There are a few concepts used in this proposal for IIIF Redux to format, organise, mutate and access data from IIIF resources.
IIIF and JSON-LD in general is built on the concept of resource types and the relations between them. In IIIF we have the basic types:
we have the basic types
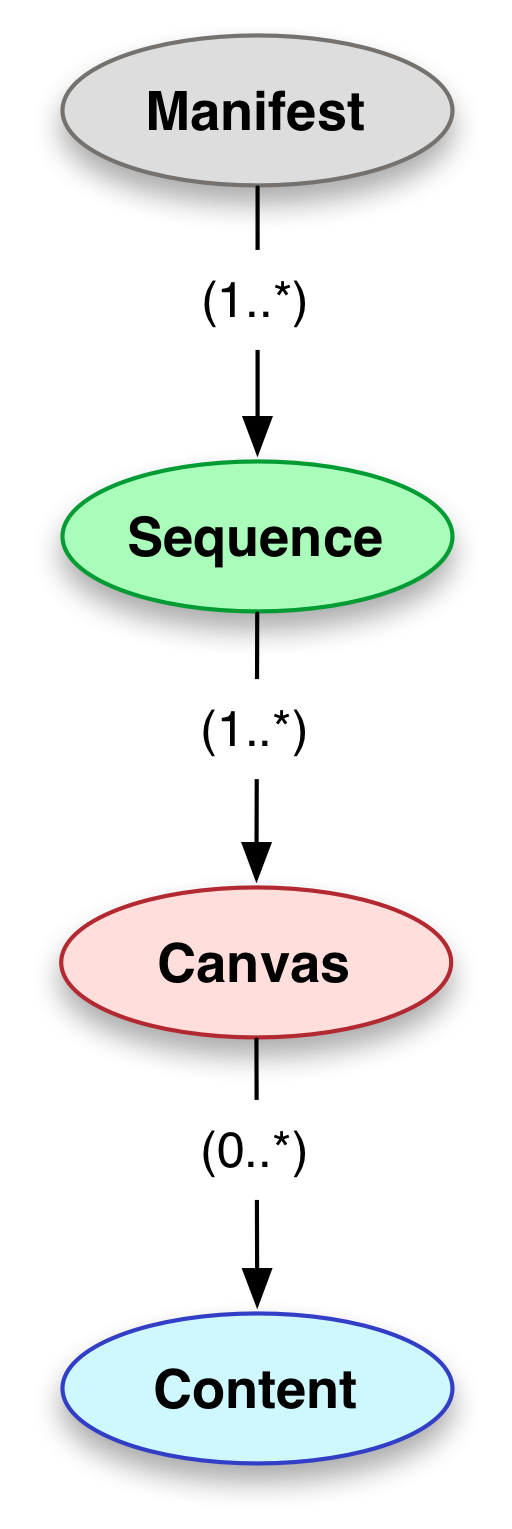
and the additional types
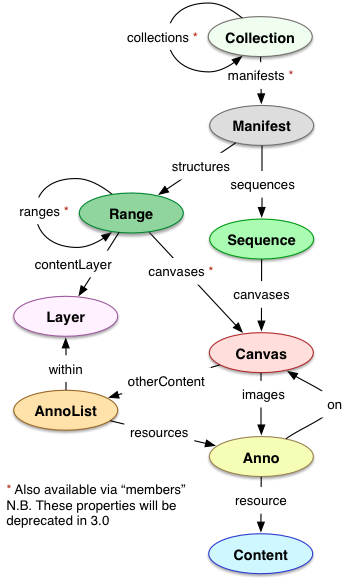
Each of these types are deeply nested and interconnected. In JSON-LD you can specify as much or as little information about a resource:
{
"@id": "http://foobar.com/test.json",
"@type": "foo"
}or
{
"@context": {"dc": "http://purl.org/dc/elements/1.1/"},
"@id": "http://foobar.com/test.json",
"@type": "foo",
"dc:title": "Some title field",
"dc:description": "Some description"
}They are the same resource, and sometimes when a field is referenced, we want to be able to show those extra fields. In IIIF ranges work much in this way:
{
"@id": "http://example.org/iiif/book1/range/r1",
"@type": "sc:Range",
"label": "Introduction",
"ranges": ["http://example.org/iiif/book1/range/r1-1"],
"canvases": [
"http://example.org/iiif/book1/canvas/p1",
"http://example.org/iiif/book1/canvas/p2",
"http://example.org/iiif/book1/canvas/p3#xywh=0,0,750,300"
]
}In an application, when you are representing a structure like this you will take the IDs here and look for them elsewhere
in the data structure, in this case in the manifest.sturctures and in the manifest.sequences[0..n].canvases. So when you
say I want all the canvas labels for a range, the process may be along the lines of:
- loop through all sequences
- loop through all canvases
- if one matches any of my ids store it
- return the list
This starts to get complicated when dealing with deeply nested structures, dereferenced resources that need to be fetched before they are available. For APIs using these resources they tend to re-map the data into maps as a cache, or use promises for some calls to wait for the data. This leads to duplicated data and inconsistent APIs.
