[TOC]
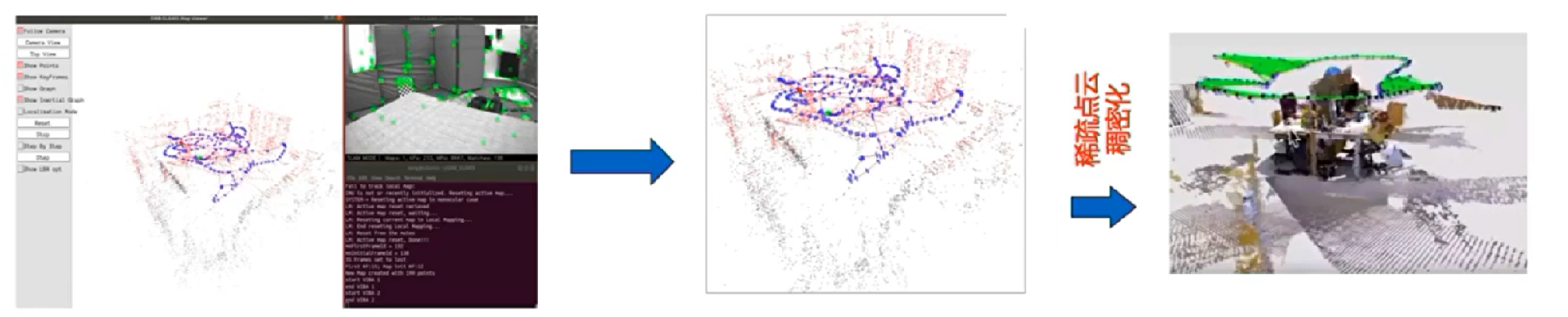
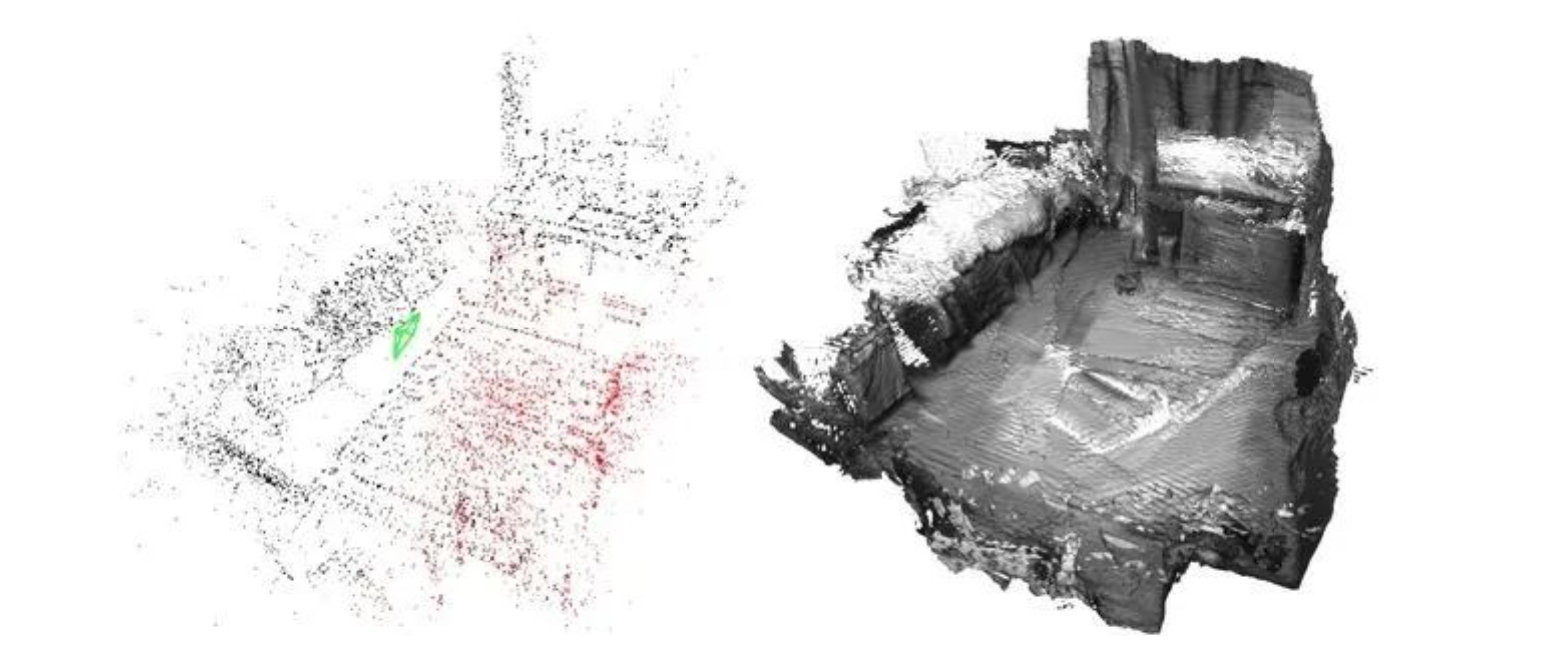
ORB-SLAM3 生成的是稀释点云地图,只能定位,无法直接用于导航,需要对稀疏点云稠密化构建稠密地图。处理分为两大类:基于数据结构、基于机器学习。
把三维空间建模成许多小方块(体素),构建占据栅格地图(Occupancy Grid Map),节点存储它是否被占据的信息。学过地信的都知道这种地图编码方式比较高效,节省空间,当某个方块的子节点都相同,就无需展开。
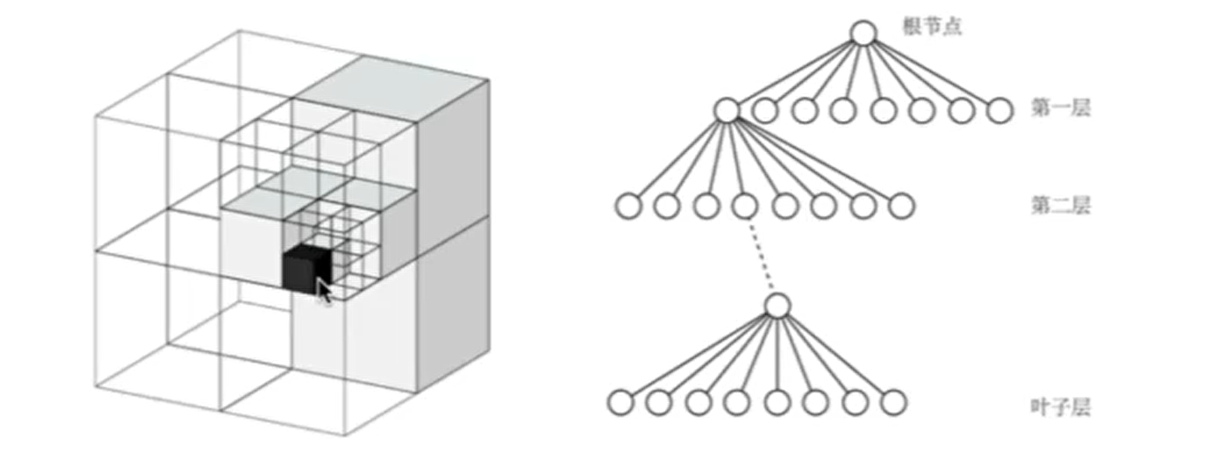
对于占据和空白来说,选择用概论的形式表达,这样就可以动态建模地图中的障碍物信息。
设
因此,假设
安装 Octomap,八叉树地图及其可视化工具 octovis 已经集成到仓库中,安装命令如下:
sudo apt-get install liboctomap-dev octovis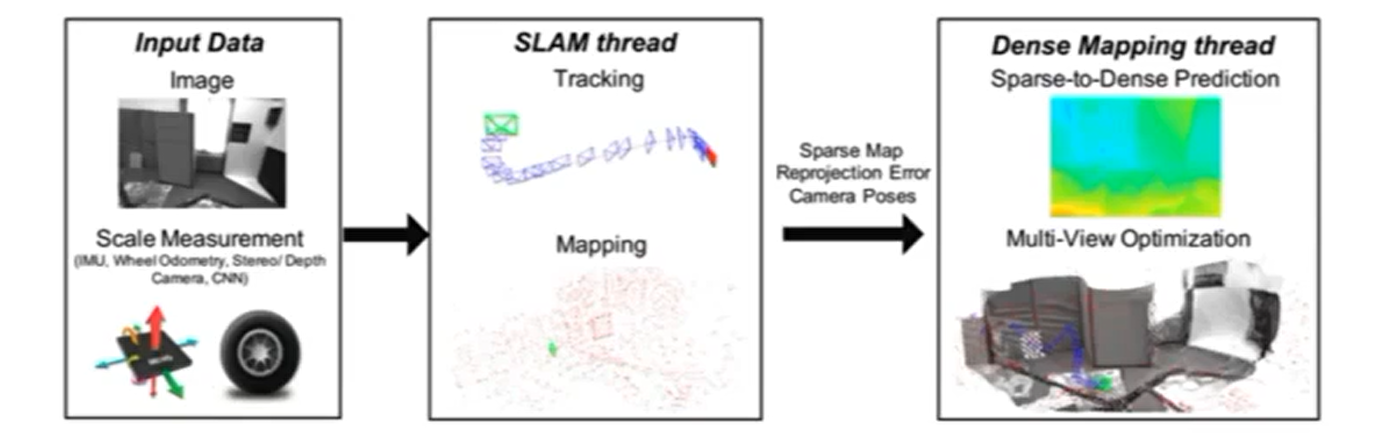
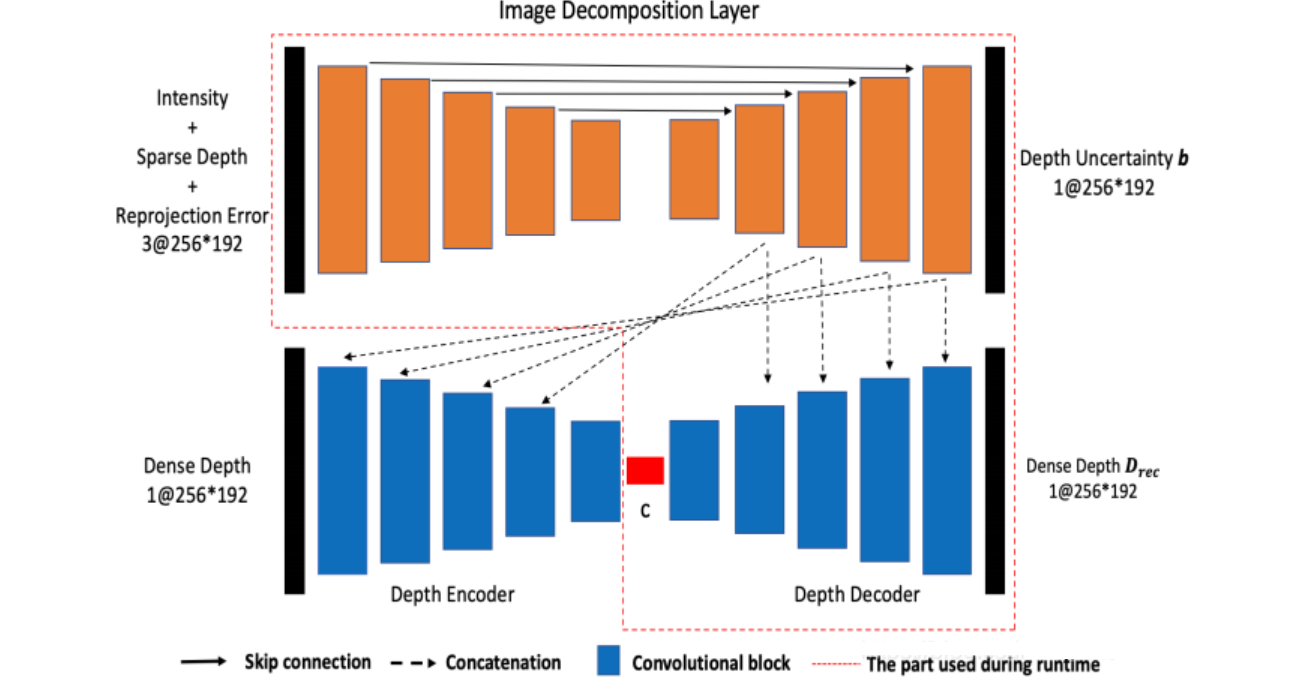
CodeMapping 的网络结构如下:
-
上层网络采用的是 U-Net,输入为:灰度图、稀疏深度 depth 和重投影误差 maps 。深度depth 和重投影误差值归一化在
$[0,1]$ 之间,输入的三个数据可以 concat 为一个三通道的输入,输出为:深度不确定图。 -
下层网络是变分自动编码器 ( VAE ),网络会生成隐编码
$c$ ,椆密的深度预测图$D$ 和深度不确定性图$b$ 。 -
损失函数由一个深度重构 loss 和一个 KL 散度 loss 构成。 其中深度重构loss定义为: $$ \sum{\mathbf{x} \in \Omega} \frac{\left|D[\mathbf{x}]-D{g