Login/Sign Up for IBM Cloud: https://ibm.biz/YourPathToDeepLearning
Hands-On Guide: https://github.com/IBMDeveloperMEA/YPDL-Build-a-movie-recommendation-engine-with-TensorFlow
Slides: https://ibmdevelopermea.github.io/YPDL-Build-a-movie-recommendation-engine-with-TensorFlow/
Workshop Replay: https://www.crowdcast.io/e/ypdl-4
Survey: https://ibm.biz/YPDL-Survey
In this tutorial, we are going to build a Restricted Boltzmann Machine using TensorFlow that will give us recommendations based on movies that have been watched already. The datasets we are going to use are acquired from GroupLens and contains movies, users, and movie ratings by these users. We are using a sigmoid activation function for the Neural Network and the recommendations are given based on the recommendation score generated by a Restricted Boltzmann Machine (RBM).
- Understand the working of Restricted Boltzmann Machines
- Get to know how collaborative filtering can be implemented on Restricted Boltzmann Machines
- Understand the use cases and learning process of Restricted Boltzmann Machines
The following prerequisites are required to follow the tutorial:
It should take you approximately 40 minutes to complete the tutorial.
But before we start, let's talk a bit about the basics of RBM. An RBM is a two-layered (input layer and hidden layer) Artificial Neural Network which learns a probability distribution based on a set of inputs, it is a stochastic (non-deterministic) which helps us solve different combination based problems. RBM's can be used for dimensionality reduction, classification, regression, collaborative filtering, feature learning, and topic modeling.
As the name suggests, RBM is a class of Boltzmann machines, but they are restricted in certain ways when considering the connections between the input and the hidden nodes of the Neural Network, and thus it is easier to implement an RBM than a Boltzmann machine. The layers and the nodes within those layers are connected in a one-to-many fashion where each node in the input layer is connected to every node in the hidden layer, but no node within each layer is connected. The restriction allows more streamlined training algorithms than what is generally used in Boltzmann machines.
This is how an RBM looks like, as you can see all the nodes in the input layer are connected to each node in the hidden layer, and the structure of the Neural Network itself makes it efficient when it comes to training our Neural Network as one input layer can use many hidden layers for training. Multiple RBMs can be stacked on as well creating a Deep Belief Network which will allow deeper learning of the neural network and incorporate further learning.
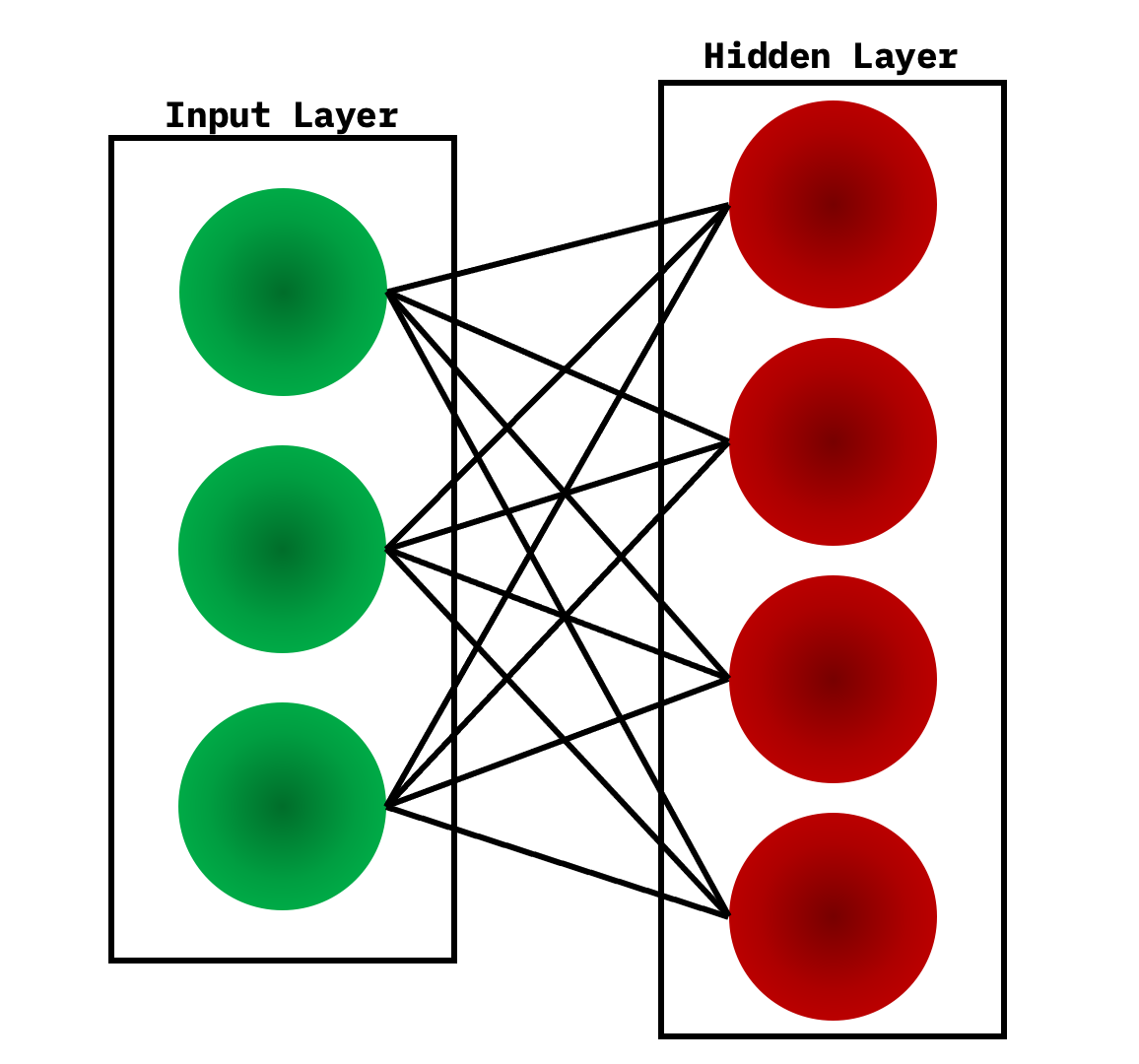
There are two steps involved when it comes to the working of an RBM:
- Multiple Inputs
- Reconstructing

