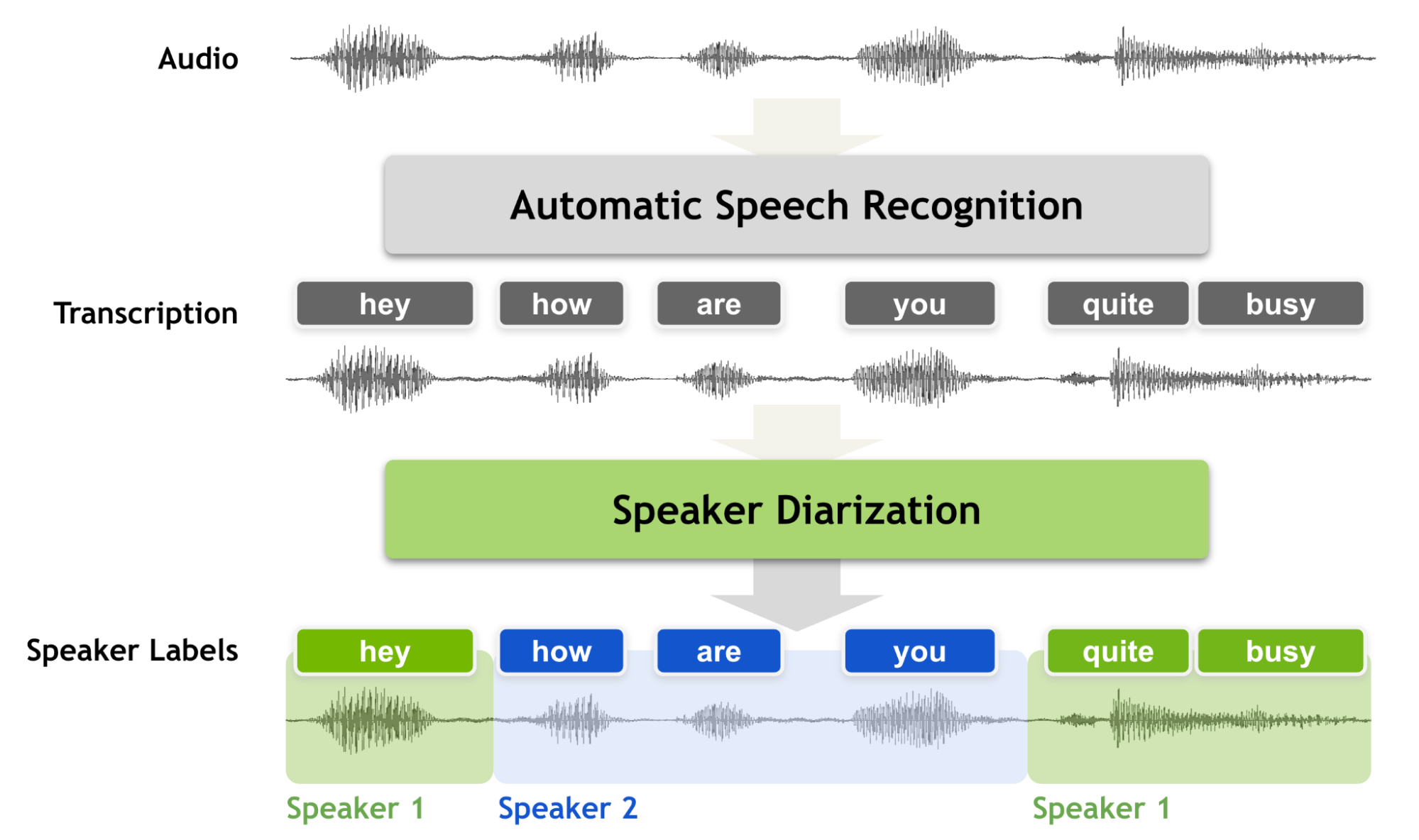
Speaker diarization is the process of partitioning an audio stream containing human speech into homogeneous segments according to the identity of each speaker. It can enhance the readability of an automatic speech transcription by structuring the audio stream into speaker turns and, when used together with speaker recognition systems, by providing the speaker’s true identity. It is used to answer the question "who spoke when?". Speaker diarization is an essential feature for a speech recognition system to enrich the transcription with speaker labels.
{kind=link}
In this tutorial, we consider how to build speaker diarization pipeline using pyannote.audio and OpenVINO. pyannote.audio is an open-source toolkit written in Python for speaker diarization. Based on PyTorch deep learning framework, it provides a set of trainable end-to-end neural building blocks that can be combined and jointly optimized to build speaker diarization pipelines. You can find more information about pyannote pre-trained models in model card, repo and paper.
This tutorial uses the pyannote/speaker-diarization pipeline and demonstrates how to integrate OpenVINO for running model inference inside pipeline.
The pipeline accepts input audio file and provides mapping between timestamps and a speaker, to which the corresponding speech fragment belongs. Below is an example of output time map produced by the demo.

If you have not installed all required dependencies, follow the Installation Guide.