+
+#### Dataset Configuration
+
+It is mainly about two parts.
+
+- The location of the dataset(s), including images and annotation files.
+
+- Data augmentation related configurations. In the OCR domain, data augmentation is usually strongly associated with the model.
+
+More parameter configurations can be found in [Data Base Class](#TODO).
+
+The naming convention for dataset fields in MMOCR is
+
+```Python
+{dataset}_{task}_{train/val/test} = dict(...)
+```
+
+- dataset: See [dataset abbreviations](#TODO)
+
+- task: `det`(text detection), `rec`(text recognition), `kie`(key information extraction)
+
+- train/val/test: Dataset split.
+
+For example, for text recognition tasks, Syn90k is used as the training set, while icdar2013 and icdar2015 serve as the test sets. These are configured as follows.
+
+```Python
+# text recognition dataset configuration
+mj_rec_train = dict(
+ type='OCRDataset',
+ data_root='data/rec/Syn90k/',
+ data_prefix=dict(img_path='mnt/ramdisk/max/90kDICT32px'),
+ ann_file='train_labels.json',
+ test_mode=False,
+ pipeline=None)
+
+ic13_rec_test = dict(
+ type='OCRDataset',
+ data_root='data/rec/icdar_2013/',
+ data_prefix=dict(img_path='Challenge2_Test_Task3_Images/'),
+ ann_file='test_labels.json',
+ test_mode=True,
+ pipeline=None)
+
+ic15_rec_test = dict(
+ type='OCRDataset',
+ data_root='data/rec/icdar_2015/',
+ data_prefix=dict(img_path='ch4_test_word_images_gt/'),
+ ann_file='test_labels.json',
+ test_mode=True,
+ pipeline=None)
+```
+
+
+
+#### Data Pipeline Configuration
+
+In MMOCR, dataset construction and data preparation are decoupled from each other. In other words, dataset classes such as `OCRDataset` are responsible for reading and parsing annotation files, while Data Transforms further implement data loading, data augmentation, data formatting and other related functions.
+
+In general, there are different augmentation strategies for training and testing, so there are usually `training_pipeline` and `testing_pipeline`. More information can be found in [Data Transforms](../basic_concepts/transforms.md)
+
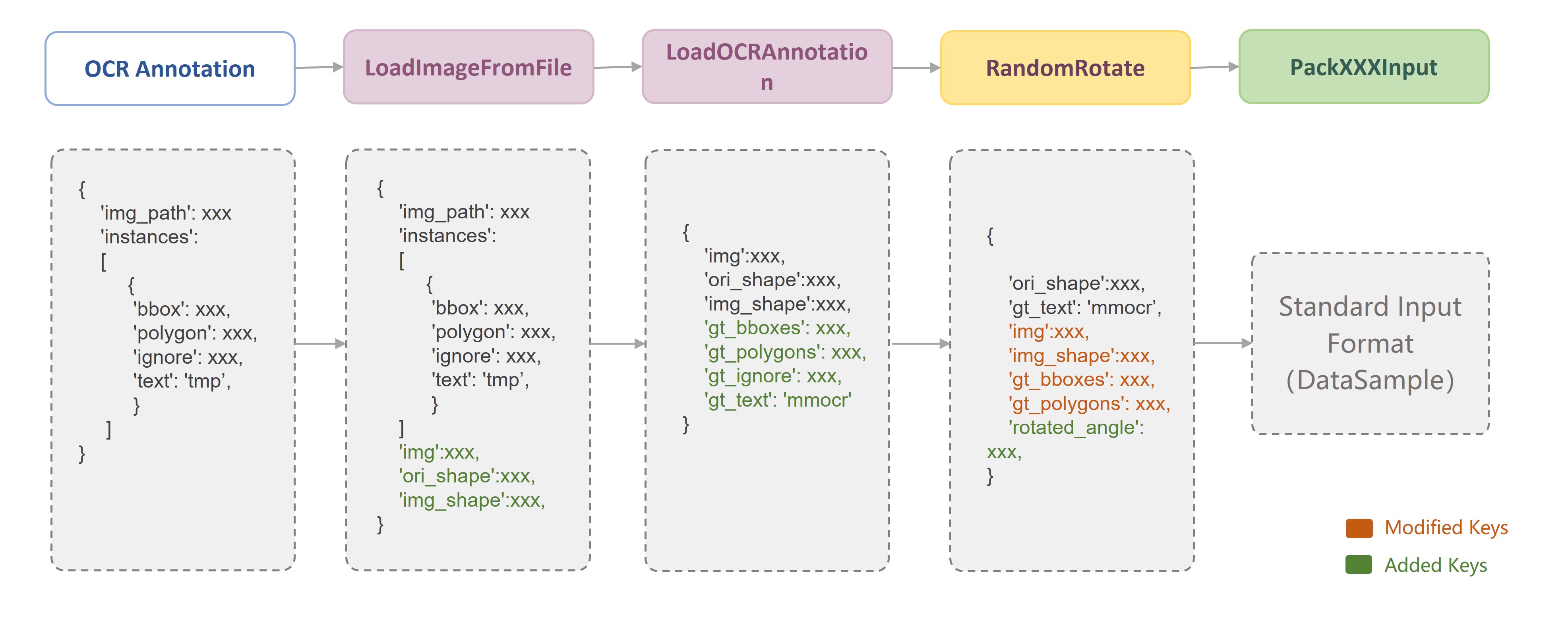
+- The data augmentation process of the training pipeline is usually: data loading (LoadImageFromFile) -> annotation information loading (LoadXXXAnntation) -> data augmentation -> data formatting (PackXXXInputs).
+
+- The data augmentation flow of the test pipeline is usually: Data Loading (LoadImageFromFile) -> Data Augmentation -> Annotation Loading (LoadXXXAnntation) -> Data Formatting (PackXXXInputs).
+
+Due to the specificity of the OCR task, different models have different data augmentation techniques, and even the same model can have different data augmentation strategies for different datasets. Take `CRNN` as an example.
+
+```Python
+# Data Augmentation
+file_client_args = dict(backend='disk')
+train_pipeline = [
+ dict(
+ type='LoadImageFromFile',
+ color_type='grayscale',
+ file_client_args=dict(backend='disk'),
+ ignore_empty=True,
+ min_size=5),
+ dict(type='LoadOCRAnnotations', with_text=True),
+ dict(type='Resize', scale=(100, 32), keep_ratio=False),
+ dict(
+ type='PackTextRecogInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape', 'valid_ratio'))
+]
+test_pipeline = [
+ dict(
+ type='LoadImageFromFile',
+ color_type='grayscale',
+ file_client_args=dict(backend='disk')),
+ dict(
+ type='RescaleToHeight',
+ height=32,
+ min_width=32,
+ max_width=None,
+ width_divisor=16),
+ dict(type='LoadOCRAnnotations', with_text=True),
+ dict(
+ type='PackTextRecogInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape', 'valid_ratio'))
+]
+```
+
+#### Dataloader Configuration
+
+The main configuration information needed to construct the dataset loader (dataloader), see {external+torch:doc}`PyTorch DataLoader
` for more tutorials.
+
+```Python
+# Dataloader
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=8,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='ConcatDataset',
+ datasets=[mj_rec_train],
+ pipeline=train_pipeline))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=4,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type='ConcatDataset',
+ datasets=[ic13_rec_test, ic15_rec_test],
+ pipeline=test_pipeline))
+test_dataloader = val_dataloader
+```
+
+### Model-related Configuration
+
+
+
+#### Network Configuration
+
+This section configures the network architecture. Different algorithmic tasks use different network architectures. Find more info about network architecture in [structures](../basic_concepts/structures.md)
+
+##### Text Detection
+
+Text detection consists of several parts:
+
+- `data_preprocessor`: [data_preprocessor](mmocr.models.textdet.data_preprocessors.TextDetDataPreprocessor)
+- `backbone`: backbone network configuration
+- `neck`: neck network configuration
+- `det_head`: detection head network configuration
+ - `module_loss`: module loss configuration
+ - `postprocessor`: postprocessor configuration
+
+We present the model configuration in text detection using DBNet as an example.
+
+```Python
+model = dict(
+ type='DBNet',
+ data_preprocessor=dict(
+ type='TextDetDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True,
+ pad_size_divisor=32)
+ backbone=dict(
+ type='mmdet.ResNet',
+ depth=18,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=-1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet18'),
+ norm_eval=False,
+ style='caffe'),
+ neck=dict(
+ type='FPNC', in_channels=[64, 128, 256, 512], lateral_channels=256),
+ det_head=dict(
+ type='DBHead',
+ in_channels=256,
+ module_loss=dict(type='DBModuleLoss'),
+ postprocessor=dict(type='DBPostprocessor', text_repr_type='quad')))
+```
+
+##### Text Recognition
+
+Text recognition mainly contains:
+
+- `data_processor`: [data preprocessor configuration](mmocr.models.textrecog.data_processors.TextRecDataPreprocessor)
+- `preprocessor`: network preprocessor configuration, e.g. TPS
+- `backbone`: backbone configuration
+- `encoder`: encoder configuration
+- `decoder`: decoder configuration
+ - `module_loss`: decoder module loss configuration
+ - `postprocessor`: decoder postprocessor configuration
+ - `dictionary`: dictionary configuration
+
+Using CRNN as an example.
+
+```Python
+# model
+model = dict(
+ type='CRNN',
+ data_preprocessor=dict(
+ type='TextRecogDataPreprocessor', mean=[127], std=[127])
+ preprocessor=None,
+ backbone=dict(type='VeryDeepVgg', leaky_relu=False, input_channels=1),
+ encoder=None,
+ decoder=dict(
+ type='CRNNDecoder',
+ in_channels=512,
+ rnn_flag=True,
+ module_loss=dict(type='CTCModuleLoss', letter_case='lower'),
+ postprocessor=dict(type='CTCPostProcessor'),
+ dictionary=dict(
+ type='Dictionary',
+ dict_file='dicts/lower_english_digits.txt',
+ with_padding=True)))
+```
+
+
+
+#### Checkpoint Loading Configuration
+
+The model weights in the checkpoint file can be loaded via the `load_from` parameter, simply by setting the `load_from` parameter to the path of the checkpoint file.
+
+You can also resume training by setting `resume=True` to load the training status information in the checkpoint. When both `load_from` and `resume=True` are set, MMEngine will load the training state from the checkpoint file at the `load_from` path.
+
+If only `resume=True` is set, the executor will try to find and read the latest checkpoint file from the `work_dir` folder
+
+```Python
+load_from = None # Path to load checkpoint
+resume = False # whether resume
+```
+
+More can be found in {external+mmengine:doc}`MMEngine: Load Weights or Recover Training ` and [OCR Advanced Tips - Resume Training from Checkpoints](train_test.md#resume-training-from-a-checkpoint).
+
+
+
+### Evaluation Configuration
+
+In model validation and model testing, quantitative measurement of model accuracy is often required. MMOCR performs this function by means of `Metric` and `Evaluator`. For more information, please refer to {external+mmengine:doc}`MMEngine: Evaluation
` and [Evaluation](../basic_concepts/evaluation.md)
+
+#### Evaluator
+
+Evaluator is mainly used to manage multiple datasets and multiple `Metrics`. For single and multiple dataset cases, there are single and multiple dataset evaluators, both of which can manage multiple `Metrics`.
+
+The single-dataset evaluator is configured as follows.
+
+```Python
+# Single Dataset Single Metric
+val_evaluator = dict(
+ type='Evaluator',
+ metrics=dict())
+
+# Single Dataset Multiple Metric
+val_evaluator = dict(
+ type='Evaluator',
+ metrics=[...])
+```
+
+`MultiDatasetsEvaluator` differs from single-dataset evaluation in two aspects: `type` and `dataset_prefixes`. The evaluator type must be `MultiDatasetsEvaluator` and cannot be omitted. The `dataset_prefixes` is mainly used to distinguish the results of different datasets with the same evaluation metrics, see [MultiDatasetsEvaluation](../basic_concepts/evaluation.md).
+
+Assuming that we need to test accuracy on IC13 and IC15 datasets, the configuration is as follows.
+
+```Python
+# Multiple datasets, single Metric
+val_evaluator = dict(
+ type='MultiDatasetsEvaluator',
+ metrics=dict(),
+ dataset_prefixes=['IC13', 'IC15'])
+
+# Multiple datasets, multiple Metrics
+val_evaluator = dict(
+ type='MultiDatasetsEvaluator',
+ metrics=[...],
+ dataset_prefixes=['IC13', 'IC15'])
+```
+
+#### Metric
+
+A metric evaluates a model's performance from a specific perspective. While there is no such common metric that fits all the tasks, MMOCR provides enough flexibility such that multiple metrics serving the same task can be used simultaneously. Here we list task-specific metrics for reference.
+
+Text detection: [`HmeanIOUMetric`](mmocr.evaluation.metrics.HmeanIOUMetric)
+
+Text recognition: [`WordMetric`](mmocr.evaluation.metrics.WordMetric), [`CharMetric`](mmocr.evaluation.metrics.CharMetric), [`OneMinusNEDMetric`](mmocr.evaluation.metrics.OneMinusNEDMetric)
+
+Key information extraction: [`F1Metric`](mmocr.evaluation.metrics.F1Metric)
+
+Text detection as an example, using a single `Metric` in the case of single dataset evaluation.
+
+```Python
+val_evaluator = dict(type='HmeanIOUMetric')
+```
+
+Take text recognition as an example, multiple datasets (`IC13` and `IC15`) are evaluated using multiple `Metric`s (`WordMetric` and `CharMetric`).
+
+```Python
+val_evaluator = dict(
+ type='MultiDatasetsEvaluator',
+ metrics=[
+ dict(
+ type='WordMetric',
+ mode=['exact', 'ignore_case', 'ignore_case_symbol']),
+ dict(type='CharMetric')
+ ],
+ dataset_prefixes=['IC13', 'IC15'])
+test_evaluator = val_evaluator
+```
+
+
+
+### Visualizaiton Configuration
+
+Each task is bound to a task-specific visualizer. The visualizer is mainly used for visualizing or storing intermediate results of user models and visualizing val and test prediction results. The visualization results can also be stored in different backends such as WandB, TensorBoard, etc. through the corresponding visualization backend. Commonly used modification operations can be found in [visualization](visualization.md).
+
+The default configuration of visualization for text detection is as follows.
+
+```Python
+vis_backends = [dict(type='LocalVisBackend')]
+visualizer = dict(
+ type='TextDetLocalVisualizer', # Different visualizers for different tasks
+ vis_backends=vis_backends,
+ name='visualizer')
+```
+
+## Directory Structure
+
+All configuration files of `MMOCR` are placed under the `configs` folder. To avoid config files from being too long and improve their reusability and clarity, MMOCR takes advantage of the inheritance mechanism and split config files into eight sections. Since each section is closely related to the task type, MMOCR provides a task folder for each task in `configs/`, namely `textdet` (text detection task), `textrecog` (text recognition task), and `kie` (key information extraction). Each folder is further divided into two parts: `_base_` folder and algorithm configuration folders.
+
+1. the `_base_` folder stores some general config files unrelated to specific algorithms, and each section is divided into datasets, training strategies and runtime configurations by directory.
+
+2. The algorithm configuration folder stores config files that are strongly related to the algorithm. The algorithm configuration folder has two kinds of config files.
+
+ 1. Config files starting with `_base_`: Configures the model and data pipeline of an algorithm. In OCR domain, data augmentation strategies are generally strongly related to the algorithm, so the model and data pipeline are usually placed in the same config file.
+
+ 2. Other config files, i.e. the algorithm-specific configurations on the specific dataset(s): These are the full config files that further configure training and testing settings, aggregating `_base_` configurations that are scattered in different locations. Inside some modifications to the fields in `_base_` configs may be performed, such as data pipeline, training strategy, etc.
+
+All these config files are distributed in different folders according to their contents as follows:
+
+
+
+
+
+The final directory structure is as follows.
+
+```Python
+configs
+├── textdet
+│ ├── _base_
+│ │ ├── datasets
+│ │ │ ├── icdar2015.py
+│ │ │ ├── icdar2017.py
+│ │ │ └── totaltext.py
+│ │ ├── schedules
+│ │ │ └── schedule_adam_600e.py
+│ │ └── default_runtime.py
+│ └── dbnet
+│ ├── _base_dbnet_resnet18_fpnc.py
+│ └── dbnet_resnet18_fpnc_1200e_icdar2015.py
+├── textrecog
+│ ├── _base_
+│ │ ├── datasets
+│ │ │ ├── icdar2015.py
+│ │ │ ├── icdar2017.py
+│ │ │ └── totaltext.py
+│ │ ├── schedules
+│ │ │ └── schedule_adam_base.py
+│ │ └── default_runtime.py
+│ └── crnn
+│ ├── _base_crnn_mini-vgg.py
+│ └── crnn_mini-vgg_5e_mj.py
+└── kie
+ ├── _base_
+ │ ├──datasets
+ │ └── default_runtime.py
+ └── sgdmr
+ └── sdmgr_novisual_60e_wildreceipt_openset.py
+```
+
+## Naming Conventions
+
+MMOCR has a convention to name config files, and contributors to the code base need to follow the same naming rules. The file names are divided into four sections: algorithm information, module information, training information, and data information. Words that logically belong to different sections are connected by an underscore `'_'`, and multiple words in the same section are connected by a hyphen `'-'`.
+
+```Python
+{{algorithm info}}_{{module info}}_{{training info}}_{{data info}}.py
+```
+
+- algorithm info: the name of the algorithm, such as dbnet, crnn, etc.
+
+- module info: list some intermediate modules in the order of data flow. Its content depends on the algorithm, and some modules strongly related to the model will be omitted to avoid an overly long name. For example:
+
+ - For the text detection task and the key information extraction task :
+
+ ```Python
+ {{algorithm info}}_{{backbone}}_{{neck}}_{{head}}_{{training info}}_{{data info}}.py
+ ```
+
+ `{head}` is usually omitted since it's algorithm-specific.
+
+ - For text recognition tasks.
+
+ ```Python
+ {{algorithm info}}_{{backbone}}_{{encoder}}_{{decoder}}_{{training info}}_{{data info}}.py
+ ```
+
+ Since encoder and decoder are generally bound to the algorithm, they are usually omitted.
+
+- training info: some settings of the training strategy, including batch size, schedule, etc.
+
+- data info: dataset name, modality, input size, etc., such as icdar2015 and synthtext.
diff --git a/docs/zh_cn/user_guides/config.md b/docs/zh_cn/user_guides/config.md
index 8c4f63256..fcec3fa67 100644
--- a/docs/zh_cn/user_guides/config.md
+++ b/docs/zh_cn/user_guides/config.md
@@ -5,7 +5,7 @@ MMOCR 主要使用 Python 文件作为配置文件。其配置文件系统的设
## 常见用法
```{note}
-本小节建议结合 [配置(Config)](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/config.md) 中的初级用法共同阅读。
+本小节建议结合 {external+mmengine:doc}`MMEngine: 配置(Config) ` 中的初级用法共同阅读。
```
MMOCR 最常用的操作为三种:配置文件的继承,对 `_base_` 变量的引用以及对 `_base_` 变量的修改。对于 `_base_` 的继承与修改, MMEngine.Config 提供了两种语法,一种是针对 Python,Json, Yaml 均可使用的操作;另一种则仅适用于 Python 配置文件。在 MMOCR 中,我们**更推荐使用只针对Python的语法**,因此下文将以此为基础作进一步介绍。
@@ -144,7 +144,7 @@ train_dataloader = dict(
python tools/train.py example.py --cfg-options optim_wrapper.optimizer.lr=1
```
-更多详细用法参考[命令行修改配置](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/config.md#%E5%91%BD%E4%BB%A4%E8%A1%8C%E4%BF%AE%E6%94%B9%E9%85%8D%E7%BD%AE)
+更多详细用法参考 {external+mmengine:ref}`MMEngine: 命令行修改配置 <命令行修改配置>`.
## 配置内容
@@ -162,16 +162,16 @@ env_cfg = dict(
cudnn_benchmark=True,
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
dist_cfg=dict(backend='nccl'))
-random_cfg = dict(seed=None)
+randomness = dict(seed=None)
```
主要包含三个部分:
-- 设置所有注册器的默认 `scope` 为 `mmocr`, 保证所有的模块首先从 `MMOCR` 代码库中进行搜索。若果该模块不存在,则继续从上游算法库 `MMEngine` 和 `MMCV` 中进行搜索(详见[注册器](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/registry.md)。
+- 设置所有注册器的默认 `scope` 为 `mmocr`, 保证所有的模块首先从 `MMOCR` 代码库中进行搜索。若果该模块不存在,则继续从上游算法库 `MMEngine` 和 `MMCV` 中进行搜索,详见 {external+mmengine:doc}`MMEngine: 注册器 `。
-- `env_cfg` 设置分布式环境配置, 更多配置可以详见 [MMEngine Runner](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/runner.md)
+- `env_cfg` 设置分布式环境配置, 更多配置可以详见 {external+mmengine:doc}`MMEngine: Runner `。
-- `random_cfg` 设置 numpy, torch,cudnn 等随机种子,更多配置详见 [Runner](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/runner.md)
+- `randomness` 设置 numpy, torch,cudnn 等随机种子,更多配置详见 {external+mmengine:doc}`MMEngine: Runner `。
@@ -183,11 +183,11 @@ Hook 主要分为两个部分,默认 hook 以及自定义 hook。默认 hook
default_hooks = dict(
timer=dict(type='IterTimerHook'), # 时间记录,包括数据增强时间以及模型推理时间
logger=dict(type='LoggerHook', interval=1), # 日志打印间隔
- param_scheduler=dict(type='ParamSchedulerHook'), # 与param_scheduler 更新学习率等超参
+ param_scheduler=dict(type='ParamSchedulerHook'), # 更新学习率等超参
checkpoint=dict(type='CheckpointHook', interval=1),# 保存 checkpoint, interval控制保存间隔
sampler_seed=dict(type='DistSamplerSeedHook'), # 多机情况下设置种子
- sync_buffer=dict(type='SyncBuffersHook'), # 同步多卡情况下,buffer
- visualization=dict( # 用户可视化val 和 test 的结果
+ sync_buffer=dict(type='SyncBuffersHook'), # 多卡情况下,同步buffer
+ visualization=dict( # 可视化val 和 test 的结果
type='VisualizationHook',
interval=1,
enable=False,
@@ -203,9 +203,9 @@ default_hooks = dict(
- `CheckpointHook`:用于配置模型断点保存相关的行为,如保存最优权重,保存最新权重等。同样可以修改 `interval` 控制保存 checkpoint 的间隔。更多设置可参考 [CheckpointHook API](mmengine.hooks.CheckpointHook)
-- `VisualizationHook`:用于配置可视化相关行为,例如在验证或测试时可视化预测结果,默认为关。同时该 Hook 依赖[可视化配置](#TODO)。想要了解详细功能可以参考 [Visualizer](visualization.md)。更多配置可以参考 [VisualizationHook API](mmocr.engine.hooks.VisualizationHook)。
+- `VisualizationHook`:用于配置可视化相关行为,例如在验证或测试时可视化预测结果,**默认为关**。同时该 Hook 依赖[可视化配置](#可视化配置)。想要了解详细功能可以参考 [Visualizer](visualization.md)。更多配置可以参考 [VisualizationHook API](mmocr.engine.hooks.VisualizationHook)。
-如果想进一步了解默认 hook 的配置以及功能,可以参考[钩子(Hook)](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/hook.md)。
+如果想进一步了解默认 hook 的配置以及功能,可以参考 {external+mmengine:doc}`MMEngine: 钩子(Hook) `。
@@ -220,13 +220,13 @@ log_processor = dict(type='LogProcessor',
by_epoch=True)
```
-- 日志配置等级与 [logging](https://docs.python.org/3/library/logging.html) 的配置一致,
+- 日志配置等级与 {external+python:doc}`Python: logging ` 的配置一致,
-- 日志处理器主要用来控制输出的格式,详细功能可参考[记录日志](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/advanced_tutorials/logging.md):
+- 日志处理器主要用来控制输出的格式,详细功能可参考 {external+mmengine:doc}`MMEngine: 记录日志 `:
- `by_epoch=True` 表示按照epoch输出日志,日志格式需要和 `train_cfg` 中的 `type='EpochBasedTrainLoop'` 参数保持一致。例如想按迭代次数输出日志,就需要令 `log_processor` 中的 ` by_epoch=False` 的同时 `train_cfg` 中的 `type = 'IterBasedTrainLoop'`。
- - `window_size` 表示损失的平滑窗口,即最近 `window_size` 次迭代的各种损失的均值。logger 中最终打印的 loss 值为经过各种损失的平均值。
+ - `window_size` 表示损失的平滑窗口,即最近 `window_size` 次迭代的各种损失的均值。logger 中最终打印的 loss 值为各种损失的平均值。
@@ -248,15 +248,15 @@ val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')
```
-- `optim_wrapper` : 主要包含两个部分,优化器封装 (OptimWrapper) 以及优化器 (Optimizer)。详情使用信息可见 [MMEngine 优化器封装](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/optim_wrapper.md)
+- `optim_wrapper` : 主要包含两个部分,优化器封装 (OptimWrapper) 以及优化器 (Optimizer)。详情使用信息可见 {external+mmengine:doc}`MMEngine: 优化器封装 `
- 优化器封装支持不同的训练策略,包括混合精度训练(AMP)、梯度累加和梯度截断。
- - 优化器设置中支持了 PyTorch 所有的优化器,所有支持的优化器见 [PyTorch 优化器列表](torch.optim.algorithms)。
+ - 优化器设置中支持了 PyTorch 所有的优化器,所有支持的优化器见 {external+torch:ref}`PyTorch 优化器列表 `。
-- `param_scheduler` : 学习率调整策略,支持大部分 PyTorch 中的学习率调度器,例如 `ExponentialLR`,`LinearLR`,`StepLR`,`MultiStepLR` 等,使用方式也基本一致,所有支持的调度器见[调度器接口文档](mmengine.optim.scheduler), 更多功能可以[参考优化器参数调整策略](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/param_scheduler.md)
+- `param_scheduler` : 学习率调整策略,支持大部分 PyTorch 中的学习率调度器,例如 `ExponentialLR`,`LinearLR`,`StepLR`,`MultiStepLR` 等,使用方式也基本一致,所有支持的调度器见[调度器接口文档](mmengine.optim.scheduler), 更多功能可以参考 {external+mmengine:doc}`MMEngine: 优化器参数调整策略 `。
-- `train/test/val_cfg` : 任务的执行流程,MMEngine 提供了四种流程:`EpochBasedTrainLoop`, `IterBasedTrainLoop`, `ValLoop`, `TestLoop` 更多可以参考[循环控制器](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/runner.md)。
+- `train/test/val_cfg` : 任务的执行流程,MMEngine 提供了四种流程:`EpochBasedTrainLoop`, `IterBasedTrainLoop`, `ValLoop`, `TestLoop` 更多可以参考 {external+mmengine:doc}`MMEngine: 循环控制器 `。
### 数据相关配置
@@ -275,14 +275,14 @@ test_cfg = dict(type='TestLoop')
数据集字段的命名规则在 MMOCR 中为:
```Python
-{数据集名称缩写}_{算法任务}_{训练/测试} = dict(...)
+{数据集名称缩写}_{算法任务}_{训练/测试/验证} = dict(...)
```
- 数据集缩写:见 [数据集名称对应表](#TODO)
- 算法任务:文本检测-det,文字识别-rec,关键信息提取-kie
-- 训练/测试:数据集用于训练还是测试
+- 训练/测试/验证:数据集用于训练,测试还是验证
以识别为例,使用 Syn90k 作为训练集,以 icdar2013 和 icdar2015 作为测试集配置如下:
@@ -319,13 +319,11 @@ ic15_rec_test = dict(
MMOCR 中,数据集的构建与数据准备是相互解耦的。也就是说,`OCRDataset` 等数据集构建类负责完成标注文件的读取与解析功能;而数据变换方法(Data Transforms)则进一步实现了数据读取、数据增强、数据格式化等相关功能。
-同时一般情况下训练和测试会存在不同的增强策略,因此一般会存在训练流水线(train_pipeline)和测试流水线(test_pipeline)。
+同时一般情况下训练和测试会存在不同的增强策略,因此一般会存在训练流水线(train_pipeline)和测试流水线(test_pipeline)。更多信息可以参考[数据流水线](../basic_concepts/transforms.md)
-训练流水线的数据增强流程通常为:数据读取(LoadImageFromFile)->标注信息读取(LoadXXXAnntation)->数据增强->数据格式化(PackXXXInputs)。
+- 训练流水线的数据增强流程通常为:数据读取(LoadImageFromFile)->标注信息读取(LoadXXXAnntation)->数据增强->数据格式化(PackXXXInputs)。
-测试流水线的数据增强流程通常为:数据读取(LoadImageFromFile)->数据增强->标注信息读取(LoadXXXAnntation)->数据格式化(PackXXXInputs)。
-
-更多信息可以参考[数据流水线](../basic_concepts/transforms.md)
+- 测试流水线的数据增强流程通常为:数据读取(LoadImageFromFile)->数据增强->标注信息读取(LoadXXXAnntation)->数据格式化(PackXXXInputs)。
由于 OCR 任务的特殊性,一般情况下不同模型有不同数据增强的方式,相同模型在不同数据集一般也会有不同的数据增强方式。以 CRNN 为例:
@@ -367,7 +365,7 @@ test_pipeline = [
#### Dataloader 配置
-主要为构造数据集加载器(dataloader)所需的配置信息,更多教程看参考[PyTorch 数据加载器](torch.data)。
+主要为构造数据集加载器(dataloader)所需的配置信息,更多教程看参考 {external+torch:doc}`PyTorch 数据加载器 `。
```Python
# Dataloader 部分
@@ -388,7 +386,7 @@ val_dataloader = dict(
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type='ConcatDataset',
- datasets=[ic13_rec_test,ic15_rec_test],
+ datasets=[ic13_rec_test, ic15_rec_test],
pipeline=test_pipeline))
test_dataloader = val_dataloader
```
@@ -399,7 +397,7 @@ test_dataloader = val_dataloader
#### 网络配置
-用于配置模型的网络结构,不同的算法任务有不同的网络结构,
+用于配置模型的网络结构,不同的算法任务有不同的网络结构。更多信息可以参考[网络结构](../basic_concepts/structures.md)
##### 文本检测
@@ -493,13 +491,13 @@ load_from = None # 加载checkpoint的路径
resume = False # 是否 resume
```
-更多可以参考[加载权重或恢复训练](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/runner.md)与[OCR进阶技巧-断点恢复训练](https://mmocr.readthedocs.io/zh_CN/dev-1.x/user_guides/train_test.html#id11)。
+更多可以参考 {external+mmengine:ref}`MMEngine: 加载权重或恢复训练 <加载权重或恢复训练>` 与 [OCR 进阶技巧-断点恢复训练](train_test.md#从断点恢复训练)。
### 评测配置
-在模型验证和模型测试中,通常需要对模型精度做定量评测。MMOCR 通过评测指标(Metric)和评测器(Evaluator)来完成这一功能。更多可以参考[评测指标(Metric)和评测器(Evaluator)](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/evaluation.md)
+在模型验证和模型测试中,通常需要对模型精度做定量评测。MMOCR 通过评测指标(Metric)和评测器(Evaluator)来完成这一功能。更多可以参考{external+mmengine:doc}`MMEngine: 评测指标(Metric)和评测器(Evaluator)
` 和 [评测器](../basic_concepts/evaluation.md)
评测部分包含两个部分,评测器和评测指标。接下来我们分部分展开讲解。
@@ -551,13 +549,13 @@ val_evaluator = dict(
#### 评测指标
-评测指标指不同度量精度的方法,同时可以多个评测指标共同使用,更多评测指标原理参考[评测指标](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/evaluation.md),在 MMOCR 中不同算法任务有不同的评测指标。
+评测指标指不同度量精度的方法,同时可以多个评测指标共同使用,更多评测指标原理参考 {external+mmengine:doc}`MMEngine: 评测指标 `,在 MMOCR 中不同算法任务有不同的评测指标。 更多 OCR 相关的评测指标可以参考 [评测指标](../basic_concepts/evaluation.md)。
-文字检测: `HmeanIOU`
+文字检测: [`HmeanIOUMetric`](mmocr.evaluation.metrics.HmeanIOUMetric)
-文字识别: `WordMetric`,`CharMetric`, `OneMinusNEDMetric`
+文字识别: [`WordMetric`](mmocr.evaluation.metrics.WordMetric),[`CharMetric`](mmocr.evaluation.metrics.CharMetric), [`OneMinusNEDMetric`](mmocr.evaluation.metrics.OneMinusNEDMetric)
-关键信息提取: `F1Metric`
+关键信息提取: [`F1Metric`](mmocr.evaluation.metrics.F1Metric)
以文本检测为例说明,在单数据集评测情况下,使用单个 `Metric`:
@@ -565,7 +563,7 @@ val_evaluator = dict(
val_evaluator = dict(type='HmeanIOUMetric')
```
-以文本识别为例,多数据集使用多个 `Metric` 评测:
+以文本识别为例,对多个数据集(IC13 和 IC15)用多个 `Metric` (`WordMetric` 和 `CharMetric`)进行评测:
```Python
# 评测部分
@@ -585,7 +583,7 @@ test_evaluator = val_evaluator
### 可视化配置
-每个任务配置该任务对应的可视化器。可视化器主要用于用户模型中间结果的可视化或存储,及 val 和 test 预测结果的可视化。同时可视化的结果可以通过可视化后端储存到不同的后端,比如 Wandb,TensorBoard 等。常用修改操作可见[可视化](visualization.md)。
+每个任务配置该任务对应的可视化器。可视化器主要用于用户模型中间结果的可视化或存储,及 val 和 test 预测结果的可视化。同时可视化的结果可以通过可视化后端储存到不同的后端,比如 WandB,TensorBoard 等。常用修改操作可见[可视化](visualization.md)。
文本检测的可视化默认配置如下:
@@ -599,7 +597,7 @@ visualizer = dict(
## 目录结构
-`MMOCR` 所有配置文件都放置在 `configs` 文件夹下。为了避免配置文件过长,同时提高配置文件的可复用性以及清晰性,MMOCR 利用 Config 文件的继承特性,将配置内容的八个部分做了拆分。因为每部分均与算法任务相关,因此 MMOCR 对每个任务在 Config 中提供了一个任务文件夹,即 `textdet` (文字检测任务)、`textrec` (文字识别任务)、`kie` (关键信息提取)。同时各个任务算法配置文件夹下进一步划分为两个部分:`_base_` 文件夹与诸多算法文件夹:
+`MMOCR` 所有配置文件都放置在 `configs` 文件夹下。为了避免配置文件过长,同时提高配置文件的可复用性以及清晰性,MMOCR 利用 Config 文件的继承特性,将配置内容的八个部分做了拆分。因为每部分均与算法任务相关,因此 MMOCR 对每个任务在 Config 中提供了一个任务文件夹,即 `textdet` (文字检测任务)、`textrecog` (文字识别任务)、`kie` (关键信息提取)。同时各个任务算法配置文件夹下进一步划分为两个部分:`_base_` 文件夹与诸多算法文件夹:
1. `_base_` 文件夹下主要存放与具体算法无关的一些通用配置文件,各部分依目录分为常用的数据集、常用的训练策略以及通用的运行配置。
@@ -607,7 +605,7 @@ visualizer = dict(
1. 算法的模型与数据流水线:OCR 领域中一般情况下数据增强策略与算法强相关,因此模型与数据流水线通常置于统一位置。
- 2. 算法在制定数据集上的特定配置:用于训练和测试的配置,将分散在不同位置的配置汇总。同时修改或配置一些在该数据集特有的配置比如batch size以及一些可能修改如数据流水线,训练策略等
+ 2. 算法在制定数据集上的特定配置:用于训练和测试的配置,将分散在不同位置的 *base* 配置汇总。同时可能会修改一些`_base_`中的变量,如batch size, 数据流水线,训练策略等
最后的将配置内容中的各个模块分布在不同配置文件中,最终各配置文件内容如下:
@@ -632,12 +630,12 @@ visualizer = dict(
数据集配置 |
- | schedulers |
+ schedules |
schedule_adam_600e.py
... |
训练策略配置 |
- defaults_runtime.py
|
+ default_runtime.py
|
- |
环境配置
默认hook配置
日志配置
权重加载配置
评测配置
可视化配置 |
@@ -658,7 +656,7 @@ visualizer = dict(
最终目录结构如下:
```Python
-config
+configs
├── textdet
│ ├── _base_
│ │ ├── datasets
@@ -699,7 +697,7 @@ MMOCR 按照以下风格进行配置文件命名,代码库的贡献者需要
{{算法信息}}_{{模块信息}}_{{训练信息}}_{{数据信息}}.py
```
-- 算法信息(algorithm info):算法名称,如 DBNet,CRNN 等
+- 算法信息(algorithm info):算法名称,如 dbnet, crnn 等
- 模块信息(module info):按照数据流的顺序列举一些中间的模块,其内容依赖于算法任务,同时为了避免Config过长,会省略一些与模型强相关的模块。下面举例说明:
@@ -717,7 +715,7 @@ MMOCR 按照以下风格进行配置文件命名,代码库的贡献者需要
{{算法信息}}_{{backbone}}_{{encoder}}_{{decoder}}_{{训练信息}}_{{数据信息}}.py
```
- 一般情况下 encode 和 decoder 位置一般为算法专有,因此一般省略。
+ 一般情况下 encoder 和 decoder 位置一般为算法专有,因此一般省略。
- 训练信息(training info):训练策略的一些设置,包括 batch size,schedule 等
From 794744826e5d0c7d7fd24eb89a54982bfc06be6d Mon Sep 17 00:00:00 2001
From: liukuikun <24622904+Harold-lkk@users.noreply.github.com>
Date: Fri, 23 Sep 2022 14:53:48 +0800
Subject: [PATCH 15/32] [Config] auto scale lr (#1326)
---
configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt-openset.py | 1 +
configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt.py | 2 ++
configs/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py | 2 ++
configs/textdet/dbnet/dbnet_resnet18_fpnc_100k_synthtext.py | 2 ++
configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py | 2 ++
.../textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_100k_synthtext.py | 2 ++
.../textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py | 2 ++
.../dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_100k_synthtext.py | 2 ++
.../dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015.py | 2 ++
configs/textdet/drrg/drrg_resnet50_fpn-unet_1200e_ctw1500.py | 2 ++
.../textdet/fcenet/fcenet_resnet50-dcnv2_fpn_1500e_ctw1500.py | 2 ++
configs/textdet/fcenet/fcenet_resnet50_fpn_1500e_icdar2015.py | 2 ++
configs/textdet/maskrcnn/mask-rcnn_resnet50_fpn_160e_ctw1500.py | 2 ++
.../textdet/maskrcnn/mask-rcnn_resnet50_fpn_160e_icdar2015.py | 2 ++
configs/textdet/panet/panet_resnet18_fpem-ffm_600e_ctw1500.py | 2 ++
configs/textdet/panet/panet_resnet18_fpem-ffm_600e_icdar2015.py | 2 ++
configs/textdet/panet/panet_resnet50_fpem-ffm_600e_icdar2017.py | 2 ++
configs/textdet/psenet/psenet_resnet50_fpnf_600e_ctw1500.py | 2 ++
configs/textdet/psenet/psenet_resnet50_fpnf_600e_icdar2015.py | 2 ++
configs/textdet/psenet/psenet_resnet50_fpnf_600e_icdar2017.py | 2 ++
.../textsnake/textsnake_resnet50_fpn-unet_1200e_ctw1500.py | 2 ++
configs/textrecog/abinet/abinet-vision_20e_st-an_mj.py | 2 ++
configs/textrecog/abinet/abinet_20e_st-an_mj.py | 2 ++
configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py | 2 ++
configs/textrecog/master/master_resnet31_12e_st_mj_sa.py | 2 ++
configs/textrecog/nrtr/nrtr_modality-transform_6e_st_mj.py | 2 ++
configs/textrecog/nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj.py | 2 ++
.../robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py | 2 ++
.../sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real.py | 2 ++
configs/textrecog/satrn/satrn_shallow_5e_st_mj.py | 2 ++
30 files changed, 59 insertions(+)
diff --git a/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt-openset.py b/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt-openset.py
index 716661930..bc3d52a1c 100644
--- a/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt-openset.py
+++ b/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt-openset.py
@@ -68,3 +68,4 @@
visualizer = dict(
type='KIELocalVisualizer', name='visualizer', is_openset=True)
+auto_scale_lr = dict(base_batch_size=4)
diff --git a/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt.py b/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt.py
index 6f979e91c..b56c2b9b6 100644
--- a/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt.py
+++ b/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt.py
@@ -24,3 +24,5 @@
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=wildreceipt_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=4)
diff --git a/configs/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py b/configs/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py
index 030f3b2c8..d49cbbc33 100644
--- a/configs/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py
+++ b/configs/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py
@@ -25,3 +25,5 @@
dataset=wildreceipt_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=4)
diff --git a/configs/textdet/dbnet/dbnet_resnet18_fpnc_100k_synthtext.py b/configs/textdet/dbnet/dbnet_resnet18_fpnc_100k_synthtext.py
index dba5fd966..c992475cd 100644
--- a/configs/textdet/dbnet/dbnet_resnet18_fpnc_100k_synthtext.py
+++ b/configs/textdet/dbnet/dbnet_resnet18_fpnc_100k_synthtext.py
@@ -26,3 +26,5 @@
dataset=st_det_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=16)
diff --git a/configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py b/configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py
index 5294552d0..13751a4ae 100644
--- a/configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py
+++ b/configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py
@@ -26,3 +26,5 @@
dataset=ic15_det_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=16)
diff --git a/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_100k_synthtext.py b/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_100k_synthtext.py
index 63919808a..19c94f89a 100644
--- a/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_100k_synthtext.py
+++ b/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_100k_synthtext.py
@@ -26,3 +26,5 @@
dataset=st_det_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=16)
diff --git a/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py b/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py
index ab05a2f23..074cf74b4 100644
--- a/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py
+++ b/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py
@@ -29,3 +29,5 @@
dataset=ic15_det_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=16)
diff --git a/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_100k_synthtext.py b/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_100k_synthtext.py
index 6a12fb549..078cb9583 100644
--- a/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_100k_synthtext.py
+++ b/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_100k_synthtext.py
@@ -30,3 +30,5 @@
pipeline=_base_.test_pipeline))
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=16)
diff --git a/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015.py b/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015.py
index be14e04f3..6fe192657 100644
--- a/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015.py
+++ b/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015.py
@@ -30,3 +30,5 @@
pipeline=_base_.test_pipeline))
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=16)
diff --git a/configs/textdet/drrg/drrg_resnet50_fpn-unet_1200e_ctw1500.py b/configs/textdet/drrg/drrg_resnet50_fpn-unet_1200e_ctw1500.py
index 6f876ce87..c6a42b079 100644
--- a/configs/textdet/drrg/drrg_resnet50_fpn-unet_1200e_ctw1500.py
+++ b/configs/textdet/drrg/drrg_resnet50_fpn-unet_1200e_ctw1500.py
@@ -26,3 +26,5 @@
dataset=ctw_det_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=16)
diff --git a/configs/textdet/fcenet/fcenet_resnet50-dcnv2_fpn_1500e_ctw1500.py b/configs/textdet/fcenet/fcenet_resnet50-dcnv2_fpn_1500e_ctw1500.py
