ @computed_field # type: ignore[misc]
+ @property
+ def prompt_token_percentiles(self) -> List[float]:
+ """
+ Get standard percentiles for number of prompt tokens.
+
+ :return: List of percentiles of number of prompt tokens.
+ :rtype: List[float]
+ """
+ return self.prompt_token_distribution.percentiles([1, 5, 50, 95, 99])
+
+ @computed_field # type: ignore[misc]
+ @property
+ def output_token(self) -> float:
+ """
+ Get the average number of output tokens.
+
+ :return: The average number of output tokens.
+ :rtype: float
+ """
+ return self.output_token_distribution.mean
+
@property
def output_token_distribution(self) -> Distribution:
"""
@@ -423,6 +503,18 @@ def output_token_distribution(self) -> Distribution:
"""
return Distribution(data=[result.output_token_count for result in self.results])
+ @computed_field # type: ignore[misc]
+ @property
+ def output_token_percentiles(self) -> List[float]:
+ """
+ Get standard percentiles for number of output tokens.
+
+ :return: List of percentiles of number of output tokens.
+ :rtype: List[float]
+ """
+ return self.output_token_distribution.percentiles([1, 5, 50, 95, 99])
+
+ @computed_field # type: ignore[misc]
@property
def overloaded(self) -> bool:
if (
#### 4. Use the Results
diff --git a/src/guidellm/core/report.py b/src/guidellm/core/report.py
index b6791e4..c48eed5 100644
--- a/src/guidellm/core/report.py
+++ b/src/guidellm/core/report.py
@@ -147,19 +147,15 @@ def _create_benchmark_report_data_tokens_summary(
for benchmark in report.benchmarks_sorted:
table.add_row(
_benchmark_rate_id(benchmark),
- f"{benchmark.prompt_token_distribution.mean:.2f}",
+ f"{benchmark.prompt_token:.2f}",
", ".join(
f"{percentile:.1f}"
- for percentile in benchmark.prompt_token_distribution.percentiles(
- [1, 5, 50, 95, 99]
- )
+ for percentile in benchmark.prompt_token_percentiles
),
- f"{benchmark.output_token_distribution.mean:.2f}",
+ f"{benchmark.output_token:.2f}",
", ".join(
f"{percentile:.1f}"
- for percentile in benchmark.output_token_distribution.percentiles(
- [1, 5, 50, 95, 99]
- )
+ for percentile in benchmark.output_token_percentiles
),
)
logger.debug("Created data tokens summary table for the report.")
@@ -181,7 +177,7 @@ def _create_benchmark_report_dist_perf_summary(
"Benchmark",
"Request Latency [1%, 5%, 10%, 50%, 90%, 95%, 99%] (sec)",
"Time to First Token [1%, 5%, 10%, 50%, 90%, 95%, 99%] (ms)",
- "Inter Token Latency [1%, 5%, 10%, 50%, 90% 95%, 99%] (ms)",
+ "Inter Token Latency [1%, 5%, 10%, 50%, 90%, 95%, 99%] (ms)",
title="[magenta]Performance Stats by Benchmark[/magenta]",
title_style="bold",
title_justify="left",
@@ -193,21 +189,15 @@ def _create_benchmark_report_dist_perf_summary(
_benchmark_rate_id(benchmark),
", ".join(
f"{percentile:.2f}"
- for percentile in benchmark.request_latency_distribution.percentiles(
- [1, 5, 10, 50, 90, 95, 99]
- )
+ for percentile in benchmark.request_latency_percentiles
),
", ".join(
f"{percentile * 1000:.1f}"
- for percentile in benchmark.ttft_distribution.percentiles(
- [1, 5, 10, 50, 90, 95, 99]
- )
+ for percentile in benchmark.time_to_first_token_percentiles
),
", ".join(
f"{percentile * 1000:.1f}"
- for percentile in benchmark.itl_distribution.percentiles(
- [1, 5, 10, 50, 90, 95, 99]
- )
+ for percentile in benchmark.inter_token_latency_percentiles
),
)
logger.debug("Created distribution performance summary table for the report.")
