diff --git a/docs/sphinx/source/examples/Matryoshka_embeddings_in_Vespa-cloud.ipynb b/docs/sphinx/source/examples/Matryoshka_embeddings_in_Vespa-cloud.ipynb
index 4e55b04e..e1273ea2 100644
--- a/docs/sphinx/source/examples/Matryoshka_embeddings_in_Vespa-cloud.ipynb
+++ b/docs/sphinx/source/examples/Matryoshka_embeddings_in_Vespa-cloud.ipynb
@@ -23,6 +23,8 @@
"\n",
"We'll use a standard information retrieval benchmark to evaluate result quality with different embedding sizes and retrieval/ranking strategies.\n",
"\n",
+ "[](https://colab.research.google.com/github/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/Matryoshka_embeddings_in_Vespa-cloud.ipynb)\n",
+ "\n",
"Let's get started! First, install a few dependencies:\n"
]
},
@@ -35,7 +37,7 @@
},
"outputs": [],
"source": [
- "!pip3 install -U pyvespa ir_datasets openai pytrec_eval"
+ "!pip3 install -U pyvespa ir_datasets openai pytrec_eval vespacli"
]
},
{
@@ -535,210 +537,13 @@
"## Deploy the application to Vespa Cloud\n",
"\n",
"With the configured application, we can deploy it to [Vespa Cloud](https://cloud.vespa.ai/en/).\n",
- "It is also possible to deploy the app using docker; see the [Hybrid Search - Quickstart](https://pyvespa.readthedocs.io/en/latest/getting-started-pyvespa.html) guide for\n",
- "an example of deploying it to a local docker container.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "59bbdb311c014d738909a11f9e486628",
- "metadata": {
- "id": "16179d9b"
- },
- "source": [
- "Install the Vespa CLI.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "b43b363d81ae4b689946ece5c682cd59",
- "metadata": {
- "id": "343981ce"
- },
- "outputs": [],
- "source": [
- "!pip3 install vespacli"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "4dd4641cc4064e0191573fe9c69df29b",
- "metadata": {
- "id": "0ff00727"
- },
- "source": [
+ "\n",
"To deploy the application to Vespa Cloud we need to create a tenant in the Vespa Cloud:\n",
"\n",
"Create a tenant at [console.vespa-cloud.com](https://console.vespa-cloud.com/) (unless you already have one).\n",
"This step requires a Google or GitHub account, and will start your [free trial](https://cloud.vespa.ai/en/free-trial).\n",
- "Make note of the tenant name, it is used in the next steps.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "8309879909854d7188b41380fd92a7c3",
- "metadata": {
- "id": "df9f9a1c"
- },
- "source": [
- "### Configure Vespa Cloud date-plane security\n",
- "\n",
- "Create Vespa Cloud data-plane mTLS cert/key-pair. The mutual certificate pair is used to talk to your Vespa cloud endpoints. See [Vespa Cloud Security Guide](https://cloud.vespa.ai/en/security/guide) for details.\n",
- "\n",
- "We save the paths to the credentials for later data-plane access without using pyvespa APIs.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "3ed186c9a28b402fb0bc4494df01f08d",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "executionInfo": {
- "elapsed": 611,
- "status": "ok",
- "timestamp": 1706648115118,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "b6a766d6",
- "outputId": "47075852-89e2-41a8-cb96-af10dbe534d7"
- },
- "outputs": [],
- "source": [
- "import os\n",
- "\n",
- "os.environ[\"TENANT_NAME\"] = \"vespa-team\" # Replace with your tenant name\n",
- "\n",
- "vespa_cli_command = (\n",
- " f'vespa config set application {os.environ[\"TENANT_NAME\"]}.{vespa_app_name}'\n",
- ")\n",
- "\n",
- "!vespa config set target cloud\n",
- "!{vespa_cli_command}\n",
- "!vespa auth cert -N"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "cb1e1581032b452c9409d6c6813c49d1",
- "metadata": {
- "id": "b228381b"
- },
- "source": [
- "Validate that we have the expected data-plane credential files:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 25,
- "id": "379cbbc1e968416e875cc15c1202d7eb",
- "metadata": {
- "executionInfo": {
- "elapsed": 241,
- "status": "ok",
- "timestamp": 1706648119995,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "1f0b97c8"
- },
- "outputs": [],
- "source": [
- "from os.path import exists\n",
- "from pathlib import Path\n",
"\n",
- "cert_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-public-cert.pem\"\n",
- ")\n",
- "key_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-private-key.pem\"\n",
- ")\n",
- "\n",
- "if not exists(cert_path) or not exists(key_path):\n",
- " print(\n",
- " \"ERROR: set the correct paths to security credentials. Correct paths above and rerun until you do not see this error\"\n",
- " )"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "277c27b1587741f2af2001be3712ef0d",
- "metadata": {
- "id": "85ce80e0"
- },
- "source": [
- "Note that the subsequent Vespa Cloud deploy call below will add `data-plane-public-cert.pem` to the application before deploying it to Vespa Cloud, so that\n",
- "you have access to both the private key and the public certificate. At the same time, Vespa Cloud only knows the public certificate.\n",
- "\n",
- "### Configure Vespa Cloud control-plane security\n",
- "\n",
- "Authenticate to generate a tenant level control plane API key for deploying the applications to Vespa Cloud, and save the path to it.\n",
- "\n",
- "The generated tenant api key must be added in the Vespa Console before attempting to deploy the application.\n",
- "\n",
- "```\n",
- "To use this key in Vespa Cloud click 'Add custom key' at\n",
- "https://console.vespa-cloud.com/tenant/TENANT_NAME/account/keys\n",
- "and paste the entire public key including the BEGIN and END lines.\n",
- "```\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 26,
- "id": "db7b79bc585a40fcaf58bf750017e135",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "executionInfo": {
- "elapsed": 244,
- "status": "ok",
- "timestamp": 1706648129288,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "5bf8731c",
- "outputId": "5f615d4c-9469-4be8-c8fe-9d0fc9dab4f6"
- },
- "outputs": [],
- "source": [
- "!vespa auth api-key\n",
- "\n",
- "from pathlib import Path\n",
- "\n",
- "api_key_path = Path.home() / \".vespa\" / f\"{os.environ['TENANT_NAME']}.api-key.pem\""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "916684f9a58a4a2aa5f864670399430d",
- "metadata": {
- "id": "21db1010"
- },
- "source": [
- "### Deploy to Vespa Cloud\n",
- "\n",
- "Now that we have data-plane and control-plane credentials ready, we can deploy our application to Vespa Cloud!\n",
- "\n",
- "`PyVespa` supports deploying apps to the [development zone](https://cloud.vespa.ai/en/reference/environments#dev-and-perf).\n",
+ "Make note of the tenant name, it is used in the next steps.\n",
"\n",
"> Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.\n"
]
@@ -763,23 +568,20 @@
"outputs": [],
"source": [
"from vespa.deployment import VespaCloud\n",
+ "import os\n",
"\n",
+ "# Replace with your tenant name from the Vespa Cloud Console\n",
+ "tenant_name = \"vespa-team\"\n",
"\n",
- "def read_secret():\n",
- " \"\"\"Read the API key from the environment variable. This is\n",
- " only used for CI/CD purposes.\"\"\"\n",
- " t = os.getenv(\"VESPA_TEAM_API_KEY\")\n",
- " if t:\n",
- " return t.replace(r\"\\n\", \"\\n\")\n",
- " else:\n",
- " return t\n",
- "\n",
+ "# Key is only used for CI/CD. Can be removed if logging in interactively\n",
+ "key = os.getenv(\"VESPA_TEAM_API_KEY\", None)\n",
+ "if key is not None:\n",
+ " key = key.replace(r\"\\n\", \"\\n\") # To parse key correctly\n",
"\n",
"vespa_cloud = VespaCloud(\n",
- " tenant=os.environ[\"TENANT_NAME\"],\n",
+ " tenant=tenant_name,\n",
" application=vespa_app_name,\n",
- " key_content=read_secret() if read_secret() else None,\n",
- " key_location=api_key_path,\n",
+ " key_content=key, # Key is only used for CI/CD. Can be removed if logging in interactively\n",
" application_package=vespa_application_package,\n",
")"
]
diff --git a/docs/sphinx/source/examples/billion-scale-vector-search-with-cohere-embeddings-cloud.ipynb b/docs/sphinx/source/examples/billion-scale-vector-search-with-cohere-embeddings-cloud.ipynb
index d370bc4d..d80efa1f 100644
--- a/docs/sphinx/source/examples/billion-scale-vector-search-with-cohere-embeddings-cloud.ipynb
+++ b/docs/sphinx/source/examples/billion-scale-vector-search-with-cohere-embeddings-cloud.ipynb
@@ -51,6 +51,8 @@
"- Re-rank by using a dot product between the float version of the query vector (1024 dims) against an unpacked float version of the binary embedding (also 1024 dims)\n",
"- A re-ranking phase using the 1024 dimensional int8 representations. This stage pages the vector data from the disk using Vespa's [paged](https://docs.vespa.ai/en/attributes.html#paged-attributes) option (unless it is already cached).\n",
"\n",
+ "[](https://colab.research.google.com/github/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/billion-scale-vector-search-with-cohere-embeddings-cloud.ipynb)\n",
+ "\n",
"Install the dependencies:\n"
]
},
@@ -63,7 +65,7 @@
},
"outputs": [],
"source": [
- "!pip3 install -U pyvespa cohere==4.57"
+ "!pip3 install -U pyvespa cohere==4.57 vespacli"
]
},
{
@@ -370,210 +372,13 @@
"## Deploy the application to Vespa Cloud\n",
"\n",
"With the configured application, we can deploy it to [Vespa Cloud](https://cloud.vespa.ai/en/).\n",
- "It is also possible to deploy the app using docker; see the [Hybrid Search - Quickstart](https://pyvespa.readthedocs.io/en/latest/getting-started-pyvespa.html) guide for\n",
- "an example of deploying it to a local docker container.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "cf82b02d",
- "metadata": {
- "id": "16179d9b"
- },
- "source": [
- "Install the [Vespa CLI](https://docs.vespa.ai/en/vespa-cli) from [PyPI](https://pypi.org/project/vespacli/):\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "1f1337cf",
- "metadata": {
- "id": "343981ce"
- },
- "outputs": [],
- "source": [
- "!pip3 install vespacli"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "b996a9d7",
- "metadata": {
- "id": "0ff00727"
- },
- "source": [
+ "\n",
"To deploy the application to Vespa Cloud we need to create a tenant in the Vespa Cloud:\n",
"\n",
"Create a tenant at [console.vespa-cloud.com](https://console.vespa-cloud.com/) (unless you already have one).\n",
"This step requires a Google or GitHub account, and will start your [free trial](https://cloud.vespa.ai/en/free-trial).\n",
- "Make note of the tenant name, it is used in the next steps.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "8b1d2950",
- "metadata": {
- "id": "df9f9a1c"
- },
- "source": [
- "### Configure Vespa Cloud date-plane security\n",
"\n",
- "Create Vespa Cloud data-plane mTLS cert/key-pair. The mutual certificate pair is used to talk to your Vespa cloud endpoints. See [Vespa Cloud Security Guide](https://cloud.vespa.ai/en/security/guide) for details.\n",
- "\n",
- "We save the paths to the credentials for later data-plane access without using pyvespa APIs.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "b9d9545c",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "executionInfo": {
- "elapsed": 611,
- "status": "ok",
- "timestamp": 1706648115118,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "b6a766d6",
- "outputId": "47075852-89e2-41a8-cb96-af10dbe534d7"
- },
- "outputs": [],
- "source": [
- "import os\n",
- "\n",
- "os.environ[\"TENANT_NAME\"] = \"vespa-team\" # Replace with your tenant name\n",
- "\n",
- "vespa_cli_command = (\n",
- " f'vespa config set application {os.environ[\"TENANT_NAME\"]}.{vespa_app_name}'\n",
- ")\n",
- "\n",
- "!vespa config set target cloud\n",
- "!{vespa_cli_command}\n",
- "!vespa auth cert -N"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "e10487bd",
- "metadata": {
- "id": "b228381b"
- },
- "source": [
- "Validate that we have the expected data-plane credential files:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 16,
- "id": "70abcc3b",
- "metadata": {
- "executionInfo": {
- "elapsed": 241,
- "status": "ok",
- "timestamp": 1706648119995,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "1f0b97c8"
- },
- "outputs": [],
- "source": [
- "from os.path import exists\n",
- "from pathlib import Path\n",
- "\n",
- "cert_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-public-cert.pem\"\n",
- ")\n",
- "key_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-private-key.pem\"\n",
- ")\n",
- "\n",
- "if not exists(cert_path) or not exists(key_path):\n",
- " print(\n",
- " \"ERROR: set the correct paths to security credentials. Correct paths above and rerun until you do not see this error\"\n",
- " )"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "fd7b4049",
- "metadata": {
- "id": "85ce80e0"
- },
- "source": [
- "Note that the subsequent Vespa Cloud deploy call below will add `data-plane-public-cert.pem` to the application before deploying it to Vespa Cloud, so that\n",
- "you have access to both the private key and the public certificate. At the same time, Vespa Cloud only knows the public certificate.\n",
- "\n",
- "### Configure Vespa Cloud control-plane security\n",
- "\n",
- "Authenticate to generate a tenant level control plane API key for deploying the applications to Vespa Cloud, and save the path to it.\n",
- "\n",
- "The generated tenant api key must be added in the Vespa Console before attempting to deploy the application.\n",
- "\n",
- "```\n",
- "To use this key in Vespa Cloud click 'Add custom key' at\n",
- "https://console.vespa-cloud.com/tenant/TENANT_NAME/account/keys\n",
- "and paste the entire public key including the BEGIN and END lines.\n",
- "```\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "e4de9e4e",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "executionInfo": {
- "elapsed": 244,
- "status": "ok",
- "timestamp": 1706648129288,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "5bf8731c",
- "outputId": "5f615d4c-9469-4be8-c8fe-9d0fc9dab4f6"
- },
- "outputs": [],
- "source": [
- "!vespa auth api-key\n",
- "\n",
- "from pathlib import Path\n",
- "\n",
- "api_key_path = Path.home() / \".vespa\" / f\"{os.environ['TENANT_NAME']}.api-key.pem\""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "52fe7b5d",
- "metadata": {
- "id": "21db1010"
- },
- "source": [
- "### Deploy to Vespa Cloud\n",
- "\n",
- "Now that we have data-plane and control-plane credentials ready, we can deploy our application to Vespa Cloud!\n",
- "\n",
- "`PyVespa` supports deploying apps to the [development zone](https://cloud.vespa.ai/en/reference/environments#dev-and-perf).\n",
+ "Make note of the tenant name, it is used in the next steps.\n",
"\n",
"> Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.\n"
]
@@ -598,23 +403,20 @@
"outputs": [],
"source": [
"from vespa.deployment import VespaCloud\n",
+ "import os\n",
"\n",
+ "# Replace with your tenant name from the Vespa Cloud Console\n",
+ "tenant_name = \"vespa-team\"\n",
"\n",
- "def read_secret():\n",
- " \"\"\"Read the API key from the environment variable. This is\n",
- " only used for CI/CD purposes.\"\"\"\n",
- " t = os.getenv(\"VESPA_TEAM_API_KEY\")\n",
- " if t:\n",
- " return t.replace(r\"\\n\", \"\\n\")\n",
- " else:\n",
- " return t\n",
- "\n",
+ "# Key is only used for CI/CD. Can be removed if logging in interactively\n",
+ "key = os.getenv(\"VESPA_TEAM_API_KEY\", None)\n",
+ "if key is not None:\n",
+ " key = key.replace(r\"\\n\", \"\\n\") # To parse key correctly\n",
"\n",
"vespa_cloud = VespaCloud(\n",
- " tenant=os.environ[\"TENANT_NAME\"],\n",
+ " tenant=tenant_name,\n",
" application=vespa_app_name,\n",
- " key_content=read_secret() if read_secret() else None,\n",
- " key_location=api_key_path,\n",
+ " key_content=key, # Key is only used for CI/CD. Can be removed if logging in interactively\n",
" application_package=vespa_application_package,\n",
")"
]
diff --git a/docs/sphinx/source/examples/chat_with_your_pdfs_using_colbert_langchain_and_Vespa-cloud.ipynb b/docs/sphinx/source/examples/chat_with_your_pdfs_using_colbert_langchain_and_Vespa-cloud.ipynb
index 21615408..f75caafe 100644
--- a/docs/sphinx/source/examples/chat_with_your_pdfs_using_colbert_langchain_and_Vespa-cloud.ipynb
+++ b/docs/sphinx/source/examples/chat_with_your_pdfs_using_colbert_langchain_and_Vespa-cloud.ipynb
@@ -56,6 +56,8 @@
"\n",
"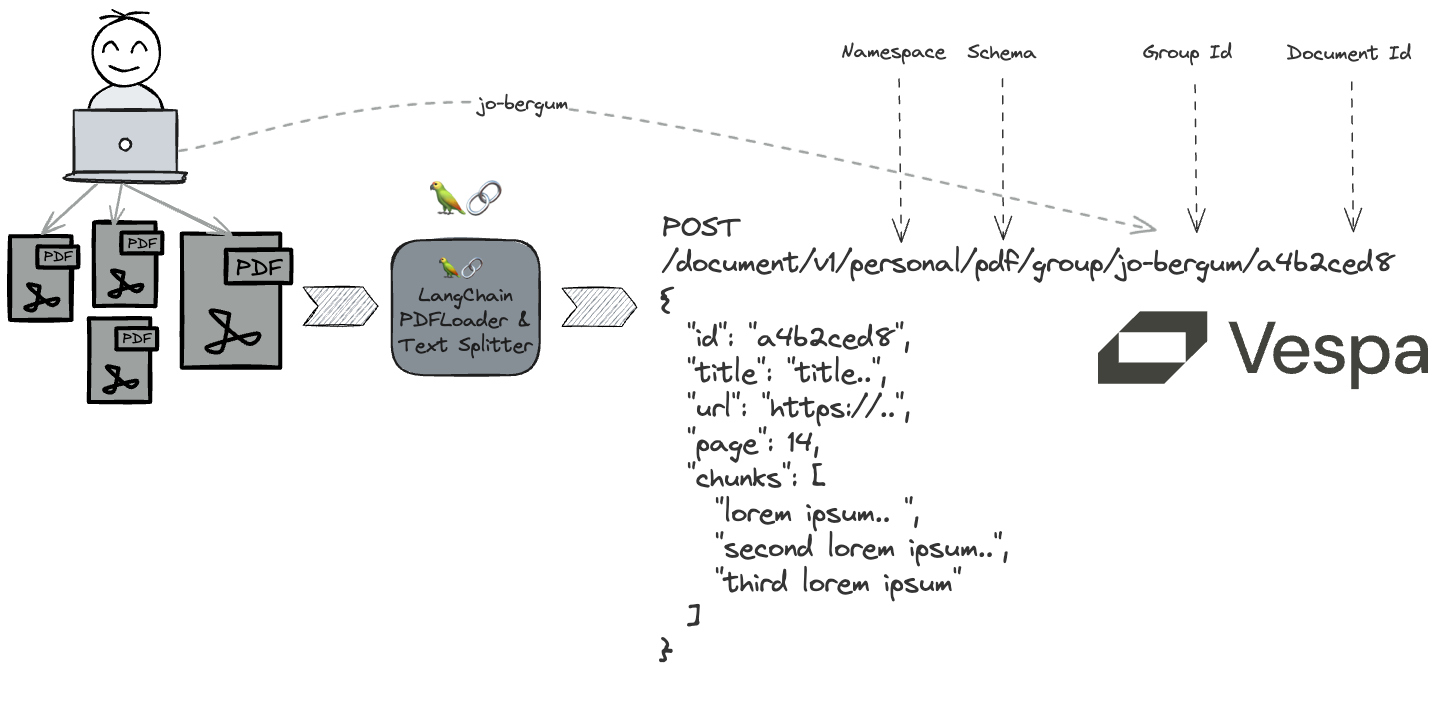\n",
"\n",
+ "[](https://colab.research.google.com/github/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/chat_with_your_pdfs_using_colbert_langchain_and_Vespa-cloud.ipynb)\n",
+ "\n",
"Let's get started! First, install dependencies:\n"
]
},
@@ -68,7 +70,7 @@
},
"outputs": [],
"source": [
- "!pip3 install -U pyvespa langchain langchain-community langchain-openai pypdf openai"
+ "!pip3 install -U pyvespa langchain langchain-community langchain-openai pypdf openai vespacli"
]
},
{
@@ -365,187 +367,20 @@
"## Deploy the application to Vespa Cloud\n",
"\n",
"With the configured application, we can deploy it to [Vespa Cloud](https://cloud.vespa.ai/en/).\n",
- "It is also possible to deploy the app using docker; see the [Hybrid Search - Quickstart](https://pyvespa.readthedocs.io/en/latest/getting-started-pyvespa.html) guide for\n",
- "an example of deploying it to a local docker container.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "16179d9b",
- "metadata": {
- "id": "16179d9b"
- },
- "source": [
- "Install the Vespa CLI\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "343981ce",
- "metadata": {
- "id": "343981ce"
- },
- "outputs": [],
- "source": [
- "!pip3 install vespacli"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "0ff00727",
- "metadata": {
- "id": "0ff00727"
- },
- "source": [
+ "\n",
"To deploy the application to Vespa Cloud we need to create a tenant in the Vespa Cloud:\n",
"\n",
"Create a tenant at [console.vespa-cloud.com](https://console.vespa-cloud.com/) (unless you already have one).\n",
"This step requires a Google or GitHub account, and will start your [free trial](https://cloud.vespa.ai/en/free-trial).\n",
- "Make note of the tenant name, it is used in the next steps.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "df9f9a1c",
- "metadata": {
- "id": "df9f9a1c"
- },
- "source": [
- "### Configure Vespa Cloud date-plane security\n",
- "\n",
- "Create Vespa Cloud data-plane mTLS cert/key-pair. The mutual certificate pair is used to talk to your Vespa cloud endpoints. See [Vespa Cloud Security Guide](https://cloud.vespa.ai/en/security/guide) for details.\n",
- "\n",
- "We save the paths to the credentials for later data-plane access without using pyvespa APIs.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "b6a766d6",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "b6a766d6",
- "outputId": "9f05ce4d-378a-4abf-cefe-d8dd2580b25a"
- },
- "outputs": [],
- "source": [
- "import os\n",
- "\n",
- "os.environ[\"TENANT_NAME\"] = \"vespa-team\" # Replace with your tenant name\n",
- "\n",
- "vespa_cli_command = (\n",
- " f'vespa config set application {os.environ[\"TENANT_NAME\"]}.{vespa_app_name}'\n",
- ")\n",
- "\n",
- "!vespa config set target cloud\n",
- "!{vespa_cli_command}\n",
- "!vespa auth cert -N"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "b228381b",
- "metadata": {
- "id": "b228381b"
- },
- "source": [
- "Validate that we have the expected data-plane credential files:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 9,
- "id": "1f0b97c8",
- "metadata": {
- "id": "1f0b97c8"
- },
- "outputs": [],
- "source": [
- "from os.path import exists\n",
- "from pathlib import Path\n",
"\n",
- "cert_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-public-cert.pem\"\n",
- ")\n",
- "key_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-private-key.pem\"\n",
- ")\n",
- "\n",
- "if not exists(cert_path) or not exists(key_path):\n",
- " print(\n",
- " \"ERROR: set the correct paths to security credentials. Correct paths above and rerun until you do not see this error\"\n",
- " )"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "85ce80e0",
- "metadata": {
- "id": "85ce80e0"
- },
- "source": [
- "Note that the subsequent Vespa Cloud deploy call below will add `data-plane-public-cert.pem` to the application before deploying it to Vespa Cloud, so that\n",
- "you have access to both the private key and the public certificate. At the same time, Vespa Cloud only knows the public certificate.\n",
- "\n",
- "### Configure Vespa Cloud control-plane security\n",
- "\n",
- "Authenticate to generate a tenant level control plane API key for deploying the applications to Vespa Cloud, and save the path to it.\n",
