适用于中文领域的基于BERT的预训练语言模型实现,分为两步:预训练和微调。目前已包括BERT、Roberta、ALbert三个模型,且皆可支持Whole Word Mask模式。
本着应用于工业生产的需要,想集成目前业界先进的预训练语言模型,并提供预训练和微调方法以此为用户提供一个端到端的预训练+微调框架。
| 领域 | 模型配置 | 下载地址 |
|---|---|---|
| 法律 | bert_base | torch版本: 刑事领域:[下载地址](链接:https://pan.baidu.com/s/1NQ0qBXyS50jaU2mJ2j9qgw 提取码:kd1q) 民事领域:[下载地址](链接:https://pan.baidu.com/s/12tIjLx4BhDcKc4Pj4ItePg 提取码:rc8p) |
| DistillBERT(通用领域-蒸馏模型) | roberta_wwm_large->roberta_wwm_base | tf版本:[下载地址](链接:https://pan.baidu.com/s/1_oizvXxI1m3L2HsrhiHOOA 提取码:gqbd) |
| ELECTRA(通用领域-对抗学习模型) | bert_tiny | tf版本:下载地址 |
法律领域的预训练模型包括两个子模型:民事领域预训练模型和刑事领域预训练模型,基于bert-base配置进行训练。
预训练语料来源于中国裁判文书网整理的民事领域和刑事领域的裁判文书(89G),其中民事领域文书数量为2500万篇,刑事领域则为900万篇。
该模型的具体细节可以参考this paper。
基于两步走策略训练该模型:
step1:使用roberta_ext_wwm_large模型来获取所有训练示例中的token输出;
step2:使用上述输出来初始化roberta_ext_wwm_base模型的权重,继而继续训练。
预训练语料包括baike_qa2019, news2016_zh, webtext_2019, wiki_zh四个领域。
模型表现(准确率):
Classification
| Model | AFQMC | CMNLI | TNEWS | LCQMC |
|---|---|---|---|---|
| roberta-wwm-ext-base | 74.04% | 80.51% | 56.94% | 86.5% |
| roberta-wwm-ext-base-distill | 74.44% | 81.1% | 57.6% | 87.2% |
SQUAD
| Model | CMRC2018 dev(F1/EM) |
|---|---|
| roberta-wwm-ext-base | 84.72%/65.24% |
| roberta-wwm-ext-base-distill | 85.2%/65.20% |
模型具体细节参考this paper。
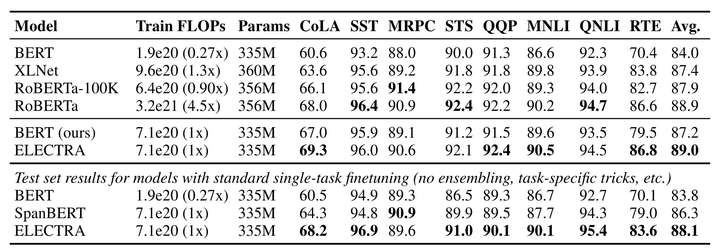
这是我觉得字BERT面世以来最有意义的一次改进,引入CV领域的类GAN机制,利用discriminator与generator来训练模型。在训练方面仅使用了相当于1/4的bert算力。
开源模型包括discriminator与generator两个模型。
模型表现:
1.可以使用TextClassifier_BERTTextSim_cn_finetune两个项目加载上述模型。
2.使用bert4keras加载。
3.使用HuggingFace的Transformers加载。
-
开源更多领域的预训练模型
-
性能对比