IIIF Redux will hold a global state, which it wholly owns. Since data may be changing, or being added during the lifecycle of an application, we should aim to only store data once. This means one source of truth for resources, and one place to update if you need to edit content. The normalisation step breaks a graph-like structure of a IIIF document into the resource types that make it up.
For example, this simplified example of a IIIF Manifest:
{
"@context": "http://iiif.io/api/presentation/2/context.json",
"@id": "http://example.org/iiif/book1/manifest",
"@type": "sc:Manifest",
"sequences": [
{
"@id": "http://example.org/iiif/book1/sequence/normal",
"@type": "sc:Sequence",
"label": "Current Page Order",
"canvases": [
{
"@id": "http://example.org/iiif/book1/canvas/p1",
"@type": "sc:Canvas",
"label": "p. 1"
},
{
"@id": "http://example.org/iiif/book1/canvas/p2",
"@type": "sc:Canvas",
"label": "p. 2"
}
]
}
]
}Would be stored as:
{
"manifests": {
"http://example.org/iiif/book1/manifest": {
"@context": "http://iiif.io/api/presentation/2/context.json",
"@id": "http://example.org/iiif/book1/manifest",
"@type": "sc:Manifest",
"sequences": [
"http://example.org/iiif/book1/sequence/normal"
]
}
},
"sequences": {
"http://example.org/iiif/book1/sequence/normal": {
"@id": "http://example.org/iiif/book1/sequence/normal",
"@type": "sc:Sequence",
"label": "Current Page Order",
"canvases": [
"http://example.org/iiif/book1/canvas/p1",
"http://example.org/iiif/book1/canvas/p2"
]
}
},
"canvases": {
"http://example.org/iiif/book1/canvas/p1": {
"@id": "http://example.org/iiif/book1/canvas/p1",
"@type": "sc:Canvas",
"label": "p. 1"
},
"http://example.org/iiif/book1/canvas/p2": {
"@id": "http://example.org/iiif/book1/canvas/p2",
"@type": "sc:Canvas",
"label": "p. 2"
}
}
}This way of storing manifests has a few key benefits:
- scalable you can store as many manifests as you need in this data structure without caring about cross-talk
- quick to read reading data from this structure is very easy
- Getting the
nthcanvas on a manifestsequence.canvases[n] - Finding out what the index of a canvas is
sequence.canvases.indexOf(id) - Getting canvas by ID:
canvases[id]
- Getting the
- quick to write writing data can be tricky, but with ID maps for every item, this becomes trivial
- Setting a label
canvas[id].label = 'something else' - Resources can be created without being referenced anywhere, great for authoring tools + drafting workflows
- Setting a label
A few of the downsides too though:
- Getting deeply nested data can be difficult:
- Label of first canvas on a manifest
const firstSequence = state.manifest.sequences[0];
const firstCanvas = state.sequences[firstSequence].canvases[0];
const firstCanvasLabel = state.canvases[firstCanvas].label;- Iterating over all resources
- If you loaded 100 manifests, but not from a collection, you wouldn't have an array of IDs to iterate, only a map (slow)
To combat the first issue, we need a complete API for reading data from our store, to make it as accessible for applications.