- "\n",
- "The generated tenant api key must be added in the Vespa Console before attempting to deploy the application.\n",
- "\n",
- "```\n",
- "To use this key in Vespa Cloud click 'Add custom key' at\n",
- "https://console.vespa-cloud.com/tenant/TENANT_NAME/account/keys\n",
- "and paste the entire public key including the BEGIN and END lines.\n",
- "```\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "5bf8731c",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "5bf8731c",
- "outputId": "12765e29-1060-43f7-bd77-ff13d72835ed"
- },
- "outputs": [],
- "source": [
- "!vespa auth api-key\n",
- "\n",
- "from pathlib import Path\n",
- "\n",
- "api_key_path = Path.home() / \".vespa\" / f\"{os.environ['TENANT_NAME']}.api-key.pem\""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "21db1010",
- "metadata": {
- "id": "21db1010"
- },
- "source": [
- "### Deploy to Vespa Cloud\n",
- "\n",
- "Now that we have data-plane and control-plane credentials ready, we can deploy our application to Vespa Cloud!\n",
- "\n",
- "`PyVespa` supports deploying apps to the [development zone](https://cloud.vespa.ai/en/reference/environments#dev-and-perf).\n",
+ "Make note of the tenant name, it is used in the next steps.\n",
"\n",
"> Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.\n"
]
},
{
"cell_type": "code",
- "execution_count": 11,
+ "execution_count": null,
"id": "b5fddf9f",
"metadata": {
"id": "b5fddf9f"
@@ -553,23 +388,20 @@
"outputs": [],
"source": [
"from vespa.deployment import VespaCloud\n",
+ "import os\n",
"\n",
+ "# Replace with your tenant name from the Vespa Cloud Console\n",
+ "tenant_name = \"vespa-team\"\n",
"\n",
- "def read_secret():\n",
- " \"\"\"Read the API key from the environment variable. This is\n",
- " only used for CI/CD purposes.\"\"\"\n",
- " t = os.getenv(\"VESPA_TEAM_API_KEY\")\n",
- " if t:\n",
- " return t.replace(r\"\\n\", \"\\n\")\n",
- " else:\n",
- " return t\n",
- "\n",
+ "# Key is only used for CI/CD. Can be removed if logging in interactively\n",
+ "key = os.getenv(\"VESPA_TEAM_API_KEY\", None)\n",
+ "if key is not None:\n",
+ " key = key.replace(r\"\\n\", \"\\n\") # To parse key correctly\n",
"\n",
"vespa_cloud = VespaCloud(\n",
- " tenant=os.environ[\"TENANT_NAME\"],\n",
+ " tenant=tenant_name,\n",
" application=vespa_app_name,\n",
- " key_content=read_secret() if read_secret() else None,\n",
- " key_location=api_key_path,\n",
+ " key_content=key, # Key is only used for CI/CD. Can be removed if logging in interactively\n",
" application_package=vespa_application_package,\n",
")"
]
diff --git a/docs/sphinx/source/examples/cohere-binary-vectors-in-vespa-cloud.ipynb b/docs/sphinx/source/examples/cohere-binary-vectors-in-vespa-cloud.ipynb
index 85873626..64f2b143 100644
--- a/docs/sphinx/source/examples/cohere-binary-vectors-in-vespa-cloud.ipynb
+++ b/docs/sphinx/source/examples/cohere-binary-vectors-in-vespa-cloud.ipynb
@@ -45,6 +45,8 @@
"\n",
"> To improve the search quality, the float query embedding can be compared with the binary document embeddings using dot-product. So we first retrieve 10\\*top_k results with the binary query embedding, and then rescore the binary document embeddings with the float query embedding. This pushes the search quality from 90% to 95%.\n",
"\n",
+ "[](https://colab.research.google.com/github/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/cohere-binary-vectors-in-vespa-cloud.ipynb)\n",
+ "\n",
"Install the dependencies:\n"
]
},
@@ -57,7 +59,7 @@
},
"outputs": [],
"source": [
- "!pip3 install -U pyvespa cohere==4.57"
+ "!pip3 install -U pyvespa cohere==4.57 vespacli"
]
},
{
@@ -357,210 +359,13 @@
"## Deploy the application to Vespa Cloud\n",
"\n",
"With the configured application, we can deploy it to [Vespa Cloud](https://cloud.vespa.ai/en/).\n",
- "It is also possible to deploy the app using docker; see the [Hybrid Search - Quickstart](https://pyvespa.readthedocs.io/en/latest/getting-started-pyvespa.html) guide for\n",
- "an example of deploying it to a local docker container.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "cf82b02d",
- "metadata": {
- "id": "16179d9b"
- },
- "source": [
- "Install the Vespa CLI\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "1f1337cf",
- "metadata": {
- "id": "343981ce"
- },
- "outputs": [],
- "source": [
- "!pip3 install vespacli"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "b996a9d7",
- "metadata": {
- "id": "0ff00727"
- },
- "source": [
+ "\n",
"To deploy the application to Vespa Cloud we need to create a tenant in the Vespa Cloud:\n",
"\n",
"Create a tenant at [console.vespa-cloud.com](https://console.vespa-cloud.com/) (unless you already have one).\n",
"This step requires a Google or GitHub account, and will start your [free trial](https://cloud.vespa.ai/en/free-trial).\n",
- "Make note of the tenant name, it is used in the next steps.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "8b1d2950",
- "metadata": {
- "id": "df9f9a1c"
- },
- "source": [
- "### Configure Vespa Cloud date-plane security\n",
"\n",
- "Create Vespa Cloud data-plane mTLS cert/key-pair. The mutual certificate pair is used to talk to your Vespa cloud endpoints. See [Vespa Cloud Security Guide](https://cloud.vespa.ai/en/security/guide) for details.\n",
- "\n",
- "We save the paths to the credentials for later data-plane access without using pyvespa APIs.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "b9d9545c",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "executionInfo": {
- "elapsed": 611,
- "status": "ok",
- "timestamp": 1706648115118,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "b6a766d6",
- "outputId": "47075852-89e2-41a8-cb96-af10dbe534d7"
- },
- "outputs": [],
- "source": [
- "import os\n",
- "\n",
- "os.environ[\"TENANT_NAME\"] = \"vespa-team\" # Replace with your tenant name\n",
- "\n",
- "vespa_cli_command = (\n",
- " f'vespa config set application {os.environ[\"TENANT_NAME\"]}.{vespa_app_name}'\n",
- ")\n",
- "\n",
- "!vespa config set target cloud\n",
- "!{vespa_cli_command}\n",
- "!vespa auth cert -N"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "e10487bd",
- "metadata": {
- "id": "b228381b"
- },
- "source": [
- "Validate that we have the expected data-plane credential files:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 24,
- "id": "70abcc3b",
- "metadata": {
- "executionInfo": {
- "elapsed": 241,
- "status": "ok",
- "timestamp": 1706648119995,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "1f0b97c8"
- },
- "outputs": [],
- "source": [
- "from os.path import exists\n",
- "from pathlib import Path\n",
- "\n",
- "cert_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-public-cert.pem\"\n",
- ")\n",
- "key_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-private-key.pem\"\n",
- ")\n",
- "\n",
- "if not exists(cert_path) or not exists(key_path):\n",
- " print(\n",
- " \"ERROR: set the correct paths to security credentials. Correct paths above and rerun until you do not see this error\"\n",
- " )"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "fd7b4049",
- "metadata": {
- "id": "85ce80e0"
- },
- "source": [
- "Note that the subsequent Vespa Cloud deploy call below will add `data-plane-public-cert.pem` to the application before deploying it to Vespa Cloud, so that\n",
- "you have access to both the private key and the public certificate. At the same time, Vespa Cloud only knows the public certificate.\n",
- "\n",
- "### Configure Vespa Cloud control-plane security\n",
- "\n",
- "Authenticate to generate a tenant level control plane API key for deploying the applications to Vespa Cloud, and save the path to it.\n",
- "\n",
- "The generated tenant api key must be added in the Vespa Console before attempting to deploy the application.\n",
- "\n",
- "```\n",
- "To use this key in Vespa Cloud click 'Add custom key' at\n",
- "https://console.vespa-cloud.com/tenant/TENANT_NAME/account/keys\n",
- "and paste the entire public key including the BEGIN and END lines.\n",
- "```\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "e4de9e4e",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "executionInfo": {
- "elapsed": 244,
- "status": "ok",
- "timestamp": 1706648129288,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "5bf8731c",
- "outputId": "5f615d4c-9469-4be8-c8fe-9d0fc9dab4f6"
- },
- "outputs": [],
- "source": [
- "!vespa auth api-key\n",
- "\n",
- "from pathlib import Path\n",
- "\n",
- "api_key_path = Path.home() / \".vespa\" / f\"{os.environ['TENANT_NAME']}.api-key.pem\""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "52fe7b5d",
- "metadata": {
- "id": "21db1010"
- },
- "source": [
- "### Deploy to Vespa Cloud\n",
- "\n",
- "Now that we have data-plane and control-plane credentials ready, we can deploy our application to Vespa Cloud!\n",
- "\n",
- "`PyVespa` supports deploying apps to the [development zone](https://cloud.vespa.ai/en/reference/environments#dev-and-perf).\n",
+ "Make note of the tenant name, it is used in the next steps.\n",
"\n",
"> Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.\n"
]
@@ -585,23 +390,20 @@
"outputs": [],
"source": [
"from vespa.deployment import VespaCloud\n",
+ "import os\n",
"\n",
+ "# Replace with your tenant name from the Vespa Cloud Console\n",
+ "tenant_name = \"vespa-team\"\n",
"\n",
- "def read_secret():\n",
- " \"\"\"Read the API key from the environment variable. This is\n",
- " only used for CI/CD purposes.\"\"\"\n",
- " t = os.getenv(\"VESPA_TEAM_API_KEY\")\n",
- " if t:\n",
- " return t.replace(r\"\\n\", \"\\n\")\n",
- " else:\n",
- " return t\n",
- "\n",
+ "# Key is only used for CI/CD. Can be removed if logging in interactively\n",
+ "key = os.getenv(\"VESPA_TEAM_API_KEY\", None)\n",
+ "if key is not None:\n",
+ " key = key.replace(r\"\\n\", \"\\n\") # To parse key correctly\n",
"\n",
"vespa_cloud = VespaCloud(\n",
- " tenant=os.environ[\"TENANT_NAME\"],\n",
+ " tenant=tenant_name,\n",
" application=vespa_app_name,\n",
- " key_content=read_secret() if read_secret() else None,\n",
- " key_location=api_key_path,\n",
+ " key_content=key, # Key is only used for CI/CD. Can be removed if logging in interactively\n",
" application_package=vespa_application_package,\n",
")"
]
diff --git a/docs/sphinx/source/examples/colbert_standalone_long_context_Vespa-cloud.ipynb b/docs/sphinx/source/examples/colbert_standalone_long_context_Vespa-cloud.ipynb
index 3901922f..ab1c7b44 100644
--- a/docs/sphinx/source/examples/colbert_standalone_long_context_Vespa-cloud.ipynb
+++ b/docs/sphinx/source/examples/colbert_standalone_long_context_Vespa-cloud.ipynb
@@ -24,7 +24,9 @@
"- Use Vespa hex feed format for binary vectors with mixed vespa tensors\n",
"- How to query\n",
"\n",
- "Read more about [Vespa Long-Context ColBERT](https://blog.vespa.ai/announcing-long-context-colbert-in-vespa/).\n"
+ "Read more about [Vespa Long-Context ColBERT](https://blog.vespa.ai/announcing-long-context-colbert-in-vespa/).\n",
+ "\n",
+ "[](https://colab.research.google.com/github/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/colbert_standalone_long_context_Vespa-cloud.ipynb)\n"
]
},
{
@@ -36,7 +38,7 @@
},
"outputs": [],
"source": [
- "!pip3 install -U pyvespa colbert-ai numpy torch"
+ "!pip3 install -U pyvespa colbert-ai numpy torch vespacli"
]
},
{
@@ -337,180 +339,13 @@
"## Deploy the application to Vespa Cloud\n",
"\n",
"With the configured application, we can deploy it to [Vespa Cloud](https://cloud.vespa.ai/en/).\n",
- "It is also possible to deploy the app using docker; see the [Hybrid Search - Quickstart](https://pyvespa.readthedocs.io/en/latest/getting-started-pyvespa.html) guide for\n",
- "an example of deploying it to a local docker container.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "16179d9b",
- "metadata": {
- "id": "16179d9b"
- },
- "source": [
- "Install the Vespa CLI.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "343981ce",
- "metadata": {
- "id": "343981ce"
- },
- "outputs": [],
- "source": [
- "!pip3 install vespacli"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "0ff00727",
- "metadata": {
- "id": "0ff00727"
- },
- "source": [
+ "\n",
"To deploy the application to Vespa Cloud we need to create a tenant in the Vespa Cloud:\n",
"\n",
"Create a tenant at [console.vespa-cloud.com](https://console.vespa-cloud.com/) (unless you already have one).\n",
"This step requires a Google or GitHub account, and will start your [free trial](https://cloud.vespa.ai/en/free-trial).\n",
- "Make note of the tenant name, it is used in the next steps.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "df9f9a1c",
- "metadata": {
- "id": "df9f9a1c"
- },
- "source": [
- "### Configure Vespa Cloud date-plane security\n",
- "\n",
- "Create Vespa Cloud data-plane mTLS cert/key-pair. The mutual certificate pair is used to talk to your Vespa cloud endpoints. See [Vespa Cloud Security Guide](https://cloud.vespa.ai/en/security/guide) for details.\n",
- "\n",
- "We save the paths to the credentials for later data-plane access without using pyvespa APIs.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "b6a766d6",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "b6a766d6",
- "outputId": "9f05ce4d-378a-4abf-cefe-d8dd2580b25a"
- },
- "outputs": [],
- "source": [
- "import os\n",
- "\n",
- "os.environ[\"TENANT_NAME\"] = \"vespa-team\" # Replace with your tenant name\n",
- "\n",
- "vespa_cli_command = (\n",
- " f'vespa config set application {os.environ[\"TENANT_NAME\"]}.{vespa_app_name}'\n",
- ")\n",
- "\n",
- "!vespa config set target cloud\n",
- "!{vespa_cli_command}\n",
- "!vespa auth cert -N"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "b228381b",
- "metadata": {
- "id": "b228381b"
- },
- "source": [
- "Validate that we have the expected data-plane credential files:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 35,
- "id": "1f0b97c8",
- "metadata": {
- "id": "1f0b97c8"
- },
- "outputs": [],
- "source": [
- "from os.path import exists\n",
- "from pathlib import Path\n",
- "\n",
- "cert_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-public-cert.pem\"\n",
- ")\n",
- "key_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-private-key.pem\"\n",
- ")\n",
- "\n",
- "if not exists(cert_path) or not exists(key_path):\n",
- " print(\n",
- " \"ERROR: set the correct paths to security credentials. Correct paths above and rerun until you do not see this error\"\n",
- " )"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "85ce80e0",
- "metadata": {
- "id": "85ce80e0"
- },
- "source": [
- "Note that the subsequent Vespa Cloud deploy call below will add `data-plane-public-cert.pem` to the application before deploying it to Vespa Cloud, so that\n",
- "you have access to both the private key and the public certificate. At the same time, Vespa Cloud only knows the public certificate.\n",
- "\n",
- "### Configure Vespa Cloud control-plane security\n",
- "\n",
- "Authenticate to generate a tenant level control plane API key for deploying the applications to Vespa Cloud, and save the path to it.\n",
"\n",
- "The generated tenant api key must be added in the Vespa Console before attempting to deploy the application.\n",
- "\n",
- "```\n",
- "To use this key in Vespa Cloud click 'Add custom key' at\n",
- "https://console.vespa-cloud.com/tenant/TENANT_NAME/account/keys\n",
- "and paste the entire public key including the BEGIN and END lines.\n",
- "```\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "5bf8731c",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "5bf8731c",
- "outputId": "12765e29-1060-43f7-bd77-ff13d72835ed"
- },
- "outputs": [],
- "source": [
- "!vespa auth api-key\n",
- "\n",
- "from pathlib import Path\n",
- "\n",
- "api_key_path = Path.home() / \".vespa\" / f\"{os.environ['TENANT_NAME']}.api-key.pem\""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "21db1010",
- "metadata": {
- "id": "21db1010"
- },
- "source": [
- "### Deploy to Vespa Cloud\n",
- "\n",
- "Now that we have data-plane and control-plane credentials ready, we can deploy our application to Vespa Cloud!\n",
- "\n",
- "`PyVespa` supports deploying apps to the [development zone](https://cloud.vespa.ai/en/reference/environments#dev-and-perf).\n",
+ "Make note of the tenant name, it is used in the next steps.\n",
"\n",
"> Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.\n"
]
@@ -525,23 +360,20 @@
"outputs": [],
"source": [
"from vespa.deployment import VespaCloud\n",
+ "import os\n",
"\n",
+ "# Replace with your tenant name from the Vespa Cloud Console\n",
+ "tenant_name = \"vespa-team\"\n",
"\n",
- "def read_secret():\n",
- " \"\"\"Read the API key from the environment variable. This is\n",
- " only used for CI/CD purposes.\"\"\"\n",
- " t = os.getenv(\"VESPA_TEAM_API_KEY\")\n",
- " if t:\n",
- " return t.replace(r\"\\n\", \"\\n\")\n",
- " else:\n",
- " return t\n",
- "\n",
+ "# Key is only used for CI/CD. Can be removed if logging in interactively\n",
+ "key = os.getenv(\"VESPA_TEAM_API_KEY\", None)\n",
+ "if key is not None:\n",
+ " key = key.replace(r\"\\n\", \"\\n\") # To parse key correctly\n",
"\n",
"vespa_cloud = VespaCloud(\n",
- " tenant=os.environ[\"TENANT_NAME\"],\n",
+ " tenant=tenant_name,\n",
" application=vespa_app_name,\n",
- " key_content=read_secret() if read_secret() else None,\n",
- " key_location=api_key_path,\n",
+ " key_content=key, # Key is only used for CI/CD. Can be removed if logging in interactively\n",
" application_package=vespa_application_package,\n",
")"
]
diff --git a/docs/sphinx/source/examples/feed_performance_cloud.ipynb b/docs/sphinx/source/examples/feed_performance_cloud.ipynb
index 358116be..f033c50f 100644
--- a/docs/sphinx/source/examples/feed_performance_cloud.ipynb
+++ b/docs/sphinx/source/examples/feed_performance_cloud.ipynb
@@ -26,6 +26,14 @@
"3. Using [Vespa CLI](https://docs.vespa.ai/en/vespa-cli).\n"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "8d88b29a",
+ "metadata": {},
+ "source": [
+ "[](https://colab.research.google.com/github/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/feed_performance_cloud.ipynb)\n"
+ ]
+ },
{
"cell_type": "markdown",
"id": "8c967bd2",
@@ -186,26 +194,21 @@
],
"source": [
"from vespa.deployment import VespaCloud\n",
- "from vespa.application import Vespa\n",
"import os\n",
"\n",
+ "# Replace with your tenant name from the Vespa Cloud Console\n",
+ "tenant_name = \"vespa-team\"\n",
"\n",
- "def read_secret():\n",
- " \"\"\"Read the API key from the environment variable. This is\n",
- " only used for CI/CD purposes.\"\"\"\n",
- " t = os.getenv(\"VESPA_TEAM_API_KEY\")\n",
- " if t:\n",
- " return t.replace(r\"\\n\", \"\\n\")\n",
- " else:\n",
- " return t\n",
+ "# Key is only used for CI/CD. Can be removed if logging in interactively\n",
+ "key = os.getenv(\"VESPA_TEAM_API_KEY\", None)\n",
+ "if key is not None:\n",
+ " key = key.replace(r\"\\n\", \"\\n\") # To parse key correctly\n",
"\n",
"\n",
"vespa_cloud = VespaCloud(\n",
- " tenant=\"vespa-team\",\n",
+ " tenant=tenant_name,\n",
" application=application,\n",
- " key_content=read_secret()\n",
- " if read_secret()\n",
- " else None, # Can removed this for interactive control-plane login\n",
+ " key_content=key, # Key is only used for CI/CD. Can be removed if logging in interactively\n",
" application_package=package,\n",
")"
]
@@ -267,6 +270,8 @@
}
],
"source": [
+ "from vespa.application import Vespa\n",
+ "\n",
"app: Vespa = vespa_cloud.deploy()"
]
},
diff --git a/docs/sphinx/source/examples/mixedbread-binary-embeddings-with-sentence-transformers-cloud.ipynb b/docs/sphinx/source/examples/mixedbread-binary-embeddings-with-sentence-transformers-cloud.ipynb
index 732afc96..831df406 100644
--- a/docs/sphinx/source/examples/mixedbread-binary-embeddings-with-sentence-transformers-cloud.ipynb
+++ b/docs/sphinx/source/examples/mixedbread-binary-embeddings-with-sentence-transformers-cloud.ipynb
@@ -41,6 +41,8 @@
"\n",
"\n",
"\n",
+ "[](https://colab.research.google.com/github/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/mixedbread-binary-embeddings-with-sentence-transformers-cloud.ipynb)\n",
+ "\n",
"Install the dependencies:\n"
]
},
@@ -53,7 +55,7 @@
},
"outputs": [],
"source": [
- "!pip3 install -U pyvespa sentence-transformers"
+ "!pip3 install -U pyvespa sentence-transformers vespacli"
]
},
{
@@ -336,210 +338,13 @@