index 9e61f8831..c08bb16ed 100644
--- a/configs/textdet/fcenet/fcenet_resnet50-dcnv2_fpn_1500e_ctw1500.py
+++ b/configs/textdet/fcenet/fcenet_resnet50-dcnv2_fpn_1500e_ctw1500.py
@@ -54,3 +54,5 @@
dataset=ctw_det_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=8)
diff --git a/configs/textdet/fcenet/fcenet_resnet50_fpn_1500e_icdar2015.py b/configs/textdet/fcenet/fcenet_resnet50_fpn_1500e_icdar2015.py
index 93d332d02..5ad6fab31 100644
--- a/configs/textdet/fcenet/fcenet_resnet50_fpn_1500e_icdar2015.py
+++ b/configs/textdet/fcenet/fcenet_resnet50_fpn_1500e_icdar2015.py
@@ -33,3 +33,5 @@
dataset=ic15_det_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=8)
diff --git a/configs/textdet/maskrcnn/mask-rcnn_resnet50_fpn_160e_ctw1500.py b/configs/textdet/maskrcnn/mask-rcnn_resnet50_fpn_160e_ctw1500.py
index 5c269aa2e..fb0186557 100644
--- a/configs/textdet/maskrcnn/mask-rcnn_resnet50_fpn_160e_ctw1500.py
+++ b/configs/textdet/maskrcnn/mask-rcnn_resnet50_fpn_160e_ctw1500.py
@@ -55,3 +55,5 @@
dataset=ctw_det_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=8)
diff --git a/configs/textdet/maskrcnn/mask-rcnn_resnet50_fpn_160e_icdar2015.py b/configs/textdet/maskrcnn/mask-rcnn_resnet50_fpn_160e_icdar2015.py
index 07ff14262..399619c9a 100644
--- a/configs/textdet/maskrcnn/mask-rcnn_resnet50_fpn_160e_icdar2015.py
+++ b/configs/textdet/maskrcnn/mask-rcnn_resnet50_fpn_160e_icdar2015.py
@@ -35,3 +35,5 @@
dataset=ic15_det_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=8)
diff --git a/configs/textdet/panet/panet_resnet18_fpem-ffm_600e_ctw1500.py b/configs/textdet/panet/panet_resnet18_fpem-ffm_600e_ctw1500.py
index d7142ddce..166b4b146 100644
--- a/configs/textdet/panet/panet_resnet18_fpem-ffm_600e_ctw1500.py
+++ b/configs/textdet/panet/panet_resnet18_fpem-ffm_600e_ctw1500.py
@@ -82,3 +82,5 @@
val_evaluator = dict(
type='HmeanIOUMetric', pred_score_thrs=dict(start=0.3, stop=1, step=0.05))
test_evaluator = val_evaluator
+
+auto_scale_lr = dict(base_batch_size=16)
diff --git a/configs/textdet/panet/panet_resnet18_fpem-ffm_600e_icdar2015.py b/configs/textdet/panet/panet_resnet18_fpem-ffm_600e_icdar2015.py
index efeb070d9..4a03cb2dc 100644
--- a/configs/textdet/panet/panet_resnet18_fpem-ffm_600e_icdar2015.py
+++ b/configs/textdet/panet/panet_resnet18_fpem-ffm_600e_icdar2015.py
@@ -31,3 +31,5 @@
val_evaluator = dict(
type='HmeanIOUMetric', pred_score_thrs=dict(start=0.3, stop=1, step=0.05))
test_evaluator = val_evaluator
+
+auto_scale_lr = dict(base_batch_size=64)
diff --git a/configs/textdet/panet/panet_resnet50_fpem-ffm_600e_icdar2017.py b/configs/textdet/panet/panet_resnet50_fpem-ffm_600e_icdar2017.py
index 489aa1542..ba8d37c46 100644
--- a/configs/textdet/panet/panet_resnet50_fpem-ffm_600e_icdar2017.py
+++ b/configs/textdet/panet/panet_resnet50_fpem-ffm_600e_icdar2017.py
@@ -77,3 +77,5 @@
val_evaluator = dict(
type='HmeanIOUMetric', pred_score_thrs=dict(start=0.3, stop=1, step=0.05))
test_evaluator = val_evaluator
+
+auto_scale_lr = dict(base_batch_size=64)
diff --git a/configs/textdet/psenet/psenet_resnet50_fpnf_600e_ctw1500.py b/configs/textdet/psenet/psenet_resnet50_fpnf_600e_ctw1500.py
index 7fa4eb298..9f36af2c6 100644
--- a/configs/textdet/psenet/psenet_resnet50_fpnf_600e_ctw1500.py
+++ b/configs/textdet/psenet/psenet_resnet50_fpnf_600e_ctw1500.py
@@ -51,3 +51,5 @@
dataset=ctw_det_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=64 * 4)
diff --git a/configs/textdet/psenet/psenet_resnet50_fpnf_600e_icdar2015.py b/configs/textdet/psenet/psenet_resnet50_fpnf_600e_icdar2015.py
index 11d7ecf8a..fc5561780 100644
--- a/configs/textdet/psenet/psenet_resnet50_fpnf_600e_icdar2015.py
+++ b/configs/textdet/psenet/psenet_resnet50_fpnf_600e_icdar2015.py
@@ -40,3 +40,5 @@
dataset=ic15_det_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=64 * 4)
diff --git a/configs/textdet/psenet/psenet_resnet50_fpnf_600e_icdar2017.py b/configs/textdet/psenet/psenet_resnet50_fpnf_600e_icdar2017.py
index ad472a21f..a813ea08a 100644
--- a/configs/textdet/psenet/psenet_resnet50_fpnf_600e_icdar2017.py
+++ b/configs/textdet/psenet/psenet_resnet50_fpnf_600e_icdar2017.py
@@ -12,3 +12,5 @@
train_dataloader = dict(dataset=ic17_det_train)
val_dataloader = dict(dataset=ic17_det_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=64 * 4)
diff --git a/configs/textdet/textsnake/textsnake_resnet50_fpn-unet_1200e_ctw1500.py b/configs/textdet/textsnake/textsnake_resnet50_fpn-unet_1200e_ctw1500.py
index 484b4f26f..525c397fa 100644
--- a/configs/textdet/textsnake/textsnake_resnet50_fpn-unet_1200e_ctw1500.py
+++ b/configs/textdet/textsnake/textsnake_resnet50_fpn-unet_1200e_ctw1500.py
@@ -26,3 +26,5 @@
dataset=ctw_det_test)
test_dataloader = val_dataloader
+
+auto_scale_lr = dict(base_batch_size=4)
diff --git a/configs/textrecog/abinet/abinet-vision_20e_st-an_mj.py b/configs/textrecog/abinet/abinet-vision_20e_st-an_mj.py
index b6f220b85..39a60f783 100644
--- a/configs/textrecog/abinet/abinet-vision_20e_st-an_mj.py
+++ b/configs/textrecog/abinet/abinet-vision_20e_st-an_mj.py
@@ -54,3 +54,5 @@
val_evaluator = dict(
dataset_prefixes=['CUTE80', 'IIIT5K', 'SVT', 'SVTP', 'IC13', 'IC15'])
test_evaluator = val_evaluator
+
+auto_scale_lr = dict(base_batch_size=192 * 8)
diff --git a/configs/textrecog/abinet/abinet_20e_st-an_mj.py b/configs/textrecog/abinet/abinet_20e_st-an_mj.py
index 078bebf40..85b00cd9d 100644
--- a/configs/textrecog/abinet/abinet_20e_st-an_mj.py
+++ b/configs/textrecog/abinet/abinet_20e_st-an_mj.py
@@ -54,3 +54,5 @@
val_evaluator = dict(
dataset_prefixes=['CUTE80', 'IIIT5K', 'SVT', 'SVTP', 'IC13', 'IC15'])
test_evaluator = val_evaluator
+
+auto_scale_lr = dict(base_batch_size=192 * 8)
diff --git a/configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py b/configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py
index 7fd16506c..acc76cdde 100644
--- a/configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py
+++ b/configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py
@@ -45,3 +45,5 @@
val_evaluator = dict(
dataset_prefixes=['CUTE80', 'IIIT5K', 'SVT', 'SVTP', 'IC13', 'IC15'])
test_evaluator = val_evaluator
+
+auto_scale_lr = dict(base_batch_size=64 * 4)
diff --git a/configs/textrecog/master/master_resnet31_12e_st_mj_sa.py b/configs/textrecog/master/master_resnet31_12e_st_mj_sa.py
index 214b2db5e..4695e4cfb 100644
--- a/configs/textrecog/master/master_resnet31_12e_st_mj_sa.py
+++ b/configs/textrecog/master/master_resnet31_12e_st_mj_sa.py
@@ -55,3 +55,5 @@
val_evaluator = dict(
dataset_prefixes=['CUTE80', 'IIIT5K', 'SVT', 'SVTP', 'IC13', 'IC15'])
test_evaluator = val_evaluator
+
+auto_scale_lr = dict(base_batch_size=512 * 4)
diff --git a/configs/textrecog/nrtr/nrtr_modality-transform_6e_st_mj.py b/configs/textrecog/nrtr/nrtr_modality-transform_6e_st_mj.py
index 452831ed7..89784a0e7 100644
--- a/configs/textrecog/nrtr/nrtr_modality-transform_6e_st_mj.py
+++ b/configs/textrecog/nrtr/nrtr_modality-transform_6e_st_mj.py
@@ -51,3 +51,5 @@
val_evaluator = dict(
dataset_prefixes=['CUTE80', 'IIIT5K', 'SVT', 'SVTP', 'IC13', 'IC15'])
test_evaluator = val_evaluator
+
+auto_scale_lr = dict(base_batch_size=384)
diff --git a/configs/textrecog/nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj.py b/configs/textrecog/nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj.py
index f82980aed..3cc9a0d33 100644
--- a/configs/textrecog/nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj.py
+++ b/configs/textrecog/nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj.py
@@ -51,3 +51,5 @@
val_evaluator = dict(
dataset_prefixes=['CUTE80', 'IIIT5K', 'SVT', 'SVTP', 'IC13', 'IC15'])
test_evaluator = val_evaluator
+
+auto_scale_lr = dict(base_batch_size=384)
diff --git a/configs/textrecog/robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py b/configs/textrecog/robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py
index 5438cef90..2a9edbf15 100644
--- a/configs/textrecog/robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py
+++ b/configs/textrecog/robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py
@@ -64,3 +64,5 @@
val_evaluator = dict(
dataset_prefixes=['CUTE80', 'IIIT5K', 'SVT', 'SVTP', 'IC13', 'IC15'])
test_evaluator = val_evaluator
+
+auto_scale_lr = dict(base_batch_size=64 * 16)
diff --git a/configs/textrecog/sar/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real.py b/configs/textrecog/sar/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real.py
index 96626e48f..cfcdf5028 100644
--- a/configs/textrecog/sar/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real.py
+++ b/configs/textrecog/sar/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real.py
@@ -63,3 +63,5 @@
val_evaluator = dict(
dataset_prefixes=['CUTE80', 'IIIT5K', 'SVT', 'SVTP', 'IC13', 'IC15'])
test_evaluator = val_evaluator
+
+auto_scale_lr = dict(base_batch_size=64 * 48)
diff --git a/configs/textrecog/satrn/satrn_shallow_5e_st_mj.py b/configs/textrecog/satrn/satrn_shallow_5e_st_mj.py
index 76b647585..16a7ef50c 100644
--- a/configs/textrecog/satrn/satrn_shallow_5e_st_mj.py
+++ b/configs/textrecog/satrn/satrn_shallow_5e_st_mj.py
@@ -47,3 +47,5 @@
val_evaluator = dict(
dataset_prefixes=['CUTE80', 'IIIT5K', 'SVT', 'SVTP', 'IC13', 'IC15'])
test_evaluator = val_evaluator
+
+auto_scale_lr = dict(base_batch_size=64 * 8)
From e9d436484287481b47e351cb440f067be9ae170d Mon Sep 17 00:00:00 2001
From: Tong Gao
Date: Fri, 23 Sep 2022 14:54:28 +0800
Subject: [PATCH 16/32] [Fix] ImgAugWrapper: Do not cilp polygons if not
applicables (#1231)
---
mmocr/datasets/transforms/wrappers.py | 7 ++++++-
1 file changed, 6 insertions(+), 1 deletion(-)
diff --git a/mmocr/datasets/transforms/wrappers.py b/mmocr/datasets/transforms/wrappers.py
index f64ffa18e..7a3489ee5 100644
--- a/mmocr/datasets/transforms/wrappers.py
+++ b/mmocr/datasets/transforms/wrappers.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
from typing import Any, Dict, List, Optional, Tuple, Union
import imgaug
@@ -154,7 +155,11 @@ def _augment_polygons(self, aug: imgaug.augmenters.meta.Augmenter,
removed_poly_inds.append(i)
continue
new_poly = []
- for point in poly.clip_out_of_image(imgaug_polys.shape)[0]:
+ try:
+ poly = poly.clip_out_of_image(imgaug_polys.shape)[0]
+ except Exception as e:
+ warnings.warn(f'Failed to clip polygon out of image: {e}')
+ for point in poly:
new_poly.append(np.array(point, dtype=np.float32))
new_poly = np.array(new_poly, dtype=np.float32).flatten()
# Under some conditions, imgaug can generate "polygon" with only
From 5a88a771c305311fff1e37b45add5f2831d1ff30 Mon Sep 17 00:00:00 2001
From: Xinyu Wang <45810070+xinke-wang@users.noreply.github.com>
Date: Mon, 26 Sep 2022 14:11:04 +0800
Subject: [PATCH 17/32] [Docs] Metrics (#1399)
* init
* fix math
* fix
* apply comments
Co-authored-by: Tong Gao
* apply comments
Co-authored-by: Tong Gao
* apply comments
Co-authored-by: Tong Gao
* fix comments
* update
* update
Co-authored-by: Tong Gao
---
docs/en/basic_concepts/evaluation.md | 196 ++++++++++++++++++++++-
docs/zh_cn/basic_concepts/evaluation.md | 199 +++++++++++++++++++++++-
2 files changed, 392 insertions(+), 3 deletions(-)
diff --git a/docs/en/basic_concepts/evaluation.md b/docs/en/basic_concepts/evaluation.md
index b5313a418..540be3a4d 100644
--- a/docs/en/basic_concepts/evaluation.md
+++ b/docs/en/basic_concepts/evaluation.md
@@ -1,3 +1,197 @@
# Evaluation
-Coming Soon!
+```{note}
+Before reading this document, we recommend that you first read {external+mmengine:doc}`MMEngine: Model Accuracy Evaluation Basics `.
+```
+
+## Metrics
+
+MMOCR implements widely-used evaluation metrics for text detection, text recognition and key information extraction tasks based on the {external+mmengine:doc}`MMEngine: BaseMetric ` base class. Users can specify the metric used in the validation and test phases by modifying the `val_evaluator` and `test_evaluator` fields in the configuration file. For example, the following config shows how to use `HmeanIOUMetric` to evaluate the model performance in text detection task.
+
+```python
+val_evaluator = dict(type='HmeanIOUMetric')
+test_evaluator = val_evaluator
+
+# In addition, MMOCR also supports the combined evaluation of multiple metrics for the same task, such as using WordMetric and CharMetric at the same time
+val_evaluator = [
+ dict(type='WordMetric', mode=['exact', 'ignore_case', 'ignore_case_symbol']),
+ dict(type='CharMetric')
+]
+```
+
+```{tip}
+More evaluation related configurations can be found in the [evaluation configuration tutorial](../user_guides/config.md#evaluation-configuration).
+```
+
+As shown in the following table, MMOCR currently supports 5 evaluation metrics for text detection, text recognition, and key information extraction tasks, including `HmeanIOUMetric`, `WordMetric`, `CharMetric`, `OneMinusNEDMetric`, and `F1Metric`.
+
+| | | | |
+| --------------------------------------- | ------- | ------------------------------------------------- | --------------------------------------------------------------------- |
+| Metric | Task | Input Field | Output Field |
+| [HmeanIOUMetric](#hmeanioumetric) | TextDet | `pred_polygons`
`pred_scores`
`gt_polygons` | `recall`
`precision`
`hmean` |
+| [WordMetric](#wordmetric) | TextRec | `pred_text`
`gt_text` | `word_acc`
`word_acc_ignore_case`
`word_acc_ignore_case_symbol` |
+| [CharMetric](#charmetric) | TextRec | `pred_text`
`gt_text` | `char_recall`
`char_precision` |
+| [OneMinusNEDMetric](#oneminusnedmetric) | TextRec | `pred_text`
`gt_text` | `1-N.E.D` |
+| [F1Metric](#f1metric) | KIE | `pred_labels`
`gt_labels` | `macro_f1`
`micro_f1` |
+
+In general, the evaluation metric used in each task is conventionally determined. Users usually do not need to understand or manually modify the internal implementation of the evaluation metric. However, to facilitate more customized requirements, this document will further introduce the specific implementation details and configurable parameters of the built-in metrics in MMOCR.
+
+### HmeanIOUMetric
+
+[HmeanIOUMetric](mmocr.evaluation.metrics.hmean_iou_metric.HmeanIOUMetric) is one of the most widely used evaluation metrics in text detection tasks, because it calculates the harmonic mean (H-mean) between the detection precision (P) and recall rate (R). The `HmeanIOUMetric` can be calculated by the following equation:
+
+```{math}
+H = \frac{2}{\frac{1}{P} + \frac{1}{R}} = \frac{2PR}{P+R}
+```
+
+In addition, since it is equivalent to the F-score (also known as F-measure or F-metric) when {math}`\beta = 1`, `HmeanIOUMetric` is sometimes written as `F1Metric` or `f1-score`:
+
+```{math}
+F_1=(1+\beta^2)\cdot\frac{PR}{\beta^2\cdot P+R} = \frac{2PR}{P+R}
+```
+
+In MMOCR, the calculation of `HmeanIOUMetric` can be summarized as the following steps:
+
+1. Filter out invalid predictions
+
+ - Filter out predictions with a score is lower than `pred_score_thrs`
+ - Filter out predictions overlapping with `ignored` ground truth boxes with an overlap ratio higher than `ignore_precision_thr`
+
+ It is worth noting that `pred_score_thrs` will **automatically search** for the **best threshold** within a certain range by default, and users can also customize the search range by manually modifying the configuration file:
+
+ ```python
+ # By default, HmeanIOUMetric searches the best threshold within the range [0.3, 0.9] with a step size of 0.1
+ val_evaluator = dict(type='HmeanIOUMetric', pred_score_thrs=dict(start=0.3, stop=0.9, step=0.1))
+ ```
+
+2. Calculate the IoU matrix
+
+ - At the data processing stage, `HmeanIOUMetric` will calculate and maintain an {math}`M \times N` IoU matrix `iou_metric` for the convenience of the subsequent bounding box pairing step. Here, M and N represent the number of label bounding boxes and filtered prediction bounding boxes, respectively. Therefore, each element of this matrix stores the IoU between the m-th label bounding box and the n-th prediction bounding box.
+
+3. Compute the number of GT samples that can be accurately matched based on the corresponding pairing strategy
+
+ Although `HmeanIOUMetric` can be calculated by a fixed formula, there may still be some subtle differences in the specific implementations. These differences mainly reflect the use of different strategies to match gt and predicted bounding boxes, which leads to the difference in final scores. Currently, MMOCR supports two matching strategies, namely `vanilla` and `max_matching`, for the `HmeanIOUMetric`. As shown below, users can specify the matching strategies in the config.
+
+ - `vanilla` matching strategy
+
+ By default, `HmeanIOUMetric` adopts the `vanilla` matching strategy, which is consistent with the `hmean-iou` implementation in MMOCR 0.x and the **official** text detection competition evaluation standard of ICDAR series. The matching strategy adopts the first-come-first-served matching method to pair the labels and predictions.
+
+ ```python
+ # By default, HmeanIOUMetric adopts 'vanilla' matching strategy
+ val_evaluator = dict(type='HmeanIOUMetric')
+ ```
+
+ - `max_matching` matching strategy
+
+ To address the shortcomings of the existing matching mechanism, MMOCR has implemented a more efficient matching strategy to maximize the number of matches.
+
+ ```python
+ # Specify to use 'max_matching' matching strategy
+ val_evaluator = dict(type='HmeanIOUMetric', strategy='max_matching')
+ ```
+
+ ```{note}
+ We recommend that research-oriented developers use the default `vanilla` matching strategy to ensure consistency with other papers. For industry-oriented developers, you can use the `max_matching` matching strategy to achieve optimized performance.
+ ```
+
+4. Compute the final evaluation score according to the aforementioned matching strategy
+
+### WordMetric
+
+[WordMetric](mmocr.evaluation.metrics.recog_metric.WordMetric) implements **word-level** text recognition evaluation metrics and includes three text matching modes, namely `exact`, `ignore_case`, and `ignore_case_symbol`. Users can freely combine the output of one or more text matching modes in the configuration file by modifying the `mode` field.
+
+```python
+# Use WordMetric for text recognition task
+val_evaluator = [
+ dict(type='WordMetric', mode=['exact', 'ignore_case', 'ignore_case_symbol'])
+]
+```
+
+- `exact`:Full matching mode, i.e., only when the predicted text and the ground truth text are exactly the same, the predicted text is considered to be correct.
+- `ignore_case`:The mode ignores the case of the predicted text and the ground truth text.
+- `ignore_case_symbol`:The mode ignores the case and symbols of the predicted text and the ground truth text. This is also the text recognition accuracy reported by most academic papers. The performance reported by MMOCR uses the `ignore_case_symbol` mode by default.
+
+Assume that the real label is `MMOCR!` and the model output is `mmocr`. The `WordMetric` scores under the three matching modes are: `{'exact': 0, 'ignore_case': 0, 'ignore_case_symbol': 1}`.
+
+### CharMetric
+
+[CharMetric](mmocr.evaluation.metrics.recog_metric.CharMetric) implements **character-level** text recognition evaluation metrics that are **case-insensitive**.
+
+```python
+# Use CharMetric for text recognition task
+val_evaluator = [dict(type='CharMetric')]
+```
+
+Specifically, `CharMetric` will output two evaluation metrics, namely `char_precision` and `char_recall`. Let the number of correctly predicted characters (True Positive) be {math}`\sigma_{tp}`, then the precision *P* and recall *R* can be calculated by the following equation:
+
+```{math}
+P=\frac{\sigma_{tp}}{\sigma_{gt}}, R = \frac{\sigma_{tp}}{\sigma_{pred}}
+```
+
+where {math}`\sigma_{gt}` and {math}`\sigma_{pred}` represent the total number of characters in the label text and the predicted text, respectively.
+
+For example, assume that the label text is "MM**O**CR" and the predicted text is "mm**0**cR**1**". The score of the `CharMetric` is:
+
+```{math}
+P=\frac{4}{5}, R=\frac{4}{6}
+```
+
+### OneMinusNEDMetric
+
+[OneMinusNEDMetric(1-N.E.D)](mmocr.evaluation.metrics.recog_metric.OneMinusNEDMetric) is commonly used for text recognition evaluation of Chinese or English **text line-level** annotations. Unlike the full matching metric that requires the prediction and the gt text to be exactly the same, `1-N.E.D` uses the normalized [edit distance](https://en.wikipedia.org/wiki/Edit_distance) (also known as Levenshtein Distance) to measure the difference between the predicted and the gt text, so that the performance difference of the model can be better distinguished when evaluating long texts. Assume that the real and predicted texts are {math}`s_i` and {math}`\hat{s_i}`, respectively, and their lengths are {math}`l_{i}` and {math}`\hat{l_i}`, respectively. The `OneMinusNEDMetric` score can be calculated by the following formula:
+
+```{math}
+score = 1 - \frac{1}{N}\sum_{i=1}^{N}\frac{D(s_i, \hat{s_{i}})}{max(l_{i},\hat{l_{i}})}
+```
+
+where *N* is the total number of samples, and {math}`D(s_1, s_2)` is the edit distance between two strings.
+
+For example, assume that the real label is "OpenMMLabMMOCR", the prediction of model A is "0penMMLabMMOCR", and the prediction of model B is "uvwxyz". The results of the full matching and `OneMinusNEDMetric` evaluation metrics are as follows:
+
+| | | |
+| ------- | ---------- | ---------- |
+| | Full-match | 1 - N.E.D. |
+| Model A | 0 | 0.92857 |
+| Model B | 0 | 0 |
+
+As shown in the table above, although the model A only predicted one letter incorrectly, both models got 0 in when using full-match strategy. However, the `OneMinusNEDMetric` evaluation metric can better distinguish the performance of the two models on **long texts**.
+
+### F1Metric
+
+[F1Metric](mmocr.evaluation.metrics.f_metric.F1Metric) implements the F1-Metric evaluation metric for KIE tasks and provides two modes, namely `micro` and `macro`.
+
+```python
+val_evaluator = [
+ dict(type='F1Metric', mode=['micro', 'macro'],
+]
+```
+
+- `micro` mode: Calculate the global F1-Metric score based on the total number of True Positive, False Negative, and False Positive.
+
+- `macro` mode:Calculate the F1-Metric score for each class and then take the average.
+
+### Customized Metric
+
+MMOCR supports the implementation of customized evaluation metrics for users who pursue higher customization. In general, users only need to create a customized evaluation metric class `CustomizedMetric` and inherit {external+mmengine:doc}`MMEngine: BaseMetric `. Then, the data format processing method `process` and the metric calculation method `compute_metrics` need to be overwritten respectively. Finally, add it to the `METRICS` registry to implement any customized evaluation metric.
+
+```python
+from mmengine.evaluator import BaseMetric
+from mmocr.registry import METRICS
+
+@METRICS.register_module()
+class CustomizedMetric(BaseMetric):
+
+ def process(self, data_batch: Sequence[Dict], predictions: Sequence[Dict]):
+ """ process receives two parameters, data_batch stores the gt label information, and predictions stores the predicted results.
+ """
+ pass
+
+ def compute_metrics(self, results: List):
+ """ compute_metric receives the results of the process method as input and returns the evaluation results.
+ """
+ pass
+```
+
+```{note}
+More details can be found in {external+mmengine:doc}`MMEngine Documentation: BaseMetric `.
+```
diff --git a/docs/zh_cn/basic_concepts/evaluation.md b/docs/zh_cn/basic_concepts/evaluation.md
index 8d1229e5c..272754c00 100644
--- a/docs/zh_cn/basic_concepts/evaluation.md
+++ b/docs/zh_cn/basic_concepts/evaluation.md
@@ -1,3 +1,198 @@
-# 评估
+# 模型评测
-待更新
+```{note}
+阅读此文档前,建议您先了解 {external+mmengine:doc}`MMEngine: 模型精度评测基本概念 `。
+```
+
+## 评测指标
+
+MMOCR 基于 {external+mmengine:doc}`MMEngine: BaseMetric ` 基类实现了常用的文本检测、文本识别以及关键信息抽取任务的评测指标,用户可以通过修改配置文件中的 `val_evaluator` 与 `test_evaluator` 字段来便捷地指定验证与测试阶段采用的评测方法。例如,以下配置展示了如何在文本检测算法中使用 `HmeanIOUMetric` 来评测模型性能。
+
+```python
+# 文本检测任务中通常使用 HmeanIOUMetric 来评测模型性能
+val_evaluator = [dict(type='HmeanIOUMetric')]
+
+# 此外,MMOCR 也支持相同任务下的多种指标组合评测,如同时使用 WordMetric 及 CharMetric
+val_evaluator = [
+ dict(type='WordMetric', mode=['exact', 'ignore_case', 'ignore_case_symbol']),
+ dict(type='CharMetric')
+]
+```
+
+```{tip}
+更多评测相关配置请参考[评测配置教程](../user_guides/config.md#评测配置)。
+```
+
+如下表所示,MMOCR 目前针对文本检测、识别、及关键信息抽取等任务共内置了 5 种评测指标,分别为 `HmeanIOUMetric`,`WordMetric`,`CharMetric`,`OneMinusNEDMetric`,和 `F1Metric`。
+
+| | | | |
+| --------------------------------------- | ------------ | ------------------------------------------------- | --------------------------------------------------------------------- |
+| 评测指标 | 任务类型 | 输入字段 | 输出字段 |
+| [HmeanIOUMetric](#hmeanioumetric) | 文本检测 | `pred_polygons`
`pred_scores`
`gt_polygons` | `recall`
`precision`
`hmean` |
+| [WordMetric](#wordmetric) | 文本识别 | `pred_text`
`gt_text` | `word_acc`
`word_acc_ignore_case`
`word_acc_ignore_case_symbol` |
+| [CharMetric](#charmetric) | 文本识别 | `pred_text`
`gt_text` | `char_recall`
`char_precision` |
+| [OneMinusNEDMetric](#oneminusnedmetric) | 文本识别 | `pred_text`
`gt_text` | `1-N.E.D` |
+| [F1Metric](#f1metric) | 关键信息抽取 | `pred_labels`
`gt_labels` | `macro_f1`
`micro_f1` |
+
+通常来说,每一类任务所采用的评测标准是约定俗成的,用户一般无须深入了解或手动修改评测方法的内部实现。然而,为了方便用户实现更加定制化的需求,本文档将进一步介绍了 MMOCR 内置评测算法的具体实现策略,以及可配置参数。
+
+### HmeanIOUMetric
+
+[HmeanIOUMetric](mmocr.evaluation.metrics.hmean_iou_metric.HmeanIOUMetric) 是文本检测任务中应用最广泛的评测指标之一,因其计算了检测精度(Precision)与召回率(Recall)之间的调和平均数(Harmonic mean, H-mean),故得名 `HmeanIOUMetric`。记精度为 *P*,召回率为 *R*,则 `HmeanIOUMetric` 可由下式计算得到:
+
+```{math}
+H = \frac{2}{\frac{1}{P} + \frac{1}{R}} = \frac{2PR}{P+R}
+```
+
+另外,由于其等价于 {math}`\beta = 1` 时的 F-score (又称 F-measure 或 F-metric),`HmeanIOUMetric` 有时也被写作 `F1Metric` 或 `f1-score` 等:
+
+```{math}
+F_1=(1+\beta^2)\cdot\frac{PR}{\beta^2\cdot P+R} = \frac{2PR}{P+R}
+```
+
+在 MMOCR 的设计中,`HmeanIOUMetric` 的计算可以概括为以下几个步骤:
+
+1. 过滤无效的预测边界盒
+
+ - 依据置信度阈值 `pred_score_thrs` 过滤掉得分较低的预测边界盒
+ - 依据 `ignore_precision_thr` 阈值过滤掉与 `ignored` 样本重合度过高的预测边界盒
+
+ 值得注意的是,`pred_score_thrs` 默认将**自动搜索**一定范围内的**最佳阈值**,用户也可以通过手动修改配置文件来自定义搜索范围:
+
+ ```python
+ # HmeanIOUMetric 默认以 0.1 为步长搜索 [0.3, 0.9] 范围内的最佳得分阈值
+ val_evaluator = dict(type='HmeanIOUMetric', pred_score_thrs=dict(start=0.3, stop=0.9, step=0.1))
+ ```
+
+2. 计算 IoU 矩阵
+
+ - 在数据处理阶段,`HmeanIOUMetric` 会计算并维护一个 {math}`M \times N` 的 IoU 矩阵 `iou_metric`,以方便后续的边界盒配对步骤。其中,M 和 N 分别为标签边界盒与过滤后预测边界盒的数量。由此,该矩阵的每个元素都存放了第 m 个标签边界盒与第 n 个预测边界盒之间的交并比(IoU)。
+
+3. 基于相应的配对策略统计能被准确匹配的 GT 样本数
+
+ 尽管 `HmeanIOUMetric` 可以由固定的公式计算取得,不同的任务或算法库内部的具体实现仍可能存在一些细微差别。这些差异主要体现在采用不同的策略来匹配真实与预测边界盒,从而导致最终得分的差距。目前,MMOCR 内部的 `HmeanIOUMetric` 共支持两种不同的匹配策略,即 `vanilla` 与 `max_matching`。如下所示,用户可以通过修改配置文件来指定不同的匹配策略。
+
+ - `vanilla` 匹配策略
+
+ `HmeanIOUMetric` 默认采用 `vanilla` 匹配策略,该实现与 MMOCR 0.x 版本中的 `hmean-iou` 及 ICDAR 系列**官方文本检测竞赛的评测标准保持一致**,采用先到先得的匹配方式对标签边界盒(Ground-truth bbox)与预测边界盒(Predicted bbox)进行配对。
+
+ ```python
+ # 不指定 strategy 时,HmeanIOUMetric 默认采用 'vanilla' 匹配策略
+ val_evaluator = dict(type='HmeanIOUMetric')
+ ```
+
+ - `max_matching` 匹配策略
+
+ 针对现有匹配机制中的不完善之处,MMOCR 算法库实现了一套更高效的匹配策略,用以最大化匹配数目。
+
+ ```python
+ # 指定采用 'max_matching' 匹配策略
+ val_evaluator = dict(type='HmeanIOUMetric', strategy='max_matching')
+ ```
+
+ ```{note}
+ 我们建议面向学术研究的开发用户采用默认的 `vanilla` 匹配策略,以保证与其他论文的对比结果保持一致。而面向工业应用的开发用户则可以采用 `max_matching` 匹配策略,以获得精准的结果。
+ ```
+
+4. 根据上文介绍的 `HmeanIOUMetric` 公式计算最终的评测得分
+
+### WordMetric
+
+[WordMetric](mmocr.evaluation.metrics.recog_metric.WordMetric) 实现了**单词级别**的文本识别评测指标,并内置了 `exact`,`ignore_case`,及 `ignore_case_symbol` 三种文本匹配模式,用户可以在配置文件中修改 `mode` 字段来自由组合输出一种或多种文本匹配模式下的 `WordMetric` 得分。
+
+```python
+# 在文本识别任务中使用 WordMetric 评测
+val_evaluator = [
+ dict(type='WordMetric', mode=['exact', 'ignore_case', 'ignore_case_symbol'])
+]
+```
+
+- `exact`:全匹配模式,即,预测与标签完全一致才能被记录为正确样本。
+- `ignore_case`:忽略大小写的匹配模式。
+- `ignore_case_symbol`:忽略大小写及符号的匹配模式,这也是大部分学术论文中报告的文本识别准确率;MMOCR 报告的识别模型性能默认采用该匹配模式。
+
+假设真实标签为 `MMOCR!`,模型的输出结果为 `mmocr`,则三种匹配模式下的 `WordMetric` 得分分别为:`{'exact': 0, 'ignore_case': 0, 'ignore_case_symbol': 1}`。
+
+### CharMetric
+
+[CharMetric](mmocr.evaluation.metrics.recog_metric.CharMetric) 实现了**不区分大小写**的**字符级别**的文本识别评测指标。
+
+```python
+# 在文本识别任务中使用 CharMetric 评测
+val_evaluator = [dict(type='CharMetric')]
+```
+
+具体而言,`CharMetric` 会输出两个评测评测指标,即字符精度 `char_precision` 和字符召回率 `char_recall`。设正确预测的字符(True Positive)数量为 {math}`\sigma_{tp}`,则精度 *P* 和召回率 *R* 可由下式计算取得:
+
+```{math}
+P=\frac{\sigma_{tp}}{\sigma_{gt}}, R = \frac{\sigma_{tp}}{\sigma_{pred}}
+```
+
+其中,{math}`\sigma_{gt}` 与 {math}`\sigma_{pred}` 分别为标签文本与预测文本所包含的字符总数。
+
+例如,假设标签文本为 "MM**O**CR",预测文本为 "mm**0**cR**1**",则使用 `CharMetric` 评测指标的得分为:
+
+```{math}
+P=\frac{4}{5}, R=\frac{4}{6}
+```
+
+### OneMinusNEDMetric
+
+[`OneMinusNEDMetric(1-N.E.D)`](mmocr.evaluation.metrics.recog_metric.OneMinusNEDMetric) 常用于中文或英文**文本行级别**标注的文本识别评测,不同于全匹配的评测标准要求预测与真实样本完全一致,该评测指标使用归一化的[编辑距离](https://en.wikipedia.org/wiki/Edit_distance)(Edit Distance,又名莱温斯坦距离 Levenshtein Distance)来测量预测文本与真实文本之间的差异性,从而在评测长文本样本时能够更好地区分出模型的性能差异。假设真实和预测文本分别为 {math}`s_i` 和 {math}`\hat{s_i}`,其长度分别为 {math}`l_{i}` 和 {math}`\hat{l_i}`,则 `OneMinusNEDMetric` 得分可由下式计算得到:
+
+```{math}
+score = 1 - \frac{1}{N}\sum_{i=1}^{N}\frac{D(s_i, \hat{s_{i}})}{max(l_{i},\hat{l_{i}})}
+```
+
+其中,*N* 是样本总数,{math}`D(s_1, s_2)` 为两个字符串之间的编辑距离。
+
+例如,假设真实标签为 "OpenMMLabMMOCR",模型 A 的预测结果为 "0penMMLabMMOCR", 模型 B 的预测结果为 "uvwxyz",则采用全匹配和 `OneMinusNEDMetric` 评测指标的结果分别为:
+
+| | | |
+| ------ | ------ | ---------- |
+| | 全匹配 | 1 - N.E.D. |
+| 模型 A | 0 | 0.92857 |
+| 模型 B | 0 | 0 |
+
+由上表可以发现,尽管模型 A 仅预测错了一个字母,而模型 B 全部预测错误,在使用全匹配的评测指标时,这两个模型的得分都为0;而使用 `OneMinuesNEDMetric` 的评测指标则能够更好地区分模型在**长文本**上的性能差异。
+
+### F1Metric
+
+[F1Metric](mmocr.evaluation.metrics.f_metric.F1Metric) 实现了针对 KIE 任务的 F1-Metric 评测指标,并提供了 `micro` 和 `macro` 两种评测模式。
+
+```python
+val_evaluator = [
+ dict(type='F1Metric', mode=['micro', 'macro'],
+]
+```
+
+- `micro` 模式:依据 True Positive,False Negative,及 False Positive 总数来计算全局 F1-Metric 得分。
+
+- `macro` 模式:依据类别标签计算每一类的 F1-Metric,并求平均值。
+
+### 自定义评测指标
+
+对于追求更高定制化功能的用户,MMOCR 也支持自定义实现不同类型的评测指标。一般来说,用户只需要新建自定义评测指标类 `CustomizedMetric` 并继承 {external+mmengine:doc}`MMEngine: BaseMetric `,然后分别重写数据格式处理方法 `process` 以及指标计算方法 `compute_metrics`。最后,将其加入 `METRICS` 注册器即可实现任意定制化的评测指标。
+
+```python
+from mmengine.evaluator import BaseMetric
+from mmocr.registry import METRICS
+
+@METRICS.register_module()
+class CustomizedMetric(BaseMetric):
+
+ def process(self, data_batch: Sequence[Dict], predictions: Sequence[Dict]):
+ """ process 接收两个参数,分别为 data_batch 存放真实标签信息,以及 predictions
+ 存放预测结果。process 方法负责将标签信息转换并存放至 self.results 变量中
+ """
+ pass
+
+ def compute_metrics(self, results: List):
+ """ compute_metric 使用经过 process 方法处理过的标签数据计算最终评测得分
+ """
+ pass
+```
+
+```{note}
+更多内容可参见 {external+mmengine:doc}`MMEngine 文档: BaseMetric `。
+```
From 77ab13b3ffe8f5d4011748cbc20f1e7f91728454 Mon Sep 17 00:00:00 2001
From: Tong Gao
Date: Tue, 27 Sep 2022 10:44:32 +0800
Subject: [PATCH 18/32] [Docs] Add version switcher to menu (#1407)
* [Docs] Add version switcher to menu
* fix link
---
docs/en/conf.py | 27 +++++++++++++++++++++++++++
docs/zh_cn/conf.py | 23 +++++++++++++++++++++++
2 files changed, 50 insertions(+)
diff --git a/docs/en/conf.py b/docs/en/conf.py
index a0e96d834..e87a4a1b3 100644
--- a/docs/en/conf.py
+++ b/docs/en/conf.py
@@ -95,6 +95,15 @@
'name':
'Upstream',
'children': [
+ {
+ 'name':
+ 'MMEngine',
+ 'url':
+ 'https://github.com/open-mmlab/mmengine',
+ 'description':
+ 'Foundational library for training deep '
+ 'learning models'
+ },
{
'name': 'MMCV',
'url': 'https://github.com/open-mmlab/mmcv',
@@ -107,6 +116,24 @@
},
]
},
+ {
+ 'name':
+ 'Version',
+ 'children': [
+ {
+ 'name': 'MMOCR 0.x',
+ 'url': 'https://mmocr.readthedocs.io/en/latest/',
+ 'description': 'Main branch'
+ },
+ {
+ 'name': 'MMOCR 1.x',
+ 'url': 'https://mmocr.readthedocs.io/en/dev-1.x/',
+ 'description': '1.x branch'
+ },
+ ],
+ 'active':
+ True,
+ },
],
# Specify the language of shared menu
'menu_lang':
diff --git a/docs/zh_cn/conf.py b/docs/zh_cn/conf.py
index 91038a717..61a07194b 100644
--- a/docs/zh_cn/conf.py
+++ b/docs/zh_cn/conf.py
@@ -96,6 +96,11 @@
'name':
'上游库',
'children': [
+ {
+ 'name': 'MMEngine',
+ 'url': 'https://github.com/open-mmlab/mmengine',
+ 'description': '深度学习模型训练基础库'
+ },
{
'name': 'MMCV',
'url': 'https://github.com/open-mmlab/mmcv',
@@ -108,6 +113,24 @@
},
]
},
+ {
+ 'name':
+ '版本',
+ 'children': [
+ {
+ 'name': 'MMOCR 0.x',
+ 'url': 'https://mmocr.readthedocs.io/zh_CN/latest/',
+ 'description': 'main 分支文档'
+ },
+ {
+ 'name': 'MMOCR 1.x',
+ 'url': 'https://mmocr.readthedocs.io/zh_CN/dev-1.x/',
+ 'description': '1.x 分支文档'
+ },
+ ],
+ 'active':
+ True,
+ },
],
# Specify the language of shared menu
'menu_lang':
From 22283b4acd047bd67184019cb37eec1c3116ebde Mon Sep 17 00:00:00 2001
From: Xinyu Wang <45810070+xinke-wang@users.noreply.github.com>
Date: Tue, 27 Sep 2022 10:48:41 +0800
Subject: [PATCH 19/32] [Docs] Data Transforms (#1392)
* init
* reorder
* update
* fix comments
* update
* update images
* update
---
docs/en/basic_concepts/transforms.md | 230 ++++++++++++++++++++++-
docs/zh_cn/basic_concepts/transforms.md | 231 +++++++++++++++++++++++-
docs/zh_cn/migration/dataset.md | 2 +-
3 files changed, 458 insertions(+), 5 deletions(-)
diff --git a/docs/en/basic_concepts/transforms.md b/docs/en/basic_concepts/transforms.md
index ef62fde8d..a5974cf7d 100644
--- a/docs/en/basic_concepts/transforms.md
+++ b/docs/en/basic_concepts/transforms.md
@@ -1,3 +1,229 @@
-# Data Transforms
+# Data Transforms and Pipeline
-Coming Soon!
