自己实现的爬虫记录,现已实现的爬虫有
- scrapy 电影天堂爬虫
- scrapy 站酷爬虫
- scrapy 通用爬虫
- 抖音视频爬虫
其中,Aburame 文件夹下实现的是通用爬虫,如果是不需要登录的全站爬虫,用它实现可以说非常简单,只需要进行简单的配置即可。实现全站爬虫的逻辑主要在页面解析和分析,非常方便
有什么问题,小伙伴们欢迎在我issues提,一起进步
该爬虫模块长期有效,后续会增加更多有趣的爬虫,如果对小伙伴们有帮助的话,请给我star鼓励,先谢过了
python3下运行这个项目
$ git clone https://github.com/hacksman/spider_world.git
$ cd spider_world/www_douyin_com/
$ python video_download_run.py -upost 93515402600
已经支持命令对应的功能有:
-upost 该用户已发布的所有视频
-ulike 该用户喜欢过的所有视频
-m 是否同时下载该用户的视频和音频(注意,这里必须和-upost 或 -ulike 同时使用)
-one 下载单个视频
命令演示:
# 下载用户id为(93515402600) 所有已发布的视频
$ python video_download_run.py -upost 93515402600
# 下载用户id为(93515402600) 所有已发布的视频和音频
$ python video_download_run.py -m -upost 93515402600
# 下载用户id为(93515402600) 所有喜欢过的视频
$ python video_download_run.py -ulike 93515402600