"## Deploy the application to Vespa Cloud\n",
"\n",
"With the configured application, we can deploy it to [Vespa Cloud](https://cloud.vespa.ai/en/).\n",
- "It is also possible to deploy the app using docker; see the [Hybrid Search - Quickstart](https://pyvespa.readthedocs.io/en/latest/getting-started-pyvespa.html) guide for\n",
- "an example of deploying it to a local docker container.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "cf82b02d",
- "metadata": {
- "id": "16179d9b"
- },
- "source": [
- "Install the Vespa CLI.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "1f1337cf",
- "metadata": {
- "id": "343981ce"
- },
- "outputs": [],
- "source": [
- "!pip3 install vespacli"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "b996a9d7",
- "metadata": {
- "id": "0ff00727"
- },
- "source": [
+ "\n",
"To deploy the application to Vespa Cloud we need to create a tenant in the Vespa Cloud:\n",
"\n",
"Create a tenant at [console.vespa-cloud.com](https://console.vespa-cloud.com/) (unless you already have one).\n",
"This step requires a Google or GitHub account, and will start your [free trial](https://cloud.vespa.ai/en/free-trial).\n",
- "Make note of the tenant name, it is used in the next steps.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "8b1d2950",
- "metadata": {
- "id": "df9f9a1c"
- },
- "source": [
- "### Configure Vespa Cloud date-plane security\n",
"\n",
- "Create Vespa Cloud data-plane mTLS cert/key-pair. The mutual certificate pair is used to talk to your Vespa cloud endpoints. See [Vespa Cloud Security Guide](https://cloud.vespa.ai/en/security/guide) for details.\n",
- "\n",
- "We save the paths to the credentials for later data-plane access without using pyvespa APIs.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "b9d9545c",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "executionInfo": {
- "elapsed": 611,
- "status": "ok",
- "timestamp": 1706648115118,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "b6a766d6",
- "outputId": "47075852-89e2-41a8-cb96-af10dbe534d7"
- },
- "outputs": [],
- "source": [
- "import os\n",
- "\n",
- "os.environ[\"TENANT_NAME\"] = \"vespa-team\" # Replace with your tenant name\n",
- "\n",
- "vespa_cli_command = (\n",
- " f'vespa config set application {os.environ[\"TENANT_NAME\"]}.{vespa_app_name}'\n",
- ")\n",
- "\n",
- "!vespa config set target cloud\n",
- "!{vespa_cli_command}\n",
- "!vespa auth cert -N"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "e10487bd",
- "metadata": {
- "id": "b228381b"
- },
- "source": [
- "Validate that we have the expected data-plane credential files:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 19,
- "id": "70abcc3b",
- "metadata": {
- "executionInfo": {
- "elapsed": 241,
- "status": "ok",
- "timestamp": 1706648119995,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "1f0b97c8"
- },
- "outputs": [],
- "source": [
- "from os.path import exists\n",
- "from pathlib import Path\n",
- "\n",
- "cert_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-public-cert.pem\"\n",
- ")\n",
- "key_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-private-key.pem\"\n",
- ")\n",
- "\n",
- "if not exists(cert_path) or not exists(key_path):\n",
- " print(\n",
- " \"ERROR: set the correct paths to security credentials. Correct paths above and rerun until you do not see this error\"\n",
- " )"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "fd7b4049",
- "metadata": {
- "id": "85ce80e0"
- },
- "source": [
- "Note that the subsequent Vespa Cloud deploy call below will add `data-plane-public-cert.pem` to the application before deploying it to Vespa Cloud, so that\n",
- "you have access to both the private key and the public certificate. At the same time, Vespa Cloud only knows the public certificate.\n",
- "\n",
- "### Configure Vespa Cloud control-plane security\n",
- "\n",
- "Authenticate to generate a tenant level control plane API key for deploying the applications to Vespa Cloud, and save the path to it.\n",
- "\n",
- "The generated tenant api key must be added in the Vespa Console before attempting to deploy the application.\n",
- "\n",
- "```\n",
- "To use this key in Vespa Cloud click 'Add custom key' at\n",
- "https://console.vespa-cloud.com/tenant/TENANT_NAME/account/keys\n",
- "and paste the entire public key including the BEGIN and END lines.\n",
- "```\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "e4de9e4e",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "executionInfo": {
- "elapsed": 244,
- "status": "ok",
- "timestamp": 1706648129288,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "5bf8731c",
- "outputId": "5f615d4c-9469-4be8-c8fe-9d0fc9dab4f6"
- },
- "outputs": [],
- "source": [
- "!vespa auth api-key\n",
- "\n",
- "from pathlib import Path\n",
- "\n",
- "api_key_path = Path.home() / \".vespa\" / f\"{os.environ['TENANT_NAME']}.api-key.pem\""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "52fe7b5d",
- "metadata": {
- "id": "21db1010"
- },
- "source": [
- "### Deploy to Vespa Cloud\n",
- "\n",
- "Now that we have data-plane and control-plane credentials ready, we can deploy our application to Vespa Cloud!\n",
- "\n",
- "`PyVespa` supports deploying apps to the [development zone](https://cloud.vespa.ai/en/reference/environments#dev-and-perf).\n",
+ "Make note of the tenant name, it is used in the next steps.\n",
"\n",
"> Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.\n"
]
@@ -564,23 +369,20 @@
"outputs": [],
"source": [
"from vespa.deployment import VespaCloud\n",
+ "import os\n",
"\n",
+ "# Replace with your tenant name from the Vespa Cloud Console\n",
+ "tenant_name = \"vespa-team\"\n",
"\n",
- "def read_secret():\n",
- " \"\"\"Read the API key from the environment variable. This is\n",
- " only used for CI/CD purposes.\"\"\"\n",
- " t = os.getenv(\"VESPA_TEAM_API_KEY\")\n",
- " if t:\n",
- " return t.replace(r\"\\n\", \"\\n\")\n",
- " else:\n",
- " return t\n",
- "\n",
+ "# Key is only used for CI/CD. Can be removed if logging in interactively\n",
+ "key = os.getenv(\"VESPA_TEAM_API_KEY\", None)\n",
+ "if key is not None:\n",
+ " key = key.replace(r\"\\n\", \"\\n\") # To parse key correctly\n",
"\n",
"vespa_cloud = VespaCloud(\n",
- " tenant=os.environ[\"TENANT_NAME\"],\n",
+ " tenant=tenant_name,\n",
" application=vespa_app_name,\n",
- " key_content=read_secret() if read_secret() else None,\n",
- " key_location=api_key_path,\n",
+ " key_content=key, # Key is only used for CI/CD. Can be removed if logging in interactively\n",
" application_package=vespa_application_package,\n",
")"
]
diff --git a/docs/sphinx/source/examples/mother-of-all-embedding-models-cloud.ipynb b/docs/sphinx/source/examples/mother-of-all-embedding-models-cloud.ipynb
index a793f8c8..1d4f7e79 100644
--- a/docs/sphinx/source/examples/mother-of-all-embedding-models-cloud.ipynb
+++ b/docs/sphinx/source/examples/mother-of-all-embedding-models-cloud.ipynb
@@ -22,6 +22,8 @@
"\n",
"This code is inspired by the README from the model hub [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3).\n",
"\n",
+ "[](https://colab.research.google.com/github/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/mother-of-all-embedding-models-cloud.ipynb)\n",
+ "\n",
"Let's get started! First, install dependencies:\n"
]
},
@@ -32,7 +34,7 @@
"metadata": {},
"outputs": [],
"source": [
- "!pip3 install -U pyvespa FlagEmbedding"
+ "!pip3 install -U pyvespa FlagEmbedding vespacli"
]
},
{
@@ -281,152 +283,13 @@
"## Deploy the application to Vespa Cloud\n",
"\n",
"With the configured application, we can deploy it to [Vespa Cloud](https://cloud.vespa.ai/en/).\n",
- "It is also possible to deploy the app using docker; see the [Hybrid Search - Quickstart](https://pyvespa.readthedocs.io/en/latest/getting-started-pyvespa.html) guide for\n",
- "an example of deploying it to a local docker container.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "16179d9b",
- "metadata": {},
- "source": [
- "Install the Vespa CLI.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "343981ce",
- "metadata": {},
- "outputs": [],
- "source": [
- "!pip3 install vespacli"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "0ff00727",
- "metadata": {},
- "source": [
+ "\n",
"To deploy the application to Vespa Cloud we need to create a tenant in the Vespa Cloud:\n",
"\n",
"Create a tenant at [console.vespa-cloud.com](https://console.vespa-cloud.com/) (unless you already have one).\n",
"This step requires a Google or GitHub account, and will start your [free trial](https://cloud.vespa.ai/en/free-trial).\n",
- "Make note of the tenant name, it is used in the next steps.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "df9f9a1c",
- "metadata": {},
- "source": [
- "### Configure Vespa Cloud date-plane security\n",
- "\n",
- "Create Vespa Cloud data-plane mTLS cert/key-pair. The mutual certificate pair is used to talk to your Vespa cloud endpoints. See [Vespa Cloud Security Guide](https://cloud.vespa.ai/en/security/guide) for details.\n",
- "\n",
- "We save the paths to the credentials for later data-plane access without using pyvespa APIs.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "b6a766d6",
- "metadata": {},
- "outputs": [],
- "source": [
- "import os\n",
"\n",
- "os.environ[\"TENANT_NAME\"] = \"vespa-team\" # Replace with your tenant name\n",
- "\n",
- "vespa_cli_command = (\n",
- " f'vespa config set application {os.environ[\"TENANT_NAME\"]}.{vespa_app_name}'\n",
- ")\n",
- "\n",
- "!vespa config set target cloud\n",
- "!{vespa_cli_command}\n",
- "!vespa auth cert -N"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "b228381b",
- "metadata": {},
- "source": [
- "Validate that we have the expected data-plane credential files:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 10,
- "id": "1f0b97c8",
- "metadata": {},
- "outputs": [],
- "source": [
- "from os.path import exists\n",
- "from pathlib import Path\n",
- "\n",
- "cert_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-public-cert.pem\"\n",
- ")\n",
- "key_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-private-key.pem\"\n",
- ")\n",
- "\n",
- "if not exists(cert_path) or not exists(key_path):\n",
- " print(\n",
- " \"ERROR: set the correct paths to security credentials. Correct paths above and rerun until you do not see this error\"\n",
- " )"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "85ce80e0",
- "metadata": {},
- "source": [
- "Note that the subsequent Vespa Cloud deploy call below will add `data-plane-public-cert.pem` to the application before deploying it to Vespa Cloud, so that\n",
- "you have access to both the private key and the public certificate. At the same time, Vespa Cloud only knows the public certificate.\n",
- "\n",
- "### Configure Vespa Cloud control-plane security\n",
- "\n",
- "Authenticate to generate a tenant level control plane API key for deploying the applications to Vespa Cloud, and save the path to it.\n",
- "\n",
- "The generated tenant api key must be added in the Vespa Console before attempting to deploy the application.\n",
- "\n",
- "```\n",
- "To use this key in Vespa Cloud click 'Add custom key' at\n",
- "https://console.vespa-cloud.com/tenant/TENANT_NAME/account/keys\n",
- "and paste the entire public key including the BEGIN and END lines.\n",
- "```\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "5bf8731c",
- "metadata": {},
- "outputs": [],
- "source": [
- "!vespa auth api-key\n",
- "\n",
- "from pathlib import Path\n",
- "\n",
- "api_key_path = Path.home() / \".vespa\" / f\"{os.environ['TENANT_NAME']}.api-key.pem\""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "21db1010",
- "metadata": {},
- "source": [
- "### Deploy to Vespa Cloud\n",
- "\n",
- "Now that we have data-plane and control-plane credentials ready, we can deploy our application to Vespa Cloud!\n",
- "\n",
- "`PyVespa` supports deploying apps to the [development zone](https://cloud.vespa.ai/en/reference/environments#dev-and-perf).\n",
+ "Make note of the tenant name, it is used in the next steps.\n",
"\n",
"> Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.\n"
]
@@ -439,23 +302,20 @@
"outputs": [],
"source": [
"from vespa.deployment import VespaCloud\n",
+ "import os\n",
"\n",
+ "# Replace with your tenant name from the Vespa Cloud Console\n",
+ "tenant_name = \"vespa-team\"\n",
"\n",
- "def read_secret():\n",
- " \"\"\"Read the API key from the environment variable. This is\n",
- " only used for CI/CD purposes.\"\"\"\n",
- " t = os.getenv(\"VESPA_TEAM_API_KEY\")\n",
- " if t:\n",
- " return t.replace(r\"\\n\", \"\\n\")\n",
- " else:\n",
- " return t\n",
- "\n",
+ "# Key is only used for CI/CD. Can be removed if logging in interactively\n",
+ "key = os.getenv(\"VESPA_TEAM_API_KEY\", None)\n",
+ "if key is not None:\n",
+ " key = key.replace(r\"\\n\", \"\\n\") # To parse key correctly\n",
"\n",
"vespa_cloud = VespaCloud(\n",
- " tenant=os.environ[\"TENANT_NAME\"],\n",
+ " tenant=tenant_name,\n",
" application=vespa_app_name,\n",
- " key_content=read_secret() if read_secret() else None,\n",
- " key_location=api_key_path,\n",
+ " key_content=key, # Key is only used for CI/CD. Can be removed if logging in interactively\n",
" application_package=vespa_application_package,\n",
")"
]
diff --git a/docs/sphinx/source/examples/multilingual-multi-vector-reps-with-cohere-cloud.ipynb b/docs/sphinx/source/examples/multilingual-multi-vector-reps-with-cohere-cloud.ipynb
index 4ef51961..6160ff32 100644
--- a/docs/sphinx/source/examples/multilingual-multi-vector-reps-with-cohere-cloud.ipynb
+++ b/docs/sphinx/source/examples/multilingual-multi-vector-reps-with-cohere-cloud.ipynb
@@ -33,6 +33,8 @@
"- Hybrid search, combining the lexical matching capabilities of Vespa with Cohere binary embeddings\n",
"- Re-scoring the binarized vectors for improved accuracy\n",
"\n",
+ "[](https://colab.research.google.com/github/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/multilingual-multi-vector-reps-with-cohere-cloud.ipynb)\n",
+ "\n",
"Install the dependencies:\n"
]
},
@@ -45,7 +47,7 @@
},
"outputs": [],
"source": [
- "!pip3 install -U pyvespa cohere==4.57 datasets"
+ "!pip3 install -U pyvespa cohere==4.57 datasets vespacli"
]
},
{
@@ -335,219 +337,13 @@
"## Deploy the application to Vespa Cloud\n",
"\n",
"With the configured application, we can deploy it to [Vespa Cloud](https://cloud.vespa.ai/en/).\n",
- "It is also possible to deploy the app using docker; see the [Hybrid Search - Quickstart](https://pyvespa.readthedocs.io/en/latest/getting-started-pyvespa.html) guide for\n",
- "an example of deploying it to a local docker container.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "cf82b02d",
- "metadata": {
- "id": "16179d9b"
- },
- "source": [
- "Install the Vespa CLI.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "1f1337cf",
- "metadata": {
- "id": "343981ce"
- },
- "outputs": [],
- "source": [
- "!pip3 install vespacli"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "b996a9d7",
- "metadata": {
- "id": "0ff00727"
- },
- "source": [
+ "\n",
"To deploy the application to Vespa Cloud we need to create a tenant in the Vespa Cloud:\n",
"\n",
"Create a tenant at [console.vespa-cloud.com](https://console.vespa-cloud.com/) (unless you already have one).\n",
"This step requires a Google or GitHub account, and will start your [free trial](https://cloud.vespa.ai/en/free-trial).\n",
- "Make note of the tenant name, it is used in the next steps.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "8b1d2950",
- "metadata": {
- "id": "df9f9a1c"
- },
- "source": [
- "### Configure Vespa Cloud date-plane security\n",
- "\n",
- "Create Vespa Cloud data-plane mTLS cert/key-pair. The mutual certificate pair is used to talk to your Vespa cloud endpoints. See [Vespa Cloud Security Guide](https://cloud.vespa.ai/en/security/guide) for details.\n",
- "\n",
- "We save the paths to the credentials for later data-plane access without using pyvespa APIs.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 11,
- "id": "b9d9545c",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "executionInfo": {
- "elapsed": 611,
- "status": "ok",
- "timestamp": 1706648115118,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "b6a766d6",
- "outputId": "47075852-89e2-41a8-cb96-af10dbe534d7"
- },
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\u001b[32mSuccess:\u001b[0m Certificate written to \u001b[36m'/Users/bergum/.vespa/samples.wikipedia.default/data-plane-public-cert.pem'\u001b[0m\n",
- "\u001b[32mSuccess:\u001b[0m Private key written to \u001b[36m'/Users/bergum/.vespa/samples.wikipedia.default/data-plane-private-key.pem'\u001b[0m\n"
- ]
- }
- ],
- "source": [
- "import os\n",
- "\n",
- "os.environ[\"TENANT_NAME\"] = \"vespa-team\" # Replace with your tenant name\n",
- "\n",
- "vespa_cli_command = (\n",
- " f'vespa config set application {os.environ[\"TENANT_NAME\"]}.{vespa_app_name}'\n",
- ")\n",
- "\n",
- "!vespa config set target cloud\n",
- "!{vespa_cli_command}\n",
- "!vespa auth cert -N"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "e10487bd",
- "metadata": {
- "id": "b228381b"
- },
- "source": [
- "Validate that we have the expected data-plane credential files:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 12,
- "id": "70abcc3b",
- "metadata": {
- "executionInfo": {
- "elapsed": 241,
- "status": "ok",
- "timestamp": 1706648119995,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "1f0b97c8"
- },
- "outputs": [],
- "source": [
- "from os.path import exists\n",
- "from pathlib import Path\n",
- "\n",
- "cert_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-public-cert.pem\"\n",
- ")\n",
- "key_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-private-key.pem\"\n",
- ")\n",
- "\n",
- "if not exists(cert_path) or not exists(key_path):\n",
- " print(\n",
- " \"ERROR: set the correct paths to security credentials. Correct paths above and rerun until you do not see this error\"\n",
- " )"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "fd7b4049",
- "metadata": {
- "id": "85ce80e0"
- },
- "source": [
- "Note that the subsequent Vespa Cloud deploy call below will add `data-plane-public-cert.pem` to the application before deploying it to Vespa Cloud, so that\n",
- "you have access to both the private key and the public certificate. At the same time, Vespa Cloud only knows the public certificate.\n",
- "\n",
- "### Configure Vespa Cloud control-plane security\n",
- "\n",
- "Authenticate to generate a tenant level control plane API key for deploying the applications to Vespa Cloud, and save the path to it.\n",
- "\n",
- "The generated tenant api key must be added in the Vespa Console before attempting to deploy the application.\n",
"\n",
- "```\n",
- "To use this key in Vespa Cloud click 'Add custom key' at\n",
- "https://console.vespa-cloud.com/tenant/TENANT_NAME/account/keys\n",
- "and paste the entire public key including the BEGIN and END lines.\n",
- "```\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "e4de9e4e",
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "executionInfo": {
- "elapsed": 244,
- "status": "ok",
- "timestamp": 1706648129288,
- "user": {
- "displayName": "Andreas Eriksen",
- "userId": "00161553861396505040"
- },
- "user_tz": -60
- },
- "id": "5bf8731c",
- "outputId": "5f615d4c-9469-4be8-c8fe-9d0fc9dab4f6"
- },
- "outputs": [],
- "source": [
- "!vespa auth api-key\n",
- "\n",
- "from pathlib import Path\n",
- "\n",
- "api_key_path = Path.home() / \".vespa\" / f\"{os.environ['TENANT_NAME']}.api-key.pem\""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "52fe7b5d",
- "metadata": {
- "id": "21db1010"
- },
- "source": [
- "### Deploy to Vespa Cloud\n",
- "\n",
- "Now that we have data-plane and control-plane credentials ready, we can deploy our application to Vespa Cloud!\n",
- "\n",
- "`PyVespa` supports deploying apps to the [development zone](https://cloud.vespa.ai/en/reference/environments#dev-and-perf).\n",
+ "Make note of the tenant name, it is used in the next steps.\n",
"\n",
"> Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.\n"
]
@@ -572,23 +368,20 @@
"outputs": [],
"source": [
"from vespa.deployment import VespaCloud\n",
+ "import os\n",
"\n",
+ "# Replace with your tenant name from the Vespa Cloud Console\n",
+ "tenant_name = \"vespa-team\"\n",
"\n",
- "def read_secret():\n",
