| layout | title | date | description | show-description | mathjax | autoanchor | image | authors | author-footnotes | links | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
default |
You've Got to Feel It To Believe It: Multi-Modal Bayesian Inference for Semantic and Property Prediction |
2024-02-08 13:24:00 -0400 |
Using multiple sensing modalities improves semantic predictions and enables complex task completion. |
true |
true |
true |
|
|
All authors affiliated with the Robotics Institute and department of Mechanical Engineering of the University of Michigan, Ann Arbor. |
|
{% include sections/authors %} {% include sections/links %}
Robots must be able to understand their surroundings to perform complex tasks in challenging environments and many of these complex tasks require estimates of physical properties such as friction or weight. Estimating such properties using learning is challenging due to the large amounts of labelled data required for training and the difficulty of updating these learned models online at run time. To overcome these challenges, this paper introduces a novel, multi-modal approach for representing semantic predictions and physical property estimates jointly in a probabilistic manner. By using conjugate pairs, the proposed method enables closed-form Bayesian updates given visual and tactile measurements without requiring additional training data. The efficacy of the proposed algorithm is demonstrated through several hardware experiments. In particular, this paper illustrates that by conditioning semantic classifications on physical properties, the proposed method quantitatively outperforms state-of-the-art semantic classification methods that rely on vision alone. To further illustrate its utility, the proposed method is used in several applications including to represent affordance-based properties probabilistically and a challenging terrain traversal task using a legged robot. In the latter task, the proposed method represents the coefficient of friction of the terrain probabilistically, which enables the use of an on-line risk-aware planner that switches the legged robot from a dynamic gait to a static, stable gait when the expected value of the coefficient of friction falls below a given threshold. Videos of these case studies are shown above.
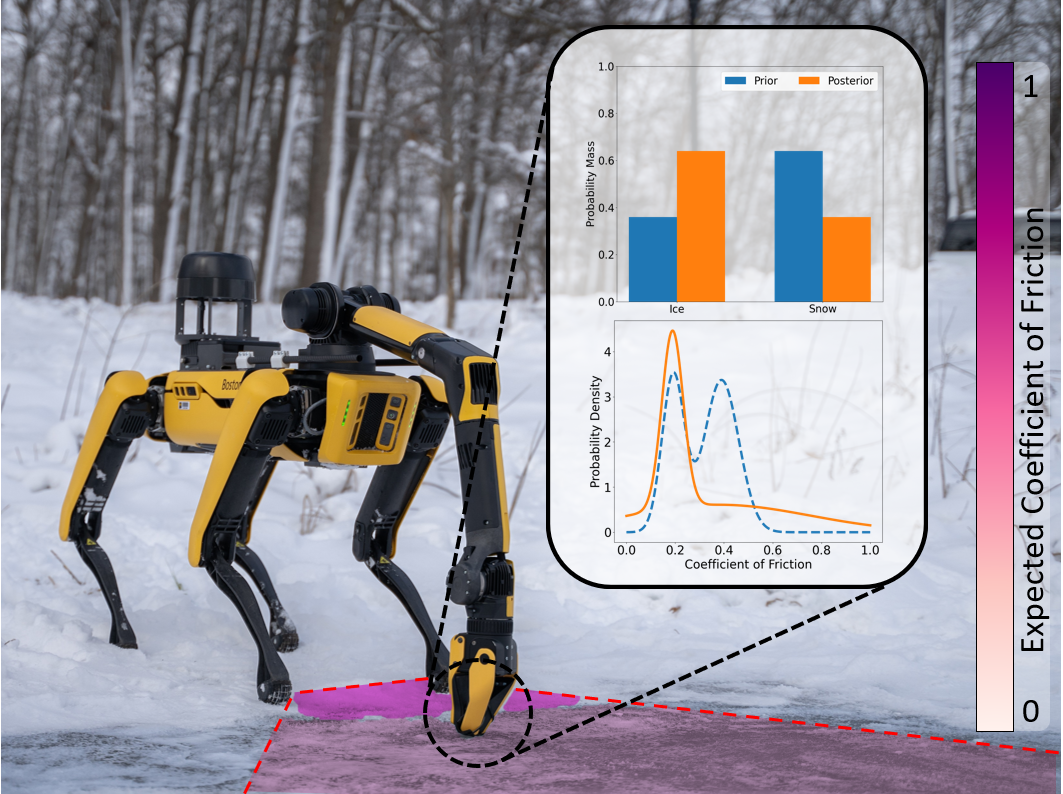
The method proposed in this paper jointly estimates semantic classifications and physical properties by combining visual and tactile data into a single semantic mapping framework. RGB-D images are used to build a metric-semantic map that iteratively estimates semantic labels. A property measurement is taken which in turn updates both the semantic class predictions and physical property estimates. In the depicted example, the robot is unsure if the terrain in front of it is snow or ice from vision measurements alone (prior estimates) which dramatically affects the coefficient of friction and the associated gait that can be applied to safely traverse the terrain. The robot uses a tactile sensor attached to its manipulator to update its coefficient of friction estimation (posterior estimates), which then enables it to change gaits to cross the ice safely.
A flow diagram illustrating our proposed mutli-modal mapping algorithm. A semantic classification algorithm predicts pixel-wise classes from RGB images that are then projected into a common mapping frame using the aligned depth image, camera intrinsics, and estimated camera pose. This semantic point cloud is used to build a metric-semantic map. When a property measurement is taken, the method of moments is used to update the semantic and property estimates jointly.

