[**트위스티 퍼즐**이란?](https://ko.wikipedia.org/wiki/%EC%A1%B0%ED%95%A9_%ED%8D%BC%EC%A6%90#.EC.A0.95.EC.9C.A1.EB.A9.B4.EC.B2.B4_.EB.AA.A8.EC.96.91.EC.9D.98_.ED.8A.B8.EC.9C.84.EC.8A.A4.ED.8B.B0_.ED.8D.BC.EC.A6.90)
이 프로젝트는 강화학습(Reinforcement Learning)을 공부하기 위한 트위스티 게임 환경입니다.
흔히 큐브라고도 붙리는 이 게임은 수많은 경우의 수로 인해 해법 공식을 이용해 문제를 풀지 않는 이상 풀기 힘들다고 알려져 있습니다.
이 프로젝트는 그런 트위스트 퍼즐의 해법을 강화학습을 이용해 찾아낼 수 있는지 실험합니다.
트위스티 게임 환경은 [OpenAI Gym](https://gym.openai.com/)과 유사한 구조를 가집니다.
[//]: # "method 다듬은 뒤 example code 추가"
<!--- Usage ```python from cuvenv import poketCube
cube = poketCube() state = cube.reset() next_state, reward, terminal = cube.action("U") ... ``` -->
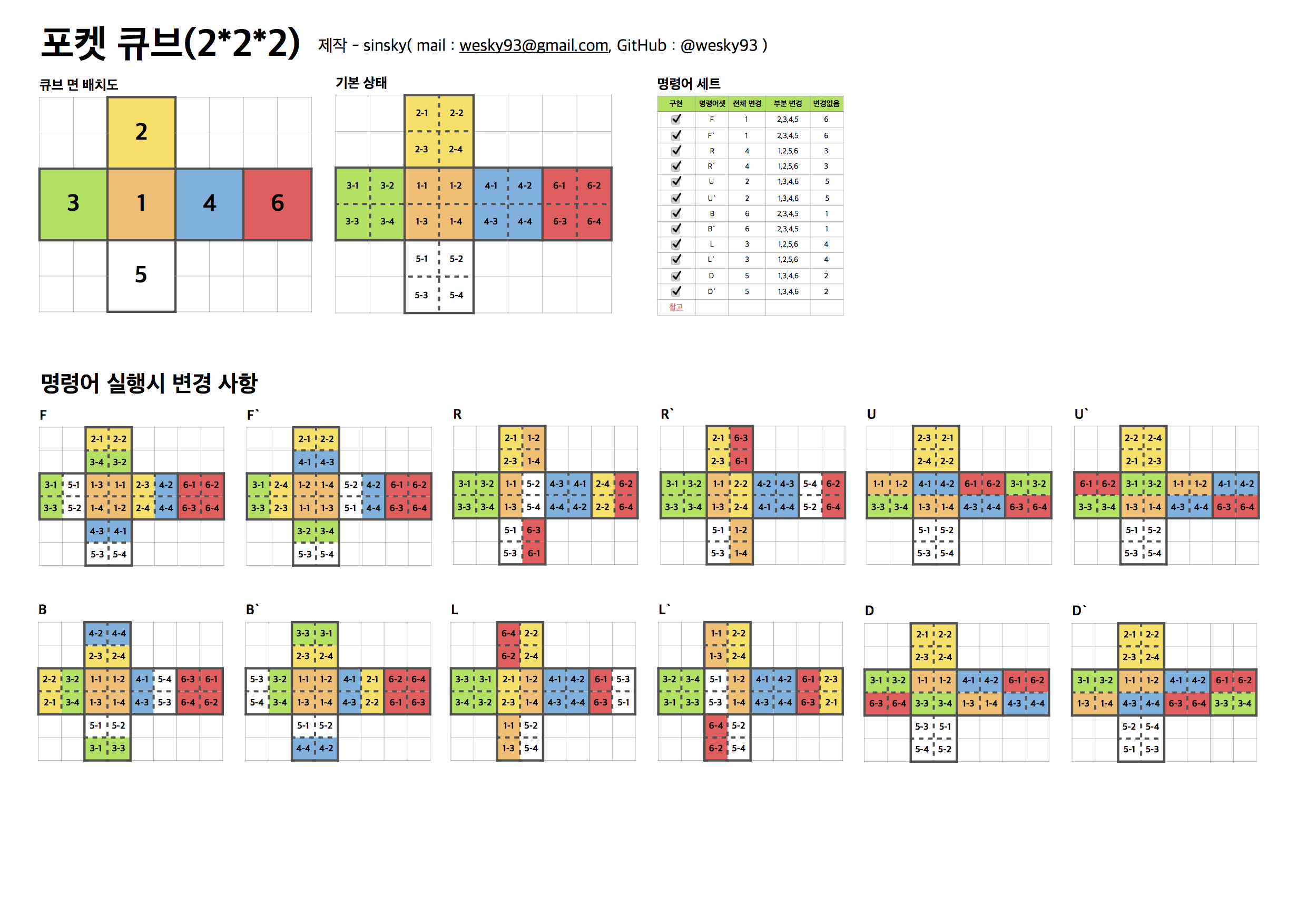
큐브의 여섯가지 색상은 1~6까지의 숫자로 표현되며, 큐브를 돌리는 행동은 미리 지정된 명령으로 표현됩니다.
