{kind=link}
This repo contains micro benchmarks of different strategies used to read multiple times.
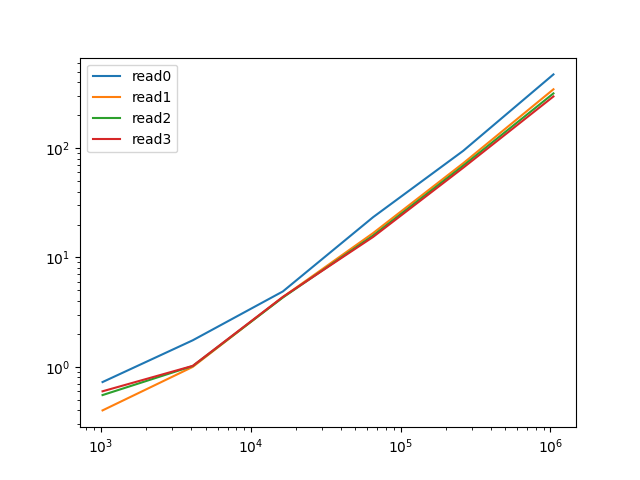
read0- allocate a newVecon every readread1- re-use aVecand allocate when necessaryread2- re-use aVecand reallocate when necessaryread3- re-use aVecandRead'sread_to_end
See https://users.rust-lang.org/t/how-to-efficiently-re-use-a-vec-u8-for-multiple-read-read/77628/5 for origin of the strategies
read0 2^10 time: [722.39 ns 724.16 ns 726.29 ns]
read0 2^10 time: [722.39 ns 724.16 ns 726.29 ns]
read1 2^10 time: [397.72 ns 398.60 ns 399.64 ns]
read2 2^10 time: [549.24 ns 550.45 ns 551.62 ns]
read3 2^10 time: [594.33 ns 596.17 ns 598.21 ns]
read0 2^12 time: [1.7400 us 1.7454 us 1.7532 us]
read1 2^12 time: [993.64 ns 996.60 ns 999.65 ns]
read2 2^12 time: [1.0136 us 1.0150 us 1.0162 us]
read3 2^12 time: [1.0151 us 1.0183 us 1.0220 us]
read0 2^14 time: [4.8709 us 4.8896 us 4.9090 us]
read1 2^14 time: [4.3353 us 4.3417 us 4.3482 us]
read2 2^14 time: [4.2929 us 4.2997 us 4.3069 us]
read3 2^14 time: [4.3443 us 4.3579 us 4.3706 us]
read0 2^16 time: [23.306 us 23.356 us 23.410 us]
read1 2^16 time: [16.682 us 16.707 us 16.733 us]
read2 2^16 time: [15.837 us 15.864 us 15.893 us]
read3 2^16 time: [15.376 us 15.396 us 15.416 us]
read0 2^18 time: [94.371 us 94.617 us 94.852 us]
read1 2^18 time: [72.739 us 72.855 us 72.979 us]
read2 2^18 time: [69.133 us 69.248 us 69.362 us]
read3 2^18 time: [66.100 us 66.237 us 66.359 us]
read0 2^20 time: [471.08 us 472.91 us 474.84 us]
read1 2^20 time: [344.30 us 345.64 us 347.24 us]
read2 2^20 time: [313.31 us 317.02 us 323.00 us]
read3 2^20 time: [296.12 us 297.16 us 298.27 us]
(RUSTFLAGS="-Ctarget-cpu=native" (skylake on my pc)) does not change
the above.