+In the design of MMOCR, dataset construction and preparation are decoupled. That is, dataset construction classes such as [`OCRDataset`](mmocr.datasets.ocr_dataset.OCRDataset) are responsible for loading and parsing annotation files; while data transforms further apply data preprocessing, augmentation, formatting, and other related functions. Currently, there are five types of data transforms implemented in MMOCR, as shown in the following table.
+
+| | | |
+| -------------------------------- | --------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------- |
+| Transforms Type | File | Description |
+| Data Loading | loading.py | Implemented the data loading functions. |
+| Data Formatting | formatting.py | Formatting the data required by different tasks. |
+| Cross Project Data Adapter | adapters.py | Converting the data format between other OpenMMLab projects and MMOCR. |
+| Data Augmentation Functions | ocr_transforms.py
textdet_transforms.py
textrecog_transforms.py | Various built-in data augmentation methods designed for different tasks. |
+| Wrappers of Third Party Packages | wrappers.py | Wrapping the transforms implemented in popular third party packages such as [ImgAug](https://github.com/aleju/imgaug), and adapting them to MMOCR format. |
+
+Since each data transform class is independent of each other, we can easily combine any data transforms to build a data pipeline after we have defined the data fields. As shown in the following figure, in MMOCR, a typical training data pipeline consists of three stages: **data loading**, **data augmentation**, and **data formatting**. Users only need to define the data pipeline list in the configuration file and specify the specific data transform class and its parameters:
+
+
+
+
+
+
+
+```python
+train_pipeline_r18 = [
+ # Loading images
+ dict(
+ type='LoadImageFromFile',
+ file_client_args=file_client_args,
+ color_type='color_ignore_orientation'),
+ # Loading annotations
+ dict(
+ type='LoadOCRAnnotations',
+ with_polygon=True,
+ with_bbox=True,
+ with_label=True,
+ ),
+ # Data augmentation
+ dict(
+ type='ImgAugWrapper',
+ args=[['Fliplr', 0.5],
+ dict(cls='Affine', rotate=[-10, 10]), ['Resize', [0.5, 3.0]]]),
+ dict(type='RandomCrop', min_side_ratio=0.1),
+ dict(type='Resize', scale=(640, 640), keep_ratio=True),
+ dict(type='Pad', size=(640, 640)),
+ # Data formatting
+ dict(
+ type='PackTextDetInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape'))
+]
+```
+
+```{tip}
+More tutorials about data pipeline configuration can be found in the [Config Doc](../user_guides/config.md#data-pipeline-configuration). Next, we will briefly introduce the data transforms supported in MMOCR according to their categories.
+```
+
+For each data transform, MMOCR provides a detailed docstring. For example, in the header of each data transform class, we annotate `Required Keys`, `Modified Keys` and `Added Keys`. The `Required Keys` represent the mandatory fields that should be included in the input required by the data transform, while the `Modified Keys` and `Added Keys` indicate that the transform may modify or add the fields into the original data. For example, `LoadImageFromFile` implements the image loading function, whose `Required Keys` is the image path `img_path`, and the `Modified Keys` includes the loaded image `img`, the current size of the image `img_shape`, the original size of the image `ori_shape`, and other image attributes.
+
+```python
+@TRANSFORMS.register_module()
+class LoadImageFromFile(MMCV_LoadImageFromFile):
+ # We provide detailed docstring for each data transform.
+ """Load an image from file.
+
+ Required Keys:
+
+ - img_path
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - ori_shape
+ """
+```
+
+```{note}
+In the data pipeline of MMOCR, the image and label information are saved in a dictionary. By using the unified fields, the data can be freely transferred between different data transforms. Therefore, it is very important to understand the conventional fields used in MMOCR.
+```
+
+For your convenience, the following table lists the conventional keys used in MMOCR data transforms.
+
+| | | |
+| ---------------- | --------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Key | Type | Description |
+| img | `np.array(dtype=np.uint8)` | Image array, shape of `(h, w, c)`. |
+| img_shape | `tuple(int, int)` | Current image size `(h, w)`. |
+| ori_shape | `tuple(int, int)` | Original image size `(h, w)`. |
+| scale | `tuple(int, int)` | Stores the target image size `(h, w)` specified by the user in the `Resize` data transform series. Note: This value may not correspond to the actual image size after the transformation. |
+| scale_factor | `tuple(float, float)` | Stores the target image scale factor `(w_scale, h_scale)` specified by the user in the `Resize` data transform series. Note: This value may not correspond to the actual image size after the transformation. |
+| keep_ratio | `bool` | Boolean flag determines whether to keep the aspect ratio while scaling images. |
+| flip | `bool` | Boolean flags to indicate whether the image has been flipped. |
+| flip_direction | `str` | Flipping direction, options are `horizontal`, `vertical`, `diagonal`. |
+| gt_bboxes | `np.array(dtype=np.float32)` | Ground-truth bounding boxes. |
+| gt_polygons | `list[np.array(dtype=np.float32)` | Ground-truth polygons. |
+| gt_bboxes_labels | `np.array(dtype=np.int64)` | Category label of bounding boxes. By default, MMOCR uses `0` to represent "text" instances. |
+| gt_texts | `list[str]` | Ground-truth text content of the instance. |
+| gt_ignored | `np.array(dtype=np.bool_)` | Boolean flag indicating whether ignoring the instance (used in text detection). |
+
+## Data Loading
+
+Data loading transforms mainly implement the functions of loading data from different formats and backends. Currently, the following data loading transforms are implemented in MMOCR:
+
+| | | | |
+| ------------------ | --------------------------------------------------------- | -------------------------------------------------------------- | --------------------------------------------------------------- |
+| Transforms Name | Required Keys | Modified/Added Keys | Description |
+| LoadImageFromFile | `img_path` | `img`
`img_shape`
`ori_shape` | Load image from the specified path,supporting different file storage backends (e.g. `disk`, `http`, `petrel`) and decoding backends (e.g. `cv2`, `turbojpeg`, `pillow`, `tifffile`). |
+| LoadOCRAnnotations | `bbox`
`bbox_label`
`polygon`
`ignore`
`text` | `gt_bboxes`
`gt_bboxes_labels`
`gt_polygons`
`gt_ignored`
`gt_texts` | Parse the annotation required by OCR task. |
+| LoadKIEAnnotations | `bboxes` `bbox_labels` `edge_labels`
`texts` | `gt_bboxes`
`gt_bboxes_labels`
`gt_edge_labels`
`gt_texts`
`ori_shape` | Parse the annotation required by KIE task. |
+| LoadImageFromLMDB | `img_path` | `img`
`img_shape`
`ori_shape` | Load images from LMDB. |
+
+## Data Augmentation
+
+Data augmentation is an indispensable process in text detection and recognition tasks. Currently, MMOCR has implemented dozens of data augmentation modules commonly used in OCR fields, which are classified into [ocr_transforms.py](/mmocr/datasets/transforms/ocr_transforms.py), [textdet_transforms.py](/mmocr/datasets/transforms/textdet_transforms.py), and [textrecog_transforms.py](/mmocr/datasets/transforms/textrecog_transforms.py).
+
+Specifically, `ocr_transforms.py` implements generic OCR data augmentation modules such as `RandomCrop` and `RandomRotate`:
+
+| | | | |
+| --------------- | ------------------------------------------------------------- | -------------------------------------------------------------- | -------------------------------------------------------------- |
+| Transforms Name | Required Keys | Modified/Added Keys | Description |
+| RandomCrop | `img`
`gt_bboxes`
`gt_bboxes_labels`
`gt_polygons`
`gt_ignored`
`gt_texts` (optional) | `img`
`img_shape`
`gt_bboxes`
`gt_bboxes_labels`
`gt_polygons`
`gt_ignored`
`gt_texts` (optional) | Randomly crop the image and make sure the cropped image contains at least one text instance. The optional parameter is `min_side_ratio`, which controls the ratio of the short side of the cropped image to the original image, the default value is `0.4`. |
+| RandomRotate | `img`
`img_shape`
`gt_bboxes` (optional)
`gt_polygons` (optional) | `img`
`img_shape`
`gt_bboxes` (optional)
`gt_polygons` (optional)
`rotated_angle` | Randomly rotate the image and optionally fill the blank areas of the rotated image. |
+| | | | |
+
+`textdet_transforms.py` implements text detection related data augmentation modules:
+
+| | | | |
+| ----------------- | ------------------------------------- | ------------------------------------------------------------------- | ------------------------------------------------------------------------------- |
+| Transforms Name | Required Keys | Modified/Added Keys | Description |
+| RandomFlip | `img`
`gt_bboxes`
`gt_polygons` | `img`
`gt_bboxes`
`gt_polygons`
`flip`
`flip_direction` | Random flip, support `horizontal`, `vertical` and `diagonal` modes. Defaults to `horizontal`. |
+| FixInvalidPolygon | `gt_polygons`
`gt_ignored` | `gt_polygons`
`gt_ignored` | Automatically fixing the invalid polygons included in the annotations. |
+
+`textrecog_transforms.py` implements text recognition related data augmentation modules:
+
+| | | | |
+| --------------- | ------------- | ----------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------- |
+| Transforms Name | Required Keys | Modified/Added Keys | Description |
+| RescaleToHeight | `img` | `img`
`img_shape`
`scale`
`scale_factor`
`keep_ratio` | Scales the image to the specified height while keeping the aspect ratio. When `min_width` and `max_width` are specified, the aspect ratio may be changed. |
+| | | | |
+
+```{warning}
+The above table only briefly introduces some selected data augmentation methods, for more information please refer to the [API documentation](../api.rst) or the code docstrings.
+```
+
+## Data Formatting
+
+Data formatting transforms are responsible for packaging images, ground truth labels, and other information into a dictionary. Different tasks usually rely on different formatting transforms. For example:
+
+| | | | |
+| ------------------- | ------------- | ------------------- | --------------------------------------------- |
+| Transforms Name | Required Keys | Modified/Added Keys | Description |
+| PackTextDetInputs | - | - | Pack the inputs required by text detection. |
+| PackTextRecogInputs | - | - | Pack the inputs required by text recognition. |
+| PackKIEInputs | - | - | Pack the inputs required by KIE. |
+
+## Cross Project Data Adapters
+
+The cross-project data adapters bridge the data formats between MMOCR and other OpenMMLab libraries such as [MMDetection](https://github.com/open-mmlab/mmdetection), making it possible to call models implemented in other OpenMMLab projects. Currently, MMOCR has implemented [`MMDet2MMOCR`](mmocr.datasets.transforms.MMDet2MMOCR) and [`MMOCR2MMDet`](mmocr.datasets.transforms.MMOCR2MMDet), allowing data to be converted between MMDetection and MMOCR formats; with these adapters, users can easily train any detectors supported by MMDetection in MMOCR. For example, we provide a [tutorial](#todo) to show how to train Mask R-CNN as a text detector in MMOCR.
+
+| | | | |
+| --------------- | -------------------------------------------- | ----------------------------- | ------------------------------------------ |
+| Transforms Name | Required Keys | Modified/Added Keys | Description |
+| MMDet2MMOCR | `gt_masks` `gt_ignore_flags` | `gt_polygons`
`gt_ignored` | Convert the fields used in MMDet to MMOCR. |
+| MMOCR2MMDet | `img_shape`
`gt_polygons`
`gt_ignored` | `gt_masks` `gt_ignore_flags` | Convert the fields used in MMOCR to MMDet. |
+
+## Wrappers
+
+To facilitate the use of popular third-party CV libraries in MMOCR, we provide wrappers in `wrappers.py` to unify the data format between MMOCR and other third-party libraries. Users can directly configure the data transforms provided by these libraries in the configuration file of MMOCR. The supported wrappers are as follows:
+
+| | | | |
+| ------------------ | ------------------------------------------------------------ | ------------------------------------------------------------- | ------------------------------------------------------------- |
+| Transforms Name | Required Keys | Modified/Added Keys | Description |
+| ImgAugWrapper | `img`
`gt_polygons` (optional for text recognition)
`gt_bboxes` (optional for text recognition)
`gt_bboxes_labels` (optional for text recognition)
`gt_ignored` (optional for text recognition)
`gt_texts` (optional) | `img`
`gt_polygons` (optional for text recognition)
`gt_bboxes` (optional for text recognition)
`gt_bboxes_labels` (optional for text recognition)
`gt_ignored` (optional for text recognition)
`img_shape` (optional)
`gt_texts` (optional) | [ImgAug](https://github.com/aleju/imgaug) wrapper, which bridges the data format and configuration between ImgAug and MMOCR, allowing users to config the data augmentation methods supported by ImgAug in MMOCR. |
+| TorchVisionWrapper | `img` | `img`
`img_shape` | [TorchVision](https://github.com/pytorch/vision) wrapper, which bridges the data format and configuration between TorchVision and MMOCR, allowing users to config the data transforms supported by `torchvision.transforms` in MMOCR. |
+| | | | |
+
+### `ImgAugWrapper` Example
+
+For example, in the original ImgAug, we can define a `Sequential` type data augmentation pipeline as follows to perform random flipping, random rotation and random scaling on the image:
+
+```python
+import imgaug.augmenters as iaa
+
+aug = iaa.Sequential(
+ iaa.Fliplr(0.5), # horizontally flip 50% of all images
+ iaa.Affine(rotate=(-10, 10)), # rotate by -10 to +10 degrees
+ iaa.Resize((0.5, 3.0)) # scale images to 50-300% of their size
+)
+```
+
+In MMOCR, we can directly configure the above data augmentation pipeline in `train_pipeline` as follows:
+
+```python
+dict(
+ type='ImgAugWrapper',
+ args=[
+ ['Fliplr', 0.5],
+ dict(cls='Affine', rotate=[-10, 10]),
+ ['Resize', [0.5, 3.0]],
+ ]
+)
+```
+
+Specifically, the `args` parameter accepts a list, and each element in the list can be a list or a dictionary. If it is a list, the first element of the list is the class name in `imgaug.augmenters`, and the following elements are the initialization parameters of the class; if it is a dictionary, the `cls` key corresponds to the class name in `imgaug.augmenters`, and the other key-value pairs correspond to the initialization parameters of the class.
+
+### `TorchVisionWrapper` Example
+
+For example, in the original TorchVision, we can define a `Compose` type data transformation pipeline as follows to perform color jittering on the image:
+
+```python
+import torchvision.transforms as transforms
+
+aug = transforms.Compose([
+ transforms.ColorJitter(
+ brightness=32.0 / 255, # brightness jittering range
+ saturation=0.5) # saturation jittering range
+])
+```
+
+In MMOCR, we can directly configure the above data transformation pipeline in `train_pipeline` as follows:
+
+```python
+dict(
+ type='TorchVisionWrapper',
+ op='ColorJitter',
+ brightness=32.0 / 255,
+ saturation=0.5
+)
+```
+
+Specifically, the `op` parameter is the class name in `torchvision.transforms`, and the following parameters correspond to the initialization parameters of the class.
diff --git a/docs/zh_cn/basic_concepts/transforms.md b/docs/zh_cn/basic_concepts/transforms.md
index f617a7a27..f610e88c7 100644
--- a/docs/zh_cn/basic_concepts/transforms.md
+++ b/docs/zh_cn/basic_concepts/transforms.md
@@ -1,3 +1,230 @@
-# 数据变换
+# 数据变换与流水线
-待更新
+在 MMOCR 的设计中,数据集的构建与数据准备是相互解耦的。也就是说,[`OCRDataset`](mmocr.datasets.ocr_dataset.OCRDataset) 等数据集构建类负责完成标注文件的读取与解析功能;而数据变换方法(Data Transforms)则进一步实现了数据预处理、数据增强、数据格式化等相关功能。目前,如下表所示,MMOCR 中共实现了 5 类数据变换方法:
+
+| | | |
+| -------------- | --------------------------------------------------------------------- | ------------------------------------------------------------------- |
+| 数据变换类型 | 对应文件 | 功能说明 |
+| 数据读取 | loading.py | 实现了不同格式数据的读取功能。 |
+| 数据格式化 | formatting.py | 完成不同任务所需数据的格式化功能。 |
+| 跨库数据适配器 | adapters.py | 负责 OpenMMLab 项目内跨库调用的数据格式转换功能。 |
+| 数据增强 | ocr_transforms.py
textdet_transforms.py
textrecog_transforms.py | 实现了不同任务下的各类数据增强方法。 |
+| 包装类 | wrappers.py | 实现了对 ImgAug 等常用算法库的包装,使其适配 MMOCR 的内部数据格式。 |
+
+由于每一个数据变换类之间都是相互独立的,因此,在约定好固定的数据存储字段后,我们可以便捷地采用任意的数据变换组合来构建数据流水线(Pipeline)。如下图所示,在 MMOCR 中,一个典型的训练数据流水线主要由**数据读取**、**图像增强**以及**数据格式化**三部分构成,用户只需要在配置文件中定义相关的数据流水线列表,并指定具体所需的数据变换类及其参数即可:
+
+
+
+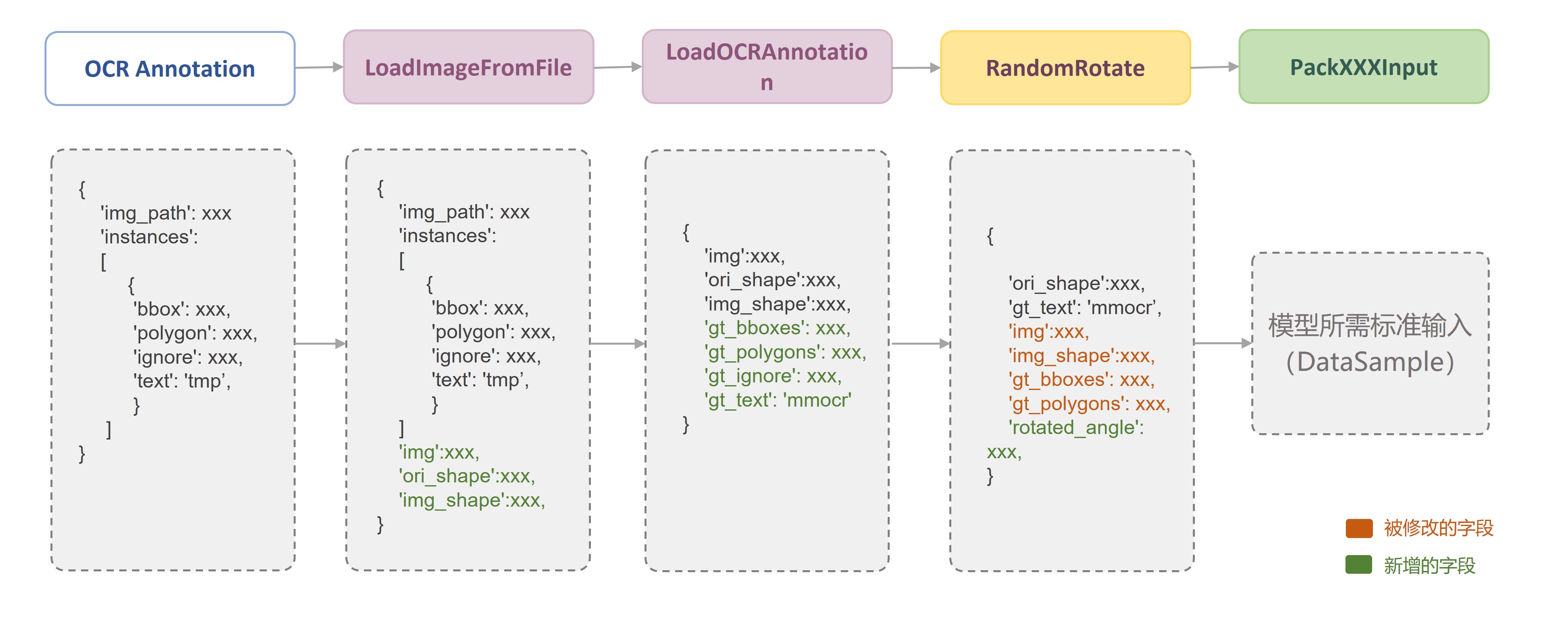
+
+
+
+```python
+train_pipeline_r18 = [
+ # 数据读取(图像)
+ dict(
+ type='LoadImageFromFile',
+ file_client_args=file_client_args,
+ color_type='color_ignore_orientation'),
+ # 数据读取(标注)
+ dict(
+ type='LoadOCRAnnotations',
+ with_polygon=True,
+ with_bbox=True,
+ with_label=True,
+ ),
+ # 使用 ImgAug 作数据增强
+ dict(
+ type='ImgAugWrapper',
+ args=[['Fliplr', 0.5],
+ dict(cls='Affine', rotate=[-10, 10]), ['Resize', [0.5, 3.0]]]),
+ # 使用 MMOCR 内置的图像增强
+ dict(type='RandomCrop', min_side_ratio=0.1),
+ dict(type='Resize', scale=(640, 640), keep_ratio=True),
+ dict(type='Pad', size=(640, 640)),
+ # 数据格式化
+ dict(
+ type='PackTextDetInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape'))
+]
+```
+
+```{tip}
+更多有关数据流水线配置的教程可见[配置文档](../user_guides/config.md#数据流水线配置)。下面,我们将简单介绍 MMOCR 中已支持的数据变换类型。
+```
+
+对于每一个数据变换方法,MMOCR 都严格按照文档字符串(docstring)规范在源码中提供了详细的代码注释。例如,每一个数据转换类的头部我们都注释了 “需求字段”(`Required keys`), “修改字段”(`Modified Keys`)与 “添加字段”(`Added Keys`)。其中,“需求字段”代表该数据转换方法对于输入数据所需包含字段的强制需求,而“修改字段”与“添加字段”则表明该方法可能会在原有数据基础之上修改或添加的字段。例如,`LoadImageFromFile` 实现了图片的读取功能,其需求字段为图像的存储路径 `img_path`,而修改字段则包括了读入的图像信息 `img`,以及图片当前尺寸 `img_shape`,图片原始尺寸 `ori_shape` 等图片属性。
+
+```python
+@TRANSFORMS.register_module()
+class LoadImageFromFile(MMCV_LoadImageFromFile):
+ # 在每一个数据变换方法的头部,我们都提供了详细的代码注释。
+ """Load an image from file.
+
+ Required Keys:
+
+ - img_path
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - ori_shape
+ """
+```
+
+```{note}
+在 MMOCR 的数据流水线中,图像及标签等信息被统一保存在字典中。通过统一的字段名,我们可以在不同的数据变换方法间灵活地传递数据。因此,了解 MMOCR 中常用的约定字段名是非常重要的。
+```
+
+为方便用户查询,下表列出了 MMOCR 中各数据转换(Data Transform)类常用的字段约定和说明。
+
+| | | |
+| ---------------- | --------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------ |
+| 字段 | 类型 | 说明 |
+| img | `np.array(dtype=np.uint8)` | 图像信息,形状为 `(h, w, c)`。 |
+| img_shape | `tuple(int, int)` | 当前图像尺寸 `(h, w)`。 |
+| ori_shape | `tuple(int, int)` | 图像在初始化时的尺寸 `(h, w)`。 |
+| scale | `tuple(int, int)` | 存放用户在 Resize 系列数据变换(Transform)中指定的目标图像尺寸 `(h, w)`。注意:该值未必与变换后的实际图像尺寸相符。 |
+| scale_factor | `tuple(float, float)` | 存放用户在 Resize 系列数据变换(Transform)中指定的目标图像缩放因子 `(w_scale, h_scale)`。注意:该值未必与变换后的实际图像尺寸相符。 |
+| keep_ratio | `bool` | 是否按等比例对图像进行缩放。 |
+| flip | `bool` | 图像是否被翻转。 |
+| flip_direction | `str` | 翻转方向。可选项为 `horizontal`, `vertical`, `diagonal`。 |
+| gt_bboxes | `np.array(dtype=np.float32)` | 文本实例边界框的真实标签。 |
+| gt_polygons | `list[np.array(dtype=np.float32)` | 文本实例边界多边形的真实标签。 |
+| gt_bboxes_labels | `np.array(dtype=np.int64)` | 文本实例对应的类别标签。在 MMOCR 中通常为 0,代指 "text" 类别。 |
+| gt_texts | `list[str]` | 与文本实例对应的字符串标注。 |
+| gt_ignored | `np.array(dtype=np.bool_)` | 是否要在计算目标时忽略该实例(用于检测任务中)。 |
+
+## 数据读取 - loading.py
+
+数据读取类主要实现了不同文件格式、后端读取图片及加载标注信息的功能。目前,MMOCR 内部共实现了以下数据读取类的 Data Transforms:
+
+| | | | |
+| ------------------ | --------------------------------------------------------- | -------------------------------------------------------------- | --------------------------------------------------------------- |
+| 数据转换类名称 | 需求字段 | 修改/添加字段 | 说明 |
+| LoadImageFromFile | `img_path` | `img`
`img_shape`
`ori_shape` | 从图片路径读取图片,支持多种文件存储后端(如 `disk`, `http`, `petrel` 等)及图片解码后端(如 `cv2`, `turbojpeg`, `pillow`, `tifffile`等)。 |
+| LoadOCRAnnotations | `bbox`
`bbox_label`
`polygon`
`ignore`
`text` | `gt_bboxes`
`gt_bboxes_labels`
`gt_polygons`
`gt_ignored`
`gt_texts` | 解析 OCR 任务所需的标注信息。 |
+| LoadKIEAnnotations | `bboxes` `bbox_labels` `edge_labels`
`texts` | `gt_bboxes`
`gt_bboxes_labels`
`gt_edge_labels`
`gt_texts`
`ori_shape` | 解析 KIE 任务所需的标注信息。 |
+| LoadImageFromLMDB | `img_path` | `img`
`img_shape`
`ori_shape` | 从 LMDB 格式标注文件中读取图片。 |
+
+## 数据增强 - xxx_transforms.py
+
+数据增强是文本检测、识别等任务中必不可少的流程之一。目前,MMOCR 中共实现了数十种文本领域内常用的数据增强模块,依据其任务类型,分别为通用 OCR 数据增强模块 [ocr_transforms.py](/mmocr/datasets/transforms/ocr_transforms.py),文本检测数据增强模块 [textdet_transforms.py](/mmocr/datasets/transforms/textdet_transforms.py),以及文本识别数据增强模块 [textrecog_transforms.py](/mmocr/datasets/transforms/textrecog_transforms.py)。
+
+具体而言,`ocr_transforms.py` 中实现了随机剪裁、随机旋转等各任务通用的数据增强模块:
+
+| | | | |
+| -------------- | -------------------------------------------------------------- | -------------------------------------------------------------- | -------------------------------------------------------------- |
+| 数据转换类名称 | 需求字段 | 修改/添加字段 | 说明 |
+| RandomCrop | `img`
`gt_bboxes`
`gt_bboxes_labels`
`gt_polygons`
`gt_ignored`
`gt_texts` (optional) | `img`
`img_shape`
`gt_bboxes`
`gt_bboxes_labels`
`gt_polygons`
`gt_ignored`
`gt_texts` (optional) | 随机裁剪,并确保裁剪后的图片至少包含一个文本实例。可选参数为 `min_side_ratio`,用以控制裁剪图片的短边占原始图片的比例,默认值为 `0.4`。 |
+| RandomRotate | `img`
`img_shape`
`gt_bboxes` (optional)
`gt_polygons` (optional) | `img`
`img_shape`
`gt_bboxes` (optional)
`gt_polygons` (optional)
`rotated_angle` | 随机旋转,并可选择对旋转后图像的黑边进行填充。 |
+| | | | |
+
+`textdet_transforms.py` 则实现了文本检测任务中常用的数据增强模块:
+
+| | | | |
+| ----------------- | ------------------------------------- | ------------------------------------------------------------------- | -------------------------------------------------------------------- |
+| 数据转换类名称 | 需求字段 | 修改/添加字段 | 说明 |
+| RandomFlip | `img`
`gt_bboxes`
`gt_polygons` | `img`
`gt_bboxes`
`gt_polygons`
`flip`
`flip_direction` | 随机翻转,支持水平、垂直和对角三种方向的图像翻转。默认使用水平翻转。 |
+| FixInvalidPolygon | `gt_polygons`
`gt_ignored` | `gt_polygons`
`gt_ignored` | 自动修复或忽略非法多边形标注。 |
+
+`textrecog_transforms.py` 中实现了文本识别任务中常用的数据增强模块:
+
+| | | | |
+| --------------- | -------- | ----------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
+| 数据转换类名称 | 需求字段 | 修改/添加字段 | 说明 |
+| RescaleToHeight | `img` | `img`
`img_shape`
`scale`
`scale_factor`
`keep_ratio` | 缩放图像至指定高度,并尽可能保持长宽比不变。当 `min_width` 及 `max_width` 被指定时,长宽比则可能会被改变。 |
+| | | | |
+
+```{warning}
+以上表格仅选择性地对部分数据增强方法作简要介绍,更多数据增强方法介绍请参考[API 文档](../api.rst)或阅读代码内的文档注释。
+```
+
+## 数据格式化 - formatting.py
+
+数据格式化负责将图像、真实标签以及其它常用信息等打包成一个字典。不同的任务通常依赖于不同的数据格式化数据变换类。例如:
+
+| | | | |
+| ------------------- | -------- | ------------- | ------------------------------------------ |
+| 数据转换类名称 | 需求字段 | 修改/添加字段 | 说明 |
+| PackTextDetInputs | - | - | 用于打包文本检测任务所需要的输入信息。 |
+| PackTextRecogInputs | - | - | 用于打包文本识别任务所需要的输入信息。 |
+| PackKIEInputs | - | - | 用于打包关键信息抽取任务所需要的输入信息。 |
+
+## 跨库数据适配器 - adapters.py
+
+跨库数据适配器打通了 MMOCR 与其他 OpenMMLab 系列算法库如 [MMDetection](https://github.com/open-mmlab/mmdetection) 之间的数据格式,使得跨项目调用其它开源算法库的配置文件及算法成为了可能。目前,MMOCR 实现了 `MMDet2MMOCR` 以及 `MMOCR2MMDet`,使得数据可以在 MMDetection 与 MMOCR 的格式之间自由转换;借助这些适配转换器,用户可以在 MMOCR 算法库内部轻松调用任何 MMDetection 已支持的检测算法,并在 OCR 相关数据集上进行训练。例如,我们以 Mask R-CNN 为例提供了[教程](#todo),展示了如何在 MMOCR 中使用 MMDetection 的检测算法训练文本检测器。
+
+| | | | |
+| -------------- | -------------------------------------------- | ----------------------------- | ---------------------------------------------- |
+| 数据转换类名称 | 需求字段 | 修改/添加字段 | 说明 |
+| MMDet2MMOCR | `gt_masks` `gt_ignore_flags` | `gt_polygons`
`gt_ignored` | 将 MMDet 中采用的字段转换为对应的 MMOCR 字段。 |
+| MMOCR2MMDet | `img_shape`
`gt_polygons`
`gt_ignored` | `gt_masks` `gt_ignore_flags` | 将 MMOCR 中采用的字段转换为对应的 MMDet 字段。 |
+
+## 包装类 - wrappers.py
+
+为了方便用户在 MMOCR 内部无缝调用常用的 CV 算法库,我们在 wrappers.py 中提供了相应的包装类。其主要打通了 MMOCR 与其它第三方算法库之间的数据格式和转换标准,使得用户可以在 MMOCR 的配置文件内直接配置使用这些第三方库提供的数据变换方法。目前支持的包装类有:
+
+| | | | |
+| ------------------ | ------------------------------------------------------------ | ------------------------------------------------------------- | ------------------------------------------------------------- |
+| 数据转换类名称 | 需求字段 | 修改/添加字段 | 说明 |
+| ImgAugWrapper | `img`
`gt_polygons` (optional for text recognition)
`gt_bboxes` (optional for text recognition)
`gt_bboxes_labels` (optional for text recognition)
`gt_ignored` (optional for text recognition)
`gt_texts` (optional) | `img`
`gt_polygons` (optional for text recognition)
`gt_bboxes` (optional for text recognition)
`gt_bboxes_labels` (optional for text recognition)
`gt_ignored` (optional for text recognition)
`img_shape` (optional)
`gt_texts` (optional) | [ImgAug](https://github.com/aleju/imgaug) 包装类,用于打通 ImgAug 与 MMOCR 的数据格式及配置,方便用户调用 ImgAug 实现的一系列数据增强方法。 |
+| TorchVisionWrapper | `img` | `img`
`img_shape` | [TorchVision](https://github.com/pytorch/vision) 包装类,用于打通 TorchVision 与 MMOCR 的数据格式及配置,方便用户调用 `torchvision.transforms` 中实现的一系列数据变换方法。 |
+| | | | |
+
+### `ImgAugWrapper` 示例
+
+例如,在原生的 ImgAug 中,我们可以按照如下代码定义一个 `Sequential` 类型的数据增强流程,对图像分别进行随机翻转、随机旋转和随机缩放:
+
+```python
+import imgaug.augmenters as iaa
+
+aug = iaa.Sequential(
+ iaa.Fliplr(0.5), # 以概率 0.5 进行水平翻转
+ iaa.Affine(rotate=(-10, 10)), # 随机旋转 -10 到 10 度
+ iaa.Resize((0.5, 3.0)) # 随机缩放到 50% 到 300% 的尺寸
+)
+```
+
+而在 MMOCR 中,我们可以通过 `ImgAugWrapper` 包装类,将上述数据增强流程直接配置到 `train_pipeline` 中:
+
+```python
+dict(
+ type='ImgAugWrapper',
+ args=[
+ ['Fliplr', 0.5],
+ dict(cls='Affine', rotate=[-10, 10]),
+ ['Resize', [0.5, 3.0]],
+ ]
+)
+```
+
+其中,`args` 参数接收一个列表,列表中的每个元素可以是一个列表,也可以是一个字典。如果是列表,则列表的第一个元素为 `imgaug.augmenters` 中的类名,后面的元素为该类的初始化参数;如果是字典,则字典的 `cls` 键对应 `imgaug.augmenters` 中的类名,其他键值对则对应该类的初始化参数。
+
+### `TorchVisionWrapper` 示例
+
+例如,在原生的 TorchVision 中,我们可以按照如下代码定义一个 `Compose` 类型的数据变换流程,对图像进行色彩抖动:
+
+```python
+import torchvision.transforms as transforms
+
+aug = transforms.Compose([
+ transforms.ColorJitter(
+ brightness=32.0 / 255, # 亮度抖动范围
+ saturation=0.5) # 饱和度抖动范围
+])
+```
+
+而在 MMOCR 中,我们可以通过 `TorchVisionWrapper` 包装类,将上述数据变换流程直接配置到 `train_pipeline` 中:
+
+```python
+dict(
+ type='TorchVisionWrapper',
+ op='ColorJitter',
+ brightness=32.0 / 255,
+ saturation=0.5
+)
+```
+
+其中,`op` 参数为 `torchvision.transforms` 中的类名,后面的参数则对应该类的初始化参数。
diff --git a/docs/zh_cn/migration/dataset.md b/docs/zh_cn/migration/dataset.md
index c8e6509af..404d59351 100644
--- a/docs/zh_cn/migration/dataset.md
+++ b/docs/zh_cn/migration/dataset.md
@@ -115,7 +115,7 @@ img2.jpg MMOCR
"bbox": [0, 0, 10, 20],
"bbox_label": 0,
"ignore": False
- },
+ },
// ...
