OpenAI's CLIP model implementation
CLIP was one of the earliest vision language models that was widely adopted and paved the way for multimodal models evolution. Before CLIP, all computer vision based systems were built to classify some fixed set of categories. To use those systems in another domain required retraining/fine-tuning the model on a domain specific dataset. The key contribution by the CLIP was its ability to do zero-shot transfer to newer domains that highlighted CLIP's robustness against data distribution shift.
Paper: Learning Transferable Visual Models From Natural Language Supervision
CLIP achieves this by combining the language and vision into a single model architecture as shown in the image below.
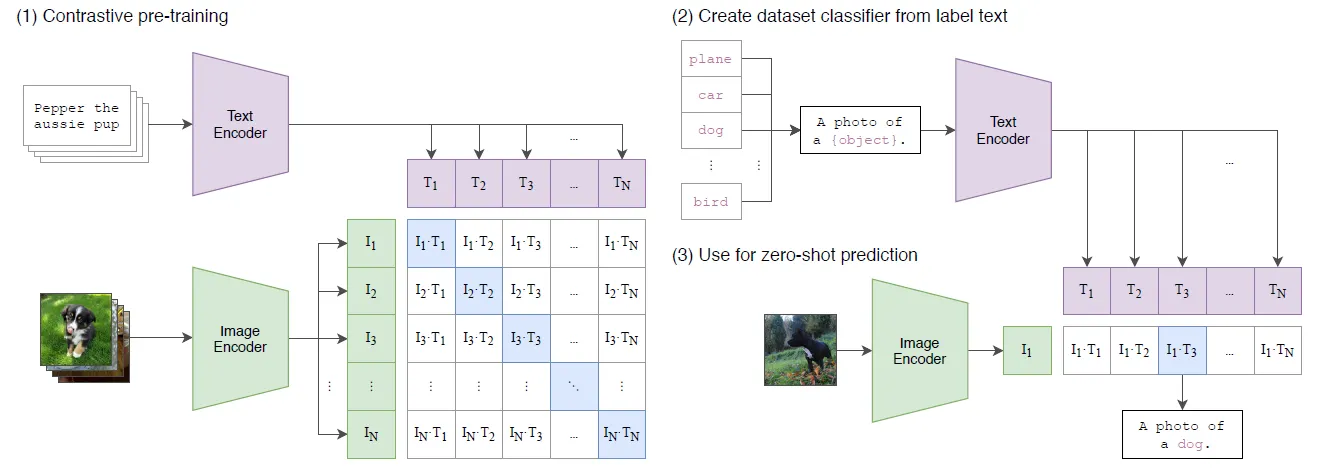
CLIP uses Image and Text encoders to learn correct representations for images and text respectively. These embeddings are jointly trained with the contrastive loss strategy to maximize the cosine similarity between the relevant <image, text> pairs and minimize the same between irrelevant pairs.
Below is the Pseudocode describing the high-level working of CLIP:

-
Image Encoder - While the paper describes experiments with Resnet and ViT family of models, in our implementation we have used ViT (Vision Transformer as Image Encoder)
-
Text Encoder - Standard BERT like transformer encoder is used for text encoding (unlike BERT, CLIP's text encoder uses causal mask in its self attention mechanism).
-
We initialize the weights of our model with the pre-trained weights from huggingface.
-
The implementation doesn't include the training loop, and hence could only be used for inference.
-
To confirm the correctness of the implementation, it contains
validate.pyto test the implementation against the CLIP as implemented by HuggingFace's transformer library.