- " \"\"\"Read the API key from the environment variable. This is\n",
- " only used for CI/CD purposes.\"\"\"\n",
- " t = os.getenv(\"VESPA_TEAM_API_KEY\")\n",
- " if t:\n",
- " return t.replace(r\"\\n\", \"\\n\")\n",
- " else:\n",
- " return t\n",
- "\n",
+ "# Key is only used for CI/CD. Can be removed if logging in interactively\n",
+ "key = os.getenv(\"VESPA_TEAM_API_KEY\", None)\n",
+ "if key is not None:\n",
+ " key = key.replace(r\"\\n\", \"\\n\") # To parse key correctly\n",
"\n",
- "vespa_cloud: VespaCloud = VespaCloud(\n",
- " tenant=os.environ[\"TENANT_NAME\"],\n",
+ "vespa_cloud = VespaCloud(\n",
+ " tenant=tenant_name,\n",
" application=vespa_app_name,\n",
- " key_content=read_secret() if read_secret() else None,\n",
- " key_location=api_key_path,\n",
+ " key_content=key, # Key is only used for CI/CD. Can be removed if logging in interactively\n",
" application_package=vespa_application_package,\n",
")"
]
diff --git a/docs/sphinx/source/examples/scaling-personal-ai-assistants-with-streaming-mode-cloud.ipynb b/docs/sphinx/source/examples/scaling-personal-ai-assistants-with-streaming-mode-cloud.ipynb
index bbf9c13e..1a4fadbf 100644
--- a/docs/sphinx/source/examples/scaling-personal-ai-assistants-with-streaming-mode-cloud.ipynb
+++ b/docs/sphinx/source/examples/scaling-personal-ai-assistants-with-streaming-mode-cloud.ipynb
@@ -33,6 +33,8 @@
"[Retriever](https://docs.llamaindex.ai/) with a [Vespa](https://vespa.ai/) app\n",
"using streaming mode to retrieve personal data. The focus is on how to use the streaming mode feature.\n",
"\n",
+ "[](https://colab.research.google.com/github/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/scaling-personal-ai-assistants-with-streaming-mode-cloud.ipynb)\n",
+ "\n",
"First, install dependencies:\n"
]
},
@@ -43,7 +45,7 @@
"metadata": {},
"outputs": [],
"source": [
- "!pip3 install -U pyvespa llama-index"
+ "!pip3 install -U pyvespa llama-index vespacli"
]
},
{
@@ -523,157 +525,13 @@
"## Deploy the application to Vespa Cloud\n",
"\n",
"With the configured application, we can deploy it to [Vespa Cloud](https://cloud.vespa.ai/en/).\n",
- "It is also possible to deploy the app using docker; see the [Hybrid Search - Quickstart](https://pyvespa.readthedocs.io/en/latest/getting-started-pyvespa.html) guide for\n",
- "an example of deploying it to a local docker container.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "16179d9b",
- "metadata": {},
- "source": [
- "Install the [Vespa CLI](https://docs.vespa.ai/en/vespa-cli.html).\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "343981ce",
- "metadata": {},
- "outputs": [],
- "source": [
- "!pip3 install vespacli"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "0ff00727",
- "metadata": {},
- "source": [
+ "\n",
"To deploy the application to Vespa Cloud we need to create a tenant in the Vespa Cloud:\n",
"\n",
"Create a tenant at [console.vespa-cloud.com](https://console.vespa-cloud.com/) (unless you already have one).\n",
"This step requires a Google or GitHub account, and will start your [free trial](https://cloud.vespa.ai/en/free-trial).\n",
- "Make note of the tenant name, it is used in the next steps.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "df9f9a1c",
- "metadata": {},
- "source": [
- "### Configure Vespa Cloud date-plane security\n",
"\n",
- "Create Vespa Cloud data-plane mTLS cert/key-pair. The mutual certificate pair is used to talk to your Vespa cloud endpoints. See [Vespa Cloud Security Guide](https://cloud.vespa.ai/en/security/guide) for details.\n",
- "\n",
- "We save the paths to the credentials, for later data-plane access without using pyvespa APIs.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "b6a766d6",
- "metadata": {},
- "outputs": [],
- "source": [
- "os.environ[\"TENANT_NAME\"] = \"vespa-team\" # Replace with your tenant name\n",
- "\n",
- "vespa_cli_command = (\n",
- " f'vespa config set application {os.environ[\"TENANT_NAME\"]}.{vespa_app_name}'\n",
- ")\n",
- "\n",
- "!vespa config set target cloud\n",
- "!{vespa_cli_command}\n",
- "!vespa auth cert -N"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "b228381b",
- "metadata": {},
- "source": [
- "Validate that we have the expected data-plane credential files:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 13,
- "id": "1f0b97c8",
- "metadata": {},
- "outputs": [],
- "source": [
- "from os.path import exists\n",
- "from pathlib import Path\n",
- "\n",
- "cert_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-public-cert.pem\"\n",
- ")\n",
- "key_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-private-key.pem\"\n",
- ")\n",
- "\n",
- "if not exists(cert_path) or not exists(key_path):\n",
- " print(\n",
- " \"ERROR: set the correct paths to security credentials. Correct paths above and rerun until you do not see this error\"\n",
- " )"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "85ce80e0",
- "metadata": {},
- "source": [
- "Note that the subsequent Vespa Cloud deploy call below will add `data-plane-public-cert.pem` to the application before deploying it to Vespa Cloud, so that\n",
- "you have access to both the private key and the public certificate. At the same time, Vespa Cloud only knows the public certificate.\n",
- "\n",
- "### Configure control-plane security\n",
- "\n",
- "Authenticate to generate a tenant level control plane API key for deploying the applications to Vespa Cloud, and save the path to it.\n",
- "\n",
- "The generated tenant api key must be added in the Vespa Console before attempting to deploy the application.\n",
- "\n",
- "```\n",
- "To use this key in Vespa Cloud click 'Add custom key' at\n",
- "https://console.vespa-cloud.com/tenant/TENANT_NAME/account/keys\n",
- "and paste the entire public key including the BEGIN and END lines.\n",
- "```\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "5bf8731c",
- "metadata": {},
- "outputs": [],
- "source": [
- "!vespa auth api-key"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "84665dcc",
- "metadata": {},
- "outputs": [],
- "source": [
- "from pathlib import Path\n",
- "\n",
- "api_key_path = Path.home() / \".vespa\" / f\"{os.environ['TENANT_NAME']}.api-key.pem\""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "21db1010",
- "metadata": {},
- "source": [
- "### Deploy to Vespa Cloud\n",
- "\n",
- "Now that we have data-plane and control-plane credentials ready, we can deploy our application to Vespa Cloud! `PyVespa` supports deploying to the\n",
- "[development zone](https://cloud.vespa.ai/en/reference/environments#dev-and-perf).\n",
+ "Make note of the tenant name, it is used in the next steps.\n",
"\n",
"> Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.\n"
]
@@ -687,22 +545,18 @@
"source": [
"from vespa.deployment import VespaCloud\n",
"\n",
+ "# Replace with your tenant name from the Vespa Cloud Console\n",
+ "tenant_name = \"vespa-team\"\n",
"\n",
- "def read_secret():\n",
- " \"\"\"Read the API key from the environment variable. This is\n",
- " only used for CI/CD purposes.\"\"\"\n",
- " t = os.getenv(\"VESPA_TEAM_API_KEY\")\n",
- " if t:\n",
- " return t.replace(r\"\\n\", \"\\n\")\n",
- " else:\n",
- " return t\n",
- "\n",
+ "# Key is only used for CI/CD. Can be removed if logging in interactively\n",
+ "key = os.getenv(\"VESPA_TEAM_API_KEY\", None)\n",
+ "if key is not None:\n",
+ " key = key.replace(r\"\\n\", \"\\n\") # To parse key correctly\n",
"\n",
"vespa_cloud = VespaCloud(\n",
- " tenant=os.environ[\"TENANT_NAME\"],\n",
+ " tenant=tenant_name,\n",
" application=vespa_app_name,\n",
- " key_content=read_secret() if read_secret() else None,\n",
- " key_location=api_key_path,\n",
+ " key_content=key, # Key is only used for CI/CD. Can be removed if logging in interactively\n",
" application_package=vespa_application_package,\n",
")"
]
@@ -732,7 +586,7 @@
"id": "02430fe9",
"metadata": {},
"source": [
- "### Feeding data to Vespa\n",
+ "## Feeding data to Vespa\n",
"\n",
"With the app up and running in Vespa Cloud, we can start feeding and querying our data.\n",
"\n",
diff --git a/docs/sphinx/source/examples/turbocharge-rag-with-langchain-and-vespa-streaming-mode-cloud.ipynb b/docs/sphinx/source/examples/turbocharge-rag-with-langchain-and-vespa-streaming-mode-cloud.ipynb
index f1565e31..76d3d379 100644
--- a/docs/sphinx/source/examples/turbocharge-rag-with-langchain-and-vespa-streaming-mode-cloud.ipynb
+++ b/docs/sphinx/source/examples/turbocharge-rag-with-langchain-and-vespa-streaming-mode-cloud.ipynb
@@ -1,1148 +1,1008 @@
{
- "cells": [
- {
- "cell_type": "markdown",
- "id": "b3ae8a2b",
- "metadata": {},
- "source": [
- "\n",
- " \n",
- " \n",
- " \n",
- "\n",
- "\n",
- "# Turbocharge RAG with LangChain and Vespa Streaming Mode for Partitioned Data\n",
- "\n",
- "This notebook illustrates using [Vespa streaming mode](https://docs.vespa.ai/en/streaming-search.html)\n",
- "to build cost-efficient RAG applications over naturally sharded data.\n",
- "\n",
- "You can read more about Vespa vector streaming search in these blog posts:\n",
- "\n",
- "- [Announcing vector streaming search: AI assistants at scale without breaking the bank](https://blog.vespa.ai/announcing-vector-streaming-search/)\n",
- "- [Yahoo Mail turns to Vespa to do RAG at scale](https://blog.vespa.ai/yahoo-mail-turns-to-vespa-to-do-rag-at-scale/)\n",
- "- [Hands-On RAG guide for personal data with Vespa and LLamaIndex](https://blog.vespa.ai/scaling-personal-ai-assistants-with-streaming-mode/)\n",
- "\n",
- "This notebook is also available in blog form: [Turbocharge RAG with LangChain and Vespa Streaming Mode for Sharded Data](https://blog.vespa.ai/turbocharge-rag-with-langchain-and-vespa-streaming-mode/)\n",
- "\n",
- "### TLDR; Vespa streaming mode for partitioned data\n",
- "\n",
- "Vespa's streaming search solution enables you to integrate a user ID (or any sharding key) into the Vespa document ID.\n",
- "This setup allows Vespa to efficiently group each user's data on a small set of nodes and the same disk chunk.\n",
- "Streaming mode enables low latency searches on a user's data without keeping data in memory.\n",
- "\n",
- "The key benefits of streaming mode:\n",
- "\n",
- "- Eliminating compromises in precision introduced by approximate algorithms\n",
- "- Achieve significantly higher write throughput, thanks to the absence of index builds required for supporting approximate search.\n",
- "- Optimize efficiency by storing documents, including tensors and data, on disk, benefiting from the cost-effective economics of storage tiers.\n",
- "- Storage cost is the primary cost driver of Vespa streaming mode; no data is in memory. Avoiding memory usage lowers deployment costs significantly.\n",
- "\n",
- "### Connecting LangChain Retriever with Vespa for Context Retrieval from PDF Documents\n",
- "\n",
- "In this notebook, we seamlessly integrate a custom [LangChain](https://python.langchain.com/v0.1/docs/get_started/introduction)\n",
- "[retriever](https://python.langchain.com/v0.1/docs/modules/data_connection/) with a Vespa app,\n",
- "leveraging Vespa's streaming mode to extract meaningful context from PDF documents.\n",
- "\n",
- "The workflow\n",
- "\n",
- "- Define and deploy a Vespa [application package](https://docs.vespa.ai/en/application-packages.html) using PyVespa.\n",
- "- Utilize [LangChain PDF Loaders](https://python.langchain.com/v0.1/docs/modules/data_connection/document_loaders/pdf) to download and parse PDF files.\n",
- "- Leverage [LangChain Document Transformers](https://python.langchain.com/v0.1/docs/modules/data_connection/document_transformers/)\n",
- " to convert each PDF page into multiple text chunks.\n",
- "- Feed the transformer representation to the running Vespa instance\n",
- "- Employ Vespa's built-in embedder functionality (using an open-source embedding model) for embedding the text chunks per page, resulting in a multi-vector representation.\n",
- "- Develop a custom [Retriever](https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/) to enable seamless retrieval for any unstructured text query.\n",
- "\n",
- "\n",
- "\n",
- "Let's get started! First, install dependencies:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "4ffa3cbe",
- "metadata": {},
- "outputs": [],
- "source": [
- "!pip3 install -U pyvespa langchain langchain-community pypdf openai"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "fd3b1e45",
- "metadata": {},
- "source": [
- "## Sample data\n",
- "\n",
- "We love [ColBERT](https://blog.vespa.ai/pretrained-transformer-language-models-for-search-part-3/), so\n",
- "we'll use a few COlBERT related papers as examples of PDFs in this notebook.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 1,
- "id": "384c4c56",
- "metadata": {},
- "outputs": [],
- "source": [
- "def sample_pdfs():\n",
- " return [\n",
- " {\n",
- " \"title\": \"ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction\",\n",
- " \"url\": \"https://arxiv.org/pdf/2112.01488.pdf\",\n",
- " \"authors\": \"Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, Matei Zaharia\",\n",
- " },\n",
- " {\n",
- " \"title\": \"ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT\",\n",
- " \"url\": \"https://arxiv.org/pdf/2004.12832.pdf\",\n",
- " \"authors\": \"Omar Khattab, Matei Zaharia\",\n",
- " },\n",
- " {\n",
- " \"title\": \"On Approximate Nearest Neighbour Selection for Multi-Stage Dense Retrieval\",\n",
- " \"url\": \"https://arxiv.org/pdf/2108.11480.pdf\",\n",
- " \"authors\": \"Craig Macdonald, Nicola Tonellotto\",\n",
- " },\n",
- " {\n",
- " \"title\": \"A Study on Token Pruning for ColBERT\",\n",
- " \"url\": \"https://arxiv.org/pdf/2112.06540.pdf\",\n",
- " \"authors\": \"Carlos Lassance, Maroua Maachou, Joohee Park, Stéphane Clinchant\",\n",
- " },\n",
- " {\n",
- " \"title\": \"Pseudo-Relevance Feedback for Multiple Representation Dense Retrieval\",\n",
- " \"url\": \"https://arxiv.org/pdf/2106.11251.pdf\",\n",
- " \"authors\": \"Xiao Wang, Craig Macdonald, Nicola Tonellotto, Iadh Ounis\",\n",
- " },\n",
- " ]"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "da356d25",
- "metadata": {},
- "source": [
- "## Defining the Vespa application\n",
- "\n",
- "[PyVespa](https://pyvespa.readthedocs.io/en/latest/) helps us build the [Vespa application package](https://docs.vespa.ai/en/application-packages.html).\n",
- "A Vespa application package consists of configuration files, schemas, models, and code (plugins).\n",
- "\n",
- "First, we define a [Vespa schema](https://docs.vespa.ai/en/schemas.html) with the fields we want to store and their type.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 2,
- "id": "0dca2378",
- "metadata": {},
- "outputs": [],
- "source": [
- "from vespa.package import Schema, Document, Field, FieldSet, HNSW\n",
- "\n",
- "pdf_schema = Schema(\n",
- " name=\"pdf\",\n",
- " mode=\"streaming\",\n",
- " document=Document(\n",
- " fields=[\n",
- " Field(name=\"id\", type=\"string\", indexing=[\"summary\", \"index\"]),\n",
- " Field(name=\"title\", type=\"string\", indexing=[\"summary\", \"index\"]),\n",
- " Field(name=\"url\", type=\"string\", indexing=[\"summary\", \"index\"]),\n",
- " Field(name=\"authors\", type=\"array\", indexing=[\"summary\", \"index\"]),\n",
- " Field(name=\"page\", type=\"int\", indexing=[\"summary\", \"index\"]),\n",
- " Field(\n",
- " name=\"metadata\",\n",
- " type=\"map\",\n",
- " indexing=[\"summary\", \"index\"],\n",
- " ),\n",
- " Field(name=\"chunks\", type=\"array\", indexing=[\"summary\", \"index\"]),\n",
- " Field(\n",
- " name=\"embedding\",\n",
- " type=\"tensor(chunk{}, x[384])\",\n",
- " indexing=[\"input chunks\", \"embed e5\", \"attribute\", \"index\"],\n",
- " ann=HNSW(distance_metric=\"angular\"),\n",
- " is_document_field=False,\n",
- " ),\n",
- " ],\n",
- " ),\n",
- " fieldsets=[FieldSet(name=\"default\", fields=[\"chunks\", \"title\"])],\n",
- ")"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "2834fe25",
- "metadata": {},
- "source": [
- "The above defines our `pdf` schema using mode `streaming`. Most fields are straightforward, but take a note of:\n",
- "\n",
- "- `metadata` using `map` - here we can store and match over page level metadata extracted by the PDF parser.\n",
- "- `chunks` using `array`, these are the text chunks that we use langchain document transformers for\n",
- "- The `embedding` field of type `tensor(chunk{},x[384])` allows us to store and search the 384-dimensional embeddings per chunk in the same document\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "4e2539f8",
- "metadata": {},
- "source": [
- "The observant reader might have noticed the `e5` argument to the `embed` expression in the above `embedding` field.\n",
- "The `e5` argument references a component of the type [hugging-face-embedder](https://docs.vespa.ai/en/embedding.html#huggingface-embedder). We configure\n",
- "the application package and its name with the `pdf` schema and the `e5` embedder component.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 3,
- "id": "66c5da1d",
- "metadata": {},
- "outputs": [],
- "source": [
- "from vespa.package import ApplicationPackage, Component, Parameter\n",
- "\n",
- "vespa_app_name = \"ragpdfs\"\n",
- "vespa_application_package = ApplicationPackage(\n",
- " name=vespa_app_name,\n",
- " schema=[pdf_schema],\n",
- " components=[\n",
- " Component(\n",
- " id=\"e5\",\n",
- " type=\"hugging-face-embedder\",\n",
- " parameters=[\n",
- " Parameter(\n",
- " \"transformer-model\",\n",
- " {\n",
- " \"url\": \"https://github.com/vespa-engine/sample-apps/raw/master/simple-semantic-search/model/e5-small-v2-int8.onnx\"\n",
- " },\n",
- " ),\n",
- " Parameter(\n",
- " \"tokenizer-model\",\n",
- " {\n",
- " \"url\": \"https://raw.githubusercontent.com/vespa-engine/sample-apps/master/simple-semantic-search/model/tokenizer.json\"\n",
- " },\n",
- " ),\n",
- " ],\n",
- " )\n",
- " ],\n",
- ")"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "7fe3d7bd",
- "metadata": {},
- "source": [
- "In the last step, we configure [ranking](https://docs.vespa.ai/en/ranking.html) by adding `rank-profile`'s to the schema.\n",
- "\n",
- "Vespa supports [phased ranking](https://docs.vespa.ai/en/phased-ranking.html) and has a rich set of built-in [rank-features](https://docs.vespa.ai/en/reference/rank-features.html), including many\n",
- "text-matching features such as:\n",
- "\n",
- "- [BM25](https://docs.vespa.ai/en/reference/bm25.html).\n",
- "- [nativeRank](https://docs.vespa.ai/en/reference/nativerank.html) and many more.\n",
- "\n",
- "Users can also define custom functions using [ranking expressions](https://docs.vespa.ai/en/reference/ranking-expressions.html). The following defines a `hybrid` Vespa ranking profile.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 4,
- "id": "a8ce5624",
- "metadata": {},
- "outputs": [],
- "source": [
- "from vespa.package import RankProfile, Function, FirstPhaseRanking\n",
- "\n",
- "\n",
- "semantic = RankProfile(\n",
- " name=\"hybrid\",\n",
- " inputs=[(\"query(q)\", \"tensor(x[384])\")],\n",
- " functions=[\n",
- " Function(\n",
- " name=\"similarities\",\n",
- " expression=\"cosine_similarity(query(q), attribute(embedding),x)\",\n",
- " )\n",
- " ],\n",
- " first_phase=FirstPhaseRanking(\n",
- " expression=\"nativeRank(title) + nativeRank(chunks) + reduce(similarities, max, chunk)\",\n",
- " rank_score_drop_limit=0.0,\n",
- " ),\n",
- " match_features=[\n",
- " \"closest(embedding)\",\n",
- " \"similarities\",\n",
- " \"nativeRank(chunks)\",\n",
- " \"nativeRank(title)\",\n",
- " \"elementSimilarity(chunks)\",\n",
- " ],\n",
- ")\n",
- "pdf_schema.add_rank_profile(semantic)"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "ce78268c",
- "metadata": {},
- "source": [
- "The `hybrid` rank-profile above defines the query input embedding type and a similarities function that\n",
- "uses a Vespa [tensor compute function](https://docs.vespa.ai/en/reference/ranking-expressions.html#tensor-functions) that calculates\n",
- "the cosine similarity between all the chunk embeddings and the query embedding.\n",
- "\n",
- "The profile only defines a single ranking phase, using a linear combination of multiple features.\n",
- "\n",
- "Using [match-features](https://docs.vespa.ai/en/reference/schema-reference.html#match-features), Vespa\n",
- "returns selected features along with the hit in the SERP (result page).\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "846545f9",
