Combine RNN and the attention mechanism into variational autoencoder to generate images.
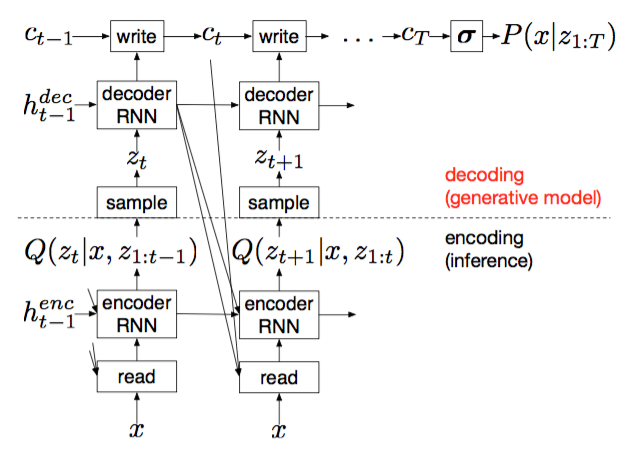
For each time step:
-
Suppose x is the input image, first use read in attention mechanism to choose which patch of the image should be input into the Encoder RNN.
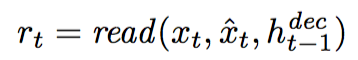
-
The Encoder RNN emits hidden state h_enc
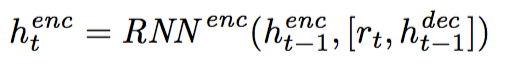
-
Use h_enc to generate parameters of distribution Q(z) ~ N(z|mu,sigma) ans sample z:
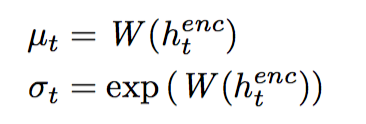
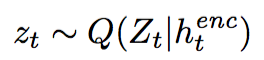
-
Input sampled z into the Decoder RNN to get h_dec
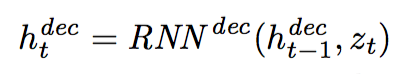
-
Input h_dec into write in attention mechanism and add output to the canvas c_t.
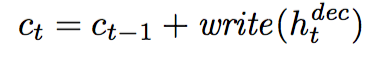
-
Use the canvas from the last time step T to generate paramters of the distribution of pixels: D(x|c_T), here this distribution is Bernoulli, so sigmoid(c_T) is the mean of this distribution.
In this case, the input is just the whole image, and the output of the Decoder RNN modifies the whole canvas at each time step.
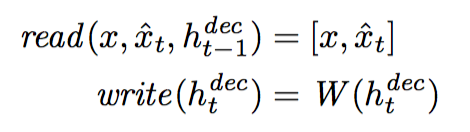
In this case, the author impose a N*N grid of Gaussian filters on top of the image, and get parameters of these Gaussian filters from the hidden state of the Decoder RNN: Then use these Gaussian filters to choose which part of the image being input into the Encoder RNN and which part of canvas is modified.
- Generate paramters of the Gaussian filters:
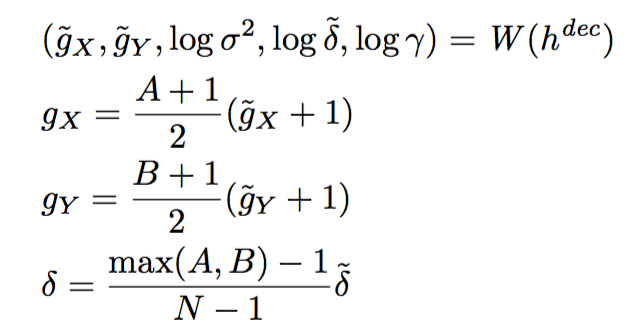
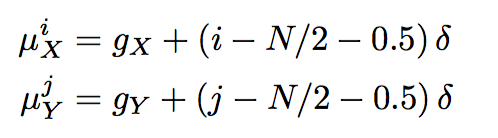
- Then the Gaussian filters can be written as:
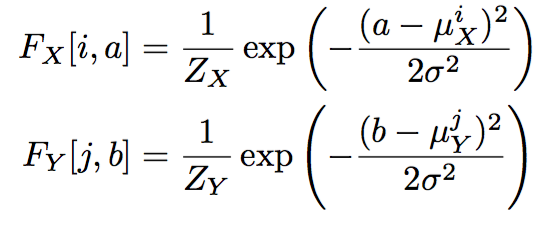
- Thus, we have read and write equations like this:
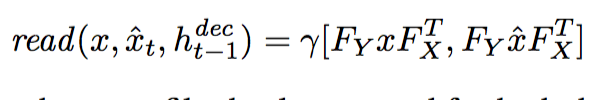
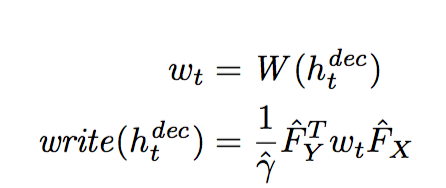
The Loss function is the same as Variational Autoencoder. It also consists of two parts: the reconstruction error and the regularization error.
Assuming z~N(0,1), then the regularization error is the same as the one in VAE:
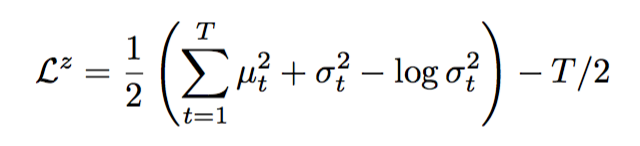
The reconstruction error is the negative log probability of x under Bernoulli distribution, whose mean is given by sigmoid(c_T):
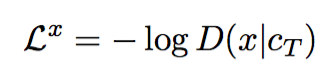
Gregor K, Danihelka I, Graves A, et al. DRAW: A recurrent neural network for image generation[J]. arXiv preprint arXiv:1502.04623, 2015.