{kind=link}
{kind=link}
Zero-shot image classification is a computer vision task to classify images into one of several classes, without any prior training or knowledge of the classes.
In this tutorial, you will use OpenAI CLIP model to perform zero-shot image classification.
This tutorial demonstrates how to perform zero-shot image classification using the open-source CLIP model. CLIP is a multi-modal vision and language model. It can be instructed in natural language to predict the most relevant text snippet, given an image, without directly optimizing for the task. According to the paper, CLIP matches the performance of the original ResNet50 on ImageNet “zero-shot” without using any of the original 1.28M labeled examples, overcoming several major challenges in computer vision. You can find more information about this model in the research paper, OpenAI blog, model card and GitHub repository.
This folder contains two notebooks that show how to convert and quantize model with OpenVINO:
The first notebook contains the following steps:
- Download the model.
- Instantiate the PyTorch model.
- Convert model to OpenVINO IR, using the model conversion API.
- Run CLIP with OpenVINO.
The second notebook contains the following steps:
- Quantize the converted OpenVINO model from notebook with NNCF.
- Check the model result using the same input data from the first notebook.
- Compare model size of converted and quantized models.
- Compare performance of converted and quantized models.
NNCF performs quantization within the OpenVINO IR. It is required to run the first notebook before running the second notebook.
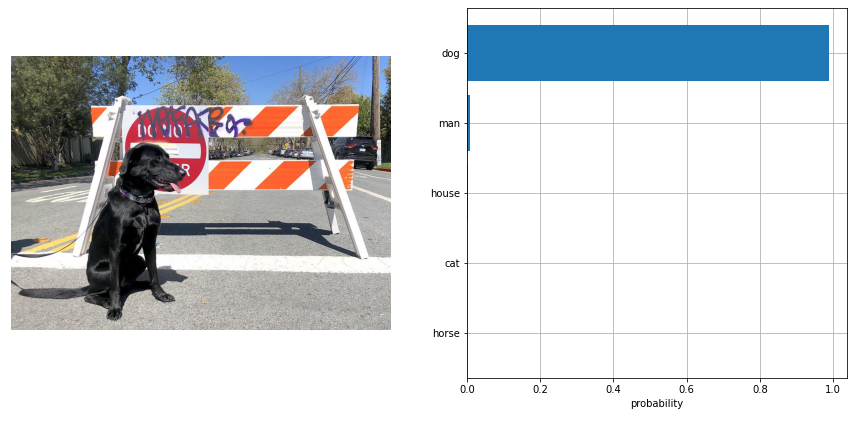
We will use CLIP model for zero-shot image classification. The result of model work demonstrated on the image below
If you have not installed all required dependencies, follow the Installation Guide.