diff --git a/src/guidellm/core/result.py b/src/guidellm/core/result.py
index f218784..aebd176 100644
--- a/src/guidellm/core/result.py
+++ b/src/guidellm/core/result.py
@@ -2,7 +2,7 @@
from typing import Any, Dict, List, Literal, Optional, Union
from loguru import logger
-from pydantic import Field
+from pydantic import Field, computed_field
from guidellm.core.distribution import Distribution
from guidellm.core.request import TextGenerationRequest
@@ -221,6 +221,7 @@ def __iter__(self):
"""
return iter(self.results)
+ @computed_field # type: ignore[misc]
@property
def request_count(self) -> int:
"""
@@ -231,6 +232,7 @@ def request_count(self) -> int:
"""
return len(self.results)
+ @computed_field # type: ignore[misc]
@property
def error_count(self) -> int:
"""
@@ -241,6 +243,7 @@ def error_count(self) -> int:
"""
return len(self.errors)
+ @computed_field # type: ignore[misc]
@property
def total_count(self) -> int:
"""
@@ -251,6 +254,7 @@ def total_count(self) -> int:
"""
return self.request_count + self.error_count
+ @computed_field # type: ignore[misc]
@property
def start_time(self) -> Optional[float]:
"""
@@ -264,6 +268,7 @@ def start_time(self) -> Optional[float]:
return self.results[0].start_time
+ @computed_field # type: ignore[misc]
@property
def end_time(self) -> Optional[float]:
"""
@@ -277,6 +282,7 @@ def end_time(self) -> Optional[float]:
return self.results[-1].end_time
+ @computed_field # type: ignore[misc]
@property
def duration(self) -> float:
"""
@@ -290,6 +296,7 @@ def duration(self) -> float:
return self.end_time - self.start_time
+ @computed_field # type: ignore[misc]
@property
def completed_request_rate(self) -> float:
"""
@@ -303,6 +310,7 @@ def completed_request_rate(self) -> float:
return len(self.results) / self.duration
+ @computed_field # type: ignore[misc]
@property
def request_latency(self) -> float:
"""
@@ -332,6 +340,19 @@ def request_latency_distribution(self) -> Distribution:
]
)
+ @computed_field # type: ignore[misc]
+ @property
+ def request_latency_percentiles(self) -> List[float]:
+ """
+ Get standard percentiles of request latency in seconds.
+
+ :return: List of percentile request latency in seconds
+ :rtype: List[float]
+ """
+ return self.request_latency_distribution.percentiles([1, 5, 10, 50, 90, 95, 99])
+
+
+ @computed_field # type: ignore[misc]
@property
def time_to_first_token(self) -> float:
"""
@@ -361,6 +382,20 @@ def ttft_distribution(self) -> Distribution:
]
)
+ @computed_field # type: ignore[misc]
+ @property
+ def time_to_first_token_percentiles(self) -> List[float]:
+ """
+ Get standard percentiles for time taken to decode the first token
+ in milliseconds.
+
+ :return: List of percentile time taken to decode the first token
+ in milliseconds.
+ :rtype: List[float]
+ """
+ return self.ttft_distribution.percentiles([1, 5, 10, 50, 90, 95, 99])
+
+ @computed_field # type: ignore[misc]
@property
def inter_token_latency(self) -> float:
"""
@@ -388,6 +423,18 @@ def itl_distribution(self) -> Distribution:
]
)
+ @computed_field # type: ignore[misc]
+ @property
+ def inter_token_latency_percentiles(self) -> List[float]:
+ """
+ Get standard percentiles for the time between tokens in milliseconds.
+
+ :return: List of percentiles for the average time between tokens.
+ :rtype: List[float]
+ """
+ return self.itl_distribution.percentiles([1, 5, 10, 50, 90, 95, 99])
+
+ @computed_field # type: ignore[misc]
@property
def output_token_throughput(self) -> float:
"""
@@ -403,6 +450,17 @@ def output_token_throughput(self) -> float:
return total_tokens / self.duration
+ @computed_field # type: ignore[misc]
+ @property
+ def prompt_token(self) -> float:
+ """
+ Get the average number of prompt tokens.
+
+ :return: The average number of prompt tokens.
+ :rtype: float
+ """
+ return self.prompt_token_distribution.mean
+
@property
def prompt_token_distribution(self) -> Distribution:
"""
@@ -413,6 +471,28 @@ def prompt_token_distribution(self) -> Distribution:
"""
return Distribution(data=[result.prompt_token_count for result in self.results])
+ @computed_field # type: ignore[misc]
+ @property
+ def prompt_token_percentiles(self) -> List[float]:
+ """
+ Get standard percentiles for number of prompt tokens.
+
+ :return: List of percentiles of number of prompt tokens.
+ :rtype: List[float]
+ """
+ return self.prompt_token_distribution.percentiles([1, 5, 50, 95, 99])
+
+ @computed_field # type: ignore[misc]
+ @property
+ def output_token(self) -> float:
+ """
+ Get the average number of output tokens.
+
+ :return: The average number of output tokens.
+ :rtype: float
+ """
+ return self.output_token_distribution.mean
+
@property
def output_token_distribution(self) -> Distribution:
"""
@@ -423,6 +503,18 @@ def output_token_distribution(self) -> Distribution:
"""
return Distribution(data=[result.output_token_count for result in self.results])
+ @computed_field # type: ignore[misc]
+ @property
+ def output_token_percentiles(self) -> List[float]:
+ """
+ Get standard percentiles for number of output tokens.
+
+ :return: List of percentiles of number of output tokens.
+ :rtype: List[float]
+ """
+ return self.output_token_distribution.percentiles([1, 5, 50, 95, 99])
+
+ @computed_field # type: ignore[misc]
@property
def overloaded(self) -> bool:
if (