I think a good rule of thumb for a new library would be to build to the most recent ratified specification. Currently this is Presentation 2, but later this year it is expected to be Presentation 3. The way this library should work is to store data that conforms to the latest Presentation specification, and convert on the way in.
If it is required that we export the state to a previous version of the presentation specification, that should be an external library or add-on that can process the state into that format. Effectively this library will double as a Presentation 2 to 3 converter once the spec is ratified.
Other external tooling possibilities:
- IIIF Validation across the state
- Manifest / Canvas Authoring tools
- External metadata comprehension, tooling + display
- External annotation comprehension, tooling + display (and authoring)
At the moment its unclear what the best approach for normalizing values, such as internationalised string should be. One option would be to normalize the data before we add it to the store. So for example:
{
"@id": "...",
"label": "some label",
"description": "some description"
}would be stored in state as:
{
"@id": "...",
"label": [{ "@language": "@none", "@value": "some label" }],
"description": [{ "@language": "@none", "@value": "some description" }]
}Similarly, for fields that can be Objects or arrays of objects, normalizing those into always be arrays.
The downsides to this approach would be the lossy nature of this, there's no way of knowing what the original manifest looked like. In addition, it would make editing existing manifests harder as this set of rules for normalizing would be reflected in the output.
The second option is to normalize on the way out, in the selectors themselves. Structurally this adds some overhead in the API, but the benefits (opposite of those mentioned above) seem to be worth it.
Some things need to be normalized on the way in, in a sort of expand for the state, and contract for the output. One example is when annotations target a specific region of a selector, this should be expanded out to make it easier to associate IDs in the original normalization step.
The very basics of a selector is a simple function that takes a big object, and returns a smaller object or a single value.
function getCurrentManifest(state) {
return state.currentManifest;
}
function getLabel(manifest) {
return manifest.label;
}They are pure by design so only have access to the parameters you put into them. This allows them to be optimised (see Memoization)
Selectors are usually either small chunks of logic to deal with potential logic of getting from big object to smaller object, which are then composed into other selectors to create new objects or models.
This library aims to use (Reselect)[https://github.com/reactjs/reselect] to compose selectors. For example, take our label examples above.
const getCurrentManifestLabel = createSelector(
getCurrentManifest,
function (manifest) {
return getLabel(manifest);
}
);Now we have a selector that we can run our entire state through to get the current manifest label:
const state = {
currentManifest: 'manifest1',
manifests: {
manifest1: {
label: 'foobar',
},
},
};
const label = getCurrentManifestLabel(state); // foobarWe can build up a library of these selectors, and since they are simple functions they are easy to test and easy to replace. Take for example, the upcoming Presentation 3 changes which changes the structure of the label field to use language maps (simplified example):
const getCurrentManifestLabel = createSelector(
getCurrentManifest,
getCurrentLocale,
function(manifest, locale) {
const label = getLabel(manifest);
if (label[locale]) {
return label[locale][0];
}
return label['@none'][0];
}
);We could go further and split out rationale of international strings too:
const getLocalisedString = function (localeMap) {
return createSelector(
getCurrentLocale,
function (locale) {
if (localeMap[locale]) {
return localeMap[locale][0];
}
return localeMap['@none'][0];
}
);
}So as this language handling is able to handle more logic, configuration etc. its benefits all components, much like creating helpers.
Lastly when you come to use these selectors you can build up a custom data structure from these selectors:
const myModel = createStructuredSelector({
label: getCurrentManifestLabel,
description: getCurrentManifestDescription,
metadata: getCurrentManifestMetadata,
thumbnails: getThumbnails(4, { width: 200 })
});An important aspect of reselect is how it caches results of the selectors based on the input. More information
So if we called:
getCurrentManifest(state);
getCurrentManifest(state);
getCurrentManifestLabel(state);
getCurrentManifestDescription(state);Since the state here never changes each of our selectors will only be called once, even though the last two are composed of the the first one.
For this to work, one of Redux's best practices should be followed: Immutable state
This ensures that oldState !== newState whenever anything changes in the tree.