]
}
From 8d29643d98d0f57127f62a9ed9376f8f5b02d22b Mon Sep 17 00:00:00 2001
From: Tong Gao
Date: Wed, 28 Sep 2022 20:56:03 +0800
Subject: [PATCH 20/32] [Docs] Fix inference docs (#1415)
---
docs/en/user_guides/inference.md | 2 +-
docs/zh_cn/user_guides/inference.md | 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/en/user_guides/inference.md b/docs/en/user_guides/inference.md
index 7d2dc5ad0..6f10d5c09 100644
--- a/docs/en/user_guides/inference.md
+++ b/docs/en/user_guides/inference.md
@@ -61,7 +61,7 @@ When calling the script from the command line, the script assumes configs are sa
from mmocr.ocr import MMOCR
# Load models into memory
-ocr = MMOCR()
+ocr = MMOCR(det='DB_r18', recog='CRNN')
# Inference
results = ocr.readtext('demo/demo_text_ocr.jpg', print_result=True, show=True)
diff --git a/docs/zh_cn/user_guides/inference.md b/docs/zh_cn/user_guides/inference.md
index 26851331b..a8f4dab56 100644
--- a/docs/zh_cn/user_guides/inference.md
+++ b/docs/zh_cn/user_guides/inference.md
@@ -60,7 +60,7 @@ python mmocr/ocr.py --det DB_r18 --recog CRNN demo/demo_text_ocr.jpg --print-res
from mmocr.ocr import MMOCR
# 导入模型到内存
-ocr = MMOCR()
+ocr = MMOCR(det='DB_r18', recog='CRNN')
# 推理
results = ocr.readtext('demo/demo_text_ocr.jpg', print_result=True, show=True)
From 73ba54cbb0cb6f08752835b0e823b5c0dc31d513 Mon Sep 17 00:00:00 2001
From: Xinyu Wang <45810070+xinke-wang@users.noreply.github.com>
Date: Wed, 28 Sep 2022 21:29:06 +0800
Subject: [PATCH 21/32] [Docs] Fix some docs (#1410)
* fix doc
* update structures
* update
---
docs/en/basic_concepts/structures.md | 27 +++----------------------
docs/en/basic_concepts/transforms.md | 1 -
docs/en/conf.py | 2 +-
docs/zh_cn/basic_concepts/structures.md | 27 +++----------------------
docs/zh_cn/basic_concepts/transforms.md | 1 -
docs/zh_cn/conf.py | 2 +-
6 files changed, 8 insertions(+), 52 deletions(-)
diff --git a/docs/en/basic_concepts/structures.md b/docs/en/basic_concepts/structures.md
index 31d36e72f..ee9ec36c3 100644
--- a/docs/en/basic_concepts/structures.md
+++ b/docs/en/basic_concepts/structures.md
@@ -1,27 +1,6 @@
# Data Structures and Elements
-During the training/testing process of a model, there is often a large amount of data to be passed between modules, and the data required by different tasks or algorithms is usually different. For example, in MMOCR, the text detection task needs to obtain the bounding box annotations of text instances during training, the recognition task needs text annotations, while the key information extraction task needs text category labels and the relationship between items, etc. This makes the interfaces of different tasks or models may be inconsistent, for example:
-
-```python
-# Text Detection
-for img, img_metas, gt_bboxes in dataloader:
- loss = detector(img, img_metas, gt_bboxes)
-
-# Text Recognition
-for img, img_metas, gt_texts in dataloader:
- loss = recognizer(img, img_metas, gt_labels)
-
-# Key Information Extraction
-for img, img_metas, gt_bboxes, gt_texts, gt_labels, gt_relations in dataloader:
- loss = kie(img, img_metas, gt_bboxes, gt_texts, gt_labels, gt_relations)
-```
-
-From the above code examples, we can see that without encapsulation, the different data required by different tasks and algorithms lead to inconsistent interfaces between their modules, which seriously affects the extensibility and reusability of the library. Therefore, in order to solve the above problem, we use {external+mmengine:doc}`MMEngine: Abstract Data Element ` to encapsulate the data required for each task into `data_sample`. The base class has implemented basic add/delete/update/check functions and supports data migration between different devices, as well as dictionary-like and tensor-like operations, which also allows the interfaces of different algorithms to be unified in the following form.
-
-```python
-for img, data_sample in dataloader:
- loss = model(img, data_sample)
-```
+MMOCR uses {external+mmengine:doc}`MMEngine: Abstract Data Element ` to encapsulate the data required for each task into `data_sample`. The base class has implemented basic add/delete/update/check functions and supports data migration between different devices, as well as dictionary-like and tensor-like operations, which also allows the interfaces of different algorithms to be unified.
Thanks to the unified data structures, the data flow between each module in the algorithm libraries, such as [`visualizer`](./visualizers.md), [`evaluator`](./evaluation.md), [`dataset`](./datasets.md), is greatly simplified. In MMOCR, we have the following conventions for different data types.
@@ -34,7 +13,7 @@ In the following, we will introduce the practical application of data elements *
`InstanceData` and `LabelData` are the `BaseDataElement` defined in `MMEngine` to encapsulate different granularity of annotation data or model output. In MMOCR, we have used `InstanceData` and `LabelData` for encapsulating the data types actually used in OCR-related tasks.
-### Text Detection - InstanceData
+### InstanceData
In the **text detection** task, the detector concentrate on instance-level text samples, so we use `InstanceData` to encapsulate the data needed for this task. Typically, its required training annotation and prediction output contain rectangular or polygonal bounding boxes, as well as bounding box labels. Since the text detection task has only one positive sample class, "text", in MMOCR we use `0` to number this class by default. The following code example shows how to use the `InstanceData` to encapsulate the data used in the text detection task.
@@ -71,7 +50,7 @@ The conventions for the fields in `InstanceData` in MMOCR are shown in the table
| edge_labels | `torch.IntTensor` | The node adjacency matrix with the shape `(N, N)`. In KIE, the optional values for the state between nodes are `-1` (ignored, not involved in loss calculation),`0` (disconnected) and `1`(connected). |
| edge_scores | `torch.FloatTensor` | The prediction confidence of each edge in the KIE task, with the shape `(N, N)`. |
-### Text Recognition - LabelData
+### LabelData
For **text recognition** tasks, both labeled content and predicted content are wrapped using `LabelData`.
diff --git a/docs/en/basic_concepts/transforms.md b/docs/en/basic_concepts/transforms.md
index a5974cf7d..5d0c563bf 100644
--- a/docs/en/basic_concepts/transforms.md
+++ b/docs/en/basic_concepts/transforms.md
@@ -170,7 +170,6 @@ To facilitate the use of popular third-party CV libraries in MMOCR, we provide w
| Transforms Name | Required Keys | Modified/Added Keys | Description |
| ImgAugWrapper | `img`
`gt_polygons` (optional for text recognition)
`gt_bboxes` (optional for text recognition)
`gt_bboxes_labels` (optional for text recognition)
`gt_ignored` (optional for text recognition)
`gt_texts` (optional) | `img`
`gt_polygons` (optional for text recognition)
`gt_bboxes` (optional for text recognition)
`gt_bboxes_labels` (optional for text recognition)
`gt_ignored` (optional for text recognition)
`img_shape` (optional)
`gt_texts` (optional) | [ImgAug](https://github.com/aleju/imgaug) wrapper, which bridges the data format and configuration between ImgAug and MMOCR, allowing users to config the data augmentation methods supported by ImgAug in MMOCR. |
| TorchVisionWrapper | `img` | `img`
`img_shape` | [TorchVision](https://github.com/pytorch/vision) wrapper, which bridges the data format and configuration between TorchVision and MMOCR, allowing users to config the data transforms supported by `torchvision.transforms` in MMOCR. |
-| | | | |
### `ImgAugWrapper` Example
diff --git a/docs/en/conf.py b/docs/en/conf.py
index e87a4a1b3..74151a362 100644
--- a/docs/en/conf.py
+++ b/docs/en/conf.py
@@ -150,7 +150,7 @@
html_static_path = ['_static']
html_css_files = ['css/readthedocs.css']
-myst_heading_anchors = 3
+myst_heading_anchors = 4
intersphinx_mapping = {
'python': ('https://docs.python.org/3', None),
diff --git a/docs/zh_cn/basic_concepts/structures.md b/docs/zh_cn/basic_concepts/structures.md
index a5fb48c57..fde18f0ba 100644
--- a/docs/zh_cn/basic_concepts/structures.md
+++ b/docs/zh_cn/basic_concepts/structures.md
@@ -1,27 +1,6 @@
# 数据元素与数据结构
-在模型的训练/测试过程中,组件之间往往有大量的数据需要传递,不同的任务或算法传递的数据通常是不一样的。例如,在 MMOCR 中,文本检测任务在训练时需要获取文本实例的边界盒标注,识别任务则需要文本内容标注,而关键信息抽取任务则还需要文本类别标签以及文本项间的关系图等。这使得不同任务或模型的接口可能存在不一致,例如:
-
-```python
-# 文本检测任务
-for img, img_metas, gt_bboxes in dataloader:
- loss = detector(img, img_metas, gt_bboxes)
-
-# 文本识别任务
-for img, img_metas, gt_texts in dataloader:
- loss = recognizer(img, img_metas, gt_labels)
-
-# 关键信息抽取任务
-for img, img_metas, gt_bboxes, gt_texts, gt_labels, gt_relations in dataloader:
- loss = kie(img, img_metas, gt_bboxes, gt_texts, gt_labels, gt_relations)
-```
-
-从以上代码示例我们可以发现,在不进行封装的情况下,不同任务和算法所需的不同数据导致了其模块之间的接口不一致的情况,严重影响了算法库的拓展性及复用性。因此,为了解决上述问题,我们基于 {external+mmengine:doc}`MMEngine: 抽象数据接口 ` 将各任务所需的数据统一封装入 `data_sample` 中。MMEngine 的抽象数据接口实现了基础的增/删/改/查功能,且支持不同设备间的数据迁移,也支持了类字典和张量的操作,充分满足了数据的日常使用需求,这也使得不同算法的接口可以统一为以下形式:
-
-```python
-for img, data_sample in dataloader:
- loss = model(img, data_sample)
-```
+MMOCR 基于 {external+mmengine:doc}`MMEngine: 抽象数据接口 ` 将各任务所需的数据统一封装入 `data_sample` 中。MMEngine 的抽象数据接口实现了基础的增/删/改/查功能,且支持不同设备间的数据迁移,也支持了类字典和张量的操作,充分满足了数据的日常使用需求,这也使得不同算法的数据接口可以得到统一。
得益于统一的数据封装,算法库内的 [`visualizer`](./visualizers.md),[`evaluator`](./evaluation.md),[`dataset`](./datasets.md) 等各个模块间的数据流通都得到了极大的简化。在 MMOCR 中,我们对数据接口类型作出以下约定:
@@ -34,7 +13,7 @@ for img, data_sample in dataloader:
`InstanceData` 和 `LabelData` 是 `MMEngine`中定义的基础数据元素,用于封装不同粒度的标注数据或模型输出。在 MMOCR 中,我们针对不同任务中实际使用的数据类型,分别采用了 `InstanceData` 与 `LabelData` 进行了封装。
-### 文本检测 InstanceData
+### InstanceData
在**文本检测**任务中,检测器关注的是实例级别的文字样本,因此我们使用 `InstanceData` 来封装该任务所需的数据。其所需的训练标注和预测输出通常包含了矩形或多边形边界盒,以及边界盒标签。由于文本检测任务只有一种正样本类,即 “text”,在 MMOCR 中我们默认使用 `0` 来编号该类别。以下代码示例展示了如何使用 `InstanceData` 数据抽象接口来封装文本检测任务中使用的数据类型。
@@ -71,7 +50,7 @@ MMOCR 中对 `InstanceData` 字段的约定如下表所示。值得注意的是
| edge_labels | `torch.IntTensor` | 节点的邻接矩阵,形状为 `(N, N)`。在 KIE 任务中,节点之间状态的可选值为 `-1` (忽略,不参与 loss 计算),`0` (断开)和 `1`(连接)。 |
| edge_scores | `torch.FloatTensor` | 用于 KIE 任务中每条边的预测置信度,形状为 `(N, N)`。 |
-### 文本识别 LabelData
+### LabelData
对于**文字识别**任务,标注内容和预测内容都会使用 `LabelData` 进行封装。
diff --git a/docs/zh_cn/basic_concepts/transforms.md b/docs/zh_cn/basic_concepts/transforms.md
index f610e88c7..4f36624fa 100644
--- a/docs/zh_cn/basic_concepts/transforms.md
+++ b/docs/zh_cn/basic_concepts/transforms.md
@@ -171,7 +171,6 @@ class LoadImageFromFile(MMCV_LoadImageFromFile):
| 数据转换类名称 | 需求字段 | 修改/添加字段 | 说明 |
| ImgAugWrapper | `img`
`gt_polygons` (optional for text recognition)
`gt_bboxes` (optional for text recognition)
`gt_bboxes_labels` (optional for text recognition)
`gt_ignored` (optional for text recognition)
`gt_texts` (optional) | `img`
`gt_polygons` (optional for text recognition)
`gt_bboxes` (optional for text recognition)
`gt_bboxes_labels` (optional for text recognition)
`gt_ignored` (optional for text recognition)
`img_shape` (optional)
`gt_texts` (optional) | [ImgAug](https://github.com/aleju/imgaug) 包装类,用于打通 ImgAug 与 MMOCR 的数据格式及配置,方便用户调用 ImgAug 实现的一系列数据增强方法。 |
| TorchVisionWrapper | `img` | `img`
`img_shape` | [TorchVision](https://github.com/pytorch/vision) 包装类,用于打通 TorchVision 与 MMOCR 的数据格式及配置,方便用户调用 `torchvision.transforms` 中实现的一系列数据变换方法。 |
-| | | | |
### `ImgAugWrapper` 示例
diff --git a/docs/zh_cn/conf.py b/docs/zh_cn/conf.py
index 61a07194b..608e5fdec 100644
--- a/docs/zh_cn/conf.py
+++ b/docs/zh_cn/conf.py
@@ -147,7 +147,7 @@
html_static_path = ['_static']
html_css_files = ['css/readthedocs.css']
-myst_heading_anchors = 3
+myst_heading_anchors = 4
# Configuration for intersphinx
intersphinx_mapping = {
From a0284ae910efad435bc3e0855497218afe087fce Mon Sep 17 00:00:00 2001
From: Xinyu Wang <45810070+xinke-wang@users.noreply.github.com>
Date: Thu, 29 Sep 2022 10:59:51 +0800
Subject: [PATCH 22/32] [Docs] Add maintainance plan to migration guide (#1413)
* init
* update en plan
* fix typos
* add coming soon flags
---
docs/en/basic_concepts/convention.md | 2 +-
docs/en/basic_concepts/data_flow.md | 2 +-
docs/en/basic_concepts/datasets.md | 2 +-
docs/en/basic_concepts/engine.md | 2 +-
docs/en/basic_concepts/models.md | 2 +-
docs/en/basic_concepts/overview.md | 2 +-
docs/en/basic_concepts/visualizers.md | 2 +-
docs/en/migration/overview.md | 8 ++++++++
docs/zh_cn/basic_concepts/convention.md | 2 +-
docs/zh_cn/basic_concepts/data_flow.md | 2 +-
docs/zh_cn/basic_concepts/datasets.md | 2 +-
docs/zh_cn/basic_concepts/engine.md | 2 +-
docs/zh_cn/basic_concepts/models.md | 2 +-
docs/zh_cn/basic_concepts/overview.md | 2 +-
docs/zh_cn/basic_concepts/visualizers.md | 2 +-
docs/zh_cn/migration/overview.md | 8 ++++++++
16 files changed, 30 insertions(+), 14 deletions(-)
diff --git a/docs/en/basic_concepts/convention.md b/docs/en/basic_concepts/convention.md
index 5779a3252..4964cacbc 100644
--- a/docs/en/basic_concepts/convention.md
+++ b/docs/en/basic_concepts/convention.md
@@ -1,3 +1,3 @@
-# Convention
+# Convention\[coming soon\]
Coming Soon!
diff --git a/docs/en/basic_concepts/data_flow.md b/docs/en/basic_concepts/data_flow.md
index a105511d7..11957fa1f 100644
--- a/docs/en/basic_concepts/data_flow.md
+++ b/docs/en/basic_concepts/data_flow.md
@@ -1,3 +1,3 @@
-# Data Flow
+# Data Flow\[coming soon\]
Coming Soon!
diff --git a/docs/en/basic_concepts/datasets.md b/docs/en/basic_concepts/datasets.md
index 8c1061cbb..183b63285 100644
--- a/docs/en/basic_concepts/datasets.md
+++ b/docs/en/basic_concepts/datasets.md
@@ -1,3 +1,3 @@
-# Datasets
+# Datasets\[coming soon\]
Coming Soon!
diff --git a/docs/en/basic_concepts/engine.md b/docs/en/basic_concepts/engine.md
index 4e527ba79..a113015ac 100644
--- a/docs/en/basic_concepts/engine.md
+++ b/docs/en/basic_concepts/engine.md
@@ -1,3 +1,3 @@
-# Engine
+# Engine\[coming soon\]
Coming Soon!
diff --git a/docs/en/basic_concepts/models.md b/docs/en/basic_concepts/models.md
index 71186aa8d..7eab561e7 100644
--- a/docs/en/basic_concepts/models.md
+++ b/docs/en/basic_concepts/models.md
@@ -1,3 +1,3 @@
-# Models
+# Models\[coming soon\]
Coming Soon!
diff --git a/docs/en/basic_concepts/overview.md b/docs/en/basic_concepts/overview.md
index 7f583f54d..9e31fefa5 100644
--- a/docs/en/basic_concepts/overview.md
+++ b/docs/en/basic_concepts/overview.md
@@ -1,3 +1,3 @@
-# Overview & Features
+# Overview & Features\[coming soon\]
Coming Soon!
diff --git a/docs/en/basic_concepts/visualizers.md b/docs/en/basic_concepts/visualizers.md
index 8086c9d17..bf620e1b7 100644
--- a/docs/en/basic_concepts/visualizers.md
+++ b/docs/en/basic_concepts/visualizers.md
@@ -1,3 +1,3 @@
-# Visualizers
+# Visualizers\[coming soon\]
Coming Soon!
diff --git a/docs/en/migration/overview.md b/docs/en/migration/overview.md
index 776306051..fd4312624 100644
--- a/docs/en/migration/overview.md
+++ b/docs/en/migration/overview.md
@@ -7,3 +7,11 @@ Next, please read the sections according to your requirements.
- If you want to migrate a model trained in version 0.x to use it directly in version 1.0, please read [Pretrained Model Migration](./model.md).
- If you want to train the model, please read [Dataset Migration](./dataset.md) and [Data Transform Migration](./transforms.md).
- If you want to develop on MMOCR, please read [Code Migration](code.md) and [Upstream Library Changes](https://github.com/open-mmlab/mmengine/tree/main/docs/en/migration).
+
+```{note}
+It should be noted that MMOCR 1.0 depends on the new foundational library for training deep learning models [MMEngine](https://github.com/open-mmlab/mmengine). Therefore, you need to create a new python environment to install the dependencies for MMOCR 1.0. We provide a detailed [installation guide](../get_started/install.md) for reference.
+```
+
+As shown in the following figure, the maintenance plan of MMOCR 1.x version is mainly divided into three stages, namely "Public Beta Period", "Compatibility Period" and "Maintenance Period". For old versions, we will no longer add major new features. Therefore, we strongly recommend users to migrate to MMOCR 1.x version as soon as possible.
+
+
diff --git a/docs/zh_cn/basic_concepts/convention.md b/docs/zh_cn/basic_concepts/convention.md
index 584b8eaf2..a094becca 100644
--- a/docs/zh_cn/basic_concepts/convention.md
+++ b/docs/zh_cn/basic_concepts/convention.md
@@ -1,3 +1,3 @@
-# 开发默认约定
+# 开发默认约定\[待更新\]
待更新
diff --git a/docs/zh_cn/basic_concepts/data_flow.md b/docs/zh_cn/basic_concepts/data_flow.md
index dadfa7766..a07a158b1 100644
--- a/docs/zh_cn/basic_concepts/data_flow.md
+++ b/docs/zh_cn/basic_concepts/data_flow.md
@@ -1,3 +1,3 @@
-# 数据流
+# 数据流\[待更新\]
待更新
diff --git a/docs/zh_cn/basic_concepts/datasets.md b/docs/zh_cn/basic_concepts/datasets.md
index ace81ab7f..cef1577a8 100644
--- a/docs/zh_cn/basic_concepts/datasets.md
+++ b/docs/zh_cn/basic_concepts/datasets.md
@@ -1,3 +1,3 @@
-# 数据集
+# 数据集\[待更新\]
待更新
diff --git a/docs/zh_cn/basic_concepts/engine.md b/docs/zh_cn/basic_concepts/engine.md
index 50f7dfdce..57cb62ae9 100644
--- a/docs/zh_cn/basic_concepts/engine.md
+++ b/docs/zh_cn/basic_concepts/engine.md
@@ -1,3 +1,3 @@
-# 引擎
+# 引擎\[待更新\]
待更新
diff --git a/docs/zh_cn/basic_concepts/models.md b/docs/zh_cn/basic_concepts/models.md
index 7c6155c60..7ec449d5c 100644
--- a/docs/zh_cn/basic_concepts/models.md
+++ b/docs/zh_cn/basic_concepts/models.md
@@ -1,3 +1,3 @@
-# 模型
+# 模型\[待更新\]
待更新
diff --git a/docs/zh_cn/basic_concepts/overview.md b/docs/zh_cn/basic_concepts/overview.md
index eb3649620..bbd721395 100644
--- a/docs/zh_cn/basic_concepts/overview.md
+++ b/docs/zh_cn/basic_concepts/overview.md
@@ -1,3 +1,3 @@
-# 设计理念与特性
+# 设计理念与特性\[待更新\]
待更新
diff --git a/docs/zh_cn/basic_concepts/visualizers.md b/docs/zh_cn/basic_concepts/visualizers.md
index 566205894..323dc0a28 100644
--- a/docs/zh_cn/basic_concepts/visualizers.md
+++ b/docs/zh_cn/basic_concepts/visualizers.md
@@ -1,3 +1,3 @@
-# 可视化组件
+# 可视化组件\[待更新\]
待更新
diff --git a/docs/zh_cn/migration/overview.md b/docs/zh_cn/migration/overview.md
index 48d075cf4..4692baa67 100644
--- a/docs/zh_cn/migration/overview.md
+++ b/docs/zh_cn/migration/overview.md
@@ -7,3 +7,11 @@
- 如果你需要把 0.x 版本中训练的模型直接迁移到 1.0 版本中使用,请阅读 [预训练模型迁移](./model.md)
- 如果你需要训练模型,请阅读 [数据集迁移](./dataset.md) 和 [数据增强迁移](./transforms.md)
- 如果你需要在 MMOCR 上进行开发,请阅读 [代码迁移](code.md) 和 [上游依赖库变更](https://github.com/open-mmlab/mmengine/tree/main/docs/zh_cn/migration)
+
+```{note}
+需要注意的是,MMOCR 1.0 依赖于新的基础训练框架 [MMEngine](https://github.com/open-mmlab/mmengine)。因此,你需要创建新的 python 环境来安装 MMOCR 1.0 版本所需要的依赖库。我们提供了详细的[安装文档](../get_started/install.md)以供参考。
+```
+
+如下图所示,MMOCR 1.x 版本的维护计划主要分为三个阶段,即“公测期”,“兼容期”以及“维护期”。对于旧版本,我们将不再增加主要新功能。因此,我们强烈建议用户尽早迁移至 MMOCR 1.x 版本。
+
+
From 5e596cc579a05413aeec783c0a603f59f03dbb70 Mon Sep 17 00:00:00 2001
From: Tong Gao
Date: Thu, 29 Sep 2022 16:26:52 +0800
Subject: [PATCH 23/32] [Config] Update paths to pretrain weights (#1416)
---
configs/textdet/dbnet/README.md | 2 +-
.../textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py | 2 +-
configs/textdet/dbnetpp/README.md | 2 +-
.../dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015.py | 2 ++
configs/textrecog/abinet/abinet_20e_st-an_mj.py | 2 ++
5 files changed, 7 insertions(+), 3 deletions(-)
diff --git a/configs/textdet/dbnet/README.md b/configs/textdet/dbnet/README.md
index 97647e5e2..60d35add7 100644
--- a/configs/textdet/dbnet/README.md
+++ b/configs/textdet/dbnet/README.md
@@ -19,7 +19,7 @@ Recently, segmentation-based methods are quite popular in scene text detection,
| Method | Pretrained Model | Training set | Test set | #epochs | Test size | Precision | Recall | Hmean | Download |
| :--------------------------------------: | :-------------------------------------------------: | :-------------: | :------------: | :-----: | :-------: | :-------: | :----: | :----: | :-----------------------------------------: |
| [DBNet_r18](/configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py) | ImageNet | ICDAR2015 Train | ICDAR2015 Test | 1200 | 736 | 0.8853 | 0.7583 | 0.8169 | [model](https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015/dbnet_resnet18_fpnc_1200e_icdar2015_20220825_221614-7c0e94f2.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015/20220825_221614.log) |
-| [DBNet_r50dcn](/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py) | [Synthtext](https://download.openmmlab.com/mmocr/textdet/dbnet/tmp_1.0_pretrain/dbnet_r50dcnv2_fpnc_sbn_2e_synthtext_20210325-aa96e477.pth) | ICDAR2015 Train | ICDAR2015 Test | 1200 | 1024 | 0.8784 | 0.8315 | 0.8543 | [model](https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015_20220828_124917-452c443c.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015/20220828_124917.log) |
+| [DBNet_r50dcn](/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py) | [Synthtext](https://download.openmmlab.com/mmocr/textdet/dbnet/tmp_1.0_pretrain/dbnet_r50dcnv2_fpnc_sbn_2e_synthtext_20210325-ed322016.pth) | ICDAR2015 Train | ICDAR2015 Test | 1200 | 1024 | 0.8784 | 0.8315 | 0.8543 | [model](https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015_20220828_124917-452c443c.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015/20220828_124917.log) |
## Citation
diff --git a/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py b/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py
index 074cf74b4..41cf2c461 100644
--- a/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py
+++ b/configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py
@@ -6,7 +6,7 @@
]
# TODO: Replace the link
-load_from = 'https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_r50dcnv2_fpnc_sbn_2e_synthtext_20210325-aa96e477.pth' # noqa
+load_from = 'https://download.openmmlab.com/mmocr/textdet/dbnet/tmp_1.0_pretrain/dbnet_r50dcnv2_fpnc_sbn_2e_synthtext_20210325-ed322016.pth' # noqa
# dataset settings
ic15_det_train = _base_.ic15_det_train
diff --git a/configs/textdet/dbnetpp/README.md b/configs/textdet/dbnetpp/README.md
index 3d0d61653..50bf3fa39 100644
--- a/configs/textdet/dbnetpp/README.md
+++ b/configs/textdet/dbnetpp/README.md
@@ -18,7 +18,7 @@ Recently, segmentation-based scene text detection methods have drawn extensive a
| Method | Pretrained Model | Training set | Test set | #epochs | Test size | Precision | Recall | Hmean | Download |
| :--------------------------------------: | :-------------------------------------------------: | :-------------: | :------------: | :-----: | :-------: | :-------: | :----: | :----: | :-----------------------------------------: |
-| [DBNetpp_r50dcn](/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015.py) | [Synthtext](/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_100k_synthtext.py) ([model](https://download.openmmlab.com/mmocr/textdet/dbnet/dbnetpp_r50dcnv2_fpnc_100k_iter_synthtext-20220502-db297554.pth)) | ICDAR2015 Train | ICDAR2015 Test | 1200 | 1024 | 0.9116 | 0.8291 | 0.8684 | [model](https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015_20220829_230108-f289bd20.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015/20220829_230108.log) |
+| [DBNetpp_r50dcn](/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015.py) | [Synthtext](/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_100k_synthtext.py) ([model](https://download.openmmlab.com/mmocr/textdet/dbnetpp/tmp_1.0_pretrain/dbnetpp_r50dcnv2_fpnc_100k_iter_synthtext-20220502-352fec8a.pth)) | ICDAR2015 Train | ICDAR2015 Test | 1200 | 1024 | 0.9116 | 0.8291 | 0.8684 | [model](https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015_20220829_230108-f289bd20.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015/20220829_230108.log) |
## Citation
diff --git a/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015.py b/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015.py
index 6fe192657..84f7af723 100644
--- a/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015.py
+++ b/configs/textdet/dbnetpp/dbnetpp_resnet50-dcnv2_fpnc_1200e_icdar2015.py
@@ -5,6 +5,8 @@
'../_base_/schedules/schedule_sgd_1200e.py',
]
+load_from = 'https://download.openmmlab.com/mmocr/textdet/dbnetpp/tmp_1.0_pretrain/dbnetpp_r50dcnv2_fpnc_100k_iter_synthtext-20220502-352fec8a.pth' # noqa
+
# dataset settings
train_list = [_base_.ic15_det_train]
test_list = [_base_.ic15_det_test]
diff --git a/configs/textrecog/abinet/abinet_20e_st-an_mj.py b/configs/textrecog/abinet/abinet_20e_st-an_mj.py
index 85b00cd9d..832770759 100644
--- a/configs/textrecog/abinet/abinet_20e_st-an_mj.py
+++ b/configs/textrecog/abinet/abinet_20e_st-an_mj.py
@@ -12,6 +12,8 @@
'_base_abinet.py',
]
+load_from = 'https://download.openmmlab.com/mmocr/textrecog/abinet/abinet_pretrain-45deac15.pth' # noqa
+
optim_wrapper = dict(optimizer=dict(lr=1e-4))
train_cfg = dict(max_epochs=20)
# learning policy
From 0b53f50eada891891da46dc9ac15e0372cea1fec Mon Sep 17 00:00:00 2001
From: Tong Gao
Date: Sat, 8 Oct 2022 14:14:32 +0800
Subject: [PATCH 24/32] [Enhancement] Streamline duplicated split_result in
pan_postprocessor (#1418)
---
.../textdet/postprocessors/pan_postprocessor.py | 12 ------------
1 file changed, 12 deletions(-)
diff --git a/mmocr/models/textdet/postprocessors/pan_postprocessor.py b/mmocr/models/textdet/postprocessors/pan_postprocessor.py
index cebe6789b..63676856b 100644
--- a/mmocr/models/textdet/postprocessors/pan_postprocessor.py
+++ b/mmocr/models/textdet/postprocessors/pan_postprocessor.py
@@ -116,18 +116,6 @@ def get_text_instances(self, pred_results: torch.Tensor,
data_sample.set_metainfo(dict(scale_factor=scale_factor))
return data_sample
- def split_results(self, pred_results: torch.Tensor) -> List[torch.Tensor]:
- """Split the prediction results into text score and kernel score.
-
- Args:
- pred_results (torch.Tensor): The prediction results.
-
- Returns:
- List[torch.Tensor]: The text score and kernel score.
- """
- pred_results = [pred_result for pred_result in pred_results]
- return pred_results
-
def _points2boundary(self,
points: np.ndarray,
min_width: int = 0) -> List[float]:
From 4fef7d1868af94c8d33020cf90717af8f4076fdb Mon Sep 17 00:00:00 2001
From: liukuikun <24622904+Harold-lkk@users.noreply.github.com>
Date: Sat, 8 Oct 2022 15:00:21 +0800
Subject: [PATCH 25/32] Upgrade pre commit hooks (#1429)
---
.pre-commit-config.yaml | 8 ++++----
docs/en/user_guides/config.md | 6 +++---
mmocr/datasets/transforms/wrappers.py | 2 +-
3 files changed, 8 insertions(+), 8 deletions(-)
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index 1da8f1a86..89d54ef05 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -1,7 +1,7 @@
exclude: ^tests/data/
repos:
- repo: https://github.com/PyCQA/flake8
- rev: 4.0.1
+ rev: 5.0.4
hooks:
- id: flake8
- repo: https://github.com/PyCQA/isort
@@ -9,15 +9,15 @@ repos:
hooks:
- id: isort
- repo: https://github.com/pre-commit/mirrors-yapf
- rev: v0.30.0
+ rev: v0.32.0
hooks:
- id: yapf
- repo: https://github.com/codespell-project/codespell
- rev: v2.1.0
+ rev: v2.2.1
hooks:
- id: codespell
- repo: https://github.com/pre-commit/pre-commit-hooks
- rev: v3.1.0
+ rev: v4.3.0
hooks:
- id: trailing-whitespace
exclude: ^dicts/
diff --git a/docs/en/user_guides/config.md b/docs/en/user_guides/config.md
index 5ebe9ccbb..43e13a830 100644
--- a/docs/en/user_guides/config.md
+++ b/docs/en/user_guides/config.md
@@ -206,7 +206,7 @@ Here is a brief description of a few hooks whose parameters may be changed frequ
- `CheckpointHook`: Used to configure checkpoint-related behavior, such as saving optimal and/or latest weights. You can also modify `interval` to control the checkpoint saving interval. More settings can be found in [CheckpointHook API](mmengine.hooks.CheckpointHook)
-- `VisualizationHook`: Used to configure visualization-related behavior, such as visualizing predicted results during validation or testing. **Default is off**. This Hook also depends on [Visualizaiton Configuration](#visualizaiton-configuration). You can refer to [Visualizer](visualization.md) for more details. For more configuration, you can refer to [VisualizationHook API](mmocr.engine.hooks.VisualizationHook).
+- `VisualizationHook`: Used to configure visualization-related behavior, such as visualizing predicted results during validation or testing. **Default is off**. This Hook also depends on [Visualization Configuration](#Visualization-configuration). You can refer to [Visualizer](visualization.md) for more details. For more configuration, you can refer to [VisualizationHook API](mmocr.engine.hooks.VisualizationHook).
If you want to learn more about the configuration of the default hooks and their functions, you can refer to {external+mmengine:doc}`MMEngine: Hooks `.
@@ -569,7 +569,7 @@ test_evaluator = val_evaluator
-### Visualizaiton Configuration
+### Visualization Configuration
Each task is bound to a task-specific visualizer. The visualizer is mainly used for visualizing or storing intermediate results of user models and visualizing val and test prediction results. The visualization results can also be stored in different backends such as WandB, TensorBoard, etc. through the corresponding visualization backend. Commonly used modification operations can be found in [visualization](visualization.md).
@@ -625,7 +625,7 @@ All these config files are distributed in different folders according to their c
default_runtime.py
|
- |
- Environment Configuration
Hook Configuration
Log Configuration
Checkpoint Loading Configuration
Evaluation Configuration
Visualizaiton Configuration |
+ Environment Configuration
Hook Configuration
Log Configuration
Checkpoint Loading Configuration
Evaluation Configuration
Visualization Configuration |
| dbnet |
diff --git a/mmocr/datasets/transforms/wrappers.py b/mmocr/datasets/transforms/wrappers.py
index 7a3489ee5..e0f900167 100644
--- a/mmocr/datasets/transforms/wrappers.py
+++ b/mmocr/datasets/transforms/wrappers.py
@@ -223,7 +223,7 @@ def __repr__(self):
@TRANSFORMS.register_module()
class TorchVisionWrapper(BaseTransform):
- """A wrapper around torchvision trasnforms. It applies specific transform
+ """A wrapper around torchvision transforms. It applies specific transform
to ``img`` and updates ``height`` and ``width`` accordingly.
Required Keys:
From bf921661c6b30c6556ef363555e74222824a79ac Mon Sep 17 00:00:00 2001
From: Xinyu Wang <45810070+xinke-wang@users.noreply.github.com>
Date: Sat, 8 Oct 2022 15:02:19 +0800
Subject: [PATCH 26/32] [Docs] Update Recog Models (#1402)
* init
* update
* update abinet
* update abinet
* update abinet
* update abinet
* apply comments
Co-authored-by: Tong Gao
* apply comments
Co-authored-by: Tong Gao
* fix
Co-authored-by: Tong Gao
---
configs/textrecog/abinet/README.md | 12 ++--
configs/textrecog/abinet/metafile.yml | 56 +++++++++------
configs/textrecog/master/README.md | 10 ++-
configs/textrecog/master/metafile.yml | 18 ++---
configs/textrecog/nrtr/README.md | 13 ++--
configs/textrecog/nrtr/metafile.yml | 70 ++++++++++++++-----
configs/textrecog/robust_scanner/README.md | 10 ++-
configs/textrecog/robust_scanner/metafile.yml | 16 ++---
configs/textrecog/sar/README.md | 12 ++--
configs/textrecog/sar/metafile.yml | 30 ++++----
configs/textrecog/satrn/README.md | 12 ++--
configs/textrecog/satrn/metafile.yml | 28 ++++----
12 files changed, 161 insertions(+), 126 deletions(-)
diff --git a/configs/textrecog/abinet/README.md b/configs/textrecog/abinet/README.md
index f3c6b6bc7..3959ebd57 100644
--- a/configs/textrecog/abinet/README.md
+++ b/configs/textrecog/abinet/README.md
@@ -34,13 +34,11 @@ Linguistic knowledge is of great benefit to scene text recognition. However, how
## Results and models
-Coming Soon!