U 명령을 수행했을 때 색의 변화 없이 90도 회전하게 되는 면을 윗면으로 두고, 모든 명령은 큐브를 이 방향으로 고정시킨 상태에서 수행됩니다.
[//]: # "state반환 시 어떤 구조로 반환되는지에 대한 설명 추가 필요"
- [x] 포켓 큐브(2*2*2) (TESTING)
- [x] 루빅스 큐브(3*3*3) (WIP)
- [ ] 리벤지 큐브(4*4*4)
- [ ] 프로페서스 큐브(5*5*5)
아래에 기술되는 명령은 회전 대상이 되는 면을 바라보고 시계방향으로 90˚ 회전한 명령, 반시계방향으로 90˚ 회전한 K'(prime) 명령과 시계반향으로 180˚ 회전한 K2 명령입니다. 실질적으로 공식 큐브 협회에서 규정한 명령어는 모두 사용가능합니다.
주의: twistyRL 에서 prime 명령어의 기호는 작은따옴표(')가 아닌 back quote(`)을 사용하고 있습니다. 주의: 180도 회전 명령어는 구현 되있지만 머신러닝에서는 90도 회전 명령어만 사용하시기 바랍니다.
- 포켓큐브:
- 시계반향 90˚ 회전: U, D, R, L, F, B
- 반시계반향 90˚ 회전: U`, D`, R`, L`, F`, B`
- 시계반향 180˚ 회전: U2, D2, R2, L2, F2, B2
{kind=link}
- 루빅스큐브:
- 시계반향 90˚ 회전: U, D, R, L, F, B
- 반시계반향 90˚ 회전: U`, D`, R`, L`, F`, B`
- 시계반향 180˚ 회전: U2, D2, R2, L2, F2, B2

{kind=link}
게임의 보상문제는 추후 토의를 통해 변경될 여지가 있습니다. 현재 보상 방식 아래와 같습니다. f = 면이 가질수 있는 최대 점수 (큐브 사이즈^2) fs = 각 면의 점수 총합(f*6) fok = 면의 모든 색(숫자)가 일치하는 면의 갯수(최대 6) c = 큐브 회전 횟수
- ~ 0.1.08 - fs
#. 0.1.09 ~ 0.1.11 - fs+fs/c 0.1.11까진 보상이 최종 점수의 개념이었으나 0.1.12이후부터 각 턴당 보상의 의미로 변경되었습니다. #. 0.1.12 ~ 0.1.14 - 완성된 면이 존재할경우 f*fok 그렇지 않으면 -1 #. 0.1.15 ~ - 완성된 면이 존재할경우 f*fok/c 로 줘서 단시간에 점수를 얻을경우 고득점을 얻게 하고 시간이 지날수록 저득점하게
WCA(World Cube Association)에서는 스크램블 프로그램을 이용하도록 [규정](https://www.worldcubeassociation.org/regulations/translations/korean/#5b5)하고 있습니다. 다만 이 게임에서는 아래와 같은 규칙으로 기본적인 스크램블을 수행합니다.
- random모듈을 이용하여 길이가 25개인 스크램블 5개를 만듭니다.
- 그중 한가지를 선택하여 스크램블을 수행합니다.
스크램블은 `cube.scramble()`메소드를 참고하시면 됩니다. 또한 스크램블 길이와 생산할 갯수는 매개변수(len,count)를 통해 변경 가능합니다.
[참고 - 공식 스크램블 프로그램](https://ruwix.com/puzzle-scramble-generators/rubiks-cube-scrambler/)
- 보상 문제: reward 책정에 관한 논의가 필요합니다.
- 0.1.01 : 패키지 메타데이터 오류 수정
- 0.1.02 : 패키지 데이터 추가
- 0.1.03 : setup.py의 readme.md 경로 문제 수정
- 0.1.04 : setup.py에서 readme.md를 setup.cfg로 분리
- 0.1.05 : cuvenv를 twistyRL로 변경
- 0.1.06 : readme.md -> readme.rst
- 0.1.07 : lodng-description추가
- 0.1.08 : 스크램블을 할때 스크램블 순서 출력 여부를 선택가능하게 변경,기본은 숨기게 함
- 0.1.09 : 보상 계산방식 변경
- 0.1.10 : getcube 메소드 추가, scramble시 큐브상태를 return하도록 변경
- 0.1.12 : 이전 point개념을 reward로 변경 및 총점수 추가
- 0.1.14 : cube.faces 스태틱 메소드 추가
- 0.1.15 : 보상 방법 변경
- 0.1.16 : 스크램블 알고리즘 강화
- 0.1.20 : check()메소드 제거 및 @property로 상테 메소드 구성