- "metadata": {},
- "source": [
- "## Deploy the application to Vespa Cloud\n",
- "\n",
- "With the configured application, we can deploy it to [Vespa Cloud](https://cloud.vespa.ai/en/).\n",
- "It is also possible to deploy the app using docker; see the [Hybrid Search - Quickstart](https://pyvespa.readthedocs.io/en/latest/getting-started-pyvespa.html) guide for\n",
- "an example of deploying it to a local docker container.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "16179d9b",
- "metadata": {},
- "source": [
- "Install the Vespa CLI.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "343981ce",
- "metadata": {},
- "outputs": [],
- "source": [
- "!pip3 install vespacli"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "0ff00727",
- "metadata": {},
- "source": [
- "To deploy the application to Vespa Cloud we need to create a tenant in the Vespa Cloud:\n",
- "\n",
- "Create a tenant at [console.vespa-cloud.com](https://console.vespa-cloud.com/) (unless you already have one).\n",
- "This step requires a Google or GitHub account, and will start your [free trial](https://cloud.vespa.ai/en/free-trial).\n",
- "Make note of the tenant name, it is used in the next steps.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "df9f9a1c",
- "metadata": {},
- "source": [
- "### Configure Vespa Cloud date-plane security\n",
- "\n",
- "Create Vespa Cloud data-plane mTLS cert/key-pair. The mutual certificate pair is used to talk to your Vespa cloud endpoints. See [Vespa Cloud Security Guide](https://cloud.vespa.ai/en/security/guide) for details.\n",
- "\n",
- "We save the paths to the credentials for later data-plane access without using pyvespa APIs.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "b6a766d6",
- "metadata": {},
- "outputs": [],
- "source": [
- "import os\n",
- "\n",
- "os.environ[\"TENANT_NAME\"] = \"vespa-team\" # Replace with your tenant name\n",
- "\n",
- "vespa_cli_command = (\n",
- " f'vespa config set application {os.environ[\"TENANT_NAME\"]}.{vespa_app_name}'\n",
- ")\n",
- "\n",
- "!vespa config set target cloud\n",
- "!{vespa_cli_command}\n",
- "!vespa auth cert -N"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "b228381b",
- "metadata": {},
- "source": [
- "Validate that we have the expected data-plane credential files:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 6,
- "id": "1f0b97c8",
- "metadata": {},
- "outputs": [],
- "source": [
- "from os.path import exists\n",
- "from pathlib import Path\n",
- "\n",
- "cert_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-public-cert.pem\"\n",
- ")\n",
- "key_path = (\n",
- " Path.home()\n",
- " / \".vespa\"\n",
- " / f\"{os.environ['TENANT_NAME']}.{vespa_app_name}.default/data-plane-private-key.pem\"\n",
- ")\n",
- "\n",
- "if not exists(cert_path) or not exists(key_path):\n",
- " print(\n",
- " \"ERROR: set the correct paths to security credentials. Correct paths above and rerun until you do not see this error\"\n",
- " )"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "85ce80e0",
- "metadata": {},
- "source": [
- "Note that the subsequent Vespa Cloud deploy call below will add `data-plane-public-cert.pem` to the application before deploying it to Vespa Cloud, so that\n",
- "you have access to both the private key and the public certificate. At the same time, Vespa Cloud only knows the public certificate.\n",
- "\n",
- "### Configure Vespa Cloud control-plane security\n",
- "\n",
- "Authenticate to generate a tenant level control plane API key for deploying the applications to Vespa Cloud, and save the path to it.\n",
- "\n",
- "The generated tenant api key must be added in the Vespa Console before attempting to deploy the application.\n",
- "\n",
- "```\n",
- "To use this key in Vespa Cloud click 'Add custom key' at\n",
- "https://console.vespa-cloud.com/tenant/TENANT_NAME/account/keys\n",
- "and paste the entire public key including the BEGIN and END lines.\n",
- "```\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "5bf8731c",
- "metadata": {},
- "outputs": [],
- "source": [
- "!vespa auth api-key\n",
- "\n",
- "from pathlib import Path\n",
- "\n",
- "api_key_path = Path.home() / \".vespa\" / f\"{os.environ['TENANT_NAME']}.api-key.pem\""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "21db1010",
- "metadata": {},
- "source": [
- "### Deploy to Vespa Cloud\n",
- "\n",
- "Now that we have data-plane and control-plane credentials ready, we can deploy our application to Vespa Cloud!\n",
- "\n",
- "`PyVespa` supports deploying apps to the [development zone](https://cloud.vespa.ai/en/reference/environments#dev-and-perf).\n",
- "\n",
- "> Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 8,
- "id": "b5fddf9f",
- "metadata": {},
- "outputs": [],
- "source": [
- "from vespa.deployment import VespaCloud\n",
- "\n",
- "\n",
- "def read_secret():\n",
- " \"\"\"Read the API key from the environment variable. This is\n",
- " only used for CI/CD purposes.\"\"\"\n",
- " t = os.getenv(\"VESPA_TEAM_API_KEY\")\n",
- " if t:\n",
- " return t.replace(r\"\\n\", \"\\n\")\n",
- " else:\n",
- " return t\n",
- "\n",
- "\n",
- "vespa_cloud = VespaCloud(\n",
- " tenant=os.environ[\"TENANT_NAME\"],\n",
- " application=vespa_app_name,\n",
- " key_content=read_secret() if read_secret() else None,\n",
- " key_location=api_key_path,\n",
- " application_package=vespa_application_package,\n",
- ")"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "fa9baa5a",
- "metadata": {},
- "source": [
- "Now deploy the app to Vespa Cloud dev zone.\n",
- "\n",
- "The first deployment typically takes 2 minutes until the endpoint is up.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 18,
- "id": "fe954dc4",
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Deployment started in run 2 of dev-aws-us-east-1c for samples.pdfs. This may take a few minutes the first time.\n",
- "INFO [17:23:35] Deploying platform version 8.270.8 and application dev build 2 for dev-aws-us-east-1c of default ...\n",
- "INFO [17:23:35] Using CA signed certificate version 0\n",
- "WARNING [17:23:35] For schema 'pdf', field 'page': Changed to attribute because numerical indexes (field has type int) is not currently supported. Index-only settings may fail. Ignore this warning for streaming search.\n",
- "INFO [17:23:35] Using 1 nodes in container cluster 'pdfs_container'\n",
- "WARNING [17:23:36] For streaming search cluster 'pdfs_content.pdf', SD field 'embedding': hnsw index is not relevant and not supported, ignoring setting\n",
- "WARNING [17:23:36] For streaming search cluster 'pdfs_content.pdf', SD field 'embedding': hnsw index is not relevant and not supported, ignoring setting\n",
- "INFO [17:23:38] Deployment successful.\n",
- "INFO [17:23:38] Session 3239 for tenant 'samples' prepared and activated.\n",
- "INFO [17:23:38] ######## Details for all nodes ########\n",
- "INFO [17:23:38] h88963a.dev.aws-us-east-1c.vespa-external.aws.oath.cloud: expected to be UP\n",
- "INFO [17:23:38] --- platform vespa/cloud-tenant-rhel8:8.270.8\n",
- "INFO [17:23:38] --- storagenode on port 19102 has config generation 3239, wanted is 3239\n",
- "INFO [17:23:38] --- searchnode on port 19107 has config generation 3239, wanted is 3239\n",
- "INFO [17:23:38] --- distributor on port 19111 has config generation 3238, wanted is 3239\n",
- "INFO [17:23:38] --- metricsproxy-container on port 19092 has config generation 3239, wanted is 3239\n",
- "INFO [17:23:38] h88969g.dev.aws-us-east-1c.vespa-external.aws.oath.cloud: expected to be UP\n",
- "INFO [17:23:38] --- platform vespa/cloud-tenant-rhel8:8.270.8\n",
- "INFO [17:23:38] --- logserver-container on port 4080 has config generation 3239, wanted is 3239\n",
- "INFO [17:23:38] --- metricsproxy-container on port 19092 has config generation 3239, wanted is 3239\n",
- "INFO [17:23:38] h88972i.dev.aws-us-east-1c.vespa-external.aws.oath.cloud: expected to be UP\n",
- "INFO [17:23:38] --- platform vespa/cloud-tenant-rhel8:8.270.8\n",
- "INFO [17:23:38] --- container-clustercontroller on port 19050 has config generation 3239, wanted is 3239\n",
- "INFO [17:23:38] --- metricsproxy-container on port 19092 has config generation 3239, wanted is 3239\n",
- "INFO [17:23:38] h89461a.dev.aws-us-east-1c.vespa-external.aws.oath.cloud: expected to be UP\n",
- "INFO [17:23:38] --- platform vespa/cloud-tenant-rhel8:8.270.8\n",
- "INFO [17:23:38] --- container on port 4080 has config generation 3239, wanted is 3239\n",
- "INFO [17:23:38] --- metricsproxy-container on port 19092 has config generation 3239, wanted is 3239\n",
- "INFO [17:23:51] Found endpoints:\n",
- "INFO [17:23:51] - dev.aws-us-east-1c\n",
- "INFO [17:23:51] |-- https://c4f42a1b.bfbdb4fd.z.vespa-app.cloud/ (cluster 'pdfs_container')\n",
- "INFO [17:23:52] Installation succeeded!\n",
- "Using mTLS (key,cert) Authentication against endpoint https://c4f42a1b.bfbdb4fd.z.vespa-app.cloud//ApplicationStatus\n",
- "Application is up!\n",
- "Finished deployment.\n"
- ]
- }
- ],
- "source": [
- "from vespa.application import Vespa\n",
- "\n",
- "app: Vespa = vespa_cloud.deploy()"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "4cde8f22",
- "metadata": {},
- "source": [
- "### Processing PDFs with LangChain\n",
- "\n",
- "[LangChain](https://python.langchain.com/) has a rich set of [document loaders](https://python.langchain.com/v0.1/docs/modules/data_connection/document_loaders/) that can be used to load and process various file formats. In this notebook, we use the [PyPDFLoader](https://python.langchain.com/v0.1/docs/modules/data_connection/document_loaders/pdf#using-pypdf).\n",
- "\n",
- "We also want to split the extracted text into _chunks_ using a [text splitter](https://python.langchain.com/v0.1/docs/modules/data_connection/document_transformers/). Most text embedding models have limited input lengths (typically less than 512 language model tokens, so splitting the text\n",
- "into multiple chunks that fits into the context limit of the embedding model is a common strategy.\n",
- "\n",
- "For embedding text data, models based on the Transformer architecture have become the de facto standard. A challenge with Transformer-based models is their input length limitation due to the quadratic self-attention computational complexity. For example, a popular open-source text embedding model like\n",
- "[e5](https://huggingface.co/intfloat/e5-small) has an absolute maximum input length of 512 wordpiece tokens. In addition to\n",
- "the technical limitation, trying to fit more tokens than used during fine-tuning of the model will impact the quality of the vector representation.\n",
- "\n",
- "One can view text embedding encoding as a lossy compression technique, where variable-length texts are compressed\n",
- "into a fixed dimensional vector representation.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 10,
- "id": "d9e42b0f",
- "metadata": {},
- "outputs": [],
- "source": [
- "from langchain_community.document_loaders import PyPDFLoader\n",
- "from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
- "\n",
- "text_splitter = RecursiveCharacterTextSplitter(\n",
- " chunk_size=1024, # chars, not llm tokens\n",
- " chunk_overlap=0,\n",
- " length_function=len,\n",
- " is_separator_regex=False,\n",
- ")"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "adaccdfc",
- "metadata": {},
- "source": [
- "The following iterates over the `sample_pdfs` and performs the following:\n",
- "\n",
- "- Load the URL and extract the text into pages. A page is the retrievable unit we will use in Vespa\n",
- "- For each page, use the text splitter to split the text into chunks. The chunks are represented as an `array` in the Vespa schema\n",
- "- Create the page level Vespa `fields`, note that we duplicate some content like the title and URL into the page level representation.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 11,
- "id": "bf8ac8c7",
- "metadata": {},
- "outputs": [],
- "source": [
- "import hashlib\n",
- "import unicodedata\n",
- "\n",
- "\n",
- "def remove_control_characters(s):\n",
- " return \"\".join(ch for ch in s if unicodedata.category(ch)[0] != \"C\")\n",
- "\n",
- "\n",
- "my_docs_to_feed = []\n",
- "for pdf in sample_pdfs():\n",
- " url = pdf[\"url\"]\n",
- " loader = PyPDFLoader(url)\n",
- " pages = loader.load_and_split()\n",
- " for index, page in enumerate(pages):\n",
- " source = page.metadata[\"source\"]\n",
- " chunks = text_splitter.transform_documents([page])\n",
- " text_chunks = [chunk.page_content for chunk in chunks]\n",
- " text_chunks = [remove_control_characters(chunk) for chunk in text_chunks]\n",
- " page_number = index + 1\n",
- " vespa_id = f\"{url}#{page_number}\"\n",
- " hash_value = hashlib.sha1(vespa_id.encode()).hexdigest()\n",
- " fields = {\n",
- " \"title\": pdf[\"title\"],\n",
- " \"url\": url,\n",
- " \"page\": page_number,\n",
- " \"id\": hash_value,\n",
- " \"authors\": [a.strip() for a in pdf[\"authors\"].split(\",\")],\n",
- " \"chunks\": text_chunks,\n",
- " \"metadata\": page.metadata,\n",
- " }\n",
- " my_docs_to_feed.append(fields)"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "54db44b1",
- "metadata": {},
- "source": [
- "Now that we have parsed the input PDFs and created a list of pages that we want to add to Vespa, we must format the\n",
- "list into the format that PyVespa accepts. Notice the `fields`, `id` and `groupname` keys. The `groupname` is the\n",
- "key that is used to shard and co-locate the data and is only relevant when using Vespa with streaming mode.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 12,
- "id": "bcbfa981",
- "metadata": {},
- "outputs": [],
- "source": [
- "from typing import Iterable\n",
- "\n",
- "\n",
- "def vespa_feed(user: str) -> Iterable[dict]:\n",
- " for doc in my_docs_to_feed:\n",
- " yield {\"fields\": doc, \"id\": doc[\"id\"], \"groupname\": user}"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "2ff628ac",
- "metadata": {},
- "source": [
- "Now, we can feed to the Vespa instance (`app`), using the `feed_iterable` API, using the generator function above as input\n",
- "with a custom `callback` function. Vespa also performs embedding inference during this step using the built-in Vespa [embedding](https://docs.vespa.ai/en/embedding.html#huggingface-embedder) functionality.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 13,
- "id": "dc1b3029",
- "metadata": {},
- "outputs": [],
- "source": [
- "from vespa.io import VespaResponse\n",
- "\n",
- "\n",
- "def callback(response: VespaResponse, id: str):\n",
- " if not response.is_successful():\n",
- " print(\n",
- " f\"Document {id} failed to feed with status code {response.status_code}, url={response.url} response={response.json}\"\n",
- " )\n",
- "\n",
- "\n",
- "app.feed_iterable(\n",
- " schema=\"pdf\", iter=vespa_feed(\"jo-bergum\"), namespace=\"personal\", callback=callback\n",
- ")"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "431dc2f9",
- "metadata": {},
- "source": [
- "Notice the `schema` and `namespace` arguments. PyVespa transforms the input operations to Vespa [document v1](https://docs.vespa.ai/en/document-v1-api-guide.html)\n",
- "requests.\n",
- "\n",
- "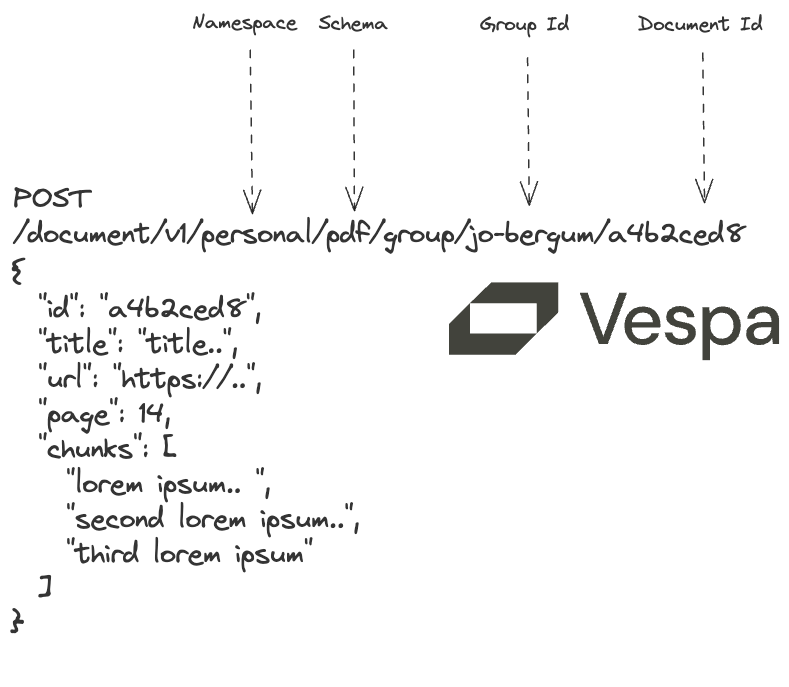\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "20b007ec",
- "metadata": {},
- "source": [
- "### Querying data\n",
- "\n",
- "Now, we can also query our data. With [streaming mode](https://docs.vespa.ai/en/reference/query-api-reference.html#streaming),\n",
- "we must pass the `groupname` parameter, or the request will fail with an error.\n",
- "\n",
- "The query request uses the Vespa Query API and the `Vespa.query()` function\n",
- "supports passing any of the Vespa query API parameters.\n",
- "\n",
- "Read more about querying Vespa in:\n",
- "\n",
- "- [Vespa Query API](https://docs.vespa.ai/en/query-api.html)\n",
- "- [Vespa Query API reference](https://docs.vespa.ai/en/reference/query-api-reference.html)\n",
- "- [Vespa Query Language API (YQL)](https://docs.vespa.ai/en/query-language.html)\n",
- "\n",
- "Sample query request for `why is colbert effective?` for the user `bergum@vespa.ai`:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 15,
- "id": "b9349fb4",
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "{\n",
- " \"id\": \"id:personal:pdf:g=jo-bergum:a4b2ced87807ee9cb0325b7a1c64a070d05a31f7\",\n",
- " \"relevance\": 1.1412738851962692,\n",
- " \"source\": \"pdfs_content.pdf\",\n",
- " \"fields\": {\n",
- " \"matchfeatures\": {\n",
- " \"closest(embedding)\": {\n",
- " \"0\": 1.0\n",
- " },\n",
- " \"elementSimilarity(chunks)\": 0.5006379585326953,\n",
- " \"nativeRank(chunks)\": 0.15642522855051508,\n",
- " \"nativeRank(title)\": 0.1341324233922751,\n",
- " \"similarities\": {\n",
- " \"1\": 0.7731813192367554,\n",
- " \"2\": 0.8196794986724854,\n",
- " \"3\": 0.796222984790802,\n",
- " \"4\": 0.7699441909790039,\n",
- " \"0\": 0.850716233253479\n",
- " }\n",
- " },\n",
- " \"id\": \"a4b2ced87807ee9cb0325b7a1c64a070d05a31f7\",\n",
- " \"title\": \"ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT\",\n",
- " \"page\": 9,\n",
- " \"chunks\": [\n",
- " \"Sq,d:=\\u00d5i\\u2208[|Eq|]maxj\\u2208[|Ed|]Eqi\\u00b7ETdj(3)ColBERT is di\\ufb00erentiable end-to-end. We /f_ine-tune the BERTencoders and train from scratch the additional parameters (i.e., thelinear layer and the [Q] and [D] markers\\u2019 embeddings) using theAdam [ 16] optimizer. Notice that our interaction mechanism hasno trainable parameters. Given a triple \\u27e8q,d+,d\\u2212\\u27e9with query q,positive document d+and negative document d\\u2212, ColBERT is usedto produce a score for each document individually and is optimizedvia pairwise so/f_tmax cross-entropy loss over the computed scoresofd+andd\\u2212.3.4 O\\ufb00line Indexing: Computing & StoringDocument EmbeddingsBy design, ColBERT isolates almost all of the computations betweenqueries and documents, largely to enable pre-computing documentrepresentations o\\ufb04ine. At a high level, our indexing procedure isstraight-forward: we proceed over the documents in the collectionin batches, running our document encoder fDon each batch andstoring the output embeddings per document. Although indexing\",\n",
- " \"a set of documents is an o\\ufb04ine process, we incorporate a fewsimple optimizations for enhancing the throughput of indexing. Aswe show in \\u00a74.5, these optimizations can considerably reduce theo\\ufb04ine cost of indexing.To begin with, we exploit multiple GPUs, if available, for fasterencoding of batches of documents in parallel. When batching, wepad all documents to the maximum length of a document withinthe batch.3To make capping the sequence length on a per-batchbasis more e\\ufb00ective, our indexer proceeds through documents ingroups of B(e.g., B=100,000) documents. It sorts these documentsby length and then feeds batches of b(e.g., b=128) documents ofcomparable length through our encoder. /T_his length-based bucket-ing is sometimes refered to as a BucketIterator in some libraries(e.g., allenNLP). Lastly, while most computations occur on the GPU,we found that a non-trivial portion of the indexing time is spent onpre-processing the text sequences, primarily BERT\\u2019s WordPiece to-\",\n",
- " \"kenization. Exploiting that these operations are independent acrossdocuments in a batch, we parallelize the pre-processing across theavailable CPU cores.Once the document representations are produced, they are savedto disk using 32-bit or 16-bit values to represent each dimension.As we describe in \\u00a73.5 and 3.6, these representations are eithersimply loaded from disk for ranking or are subsequently indexedfor vector-similarity search, respectively.3.5 Top- kRe-ranking with ColBERTRecall that ColBERT can be used for re-ranking the output of an-other retrieval model, typically a term-based model, or directlyfor end-to-end retrieval from a document collection. In this sec-tion, we discuss how we use ColBERT for ranking a small set ofk(e.g., k=1000) documents given a query q. Since kis small, werely on batch computations to exhaustively score each document\",\n",