-
-| methods | pretrained | | Regular Text | | | Irregular Text | | download |
-| :----------------------------------------------------------------------: | :--------------: | :----: | :----------: | :--: | :--: | :------------: | :--: | :----------------------- |
-| | | IIIT5K | SVT | IC13 | IC15 | SVTP | CT80 | |
-| [ABINet-Vision](/configs/textrecog/abinet/abinet-vision_20e_st-an_mj.py) | - | | | | | | | [model](<>) \| [log](<>) |
-| [ABINet](/configs/textrecog/abinet/abinet_20e_st-an_mj.py) | [Pretrained](<>) | | | | | | | [model](<>) \| [log](<>) |
+| methods | pretrained | | Regular Text | | | Irregular Text | | download |
+| :----------------------------------------------: | :--------------------------------------------------: | :----: | :----------: | :----: | :----: | :------------: | :----: | :------------------------------------------------- |
+| | | IIIT5K | SVT | IC13 | IC15 | SVTP | CT80 | |
+| [ABINet-Vision](/configs/textrecog/abinet/abinet-vision_20e_st-an_mj.py) | - | 0.9523 | 0.9057 | 0.9369 | 0.7886 | 0.8403 | 0.8437 | [model](https://download.openmmlab.com/mmocr/textrecog/abinet/abinet-vision_20e_st-an_mj/abinet-vision_20e_st-an_mj_20220915_152445-85cfb03d.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/abinet/abinet-vision_20e_st-an_mj/20220915_152445.log) |
+| [ABINet](/configs/textrecog/abinet/abinet_20e_st-an_mj.py) | [Pretrained](https://download.openmmlab.com/mmocr/textrecog/abinet/abinet_pretrain-45deac15.pth) | 0.9603 | 0.9382 | 0.9547 | 0.8122 | 0.8868 | 0.8785 | [model](https://download.openmmlab.com/mmocr/textrecog/abinet/abinet_20e_st-an_mj/abinet_20e_st-an_mj_20221005_012617-ead8c139.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/abinet/abinet_20e_st-an_mj/20221005_012617.log) |
```{note}
1. ABINet allows its encoder to run and be trained without decoder and fuser. Its encoder is designed to recognize texts as a stand-alone model and therefore can work as an independent text recognizer. We release it as ABINet-Vision.
diff --git a/configs/textrecog/abinet/metafile.yml b/configs/textrecog/abinet/metafile.yml
index d73aa9b06..dbc2cfbfb 100644
--- a/configs/textrecog/abinet/metafile.yml
+++ b/configs/textrecog/abinet/metafile.yml
@@ -1,4 +1,19 @@
Collections:
+- Name: ABINet-vision
+ Metadata:
+ Training Data: OCRDataset
+ Training Techniques:
+ - Adam
+ Epochs: 20
+ Batch Size: 1536
+ Training Resources: 2 x NVIDIA A100-SXM4-80GB
+ Architecture:
+ - ResNetABI
+ - ABIVisionModel
+ Paper:
+ URL: https://arxiv.org/pdf/2103.06495.pdf
+ Title: 'Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition'
+ README: configs/textrecog/abinet/README.md
- Name: ABINet
Metadata:
Training Data: OCRDataset
@@ -6,7 +21,7 @@ Collections:
- Adam
Epochs: 20
Batch Size: 1536
- Training Resources: 8x Tesla V100
+ Training Resources: 8 x NVIDIA A100-SXM4-80GB
Architecture:
- ResNetABI
- ABIVisionModel
@@ -18,9 +33,9 @@ Collections:
README: configs/textrecog/abinet/README.md
Models:
- - Name: abinet-vision_6e_st-an_mj
- In Collection: ABINet
- Config: configs/textrecog/abinet/abinet-vision_6e_st-an_mj.py
+ - Name: abinet-vision_20e_st-an_mj
+ In Collection: ABINet-vision
+ Config: configs/textrecog/abinet/abinet-vision_20e_st-an_mj.py
Metadata:
Training Data:
- SynthText
@@ -29,32 +44,31 @@ Models:
- Task: Text Recognition
Dataset: IIIT5K
Metrics:
- word_acc:
+ word_acc: 0.9523
- Task: Text Recognition
Dataset: SVT
Metrics:
- word_acc:
+ word_acc: 0.9057
- Task: Text Recognition
Dataset: ICDAR2013
Metrics:
- word_acc:
+ word_acc: 0.9369
- Task: Text Recognition
Dataset: ICDAR2015
Metrics:
- word_acc:
+ word_acc: 0.7886
- Task: Text Recognition
Dataset: SVTP
Metrics:
- word_acc:
+ word_acc: 0.8403
- Task: Text Recognition
Dataset: CT80
Metrics:
- word_acc:
- Weights:
-
- - Name: abinet_6e_st-an_mj
+ word_acc: 0.8437
+ Weights: https://download.openmmlab.com/mmocr/textrecog/abinet/abinet-vision_20e_st-an_mj/abinet-vision_20e_st-an_mj_20220915_152445-85cfb03d.pth
+ - Name: abinet_20e_st-an_mj
In Collection: ABINet
- Config: configs/textrecog/abinet/abinet_6e_st-an_mj.py
+ Config: configs/textrecog/abinet/abinet_20e_st-an_mj.py
Metadata:
Training Data:
- SynthText
@@ -63,25 +77,25 @@ Models:
- Task: Text Recognition
Dataset: IIIT5K
Metrics:
- word_acc:
+ word_acc: 0.9603
- Task: Text Recognition
Dataset: SVT
Metrics:
- word_acc:
+ word_acc: 0.9382
- Task: Text Recognition
Dataset: ICDAR2013
Metrics:
- word_acc:
+ word_acc: 0.9547
- Task: Text Recognition
Dataset: ICDAR2015
Metrics:
- word_acc:
+ word_acc: 0.8122
- Task: Text Recognition
Dataset: SVTP
Metrics:
- word_acc:
+ word_acc: 0.8868
- Task: Text Recognition
Dataset: CT80
Metrics:
- word_acc:
- Weights:
+ word_acc: 0.8785
+ Weights: https://download.openmmlab.com/mmocr/textrecog/abinet/abinet_20e_st-an_mj/abinet_20e_st-an_mj_20221005_012617-ead8c139.pth
diff --git a/configs/textrecog/master/README.md b/configs/textrecog/master/README.md
index 874d0ed3a..db2bd680d 100644
--- a/configs/textrecog/master/README.md
+++ b/configs/textrecog/master/README.md
@@ -35,12 +35,10 @@ Attention-based scene text recognizers have gained huge success, which leverages
## Results and Models
-Coming Soon!
-
-| Methods | Backbone | | Regular Text | | | | Irregular Text | | download |
-| :-----------------------------------------------------------------: | :-----------: | :----: | :----------: | :--: | :-: | :--: | :------------: | :--: | :----------------------: |
-| | | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 | |
-| [MASTER](/configs/textrecog/master/master_resnet31_12e_st_mj_sa.py) | R31-GCAModule | | | | | | | | [model](<>) \| [log](<>) |
+| Methods | Backbone | | Regular Text | | | | Irregular Text | | download |
+| :----------------------------------------------------------------: | :-----------: | :----: | :----------: | :----: | :-: | :----: | :------------: | :----: | :------------------------------------------------------------------: |
+| | | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 | |
+| [MASTER](/configs/textrecog/master/master_resnet31_12e_st_mj_sa.py) | R31-GCAModule | 0.9490 | 0.8967 | 0.9517 | | 0.7631 | 0.8465 | 0.8854 | [model](https://download.openmmlab.com/mmocr/textrecog/master/master_resnet31_12e_st_mj_sa/master_resnet31_12e_st_mj_sa_20220915_152443-f4a5cabc.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/master/master_resnet31_12e_st_mj_sa/20220915_152443.log) |
## Citation
diff --git a/configs/textrecog/master/metafile.yml b/configs/textrecog/master/metafile.yml
index e8c0cbde7..f4876e963 100644
--- a/configs/textrecog/master/metafile.yml
+++ b/configs/textrecog/master/metafile.yml
@@ -5,8 +5,8 @@ Collections:
Training Techniques:
- Adam
Epochs: 12
- Batch Size: 512
- Training Resources: 4x Tesla A100
+ Batch Size: 2048
+ Training Resources: 4x NVIDIA A100-SXM4-80GB
Architecture:
- ResNet31-GCAModule
- MASTERDecoder
@@ -28,25 +28,25 @@ Models:
- Task: Text Recognition
Dataset: IIIT5K
Metrics:
- word_acc:
+ word_acc: 0.9490
- Task: Text Recognition
Dataset: SVT
Metrics:
- word_acc:
+ word_acc: 0.8967
- Task: Text Recognition
Dataset: ICDAR2013
Metrics:
- word_acc:
+ word_acc: 0.9517
- Task: Text Recognition
Dataset: ICDAR2015
Metrics:
- word_acc:
+ word_acc: 0.7631
- Task: Text Recognition
Dataset: SVTP
Metrics:
- word_acc:
+ word_acc: 0.8465
- Task: Text Recognition
Dataset: CT80
Metrics:
- word_acc:
- Weights:
+ word_acc: 0.8854
+ Weights: https://download.openmmlab.com/mmocr/textrecog/master/master_resnet31_12e_st_mj_sa/master_resnet31_12e_st_mj_sa_20220915_152443-f4a5cabc.pth
diff --git a/configs/textrecog/nrtr/README.md b/configs/textrecog/nrtr/README.md
index f277f634c..86bfe04e8 100644
--- a/configs/textrecog/nrtr/README.md
+++ b/configs/textrecog/nrtr/README.md
@@ -34,13 +34,12 @@ Scene text recognition has attracted a great many researches due to its importan
## Results and Models
-Coming Soon!
-
-| Methods | Backbone | | Regular Text | | | | Irregular Text | | download |
-| :------------------------------------------------------------------: | :----------: | :----: | :----------: | :--: | :-: | :--: | :------------: | :--: | :----------------------: |
-| | | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 | |
-| [NRTR](/configs/textrecog/nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj.py) | R31-1/16-1/8 | | | | | | | | [model](<>) \| [log](<>) |
-| [NRTR](/configs/textrecog/nrtr/nrtr_resnet31-1by8-1by4_6e_st_mj.py) | R31-1/8-1/4 | | | | | | | | [model](<>) \| [log](<>) |
+| Methods | Backbone | | Regular Text | | | | Irregular Text | | download |
+| :------------------------------------------------------------: | :-------------------: | :----: | :----------: | :----: | :-: | :----: | :------------: | :----: | :--------------------------------------------------------------: |
+| | | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 | |
+| [NRTR](/configs/textrecog/nrtr/nrtr_modality-transform_6e_st_mj.py) | NRTRModalityTransform | 0.9150 | 0.8825 | 0.9369 | | 0.7232 | 0.7783 | 0.7500 | [model](https://download.openmmlab.com/mmocr/textrecog/nrtr/nrtr_modality-transform_6e_st_mj/nrtr_modality-transform_6e_st_mj_20220916_103322-bd9425be.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/nrtr/nrtr_modality-transform_6e_st_mj/20220916_103322.log) |
+| [NRTR](/configs/textrecog/nrtr/nrtr_resnet31-1by8-1by4_6e_st_mj.py) | R31-1/8-1/4 | 0.9483 | 0.8825 | 0.9507 | | 0.7559 | 0.8016 | 0.8889 | [model](https://download.openmmlab.com/mmocr/textrecog/nrtr/nrtr_resnet31-1by8-1by4_6e_st_mj/nrtr_resnet31-1by8-1by4_6e_st_mj_20220916_103322-a6a2a123.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/nrtr/nrtr_resnet31-1by8-1by4_6e_st_mj/20220916_103322.log) |
+| [NRTR](/configs/textrecog/nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj.py) | R31-1/16-1/8 | 0.9470 | 0.8964 | 0.9399 | | 0.7357 | 0.7969 | 0.8854 | [model](https://download.openmmlab.com/mmocr/textrecog/nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj/nrtr_resnet31-1by16-1by8_6e_st_mj_20220920_143358-43767036.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj/20220920_143358.log) |
## Citation
diff --git a/configs/textrecog/nrtr/metafile.yml b/configs/textrecog/nrtr/metafile.yml
index d2900840c..e7934a2e7 100644
--- a/configs/textrecog/nrtr/metafile.yml
+++ b/configs/textrecog/nrtr/metafile.yml
@@ -5,8 +5,8 @@ Collections:
Training Techniques:
- Adam
Epochs: 6
- Batch Size: 6144
- Training Resources: 1x Tesla A100
+ Batch Size: 384
+ Training Resources: 1x NVIDIA A100-SXM4-80GB
Architecture:
- CNN
- NRTREncoder
@@ -17,9 +17,9 @@ Collections:
README: configs/textrecog/nrtr/README.md
Models:
- - Name: nrtr_resnet31-1by16-1by8_6e_st_mj
+ - Name: nrtr_modality-transform_6e_st_mj
In Collection: NRTR
- Config: configs/textrecog/nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj.py
+ Config: configs/textrecog/nrtr/nrtr_modality-transform_6e_st_mj.py
Metadata:
Training Data:
- SynthText
@@ -28,29 +28,28 @@ Models:
- Task: Text Recognition
Dataset: IIIT5K
Metrics:
- word_acc:
+ word_acc: 0.9150
- Task: Text Recognition
Dataset: SVT
Metrics:
- word_acc:
+ word_acc: 0.8825
- Task: Text Recognition
Dataset: ICDAR2013
Metrics:
- word_acc:
+ word_acc: 0.9369
- Task: Text Recognition
Dataset: ICDAR2015
Metrics:
- word_acc:
+ word_acc: 0.7232
- Task: Text Recognition
Dataset: SVTP
Metrics:
- word_acc:
+ word_acc: 0.7783
- Task: Text Recognition
Dataset: CT80
Metrics:
- word_acc:
- Weights:
-
+ word_acc: 0.7500
+ Weights: https://download.openmmlab.com/mmocr/textrecog/nrtr/nrtr_modality-transform_6e_st_mj/nrtr_modality-transform_6e_st_mj_20220916_103322-bd9425be.pth
- Name: nrtr_resnet31-1by8-1by4_6e_st_mj
In Collection: NRTR
Config: configs/textrecog/nrtr/nrtr_resnet31-1by8-1by4_6e_st_mj.py
@@ -62,25 +61,58 @@ Models:
- Task: Text Recognition
Dataset: IIIT5K
Metrics:
- word_acc:
+ word_acc: 0.9483
+ - Task: Text Recognition
+ Dataset: SVT
+ Metrics:
+ word_acc: 0.8825
+ - Task: Text Recognition
+ Dataset: ICDAR2013
+ Metrics:
+ word_acc: 0.9507
+ - Task: Text Recognition
+ Dataset: ICDAR2015
+ Metrics:
+ word_acc: 0.7559
+ - Task: Text Recognition
+ Dataset: SVTP
+ Metrics:
+ word_acc: 0.8016
+ - Task: Text Recognition
+ Dataset: CT80
+ Metrics:
+ word_acc: 0.8889
+ Weights: https://download.openmmlab.com/mmocr/textrecog/nrtr/nrtr_resnet31-1by8-1by4_6e_st_mj/nrtr_resnet31-1by8-1by4_6e_st_mj_20220916_103322-a6a2a123.pth
+ - Name: nrtr_resnet31-1by16-1by8_6e_st_mj
+ In Collection: NRTR
+ Config: configs/textrecog/nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj.py
+ Metadata:
+ Training Data:
+ - SynthText
+ - Syn90k
+ Results:
+ - Task: Text Recognition
+ Dataset: IIIT5K
+ Metrics:
+ word_acc: 0.9470
- Task: Text Recognition
Dataset: SVT
Metrics:
- word_acc:
+ word_acc: 0.8964
- Task: Text Recognition
Dataset: ICDAR2013
Metrics:
- word_acc:
+ word_acc: 0.9399
- Task: Text Recognition
Dataset: ICDAR2015
Metrics:
- word_acc:
+ word_acc: 0.7357
- Task: Text Recognition
Dataset: SVTP
Metrics:
- word_acc:
+ word_acc: 0.7969
- Task: Text Recognition
Dataset: CT80
Metrics:
- word_acc:
- Weights:
+ word_acc: 0.8854
+ Weights: https://download.openmmlab.com/mmocr/textrecog/nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj/nrtr_resnet31-1by16-1by8_6e_st_mj_20220920_143358-43767036.pth
diff --git a/configs/textrecog/robust_scanner/README.md b/configs/textrecog/robust_scanner/README.md
index 24304fff7..1d1047284 100644
--- a/configs/textrecog/robust_scanner/README.md
+++ b/configs/textrecog/robust_scanner/README.md
@@ -40,12 +40,10 @@ The attention-based encoder-decoder framework has recently achieved impressive r
## Results and Models
-Coming Soon!
-
-| Methods | GPUs | | Regular Text | | | | Irregular Text | | download |
-| :--------------------------------------------------------------------------------------------------: | :--: | :----: | :----------: | :--: | :-: | :--: | :------------: | :--: | :----------------------: |
-| | | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 | |
-| [RobustScanner](configs/textrecog/robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py) | | | | | | | | | [model](<>) \| [log](<>) |
+| Methods | GPUs | | Regular Text | | | | Irregular Text | | download |
+| :---------------------------------------------------------------------: | :--: | :----: | :----------: | :----: | :-: | :----: | :------------: | :----: | :----------------------------------------------------------------------: |
+| | | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 | |
+| [RobustScanner](/configs/textrecog/robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py) | 4 | 0.9510 | 0.8934 | 0.9320 | | 0.7559 | 0.8078 | 0.8715 | [model](https://download.openmmlab.com/mmocr/textrecog/robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real_20220915_152447-7fc35929.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real/20220915_152447.log) |
## References
diff --git a/configs/textrecog/robust_scanner/metafile.yml b/configs/textrecog/robust_scanner/metafile.yml
index a4ed3bdaa..bdf6db428 100644
--- a/configs/textrecog/robust_scanner/metafile.yml
+++ b/configs/textrecog/robust_scanner/metafile.yml
@@ -6,7 +6,7 @@ Collections:
- Adam
Epochs: 5
Batch Size: 1024
- Training Resources: 16x GeForce GTX 1080 Ti
+ Training Resources: 4x NVIDIA A100-SXM4-80GB
Architecture:
- ResNet31OCR
- ChannelReductionEncoder
@@ -34,25 +34,25 @@ Models:
- Task: Text Recognition
Dataset: IIIT5K
Metrics:
- word_acc:
+ word_acc: 0.9510
- Task: Text Recognition
Dataset: SVT
Metrics:
- word_acc:
+ word_acc: 0.8934
- Task: Text Recognition
Dataset: ICDAR2013
Metrics:
- word_acc:
+ word_acc: 0.9320
- Task: Text Recognition
Dataset: ICDAR2015
Metrics:
- word_acc:
+ word_acc: 0.7559
- Task: Text Recognition
Dataset: SVTP
Metrics:
- word_acc:
+ word_acc: 0.8078
- Task: Text Recognition
Dataset: CT80
Metrics:
- word_acc:
- Weights:
+ word_acc: 0.8715
+ Weights: https://download.openmmlab.com/mmocr/textrecog/robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real_20220915_152447-7fc35929.pth
diff --git a/configs/textrecog/sar/README.md b/configs/textrecog/sar/README.md
index e02d353ba..d990de666 100644
--- a/configs/textrecog/sar/README.md
+++ b/configs/textrecog/sar/README.md
@@ -40,13 +40,11 @@ Recognizing irregular text in natural scene images is challenging due to the lar
## Results and Models
-Coming Soon!
-
-| Methods | Backbone | Decoder | | Regular Text | | | | Irregular Text | | download |
-| :-----------------------------------------------------------------: | :---------: | :------------------: | :----: | :----------: | :--: | :-: | :--: | :------------: | :--: | :----------------------: |
-| | | | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 | |
-| [SAR](/configs/textrecog/sar/sar_r31_parallel_decoder_academic.py) | R31-1/8-1/4 | ParallelSARDecoder | | | | | | | | [model](<>) \| [log](<>) |
-| [SAR](configs/textrecog/sar/sar_r31_sequential_decoder_academic.py) | R31-1/8-1/4 | SequentialSARDecoder | | | | | | | | [model](<>) \| [log](<>) |
+| Methods | Backbone | Decoder | | Regular Text | | | | Irregular Text | | download |
+| :-------------------------------------------------------: | :---------: | :------------------: | :----: | :----------: | :----: | :-: | :----: | :------------: | :----: | :---------------------------------------------------------: |
+| | | | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 | |
+| [SAR](/configs/textrecog/sar/sar_r31_parallel_decoder_academic.py) | R31-1/8-1/4 | ParallelSARDecoder | 0.9533 | 0.8841 | 0.9369 | | 0.7602 | 0.8326 | 0.9028 | [model](https://download.openmmlab.com/mmocr/textrecog/sar/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real_20220915_171910-04eb4e75.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/sar/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real/20220915_171910.log) |
+| [SAR](/configs/textrecog/sar/sar_r31_sequential_decoder_academic.py) | R31-1/8-1/4 | SequentialSARDecoder | 0.9553 | 0.8717 | 0.9409 | | 0.7737 | 0.8093 | 0.8924 | [model](https://download.openmmlab.com/mmocr/textrecog/sar/sar_resnet31_sequential-decoder_5e_st-sub_mj-sub_sa_real/sar_resnet31_sequential-decoder_5e_st-sub_mj-sub_sa_real_20220915_185451-1fd6b1fc.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/sar/sar_resnet31_sequential-decoder_5e_st-sub_mj-sub_sa_real/20220915_185451.log) |
## Citation
diff --git a/configs/textrecog/sar/metafile.yml b/configs/textrecog/sar/metafile.yml
index 5cd8d283b..cb1938347 100644
--- a/configs/textrecog/sar/metafile.yml
+++ b/configs/textrecog/sar/metafile.yml
@@ -4,7 +4,7 @@ Collections:
Training Data: OCRDataset
Training Techniques:
- Adam
- Training Resources: 48x GeForce GTX 1080 Ti
+ Training Resources: 8x NVIDIA A100-SXM4-80GB
Epochs: 5
Batch Size: 3072
Architecture:
@@ -34,28 +34,28 @@ Models:
- Task: Text Recognition
Dataset: IIIT5K
Metrics:
- word_acc:
+ word_acc: 0.9533
- Task: Text Recognition
Dataset: SVT
Metrics:
- word_acc:
+ word_acc: 0.8841
- Task: Text Recognition
Dataset: ICDAR2013
Metrics:
- word_acc:
+ word_acc: 0.9369
- Task: Text Recognition
Dataset: ICDAR2015
Metrics:
- word_acc:
+ word_acc: 0.7602
- Task: Text Recognition
Dataset: SVTP
Metrics:
- word_acc:
+ word_acc: 0.8326
- Task: Text Recognition
Dataset: CT80
Metrics:
- word_acc:
- Weights:
+ word_acc: 0.9028
+ Weights: https://download.openmmlab.com/mmocr/textrecog/sar/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real_20220915_171910-04eb4e75.pth
- Name: sar_resnet31_sequential-decoder_5e_st-sub_mj-sub_sa_real
In Collection: SAR
@@ -74,25 +74,25 @@ Models:
- Task: Text Recognition
Dataset: IIIT5K
Metrics:
- word_acc:
+ word_acc: 0.9553
- Task: Text Recognition
Dataset: SVT
Metrics:
- word_acc:
+ word_acc: 0.8717
- Task: Text Recognition
Dataset: ICDAR2013
Metrics:
- word_acc:
+ word_acc: 0.9409
- Task: Text Recognition
Dataset: ICDAR2015
Metrics:
- word_acc:
+ word_acc: 0.7737
- Task: Text Recognition
Dataset: SVTP
Metrics:
- word_acc:
+ word_acc: 0.8093
- Task: Text Recognition
Dataset: CT80
Metrics:
- word_acc:
- Weights:
+ word_acc: 0.8924
+ Weights: https://download.openmmlab.com/mmocr/textrecog/sar/sar_resnet31_sequential-decoder_5e_st-sub_mj-sub_sa_real/sar_resnet31_sequential-decoder_5e_st-sub_mj-sub_sa_real_20220915_185451-1fd6b1fc.pth
diff --git a/configs/textrecog/satrn/README.md b/configs/textrecog/satrn/README.md
index 731e69e4a..936b93d6b 100644
--- a/configs/textrecog/satrn/README.md
+++ b/configs/textrecog/satrn/README.md
@@ -34,13 +34,11 @@ Scene text recognition (STR) is the task of recognizing character sequences in n
## Results and Models
-Coming Soon!
-
-| Methods | | Regular Text | | | | Irregular Text | | download |
-| :---------------------------------------------------------------------: | :----: | :----------: | :--: | :-: | :--: | :------------: | :--: | :----------------------: |
-| | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 | |
-| [Satrn](/configs/textrecog/satrn/satrn_shallow_5e_st_mj.py) | | | | | | | | [model](<>) \| [log](<>) |
-| [Satrn_small](/configs/textrecog/satrn/satrn_shallow-small_5e_st_mj.py) | | | | | | | | [model](<>) \| [log](<>) |
+| Methods | | Regular Text | | | | Irregular Text | | download |
+| :---------------------------------------------------------------------: | :----: | :----------: | :----: | :-: | :----: | :------------: | :----: | :--------------------------------------------------------------------------: |
+| | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 | |
+| [Satrn](/configs/textrecog/satrn/satrn_shallow_5e_st_mj.py) | 0.9600 | 0.9196 | 0.9606 | | 0.8031 | 0.8837 | 0.8993 | [model](https://download.openmmlab.com/mmocr/textrecog/satrn/satrn_shallow_5e_st_mj/satrn_shallow_5e_st_mj_20220915_152443-5fd04a4c.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/satrn/satrn_shallow_5e_st_mj/20220915_152443.log) |
+| [Satrn_small](/configs/textrecog/satrn/satrn_shallow-small_5e_st_mj.py) | 0.9423 | 0.8995 | 0.9567 | | 0.7877 | 0.8574 | 0.8507 | [model](https://download.openmmlab.com/mmocr/textrecog/satrn/satrn_shallow-small_5e_st_mj/satrn_shallow-small_5e_st_mj_20220915_152442-5591bf27.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/satrn/satrn_shallow-small_5e_st_mj/20220915_152442.log) |
## Citation
diff --git a/configs/textrecog/satrn/metafile.yml b/configs/textrecog/satrn/metafile.yml
index 2ad8174f1..636fc368b 100644
--- a/configs/textrecog/satrn/metafile.yml
+++ b/configs/textrecog/satrn/metafile.yml
@@ -28,28 +28,28 @@ Models:
- Task: Text Recognition
Dataset: IIIT5K
Metrics:
- word_acc:
+ word_acc: 0.9600
- Task: Text Recognition
Dataset: SVT
Metrics:
- word_acc:
+ word_acc: 0.9196
- Task: Text Recognition
Dataset: ICDAR2013
Metrics:
- word_acc:
+ word_acc: 0.9606
- Task: Text Recognition
Dataset: ICDAR2015
Metrics:
- word_acc:
+ word_acc: 0.8031
- Task: Text Recognition
Dataset: SVTP
Metrics:
- word_acc:
+ word_acc: 0.8837
- Task: Text Recognition
Dataset: CT80
Metrics:
- word_acc:
- Weights:
+ word_acc: 0.8993
+ Weights: https://download.openmmlab.com/mmocr/textrecog/satrn/satrn_shallow_5e_st_mj/satrn_shallow_5e_st_mj_20220915_152443-5fd04a4c.pth
- Name: satrn_shallow-small_5e_st_mj
In Collection: SATRN
@@ -62,25 +62,25 @@ Models:
- Task: Text Recognition
Dataset: IIIT5K
Metrics:
- word_acc:
+ word_acc: 0.9423
- Task: Text Recognition
Dataset: SVT
Metrics:
- word_acc:
+ word_acc: 0.8995
- Task: Text Recognition
Dataset: ICDAR2013
Metrics:
- word_acc:
+ word_acc: 0.9567
- Task: Text Recognition
Dataset: ICDAR2015
Metrics:
- word_acc:
+ word_acc: 0.7877
- Task: Text Recognition
Dataset: SVTP
Metrics:
- word_acc:
+ word_acc: 0.8574
- Task: Text Recognition
Dataset: CT80
Metrics:
- word_acc:
- Weights:
+ word_acc: 0.8507
+ Weights: https://download.openmmlab.com/mmocr/textrecog/satrn/satrn_shallow-small_5e_st_mj/satrn_shallow-small_5e_st_mj_20220915_152442-5591bf27.pth
From 3d015462e7ef21de01cf5d251b5ad25f45fe9e5e Mon Sep 17 00:00:00 2001
From: Tong Gao
Date: Sun, 9 Oct 2022 12:43:23 +0800
Subject: [PATCH 27/32] [Feature] Update model links in ocr.py and inference.md
(#1431)
* [Feature] Update model links in ocr.py and inference.md
* Apply suggestions from code review
Co-authored-by: Xinyu Wang <45810070+xinke-wang@users.noreply.github.com>
Co-authored-by: Xinyu Wang <45810070+xinke-wang@users.noreply.github.com>
---
docs/en/user_guides/inference.md | 45 ++++++-----
docs/zh_cn/user_guides/inference.md | 51 +++++++-----
mmocr/ocr.py | 120 ++++++++++++++++------------
3 files changed, 125 insertions(+), 91 deletions(-)
diff --git a/docs/en/user_guides/inference.md b/docs/en/user_guides/inference.md
index 6f10d5c09..6660d0bd8 100644
--- a/docs/en/user_guides/inference.md
+++ b/docs/en/user_guides/inference.md
@@ -147,27 +147,36 @@ means that `print_result` is set to `True`)
**Text detection:**
-| Name | Reference |
-| ------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------: |
-| DB_r18 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#real-time-scene-text-detection-with-differentiable-binarization) |
-| DB_r50 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#real-time-scene-text-detection-with-differentiable-binarization) |
-| DBPP_r50 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#dbnetpp) |
-| DRRG | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#drrg) |
-| FCE_IC15 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#fourier-contour-embedding-for-arbitrary-shaped-text-detection) |
-| FCE_CTW_DCNv2 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#fourier-contour-embedding-for-arbitrary-shaped-text-detection) |
-| MaskRCNN_CTW | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#mask-r-cnn) |
-| MaskRCNN_IC15 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#mask-r-cnn) |
-| PANet_CTW | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#efficient-and-accurate-arbitrary-shaped-text-detection-with-pixel-aggregation-network) |
-| PANet_IC15 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#efficient-and-accurate-arbitrary-shaped-text-detection-with-pixel-aggregation-network) |
-| PS_CTW | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#psenet) |
-| PS_IC15 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#psenet) |
-| TextSnake | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#textsnake) |
+| Name | Reference |
+| ------------- | :----------------------------------------------------------------------------: |
+| DB_r18 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#dbnet) |
+| DB_r50 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#dbnet) |
+| DBPP_r50 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#dbnetpp) |
+| DRRG | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#drrg) |
+| FCE_IC15 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#fcenet) |
+| FCE_CTW_DCNv2 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#fcenet) |
+| MaskRCNN_CTW | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#mask-r-cnn) |
+| MaskRCNN_IC15 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#mask-r-cnn) |
+| PANet_CTW | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#panet) |
+| PANet_IC15 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#panet) |
+| PS_CTW | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#psenet) |
+| PS_IC15 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#psenet) |
+| TextSnake | [link](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#textsnake) |
**Text recognition:**
-| Name | Reference |
-| ---- | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
-| CRNN | [link](https://mmocr.readthedocs.io/en/dev-1.x/textrecog_models.html#an-end-to-end-trainable-neural-network-for-image-based-sequence-recognition-and-its-application-to-scene-text-recognition) |
+| Name | Reference |
+| ------------- | :---------------------------------------------------------------------------------: |
+| ABINet | [link](https://mmocr.readthedocs.io/en/dev-1.x/textrecog_models.html#abinet) |
+| ABINet_Vision | [link](https://mmocr.readthedocs.io/en/dev-1.x/textrecog_models.html#abinet) |
+| CRNN | [link](https://mmocr.readthedocs.io/en/dev-1.x/textrecog_models.html#crnn) |
+| MASTER | [link](https://mmocr.readthedocs.io/en/dev-1.x/textrecog_models.html#master) |
+| NRTR_1/16-1/8 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textrecog_models.html#nrtr) |
+| NRTR_1/8-1/4 | [link](https://mmocr.readthedocs.io/en/dev-1.x/textrecog_models.html#nrtr) |
+| RobustScanner | [link](https://mmocr.readthedocs.io/en/dev-1.x/textrecog_models.html#robustscanner) |
+| SAR | [link](https://mmocr.readthedocs.io/en/dev-1.x/textrecog_models.html#sar) |
+| SATRN | [link](https://mmocr.readthedocs.io/en/dev-1.x/textrecog_models.html#satrn) |
+| SATRN_sm | [link](https://mmocr.readthedocs.io/en/dev-1.x/textrecog_models.html#satrn) |
**Key information extraction:**
diff --git a/docs/zh_cn/user_guides/inference.md b/docs/zh_cn/user_guides/inference.md
index a8f4dab56..0b2ef6945 100644
--- a/docs/zh_cn/user_guides/inference.md
+++ b/docs/zh_cn/user_guides/inference.md
@@ -145,33 +145,42 @@ mmocr 为了方便使用提供了预置的模型配置和对应的预训练权
**文本检测:**
-| 名称 | 引用 |
-| ------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------: |
-| DB_r18 | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#real-time-scene-text-detection-with-differentiable-binarization) |
-| DB_r50 | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#real-time-scene-text-detection-with-differentiable-binarization) |
-| DBPP_r50 | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#dbnetpp) |
-| DRRG | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#drrg) |
-| FCE_IC15 | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#fourier-contour-embedding-for-arbitrary-shaped-text-detection) |
-| FCE_CTW_DCNv2 | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#fourier-contour-embedding-for-arbitrary-shaped-text-detection) |
-| MaskRCNN_CTW | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#mask-r-cnn) |
-| MaskRCNN_IC15 | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#mask-r-cnn) |
-| PANet_CTW | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#efficient-and-accurate-arbitrary-shaped-text-detection-with-pixel-aggregation-network) |
-| PANet_IC15 | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#efficient-and-accurate-arbitrary-shaped-text-detection-with-pixel-aggregation-network) |
-| PS_CTW | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#psenet) |
-| PS_IC15 | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#psenet) |
-| TextSnake | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textdet_models.html#textsnake) |
+| 名称 | 引用 |
+| ------------- | :----------------------------------------------------------------------------: |
+| DB_r18 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#dbnet) |
+| DB_r50 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#dbnet) |
+| DBPP_r50 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#dbnetpp) |
+| DRRG | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#drrg) |
+| FCE_IC15 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#fcenet) |
+| FCE_CTW_DCNv2 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#fcenet) |
+| MaskRCNN_CTW | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#mask-r-cnn) |
+| MaskRCNN_IC15 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#mask-r-cnn) |
+| PANet_CTW | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#panet) |
+| PANet_IC15 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#panet) |
+| PS_CTW | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#psenet) |
+| PS_IC15 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#psenet) |
+| TextSnake | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#textsnake) |
**文本识别:**
-| 名称 | 引用 |
-| ---- | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
-| CRNN | [链接](https://mmocr.readthedocs.io/en/dev-1.x/textrecog_models.html#an-end-to-end-trainable-neural-network-for-image-based-sequence-recognition-and-its-application-to-scene-text-recognition) |
+| 名称 | 引用 |
+| ------------- | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| ABINet | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#abinet) |
+| ABINet_Vision | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#abinet) |
+| CRNN | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#crnn) |
+| MASTER | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#master) |
+| NRTR_1/16-1/8 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#nrtr) |
+| NRTR_1/8-1/4 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#nrtr) |
+| RobustScanner | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#robustscanner) |
+| SAR | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#sar) |
+| SATRN | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#satrn) |
+| SATRN_sm | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#satrn) |
**关键信息提取:**
-| 名称 |
-| ------------------------------------------------------------------------------------------------------------------------------------- |
-| [SDMGR](https://mmocr.readthedocs.io/en/dev-1.x/kie_models.html#spatial-dual-modality-graph-reasoning-for-key-information-extraction) |
+| 名称 |
+| ------------------------------------------------------------------- |
+| [SDMGR](https://mmocr.readthedocs.io/zh_CN/dev-1.x/kie_models.html) |
## 其他需要注意
diff --git a/mmocr/ocr.py b/mmocr/ocr.py
index a55022b2e..616c20f83 100755
--- a/mmocr/ocr.py
+++ b/mmocr/ocr.py
@@ -379,71 +379,87 @@ def get_model_config(self, model_name: str) -> Dict:
'ckpt':
'textrecog/crnn/crnn_mini-vgg_5e_mj/crnn_mini-vgg_5e_mj_20220826_224120-8afbedbb.pth' # noqa: E501
},
- # 'SAR': {
- # 'config':
- # 'textrecog/sar/'
- # 'sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real.py',
- # 'ckpt':
- # ''
- # },
+ 'SAR': {
+ 'config':
+ 'textrecog/sar/'
+ 'sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real.py',
+ 'ckpt':
+ 'textrecog/sar/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real_20220915_171910-04eb4e75.pth' # noqa: E501
+ },
# 'SAR_CN': {
# 'config':
# 'textrecog/'
# 'sar/sar_r31_parallel_decoder_chinese.py',
# 'ckpt':
- # 'textrecog/'
- # ''
- # },
- # 'NRTR_1/16-1/8': {
- # 'config':
- # 'textrecog/'
- # 'nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj.py',
- # 'ckpt':
- # 'textrecog/'
- # ''
- # },
- # 'NRTR_1/8-1/4': {
- # 'config':
- # 'textrecog/'
- # 'nrtr/nrtr_resnet31-1by8-1by4_6e_st_mj.py',
- # 'ckpt':
- # 'textrecog/'
- # ''
- # },
- # 'RobustScanner': {
- # 'config':
- # 'textrecog/robust_scanner/'
- # 'robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py',
- # 'ckpt':
- # 'textrecog/'
+ # 'textrecog/' # noqa: E501
# ''
# },
- # 'SATRN': {
- # 'config': 'textrecog/satrn/satrn_shallow_5e_st_mj.py',
- # 'ckpt': ''
- # },
- # 'SATRN_sm': {
- # 'config': 'textrecog/satrn/satrn_shallow-small_5e_st_mj.py',
- # 'ckpt': ''
- # },
- # 'ABINet': {
- # 'config': 'textrecog/abinet/abinet_20e_st-an_mj.py',
- # 'ckpt': ''
- # },
- # 'ABINet_Vision': {
- # 'config': 'textrecog/abinet/abinet-vision_20e_st-an_mj.py',
- # 'ckpt': ''
- # },
+ 'NRTR_1/16-1/8': {
+ 'config':
+ 'textrecog/'
+ 'nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj.py',
+ 'ckpt':
+ 'textrecog/'
+ 'nrtr/nrtr_resnet31-1by16-1by8_6e_st_mj/nrtr_resnet31-1by16-1by8_6e_st_mj_20220920_143358-43767036.pth' # noqa: E501
+ },
+ 'NRTR_1/8-1/4': {
+ 'config':
+ 'textrecog/'
+ 'nrtr/nrtr_resnet31-1by8-1by4_6e_st_mj.py',
+ 'ckpt':
+ 'textrecog/'
+ 'nrtr/nrtr_resnet31-1by8-1by4_6e_st_mj/nrtr_resnet31-1by8-1by4_6e_st_mj_20220916_103322-a6a2a123.pth' # noqa: E501
+ },
+ 'RobustScanner': {
+ 'config':
+ 'textrecog/robust_scanner/'
+ 'robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py',
+ 'ckpt':
+ 'textrecog/'
+ 'robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real_20220915_152447-7fc35929.pth' # noqa: E501
+ },
+ 'SATRN': {
+ 'config':
+ 'textrecog/satrn/satrn_shallow_5e_st_mj.py',
+ 'ckpt':
+ 'textrecog/'
+ 'satrn/satrn_shallow_5e_st_mj/satrn_shallow_5e_st_mj_20220915_152443-5fd04a4c.pth' # noqa: E501
+ },
+ 'SATRN_sm': {
+ 'config':
+ 'textrecog/satrn/satrn_shallow-small_5e_st_mj.py',
+ 'ckpt':
+ 'textrecog/'
+ 'satrn/satrn_shallow-small_5e_st_mj/satrn_shallow-small_5e_st_mj_20220915_152442-5591bf27.pth' # noqa: E501
+ },
+ 'ABINet': {
+ 'config':
+ 'textrecog/abinet/abinet_20e_st-an_mj.py',
+ 'ckpt':
+ 'textrecog/'
+ 'abinet/abinet_20e_st-an_mj/abinet_20e_st-an_mj_20221005_012617-ead8c139.pth' # noqa: E501