Multiple inputs are considered to be the first step when it comes to the training of the Neural Network, the inputs are taken into the input layer, multiplied by the weights, and is added to the bias. After which it goes through the activation function (sigmoid) and thus the outputs decide if the hidden state gets activated.
The weights in the Neural Network are in a matrix, where the number of input nodes is the number of rows and the number of hidden nodes is the number of columns. Furthermore, the primary hidden node will obtain the vector multiplication of the inputs and will be multiplied by the first column of weights before the corresponding bias term is added to it.

In reconstruction, the logic is pretty simple, we habe the activations which are the inputs at this point, which are then passed to the hidden layer and then to the input later after which new biases are obtained and the reconstruction is the new output.
So how does the learning process really work? As these two steps happen subsequently, where first we generate activations using multiple inputs phase and then reconstruction takes place when the reconstruction is taking place in an epoch, our main goal here is to decrease the reconstruction error, thus the weights are then adjusted per-iteration accordingly by the algorithm to decrease the reconstruction error which will result in giving us a good prediction/higher accuracy.

- Recommendation Systems
- Representation Learning (Feature Learning)
- Image Recognition
- Natural Language Understanding (Deep Belief Network)
Now we will implement a movie recommendation system based on Restricted Boltzmann Machine using TensorFlow, where we will use a users and ratings data set to predict recommendation scores for movies a particular user may be interested to watch based on their previous watch history.
- Set up IBM Cloud Pak for Data as a Service
- Create a new Project
- Import the notebook
- Read through the notebook
-
Sign up or log in.
- Create an IBM Cloud Account or login at here
-
Create an instance of Watson Studio
- Once logged in, search for Watson Studio and create a lite instance


- Access the serivce and click either Create a project or New project.
- Select Create an empty project.
- Give the project a name.
- Choose an existing Object Storage service instance or create a new one.
- Click Create.

Alternatively you can click on the navigation menu on the top left and click on View all projects and create a new project.

Once your project is created
- Access the created project.
- Click +Add to project.
- Click Notebook.
- Click From URL.
- Provide a Name.
- Under Select runtime, choose Default Python 3.7 XS.
- Enter
https://raw.githubusercontent.com/IBM/dl-learning-path-assets/main/unsupervised-deeplearning/notebooks/CollabortiveFilteringUsingRBM.ipynbas the Notebook URL. - Click Create.


-
Run the Notebook.
In the open Notebook, click Run to run the cells one at a time. The rest of the tutorial follows the order of the Notebook.
- Loading the data set
Like every notebook, we start with downloading our data set into the environment

- Adding data into the data frame
We create two data frames movies_df for our movies and ratings_df for our movie ratings

- Rename the columns in the data frames
We rename the columns in the data frames making sure that we are able to understand the data properly
movies_df consists of 3 columns MovieID, Title and Genres
ratings_df consists of 4 columns UserID, MovieID, Rating and Timestamp

- Normalize the data
When we create a pivot of ratings_df there is a lot of data marked as NaN
user_rating_df = ratings_df.pivot(index='UserID', columns='MovieID', values='Rating')
user_rating_df.head()Thus, we store the normalized users ratings into as a matrix of user-rating called trX, and normalize the values.