- " \"3/T_he public BERT implementations we saw simply pad to a pre-de/f_ined length.(unlike our approach in \\u00a73.6). To begin with, our query serving sub-system loads the indexed documents representations into memory,representing each document as a matrix of embeddings.Given a query q, we compute its bag of contextualized embed-dings Eq(Equation 1) and, concurrently, gather the document repre-sentations into a 3-dimensional tensor Dconsisting of kdocumentmatrices. We pad the kdocuments to their maximum length tofacilitate batched operations, and move the tensor Dto the GPU\\u2019smemory. On the GPU, we compute a batch dot-product of EqandD, possibly over multiple mini-batches. /T_he output materializes a3-dimensional tensor that is a collection of cross-match matricesbetween qand each document. To compute the score of each docu-ment, we reduce its matrix across document terms via a max-pool(i.e., representing an exhaustive implementation of our MaxSim\",\n",
- " \"computation) and reduce across query terms via a summation. Fi-nally, we sort the kdocuments by their total scores.\"\n",
- " ]\n",
- " }\n",
- "}\n"
- ]
- }
- ],
- "source": [
- "from vespa.io import VespaQueryResponse\n",
- "import json\n",
- "\n",
- "response: VespaQueryResponse = app.query(\n",
- " yql=\"select id,title,page,chunks from pdf where userQuery() or ({targetHits:10}nearestNeighbor(embedding,q))\",\n",
- " groupname=\"jo-bergum\",\n",
- " ranking=\"hybrid\",\n",
- " query=\"why is colbert effective?\",\n",
- " body={\n",
- " \"presentation.format.tensors\": \"short-value\",\n",
- " \"input.query(q)\": 'embed(e5, \"why is colbert effective?\")',\n",
- " },\n",
- " timeout=\"2s\",\n",
- ")\n",
- "assert response.is_successful()\n",
- "print(json.dumps(response.hits[0], indent=2))"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "4d3ca1da",
- "metadata": {},
- "source": [
- "Notice the `matchfeatures` that returns the configured match-features from the rank-profile, including all the chunk similarities.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "57f323df",
- "metadata": {},
- "source": [
- "## LangChain Retriever\n",
- "\n",
- "We use the [LangChain Retriever](https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/) interface so that\n",
- "we can connect our Vespa app with the flexibility and power of the [LangChain](https://python.langchain.com/v0.1/docs/get_started/introduction) LLM framework.\n",
- "\n",
- "> A retriever is an interface that returns documents given an unstructured query. It is more general than a vector store. A retriever does not need to be able to store documents, only to return (or retrieve) them. Vector stores can be used as the backbone of a retriever, but there are other types of retrievers as well.\n",
- "\n",
- "The retriever interface fits perfectly with Vespa, as Vespa can support a wide range of features and ways to retrieve and\n",
- "rank content. The following implements a custom retriever `VespaStreamingHybridRetriever` that takes the following arguments:\n",
- "\n",
- "- `app:Vespa` The Vespa application we retrieve from. This could be a Vespa Cloud instance or a local instance, for example running on a laptop.\n",
- "- `user:str` The user that that we want to retrieve for, this argument maps to the [Vespa streaming mode groupname parameter](https://docs.vespa.ai/en/reference/query-api-reference.html#streaming.groupname)\n",
- "- `pages:int` The target number of PDF pages we want to retrieve for a given query\n",
- "- `chunks_per_page` The is the target number of relevant text chunks that are associated with the page\n",
- "- `chunk_similarity_threshold` - The chunk similarity threshold, only chunks with a similarity above this threshold\n",
- "\n",
- "The core idea is to _retrieve_ pages using maximum chunk similarity as the initial scoring function, then consider other chunks on the same page potentially relevant.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 19,
- "id": "c5b7c0d1",
- "metadata": {},
- "outputs": [],
- "source": [
- "from langchain_core.documents import Document\n",
- "from langchain_core.retrievers import BaseRetriever\n",
- "from typing import List\n",
- "\n",
- "\n",
- "class VespaStreamingHybridRetriever(BaseRetriever):\n",
- " app: Vespa\n",
- " user: str\n",
- " pages: int = 5\n",
- " chunks_per_page: int = 3\n",
- " chunk_similarity_threshold: float = 0.8\n",
- "\n",
- " def _get_relevant_documents(self, query: str) -> List[Document]:\n",
- " response: VespaQueryResponse = self.app.query(\n",
- " yql=\"select id, url, title, page, authors, chunks from pdf where userQuery() or ({targetHits:20}nearestNeighbor(embedding,q))\",\n",
- " groupname=self.user,\n",
- " ranking=\"hybrid\",\n",
- " query=query,\n",
- " hits=self.pages,\n",
- " body={\n",
- " \"presentation.format.tensors\": \"short-value\",\n",
- " \"input.query(q)\": f'embed(e5, \"query: {query} \")',\n",
- " },\n",
- " timeout=\"2s\",\n",
- " )\n",
- " if not response.is_successful():\n",
- " raise ValueError(\n",
- " f\"Query failed with status code {response.status_code}, url={response.url} response={response.json}\"\n",
- " )\n",
- " return self._parse_response(response)\n",
- "\n",
- " def _parse_response(self, response: VespaQueryResponse) -> List[Document]:\n",
- " documents: List[Document] = []\n",
- " for hit in response.hits:\n",
- " fields = hit[\"fields\"]\n",
- " chunks_with_scores = self._get_chunk_similarities(fields)\n",
- " ## Best k chunks from each page\n",
- " best_chunks_on_page = \" ### \".join(\n",
- " [\n",
- " chunk\n",
- " for chunk, score in chunks_with_scores[0 : self.chunks_per_page]\n",
- " if score > self.chunk_similarity_threshold\n",
- " ]\n",
- " )\n",
- " documents.append(\n",
- " Document(\n",
- " id=fields[\"id\"],\n",
- " page_content=best_chunks_on_page,\n",
- " title=fields[\"title\"],\n",
- " metadata={\n",
- " \"title\": fields[\"title\"],\n",
- " \"url\": fields[\"url\"],\n",
- " \"page\": fields[\"page\"],\n",
- " \"authors\": fields[\"authors\"],\n",
- " \"features\": fields[\"matchfeatures\"],\n",
- " },\n",
- " )\n",
- " )\n",
- " return documents\n",
- "\n",
- " def _get_chunk_similarities(self, hit_fields: dict) -> List[tuple]:\n",
- " match_features = hit_fields[\"matchfeatures\"]\n",
- " similarities = match_features[\"similarities\"]\n",
- " chunk_scores = []\n",
- " for i in range(0, len(similarities)):\n",
- " chunk_scores.append(similarities.get(str(i), 0))\n",
- " chunks = hit_fields[\"chunks\"]\n",
- " chunks_with_scores = list(zip(chunks, chunk_scores))\n",
- " return sorted(chunks_with_scores, key=lambda x: x[1], reverse=True)"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "341dd861",
- "metadata": {},
- "source": [
- "That's it! We can give our newborn retriever a spin for the user `jo-bergum` by\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 20,
- "id": "ac9088a4",
- "metadata": {},
- "outputs": [],
- "source": [
- "vespa_hybrid_retriever = VespaStreamingHybridRetriever(\n",
- " app=app, user=\"jo-bergum\", pages=1, chunks_per_page=1\n",
- ")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 21,
- "id": "3198db04",
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "[Document(page_content='ture that precisely does so. As illustrated, every query embeddinginteracts with all document embeddings via a MaxSim operator,which computes maximum similarity (e.g., cosine similarity), andthe scalar outputs of these operators are summed across queryterms. /T_his paradigm allows ColBERT to exploit deep LM-basedrepresentations while shi/f_ting the cost of encoding documents of-/f_line and amortizing the cost of encoding the query once acrossall ranked documents. Additionally, it enables ColBERT to lever-age vector-similarity search indexes (e.g., [ 1,15]) to retrieve thetop-kresults directly from a large document collection, substan-tially improving recall over models that only re-rank the output ofterm-based retrieval.As Figure 1 illustrates, ColBERT can serve queries in tens orfew hundreds of milliseconds. For instance, when used for re-ranking as in “ColBERT (re-rank)”, it delivers over 170 ×speedup(and requires 14,000 ×fewer FLOPs) relative to existing BERT-based', metadata={'title': 'ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT', 'url': 'https://arxiv.org/pdf/2004.12832.pdf', 'page': 4, 'authors': ['Omar Khattab', 'Matei Zaharia'], 'features': {'closest(embedding)': {'0': 1.0}, 'elementSimilarity(chunks)': 0.41768707482993195, 'nativeRank(chunks)': 0.1401101487033024, 'nativeRank(title)': 0.0520403737720047, 'similarities': {'1': 0.8369992971420288, '0': 0.8730311393737793}}})]"
- ]
- },
- "execution_count": 21,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "vespa_hybrid_retriever.get_relevant_documents(\"what is the maxsim operator in colbert?\")"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "fcca4fc7",
- "metadata": {},
- "source": [
- "## RAG\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "a84b98db",
- "metadata": {},
- "source": [
- "Finally, we can connect our custom retriever with the complete flexibility and power of the [LangChain] LLM framework.\n",
- "The following uses [LangChain Expression Language, or LCEL](https://python.langchain.com/v0.1/docs/expression_language/), a declarative way to compose chains.\n",
- "\n",
- "We have several steps composed into a chain:\n",
- "\n",
- "- The prompt template and LLM model, in this case using OpenAI\n",
- "- The retriever that provides the retrieved context for the question\n",
- "- The formatting of the retrieved context\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 22,
- "id": "e3dcf5b4",
- "metadata": {},
- "outputs": [],
- "source": [
- "vespa_hybrid_retriever = VespaStreamingHybridRetriever(\n",
- " app=app, user=\"jo-bergum\", pages=3, chunks_per_page=3\n",
- ")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 25,
- "id": "d95473dc",
- "metadata": {},
- "outputs": [],
- "source": [
- "from langchain.chat_models import ChatOpenAI\n",
- "from langchain.prompts import ChatPromptTemplate\n",
- "from langchain.schema import StrOutputParser\n",
- "from langchain.schema.runnable import RunnablePassthrough\n",
- "\n",
- "prompt_template = \"\"\"\n",
- "Answer the question based only on the following context. \n",
- "Cite the page number and the url of the document you are citing.\n",
- "\n",
- "{context}\n",
- "Question: {question}\n",
- "\"\"\"\n",
- "prompt = ChatPromptTemplate.from_template(prompt_template)\n",
- "model = ChatOpenAI()\n",
- "\n",
- "\n",
- "def format_prompt_context(docs) -> str:\n",
- " context = []\n",
- " for d in docs:\n",
- " context.append(f\"{d.metadata['title']} by {d.metadata['authors']}\\n\")\n",
- " context.append(f\"url: {d.metadata['url']}\\n\")\n",
- " context.append(f\"page: {d.metadata['page']}\\n\")\n",
- " context.append(f\"{d.page_content}\\n\\n\")\n",
- " return \"\".join(context)\n",
- "\n",
- "\n",
- "chain = (\n",
- " {\n",
- " \"context\": vespa_hybrid_retriever | format_prompt_context,\n",
- " \"question\": RunnablePassthrough(),\n",
- " }\n",
- " | prompt\n",
- " | model\n",
- " | StrOutputParser()\n",
- ")"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "562d2c7d",
- "metadata": {},
- "source": [
- "### Interact with the chain\n",
- "\n",
- "Now, we can start asking questions using the `chain` define above.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 26,
- "id": "36f7f092",
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "'ColBERT is a ranking model that adapts deep language models, specifically BERT, for efficient retrieval. It introduces a late interaction architecture that independently encodes queries and documents using BERT and then uses a cheap yet powerful interaction step to model their fine-grained similarity. This allows ColBERT to leverage the expressiveness of deep language models while also being able to pre-compute document representations offline, significantly speeding up query processing. ColBERT can be used for re-ranking documents retrieved by a traditional model or for end-to-end retrieval directly from a large document collection. It has been shown to be effective and efficient compared to existing models. (source: ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT by Omar Khattab, Matei Zaharia, page 1, url: https://arxiv.org/pdf/2004.12832.pdf)'"
- ]
- },
- "execution_count": 26,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "chain.invoke(\"what is colbert?\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 27,
- "id": "569929de",
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "\"The ColBERT model utilizes the MaxSim operator, which computes the maximum similarity (e.g., cosine similarity) between query embeddings and document embeddings. The scalar outputs of these operators are summed across query terms, allowing ColBERT to exploit deep LM-based representations while reducing the cost of encoding documents offline and amortizing the cost of encoding the query once across all ranked documents.\\n\\nSource: \\nColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT by ['Omar Khattab', 'Matei Zaharia']\\nURL: https://arxiv.org/pdf/2004.12832.pdf\\nPage: 4\""
- ]
- },
- "execution_count": 27,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "chain.invoke(\"what is the colbert maxsim operator\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 28,
- "id": "fde46620",
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "'The difference between ColBERT and single vector representational models is that ColBERT utilizes a late interaction architecture that independently encodes the query and the document using BERT, while single vector models use a single embedding vector for both the query and the document. This late interaction mechanism in ColBERT allows for fine-grained similarity estimation, which leads to more effective retrieval. (Source: ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT by Omar Khattab and Matei Zaharia, page 17, url: https://arxiv.org/pdf/2004.12832.pdf)'"
- ]
- },
- "execution_count": 28,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "chain.invoke(\n",
- " \"What is the difference between colbert and single vector representational models?\"\n",
- ")"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "7c8b8223",
- "metadata": {},
- "source": [
- "## Summary\n",
- "\n",
- "Vespa’s streaming mode is a game-changer, enabling the creation of highly cost-effective RAG applications for naturally partitioned data.\n",
- "\n",
- "In this notebook, we delved into the hands-on application of [LangChain](https://python.langchain.com/v0.1/docs/get_started/introduction),\n",
- "leveraging document loaders and transformers. Finally, we showcased a custom LangChain retriever that connected\n",
- "all the functionality of LangChain with Vespa.\n",
- "\n",
- "For those interested in learning more about Vespa, join the [Vespa community on Slack](https://vespatalk.slack.com/) to exchange ideas,\n",
- "seek assistance, or stay in the loop on the latest Vespa developments.\n",
- "\n",
- "We can now delete the cloud instance:\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "71e310e3",
- "metadata": {},
- "outputs": [],
- "source": [
- "vespa_cloud.delete()"
- ]
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3.11.4 64-bit",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.11.4"
- },
- "vscode": {
- "interpreter": {
- "hash": "b0fa6594d8f4cbf19f97940f81e996739fb7646882a419484c72d19e05852a7e"
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 5
-}
\ No newline at end of file
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "b3ae8a2b",
+ "metadata": {},
+ "source": [
+ "\n",
+ " \n",
+ " \n",
+ " \n",
+ "\n",
+ "\n",
+ "# Turbocharge RAG with LangChain and Vespa Streaming Mode for Partitioned Data\n",
+ "\n",
+ "This notebook illustrates using [Vespa streaming mode](https://docs.vespa.ai/en/streaming-search.html)\n",
+ "to build cost-efficient RAG applications over naturally sharded data.\n",
+ "\n",
+ "You can read more about Vespa vector streaming search in these blog posts:\n",
+ "\n",
+ "- [Announcing vector streaming search: AI assistants at scale without breaking the bank](https://blog.vespa.ai/announcing-vector-streaming-search/)\n",
+ "- [Yahoo Mail turns to Vespa to do RAG at scale](https://blog.vespa.ai/yahoo-mail-turns-to-vespa-to-do-rag-at-scale/)\n",
+ "- [Hands-On RAG guide for personal data with Vespa and LLamaIndex](https://blog.vespa.ai/scaling-personal-ai-assistants-with-streaming-mode/)\n",
+ "\n",
+ "This notebook is also available in blog form: [Turbocharge RAG with LangChain and Vespa Streaming Mode for Sharded Data](https://blog.vespa.ai/turbocharge-rag-with-langchain-and-vespa-streaming-mode/)\n",
+ "\n",
+ "### TLDR; Vespa streaming mode for partitioned data\n",
+ "\n",
+ "Vespa's streaming search solution enables you to integrate a user ID (or any sharding key) into the Vespa document ID.\n",
+ "This setup allows Vespa to efficiently group each user's data on a small set of nodes and the same disk chunk.\n",
+ "Streaming mode enables low latency searches on a user's data without keeping data in memory.\n",
+ "\n",
+ "The key benefits of streaming mode:\n",
+ "\n",
+ "- Eliminating compromises in precision introduced by approximate algorithms\n",
+ "- Achieve significantly higher write throughput, thanks to the absence of index builds required for supporting approximate search.\n",
+ "- Optimize efficiency by storing documents, including tensors and data, on disk, benefiting from the cost-effective economics of storage tiers.\n",
+ "- Storage cost is the primary cost driver of Vespa streaming mode; no data is in memory. Avoiding memory usage lowers deployment costs significantly.\n",
+ "\n",
+ "### Connecting LangChain Retriever with Vespa for Context Retrieval from PDF Documents\n",
+ "\n",
+ "In this notebook, we seamlessly integrate a custom [LangChain](https://python.langchain.com/v0.1/docs/get_started/introduction)\n",
+ "[retriever](https://python.langchain.com/v0.1/docs/modules/data_connection/) with a Vespa app,\n",
+ "leveraging Vespa's streaming mode to extract meaningful context from PDF documents.\n",
+ "\n",
+ "The workflow\n",
+ "\n",
+ "- Define and deploy a Vespa [application package](https://docs.vespa.ai/en/application-packages.html) using PyVespa.\n",
+ "- Utilize [LangChain PDF Loaders](https://python.langchain.com/v0.1/docs/modules/data_connection/document_loaders/pdf) to download and parse PDF files.\n",
+ "- Leverage [LangChain Document Transformers](https://python.langchain.com/v0.1/docs/modules/data_connection/document_transformers/)\n",
+ " to convert each PDF page into multiple text chunks.\n",
+ "- Feed the transformer representation to the running Vespa instance\n",
+ "- Employ Vespa's built-in embedder functionality (using an open-source embedding model) for embedding the text chunks per page, resulting in a multi-vector representation.\n",
+ "- Develop a custom [Retriever](https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/) to enable seamless retrieval for any unstructured text query.\n",
+ "\n",
+ "\n",
+ "\n",
+ "[](https://colab.research.google.com/github/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/turbocharge-rag-with-langchain-and-vespa-streaming-mode-cloud.ipynb)\n",
+ "\n",
+ "Let's get started! First, install dependencies:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4ffa3cbe",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip3 install -U pyvespa langchain langchain-community pypdf openai"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fd3b1e45",
+ "metadata": {},
+ "source": [
+ "## Sample data\n",
+ "\n",
+ "We love [ColBERT](https://blog.vespa.ai/pretrained-transformer-language-models-for-search-part-3/), so\n",
+ "we'll use a few COlBERT related papers as examples of PDFs in this notebook.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "384c4c56",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def sample_pdfs():\n",
+ " return [\n",
+ " {\n",
+ " \"title\": \"ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction\",\n",
+ " \"url\": \"https://arxiv.org/pdf/2112.01488.pdf\",\n",
+ " \"authors\": \"Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, Matei Zaharia\",\n",
+ " },\n",
+ " {\n",
+ " \"title\": \"ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT\",\n",
+ " \"url\": \"https://arxiv.org/pdf/2004.12832.pdf\",\n",
+ " \"authors\": \"Omar Khattab, Matei Zaharia\",\n",