+ },
+ 'ABINet_Vision': {
+ 'config':
+ 'textrecog/abinet/abinet-vision_20e_st-an_mj.py',
+ 'ckpt':
+ 'textrecog/'
+ 'abinet/abinet-vision_20e_st-an_mj/abinet-vision_20e_st-an_mj_20220915_152445-85cfb03d.pth' # noqa: E501
+ },
# 'CRNN_TPS': {
# 'config':
# 'textrecog/tps/crnn_tps_academic_dataset.py',
# 'ckpt':
+ # 'textrecog/'
# ''
# },
- # 'MASTER': {
- # 'config': 'textrecog/master/master_resnet31_12e_st_mj_sa.py',
- # 'ckpt': ''
- # },
+ 'MASTER': {
+ 'config':
+ 'textrecog/master/master_resnet31_12e_st_mj_sa.py',
+ 'ckpt':
+ 'textrecog/'
+ 'master/master_resnet31_12e_st_mj_sa/master_resnet31_12e_st_mj_sa_20220915_152443-f4a5cabc.pth' # noqa: E501
+ },
# KIE models
'SDMGR': {
'config':
From b26907e9081d18543e969d02c82390912def023b Mon Sep 17 00:00:00 2001
From: Tong Gao
Date: Sun, 9 Oct 2022 12:43:45 +0800
Subject: [PATCH 28/32] [Config] Update rec configs (#1417)
---
configs/textrecog/abinet/_base_abinet-vision.py | 2 +-
configs/textrecog/abinet/abinet_20e_st-an_mj.py | 2 +-
configs/textrecog/crnn/_base_crnn_mini-vgg.py | 2 +-
configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py | 2 +-
configs/textrecog/master/_base_master_resnet31.py | 2 +-
configs/textrecog/master/master_resnet31_12e_st_mj_sa.py | 2 +-
configs/textrecog/nrtr/_base_nrtr_modality-transform.py | 2 +-
configs/textrecog/nrtr/_base_nrtr_resnet31.py | 2 +-
configs/textrecog/nrtr/nrtr_modality-transform_6e_st_mj.py | 2 +-
.../textrecog/robust_scanner/_base_robustscanner_resnet31.py | 2 +-
.../robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py | 4 ++--
configs/textrecog/sar/_base_sar_resnet31_parallel-decoder.py | 2 +-
.../sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real.py | 4 ++--
configs/textrecog/satrn/_base_satrn_shallow.py | 2 +-
configs/textrecog/satrn/satrn_shallow_5e_st_mj.py | 4 ++--
15 files changed, 18 insertions(+), 18 deletions(-)
diff --git a/configs/textrecog/abinet/_base_abinet-vision.py b/configs/textrecog/abinet/_base_abinet-vision.py
index ee889c287..ef9a482f3 100644
--- a/configs/textrecog/abinet/_base_abinet-vision.py
+++ b/configs/textrecog/abinet/_base_abinet-vision.py
@@ -46,7 +46,7 @@
type='LoadImageFromFile',
file_client_args=file_client_args,
ignore_empty=True,
- min_size=5),
+ min_size=2),
dict(type='LoadOCRAnnotations', with_text=True),
dict(type='Resize', scale=(128, 32)),
dict(
diff --git a/configs/textrecog/abinet/abinet_20e_st-an_mj.py b/configs/textrecog/abinet/abinet_20e_st-an_mj.py
index 832770759..f59925c1e 100644
--- a/configs/textrecog/abinet/abinet_20e_st-an_mj.py
+++ b/configs/textrecog/abinet/abinet_20e_st-an_mj.py
@@ -37,7 +37,7 @@
type='ConcatDataset', datasets=test_list, pipeline=_base_.test_pipeline)
train_dataloader = dict(
- batch_size=192 * 4,
+ batch_size=192,
num_workers=32,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
diff --git a/configs/textrecog/crnn/_base_crnn_mini-vgg.py b/configs/textrecog/crnn/_base_crnn_mini-vgg.py
index 519f95e9c..b18a61e7c 100644
--- a/configs/textrecog/crnn/_base_crnn_mini-vgg.py
+++ b/configs/textrecog/crnn/_base_crnn_mini-vgg.py
@@ -25,7 +25,7 @@
color_type='grayscale',
file_client_args=file_client_args,
ignore_empty=True,
- min_size=5),
+ min_size=2),
dict(type='LoadOCRAnnotations', with_text=True),
dict(type='Resize', scale=(100, 32), keep_ratio=False),
dict(
diff --git a/configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py b/configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py
index acc76cdde..d3eed5cbc 100644
--- a/configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py
+++ b/configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py
@@ -23,7 +23,7 @@
train_dataloader = dict(
batch_size=64,
- num_workers=8,
+ num_workers=24,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=dict(
diff --git a/configs/textrecog/master/_base_master_resnet31.py b/configs/textrecog/master/_base_master_resnet31.py
index 03ff7afe2..decc755d5 100644
--- a/configs/textrecog/master/_base_master_resnet31.py
+++ b/configs/textrecog/master/_base_master_resnet31.py
@@ -79,7 +79,7 @@
type='LoadImageFromFile',
file_client_args=file_client_args,
ignore_empty=True,
- min_size=5),
+ min_size=2),
dict(type='LoadOCRAnnotations', with_text=True),
dict(
type='RescaleToHeight',
diff --git a/configs/textrecog/master/master_resnet31_12e_st_mj_sa.py b/configs/textrecog/master/master_resnet31_12e_st_mj_sa.py
index 4695e4cfb..01c461925 100644
--- a/configs/textrecog/master/master_resnet31_12e_st_mj_sa.py
+++ b/configs/textrecog/master/master_resnet31_12e_st_mj_sa.py
@@ -37,7 +37,7 @@
train_dataloader = dict(
batch_size=512,
- num_workers=4,
+ num_workers=24,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=train_dataset)
diff --git a/configs/textrecog/nrtr/_base_nrtr_modality-transform.py b/configs/textrecog/nrtr/_base_nrtr_modality-transform.py
index 1ca42dd88..bd119f146 100644
--- a/configs/textrecog/nrtr/_base_nrtr_modality-transform.py
+++ b/configs/textrecog/nrtr/_base_nrtr_modality-transform.py
@@ -30,7 +30,7 @@
type='LoadImageFromFile',
file_client_args=file_client_args,
ignore_empty=True,
- min_size=5),
+ min_size=2),
dict(type='LoadOCRAnnotations', with_text=True),
dict(
type='RescaleToHeight',
diff --git a/configs/textrecog/nrtr/_base_nrtr_resnet31.py b/configs/textrecog/nrtr/_base_nrtr_resnet31.py
index 9a2e4d95b..e5757eaa4 100644
--- a/configs/textrecog/nrtr/_base_nrtr_resnet31.py
+++ b/configs/textrecog/nrtr/_base_nrtr_resnet31.py
@@ -36,7 +36,7 @@
type='LoadImageFromFile',
file_client_args=file_client_args,
ignore_empty=True,
- min_size=5),
+ min_size=2),
dict(type='LoadOCRAnnotations', with_text=True),
dict(
type='RescaleToHeight',
diff --git a/configs/textrecog/nrtr/nrtr_modality-transform_6e_st_mj.py b/configs/textrecog/nrtr/nrtr_modality-transform_6e_st_mj.py
index 89784a0e7..a25afa197 100644
--- a/configs/textrecog/nrtr/nrtr_modality-transform_6e_st_mj.py
+++ b/configs/textrecog/nrtr/nrtr_modality-transform_6e_st_mj.py
@@ -33,7 +33,7 @@
train_dataloader = dict(
batch_size=384,
- num_workers=32,
+ num_workers=24,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=train_dataset)
diff --git a/configs/textrecog/robust_scanner/_base_robustscanner_resnet31.py b/configs/textrecog/robust_scanner/_base_robustscanner_resnet31.py
index d75b1fd55..aab1708be 100644
--- a/configs/textrecog/robust_scanner/_base_robustscanner_resnet31.py
+++ b/configs/textrecog/robust_scanner/_base_robustscanner_resnet31.py
@@ -36,7 +36,7 @@
type='LoadImageFromFile',
file_client_args=file_client_args,
ignore_empty=True,
- min_size=5),
+ min_size=2),
dict(type='LoadOCRAnnotations', with_text=True),
dict(
type='RescaleToHeight',
diff --git a/configs/textrecog/robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py b/configs/textrecog/robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py
index 2a9edbf15..6651ab7b5 100644
--- a/configs/textrecog/robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py
+++ b/configs/textrecog/robust_scanner/robustscanner_resnet31_5e_st-sub_mj-sub_sa_real.py
@@ -43,8 +43,8 @@
]
train_dataloader = dict(
- batch_size=64,
- num_workers=8,
+ batch_size=64 * 4,
+ num_workers=24,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=dict(type='ConcatDataset', datasets=train_list, verify_meta=False))
diff --git a/configs/textrecog/sar/_base_sar_resnet31_parallel-decoder.py b/configs/textrecog/sar/_base_sar_resnet31_parallel-decoder.py
index 6734fb667..3fcb0cee6 100755
--- a/configs/textrecog/sar/_base_sar_resnet31_parallel-decoder.py
+++ b/configs/textrecog/sar/_base_sar_resnet31_parallel-decoder.py
@@ -41,7 +41,7 @@
type='LoadImageFromFile',
file_client_args=file_client_args,
ignore_empty=True,
- min_size=5),
+ min_size=2),
dict(type='LoadOCRAnnotations', with_text=True),
dict(
type='RescaleToHeight',
diff --git a/configs/textrecog/sar/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real.py b/configs/textrecog/sar/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real.py
index cfcdf5028..1db30c22a 100644
--- a/configs/textrecog/sar/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real.py
+++ b/configs/textrecog/sar/sar_resnet31_parallel-decoder_5e_st-sub_mj-sub_sa_real.py
@@ -43,8 +43,8 @@
]
train_dataloader = dict(
- batch_size=64,
- num_workers=8,
+ batch_size=64 * 6,
+ num_workers=24,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=dict(type='ConcatDataset', datasets=train_list, verify_meta=False))
diff --git a/configs/textrecog/satrn/_base_satrn_shallow.py b/configs/textrecog/satrn/_base_satrn_shallow.py
index d8eb7a256..11daee52b 100644
--- a/configs/textrecog/satrn/_base_satrn_shallow.py
+++ b/configs/textrecog/satrn/_base_satrn_shallow.py
@@ -46,7 +46,7 @@
type='LoadImageFromFile',
file_client_args=file_client_args,
ignore_empty=True,
- min_size=5),
+ min_size=2),
dict(type='LoadOCRAnnotations', with_text=True),
dict(type='Resize', scale=(100, 32), keep_ratio=False),
dict(
diff --git a/configs/textrecog/satrn/satrn_shallow_5e_st_mj.py b/configs/textrecog/satrn/satrn_shallow_5e_st_mj.py
index 16a7ef50c..bbf75c0b4 100644
--- a/configs/textrecog/satrn/satrn_shallow_5e_st_mj.py
+++ b/configs/textrecog/satrn/satrn_shallow_5e_st_mj.py
@@ -28,8 +28,8 @@
optim_wrapper = dict(type='OptimWrapper', optimizer=dict(type='Adam', lr=3e-4))
train_dataloader = dict(
- batch_size=64,
- num_workers=8,
+ batch_size=128,
+ num_workers=24,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=train_dataset)
From dfc17207baa812def8ca13d0e31e11650be2e1f9 Mon Sep 17 00:00:00 2001
From: liukuikun <24622904+Harold-lkk@users.noreply.github.com>
Date: Sun, 9 Oct 2022 12:45:17 +0800
Subject: [PATCH 29/32] [Vis] visualizer refine (#1411)
* visualizer refine
* updata docs
---
mmocr/visualization/__init__.py | 5 +-
mmocr/visualization/base_visualizer.py | 135 ++-
mmocr/visualization/kie_visualizer.py | 201 +---
mmocr/visualization/textdet_visualizer.py | 140 ++-
mmocr/visualization/textrecog_visualizer.py | 75 +-
.../visualization/textspotting_visualizer.py | 89 +-
mmocr/visualization/visualize.py | 890 ------------------
.../test_base_visualizer.py | 55 ++
.../test_visualization/test_kie_visualizer.py | 15 +
.../test_textdet_visualizer.py | 4 +
.../test_textrecog_visualizer.py | 10 +-
.../test_textspotting_visualizer.py | 113 +++
12 files changed, 489 insertions(+), 1243 deletions(-)
delete mode 100644 mmocr/visualization/visualize.py
create mode 100644 tests/test_visualization/test_base_visualizer.py
create mode 100644 tests/test_visualization/test_textspotting_visualizer.py
diff --git a/mmocr/visualization/__init__.py b/mmocr/visualization/__init__.py
index 260818857..b070794bb 100644
--- a/mmocr/visualization/__init__.py
+++ b/mmocr/visualization/__init__.py
@@ -1,10 +1,11 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from .base_visualizer import BaseLocalVisualizer
from .kie_visualizer import KIELocalVisualizer
from .textdet_visualizer import TextDetLocalVisualizer
from .textrecog_visualizer import TextRecogLocalVisualizer
from .textspotting_visualizer import TextSpottingLocalVisualizer
__all__ = [
- 'KIELocalVisualizer', 'TextDetLocalVisualizer', 'TextRecogLocalVisualizer',
- 'TextSpottingLocalVisualizer'
+ 'BaseLocalVisualizer', 'KIELocalVisualizer', 'TextDetLocalVisualizer',
+ 'TextRecogLocalVisualizer', 'TextSpottingLocalVisualizer'
]
diff --git a/mmocr/visualization/base_visualizer.py b/mmocr/visualization/base_visualizer.py
index ffee8d3cd..1501c6cb9 100644
--- a/mmocr/visualization/base_visualizer.py
+++ b/mmocr/visualization/base_visualizer.py
@@ -50,14 +50,13 @@ class BaseLocalVisualizer(Visualizer):
(95, 54, 80), (128, 76, 255), (201, 57, 1), (246, 0, 122),
(191, 162, 208)]
- @staticmethod
- def _draw_labels(visualizer: Visualizer,
- image: np.ndarray,
- labels: Union[np.ndarray, torch.Tensor],
- bboxes: Union[np.ndarray, torch.Tensor],
- colors: Union[str, Sequence[str]] = 'k',
- font_size: Union[int, float] = 10,
- auto_font_size: bool = False) -> np.ndarray:
+ def get_labels_image(self,
+ image: np.ndarray,
+ labels: Union[np.ndarray, torch.Tensor],
+ bboxes: Union[np.ndarray, torch.Tensor],
+ colors: Union[str, Sequence[str]] = 'k',
+ font_size: Union[int, float] = 10,
+ auto_font_size: bool = False) -> np.ndarray:
"""Draw labels on image.
Args:
@@ -75,7 +74,7 @@ def _draw_labels(visualizer: Visualizer,
auto_font_size (bool): Whether to automatically adjust font size.
Defaults to False.
"""
- if colors is not None and isinstance(colors, Sequence):
+ if colors is not None and isinstance(colors, (list, tuple)):
size = math.ceil(len(labels) / len(colors))
colors = (colors * size)[:len(labels)]
if auto_font_size:
@@ -83,68 +82,124 @@ def _draw_labels(visualizer: Visualizer,
font_size, (int, float))
font_size = (bboxes[:, 2:] - bboxes[:, :2]).min(-1) * font_size
font_size = font_size.tolist()
- visualizer.set_image(image)
- visualizer.draw_texts(
+ self.set_image(image)
+ self.draw_texts(
labels, (bboxes[:, :2] + bboxes[:, 2:]) / 2,
vertical_alignments='center',
horizontal_alignments='center',
colors='k',
font_sizes=font_size)
- return visualizer.get_image()
-
- @staticmethod
- def _draw_polygons(visualizer: Visualizer,
- image: np.ndarray,
- polygons: Sequence[np.ndarray],
- colors: Union[str, Sequence[str]] = 'g',
- filling: bool = False,
- line_width: Union[int, float] = 0.5,
- alpha: float = 0.5) -> np.ndarray:
- if colors is not None and isinstance(colors, Sequence):
+ return self.get_image()
+
+ def get_polygons_image(self,
+ image: np.ndarray,
+ polygons: Sequence[np.ndarray],
+ colors: Union[str, Sequence[str]] = 'g',
+ filling: bool = False,
+ line_width: Union[int, float] = 0.5,
+ alpha: float = 0.5) -> np.ndarray:
+ """Draw polygons on image.
+
+ Args:
+ image (np.ndarray): The origin image to draw. The format
+ should be RGB.
+ polygons (Sequence[np.ndarray]): The polygons to draw. The shape
+ should be (N, 2).
+ colors (Union[str, Sequence[str]]): The colors of polygons.
+ ``colors`` can have the same length with polygons or just
+ single value. If ``colors`` is single value, all the polygons
+ will have the same colors. Refer to `matplotlib.colors` for
+ full list of formats that are accepted. Defaults to 'g'.
+ filling (bool): Whether to fill the polygons. Defaults to False.
+ line_width (Union[int, float]): The line width of polygons.
+ Defaults to 0.5.
+ alpha (float): The alpha of polygons. Defaults to 0.5.
+
+ Returns:
+ np.ndarray: The image with polygons drawn.
+ """
+ if colors is not None and isinstance(colors, (list, tuple)):
size = math.ceil(len(polygons) / len(colors))
colors = (colors * size)[:len(polygons)]
- visualizer.set_image(image)
+ self.set_image(image)
if filling:
- visualizer.draw_polygons(
+ self.draw_polygons(
polygons,
face_colors=colors,
edge_colors=colors,
line_widths=line_width,
alpha=alpha)
else:
- visualizer.draw_polygons(
+ self.draw_polygons(
polygons,
edge_colors=colors,
line_widths=line_width,
alpha=alpha)
- return visualizer.get_image()
-
- @staticmethod
- def _draw_bboxes(visualizer: Visualizer,
- image: np.ndarray,
- bboxes: Union[np.ndarray, torch.Tensor],
- colors: Union[str, Sequence[str]] = 'g',
- filling: bool = False,
- line_width: Union[int, float] = 0.5,
- alpha: float = 0.5) -> np.ndarray:
- if colors is not None and isinstance(colors, Sequence):
+ return self.get_image()
+
+ def get_bboxes_image(self: Visualizer,
+ image: np.ndarray,
+ bboxes: Union[np.ndarray, torch.Tensor],
+ colors: Union[str, Sequence[str]] = 'g',
+ filling: bool = False,
+ line_width: Union[int, float] = 0.5,
+ alpha: float = 0.5) -> np.ndarray:
+ """Draw bboxes on image.
+
+ Args:
+ image (np.ndarray): The origin image to draw. The format
+ should be RGB.
+ bboxes (Union[np.ndarray, torch.Tensor]): The bboxes to draw.
+ colors (Union[str, Sequence[str]]): The colors of bboxes.
+ ``colors`` can have the same length with bboxes or just single
+ value. If ``colors`` is single value, all the bboxes will have
+ the same colors. Refer to `matplotlib.colors` for full list of
+ formats that are accepted. Defaults to 'g'.
+ filling (bool): Whether to fill the bboxes. Defaults to False.
+ line_width (Union[int, float]): The line width of bboxes.
+ Defaults to 0.5.
+ alpha (float): The alpha of bboxes. Defaults to 0.5.
+
+ Returns:
+ np.ndarray: The image with bboxes drawn.
+ """
+ if colors is not None and isinstance(colors, (list, tuple)):
size = math.ceil(len(bboxes) / len(colors))
colors = (colors * size)[:len(bboxes)]
- visualizer.set_image(image)
+ self.set_image(image)
if filling:
- visualizer.draw_bboxes(
+ self.draw_bboxes(
bboxes,
face_colors=colors,
edge_colors=colors,
line_widths=line_width,
alpha=alpha)
else:
- visualizer.draw_bboxes(
+ self.draw_bboxes(
bboxes,
edge_colors=colors,
line_widths=line_width,
alpha=alpha)
- return visualizer.get_image()
+ return self.get_image()
def _draw_instances(self) -> np.ndarray:
raise NotImplementedError
+
+ def _cat_image(self, imgs: Sequence[np.ndarray], axis: int) -> np.ndarray:
+ """Concatenate images.
+
+ Args:
+ imgs (Sequence[np.ndarray]): The images to concatenate.
+ axis (int): The axis to concatenate.
+
+ Returns:
+ np.ndarray: The concatenated image.
+ """
+ cat_image = list()
+ for img in imgs:
+ if img is not None:
+ cat_image.append(img)
+ if len(cat_image):
+ return np.concatenate(cat_image, axis=axis)
+ else:
+ return None
diff --git a/mmocr/visualization/kie_visualizer.py b/mmocr/visualization/kie_visualizer.py
index 25c2620ce..b29cceb95 100644
--- a/mmocr/visualization/kie_visualizer.py
+++ b/mmocr/visualization/kie_visualizer.py
@@ -1,5 +1,4 @@
# Copyright (c) OpenMMLab. All rights reserved.
-import math
import warnings
from typing import Dict, List, Optional, Sequence, Union
@@ -15,31 +14,11 @@
from mmocr.registry import VISUALIZERS
from mmocr.structures import KIEDataSample
-
-PALETTE = [(220, 20, 60), (119, 11, 32), (0, 0, 142), (0, 0, 230),
- (106, 0, 228), (0, 60, 100), (0, 80, 100), (0, 0, 70), (0, 0, 192),
- (250, 170, 30), (100, 170, 30), (220, 220, 0), (175, 116, 175),
- (250, 0, 30), (165, 42, 42), (255, 77, 255), (0, 226, 252),
- (182, 182, 255), (0, 82, 0), (120, 166, 157), (110, 76, 0),
- (174, 57, 255), (199, 100, 0), (72, 0, 118), (255, 179, 240),
- (0, 125, 92), (209, 0, 151), (188, 208, 182), (0, 220, 176),
- (255, 99, 164), (92, 0, 73), (133, 129, 255), (78, 180, 255),
- (0, 228, 0), (174, 255, 243), (45, 89, 255), (134, 134, 103),
- (145, 148, 174), (255, 208, 186), (197, 226, 255), (171, 134, 1),
- (109, 63, 54), (207, 138, 255), (151, 0, 95), (9, 80, 61),
- (84, 105, 51), (74, 65, 105), (166, 196, 102), (208, 195, 210),
- (255, 109, 65), (0, 143, 149), (179, 0, 194), (209, 99, 106),
- (5, 121, 0), (227, 255, 205), (147, 186, 208), (153, 69, 1),
- (3, 95, 161), (163, 255, 0), (119, 0, 170), (0, 182, 199),
- (0, 165, 120), (183, 130, 88), (95, 32, 0), (130, 114, 135),
- (110, 129, 133), (166, 74, 118), (219, 142, 185), (79, 210, 114),
- (178, 90, 62), (65, 70, 15), (127, 167, 115), (59, 105, 106),
- (142, 108, 45), (196, 172, 0), (95, 54, 80), (128, 76, 255),
- (201, 57, 1), (246, 0, 122), (191, 162, 208)]
+from .base_visualizer import BaseLocalVisualizer
@VISUALIZERS.register_module()
-class KIELocalVisualizer(Visualizer):
+class KIELocalVisualizer(BaseLocalVisualizer):
"""The MMOCR Text Detection Local Visualizer.
Args:
@@ -65,102 +44,6 @@ def __init__(self,
super().__init__(name=name, **kwargs)
self.is_openset = is_openset
- @staticmethod
- def _draw_labels(visualizer: Visualizer,
- image: np.ndarray,
- labels: Union[np.ndarray, torch.Tensor],
- bboxes: Union[np.ndarray, torch.Tensor],
- colors: Union[str, Sequence[str]] = 'k',
- font_size: Union[int, float] = 10,
- auto_font_size: bool = False) -> np.ndarray:
- """Draw labels on image.
-
- Args:
- image (np.ndarray): The origin image to draw. The format
- should be RGB.
- labels (Union[np.ndarray, torch.Tensor]): The labels to draw.
- bboxes (Union[np.ndarray, torch.Tensor]): The bboxes to draw.
- colors (Union[str, Sequence[str]]): The colors of labels.
- ``colors`` can have the same length with labels or just single
- value. If ``colors`` is single value, all the labels will have
- the same colors. Refer to `matplotlib.colors` for full list of
- formats that are accepted. Defaults to 'k'.
- font_size (Union[int, float]): The font size of labels. Defaults
- to 10.
- auto_font_size (bool): Whether to automatically adjust font size.
- Defaults to False.
- """
- if colors is not None and isinstance(colors, Sequence):
- size = math.ceil(len(labels) / len(colors))
- colors = (colors * size)[:len(labels)]
- if auto_font_size:
- assert font_size is not None and isinstance(
- font_size, (int, float))
- font_size = (bboxes[:, 2:] - bboxes[:, :2]).min(-1) * font_size
- font_size = font_size.tolist()
- visualizer.set_image(image)
- visualizer.draw_texts(
- labels, (bboxes[:, :2] + bboxes[:, 2:]) / 2,
- vertical_alignments='center',
- horizontal_alignments='center',
- colors='k',
- font_sizes=font_size)
- return visualizer.get_image()
-
- @staticmethod
- def _draw_polygons(visualizer: Visualizer,
- image: np.ndarray,
- polygons: Sequence[np.ndarray],
- colors: Union[str, Sequence[str]] = 'g',
- filling: bool = False,
- line_width: Union[int, float] = 0.5,
- alpha: float = 0.5) -> np.ndarray:
- if colors is not None and isinstance(colors, Sequence):
- size = math.ceil(len(polygons) / len(colors))
- colors = (colors * size)[:len(polygons)]
- visualizer.set_image(image)
- if filling:
- visualizer.draw_polygons(
- polygons,
- face_colors=colors,
- edge_colors=colors,
- line_widths=line_width,
- alpha=alpha)
- else:
- visualizer.draw_polygons(
- polygons,
- edge_colors=colors,
- line_widths=line_width,
- alpha=alpha)
- return visualizer.get_image()
-
- @staticmethod
- def _draw_bboxes(visualizer: Visualizer,
- image: np.ndarray,
- bboxes: Union[np.ndarray, torch.Tensor],
- colors: Union[str, Sequence[str]] = 'g',
- filling: bool = False,
- line_width: Union[int, float] = 0.5,
- alpha: float = 0.5) -> np.ndarray:
- if colors is not None and isinstance(colors, Sequence):
- size = math.ceil(len(bboxes) / len(colors))
- colors = (colors * size)[:len(bboxes)]
- visualizer.set_image(image)
- if filling:
- visualizer.draw_bboxes(
- bboxes,
- face_colors=colors,
- edge_colors=colors,
- line_widths=line_width,
- alpha=alpha)
- else:
- visualizer.draw_bboxes(
- bboxes,
- edge_colors=colors,
- line_widths=line_width,
- alpha=alpha)
- return visualizer.get_image()
-
def _draw_edge_label(self,
image: np.ndarray,
edge_labels: Union[np.ndarray, torch.Tensor],
@@ -182,6 +65,9 @@ def _draw_edge_label(self,
arrow_colors (str, optional): The colors of arrows. Refer to
`matplotlib.colors` for full list of formats that are accepted.
Defaults to 'g'.
+
+ Returns:
+ np.ndarray: The image with edge labels drawn.
"""
pairs = np.where(edge_labels > 0)
key_bboxes = bboxes[pairs[0]]
@@ -253,49 +139,45 @@ def _draw_instances(
class_names (dict): The class names for bbox labels.
is_openset (bool): Whether the dataset is openset. Defaults to
False.
+ arrow_colors (str, optional): The colors of arrows. Refer to
+ `matplotlib.colors` for full list of formats that are accepted.
+ Defaults to 'g'.
+
+ Returns:
+ np.ndarray: The image with instances drawn.
"""
img_shape = image.shape[:2]
empty_shape = (img_shape[0], img_shape[1], 3)
- if polygons:
- polygons = [polygon.reshape(-1, 2) for polygon in polygons]
- if polygons:
- image = self._draw_polygons(
- self, image, polygons, filling=True, colors=PALETTE)
- else:
- image = self._draw_bboxes(
- self, image, bboxes, filling=True, colors=PALETTE)
-
text_image = np.full(empty_shape, 255, dtype=np.uint8)
- text_image = self._draw_labels(self, text_image, texts, bboxes)
- if polygons:
- text_image = self._draw_polygons(
- self, text_image, polygons, colors=PALETTE)
- else:
- text_image = self._draw_bboxes(
- self, text_image, bboxes, colors=PALETTE)
+ text_image = self.get_labels_image(text_image, texts, bboxes)
classes_image = np.full(empty_shape, 255, dtype=np.uint8)
bbox_classes = [class_names[int(i)]['name'] for i in bbox_labels]
- classes_image = self._draw_labels(self, classes_image, bbox_classes,
- bboxes)
+ classes_image = self.get_labels_image(classes_image, bbox_classes,
+ bboxes)
if polygons:
- classes_image = self._draw_polygons(
- self, classes_image, polygons, colors=PALETTE)
+ polygons = [polygon.reshape(-1, 2) for polygon in polygons]
+ image = self.get_polygons_image(
+ image, polygons, filling=True, colors=self.PALETTE)
+ text_image = self.get_polygons_image(
+ text_image, polygons, colors=self.PALETTE)
+ classes_image = self.get_polygons_image(
+ classes_image, polygons, colors=self.PALETTE)
else:
- classes_image = self._draw_bboxes(
- self, classes_image, bboxes, colors=PALETTE)
-
- edge_image = None
+ image = self.get_bboxes_image(
+ image, bboxes, filling=True, colors=self.PALETTE)
+ text_image = self.get_bboxes_image(
+ text_image, bboxes, colors=self.PALETTE)
+ classes_image = self.get_bboxes_image(
+ classes_image, bboxes, colors=self.PALETTE)
+ cat_image = [image, text_image, classes_image]
if is_openset:
edge_image = np.full(empty_shape, 255, dtype=np.uint8)
edge_image = self._draw_edge_label(edge_image, edge_labels, bboxes,
texts, arrow_colors)
- cat_image = []
- for i in [image, text_image, classes_image, edge_image]:
- if i is not None:
- cat_image.append(i)
- return np.concatenate(cat_image, axis=1)
+ cat_image.append(edge_image)
+ return self._cat_image(cat_image, axis=1)
def add_datasample(self,
name: str,
@@ -336,8 +218,7 @@ def add_datasample(self,
out_file (str): Path to output file. Defaults to None.
step (int): Global step value to record. Defaults to 0.
"""
- gt_img_data = None
- pred_img_data = None
+ cat_images = list()
if draw_gt:
gt_bboxes = data_sample.gt_instances.bboxes
@@ -350,6 +231,7 @@ def add_datasample(self,
gt_texts,
self.dataset_meta['category'],
self.is_openset, 'g')
+ cat_images.append(gt_img_data)
if draw_pred:
gt_bboxes = data_sample.gt_instances.bboxes
pred_labels = data_sample.pred_instances.labels
@@ -362,22 +244,19 @@ def add_datasample(self,
gt_texts,
self.dataset_meta['category'],
self.is_openset, 'r')
- if gt_img_data is not None and pred_img_data is not None:
- drawn_img = np.concatenate((gt_img_data, pred_img_data), axis=0)
- elif gt_img_data is not None:
- drawn_img = gt_img_data
- elif pred_img_data is not None:
- drawn_img = pred_img_data
- else:
- drawn_img = image
+ cat_images.append(pred_img_data)
+
+ cat_images = self._cat_image(cat_images, axis=0)
+ if cat_images is None:
+ cat_images = image
if show:
- self.show(drawn_img, win_name=name, wait_time=wait_time)
+ self.show(cat_images, win_name=name, wait_time=wait_time)
else:
- self.add_image(name, drawn_img, step)
+ self.add_image(name, cat_images, step)
if out_file is not None:
- mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ mmcv.imwrite(cat_images[..., ::-1], out_file)
def draw_arrows(self,
x_data: Union[np.ndarray, torch.Tensor],
diff --git a/mmocr/visualization/textdet_visualizer.py b/mmocr/visualization/textdet_visualizer.py
index 152096709..5f52074a4 100644
--- a/mmocr/visualization/textdet_visualizer.py
+++ b/mmocr/visualization/textdet_visualizer.py
@@ -1,16 +1,17 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Dict, List, Optional, Tuple, Union
+from typing import Dict, List, Optional, Sequence, Tuple, Union
import mmcv
import numpy as np
-from mmengine.visualization import Visualizer
+import torch
from mmocr.registry import VISUALIZERS
from mmocr.structures import TextDetDataSample
+from .base_visualizer import BaseLocalVisualizer
@VISUALIZERS.register_module()
-class TextDetLocalVisualizer(Visualizer):
+class TextDetLocalVisualizer(BaseLocalVisualizer):
"""The MMOCR Text Detection Local Visualizer.
Args:
@@ -62,6 +63,42 @@ def __init__(self,
self.line_width = line_width
self.alpha = alpha
+ def _draw_instances(
+ self,
+ image: np.ndarray,
+ bboxes: Union[np.ndarray, torch.Tensor],
+ polygons: Sequence[np.ndarray],
+ color: Union[str, Tuple, List[str], List[Tuple]] = 'g',
+ ) -> np.ndarray:
+ """Draw bboxes and polygons on image.
+
+ Args:
+ image (np.ndarray): The origin image to draw.
+ bboxes (Union[np.ndarray, torch.Tensor]): The bboxes to draw.
+ polygons (Sequence[np.ndarray]): The polygons to draw.
+ color (Union[str, tuple, list[str], list[tuple]]): The
+ colors of polygons and bboxes. ``colors`` can have the same
+ length with lines or just single value. If ``colors`` is
+ single value, all the lines will have the same colors. Refer
+ to `matplotlib.colors` for full list of formats that are
+ accepted. Defaults to 'g'.
+
+ Returns:
+ np.ndarray: The image with bboxes and polygons drawn.
+ """
+ if polygons is not None and self.with_poly:
+ polygons = [polygon.reshape(-1, 2) for polygon in polygons]
+ image = self.get_polygons_image(
+ image, polygons, filling=True, colors=color, alpha=self.alpha)
+ if bboxes is not None and self.with_bbox:
+ image = self.get_bboxes_image(
+ image,
+ bboxes,
+ colors=color,
+ line_width=self.line_width,
+ alpha=self.alpha)
+ return image
+
def add_datasample(self,
name: str,
image: np.ndarray,
@@ -101,79 +138,32 @@ def add_datasample(self,
and masks. Defaults to 0.3.
step (int): Global step value to record. Defaults to 0.
"""
- gt_img_data = None
- pred_img_data = None
-
- if (draw_gt and data_sample is not None
- and 'gt_instances' in data_sample):
- gt_instances = data_sample.gt_instances
-
- self.set_image(image)
-
- if self.with_poly and 'polygons' in gt_instances:
- gt_polygons = gt_instances.polygons
- gt_polygons = [
- gt_polygon.reshape(-1, 2) for gt_polygon in gt_polygons
- ]
- self.draw_polygons(
- gt_polygons,
- alpha=self.alpha,
- edge_colors=self.gt_color,
- line_widths=self.line_width)
-
- if self.with_bbox and 'bboxes' in gt_instances:
- gt_bboxes = gt_instances.bboxes
- self.draw_bboxes(
- gt_bboxes,
- alpha=self.alpha,
- edge_colors=self.gt_color,
- line_widths=self.line_width)
-
- gt_img_data = self.get_image()
-
- if draw_pred and data_sample is not None \
- and 'pred_instances' in data_sample:
- pred_instances = data_sample.pred_instances
- pred_instances = pred_instances[
- pred_instances.scores > pred_score_thr].cpu()
-
- self.set_image(image)
-
- if self.with_poly and 'polygons' in pred_instances:
- pred_polygons = pred_instances.polygons
- pred_polygons = [
- pred_polygon.reshape(-1, 2)
- for pred_polygon in pred_polygons
- ]
- self.draw_polygons(
- pred_polygons,
- alpha=self.alpha,
- edge_colors=self.pred_color,
- line_widths=self.line_width)
-
- if self.with_bbox and 'bboxes' in pred_instances:
- pred_bboxes = pred_instances.bboxes
- self.draw_bboxes(
- pred_bboxes,
- alpha=self.alpha,
- edge_colors=self.pred_color,
- line_widths=self.line_width)
-
- pred_img_data = self.get_image()
-
- if gt_img_data is not None and pred_img_data is not None:
- drawn_img = np.concatenate((gt_img_data, pred_img_data), axis=1)
- elif gt_img_data is not None:
- drawn_img = gt_img_data
- elif pred_img_data is not None:
- drawn_img = pred_img_data
- else:
- drawn_img = image
-
+ cat_images = []
+ if data_sample is not None:
+ if draw_gt and 'gt_instances' in data_sample:
+ gt_instances = data_sample.gt_instances
+ gt_polygons = gt_instances.get('polygons', None)
+ gt_bboxes = gt_instances.get('bboxes', None)
+ gt_img_data = self._draw_instances(image.copy(), gt_bboxes,
+ gt_polygons, self.gt_color)
+ cat_images.append(gt_img_data)
+ if draw_pred and 'pred_instances' in data_sample:
+ pred_instances = data_sample.pred_instances
+ pred_instances = pred_instances[
+ pred_instances.scores > pred_score_thr].cpu()
+ pred_polygons = pred_instances.get('polygons', None)
+ pred_bboxes = pred_instances.get('bboxes', None)
+ pred_img_data = self._draw_instances(image.copy(), pred_bboxes,
+ pred_polygons,
+ self.pred_color)
+ cat_images.append(pred_img_data)
+ cat_images = self._cat_image(cat_images, axis=1)
+ if cat_images is None:
+ cat_images = image
if show:
- self.show(drawn_img, win_name=name, wait_time=wait_time)
+ self.show(cat_images, win_name=name, wait_time=wait_time)
else:
- self.add_image(name, drawn_img, step)
+ self.add_image(name, cat_images, step)
if out_file is not None:
- mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ mmcv.imwrite(cat_images[..., ::-1], out_file)
diff --git a/mmocr/visualization/textrecog_visualizer.py b/mmocr/visualization/textrecog_visualizer.py
index 5db038305..623bf7642 100644
--- a/mmocr/visualization/textrecog_visualizer.py
+++ b/mmocr/visualization/textrecog_visualizer.py
@@ -4,14 +4,14 @@
import cv2
import mmcv
import numpy as np
-from mmengine.visualization import Visualizer
from mmocr.registry import VISUALIZERS
from mmocr.structures import TextRecogDataSample
+from .base_visualizer import BaseLocalVisualizer
@VISUALIZERS.register_module()
-class TextRecogLocalVisualizer(Visualizer):
+class TextRecogLocalVisualizer(BaseLocalVisualizer):
"""MMOCR Text Detection Local Visualizer.
Args:
@@ -46,6 +46,30 @@ def __init__(self,
self.gt_color = gt_color
self.pred_color = pred_color
+ def _draw_instances(self, image: np.ndarray, text: str) -> np.ndarray:
+ """Draw text on image.
+
+ Args:
+ image (np.ndarray): The image to draw.
+ text (str): The text to draw.
+
+ Returns:
+ np.ndarray: The image with text drawn.
+ """
+ height, width = image.shape[:2]
+ empty_img = np.full_like(image, 255)
+ self.set_image(empty_img)
+ font_size = 0.5 * width / (len(text) + 1)
+ self.draw_texts(
+ text,
+ np.array([width / 2, height / 2]),
+ colors=self.gt_color,
+ font_sizes=font_size,
+ vertical_alignments='center',
+ horizontal_alignments='center')
+ text_image = self.get_image()
+ return text_image
+
def add_datasample(self,
name: str,
image: np.ndarray,
@@ -85,59 +109,28 @@ def add_datasample(self,
pred_score_thr (float): Threshold of prediction score. It's not
used in this function. Defaults to None.
"""
- gt_img_data = None
- pred_img_data = None
height, width = image.shape[:2]
resize_height = 64
resize_width = int(1.0 * width / height * resize_height)
image = cv2.resize(image, (resize_width, resize_height))
+
if image.ndim == 2:
image = cv2.cvtColor(image, cv2.COLOR_GRAY2RGB)
+ cat_images = [image]
if draw_gt and data_sample is not None and 'gt_text' in data_sample:
gt_text = data_sample.gt_text.item
- empty_img = np.full_like(image, 255)
- self.set_image(empty_img)
- font_size = 0.5 * resize_width / (len(gt_text) + 1)
- self.draw_texts(
- gt_text,
- np.array([resize_width / 2, resize_height / 2]),
- colors=self.gt_color,
- font_sizes=font_size,
- vertical_alignments='center',
- horizontal_alignments='center')
- gt_text_image = self.get_image()
- gt_img_data = np.concatenate((image, gt_text_image), axis=0)
-
+ cat_images.append(self._draw_instances(image, gt_text))
if (draw_pred and data_sample is not None
and 'pred_text' in data_sample):
pred_text = data_sample.pred_text.item
- empty_img = np.full_like(image, 255)
- self.set_image(empty_img)
- font_size = 0.5 * resize_width / (len(pred_text) + 1)
- self.draw_texts(
- pred_text,
- np.array([resize_width / 2, resize_height / 2]),
- colors=self.pred_color,
- font_sizes=font_size,
- vertical_alignments='center',
- horizontal_alignments='center')
- pred_text_image = self.get_image()
- pred_img_data = np.concatenate((image, pred_text_image), axis=0)
-
- if gt_img_data is not None and pred_img_data is not None:
- drawn_img = np.concatenate((gt_img_data, pred_text_image), axis=0)
- elif gt_img_data is not None:
- drawn_img = gt_img_data
- elif pred_img_data is not None:
- drawn_img = pred_img_data
- else:
- drawn_img = image
+ cat_images.append(self._draw_instances(image, pred_text))
+ cat_images = self._cat_image(cat_images, axis=0)
if show:
- self.show(drawn_img, win_name=name, wait_time=wait_time)
+ self.show(cat_images, win_name=name, wait_time=wait_time)
else:
- self.add_image(name, drawn_img, step)
+ self.add_image(name, cat_images, step)
if out_file is not None:
- mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ mmcv.imwrite(cat_images[..., ::-1], out_file)
diff --git a/mmocr/visualization/textspotting_visualizer.py b/mmocr/visualization/textspotting_visualizer.py
index 1571d88d3..19a5e4ad3 100644
--- a/mmocr/visualization/textspotting_visualizer.py
+++ b/mmocr/visualization/textspotting_visualizer.py
@@ -37,27 +37,26 @@ def _draw_instances(
should be the same as the number of bboxes.
class_names (dict): The class names for bbox labels.
is_openset (bool): Whether the dataset is openset. Default: False.
