This project was developed under a previous phase of the Yale Digital Humanities Lab. Now a part of Yale Library’s Computational Methods and Data department, the Lab no longer includes this project in its scope of work. As such, it will receive no further updates.
Detect and visualize text reuse within collections of plain text or XML documents.
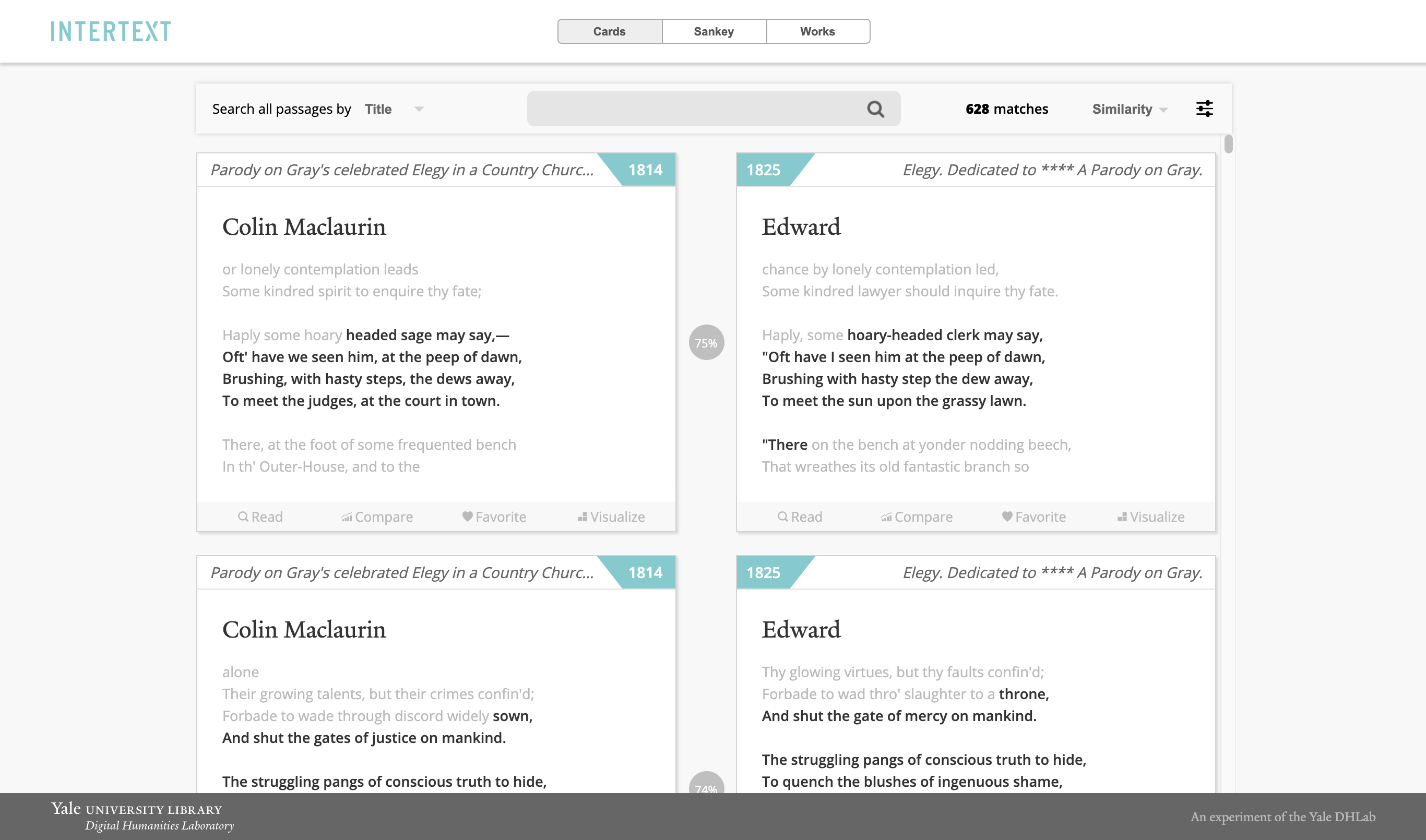
Intertext uses machine learning and interactive visualizations to identify and display intertextual patterns in text collections. The text processing is based on minhashing vectorized strings and the web viewer is based on interactive React components. [Demo]
To install Intertext, run the steps below:
# optional: install Anaconda and set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zip# search for intertextuality in some documents
python intertext/intertext.py --infiles "sample_data/texts/*.txt" --metadata "sample_data/metadata.json" --verbose --update_client
# serve output
python -m http.server 8000Then open a web browser to http://localhost:8000/output and you'll see any intertextualities the engine discovered!
To enable Cuda acceleration, we recommend using the following steps when installing the module:
# set up conda virtual environment
conda create --name intertext python=3.7
conda activate intertext
# set up cuda and cupy
conda install cudatoolkit
conda install -c conda-forge cupy
# install the package
pip uninstall intertext -y
pip install https://github.com/yaledhlab/intertext/archive/master.zipTo indicate the author and title of matching texts, one should pass the flag to a metadata file to the intertext command, e.g.
intertext --infiles "sample_data/texts/*.txt" --metadata "sample_data/metadata.json"Metadata files should be JSON files with the following format:
{
"a.xml": {
"author": "Author A",
"title": "Title A",
"year": 1751,
"url": "https://google.com?text=a.xml"
},
"b.xml": {
"author": "Author B",
"title": "Title B",
"year": 1753,
"url": "https://google.com?text=b.xml"
}
}If your text documents can be read on another website, you can add a url attribute to each of your files within your metadata JSON file (see example above).
If your documents are XML files and you would like to deeplink to specific pages within a reading environment, you can use the --xml_page_tag flag to designate the tag within which page breaks are identified. Additionally, you should include $PAGE_ID in the url attribute for the given file within your metadata file, e.g.
{
"a.xml": {
"author": "Author A",
"title": "Title A",
"year": 1751,
"url": "https://google.com?text=a.xml&page=$PAGE_ID"
},
"b.xml": {
"author": "Author B",
"title": "Title B",
"year": 1753,
"url": "https://google.com?text=b.xml&page=$PAGE_ID"
}
}If your page ids are specified within an attribute in the --xml_page_tag tag, you can specify the relevant attribute using the --xml_page_attr flag.