# 下载视频id为(6610679501925911815) 的视频
$ python video_download_run.py -one 6610679501925911815
你可以通过以下方式获取用户id
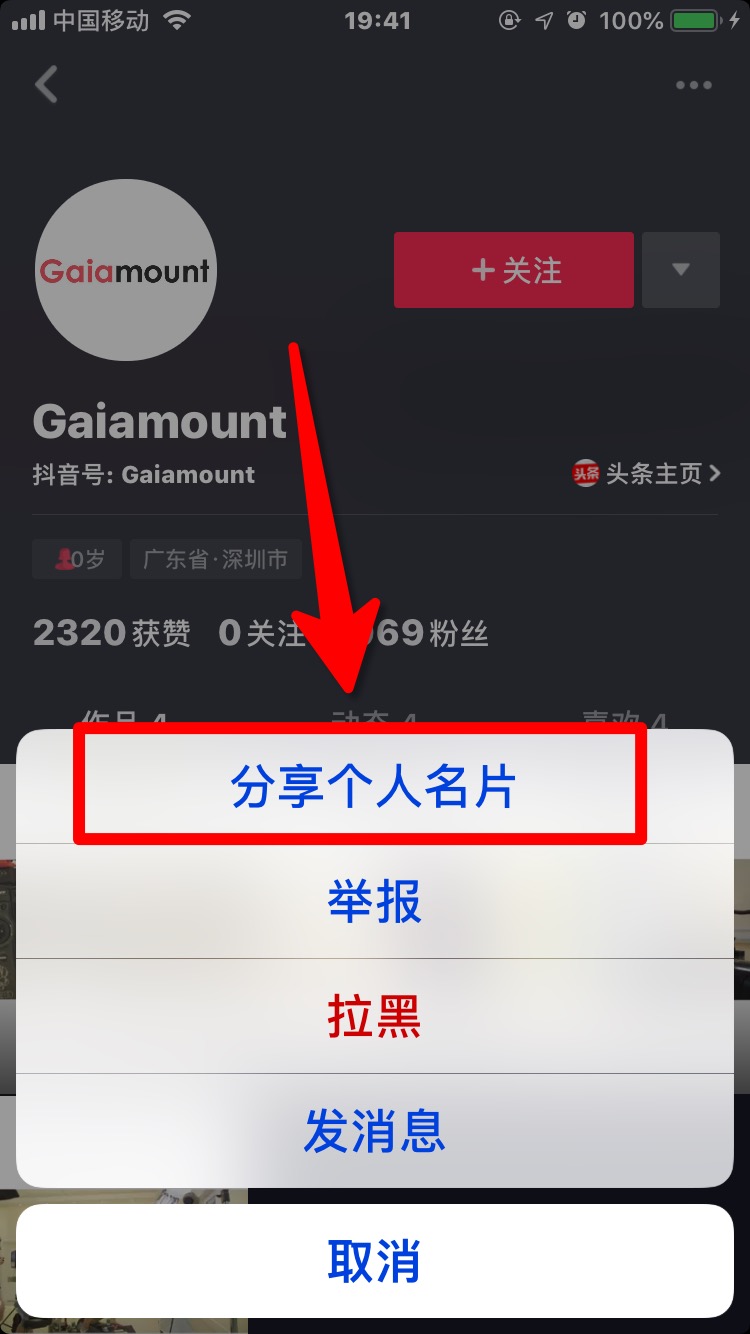

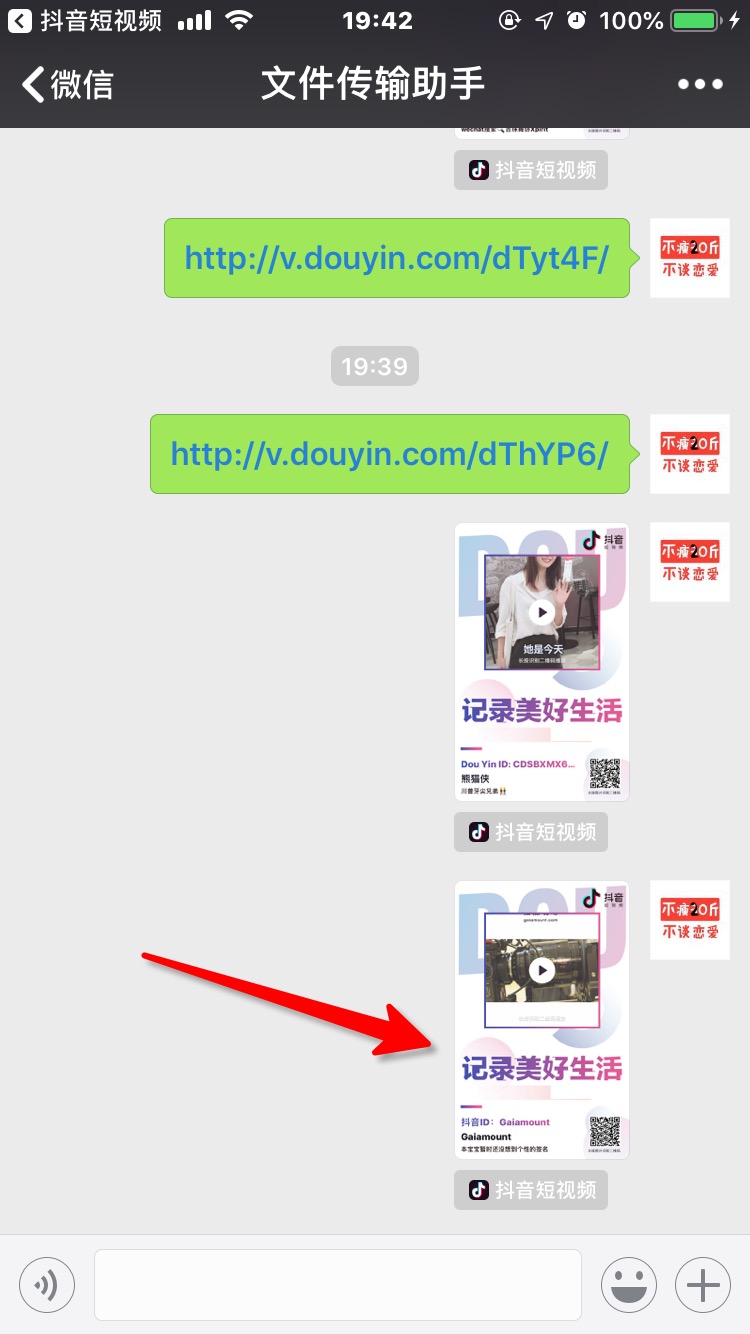

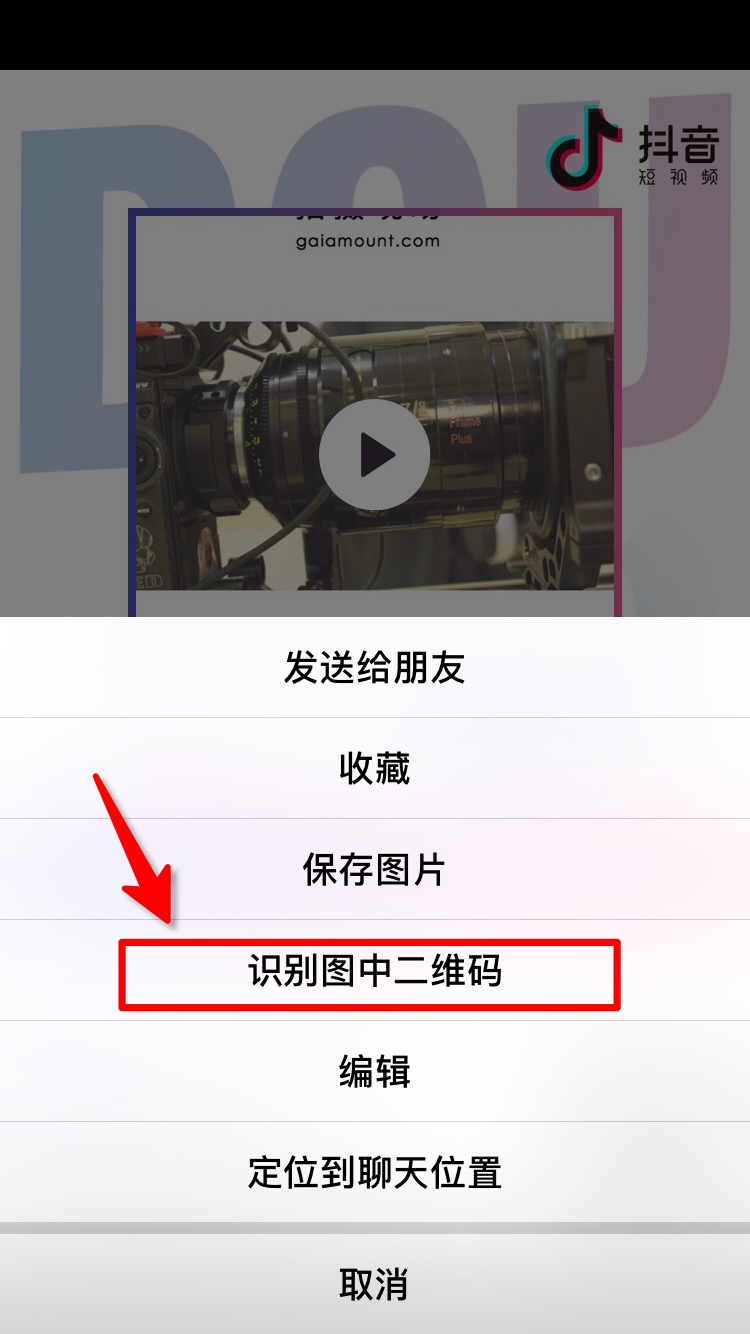

用户id就是图中最后一步链接user后的数字,比如此处url为https://www.douyin.com/share/user/93515402600,用户id就是93515402600
你可以通过以下方式获取视频id
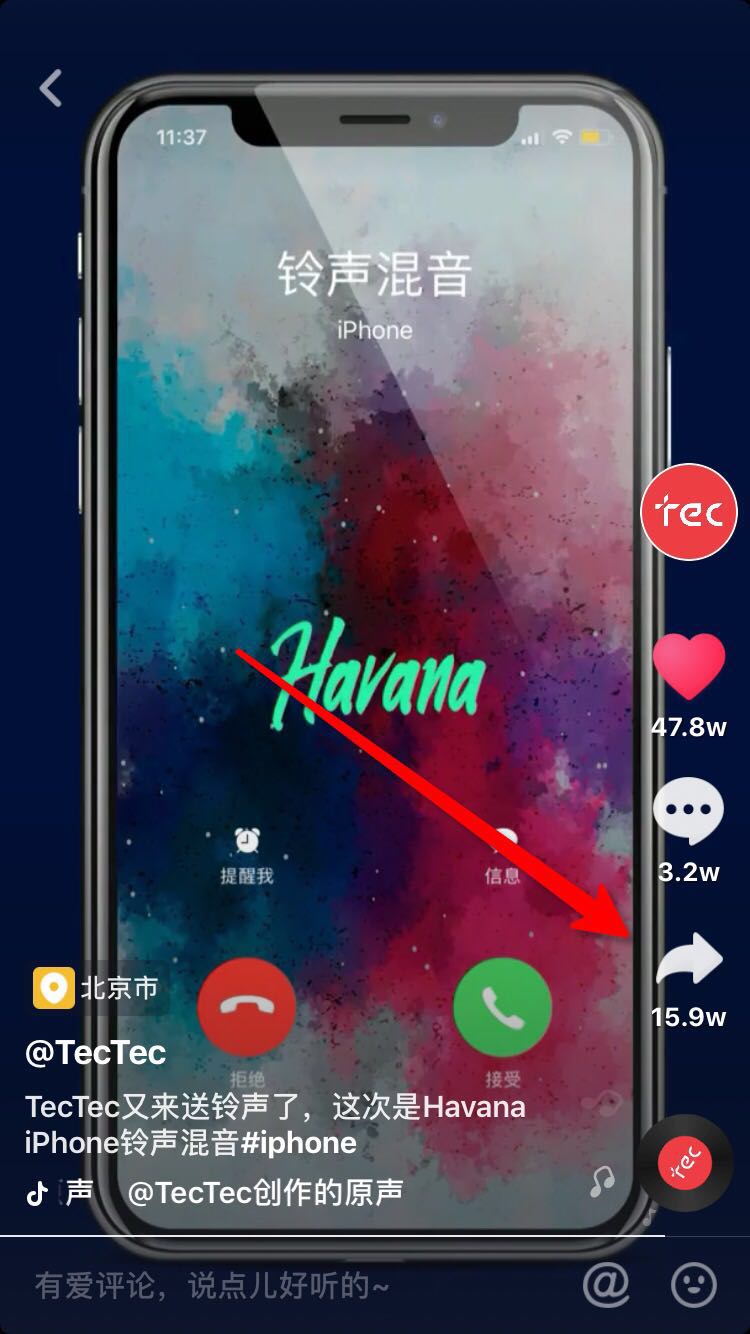
