Use fully convolutional neural network (FCN) to predict semantic segmentation of images.
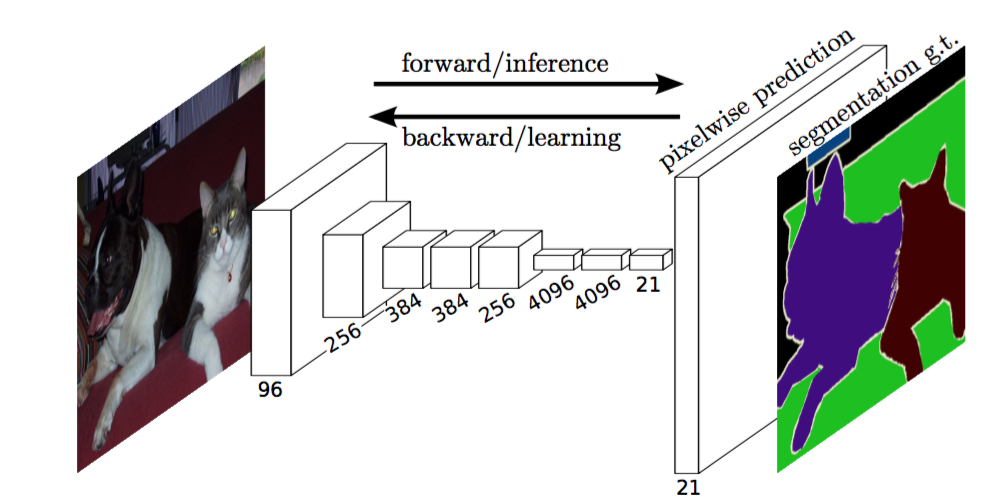
The whole network is an end-to-end convolutional neural network. Its input is a color image, and output is the semantic segmentation prediction of input. There are two novel points:
- The network only contains convolutional layer, all fully connected layers are interpreted as convolutional layers. This perspective brings 3 advantages:
- By getting rid of fully connected layers, the network can take images of any size as inputs rather than fix-sized images.
- Convolution is more time efficient than fully connected layers.
- Convolution keeps spatial structure of the images.
- The network fuses feature maps from different layers to generate final semantic segmentation. The lower layers of NNs capture the local structure of images while the higher layers of NNs capture the high level (semantic) structure of images. Fusing these two together helps to produce finer segmentation predictions which also respect high level semantic structure of the image.
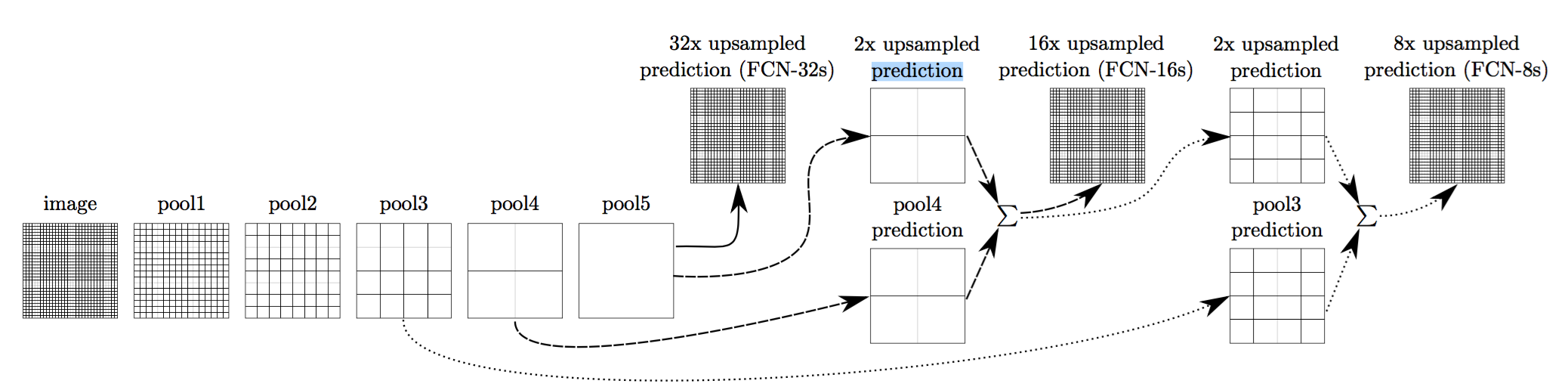
- Fully connected layers can be viewed as special convolution layers.
- Fusing feature maps from earlier layers help to capture local structure of images.
Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 3431-3440.