+ " },\n",
+ " {\n",
+ " \"title\": \"On Approximate Nearest Neighbour Selection for Multi-Stage Dense Retrieval\",\n",
+ " \"url\": \"https://arxiv.org/pdf/2108.11480.pdf\",\n",
+ " \"authors\": \"Craig Macdonald, Nicola Tonellotto\",\n",
+ " },\n",
+ " {\n",
+ " \"title\": \"A Study on Token Pruning for ColBERT\",\n",
+ " \"url\": \"https://arxiv.org/pdf/2112.06540.pdf\",\n",
+ " \"authors\": \"Carlos Lassance, Maroua Maachou, Joohee Park, Stéphane Clinchant\",\n",
+ " },\n",
+ " {\n",
+ " \"title\": \"Pseudo-Relevance Feedback for Multiple Representation Dense Retrieval\",\n",
+ " \"url\": \"https://arxiv.org/pdf/2106.11251.pdf\",\n",
+ " \"authors\": \"Xiao Wang, Craig Macdonald, Nicola Tonellotto, Iadh Ounis\",\n",
+ " },\n",
+ " ]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "da356d25",
+ "metadata": {},
+ "source": [
+ "## Defining the Vespa application\n",
+ "\n",
+ "[PyVespa](https://pyvespa.readthedocs.io/en/latest/) helps us build the [Vespa application package](https://docs.vespa.ai/en/application-packages.html).\n",
+ "A Vespa application package consists of configuration files, schemas, models, and code (plugins).\n",
+ "\n",
+ "First, we define a [Vespa schema](https://docs.vespa.ai/en/schemas.html) with the fields we want to store and their type.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "0dca2378",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from vespa.package import Schema, Document, Field, FieldSet, HNSW\n",
+ "\n",
+ "pdf_schema = Schema(\n",
+ " name=\"pdf\",\n",
+ " mode=\"streaming\",\n",
+ " document=Document(\n",
+ " fields=[\n",
+ " Field(name=\"id\", type=\"string\", indexing=[\"summary\", \"index\"]),\n",
+ " Field(name=\"title\", type=\"string\", indexing=[\"summary\", \"index\"]),\n",
+ " Field(name=\"url\", type=\"string\", indexing=[\"summary\", \"index\"]),\n",
+ " Field(name=\"authors\", type=\"array\", indexing=[\"summary\", \"index\"]),\n",
+ " Field(name=\"page\", type=\"int\", indexing=[\"summary\", \"index\"]),\n",
+ " Field(\n",
+ " name=\"metadata\",\n",
+ " type=\"map\",\n",
+ " indexing=[\"summary\", \"index\"],\n",
+ " ),\n",
+ " Field(name=\"chunks\", type=\"array\", indexing=[\"summary\", \"index\"]),\n",
+ " Field(\n",
+ " name=\"embedding\",\n",
+ " type=\"tensor(chunk{}, x[384])\",\n",
+ " indexing=[\"input chunks\", \"embed e5\", \"attribute\", \"index\"],\n",
+ " ann=HNSW(distance_metric=\"angular\"),\n",
+ " is_document_field=False,\n",
+ " ),\n",
+ " ],\n",
+ " ),\n",
+ " fieldsets=[FieldSet(name=\"default\", fields=[\"chunks\", \"title\"])],\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2834fe25",
+ "metadata": {},
+ "source": [
+ "The above defines our `pdf` schema using mode `streaming`. Most fields are straightforward, but take a note of:\n",
+ "\n",
+ "- `metadata` using `map` - here we can store and match over page level metadata extracted by the PDF parser.\n",
+ "- `chunks` using `array`, these are the text chunks that we use langchain document transformers for\n",
+ "- The `embedding` field of type `tensor(chunk{},x[384])` allows us to store and search the 384-dimensional embeddings per chunk in the same document\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4e2539f8",
+ "metadata": {},
+ "source": [
+ "The observant reader might have noticed the `e5` argument to the `embed` expression in the above `embedding` field.\n",
+ "The `e5` argument references a component of the type [hugging-face-embedder](https://docs.vespa.ai/en/embedding.html#huggingface-embedder). We configure\n",
+ "the application package and its name with the `pdf` schema and the `e5` embedder component.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "66c5da1d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from vespa.package import ApplicationPackage, Component, Parameter\n",
+ "\n",
+ "vespa_app_name = \"ragpdfs\"\n",
+ "vespa_application_package = ApplicationPackage(\n",
+ " name=vespa_app_name,\n",
+ " schema=[pdf_schema],\n",
+ " components=[\n",
+ " Component(\n",
+ " id=\"e5\",\n",
+ " type=\"hugging-face-embedder\",\n",
+ " parameters=[\n",
+ " Parameter(\n",
+ " \"transformer-model\",\n",
+ " {\n",
+ " \"url\": \"https://github.com/vespa-engine/sample-apps/raw/master/simple-semantic-search/model/e5-small-v2-int8.onnx\"\n",
+ " },\n",
+ " ),\n",
+ " Parameter(\n",
+ " \"tokenizer-model\",\n",
+ " {\n",
+ " \"url\": \"https://raw.githubusercontent.com/vespa-engine/sample-apps/master/simple-semantic-search/model/tokenizer.json\"\n",
+ " },\n",
+ " ),\n",
+ " ],\n",
+ " )\n",
+ " ],\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7fe3d7bd",
+ "metadata": {},
+ "source": [
+ "In the last step, we configure [ranking](https://docs.vespa.ai/en/ranking.html) by adding `rank-profile`'s to the schema.\n",
+ "\n",
+ "Vespa supports [phased ranking](https://docs.vespa.ai/en/phased-ranking.html) and has a rich set of built-in [rank-features](https://docs.vespa.ai/en/reference/rank-features.html), including many\n",
+ "text-matching features such as:\n",
+ "\n",
+ "- [BM25](https://docs.vespa.ai/en/reference/bm25.html).\n",
+ "- [nativeRank](https://docs.vespa.ai/en/reference/nativerank.html) and many more.\n",
+ "\n",
+ "Users can also define custom functions using [ranking expressions](https://docs.vespa.ai/en/reference/ranking-expressions.html). The following defines a `hybrid` Vespa ranking profile.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "a8ce5624",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from vespa.package import RankProfile, Function, FirstPhaseRanking\n",
+ "\n",
+ "\n",
+ "semantic = RankProfile(\n",
+ " name=\"hybrid\",\n",
+ " inputs=[(\"query(q)\", \"tensor(x[384])\")],\n",
+ " functions=[\n",
+ " Function(\n",
+ " name=\"similarities\",\n",
+ " expression=\"cosine_similarity(query(q), attribute(embedding),x)\",\n",
+ " )\n",
+ " ],\n",
+ " first_phase=FirstPhaseRanking(\n",
+ " expression=\"nativeRank(title) + nativeRank(chunks) + reduce(similarities, max, chunk)\",\n",
+ " rank_score_drop_limit=0.0,\n",
+ " ),\n",
+ " match_features=[\n",
+ " \"closest(embedding)\",\n",
+ " \"similarities\",\n",
+ " \"nativeRank(chunks)\",\n",
+ " \"nativeRank(title)\",\n",
+ " \"elementSimilarity(chunks)\",\n",
+ " ],\n",
+ ")\n",
+ "pdf_schema.add_rank_profile(semantic)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ce78268c",
+ "metadata": {},
+ "source": [
+ "The `hybrid` rank-profile above defines the query input embedding type and a similarities function that\n",
+ "uses a Vespa [tensor compute function](https://docs.vespa.ai/en/reference/ranking-expressions.html#tensor-functions) that calculates\n",
+ "the cosine similarity between all the chunk embeddings and the query embedding.\n",
+ "\n",
+ "The profile only defines a single ranking phase, using a linear combination of multiple features.\n",
+ "\n",
+ "Using [match-features](https://docs.vespa.ai/en/reference/schema-reference.html#match-features), Vespa\n",
+ "returns selected features along with the hit in the SERP (result page).\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "846545f9",
+ "metadata": {},
+ "source": [
+ "## Deploy the application to Vespa Cloud\n",
+ "\n",
+ "With the configured application, we can deploy it to [Vespa Cloud](https://cloud.vespa.ai/en/).\n",
+ "\n",
+ "To deploy the application to Vespa Cloud we need to create a tenant in the Vespa Cloud:\n",
+ "\n",
+ "Create a tenant at [console.vespa-cloud.com](https://console.vespa-cloud.com/) (unless you already have one).\n",
+ "This step requires a Google or GitHub account, and will start your [free trial](https://cloud.vespa.ai/en/free-trial).\n",
+ "\n",
+ "Make note of the tenant name, it is used in the next steps.\n",
+ "\n",
+ "> Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "b5fddf9f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from vespa.deployment import VespaCloud\n",
+ "import os\n",
+ "\n",
+ "# Replace with your tenant name from the Vespa Cloud Console\n",
+ "tenant_name = \"vespa-team\"\n",
+ "\n",
+ "# Key is only used for CI/CD. Can be removed if logging in interactively\n",
+ "key = os.getenv(\"VESPA_TEAM_API_KEY\", None)\n",
+ "if key is not None:\n",
+ " key = key.replace(r\"\\n\", \"\\n\") # To parse key correctly\n",
+ "\n",
+ "vespa_cloud = VespaCloud(\n",
+ " tenant=tenant_name,\n",
+ " application=vespa_app_name,\n",
+ " key_content=key, # Key is only used for CI/CD. Can be removed if logging in interactively\n",
+ " application_package=vespa_application_package,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fa9baa5a",
+ "metadata": {},
+ "source": [
+ "Now deploy the app to Vespa Cloud dev zone.\n",
+ "\n",
+ "The first deployment typically takes 2 minutes until the endpoint is up.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 18,
+ "id": "fe954dc4",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Deployment started in run 2 of dev-aws-us-east-1c for samples.pdfs. This may take a few minutes the first time.\n",
+ "INFO [17:23:35] Deploying platform version 8.270.8 and application dev build 2 for dev-aws-us-east-1c of default ...\n",
+ "INFO [17:23:35] Using CA signed certificate version 0\n",
+ "WARNING [17:23:35] For schema 'pdf', field 'page': Changed to attribute because numerical indexes (field has type int) is not currently supported. Index-only settings may fail. Ignore this warning for streaming search.\n",
+ "INFO [17:23:35] Using 1 nodes in container cluster 'pdfs_container'\n",
+ "WARNING [17:23:36] For streaming search cluster 'pdfs_content.pdf', SD field 'embedding': hnsw index is not relevant and not supported, ignoring setting\n",
+ "WARNING [17:23:36] For streaming search cluster 'pdfs_content.pdf', SD field 'embedding': hnsw index is not relevant and not supported, ignoring setting\n",
+ "INFO [17:23:38] Deployment successful.\n",
+ "INFO [17:23:38] Session 3239 for tenant 'samples' prepared and activated.\n",
+ "INFO [17:23:38] ######## Details for all nodes ########\n",
+ "INFO [17:23:38] h88963a.dev.aws-us-east-1c.vespa-external.aws.oath.cloud: expected to be UP\n",
+ "INFO [17:23:38] --- platform vespa/cloud-tenant-rhel8:8.270.8\n",
+ "INFO [17:23:38] --- storagenode on port 19102 has config generation 3239, wanted is 3239\n",
+ "INFO [17:23:38] --- searchnode on port 19107 has config generation 3239, wanted is 3239\n",
+ "INFO [17:23:38] --- distributor on port 19111 has config generation 3238, wanted is 3239\n",
+ "INFO [17:23:38] --- metricsproxy-container on port 19092 has config generation 3239, wanted is 3239\n",
+ "INFO [17:23:38] h88969g.dev.aws-us-east-1c.vespa-external.aws.oath.cloud: expected to be UP\n",
+ "INFO [17:23:38] --- platform vespa/cloud-tenant-rhel8:8.270.8\n",
+ "INFO [17:23:38] --- logserver-container on port 4080 has config generation 3239, wanted is 3239\n",
+ "INFO [17:23:38] --- metricsproxy-container on port 19092 has config generation 3239, wanted is 3239\n",
+ "INFO [17:23:38] h88972i.dev.aws-us-east-1c.vespa-external.aws.oath.cloud: expected to be UP\n",
+ "INFO [17:23:38] --- platform vespa/cloud-tenant-rhel8:8.270.8\n",
+ "INFO [17:23:38] --- container-clustercontroller on port 19050 has config generation 3239, wanted is 3239\n",
+ "INFO [17:23:38] --- metricsproxy-container on port 19092 has config generation 3239, wanted is 3239\n",
+ "INFO [17:23:38] h89461a.dev.aws-us-east-1c.vespa-external.aws.oath.cloud: expected to be UP\n",
+ "INFO [17:23:38] --- platform vespa/cloud-tenant-rhel8:8.270.8\n",
+ "INFO [17:23:38] --- container on port 4080 has config generation 3239, wanted is 3239\n",
+ "INFO [17:23:38] --- metricsproxy-container on port 19092 has config generation 3239, wanted is 3239\n",
+ "INFO [17:23:51] Found endpoints:\n",
+ "INFO [17:23:51] - dev.aws-us-east-1c\n",
+ "INFO [17:23:51] |-- https://c4f42a1b.bfbdb4fd.z.vespa-app.cloud/ (cluster 'pdfs_container')\n",
+ "INFO [17:23:52] Installation succeeded!\n",
+ "Using mTLS (key,cert) Authentication against endpoint https://c4f42a1b.bfbdb4fd.z.vespa-app.cloud//ApplicationStatus\n",
+ "Application is up!\n",
+ "Finished deployment.\n"
+ ]
+ }
+ ],
+ "source": [
+ "from vespa.application import Vespa\n",
+ "\n",
+ "app: Vespa = vespa_cloud.deploy()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4cde8f22",
+ "metadata": {},
+ "source": [
+ "## Processing PDFs with LangChain\n",
+ "\n",
+ "[LangChain](https://python.langchain.com/) has a rich set of [document loaders](https://python.langchain.com/v0.1/docs/modules/data_connection/document_loaders/) that can be used to load and process various file formats. In this notebook, we use the [PyPDFLoader](https://python.langchain.com/v0.1/docs/modules/data_connection/document_loaders/pdf#using-pypdf).\n",
+ "\n",
+ "We also want to split the extracted text into _chunks_ using a [text splitter](https://python.langchain.com/v0.1/docs/modules/data_connection/document_transformers/). Most text embedding models have limited input lengths (typically less than 512 language model tokens, so splitting the text\n",
+ "into multiple chunks that fits into the context limit of the embedding model is a common strategy.\n",
+ "\n",
+ "For embedding text data, models based on the Transformer architecture have become the de facto standard. A challenge with Transformer-based models is their input length limitation due to the quadratic self-attention computational complexity. For example, a popular open-source text embedding model like\n",
+ "[e5](https://huggingface.co/intfloat/e5-small) has an absolute maximum input length of 512 wordpiece tokens. In addition to\n",
+ "the technical limitation, trying to fit more tokens than used during fine-tuning of the model will impact the quality of the vector representation.\n",
+ "\n",
+ "One can view text embedding encoding as a lossy compression technique, where variable-length texts are compressed\n",
+ "into a fixed dimensional vector representation.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "d9e42b0f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from langchain_community.document_loaders import PyPDFLoader\n",
+ "from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
+ "\n",
+ "text_splitter = RecursiveCharacterTextSplitter(\n",
+ " chunk_size=1024, # chars, not llm tokens\n",
+ " chunk_overlap=0,\n",
+ " length_function=len,\n",
+ " is_separator_regex=False,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "adaccdfc",
+ "metadata": {},
+ "source": [
+ "The following iterates over the `sample_pdfs` and performs the following:\n",
+ "\n",
+ "- Load the URL and extract the text into pages. A page is the retrievable unit we will use in Vespa\n",
+ "- For each page, use the text splitter to split the text into chunks. The chunks are represented as an `array` in the Vespa schema\n",
+ "- Create the page level Vespa `fields`, note that we duplicate some content like the title and URL into the page level representation.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "bf8ac8c7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import hashlib\n",
+ "import unicodedata\n",
+ "\n",
+ "\n",
+ "def remove_control_characters(s):\n",
+ " return \"\".join(ch for ch in s if unicodedata.category(ch)[0] != \"C\")\n",
+ "\n",
+ "\n",
+ "my_docs_to_feed = []\n",
+ "for pdf in sample_pdfs():\n",
+ " url = pdf[\"url\"]\n",
+ " loader = PyPDFLoader(url)\n",
+ " pages = loader.load_and_split()\n",
+ " for index, page in enumerate(pages):\n",
+ " source = page.metadata[\"source\"]\n",
+ " chunks = text_splitter.transform_documents([page])\n",
+ " text_chunks = [chunk.page_content for chunk in chunks]\n",
+ " text_chunks = [remove_control_characters(chunk) for chunk in text_chunks]\n",
+ " page_number = index + 1\n",
+ " vespa_id = f\"{url}#{page_number}\"\n",
+ " hash_value = hashlib.sha1(vespa_id.encode()).hexdigest()\n",
+ " fields = {\n",
+ " \"title\": pdf[\"title\"],\n",
+ " \"url\": url,\n",
+ " \"page\": page_number,\n",
+ " \"id\": hash_value,\n",
+ " \"authors\": [a.strip() for a in pdf[\"authors\"].split(\",\")],\n",
+ " \"chunks\": text_chunks,\n",
+ " \"metadata\": page.metadata,\n",
+ " }\n",
+ " my_docs_to_feed.append(fields)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "54db44b1",
+ "metadata": {},
+ "source": [
+ "Now that we have parsed the input PDFs and created a list of pages that we want to add to Vespa, we must format the\n",
+ "list into the format that PyVespa accepts. Notice the `fields`, `id` and `groupname` keys. The `groupname` is the\n",
+ "key that is used to shard and co-locate the data and is only relevant when using Vespa with streaming mode.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "bcbfa981",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from typing import Iterable\n",
+ "\n",
+ "\n",
+ "def vespa_feed(user: str) -> Iterable[dict]:\n",
+ " for doc in my_docs_to_feed:\n",
+ " yield {\"fields\": doc, \"id\": doc[\"id\"], \"groupname\": user}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2ff628ac",
+ "metadata": {},
+ "source": [
+ "Now, we can feed to the Vespa instance (`app`), using the `feed_iterable` API, using the generator function above as input\n",
+ "with a custom `callback` function. Vespa also performs embedding inference during this step using the built-in Vespa [embedding](https://docs.vespa.ai/en/embedding.html#huggingface-embedder) functionality.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "dc1b3029",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from vespa.io import VespaResponse\n",
+ "\n",
+ "\n",
+ "def callback(response: VespaResponse, id: str):\n",
+ " if not response.is_successful():\n",
+ " print(\n",
+ " f\"Document {id} failed to feed with status code {response.status_code}, url={response.url} response={response.json}\"\n",
+ " )\n",
+ "\n",
+ "\n",
+ "app.feed_iterable(\n",
+ " schema=\"pdf\", iter=vespa_feed(\"jo-bergum\"), namespace=\"personal\", callback=callback\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "431dc2f9",
+ "metadata": {},
+ "source": [
+ "Notice the `schema` and `namespace` arguments. PyVespa transforms the input operations to Vespa [document v1](https://docs.vespa.ai/en/document-v1-api-guide.html)\n",
+ "requests.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "20b007ec",
+ "metadata": {},
+ "source": [
+ "### Querying data\n",
+ "\n",
+ "Now, we can also query our data. With [streaming mode](https://docs.vespa.ai/en/reference/query-api-reference.html#streaming),\n",
+ "we must pass the `groupname` parameter, or the request will fail with an error.\n",
+ "\n",
+ "The query request uses the Vespa Query API and the `Vespa.query()` function\n",
+ "supports passing any of the Vespa query API parameters.\n",
+ "\n",
+ "Read more about querying Vespa in:\n",
+ "\n",
+ "- [Vespa Query API](https://docs.vespa.ai/en/query-api.html)\n",
+ "- [Vespa Query API reference](https://docs.vespa.ai/en/reference/query-api-reference.html)\n",
+ "- [Vespa Query Language API (YQL)](https://docs.vespa.ai/en/query-language.html)\n",
+ "\n",
+ "Sample query request for `why is colbert effective?` for the user `bergum@vespa.ai`:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "b9349fb4",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "{\n",
+ " \"id\": \"id:personal:pdf:g=jo-bergum:a4b2ced87807ee9cb0325b7a1c64a070d05a31f7\",\n",
+ " \"relevance\": 1.1412738851962692,\n",
+ " \"source\": \"pdfs_content.pdf\",\n",
+ " \"fields\": {\n",
+ " \"matchfeatures\": {\n",
+ " \"closest(embedding)\": {\n",
+ " \"0\": 1.0\n",
+ " },\n",
+ " \"elementSimilarity(chunks)\": 0.5006379585326953,\n",
+ " \"nativeRank(chunks)\": 0.15642522855051508,\n",
+ " \"nativeRank(title)\": 0.1341324233922751,\n",
+ " \"similarities\": {\n",
+ " \"1\": 0.7731813192367554,\n",
+ " \"2\": 0.8196794986724854,\n",
+ " \"3\": 0.796222984790802,\n",
+ " \"4\": 0.7699441909790039,\n",
+ " \"0\": 0.850716233253479\n",
+ " }\n",
+ " },\n",
+ " \"id\": \"a4b2ced87807ee9cb0325b7a1c64a070d05a31f7\",\n",
+ " \"title\": \"ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT\",\n",
+ " \"page\": 9,\n",
+ " \"chunks\": [\n",