- Setting the models parameters
After normalizing our data, we set the model parameters which includes the hidden units and the visible units, after which we add our activation functions f.sigmoid and tf.relu since they are commonly used for RBM's and continue with defining a function to return only the generated hidden states for the hidden layer and also for the reconstructed output

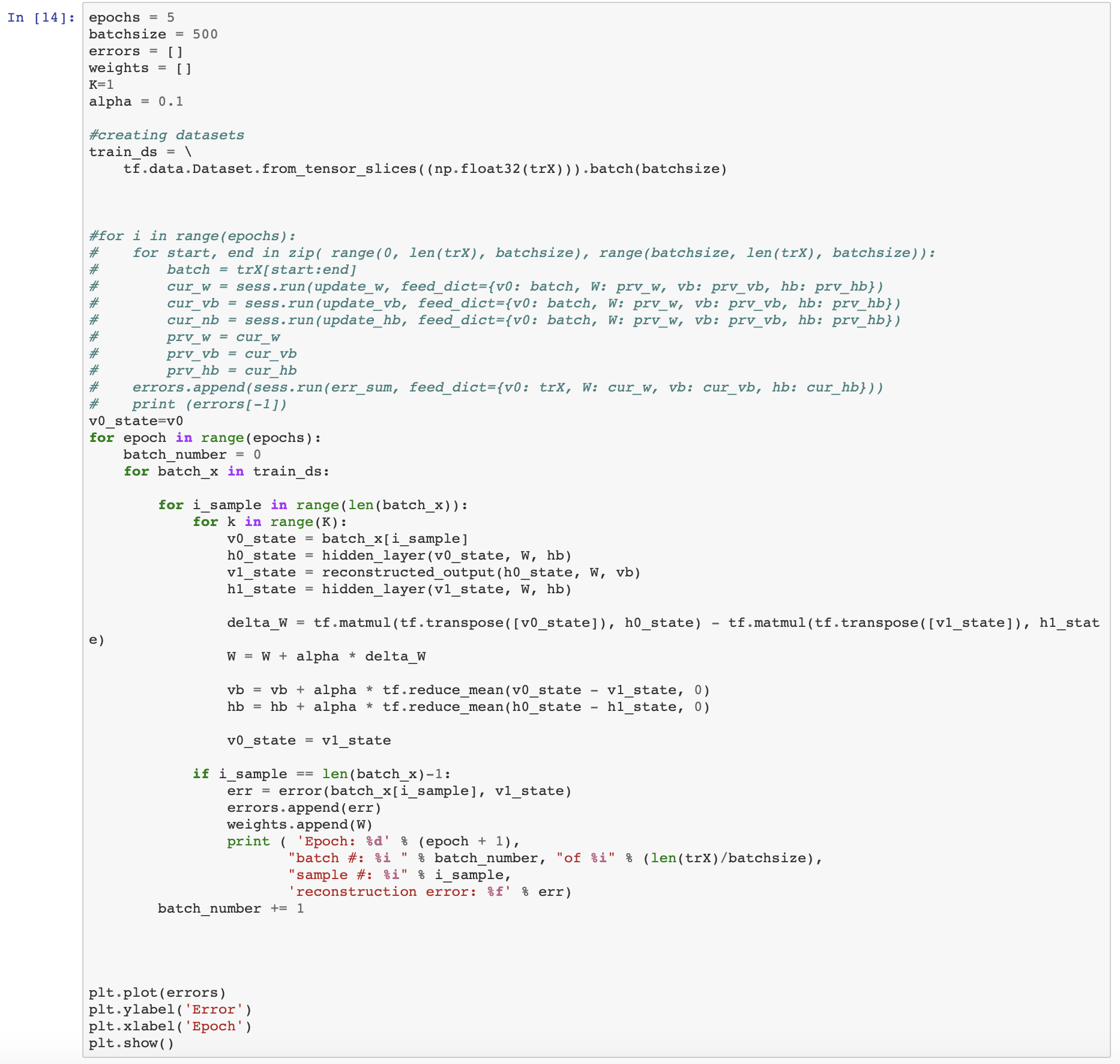
- Train the model
Once the model parameters are set, we train our model with
epochs = 5
batchsize = 500
errors = []
weights = []
K=1
alpha = 0.1
- Create mock user
We create a mock user by providing a mock user id and feeding it into the model