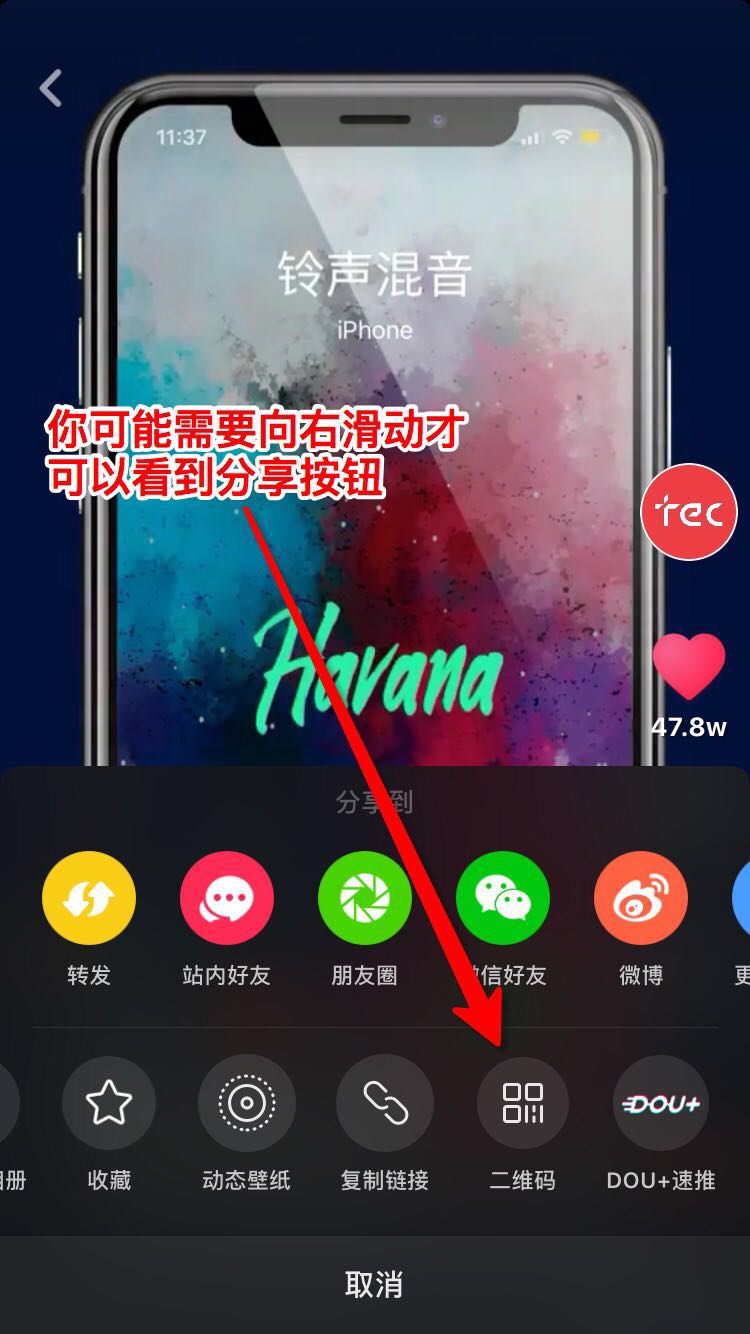
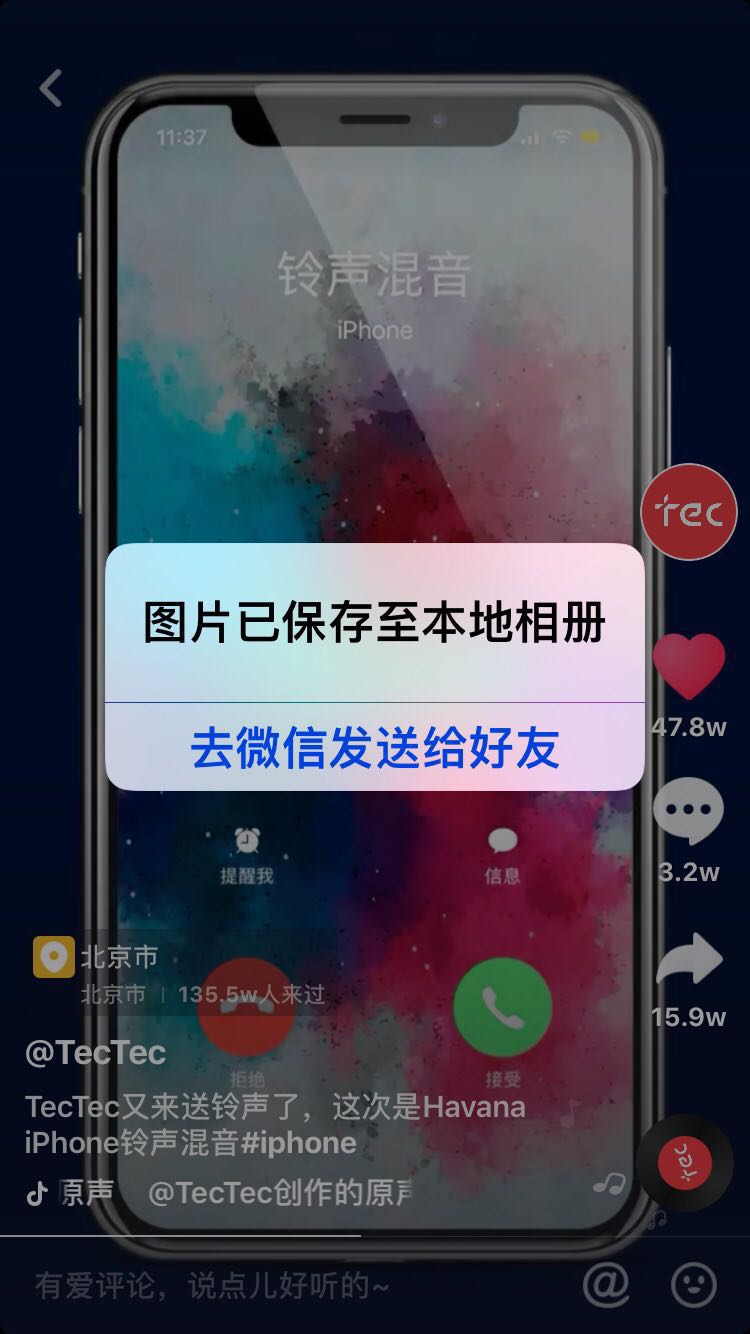
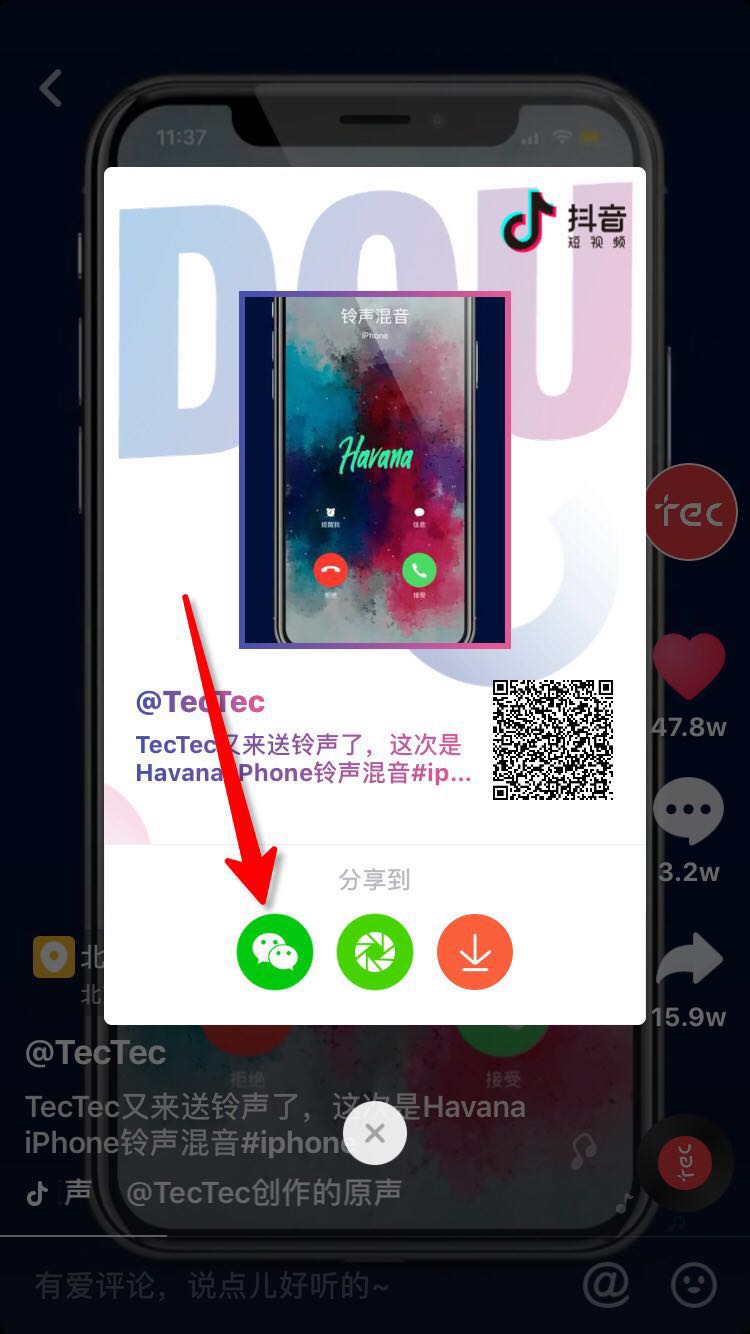


视频id就是就是图中最后一步链接video后的数字,比如此处url为
https://www.iesdouyin.com/share/video/6610679501925911815/?u_code=hjdm8k44®ion=CN&mid=6610679524466101005&schema_type=1&object_id=6610679501925911815&utm_campaign=client_scan_share&app=aweme&utm_medium=ios&tt_from=scan_share&iid=45561030398&utm_source=scan_share
视频id就是6610679501925911815
如果你正常运行命令python video_download_run.py -upost 93515402600的实例, 将会得到类似如下的log日志
2018-10-11 20:11:21,039 - douyin_crawl.py[line:147] INFO - download_favorite_video 正在下载视频 Gaiamount_93515402600_#8k #hdr 论现场灯光的重要性~
2018-10-11 20:11:27,817 - douyin_crawl.py[line:147] INFO - download_favorite_video 正在下载视频 Gaiamount_93515402600_#8k #hdr 片场那些好玩儿的事儿~比如轮椅直线加速⏩
2018-10-11 20:11:34,690 - douyin_crawl.py[line:147] INFO - download_favorite_video 正在下载视频 Gaiamount_93515402600_#8k #hdr 关于现场的那些事儿
2018-10-11 20:11:40,793 - douyin_crawl.py[line:147] INFO - download_favorite_video 正在下载视频 Gaiamount_93515402600_#8k#HDR 中国首部8K HDR 影片!敬请期待~
-
下载该用户所有视频
-
下载该用户所有视频和音频
-
下载单个视频
-
下载单个视频的音频
-
用户的评论信息