Replies: 4 comments 2 replies
-
|
I think doing a complete re-write might be tricky. It is connected to a lot of different parts of the operator, so there might be many conflicts. You also cannot roll it out with just some features. It needs to have at least parity with the current implementation. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @scholzj. Also there was an idea about implementing this as a state machine @tombentley Did you imagine a state machine to bring a single pod to a healthy state, or a state machine for the whole cluster? So a whole cluster state machine would observe the entire cluster state and determine the next action to progress it (or bail out if something is unhealthy). |
Beta Was this translation helpful? Give feedback.
-
I was thinking about having a state machine per broker. But we should be KRaft-aware and think in terms of server (which could be broker, controller or both). You can see a very hand-wavy bit of code here. The basic idea there is to separate out:
The main benefit I see from using an explicit state machine is simply that it makes it very easy to understand (such as in application logs) what's happening/happened if you log the state of all brokers when you take actions in the roller. In a way it's not really a state machine because you don't prohibit any transitions between states. i.e. we shouldn't build in assumptions about what is possible/impossible, but we do build in the logic for "if it's in state X then we do action Y". |
Beta Was this translation helpful? Give feedback.
-
|
Another question about the Roller. It currently does things like detect "stuck pods" or pods that it can't make an admin connection to and restarts them, having no awareness of log recovery. There is an idea proposed to expose to the operator that a broker is in recovery so that Roller won't restart it. Should restarting stuck/non-responsive pods be a Roller responsibility, or could we keep improving the Liveness/Readiness probe so they handle detecting these stuck cases so roller can focus on awaiting readiness? I imagine there is some history of problems fixed by each behaviour of the roller. Maybe it fixes some problems that we can't detect from the probes? |
Beta Was this translation helpful? Give feedback.
-
|
IIRC the "stuck pod" is trying capture the case where either:
Aside: I have wondered whether point 1 could also be made less common by killing and restarting the broker within its existing container, thus avoiding the need to involve the kube scheduler at all (since the pod wouldn't get deleted). However, this interacts poorly with kube healthy probes, and the benefits don't seem worth the additional complexity. What we wanted to avoid was the broker picking healthy pods to delete over successive reconciliations and eventually taking down the cluster. But the definition of a "stuck pod" was always a bit vague, it was based on what's broken in the past. With the state machine idea this is achieved by:
The Admin thing is also a bit vague. The idea was to infer that the broker isn't unhealthy because it's responding to a client, so you know you have network reachability at least. If this fails maybe deleting the pod will make things work (because who knows how reliable the networking stack that we're running on really is?). But there are possibly simpler ways of achieving this: We don't really need to use a separate Admin client instance, for example: It should be enough to use a describe broker configs request. This is also the same basic idea that the canary uses. It seems a bit wasteful to duplicate the logic for this kind of thing, and creates the possibility that the canary reaches a different conclusion than the broker. So it would be nice for these to converge eventually (i.e. I don't see it as a short term goal). |
Beta Was this translation helpful? Give feedback.