+
+ Returns:
+ np.ndarray: The image with instances drawn.
"""
img_shape = image.shape[:2]
empty_shape = (img_shape[0], img_shape[1], 3)
-
- if polygons:
- polygons = [polygon.reshape(-1, 2) for polygon in polygons]
- if polygons:
- image = self._draw_polygons(
- self, image, polygons, filling=True, colors=self.PALETTE)
- else:
- image = self._draw_bboxes(
- self, image, bboxes, filling=True, colors=self.PALETTE)
-
text_image = np.full(empty_shape, 255, dtype=np.uint8)
- text_image = self._draw_labels(self, text_image, texts, bboxes)
+ text_image = self.get_labels_image(
+ text_image, labels=texts, bboxes=bboxes)
if polygons:
- text_image = self._draw_polygons(
- self, text_image, polygons, colors=self.PALETTE)
+ polygons = [polygon.reshape(-1, 2) for polygon in polygons]
+ image = self.get_polygons_image(
+ image, polygons, filling=True, colors=self.PALETTE)
+ text_image = self.get_polygons_image(
+ text_image, polygons, colors=self.PALETTE)
else:
- text_image = self._draw_bboxes(
- self, text_image, bboxes, colors=self.PALETTE)
+ image = self.get_bboxes_image(
+ image, bboxes, filling=True, colors=self.PALETTE)
+ text_image = self.get_bboxes_image(
+ text_image, bboxes, colors=self.PALETTE)
return np.concatenate([image, text_image], axis=1)
def add_datasample(self,
@@ -68,43 +67,69 @@ def add_datasample(self,
draw_pred: bool = True,
show: bool = False,
wait_time: int = 0,
- pred_score_thr: float = None,
+ pred_score_thr: float = 0.5,
out_file: Optional[str] = None,
step: int = 0) -> None:
- gt_img_data = None
- pred_img_data = None
+ """Draw datasample and save to all backends.
+
+ - If GT and prediction are plotted at the same time, they are
+ displayed in a stitched image where the left image is the
+ ground truth and the right image is the prediction.
+ - If ``show`` is True, all storage backends are ignored, and
+ the images will be displayed in a local window.
+ - If ``out_file`` is specified, the drawn image will be
+ saved to ``out_file``. This is usually used when the display
+ is not available.
+
+ Args:
+ name (str): The image identifier.
+ image (np.ndarray): The image to draw.
+ data_sample (:obj:`TextSpottingDataSample`, optional):
+ TextDetDataSample which contains gt and prediction. Defaults
+ to None.
+ draw_gt (bool): Whether to draw GT TextDetDataSample.
+ Defaults to True.
+ draw_pred (bool): Whether to draw Predicted TextDetDataSample.
+ Defaults to True.
+ show (bool): Whether to display the drawn image. Default to False.
+ wait_time (float): The interval of show (s). Defaults to 0.
+ out_file (str): Path to output file. Defaults to None.
+ pred_score_thr (float): The threshold to visualize the bboxes
+ and masks. Defaults to 0.3.
+ step (int): Global step value to record. Defaults to 0.
+ """
+ cat_images = []
if draw_gt:
- gt_bboxes = data_sample.gt_instances.bboxes
+ gt_bboxes = data_sample.gt_instances.get('bboxes', None)
gt_texts = data_sample.gt_instances.texts
- gt_polygons = data_sample.gt_instances.polygons
+ gt_polygons = data_sample.gt_instances.get('polygons', None)
gt_img_data = self._draw_instances(image, gt_bboxes, gt_polygons,
gt_texts)
+ cat_images.append(gt_img_data)
+
if draw_pred:
pred_instances = data_sample.pred_instances
pred_instances = pred_instances[
pred_instances.scores > pred_score_thr].cpu().numpy()
pred_bboxes = pred_instances.get('bboxes', None)
pred_texts = pred_instances.texts
- pred_polygons = pred_instances.polygons
+ pred_polygons = pred_instances.get('polygons', None)
if pred_bboxes is None:
pred_bboxes = [poly2bbox(poly) for poly in pred_polygons]
pred_bboxes = np.array(pred_bboxes)
pred_img_data = self._draw_instances(image, pred_bboxes,
pred_polygons, pred_texts)
- if gt_img_data is not None and pred_img_data is not None:
- drawn_img = np.concatenate((gt_img_data, pred_img_data), axis=0)
- elif gt_img_data is not None:
- drawn_img = gt_img_data
- elif pred_img_data is not None:
- drawn_img = pred_img_data
- else:
- drawn_img = image
+ cat_images.append(pred_img_data)
+
+ cat_images = self._cat_image(cat_images, axis=0)
+ if cat_images is None:
+ cat_images = image
if show:
- self.show(drawn_img, win_name=name, wait_time=wait_time)
+ self.show(cat_images, win_name=name, wait_time=wait_time)
else:
- self.add_image(name, drawn_img, step)
+ self.add_image(name, cat_images, step)
if out_file is not None:
- mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ mmcv.imwrite(cat_images[..., ::-1], out_file)
diff --git a/mmocr/visualization/visualize.py b/mmocr/visualization/visualize.py
deleted file mode 100644
index a8af6f34f..000000000
--- a/mmocr/visualization/visualize.py
+++ /dev/null
@@ -1,890 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import math
-import os
-import shutil
-import urllib
-import warnings
-
-import cv2
-import mmcv
-import mmengine
-import numpy as np
-import torch
-from matplotlib import pyplot as plt
-from PIL import Image, ImageDraw, ImageFont
-
-import mmocr.utils as utils
-
-
-# TODO remove after KieVisualizer and TextSpotterVisualizer
-def overlay_mask_img(img, mask):
- """Draw mask boundaries on image for visualization.
-
- Args:
- img (ndarray): The input image.
- mask (ndarray): The instance mask.
-
- Returns:
- img (ndarray): The output image with instance boundaries on it.
- """
- assert isinstance(img, np.ndarray)
- assert isinstance(mask, np.ndarray)
-
- contours, _ = cv2.findContours(
- mask.astype(np.uint8), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
-
- cv2.drawContours(img, contours, -1, (0, 255, 0), 1)
-
- return img
-
-
-def show_feature(features, names, to_uint8, out_file=None):
- """Visualize a list of feature maps.
-
- Args:
- features (list(ndarray)): The feature map list.
- names (list(str)): The visualized title list.
- to_uint8 (list(1|0)): The list indicating whether to convent
- feature maps to uint8.
- out_file (str): The output file name. If set to None,
- the output image will be shown without saving.
- """
- assert utils.is_type_list(features, np.ndarray)
- assert utils.is_type_list(names, str)
- assert utils.is_type_list(to_uint8, int)
- assert utils.is_none_or_type(out_file, str)
- assert utils.equal_len(features, names, to_uint8)
-
- num = len(features)
- row = col = math.ceil(math.sqrt(num))
-
- for i, (f, n) in enumerate(zip(features, names)):
- plt.subplot(row, col, i + 1)
- plt.title(n)
- if to_uint8[i]:
- f = f.astype(np.uint8)
- plt.imshow(f)
- if out_file is None:
- plt.show()
- else:
- plt.savefig(out_file)
-
-
-def show_img_boundary(img, boundary):
- """Show image and instance boundaires.
-
- Args:
- img (ndarray): The input image.
- boundary (list[float or int]): The input boundary.
- """
- assert isinstance(img, np.ndarray)
- assert utils.is_type_list(boundary, (int, float))
-
- cv2.polylines(
- img, [np.array(boundary).astype(np.int32).reshape(-1, 1, 2)],
- True,
- color=(0, 255, 0),
- thickness=1)
- plt.imshow(img)
- plt.show()
-
-
-def show_pred_gt(preds,
- gts,
- show=False,
- win_name='',
- wait_time=0,
- out_file=None):
- """Show detection and ground truth for one image.
-
- Args:
- preds (list[list[float]]): The detection boundary list.
- gts (list[list[float]]): The ground truth boundary list.
- show (bool): Whether to show the image.
- win_name (str): The window name.
- wait_time (int): The value of waitKey param.
- out_file (str): The filename of the output.
- """
- assert utils.is_2dlist(preds)
- assert utils.is_2dlist(gts)
- assert isinstance(show, bool)
- assert isinstance(win_name, str)
- assert isinstance(wait_time, int)
- assert utils.is_none_or_type(out_file, str)
-
- p_xy = [p for boundary in preds for p in boundary]
- gt_xy = [g for gt in gts for g in gt]
-
- max_xy = np.max(np.array(p_xy + gt_xy).reshape(-1, 2), axis=0)
-
- width = int(max_xy[0]) + 100
- height = int(max_xy[1]) + 100
-
- img = np.ones((height, width, 3), np.int8) * 255
- pred_color = mmcv.color_val('red')
- gt_color = mmcv.color_val('blue')
- thickness = 1
-
- for boundary in preds:
- cv2.polylines(
- img, [np.array(boundary).astype(np.int32).reshape(-1, 1, 2)],
- True,
- color=pred_color,
- thickness=thickness)
- for gt in gts:
- cv2.polylines(
- img, [np.array(gt).astype(np.int32).reshape(-1, 1, 2)],
- True,
- color=gt_color,
- thickness=thickness)
- if show:
- mmcv.imshow(img, win_name, wait_time)
- if out_file is not None:
- mmcv.imwrite(img, out_file)
-
- return img
-
-
-def imshow_pred_boundary(img,
- boundaries_with_scores,
- labels,
- score_thr=0,
- boundary_color='blue',
- text_color='blue',
- thickness=1,
- font_scale=0.5,
- show=True,
- win_name='',
- wait_time=0,
- out_file=None,
- show_score=False):
- """Draw boundaries and class labels (with scores) on an image.
-
- Args:
- img (str or ndarray): The image to be displayed.
- boundaries_with_scores (list[list[float]]): Boundaries with scores.
- labels (list[int]): Labels of boundaries.
- score_thr (float): Minimum score of boundaries to be shown.
- boundary_color (str or tuple or :obj:`Color`): Color of boundaries.
- text_color (str or tuple or :obj:`Color`): Color of texts.
- thickness (int): Thickness of lines.
- font_scale (float): Font scales of texts.
- show (bool): Whether to show the image.
- win_name (str): The window name.
- wait_time (int): Value of waitKey param.
- out_file (str or None): The filename of the output.
- show_score (bool): Whether to show text instance score.
- """
- assert isinstance(img, (str, np.ndarray))
- assert utils.is_2dlist(boundaries_with_scores)
- assert utils.is_type_list(labels, int)
- assert utils.equal_len(boundaries_with_scores, labels)
- if len(boundaries_with_scores) == 0:
- warnings.warn('0 text found in ' + out_file)
- return None
-
- utils.valid_boundary(boundaries_with_scores[0])
- img = mmcv.imread(img)
-
- scores = np.array([b[-1] for b in boundaries_with_scores])
- inds = scores > score_thr
- boundaries = [boundaries_with_scores[i][:-1] for i in np.where(inds)[0]]
- scores = [scores[i] for i in np.where(inds)[0]]
- labels = [labels[i] for i in np.where(inds)[0]]
-
- boundary_color = mmcv.color_val(boundary_color)
- text_color = mmcv.color_val(text_color)
- font_scale = 0.5
-
- for boundary, score in zip(boundaries, scores):
- boundary_int = np.array(boundary).astype(np.int32)
-
- cv2.polylines(
- img, [boundary_int.reshape(-1, 1, 2)],
- True,
- color=boundary_color,
- thickness=thickness)
-
- if show_score:
- label_text = f'{score:.02f}'
- cv2.putText(img, label_text,
- (boundary_int[0], boundary_int[1] - 2),
- cv2.FONT_HERSHEY_COMPLEX, font_scale, text_color)
- if show:
- mmcv.imshow(img, win_name, wait_time)
- if out_file is not None:
- mmcv.imwrite(img, out_file)
-
- return img
-
-
-def imshow_text_char_boundary(img,
- text_quads,
- boundaries,
- char_quads,
- chars,
- show=False,
- thickness=1,
- font_scale=0.5,
- win_name='',
- wait_time=-1,
- out_file=None):
- """Draw text boxes and char boxes on img.
-
- Args:
- img (str or ndarray): The img to be displayed.
- text_quads (list[list[int|float]]): The text boxes.
- boundaries (list[list[int|float]]): The boundary list.
- char_quads (list[list[list[int|float]]]): A 2d list of char boxes.
- char_quads[i] is for the ith text, and char_quads[i][j] is the jth
- char of the ith text.
- chars (list[list[char]]). The string for each text box.
- thickness (int): Thickness of lines.
- font_scale (float): Font scales of texts.
- show (bool): Whether to show the image.
- win_name (str): The window name.
- wait_time (int): Value of waitKey param.
- out_file (str or None): The filename of the output.
- """
- assert isinstance(img, (np.ndarray, str))
- assert utils.is_2dlist(text_quads)
- assert utils.is_2dlist(boundaries)
- assert utils.is_3dlist(char_quads)
- assert utils.is_2dlist(chars)
- assert utils.equal_len(text_quads, char_quads, boundaries)
-
- img = mmcv.imread(img)
- char_color = [mmcv.color_val('blue'), mmcv.color_val('green')]
- text_color = mmcv.color_val('red')
- text_inx = 0
- for text_box, boundary, char_box, txt in zip(text_quads, boundaries,
- char_quads, chars):
- text_box = np.array(text_box)
- boundary = np.array(boundary)
-
- text_box = text_box.reshape(-1, 2).astype(np.int32)
- cv2.polylines(
- img, [text_box.reshape(-1, 1, 2)],
- True,
- color=text_color,
- thickness=thickness)
- if boundary.shape[0] > 0:
- cv2.polylines(
- img, [boundary.reshape(-1, 1, 2)],
- True,
- color=text_color,
- thickness=thickness)
-
- for b in char_box:
- b = np.array(b)
- c = char_color[text_inx % 2]
- b = b.astype(np.int32)
- cv2.polylines(
- img, [b.reshape(-1, 1, 2)], True, color=c, thickness=thickness)
-
- label_text = ''.join(txt)
- cv2.putText(img, label_text, (text_box[0, 0], text_box[0, 1] - 2),
- cv2.FONT_HERSHEY_COMPLEX, font_scale, text_color)
- text_inx = text_inx + 1
-
- if show:
- mmcv.imshow(img, win_name, wait_time)
- if out_file is not None:
- mmcv.imwrite(img, out_file)
-
- return img
-
-
-def tile_image(images):
- """Combined multiple images to one vertically.
-
- Args:
- images (list[np.ndarray]): Images to be combined.
- """
- assert isinstance(images, list)
- assert len(images) > 0
-
- for i, _ in enumerate(images):
- if len(images[i].shape) == 2:
- images[i] = cv2.cvtColor(images[i], cv2.COLOR_GRAY2BGR)
-
- widths = [img.shape[1] for img in images]
- heights = [img.shape[0] for img in images]
- h, w = sum(heights), max(widths)
- vis_img = np.zeros((h, w, 3), dtype=np.uint8)
-
- offset_y = 0
- for image in images:
- img_h, img_w = image.shape[:2]
- vis_img[offset_y:(offset_y + img_h), 0:img_w, :] = image
- offset_y += img_h
-
- return vis_img
-
-
-def imshow_text_label(img,
- pred_label,
- gt_label,
- show=False,
- win_name='',
- wait_time=-1,
- out_file=None):
- """Draw predicted texts and ground truth texts on images.
-
- Args:
- img (str or np.ndarray): Image filename or loaded image.
- pred_label (str): Predicted texts.
- gt_label (str): Ground truth texts.
- show (bool): Whether to show the image.
- win_name (str): The window name.
- wait_time (int): Value of waitKey param.
- out_file (str): The filename of the output.
- """
- assert isinstance(img, (np.ndarray, str))
- assert isinstance(pred_label, str)
- assert isinstance(gt_label, str)
- assert isinstance(show, bool)
- assert isinstance(win_name, str)
- assert isinstance(wait_time, int)
-
- img = mmcv.imread(img)
-
- src_h, src_w = img.shape[:2]
- resize_height = 64
- resize_width = int(1.0 * src_w / src_h * resize_height)
- img = cv2.resize(img, (resize_width, resize_height))
- h, w = img.shape[:2]
-
- if is_contain_chinese(pred_label):
- pred_img = draw_texts_by_pil(img, [pred_label], None)
- else:
- pred_img = np.ones((h, w, 3), dtype=np.uint8) * 255
- cv2.putText(pred_img, pred_label, (5, 40), cv2.FONT_HERSHEY_SIMPLEX,
- 0.9, (0, 0, 255), 2)
- images = [pred_img, img]
-
- if gt_label != '':
- if is_contain_chinese(gt_label):
- gt_img = draw_texts_by_pil(img, [gt_label], None)
- else:
- gt_img = np.ones((h, w, 3), dtype=np.uint8) * 255
- cv2.putText(gt_img, gt_label, (5, 40), cv2.FONT_HERSHEY_SIMPLEX,
- 0.9, (255, 0, 0), 2)
- images.append(gt_img)
-
- img = tile_image(images)
-
- if show:
- mmcv.imshow(img, win_name, wait_time)
- if out_file is not None:
- mmcv.imwrite(img, out_file)
-
- return img
-
-
-def imshow_node(img,
- result,
- boxes,
- idx_to_cls={},
- show=False,
- win_name='',
- wait_time=-1,
- out_file=None):
-
- img = mmcv.imread(img)
- h, w = img.shape[:2]
-
- max_value, max_idx = torch.max(result['nodes'].detach().cpu(), -1)
- node_pred_label = max_idx.numpy().tolist()
- node_pred_score = max_value.numpy().tolist()
-
- texts, text_boxes = [], []
- for i, box in enumerate(boxes):
- new_box = [[box[0], box[1]], [box[2], box[1]], [box[2], box[3]],
- [box[0], box[3]]]
- Pts = np.array([new_box], np.int32)
- cv2.polylines(
- img, [Pts.reshape((-1, 1, 2))],
- True,
- color=(255, 255, 0),
- thickness=1)
- x_min = int(min(point[0] for point in new_box))
- y_min = int(min(point[1] for point in new_box))
-
- # text
- pred_label = str(node_pred_label[i])
- if pred_label in idx_to_cls:
- pred_label = idx_to_cls[pred_label]
- pred_score = f'{node_pred_score[i]:.2f}'
- text = pred_label + '(' + pred_score + ')'
- texts.append(text)
-
- # text box
- font_size = int(
- min(
- abs(new_box[3][1] - new_box[0][1]),
- abs(new_box[1][0] - new_box[0][0])))
- char_num = len(text)
- text_box = [
- x_min * 2, y_min, x_min * 2 + font_size * char_num, y_min,
- x_min * 2 + font_size * char_num, y_min + font_size, x_min * 2,
- y_min + font_size
- ]
- text_boxes.append(text_box)
-
- pred_img = np.ones((h, w * 2, 3), dtype=np.uint8) * 255
- pred_img = draw_texts_by_pil(
- pred_img, texts, text_boxes, draw_box=False, on_ori_img=True)
-
- vis_img = np.ones((h, w * 3, 3), dtype=np.uint8) * 255
- vis_img[:, :w] = img
- vis_img[:, w:] = pred_img
-
- if show:
- mmcv.imshow(vis_img, win_name, wait_time)
- if out_file is not None:
- mmcv.imwrite(vis_img, out_file)
-
- return vis_img
-
-
-def gen_color():
- """Generate BGR color schemes."""
- color_list = [(101, 67, 254), (154, 157, 252), (173, 205, 249),
- (123, 151, 138), (187, 200, 178), (148, 137, 69),
- (169, 200, 200), (155, 175, 131), (154, 194, 182),
- (178, 190, 137), (140, 211, 222), (83, 156, 222)]
- return color_list
-
-
-def draw_polygons(img, polys):
- """Draw polygons on image.
-
- Args:
- img (np.ndarray): The original image.
- polys (list[list[float]]): Detected polygons.
- Return:
- out_img (np.ndarray): Visualized image.
- """
- dst_img = img.copy()
- color_list = gen_color()
- out_img = dst_img
- for idx, poly in enumerate(polys):
- poly = np.array(poly).reshape((-1, 1, 2)).astype(np.int32)
- cv2.drawContours(
- img,
- np.array([poly]),
- -1,
- color_list[idx % len(color_list)],
- thickness=cv2.FILLED)
- out_img = cv2.addWeighted(dst_img, 0.5, img, 0.5, 0)
- return out_img
-
-
-def get_optimal_font_scale(text, width):
- """Get optimal font scale for cv2.putText.
-
- Args:
- text (str): Text in one box.
- width (int): The box width.
- """
- for scale in reversed(range(0, 60, 1)):
- textSize = cv2.getTextSize(
- text,
- fontFace=cv2.FONT_HERSHEY_SIMPLEX,
- fontScale=scale / 10,
- thickness=1)
- new_width = textSize[0][0]
- if new_width <= width:
- return scale / 10
- return 1
-
-
-def draw_texts(img, texts, boxes=None, draw_box=True, on_ori_img=False):
- """Draw boxes and texts on empty img.
-
- Args:
- img (np.ndarray): The original image.
- texts (list[str]): Recognized texts.
- boxes (list[list[float]]): Detected bounding boxes.
- draw_box (bool): Whether draw box or not. If False, draw text only.
- on_ori_img (bool): If True, draw box and text on input image,
- else, on a new empty image.
- Return:
- out_img (np.ndarray): Visualized image.
- """
- color_list = gen_color()
- h, w = img.shape[:2]
- if boxes is None:
- boxes = [[0, 0, w, 0, w, h, 0, h]]
- assert len(texts) == len(boxes)
-
- if on_ori_img:
- out_img = img
- else:
- out_img = np.ones((h, w, 3), dtype=np.uint8) * 255
- for idx, (box, text) in enumerate(zip(boxes, texts)):
- if draw_box:
- new_box = [[x, y] for x, y in zip(box[0::2], box[1::2])]
- Pts = np.array([new_box], np.int32)
- cv2.polylines(
- out_img, [Pts.reshape((-1, 1, 2))],
- True,
- color=color_list[idx % len(color_list)],
- thickness=1)
- min_x = int(min(box[0::2]))
- max_y = int(
- np.mean(np.array(box[1::2])) + 0.2 *
- (max(box[1::2]) - min(box[1::2])))
- font_scale = get_optimal_font_scale(
- text, int(max(box[0::2]) - min(box[0::2])))
- cv2.putText(out_img, text, (min_x, max_y), cv2.FONT_HERSHEY_SIMPLEX,
- font_scale, (0, 0, 0), 1)
-
- return out_img
-
-
-def draw_texts_by_pil(img,
- texts,
- boxes=None,
- draw_box=True,
- on_ori_img=False,
- font_size=None,
- fill_color=None,
- draw_pos=None,
- return_text_size=False):
- """Draw boxes and texts on empty image, especially for Chinese.
-
- Args:
- img (np.ndarray): The original image.
- texts (list[str]): Recognized texts.
- boxes (list[list[float]]): Detected bounding boxes.
- draw_box (bool): Whether draw box or not. If False, draw text only.
- on_ori_img (bool): If True, draw box and text on input image,
- else on a new empty image.
- font_size (int, optional): Size to create a font object for a font.
- fill_color (tuple(int), optional): Fill color for text.
- draw_pos (list[tuple(int)], optional): Start point to draw each text.
- return_text_size (bool): If True, return the list of text size.
-
- Returns:
- (np.ndarray, list[tuple]) or np.ndarray: Return a tuple
- ``(out_img, text_sizes)``, where ``out_img`` is the output image
- with texts drawn on it and ``text_sizes`` are the size of drawing
- texts. If ``return_text_size`` is False, only the output image will be
- returned.
- """
-
- color_list = gen_color()
- h, w = img.shape[:2]
- if boxes is None:
- boxes = [[0, 0, w, 0, w, h, 0, h]]
- if draw_pos is None:
- draw_pos = [None for _ in texts]
- assert len(boxes) == len(texts) == len(draw_pos)
-
- if fill_color is None:
- fill_color = (0, 0, 0)
-
- if on_ori_img:
- out_img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
- else:
- out_img = Image.new('RGB', (w, h), color=(255, 255, 255))
- out_draw = ImageDraw.Draw(out_img)
-
- text_sizes = []
- for idx, (box, text, ori_point) in enumerate(zip(boxes, texts, draw_pos)):
- if len(text) == 0:
- continue
- min_x, max_x = min(box[0::2]), max(box[0::2])
- min_y, max_y = min(box[1::2]), max(box[1::2])
- color = tuple(list(color_list[idx % len(color_list)])[::-1])
- if draw_box:
- out_draw.line(box, fill=color, width=1)
- dirname, _ = os.path.split(os.path.abspath(__file__))
- font_path = os.path.join(dirname, 'font.TTF')
- if not os.path.exists(font_path):
- url = ('https://download.openmmlab.com/mmocr/data/font.TTF')
- print(f'Downloading {url} ...')
- local_filename, _ = urllib.request.urlretrieve(url)
- shutil.move(local_filename, font_path)
- tmp_font_size = font_size
- if tmp_font_size is None:
- box_width = max(max_x - min_x, max_y - min_y)
- tmp_font_size = int(0.9 * box_width / len(text))
- fnt = ImageFont.truetype(font_path, tmp_font_size)
- if ori_point is None:
- ori_point = (min_x + 1, min_y + 1)
- out_draw.text(ori_point, text, font=fnt, fill=fill_color)
- text_sizes.append(fnt.getsize(text))
-
- del out_draw
-
- out_img = cv2.cvtColor(np.asarray(out_img), cv2.COLOR_RGB2BGR)
-
- if return_text_size:
- return out_img, text_sizes
-
- return out_img
-
-
-def is_contain_chinese(check_str):
- """Check whether string contains Chinese or not.
-
- Args:
- check_str (str): String to be checked.
-
- Return True if contains Chinese, else False.
- """
- for ch in check_str:
- if '\u4e00' <= ch <= '\u9fff':
- return True
- return False
-
-
-def det_recog_show_result(img, end2end_res, out_file=None):
- """Draw `result`(boxes and texts) on `img`.
-
- Args:
- img (str or np.ndarray): The image to be displayed.
- end2end_res (dict): Text detect and recognize results.
- out_file (str): Image path where the visualized image should be saved.
- Return:
- out_img (np.ndarray): Visualized image.
- """
- img = mmcv.imread(img)
- boxes, texts = [], []
- for res in end2end_res['result']:
- boxes.append(res['box'])
- texts.append(res['text'])
- box_vis_img = draw_polygons(img, boxes)
-
- if is_contain_chinese(''.join(texts)):
- text_vis_img = draw_texts_by_pil(img, texts, boxes)
- else:
- text_vis_img = draw_texts(img, texts, boxes)
-
- h, w = img.shape[:2]
- out_img = np.ones((h, w * 2, 3), dtype=np.uint8)
- out_img[:, :w, :] = box_vis_img
- out_img[:, w:, :] = text_vis_img
-
- if out_file:
- mmcv.imwrite(out_img, out_file)
-
- return out_img
-
-
-def draw_edge_result(img, result, edge_thresh=0.5, keynode_thresh=0.5):
- """Draw text and their relationship on empty images.
-
- Args:
- img (np.ndarray): The original image.
- result (dict): The result of model forward_test, including:
- - img_metas (list[dict]): List of meta information dictionary.
- - nodes (Tensor): Node prediction with size:
- number_node * node_classes.
- - edges (Tensor): Edge prediction with size: number_edge * 2.
- edge_thresh (float): Score threshold for edge classification.
- keynode_thresh (float): Score threshold for node
- (``key``) classification.
-
- Returns:
- np.ndarray: The image with key, value and relation drawn on it.
- """
-
- h, w = img.shape[:2]
-
- vis_area_width = w // 3 * 2
- vis_area_height = h
- dist_key_to_value = vis_area_width // 2
- dist_pair_to_pair = 30
-
- bbox_x1 = dist_pair_to_pair
- bbox_y1 = 0
-
- new_w = vis_area_width
- new_h = vis_area_height
- pred_edge_img = np.ones((new_h, new_w, 3), dtype=np.uint8) * 255
-
- nodes = result['nodes'].detach().cpu()
- texts = result['img_metas'][0]['ori_texts']
- num_nodes = result['nodes'].size(0)
- edges = result['edges'].detach().cpu()[:, -1].view(num_nodes, num_nodes)
-
- # (i, j) will be a valid pair
- # either edge_score(node_i->node_j) > edge_thresh
- # or edge_score(node_j->node_i) > edge_thresh
- pairs = (torch.max(edges, edges.T) > edge_thresh).nonzero(as_tuple=True)
- pairs = (pairs[0].numpy().tolist(), pairs[1].numpy().tolist())
-
- # 1. "for n1, n2 in zip(*pairs) if n1 < n2":
- # Only (n1, n2) will be included if n1 < n2 but not (n2, n1), to
- # avoid duplication.
- # 2. "(n1, n2) if nodes[n1, 1] > nodes[n1, 2]":
- # nodes[n1, 1] is the score that this node is predicted as key,
- # nodes[n1, 2] is the score that this node is predicted as value.
- # If nodes[n1, 1] > nodes[n1, 2], n1 will be the index of key,
- # so that n2 will be the index of value.
- result_pairs = [(n1, n2) if nodes[n1, 1] > nodes[n1, 2] else (n2, n1)
- for n1, n2 in zip(*pairs) if n1 < n2]
-
- result_pairs.sort()
- result_pairs_score = [
- torch.max(edges[n1, n2], edges[n2, n1]) for n1, n2 in result_pairs
- ]
-
- key_current_idx = -1
- pos_current = (-1, -1)
- newline_flag = False
-
- key_font_size = 15
- value_font_size = 15
- key_font_color = (0, 0, 0)
- value_font_color = (0, 0, 255)
- arrow_color = (0, 0, 255)
- score_color = (0, 255, 0)
- for pair, pair_score in zip(result_pairs, result_pairs_score):
- key_idx = pair[0]
- if nodes[key_idx, 1] < keynode_thresh:
- continue
- if key_idx != key_current_idx:
- # move y-coords down for a new key
- bbox_y1 += 10
- # enlarge blank area to show key-value info
- if newline_flag:
- bbox_x1 += vis_area_width
- tmp_img = np.ones(
- (new_h, new_w + vis_area_width, 3), dtype=np.uint8) * 255
- tmp_img[:new_h, :new_w] = pred_edge_img
- pred_edge_img = tmp_img
- new_w += vis_area_width
- newline_flag = False
- bbox_y1 = 10
- key_text = texts[key_idx]
- key_pos = (bbox_x1, bbox_y1)
- value_idx = pair[1]
- value_text = texts[value_idx]
- value_pos = (bbox_x1 + dist_key_to_value, bbox_y1)
- if key_idx != key_current_idx:
- # draw text for a new key
- key_current_idx = key_idx
- pred_edge_img, text_sizes = draw_texts_by_pil(
- pred_edge_img, [key_text],
- draw_box=False,
- on_ori_img=True,
- font_size=key_font_size,
- fill_color=key_font_color,
- draw_pos=[key_pos],
- return_text_size=True)
- pos_right_bottom = (key_pos[0] + text_sizes[0][0],
- key_pos[1] + text_sizes[0][1])
- pos_current = (pos_right_bottom[0] + 5, bbox_y1 + 10)
- pred_edge_img = cv2.arrowedLine(
- pred_edge_img, (pos_right_bottom[0] + 5, bbox_y1 + 10),
- (bbox_x1 + dist_key_to_value - 5, bbox_y1 + 10), arrow_color,
- 1)
- score_pos_x = int(
- (pos_right_bottom[0] + bbox_x1 + dist_key_to_value) / 2.)
- score_pos_y = bbox_y1 + 10 - int(key_font_size * 0.3)
- else:
- # draw arrow from key to value
- if newline_flag:
- tmp_img = np.ones((new_h + dist_pair_to_pair, new_w, 3),
- dtype=np.uint8) * 255
- tmp_img[:new_h, :new_w] = pred_edge_img
- pred_edge_img = tmp_img
- new_h += dist_pair_to_pair
- pred_edge_img = cv2.arrowedLine(pred_edge_img, pos_current,
- (bbox_x1 + dist_key_to_value - 5,
- bbox_y1 + 10), arrow_color, 1)
- score_pos_x = int(
- (pos_current[0] + bbox_x1 + dist_key_to_value - 5) / 2.)
- score_pos_y = int((pos_current[1] + bbox_y1 + 10) / 2.)
- # draw edge score
- cv2.putText(pred_edge_img, f'{pair_score:.2f}',
- (score_pos_x, score_pos_y), cv2.FONT_HERSHEY_COMPLEX, 0.4,
- score_color)
- # draw text for value
- pred_edge_img = draw_texts_by_pil(
- pred_edge_img, [value_text],
- draw_box=False,
- on_ori_img=True,
- font_size=value_font_size,
- fill_color=value_font_color,
- draw_pos=[value_pos],
- return_text_size=False)
- bbox_y1 += dist_pair_to_pair
- if bbox_y1 + dist_pair_to_pair >= new_h:
- newline_flag = True
-
- return pred_edge_img
-
-
-def imshow_edge(img,
- result,
- boxes,
- show=False,
- win_name='',
- wait_time=-1,
- out_file=None):
- """Display the prediction results of the nodes and edges of the KIE model.
-
- Args:
- img (np.ndarray): The original image.
- result (dict): The result of model forward_test, including:
- - img_metas (list[dict]): List of meta information dictionary.
- - nodes (Tensor): Node prediction with size: \
- number_node * node_classes.
- - edges (Tensor): Edge prediction with size: number_edge * 2.
- boxes (list): The text boxes corresponding to the nodes.
- show (bool): Whether to show the image. Default: False.
- win_name (str): The window name. Default: ''
- wait_time (float): Value of waitKey param. Default: 0.
- out_file (str or None): The filename to write the image.
- Default: None.
-
- Returns:
- np.ndarray: The image with key, value and relation drawn on it.
