This is a milestone paper in utilizing Convolutional Neural Networks into object detections. It uses Selective Search to generate region proposals, uses CNN to extract region features and then uses SVM and linear regression to classify regions as well as fine-tune bounding boxes.
- Improve mAP by more than 30% relative to the previous best result on VOC 2012 by achieving 53.3%
- More efficient compared to sliding window methods
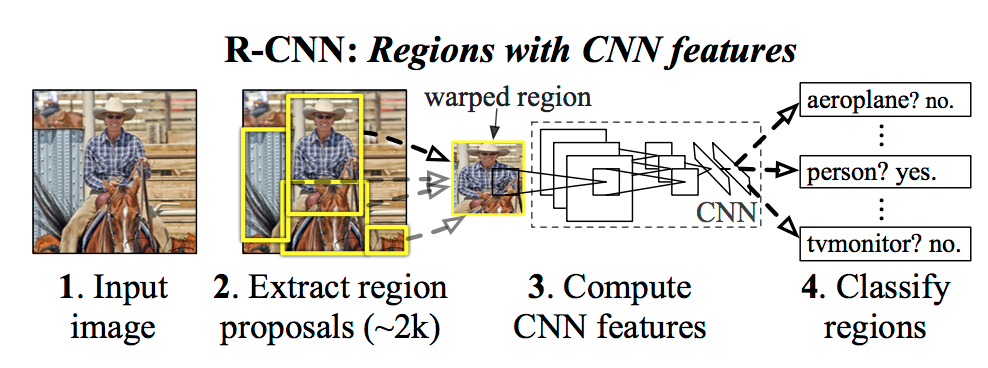
- Fine-tuning the network trained on ImageNet with PascalVOC dataset.
- Using Selective Search to generate 2k region proposals;
- Using CNN to extract feature for each region;
- Train SVM on these features to do classification;
- Using linear regression to fine-tune the positions of bounding boxes.
- This paper shows the power of features extracted by CNN;
- Region proposal methods such as Selective Search can be used to reduce regions that need to be considered, thus it's more efficient than algorithms based on sliding windows.
- An interesting point in this paper is that it does comparisons on fine-tuning and not fine-tuning. Without fine-tuning, features from pool5 perform as well as features from fc6 or fc7, that means the CNN can extract good feature with only 6% of its paramters! However, with fine-tuning, features from fc6 and fc7 perform much better than pool5. The conclusion is that pool5 gives general feature learned to represent images while fc6 or fc7 features are more domain specific.
- Bounding box regression might be a good way to solve high localization error problem.
- Too slow, use CNN to draw features for each region, takes nearly 40s per image.
- The algorithms composes three disjoint parts, which are not able to train jointly.
Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.