-
|
Some thoughts from my understanding based on @tombentley 's session and following discussions
@tombentley 's proposed state machine (see below) is broker level. I wanted to get the status from @ShubhamRwt about his WIP and see if we (@ShubhamRwt , myself and any folks interested) can get a PoC, review it, and then explore enriching it that with a topic and partition state machine or maybe a cluster state machine "i.e in maintenance window, etc"
|
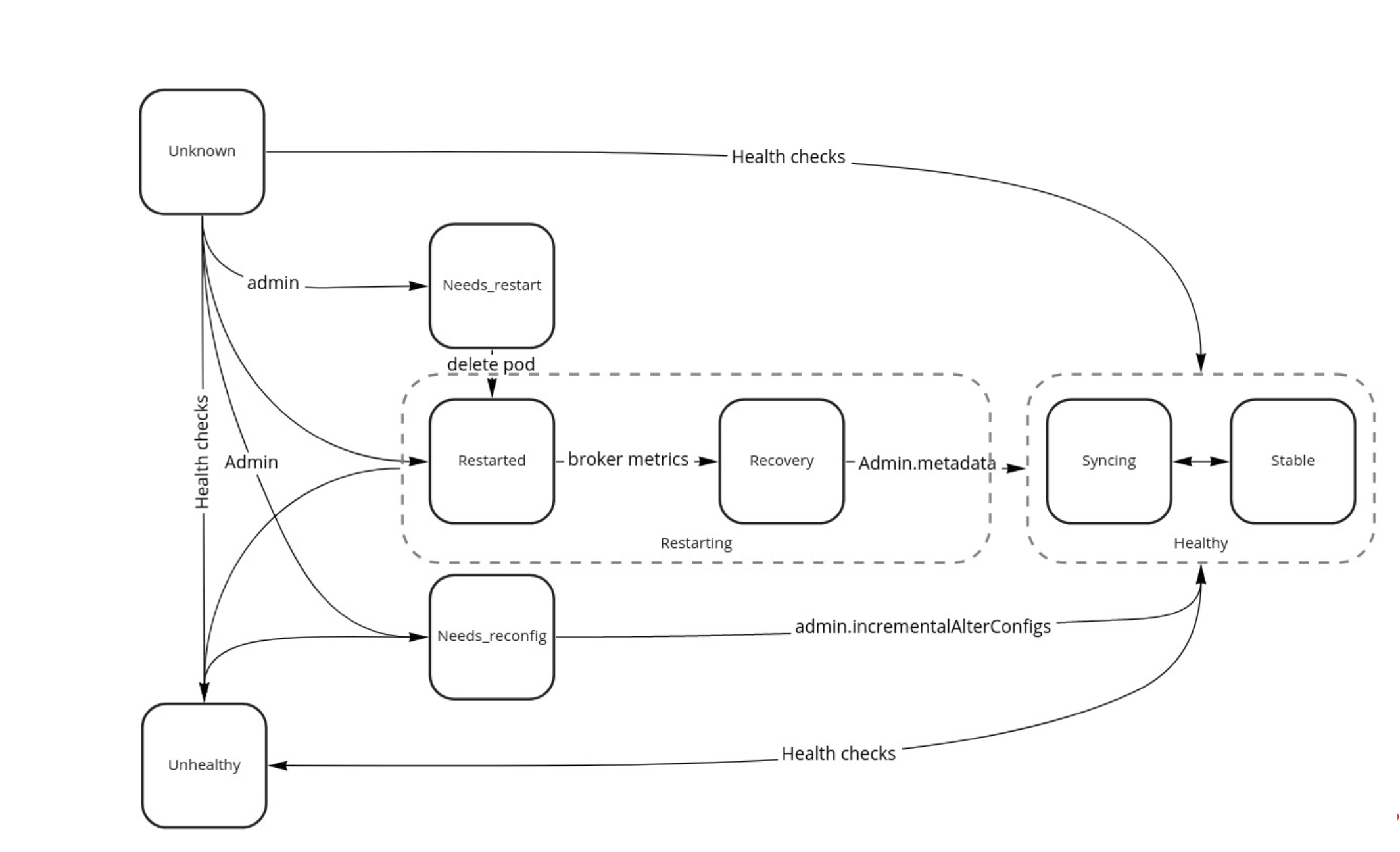
Beta Was this translation helpful? Give feedback.
-
There are several issues around the Kafka Roller that could warrant a re-implementation of the Roller.
General Questions:
Technical Discussion
Possible responsibilities that could be decomposed out:
Some kind of next-pod-selector or planner could be warranted because we currently distribute this decision in KafkaRoller. We sort the node list to act on unready pods first (selection in a roundabout way), then while processing a pod the roller can decide to defer acting if the pod is controller or would break availability. This might be easier to reason about if there is one place that says, "first we want to act on unready pods, then pods that won't break availability, and finally the controller". It could also be a good place to put the logic that says "after acting on pod X, pod X remained unhealthy, stop the roll".
First Steps
The above questions might not be answerable until we've had a first shot at an implementation.
We could start by spiking out an implementation that does a subset of the work, like "restarts pods that need restarting, rolling the controller last" so we can put up some rough code for criticism.
Beta Was this translation helpful? Give feedback.
All reactions