+ " \"Sq,d:=\\u00d5i\\u2208[|Eq|]maxj\\u2208[|Ed|]Eqi\\u00b7ETdj(3)ColBERT is di\\ufb00erentiable end-to-end. We /f_ine-tune the BERTencoders and train from scratch the additional parameters (i.e., thelinear layer and the [Q] and [D] markers\\u2019 embeddings) using theAdam [ 16] optimizer. Notice that our interaction mechanism hasno trainable parameters. Given a triple \\u27e8q,d+,d\\u2212\\u27e9with query q,positive document d+and negative document d\\u2212, ColBERT is usedto produce a score for each document individually and is optimizedvia pairwise so/f_tmax cross-entropy loss over the computed scoresofd+andd\\u2212.3.4 O\\ufb00line Indexing: Computing & StoringDocument EmbeddingsBy design, ColBERT isolates almost all of the computations betweenqueries and documents, largely to enable pre-computing documentrepresentations o\\ufb04ine. At a high level, our indexing procedure isstraight-forward: we proceed over the documents in the collectionin batches, running our document encoder fDon each batch andstoring the output embeddings per document. Although indexing\",\n",
+ " \"a set of documents is an o\\ufb04ine process, we incorporate a fewsimple optimizations for enhancing the throughput of indexing. Aswe show in \\u00a74.5, these optimizations can considerably reduce theo\\ufb04ine cost of indexing.To begin with, we exploit multiple GPUs, if available, for fasterencoding of batches of documents in parallel. When batching, wepad all documents to the maximum length of a document withinthe batch.3To make capping the sequence length on a per-batchbasis more e\\ufb00ective, our indexer proceeds through documents ingroups of B(e.g., B=100,000) documents. It sorts these documentsby length and then feeds batches of b(e.g., b=128) documents ofcomparable length through our encoder. /T_his length-based bucket-ing is sometimes refered to as a BucketIterator in some libraries(e.g., allenNLP). Lastly, while most computations occur on the GPU,we found that a non-trivial portion of the indexing time is spent onpre-processing the text sequences, primarily BERT\\u2019s WordPiece to-\",\n",
+ " \"kenization. Exploiting that these operations are independent acrossdocuments in a batch, we parallelize the pre-processing across theavailable CPU cores.Once the document representations are produced, they are savedto disk using 32-bit or 16-bit values to represent each dimension.As we describe in \\u00a73.5 and 3.6, these representations are eithersimply loaded from disk for ranking or are subsequently indexedfor vector-similarity search, respectively.3.5 Top- kRe-ranking with ColBERTRecall that ColBERT can be used for re-ranking the output of an-other retrieval model, typically a term-based model, or directlyfor end-to-end retrieval from a document collection. In this sec-tion, we discuss how we use ColBERT for ranking a small set ofk(e.g., k=1000) documents given a query q. Since kis small, werely on batch computations to exhaustively score each document\",\n",
+ " \"3/T_he public BERT implementations we saw simply pad to a pre-de/f_ined length.(unlike our approach in \\u00a73.6). To begin with, our query serving sub-system loads the indexed documents representations into memory,representing each document as a matrix of embeddings.Given a query q, we compute its bag of contextualized embed-dings Eq(Equation 1) and, concurrently, gather the document repre-sentations into a 3-dimensional tensor Dconsisting of kdocumentmatrices. We pad the kdocuments to their maximum length tofacilitate batched operations, and move the tensor Dto the GPU\\u2019smemory. On the GPU, we compute a batch dot-product of EqandD, possibly over multiple mini-batches. /T_he output materializes a3-dimensional tensor that is a collection of cross-match matricesbetween qand each document. To compute the score of each docu-ment, we reduce its matrix across document terms via a max-pool(i.e., representing an exhaustive implementation of our MaxSim\",\n",
+ " \"computation) and reduce across query terms via a summation. Fi-nally, we sort the kdocuments by their total scores.\"\n",
+ " ]\n",
+ " }\n",
+ "}\n"
+ ]
+ }
+ ],
+ "source": [
+ "from vespa.io import VespaQueryResponse\n",
+ "import json\n",
+ "\n",
+ "response: VespaQueryResponse = app.query(\n",
+ " yql=\"select id,title,page,chunks from pdf where userQuery() or ({targetHits:10}nearestNeighbor(embedding,q))\",\n",
+ " groupname=\"jo-bergum\",\n",
+ " ranking=\"hybrid\",\n",
+ " query=\"why is colbert effective?\",\n",
+ " body={\n",
+ " \"presentation.format.tensors\": \"short-value\",\n",
+ " \"input.query(q)\": 'embed(e5, \"why is colbert effective?\")',\n",
+ " },\n",
+ " timeout=\"2s\",\n",
+ ")\n",
+ "assert response.is_successful()\n",
+ "print(json.dumps(response.hits[0], indent=2))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4d3ca1da",
+ "metadata": {},
+ "source": [
+ "Notice the `matchfeatures` that returns the configured match-features from the rank-profile, including all the chunk similarities.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "57f323df",
+ "metadata": {},
+ "source": [
+ "## LangChain Retriever\n",
+ "\n",
+ "We use the [LangChain Retriever](https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/) interface so that\n",
+ "we can connect our Vespa app with the flexibility and power of the [LangChain](https://python.langchain.com/v0.1/docs/get_started/introduction) LLM framework.\n",
+ "\n",
+ "> A retriever is an interface that returns documents given an unstructured query. It is more general than a vector store. A retriever does not need to be able to store documents, only to return (or retrieve) them. Vector stores can be used as the backbone of a retriever, but there are other types of retrievers as well.\n",
+ "\n",
+ "The retriever interface fits perfectly with Vespa, as Vespa can support a wide range of features and ways to retrieve and\n",
+ "rank content. The following implements a custom retriever `VespaStreamingHybridRetriever` that takes the following arguments:\n",
+ "\n",
+ "- `app:Vespa` The Vespa application we retrieve from. This could be a Vespa Cloud instance or a local instance, for example running on a laptop.\n",
+ "- `user:str` The user that that we want to retrieve for, this argument maps to the [Vespa streaming mode groupname parameter](https://docs.vespa.ai/en/reference/query-api-reference.html#streaming.groupname)\n",
+ "- `pages:int` The target number of PDF pages we want to retrieve for a given query\n",
+ "- `chunks_per_page` The is the target number of relevant text chunks that are associated with the page\n",
+ "- `chunk_similarity_threshold` - The chunk similarity threshold, only chunks with a similarity above this threshold\n",
+ "\n",
+ "The core idea is to _retrieve_ pages using maximum chunk similarity as the initial scoring function, then consider other chunks on the same page potentially relevant.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 19,
+ "id": "c5b7c0d1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from langchain_core.documents import Document\n",
+ "from langchain_core.retrievers import BaseRetriever\n",
+ "from typing import List\n",
+ "\n",
+ "\n",
+ "class VespaStreamingHybridRetriever(BaseRetriever):\n",
+ " app: Vespa\n",
+ " user: str\n",
+ " pages: int = 5\n",
+ " chunks_per_page: int = 3\n",
+ " chunk_similarity_threshold: float = 0.8\n",
+ "\n",
+ " def _get_relevant_documents(self, query: str) -> List[Document]:\n",
+ " response: VespaQueryResponse = self.app.query(\n",
+ " yql=\"select id, url, title, page, authors, chunks from pdf where userQuery() or ({targetHits:20}nearestNeighbor(embedding,q))\",\n",
+ " groupname=self.user,\n",
+ " ranking=\"hybrid\",\n",
+ " query=query,\n",
+ " hits=self.pages,\n",
+ " body={\n",
+ " \"presentation.format.tensors\": \"short-value\",\n",
+ " \"input.query(q)\": f'embed(e5, \"query: {query} \")',\n",
+ " },\n",
+ " timeout=\"2s\",\n",
+ " )\n",
+ " if not response.is_successful():\n",
+ " raise ValueError(\n",
+ " f\"Query failed with status code {response.status_code}, url={response.url} response={response.json}\"\n",
+ " )\n",
+ " return self._parse_response(response)\n",
+ "\n",
+ " def _parse_response(self, response: VespaQueryResponse) -> List[Document]:\n",
+ " documents: List[Document] = []\n",
+ " for hit in response.hits:\n",
+ " fields = hit[\"fields\"]\n",
+ " chunks_with_scores = self._get_chunk_similarities(fields)\n",
+ " ## Best k chunks from each page\n",
+ " best_chunks_on_page = \" ### \".join(\n",
+ " [\n",
+ " chunk\n",
+ " for chunk, score in chunks_with_scores[0 : self.chunks_per_page]\n",
+ " if score > self.chunk_similarity_threshold\n",
+ " ]\n",
+ " )\n",
+ " documents.append(\n",
+ " Document(\n",
+ " id=fields[\"id\"],\n",
+ " page_content=best_chunks_on_page,\n",
+ " title=fields[\"title\"],\n",
+ " metadata={\n",
+ " \"title\": fields[\"title\"],\n",
+ " \"url\": fields[\"url\"],\n",
+ " \"page\": fields[\"page\"],\n",
+ " \"authors\": fields[\"authors\"],\n",
+ " \"features\": fields[\"matchfeatures\"],\n",
+ " },\n",
+ " )\n",
+ " )\n",
+ " return documents\n",
+ "\n",
+ " def _get_chunk_similarities(self, hit_fields: dict) -> List[tuple]:\n",
+ " match_features = hit_fields[\"matchfeatures\"]\n",
+ " similarities = match_features[\"similarities\"]\n",
+ " chunk_scores = []\n",
+ " for i in range(0, len(similarities)):\n",
+ " chunk_scores.append(similarities.get(str(i), 0))\n",
+ " chunks = hit_fields[\"chunks\"]\n",
+ " chunks_with_scores = list(zip(chunks, chunk_scores))\n",
+ " return sorted(chunks_with_scores, key=lambda x: x[1], reverse=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "341dd861",
+ "metadata": {},
+ "source": [
+ "That's it! We can give our newborn retriever a spin for the user `jo-bergum` by\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 20,
+ "id": "ac9088a4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "vespa_hybrid_retriever = VespaStreamingHybridRetriever(\n",
+ " app=app, user=\"jo-bergum\", pages=1, chunks_per_page=1\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 21,
+ "id": "3198db04",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "[Document(page_content='ture that precisely does so. As illustrated, every query embeddinginteracts with all document embeddings via a MaxSim operator,which computes maximum similarity (e.g., cosine similarity), andthe scalar outputs of these operators are summed across queryterms. /T_his paradigm allows ColBERT to exploit deep LM-basedrepresentations while shi/f_ting the cost of encoding documents of-/f_line and amortizing the cost of encoding the query once acrossall ranked documents. Additionally, it enables ColBERT to lever-age vector-similarity search indexes (e.g., [ 1,15]) to retrieve thetop-kresults directly from a large document collection, substan-tially improving recall over models that only re-rank the output ofterm-based retrieval.As Figure 1 illustrates, ColBERT can serve queries in tens orfew hundreds of milliseconds. For instance, when used for re-ranking as in “ColBERT (re-rank)”, it delivers over 170 ×speedup(and requires 14,000 ×fewer FLOPs) relative to existing BERT-based', metadata={'title': 'ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT', 'url': 'https://arxiv.org/pdf/2004.12832.pdf', 'page': 4, 'authors': ['Omar Khattab', 'Matei Zaharia'], 'features': {'closest(embedding)': {'0': 1.0}, 'elementSimilarity(chunks)': 0.41768707482993195, 'nativeRank(chunks)': 0.1401101487033024, 'nativeRank(title)': 0.0520403737720047, 'similarities': {'1': 0.8369992971420288, '0': 0.8730311393737793}}})]"
+ ]
+ },
+ "execution_count": 21,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "vespa_hybrid_retriever.get_relevant_documents(\"what is the maxsim operator in colbert?\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fcca4fc7",
+ "metadata": {},
+ "source": [
+ "## RAG\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a84b98db",
+ "metadata": {},
+ "source": [
+ "Finally, we can connect our custom retriever with the complete flexibility and power of the [LangChain] LLM framework.\n",
+ "The following uses [LangChain Expression Language, or LCEL](https://python.langchain.com/v0.1/docs/expression_language/), a declarative way to compose chains.\n",
+ "\n",
+ "We have several steps composed into a chain:\n",
+ "\n",
+ "- The prompt template and LLM model, in this case using OpenAI\n",
+ "- The retriever that provides the retrieved context for the question\n",
+ "- The formatting of the retrieved context\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 22,
+ "id": "e3dcf5b4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "vespa_hybrid_retriever = VespaStreamingHybridRetriever(\n",
+ " app=app, user=\"jo-bergum\", pages=3, chunks_per_page=3\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 25,
+ "id": "d95473dc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from langchain.chat_models import ChatOpenAI\n",
+ "from langchain.prompts import ChatPromptTemplate\n",
+ "from langchain.schema import StrOutputParser\n",
+ "from langchain.schema.runnable import RunnablePassthrough\n",
+ "\n",
+ "prompt_template = \"\"\"\n",
+ "Answer the question based only on the following context. \n",
+ "Cite the page number and the url of the document you are citing.\n",
+ "\n",
+ "{context}\n",
+ "Question: {question}\n",
+ "\"\"\"\n",
+ "prompt = ChatPromptTemplate.from_template(prompt_template)\n",
+ "model = ChatOpenAI()\n",
+ "\n",
+ "\n",
+ "def format_prompt_context(docs) -> str:\n",
+ " context = []\n",
+ " for d in docs:\n",
+ " context.append(f\"{d.metadata['title']} by {d.metadata['authors']}\\n\")\n",
+ " context.append(f\"url: {d.metadata['url']}\\n\")\n",
+ " context.append(f\"page: {d.metadata['page']}\\n\")\n",
+ " context.append(f\"{d.page_content}\\n\\n\")\n",
+ " return \"\".join(context)\n",
+ "\n",
+ "\n",
+ "chain = (\n",
+ " {\n",
+ " \"context\": vespa_hybrid_retriever | format_prompt_context,\n",
+ " \"question\": RunnablePassthrough(),\n",
+ " }\n",
+ " | prompt\n",
+ " | model\n",
+ " | StrOutputParser()\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "562d2c7d",
+ "metadata": {},
+ "source": [
+ "### Interact with the chain\n",
+ "\n",
+ "Now, we can start asking questions using the `chain` define above.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 26,
+ "id": "36f7f092",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'ColBERT is a ranking model that adapts deep language models, specifically BERT, for efficient retrieval. It introduces a late interaction architecture that independently encodes queries and documents using BERT and then uses a cheap yet powerful interaction step to model their fine-grained similarity. This allows ColBERT to leverage the expressiveness of deep language models while also being able to pre-compute document representations offline, significantly speeding up query processing. ColBERT can be used for re-ranking documents retrieved by a traditional model or for end-to-end retrieval directly from a large document collection. It has been shown to be effective and efficient compared to existing models. (source: ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT by Omar Khattab, Matei Zaharia, page 1, url: https://arxiv.org/pdf/2004.12832.pdf)'"
+ ]
+ },
+ "execution_count": 26,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "chain.invoke(\"what is colbert?\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 27,
+ "id": "569929de",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "\"The ColBERT model utilizes the MaxSim operator, which computes the maximum similarity (e.g., cosine similarity) between query embeddings and document embeddings. The scalar outputs of these operators are summed across query terms, allowing ColBERT to exploit deep LM-based representations while reducing the cost of encoding documents offline and amortizing the cost of encoding the query once across all ranked documents.\\n\\nSource: \\nColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT by ['Omar Khattab', 'Matei Zaharia']\\nURL: https://arxiv.org/pdf/2004.12832.pdf\\nPage: 4\""
+ ]
+ },
+ "execution_count": 27,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "chain.invoke(\"what is the colbert maxsim operator\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 28,
+ "id": "fde46620",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'The difference between ColBERT and single vector representational models is that ColBERT utilizes a late interaction architecture that independently encodes the query and the document using BERT, while single vector models use a single embedding vector for both the query and the document. This late interaction mechanism in ColBERT allows for fine-grained similarity estimation, which leads to more effective retrieval. (Source: ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT by Omar Khattab and Matei Zaharia, page 17, url: https://arxiv.org/pdf/2004.12832.pdf)'"
+ ]
+ },
+ "execution_count": 28,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "chain.invoke(\n",
+ " \"What is the difference between colbert and single vector representational models?\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7c8b8223",
+ "metadata": {},
+ "source": [
+ "## Summary\n",
+ "\n",
+ "Vespa’s streaming mode is a game-changer, enabling the creation of highly cost-effective RAG applications for naturally partitioned data.\n",
+ "\n",
+ "In this notebook, we delved into the hands-on application of [LangChain](https://python.langchain.com/v0.1/docs/get_started/introduction),\n",
+ "leveraging document loaders and transformers. Finally, we showcased a custom LangChain retriever that connected\n",
+ "all the functionality of LangChain with Vespa.\n",
+ "\n",
+ "For those interested in learning more about Vespa, join the [Vespa community on Slack](https://vespatalk.slack.com/) to exchange ideas,\n",
+ "seek assistance, or stay in the loop on the latest Vespa developments.\n",
+ "\n",
+ "We can now delete the cloud instance:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "71e310e3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "vespa_cloud.delete()"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3.11.4 64-bit",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.4"
+ },
+ "vscode": {
+ "interpreter": {
+ "hash": "b0fa6594d8f4cbf19f97940f81e996739fb7646882a419484c72d19e05852a7e"
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/docs/sphinx/source/getting-started-pyvespa-cloud.ipynb b/docs/sphinx/source/getting-started-pyvespa-cloud.ipynb
index 28bd6852..3a4eaaac 100644
--- a/docs/sphinx/source/getting-started-pyvespa-cloud.ipynb
+++ b/docs/sphinx/source/getting-started-pyvespa-cloud.ipynb
@@ -265,6 +265,8 @@
"id": "197c0a27",
"metadata": {},
"source": [
+ "For more details on different authentication options and methods, see [authenticating-to-vespa-cloud](https://pyvespa.readthedocs.io/en/latest/authenticating-to-vespa-cloud.html).\n",
+ "\n",
"The following will upload the application package to Vespa Cloud Dev Zone (`aws-us-east-1c`), read more about [Vespa Zones](https://cloud.vespa.ai/en/reference/zones.html).\n",
"The Vespa Cloud Dev Zone is considered as a sandbox environment where resources are down-scaled and idle deployments are expired automatically.\n",
"For information about production deployments, see the following [method](https://pyvespa.readthedocs.io/en/latest/reference-api.html#vespa.deployment.VespaCloud.deploy_to_prod).\n",
@@ -272,6 +274,16 @@
"> Note: Deployments to dev and perf expire after 7 days of inactivity, i.e., 7 days after running deploy. This applies to all plans, not only the Free Trial. Use the Vespa Console to extend the expiry period, or redeploy the application to add 7 more days.\n"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "fb2ba0e1",
+ "metadata": {},
+ "source": [
+ "Now deploy the app to Vespa Cloud dev zone.\n",
+ "\n",
+ "The first deployment typically takes 2 minutes until the endpoint is up. (Applications that for example refer to large onnx-models may take a bit longer.)\n"
+ ]
+ },
{
"cell_type": "code",
"execution_count": 5,
@@ -380,7 +392,7 @@
"id": "sealed-mustang",
"metadata": {},
"source": [
- "### Feeding documents to Vespa\n",
+ "## Feeding documents to Vespa\n",
"\n",
"In this example we use the [HF Datasets](https://huggingface.co/docs/datasets/index) library to stream the\n",
"[BeIR/nfcorpus](https://huggingface.co/datasets/BeIR/nfcorpus) dataset and index in our newly deployed Vespa instance. Read\n",