We use a custom implementation of the SegFormer network trained on the Dense Material Segmentation Dataset. The output of the network is then post-processed with a segment-based voting scheme using FastSAM. When a property measurement is taken, the method of moments updates a region of the geometric representation segmented using FastSAM. This incentivizes regions with spatial proximity and visual similarity to be updated using a single measurement rather than requiring one measurement for each voxel, making the algorithm more efficient. For hardware demonstrations, static friction measurements are taken using a force-torque sensor which measures contact forces during the motion of an end-effector against a surface.
We validate our approach in simulation and demonstrate property measurements improve semantic predictions. We use 1800 images and ground-truth semantic labels taken from the testing set of the Dense Material Segmentation Dataset and a pre-trained semantic segmentation neural network is used to predict semantic labels. Misclassified pixels in each image are randomly selected and a friction measurement is drawn from a Gaussian distribution using the corresponding ground-truth semantic label.

Results for a single simulated experiment are shown above. The image (a) and ground truth semantic labels (b) are from the Dense Material Segmentation Dataset. The semantic segmentation predictions (c) do not classify parts of the desk as wood. The method of moments then computes the correct posterior semantic label (d).
The mean pixel-wise accuracy of the semantic segmentation network over this dataset without applying the proposed algorithm is 27.2%. The mean pixel accuracy of the posterior semantic predictions output by Algorithm \ref{alg:moments} is 33.0%, an increase of 21.3%, demonstrating increased semantic prediction performance compared to semantic predictions using vision alone. This experiment highlights that by conditioning semantic classifications on physical properties, one can generally improve the accuracy of visual semantic classifications.
We further validate our method on several hardware demonstrations and compare against existing semantic mapping and property estimation approaches.
The end-effector of a Kinova Gen 3 robotic arm and a Spot Arm are used to collect friction measurements using built-in wrist-mounted force-torque sensors. For this experiment, 5 frames from the RGB-D stream are used to initialize the semantic TSDF map. Each RGB-D image is semantically segmented using the trained network and projected into the global coordinate frame using the aligned depth image. The recursive vision-based semantic update is applied for each semantic point cloud. This initializes the Dirichlet parameters used to compute the initial semantic classification weights for the measurement likelihood.

We compare our approach to the recursive semantic mapping approach of selmap which only uses vision. The same SegFormer-FastSAM semantic segmentation network is used for both methods. As shown in in the above demonstration, the network incorrectly classifies various objects in the scenes. When only vision-based semantic classifications are considered, the erroneous predictions from the network are unable to be corrected by selmap. Using the proposed method, a user specifies the location for friction measurements to be taken. The method of moments then computes the posterior semantic classification weights using the friction measurements as input. This corrects the expected semantic classification. We ran the experiment on two indoor scenes with two friction measurements each and show the semantic prediction accuracy increases using the proposed method and matches the ground-truth semantic labels.
We demonstrate the utility of our proposed property estimation method using a case study involving a challenging legged locomotion traversal task of crossing an icy surface and, likewise, on a case study for affordance-based property estimation. These two case studies are presented in the above video.
This project was developed in Robotics and Optimization for Analysis of Human Motion (ROAHM) Lab at University of Michigan - Ann Arbor.
@article{ewen2024feelit,
author = "Ewen, Parker and Chen, Hao and Chen, Yuzhen and Li, Anran and Bagali, Anup and Gunjal, Gitesh and Vasudevan, Ram",
title = "You've Got to Feel It To Believe It: Multi-Modal Bayesian Inference for Semantic and Property Prediction",
journal = "Robotics: Science and Systems",
year = 2024
}