- """
- img = mmcv.imread(img)
- h, w = img.shape[:2]
- color_list = gen_color()
-
- for i, box in enumerate(boxes):
- new_box = [[box[0], box[1]], [box[2], box[1]], [box[2], box[3]],
- [box[0], box[3]]]
- Pts = np.array([new_box], np.int32)
- cv2.polylines(
- img, [Pts.reshape((-1, 1, 2))],
- True,
- color=color_list[i % len(color_list)],
- thickness=1)
-
- pred_img_h = h
- pred_img_w = w
-
- pred_edge_img = draw_edge_result(img, result)
- pred_img_h = max(pred_img_h, pred_edge_img.shape[0])
- pred_img_w += pred_edge_img.shape[1]
-
- vis_img = np.zeros((pred_img_h, pred_img_w, 3), dtype=np.uint8)
- vis_img[:h, :w] = img
- vis_img[:, w:] = 255
-
- height_t, width_t = pred_edge_img.shape[:2]
- vis_img[:height_t, w:(w + width_t)] = pred_edge_img
-
- if show:
- mmcv.imshow(vis_img, win_name, wait_time)
- if out_file is not None:
- mmcv.imwrite(vis_img, out_file)
- res_dic = {
- 'boxes': boxes,
- 'nodes': result['nodes'].detach().cpu(),
- 'edges': result['edges'].detach().cpu(),
- 'metas': result['img_metas'][0]
- }
- mmengine.dump(res_dic, f'{out_file}_res.pkl')
-
- return vis_img
diff --git a/tests/test_visualization/test_base_visualizer.py b/tests/test_visualization/test_base_visualizer.py
new file mode 100644
index 000000000..57abc242f
--- /dev/null
+++ b/tests/test_visualization/test_base_visualizer.py
@@ -0,0 +1,55 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import numpy as np
+
+from mmocr.visualization import BaseLocalVisualizer
+
+
+class TestBaseLocalVisualizer(TestCase):
+
+ def test_get_labels_image(self):
+ labels = ['a', 'b', 'c']
+ image = np.zeros((40, 40, 3), dtype=np.uint8)
+ bboxes = np.array([[0, 0, 10, 10], [10, 10, 20, 20], [20, 20, 30, 30]])
+ labels_image = BaseLocalVisualizer().get_labels_image(
+ image,
+ labels,
+ bboxes=bboxes,
+ auto_font_size=True,
+ colors=['r', 'r', 'r', 'r'])
+ self.assertEqual(labels_image.shape, (40, 40, 3))
+
+ def test_get_polygons_image(self):
+ polygons = [np.array([0, 0, 10, 10, 20, 20, 30, 30]).reshape(-1, 2)]
+ image = np.zeros((40, 40, 3), dtype=np.uint8)
+ polygons_image = BaseLocalVisualizer().get_polygons_image(
+ image, polygons, colors=['r', 'r', 'r', 'r'])
+ self.assertEqual(polygons_image.shape, (40, 40, 3))
+
+ polygons_image = BaseLocalVisualizer().get_polygons_image(
+ image, polygons, colors=['r', 'r', 'r', 'r'], filling=True)
+ self.assertEqual(polygons_image.shape, (40, 40, 3))
+
+ def test_get_bboxes_image(self):
+ bboxes = np.array([[0, 0, 10, 10], [10, 10, 20, 20], [20, 20, 30, 30]])
+ image = np.zeros((40, 40, 3), dtype=np.uint8)
+ bboxes_image = BaseLocalVisualizer().get_bboxes_image(
+ image, bboxes, colors=['r', 'r', 'r', 'r'])
+ self.assertEqual(bboxes_image.shape, (40, 40, 3))
+
+ bboxes_image = BaseLocalVisualizer().get_bboxes_image(
+ image, bboxes, colors=['r', 'r', 'r', 'r'], filling=True)
+ self.assertEqual(bboxes_image.shape, (40, 40, 3))
+
+ def test_cat_images(self):
+ image1 = np.zeros((40, 40, 3), dtype=np.uint8)
+ image2 = np.zeros((40, 40, 3), dtype=np.uint8)
+ image = BaseLocalVisualizer()._cat_image([image1, image2], axis=1)
+ self.assertEqual(image.shape, (40, 80, 3))
+
+ image = BaseLocalVisualizer()._cat_image([], axis=0)
+ self.assertIsNone(image)
+
+ image = BaseLocalVisualizer()._cat_image([image1, None], axis=0)
+ self.assertEqual(image.shape, (40, 40, 3))
diff --git a/tests/test_visualization/test_kie_visualizer.py b/tests/test_visualization/test_kie_visualizer.py
index 5237d6b46..0cc650b3f 100644
--- a/tests/test_visualization/test_kie_visualizer.py
+++ b/tests/test_visualization/test_kie_visualizer.py
@@ -105,6 +105,21 @@ def test_add_datasample(self):
out_file=out_file)
self._assert_image_and_shape(out_file, (h, w * 4, c))
+ visualizer = KIELocalVisualizer(is_openset=False)
+ visualizer.dataset_meta = dict(category=[
+ dict(id=0, name='bg'),
+ dict(id=1, name='key'),
+ dict(id=2, name='value'),
+ dict(id=3, name='other')
+ ])
+ visualizer.add_datasample(
+ 'image',
+ image,
+ self.data_sample,
+ draw_pred=False,
+ out_file=out_file)
+ self._assert_image_and_shape(out_file, (h, w * 3, c))
+
def _assert_image_and_shape(self, out_file, out_shape):
self.assertTrue(osp.exists(out_file))
drawn_img = cv2.imread(out_file)
diff --git a/tests/test_visualization/test_textdet_visualizer.py b/tests/test_visualization/test_textdet_visualizer.py
index c6da49019..21a493ada 100644
--- a/tests/test_visualization/test_textdet_visualizer.py
+++ b/tests/test_visualization/test_textdet_visualizer.py
@@ -101,6 +101,10 @@ def _test_add_datasample(self, vis_cfg):
out_file=out_file)
self._assert_image_and_shape(out_file, (h, w, c))
+ det_local_visualizer.add_datasample(
+ 'image', image, None, out_file=out_file)
+ self._assert_image_and_shape(out_file, (h, w, c))
+
def _assert_image_and_shape(self, out_file, out_shape):
self.assertTrue(osp.exists(out_file))
drawn_img = cv2.imread(out_file)
diff --git a/tests/test_visualization/test_textrecog_visualizer.py b/tests/test_visualization/test_textrecog_visualizer.py
index 1154f770c..3171a02d9 100644
--- a/tests/test_visualization/test_textrecog_visualizer.py
+++ b/tests/test_visualization/test_textrecog_visualizer.py
@@ -46,7 +46,7 @@ def test_add_datasample(self):
draw_pred=False)
self._assert_image_and_shape(out_file, (h * 2, w, 3))
- # draw_gt = True + gt_sample + pred_sample
+ # draw_gt = True
recog_local_visualizer.add_datasample(
'image',
image,
@@ -56,7 +56,13 @@ def test_add_datasample(self):
draw_pred=True)
self._assert_image_and_shape(out_file, (h * 3, w, 3))
- # draw_gt = False + gt_sample + pred_sample
+ # draw_gt = False
+ recog_local_visualizer.add_datasample(
+ 'image', image, data_sample, draw_gt=False, out_file=out_file)
+ self._assert_image_and_shape(out_file, (h * 2, w, 3))
+
+ # gray image
+ image = np.random.randint(0, 256, size=(h, w)).astype('uint8')
recog_local_visualizer.add_datasample(
'image', image, data_sample, draw_gt=False, out_file=out_file)
self._assert_image_and_shape(out_file, (h * 2, w, 3))
diff --git a/tests/test_visualization/test_textspotting_visualizer.py b/tests/test_visualization/test_textspotting_visualizer.py
new file mode 100644
index 000000000..91086475a
--- /dev/null
+++ b/tests/test_visualization/test_textspotting_visualizer.py
@@ -0,0 +1,113 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import tempfile
+import unittest
+
+import cv2
+import numpy as np
+import torch
+from mmengine.structures import InstanceData
+
+from mmocr.structures import TextDetDataSample
+from mmocr.utils import bbox2poly
+from mmocr.visualization import TextSpottingLocalVisualizer
+
+
+class TestTextKIELocalVisualizer(unittest.TestCase):
+
+ def setUp(self):
+ h, w = 12, 10
+ self.image = np.random.randint(0, 256, size=(h, w, 3)).astype('uint8')
+ # gt_instances
+ data_sample = TextDetDataSample()
+ gt_instances_data = dict(
+ bboxes=self._rand_bboxes(5, h, w),
+ polygons=self._rand_polys(5, h, w),
+ labels=torch.zeros(5, ),
+ texts=['text1', 'text2', 'text3', 'text4', 'text5'])
+ gt_instances = InstanceData(**gt_instances_data)
+ data_sample.gt_instances = gt_instances
+
+ pred_instances_data = dict(
+ bboxes=self._rand_bboxes(5, h, w),
+ labels=torch.zeros(5, ),
+ scores=torch.rand((5, )),
+ texts=['text1', 'text2', 'text3', 'text4', 'text5'])
+ pred_instances = InstanceData(**pred_instances_data)
+ data_sample.pred_instances = pred_instances
+ data_sample = data_sample.numpy()
+ self.data_sample = data_sample
+
+ @staticmethod
+ def _rand_bboxes(num_boxes, h, w):
+ cx, cy, bw, bh = torch.rand(num_boxes, 4).T
+
+ tl_x = ((cx * w) - (w * bw / 2)).clamp(0, w).unsqueeze(0)
+ tl_y = ((cy * h) - (h * bh / 2)).clamp(0, h).unsqueeze(0)
+ br_x = ((cx * w) + (w * bw / 2)).clamp(0, w).unsqueeze(0)
+ br_y = ((cy * h) + (h * bh / 2)).clamp(0, h).unsqueeze(0)
+
+ bboxes = torch.cat([tl_x, tl_y, br_x, br_y], dim=0).T
+
+ return bboxes
+
+ def _rand_polys(self, num_bboxes, h, w):
+ bboxes = self._rand_bboxes(num_bboxes, h, w)
+ bboxes = bboxes.tolist()
+ polys = [bbox2poly(bbox) for bbox in bboxes]
+ return polys
+
+ def test_add_datasample(self):
+ image = self.image
+ h, w, c = image.shape
+
+ visualizer = TextSpottingLocalVisualizer()
+ visualizer.add_datasample('image', image, self.data_sample)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ # test out
+ out_file = osp.join(tmp_dir, 'out_file.jpg')
+ visualizer.add_datasample(
+ 'image',
+ image,
+ self.data_sample,
+ out_file=out_file,
+ draw_gt=False,
+ draw_pred=False)
+ self._assert_image_and_shape(out_file, (h, w, c))
+
+ visualizer.add_datasample(
+ 'image', image, self.data_sample, out_file=out_file)
+ self._assert_image_and_shape(out_file, (h * 2, w * 2, c))
+
+ visualizer.add_datasample(
+ 'image',
+ image,
+ self.data_sample,
+ draw_gt=False,
+ out_file=out_file)
+ self._assert_image_and_shape(out_file, (h, w * 2, c))
+
+ visualizer.add_datasample(
+ 'image',
+ image,
+ self.data_sample,
+ draw_pred=False,
+ out_file=out_file)
+ self._assert_image_and_shape(out_file, (h, w * 2, c))
+ bboxes = self.data_sample.pred_instances.pop('bboxes')
+ bboxes = bboxes.tolist()
+ polys = [bbox2poly(bbox) for bbox in bboxes]
+ self.data_sample.pred_instances.polygons = polys
+ visualizer.add_datasample(
+ 'image',
+ image,
+ self.data_sample,
+ draw_gt=False,
+ out_file=out_file)
+ self._assert_image_and_shape(out_file, (h, w * 2, c))
+
+ def _assert_image_and_shape(self, out_file, out_shape):
+ self.assertTrue(osp.exists(out_file))
+ drawn_img = cv2.imread(out_file)
+ self.assertTrue(drawn_img.shape == out_shape)
From 769d845b4ff1d691fc1e133b4e7421c142519311 Mon Sep 17 00:00:00 2001
From: Tong Gao
Date: Sun, 9 Oct 2022 16:11:15 +0800
Subject: [PATCH 30/32] [Fix] Skip invalud augmented polygons in ImgAugWrapper
(#1434)
* [Fix] Skip invalud augmented polygons in ImgAugWrapper
* fix precommit
---
docs/zh_cn/user_guides/inference.md | 42 +++++++++++++--------------
mmocr/datasets/transforms/wrappers.py | 3 +-
2 files changed, 23 insertions(+), 22 deletions(-)
diff --git a/docs/zh_cn/user_guides/inference.md b/docs/zh_cn/user_guides/inference.md
index 0b2ef6945..1dbc36558 100644
--- a/docs/zh_cn/user_guides/inference.md
+++ b/docs/zh_cn/user_guides/inference.md
@@ -145,36 +145,36 @@ mmocr 为了方便使用提供了预置的模型配置和对应的预训练权
**文本检测:**
-| 名称 | 引用 |
-| ------------- | :----------------------------------------------------------------------------: |
-| DB_r18 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#dbnet) |
-| DB_r50 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#dbnet) |
-| DBPP_r50 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#dbnetpp) |
+| 名称 | 引用 |
+| ------------- | :-------------------------------------------------------------------------------: |
+| DB_r18 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#dbnet) |
+| DB_r50 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#dbnet) |
+| DBPP_r50 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#dbnetpp) |
| DRRG | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#drrg) |
-| FCE_IC15 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#fcenet) |
-| FCE_CTW_DCNv2 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#fcenet) |
+| FCE_IC15 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#fcenet) |
+| FCE_CTW_DCNv2 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#fcenet) |
| MaskRCNN_CTW | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#mask-r-cnn) |
| MaskRCNN_IC15 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#mask-r-cnn) |
-| PANet_CTW | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#panet) |
-| PANet_IC15 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#panet) |
+| PANet_CTW | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#panet) |
+| PANet_IC15 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#panet) |
| PS_CTW | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#psenet) |
| PS_IC15 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#psenet) |
| TextSnake | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textdet_models.html#textsnake) |
**文本识别:**
-| 名称 | 引用 |
-| ------------- | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
-| ABINet | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#abinet) |
-| ABINet_Vision | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#abinet) |
-| CRNN | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#crnn) |
-| MASTER | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#master) |
-| NRTR_1/16-1/8 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#nrtr) |
-| NRTR_1/8-1/4 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#nrtr) |
-| RobustScanner | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#robustscanner) |
-| SAR | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#sar) |
-| SATRN | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#satrn) |
-| SATRN_sm | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#satrn) |
+| 名称 | 引用 |
+| ------------- | :------------------------------------------------------------------------------------: |
+| ABINet | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#abinet) |
+| ABINet_Vision | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#abinet) |
+| CRNN | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#crnn) |
+| MASTER | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#master) |
+| NRTR_1/16-1/8 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#nrtr) |
+| NRTR_1/8-1/4 | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#nrtr) |
+| RobustScanner | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#robustscanner) |
+| SAR | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#sar) |
+| SATRN | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#satrn) |
+| SATRN_sm | [链接](https://mmocr.readthedocs.io/zh_CN/dev-1.x/textrecog_models.html#satrn) |
**关键信息提取:**
diff --git a/mmocr/datasets/transforms/wrappers.py b/mmocr/datasets/transforms/wrappers.py
index e0f900167..c4820a160 100644
--- a/mmocr/datasets/transforms/wrappers.py
+++ b/mmocr/datasets/transforms/wrappers.py
@@ -151,7 +151,8 @@ def _augment_polygons(self, aug: imgaug.augmenters.meta.Augmenter,
new_polys = []
removed_poly_inds = []
for i, poly in enumerate(imgaug_polys.polygons):
- if poly.is_out_of_image(imgaug_polys.shape):
+ # Sometimes imgaug may produce some invalid polygons with no points
+ if not poly.is_valid or poly.is_out_of_image(imgaug_polys.shape):
removed_poly_inds.append(i)
continue
new_poly = []
From e7e46771ba4aeba4b77355661df389ac29a4cbef Mon Sep 17 00:00:00 2001
From: vansin
Date: Sun, 9 Oct 2022 17:47:51 +0800
Subject: [PATCH 31/32] [WIP] support get flops and parameters in dev-1.x
(#1414)
* [Feature] support get_flops
* [Fix] add the divisor
* [Doc] add the get_flops doc
* [Doc] update the get_flops doc
* [Doc] update get FLOPs doc
* [Fix] delete unnecessary args
* [Fix] delete unnecessary code in get_flops
* [Doc] update get flops doc
* [Fix] remove unnecessary code
* [Doc] add space between Chinese and English
* [Doc] add English doc of get flops
* Update docs/zh_cn/user_guides/useful_tools.md
Co-authored-by: Tong Gao
* Update docs/zh_cn/user_guides/useful_tools.md
Co-authored-by: Tong Gao
* Update docs/en/user_guides/useful_tools.md
Co-authored-by: Tong Gao
* Update docs/en/user_guides/useful_tools.md
Co-authored-by: Tong Gao
* Update docs/en/user_guides/useful_tools.md
Co-authored-by: Tong Gao
* Update docs/en/user_guides/useful_tools.md
Co-authored-by: Tong Gao
* [Docs] fix the lint
* fix
* fix docs
Co-authored-by: Tong Gao
---
docs/en/user_guides/useful_tools.md | 87 ++++++++++++++++++++++++--
docs/zh_cn/user_guides/useful_tools.md | 87 ++++++++++++++++++++++++--
tools/analysis_tools/get_flops.py | 56 +++++++++++++++++
3 files changed, 220 insertions(+), 10 deletions(-)
create mode 100644 tools/analysis_tools/get_flops.py
diff --git a/docs/en/user_guides/useful_tools.md b/docs/en/user_guides/useful_tools.md
index a8440ac80..fefcb120f 100644
--- a/docs/en/user_guides/useful_tools.md
+++ b/docs/en/user_guides/useful_tools.md
@@ -45,8 +45,85 @@ python tools/analysis_tools/offline_eval.py configs/textdet/psenet/psenet_r50_fp
In addition, based on this tool, users can also convert predictions obtained from other libraries into MMOCR-supported formats, then use MMOCR's built-in metrics to evaluate them.
-| ARGS | Type | Description |
-| ------------- | ----- | --------------------------------- |
-| config | str | (required) Path to the config. |
-| pkl_results | str | (required) The saved predictions. |
-| --cfg-options | float | Override configs. [Example](<>) |
+| ARGS | Type | Description |
+| ------------- | ----- | ------------------------------------------------------------------ |
+| config | str | (required) Path to the config. |
+| pkl_results | str | (required) The saved predictions. |
+| --cfg-options | float | Override configs. [Example](./config.md#command-line-modification) |
+
+### Calculate FLOPs and the Number of Parameters
+
+We provide a method to calculate the FLOPs and the number of parameters, first we install the dependencies using the following command.
+
+```shell
+pip install fvcore
+```
+
+The usage of the script to calculate FLOPs and the number of parameters is as follows.
+
+```shell
+python tools/analysis_tools/get_flops.py ${config} --shape ${IMAGE_SHAPE}
+```
+
+| ARGS | Type | Description |
+| ------- | ---- | ----------------------------------------------------------------------------------------- |
+| config | str | (required) Path to the config. |
+| --shape | int | Image size to use when calculating FLOPs, such as `--shape 320 320`. Default is `640 640` |
+
+For example, you can run the following command to get FLOPs and the number of parameters of `dbnet_resnet18_fpnc_100k_synthtext.py`:
+
+```shell
+python tools/analysis_tools/get_flops.py configs/textdet/dbnet/dbnet_resnet18_fpnc_100k_synthtext.py --shape 1024 1024
+```
+
+The output is as follows:
+
+```shell
+input shape is (1, 3, 1024, 1024)
+| module | #parameters or shape | #flops |
+| :------------------------ | :------------------- | :------ |
+| model | 12.341M | 63.955G |
+| backbone | 11.177M | 38.159G |
+| backbone.conv1 | 9.408K | 2.466G |
+| backbone.conv1.weight | (64, 3, 7, 7) | |
+| backbone.bn1 | 0.128K | 83.886M |
+| backbone.bn1.weight | (64,) | |
+| backbone.bn1.bias | (64,) | |
+| backbone.layer1 | 0.148M | 9.748G |
+| backbone.layer1.0 | 73.984K | 4.874G |
+| backbone.layer1.1 | 73.984K | 4.874G |
+| backbone.layer2 | 0.526M | 8.642G |
+| backbone.layer2.0 | 0.23M | 3.79G |
+| backbone.layer2.1 | 0.295M | 4.853G |
+| backbone.layer3 | 2.1M | 8.616G |
+| backbone.layer3.0 | 0.919M | 3.774G |
+| backbone.layer3.1 | 1.181M | 4.842G |
+| backbone.layer4 | 8.394M | 8.603G |
+| backbone.layer4.0 | 3.673M | 3.766G |
+| backbone.layer4.1 | 4.721M | 4.837G |
+| neck | 0.836M | 14.887G |
+| neck.lateral_convs | 0.246M | 2.013G |
+| neck.lateral_convs.0.conv | 16.384K | 1.074G |
+| neck.lateral_convs.1.conv | 32.768K | 0.537G |
+| neck.lateral_convs.2.conv | 65.536K | 0.268G |
+| neck.lateral_convs.3.conv | 0.131M | 0.134G |
+| neck.smooth_convs | 0.59M | 12.835G |
+| neck.smooth_convs.0.conv | 0.147M | 9.664G |
+| neck.smooth_convs.1.conv | 0.147M | 2.416G |
+| neck.smooth_convs.2.conv | 0.147M | 0.604G |
+| neck.smooth_convs.3.conv | 0.147M | 0.151G |
+| det_head | 0.329M | 10.909G |
+| det_head.binarize | 0.164M | 10.909G |
+| det_head.binarize.0 | 0.147M | 9.664G |
+| det_head.binarize.1 | 0.128K | 20.972M |
+| det_head.binarize.3 | 16.448K | 1.074G |
+| det_head.binarize.4 | 0.128K | 83.886M |
+| det_head.binarize.6 | 0.257K | 67.109M |
+| det_head.threshold | 0.164M | |
+| det_head.threshold.0 | 0.147M | |
+| det_head.threshold.1 | 0.128K | |
+| det_head.threshold.3 | 16.448K | |
+| det_head.threshold.4 | 0.128K | |
+| det_head.threshold.6 | 0.257K | |
+!!!Please be cautious if you use the results in papers. You may need to check if all ops are supported and verify that the flops computation is correct.
+```
diff --git a/docs/zh_cn/user_guides/useful_tools.md b/docs/zh_cn/user_guides/useful_tools.md
index 3214c7440..bcca608f8 100644
--- a/docs/zh_cn/user_guides/useful_tools.md
+++ b/docs/zh_cn/user_guides/useful_tools.md
@@ -45,8 +45,85 @@ python tools/analysis_tools/offline_eval.py configs/textdet/psenet/psenet_r50_fp
此外,基于此工具,用户也可以将其他算法库获取的预测结果转换成 MMOCR 支持的格式,从而使用 MMOCR 内置的评估指标来对其他算法库的模型进行评测。
-| 参数 | 类型 | 说明 |
-| ------------- | ----- | ---------------------------------------- |
-| config | str | (必须)配置文件路径。 |
-| pkl_results | str | (必须)预先保存的预测结果文件。 |
-| --cfg-options | float | 用于覆写配置文件中的指定参数。[示例](<>) |
+| 参数 | 类型 | 说明 |
+| ------------- | ----- | ---------------------------------------------------------------- |
+| config | str | (必须)配置文件路径。 |
+| pkl_results | str | (必须)预先保存的预测结果文件。 |
+| --cfg-options | float | 用于覆写配置文件中的指定参数。[示例](./config.md#命令行修改配置) |
+
+### 计算 FLOPs 和参数量
+
+我们提供一个计算 FLOPs 和参数量的方法,首先我们使用以下命令安装依赖。
+
+```shell
+pip install fvcore
+```
+
+计算 FLOPs 和参数量的脚本使用方法如下:
+
+```shell
+python tools/analysis_tools/get_flops.py ${config} --shape ${IMAGE_SHAPE}
+```
+
+| 参数 | 类型 | 说明 |
+| ------- | ------ | ------------------------------------------------------------------ |
+| config | str | (必须) 配置文件路径。 |
+| --shape | int\*2 | 计算 FLOPs 使用的图片尺寸,如 `--shape 320 320`。 默认为 `640 640` |
+
+获取 `dbnet_resnet18_fpnc_100k_synthtext.py` FLOPs 和参数量的示例命令如下。
+
+```shell
+python tools/analysis_tools/get_flops.py configs/textdet/dbnet/dbnet_resnet18_fpnc_100k_synthtext.py --shape 1024 1024
+```
+
+输出如下:
+
+```shell
+input shape is (1, 3, 1024, 1024)
+| module | #parameters or shape | #flops |
+| :------------------------ | :------------------- | :------ |
+| model | 12.341M | 63.955G |
+| backbone | 11.177M | 38.159G |
+| backbone.conv1 | 9.408K | 2.466G |
+| backbone.conv1.weight | (64, 3, 7, 7) | |
+| backbone.bn1 | 0.128K | 83.886M |
+| backbone.bn1.weight | (64,) | |
+| backbone.bn1.bias | (64,) | |
+| backbone.layer1 | 0.148M | 9.748G |
+| backbone.layer1.0 | 73.984K | 4.874G |
+| backbone.layer1.1 | 73.984K | 4.874G |
+| backbone.layer2 | 0.526M | 8.642G |
+| backbone.layer2.0 | 0.23M | 3.79G |
+| backbone.layer2.1 | 0.295M | 4.853G |
+| backbone.layer3 | 2.1M | 8.616G |
+| backbone.layer3.0 | 0.919M | 3.774G |
+| backbone.layer3.1 | 1.181M | 4.842G |
+| backbone.layer4 | 8.394M | 8.603G |
+| backbone.layer4.0 | 3.673M | 3.766G |
+| backbone.layer4.1 | 4.721M | 4.837G |
+| neck | 0.836M | 14.887G |
+| neck.lateral_convs | 0.246M | 2.013G |
+| neck.lateral_convs.0.conv | 16.384K | 1.074G |
+| neck.lateral_convs.1.conv | 32.768K | 0.537G |
+| neck.lateral_convs.2.conv | 65.536K | 0.268G |
+| neck.lateral_convs.3.conv | 0.131M | 0.134G |
+| neck.smooth_convs | 0.59M | 12.835G |
+| neck.smooth_convs.0.conv | 0.147M | 9.664G |
+| neck.smooth_convs.1.conv | 0.147M | 2.416G |
+| neck.smooth_convs.2.conv | 0.147M | 0.604G |
+| neck.smooth_convs.3.conv | 0.147M | 0.151G |
+| det_head | 0.329M | 10.909G |
+| det_head.binarize | 0.164M | 10.909G |
+| det_head.binarize.0 | 0.147M | 9.664G |
+| det_head.binarize.1 | 0.128K | 20.972M |
+| det_head.binarize.3 | 16.448K | 1.074G |
+| det_head.binarize.4 | 0.128K | 83.886M |
+| det_head.binarize.6 | 0.257K | 67.109M |
+| det_head.threshold | 0.164M | |
+| det_head.threshold.0 | 0.147M | |
+| det_head.threshold.1 | 0.128K | |
+| det_head.threshold.3 | 16.448K | |
+| det_head.threshold.4 | 0.128K | |
+| det_head.threshold.6 | 0.257K | |
+!!!Please be cautious if you use the results in papers. You may need to check if all ops are supported and verify that the flops computation is correct.
+```
diff --git a/tools/analysis_tools/get_flops.py b/tools/analysis_tools/get_flops.py
new file mode 100644
index 000000000..4c88c847d
--- /dev/null
+++ b/tools/analysis_tools/get_flops.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+import torch
+from fvcore.nn import FlopCountAnalysis, flop_count_table
+from mmengine import Config
+
+from mmocr.registry import MODELS
+from mmocr.utils import register_all_modules
+
+register_all_modules()
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train a detector')
+ parser.add_argument('config', help='train config file path')
+ parser.add_argument(
+ '--shape',
+ type=int,
+ nargs='+',
+ default=[640, 640],
+ help='input image size')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+
+ args = parse_args()
+
+ if len(args.shape) == 1:
+ h = w = args.shape[0]
+ elif len(args.shape) == 2:
+ h, w = args.shape
+ else:
+ raise ValueError('invalid input shape, please use --shape h w')
+
+ input_shape = (1, 3, h, w)
+
+ cfg = Config.fromfile(args.config)
+ model = MODELS.build(cfg.model)
+
+ flops = FlopCountAnalysis(model, torch.ones(input_shape))
+
+ # params = parameter_count_table(model)
+ flops_data = flop_count_table(flops)
+
+ print(flops_data)
+
+ print('!!!Please be cautious if you use the results in papers. '
+ 'You may need to check if all ops are supported and verify that the '
+ 'flops computation is correct.')
+
+
+if __name__ == '__main__':
+ main()
From daa676dd37d9ac7aab570fbb4fdf99966bb917ee Mon Sep 17 00:00:00 2001
From: Tong Gao
Date: Sun, 9 Oct 2022 19:08:12 +0800
Subject: [PATCH 32/32] Bump version to 1.0.0rc1 (#1432)
* Bump version to 1.0.0rc1
* update changelog
* update changelog
* update changelog
* update changelog
* update highlights
---
docs/en/get_started/install.md | 8 ++---
docs/en/notes/changelog.md | 53 +++++++++++++++++++++++++++++++
docs/zh_cn/get_started/install.md | 8 ++---
mmocr/version.py | 2 +-
4 files changed, 62 insertions(+), 9 deletions(-)
diff --git a/docs/en/get_started/install.md b/docs/en/get_started/install.md
index 94365d3c3..74d16a932 100644
--- a/docs/en/get_started/install.md
+++ b/docs/en/get_started/install.md
@@ -191,7 +191,7 @@ docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmocr/data mmocr
MMOCR has different version requirements on MMCV and MMDetection at each release to guarantee the implementation correctness. Please refer to the table below and ensure the package versions fit the requirement.
-| MMOCR | MMCV | MMDetection |
-| -------- | ----------------- | ------------------ |
-| dev-1.x | 2.0.0rc1 \<= mmcv | 3.0.0rc0 \<= mmdet |
-| 1.0.0rc0 | 2.0.0rc1 \<= mmcv | 3.0.0rc0 \<= mmdet |
+| MMOCR | MMCV | MMDetection |
+| ------------- | ----------------- | ------------------ |
+| dev-1.x | 2.0.0rc1 \<= mmcv | 3.0.0rc0 \<= mmdet |
+| 1.0.0rc0, rc1 | 2.0.0rc1 \<= mmcv | 3.0.0rc0 \<= mmdet |
diff --git a/docs/en/notes/changelog.md b/docs/en/notes/changelog.md
index 379d9269b..65b55eca1 100644
--- a/docs/en/notes/changelog.md
+++ b/docs/en/notes/changelog.md
@@ -1,5 +1,58 @@
# Changelog of v1.x
+## v1.0.0rc1 (9/10/2022)
+
+### Highlights
+
+This release fixes a severe bug leading to inaccurate metric report in multi-GPU training.
+We release the weights for all the text recognition models in MMOCR 1.0 architecture. The inference shorthand for them are also added back to `ocr.py`. Besides, more documentation chapters are available now.
+
+### New Features & Enhancements
+
+- Simplify the Mask R-CNN config by @xinke-wang in https://github.com/open-mmlab/mmocr/pull/1391
+- auto scale lr by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/1326
+- Update paths to pretrain weights by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1416
+- Streamline duplicated split_result in pan_postprocessor by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1418
+- Update model links in ocr.py and inference.md by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1431
+- Update rec configs by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1417
+- Visualizer refine by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/1411
+- Support get flops and parameters in dev-1.x by @vansin in https://github.com/open-mmlab/mmocr/pull/1414
+
+### Docs
+
+- intersphinx and api by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/1367
+- Fix quickrun by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1374
+- Fix some docs issues by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1385
+- Add Documents for DataElements by @xinke-wang in https://github.com/open-mmlab/mmocr/pull/1381
+- config english by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/1372
+- Metrics by @xinke-wang in https://github.com/open-mmlab/mmocr/pull/1399
+- Add version switcher to menu by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1407
+- Data Transforms by @xinke-wang in https://github.com/open-mmlab/mmocr/pull/1392
+- Fix inference docs by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1415
+- Fix some docs by @xinke-wang in https://github.com/open-mmlab/mmocr/pull/1410
+- Add maintenance plan to migration guide by @xinke-wang in https://github.com/open-mmlab/mmocr/pull/1413
+- Update Recog Models by @xinke-wang in https://github.com/open-mmlab/mmocr/pull/1402
+
+### Bug Fixes
+
+- clear metric.results only done in main process by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/1379
+- Fix a bug in MMDetWrapper by @xinke-wang in https://github.com/open-mmlab/mmocr/pull/1393
+- Fix browse_dataset.py by @Mountchicken in https://github.com/open-mmlab/mmocr/pull/1398
+- ImgAugWrapper: Do not cilp polygons if not applicable by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1231
+- Fix CI by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1365
+- Fix merge stage test by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1370
+- Del CI support for torch 1.5.1 by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1371
+- Test windows cu111 by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1373
+- Fix windows CI by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1387
+- Upgrade pre commit hooks by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/1429
+- Skip invalid augmented polygons in ImgAugWrapper by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/1434
+
+## New Contributors
+
+- @vansin made their first contribution in https://github.com/open-mmlab/mmocr/pull/1414
+
+**Full Changelog**: https://github.com/open-mmlab/mmocr/compare/v1.0.0rc0...v1.0.0rc1
+
## v1.0.0rc0 (1/9/2022)
We are excited to announce the release of MMOCR 1.0.0rc0.
diff --git a/docs/zh_cn/get_started/install.md b/docs/zh_cn/get_started/install.md
index 1cbf2a7e7..6ddddf909 100644
--- a/docs/zh_cn/get_started/install.md
+++ b/docs/zh_cn/get_started/install.md
@@ -192,7 +192,7 @@ docker run --gpus all --shm-size=8g -it -v {实际数据目录}:/mmocr/data mmoc
为了确保代码实现的正确性,MMOCR 每个版本都有可能改变对 MMCV 和 MMDetection 版本的依赖。请根据以下表格确保版本之间的相互匹配。
-| MMOCR | MMCV | MMDetection |
-| -------- | ----------------- | ------------------ |
-| dev-1.x | 2.0.0rc1 \<= mmcv | 3.0.0rc0 \<= mmdet |
-| 1.0.0rc0 | 2.0.0rc1 \<= mmcv | 3.0.0rc0 \<= mmdet |
+| MMOCR | MMCV | MMDetection |
+| ------------- | ----------------- | ------------------ |
+| dev-1.x | 2.0.0rc1 \<= mmcv | 3.0.0rc0 \<= mmdet |
+| 1.0.0rc0, rc1 | 2.0.0rc1 \<= mmcv | 3.0.0rc0 \<= mmdet |
diff --git a/mmocr/version.py b/mmocr/version.py
index 2a4882c14..6dd1ae051 100644
--- a/mmocr/version.py
+++ b/mmocr/version.py
@@ -1,4 +1,4 @@
# Copyright (c) Open-MMLab. All rights reserved.
-__version__ = '1.0.0rc0'
+__version__ = '1.0.0rc1'
short_version = __version__




 -
- -
- -
-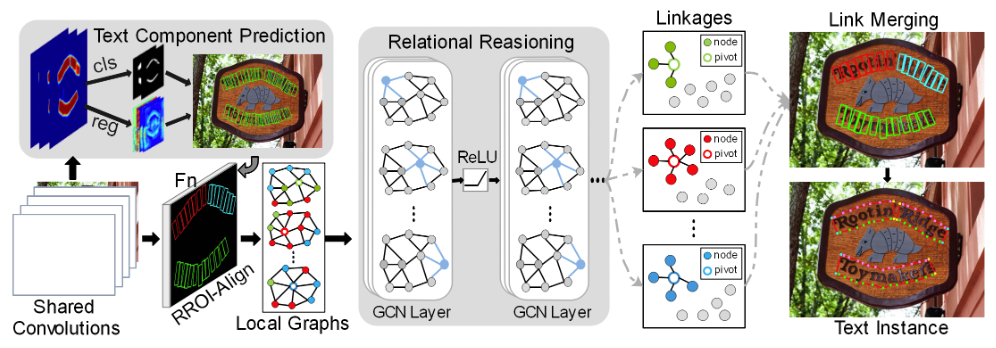 -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
-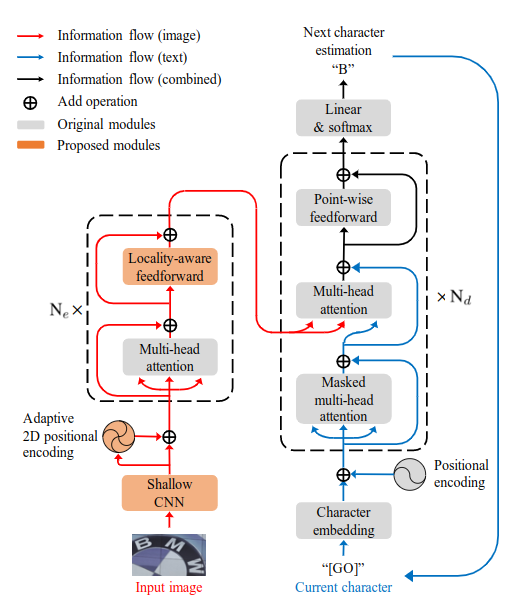 -
-

 +```{note}
For details on the parameters and usage of this script, please refer to [here](../user_guides/useful_tools.md).
+```
```{tip}
In addition to satisfying our curiosity, visualization can also help us check the parts that may affect the model's performance before training, such as problems in configs, datasets and data transforms.
diff --git a/docs/en/migration/model.md b/docs/en/migration/model.md
index c4b492e8b..2ab507470 100644
--- a/docs/en/migration/model.md
+++ b/docs/en/migration/model.md
@@ -1,4 +1,4 @@
-# Pretrained Models Migration
+# Pretrained Model Migration
Due to the extensive refactoring and fixing of the model structure in the new version, MMOCR 1.x does not support load weights trained by the old version. We have updated the pre-training weights and logs of all models on our website.
diff --git a/docs/en/migration/overview.md b/docs/en/migration/overview.md
index d1b1e2472..776306051 100644
--- a/docs/en/migration/overview.md
+++ b/docs/en/migration/overview.md
@@ -1,9 +1,9 @@
# Overview
-Along with the release of OpenMMLab 2.0, MMOCR 1.0 made many groundbreaking changes, resulting in less redundant, more efficient code and a more consistent overall design. However, these changes break backward compatibility. We understand that with such huge changes, it is not easy for users familiar with the old version to adapt to the new version. Therefore, we prepared a detailed migration guide to make the transition as smooth as possible so that all users can enjoy the productivity benefits of the new MMOCR and the entire OpenMMLab 2.0 ecosystem.
+Along with the release of OpenMMLab 2.0, MMOCR 1.0 made many significant changes, resulting in less redundant, more efficient code and a more consistent overall design. However, these changes break backward compatibility. We understand that with such huge changes, it is not easy for users familiar with the old version to adapt to the new version. Therefore, we prepared a detailed migration guide to make the transition as smooth as possible so that all users can enjoy the productivity benefits of the new MMOCR and the entire OpenMMLab 2.0 ecosystem.
Next, please read the sections according to your requirements.
-- If you want to migrate a model trained in version 0.x to use it directly in version 1.0, please read [Pre-trained Model Migration](./model.md).
-- If you want to train the model, please read [Dataset Migration](./dataset.md) and [Data Augmentation Migration](./transforms.md).
-- If you want to develop on MMOCR, please read [Code Migration](code.md) and [Upstream Dependency Library Changes](https://github.com/open-mmlab/mmengine/tree/main/docs/en/migration).
+- If you want to migrate a model trained in version 0.x to use it directly in version 1.0, please read [Pretrained Model Migration](./model.md).
+- If you want to train the model, please read [Dataset Migration](./dataset.md) and [Data Transform Migration](./transforms.md).
+- If you want to develop on MMOCR, please read [Code Migration](code.md) and [Upstream Library Changes](https://github.com/open-mmlab/mmengine/tree/main/docs/en/migration).
diff --git a/docs/en/migration/transforms.md b/docs/en/migration/transforms.md
index f9cb9bd6b..33661313d 100644
--- a/docs/en/migration/transforms.md
+++ b/docs/en/migration/transforms.md
@@ -1,4 +1,4 @@
-# Migration of Data Transforms
+# Data Transform Migration
## Introduction
diff --git a/docs/zh_cn/get_started/quick_run.md b/docs/zh_cn/get_started/quick_run.md
index d26686853..ea3a3212c 100644
--- a/docs/zh_cn/get_started/quick_run.md
+++ b/docs/zh_cn/get_started/quick_run.md
@@ -2,10 +2,16 @@
## 推理
+如果想快速运行一个推理,请直接阅读安装文档的[检验](install.md#检验)。对 MMOCR 中推理接口更为详细说明,可以在[这里](../user_guides/inference.md)找到。
+
+```{note}
+
除了使用我们提供好的预训练模型,用户也可以在自己的数据集上训练流行模型。接下来我们以在迷你的 [ICDAR 2015](https://rrc.cvc.uab.es/?ch=4&com=downloads) 数据集上训练 DBNet 为例,带大家熟悉 MMOCR 的基本功能。
接下来的部分都假设你使用的是[编辑方式安装 MMOCR 代码库](install.md)。
+```
+
## 准备数据集
由于 OCR 任务的数据集种类多样,格式不一,不利于多数据集的切换和联合训练,因此 MMOCR 约定了一种[统一的数据格式](../user_guides/dataset_prepare.md),并针对常用的 OCR 数据集都提供了对应的转换脚本和[教程](../user_guides/dataset_prepare.md)。通常,要在 MMOCR 中使用数据集,你只需要按照对应步骤运行指令即可。
@@ -65,7 +71,9 @@ python tools/analysis_tools/browse_dataset.py configs/textdet/dbnet/dbnet_resnet
+```{note}
For details on the parameters and usage of this script, please refer to [here](../user_guides/useful_tools.md).
+```
```{tip}
In addition to satisfying our curiosity, visualization can also help us check the parts that may affect the model's performance before training, such as problems in configs, datasets and data transforms.
diff --git a/docs/en/migration/model.md b/docs/en/migration/model.md
index c4b492e8b..2ab507470 100644
--- a/docs/en/migration/model.md
+++ b/docs/en/migration/model.md
@@ -1,4 +1,4 @@
-# Pretrained Models Migration
+# Pretrained Model Migration
Due to the extensive refactoring and fixing of the model structure in the new version, MMOCR 1.x does not support load weights trained by the old version. We have updated the pre-training weights and logs of all models on our website.
diff --git a/docs/en/migration/overview.md b/docs/en/migration/overview.md
index d1b1e2472..776306051 100644
--- a/docs/en/migration/overview.md
+++ b/docs/en/migration/overview.md
@@ -1,9 +1,9 @@
# Overview
-Along with the release of OpenMMLab 2.0, MMOCR 1.0 made many groundbreaking changes, resulting in less redundant, more efficient code and a more consistent overall design. However, these changes break backward compatibility. We understand that with such huge changes, it is not easy for users familiar with the old version to adapt to the new version. Therefore, we prepared a detailed migration guide to make the transition as smooth as possible so that all users can enjoy the productivity benefits of the new MMOCR and the entire OpenMMLab 2.0 ecosystem.
+Along with the release of OpenMMLab 2.0, MMOCR 1.0 made many significant changes, resulting in less redundant, more efficient code and a more consistent overall design. However, these changes break backward compatibility. We understand that with such huge changes, it is not easy for users familiar with the old version to adapt to the new version. Therefore, we prepared a detailed migration guide to make the transition as smooth as possible so that all users can enjoy the productivity benefits of the new MMOCR and the entire OpenMMLab 2.0 ecosystem.
Next, please read the sections according to your requirements.
-- If you want to migrate a model trained in version 0.x to use it directly in version 1.0, please read [Pre-trained Model Migration](./model.md).
-- If you want to train the model, please read [Dataset Migration](./dataset.md) and [Data Augmentation Migration](./transforms.md).
-- If you want to develop on MMOCR, please read [Code Migration](code.md) and [Upstream Dependency Library Changes](https://github.com/open-mmlab/mmengine/tree/main/docs/en/migration).
+- If you want to migrate a model trained in version 0.x to use it directly in version 1.0, please read [Pretrained Model Migration](./model.md).
+- If you want to train the model, please read [Dataset Migration](./dataset.md) and [Data Transform Migration](./transforms.md).
+- If you want to develop on MMOCR, please read [Code Migration](code.md) and [Upstream Library Changes](https://github.com/open-mmlab/mmengine/tree/main/docs/en/migration).
diff --git a/docs/en/migration/transforms.md b/docs/en/migration/transforms.md
index f9cb9bd6b..33661313d 100644
--- a/docs/en/migration/transforms.md
+++ b/docs/en/migration/transforms.md
@@ -1,4 +1,4 @@
-# Migration of Data Transforms
+# Data Transform Migration
## Introduction
diff --git a/docs/zh_cn/get_started/quick_run.md b/docs/zh_cn/get_started/quick_run.md
index d26686853..ea3a3212c 100644
--- a/docs/zh_cn/get_started/quick_run.md
+++ b/docs/zh_cn/get_started/quick_run.md
@@ -2,10 +2,16 @@
## 推理
+如果想快速运行一个推理,请直接阅读安装文档的[检验](install.md#检验)。对 MMOCR 中推理接口更为详细说明,可以在[这里](../user_guides/inference.md)找到。
+
+```{note}
+
除了使用我们提供好的预训练模型,用户也可以在自己的数据集上训练流行模型。接下来我们以在迷你的 [ICDAR 2015](https://rrc.cvc.uab.es/?ch=4&com=downloads) 数据集上训练 DBNet 为例,带大家熟悉 MMOCR 的基本功能。
接下来的部分都假设你使用的是[编辑方式安装 MMOCR 代码库](install.md)。
+```
+
## 准备数据集
由于 OCR 任务的数据集种类多样,格式不一,不利于多数据集的切换和联合训练,因此 MMOCR 约定了一种[统一的数据格式](../user_guides/dataset_prepare.md),并针对常用的 OCR 数据集都提供了对应的转换脚本和[教程](../user_guides/dataset_prepare.md)。通常,要在 MMOCR 中使用数据集,你只需要按照对应步骤运行指令即可。
@@ -65,7 +71,9 @@ python tools/analysis_tools/browse_dataset.py configs/textdet/dbnet/dbnet_resnet