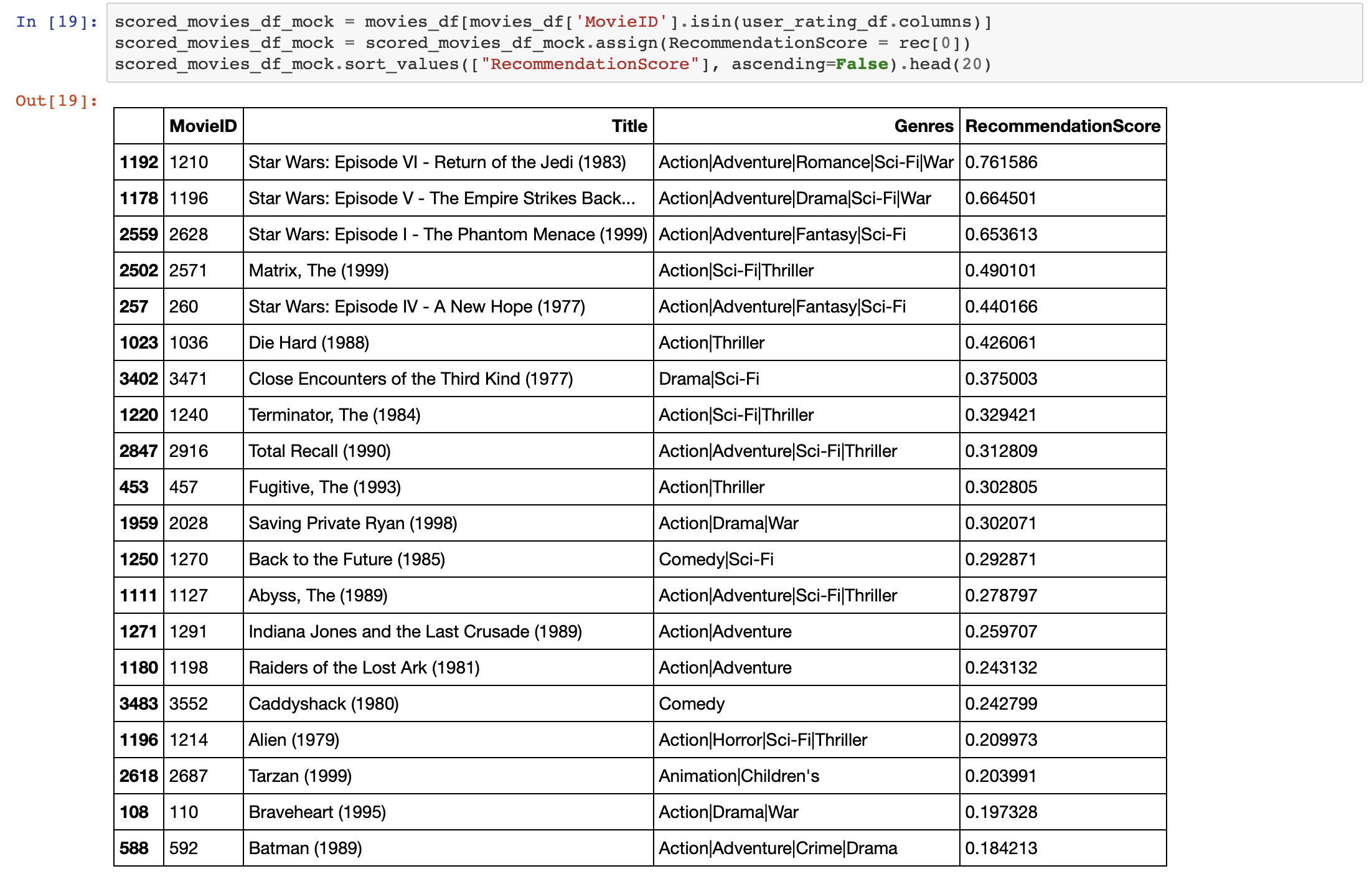
- List recommended movies for mock user
We then list 20 most recommended movies for our mock user by sorting it by their recommendation scores which are provided by the model
- Add timestamp to watched movies
We then add a timestamp based on our user using the ratings_df data frame using the following function
movies_df_mock = ratings_df[ratings_df['UserID'] == mock_user_id]
movies_df_mock.head()

- Merge watched movies with the predicted scores
And then we merge and output the first 20 rows, which will allow us to see the users watched movies as well as recommended movies based on their recommendation score

Finally with this last step we have completed going through our notebook, you can try to change the model parameters such as adding more units to the hidden layer, changing the loss functions to see if anything changes and for more optimization you can change the number of epochs, the size of K, and the batch size are all interesting numbers to explore as they will give a different output.
In this tutorial, you looked at the basics and implementation of Restricted Boltzmann Machines using TensorFlow and created a movie recommendation model based on collaborative filtering, where ratings and users were involved to give the recommendation for the movies a user would be interested to watch.
Login/Sign Up for IBM Cloud: https://ibm.biz/YourPathToDeepLearning
Hands-On Guide: https://github.com/IBMDeveloperMEA/YPDL-Build-a-movie-recommendation-engine-with-TensorFlow
Slides: https://ibmdevelopermea.github.io/YPDL-Build-a-movie-recommendation-engine-with-TensorFlow/
Workshop Replay: https://www.crowdcast.io/e/ypdl-4
Survey: https://ibm.biz/YPDL-Survey