t}[\mathbf{x}]\right|}{b[\mathbf{x}]}+\log (b[\mathbf{x}]) $$
效果如下:
语义 SLAM(Semantic SLAM)指将语义分割、目标检测、实例分割等技术用于 SLAM 中,系统在建图过程中不仅仅获得环境中的几何信息,同时还可以识别环境中独立的个体,获取其位置、姿态和功能属性等语义信息,以应对复杂场景完成更高级的任务。

语义 SLAM 的优势:
- 传统SLAM方法以静态环境假设为前提,而语义SLAM可以预知移动物体 (人、汽车等) 的动态特性;
- 语义SLAM中的相似物体知识表示可以共享,通过维护共享知识库提高SLAM系统的可扩展性和存储效率;
- 语义SLAM可实现智能路径规划,如机器人可以搬动路径中的可移动物体等实现路径更优;
- 语义SLAM中包含物体的功能属性,可以提高机器人对环境的自主感知和人机交互能力。 语义ORB-SLAM3 : 将目标检则或图像分割算法与ORB-SLAM3相结合。
通常,主要的步骤包括:
- 利用目标检测或图像分割算法,获取空间中物体的2D标签;
- 使用点云分割算法,对稀疏点云进行分割(分类);
- 结合含有2D标签的彩色图像和对应的深度图像,融合分割后的稀疏点云,获得稠密点云语义地图;
- 稠密点云语义地图转换为八叉树地图,减小了地图的存储空间,并便于移动机器人进行避障和导航。
人脑
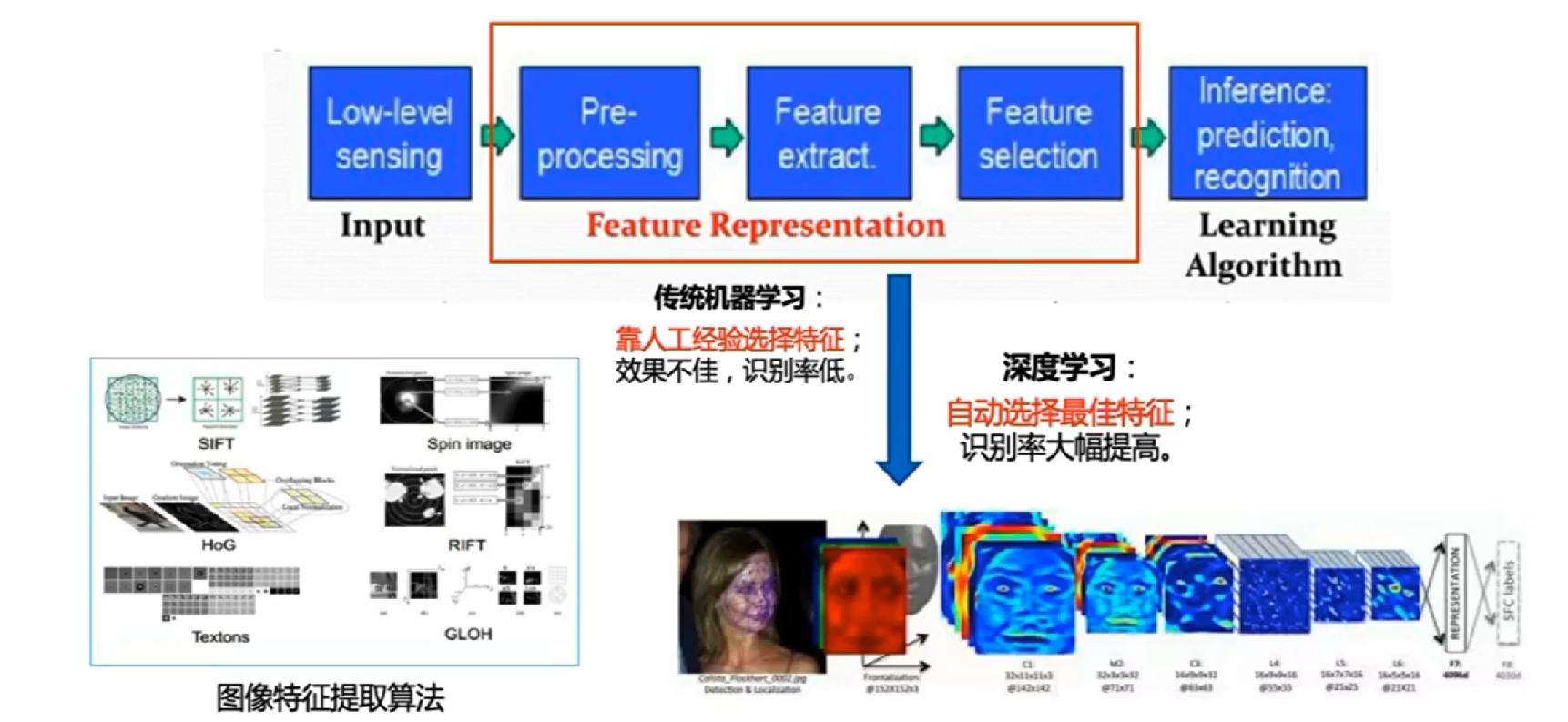
帧间估计也称为视觉里程计,是通过分析关联相机图像之间的多视几何关系确定机器人位姿与朝向的过程,可作为视觉 SLAM 的前端。相较于传统的基于稀疏特征或稠密特征,基于深度学习的帧间估计方法的优势在于 :
- 端到端的学习方式,无需特征提取、特征匹配,输入数据直接得结果。
- 无需复杂的多视图几何计算过程,方法更直观简洁;
- 训练好的模型,运算速度快,效率更高。