In recent times, the AI community has witnessed a remarkable surge in the development of larger and more performant language models, such as Falcon 40B, LLaMa-2 70B, Falcon 40B, MPT 30B, and in the imaging domain with models like SD2.1 and SDXL. These advancements have undoubtedly pushed the boundaries of what AI can achieve, enabling highly versatile and state-of-the-art image generation and language understanding capabilities. However, the breakthrough of large models comes with substantial computational demands. To resolve this issue, recent research on efficient Stable Diffusion has prioritized reducing the number of sampling steps and utilizing network quantization.
Moving towards the goal of making image generative models faster, smaller, and cheaper, Tiny-SD was proposed by Segmind. Tiny SD is a compressed Stable Diffusion (SD) model that has been trained on Knowledge-Distillation (KD) techniques and the work has been largely based on this paper. The authors describe a Block-removal Knowledge-Distillation method where some of the UNet layers are removed and the student model weights are trained. Using the KD methods described in the paper, they were able to train two compressed models using the 🧨 diffusers library; Small and Tiny, that have 35% and 55% fewer parameters, respectively than the base model while achieving comparable image fidelity as the base model. More details about model can be found in model card, blog post and training repository.
This notebook demonstrates how to convert and run the Tiny-SD model using OpenVINO.
It considers two approaches of image generation using an AI method called diffusion:
Text-to-imagegeneration to create images from a text description as input.Text-guided Image-to-Imagegeneration to create an image, using text description and initial image semantic.
The complete pipeline of this demo is shown below.
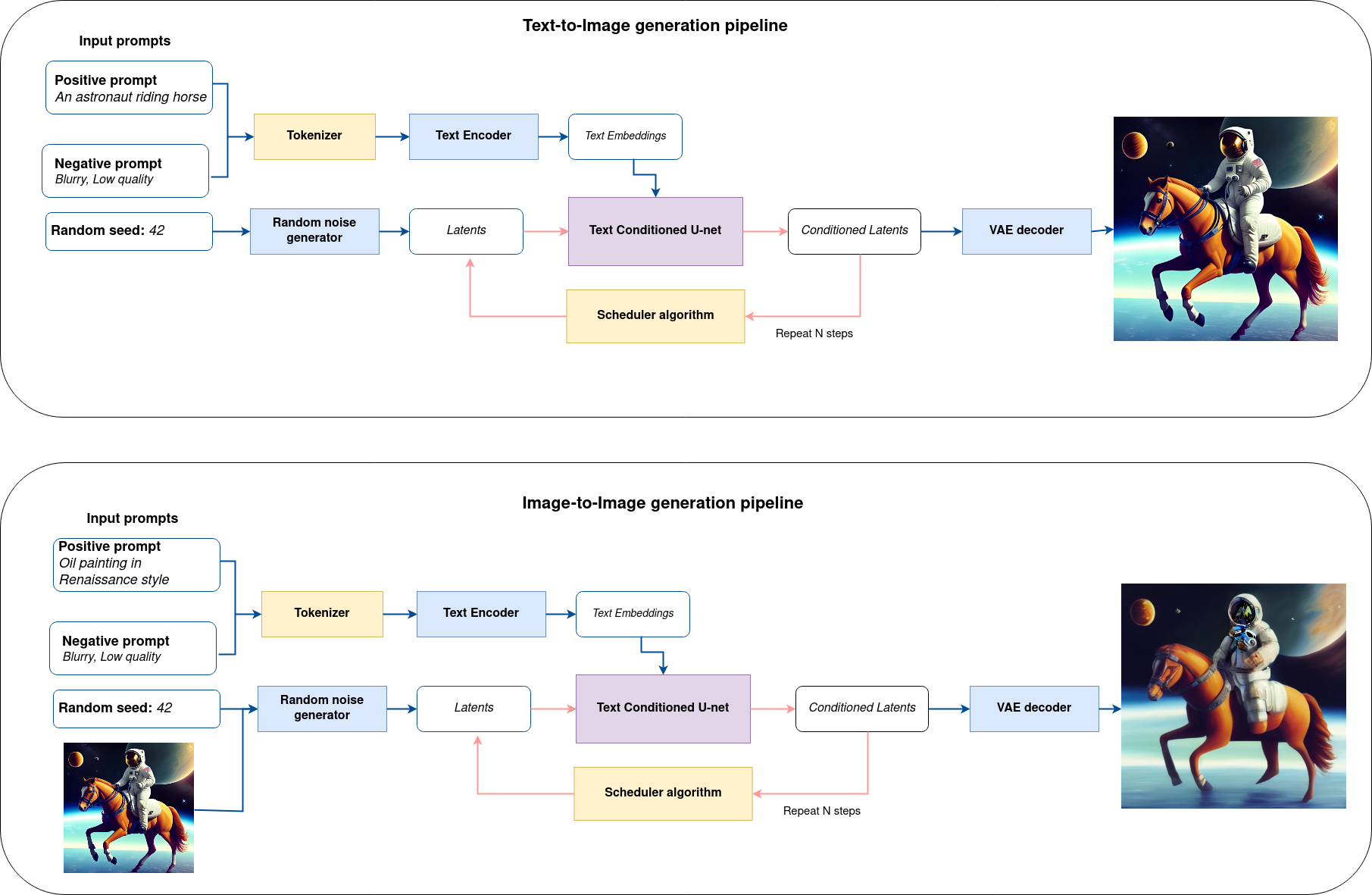
This is a demonstration in which you can type a text description (and provide input image in case of Image-to-Image generation) and the pipeline will generate an image that reflects the context of the input text. Step-by-step, the diffusion process will iteratively denoise latent image representation while being conditioned on the text embeddings provided by the text encoder.
The following image shows an example of the input sequence and corresponding predicted image.
Input text: RAW studio photo of An intricate forest minitown landscape trapped in a bottle, atmospheric oliva lighting, on the table, intricate details, dark shot, soothing tones, muted colors

This notebook demonstrates how to convert and run Tiny-SD using OpenVINO.
The notebook contains the following steps:
- Convert PyTorch models to OpenVINO Intermediate Representation using OpenVINO Converter Tool (OVC).
- Prepare Inference Pipeline.
- Run Inference pipeline with OpenVINO.
- Run Interactive demo for Tiny-SD model
The notebook also provides interactive interface for image generation based on user input (text prompts and source image, if required).
Text-to-Image Generation Example

Image-to-Image Generation Example

This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.
For details, please refer to Installation Guide.