-
Notifications
You must be signed in to change notification settings - Fork 1
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
5 changed files
with
106 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,12 @@ | ||
| # Debugging jobs | ||
|
|
||
| If a job fails on seqera an intermediate files are lost as the VM state is not saved back | ||
| to the associated blob storage container. This makes debugging a bit more challenging, | ||
| although all relevant inputs are still normally found in the respective working directory | ||
| for a single job. | ||
|
|
||
| ## Debugging on local machine (or any VM or HPC) | ||
|
|
||
| - download the relevant files | ||
| - install the required software using preferrably the method used on Seqera (docker, conda, etc.) | ||
| - run the command that failed and debug |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,47 @@ | ||
| ## Overview | ||
|
|
||
| ## Pipeline parameters in Seqera | ||
|
|
||
| How can directories be set by a browse button? | ||
|
|
||
| [`nf-schema`](https://github.com/nextflow-io/nf-schema) sets this up saving it in a autogenerated `nextflow_schema.json` which | ||
| is part of the root directory of a pipeline repository. | ||
|
|
||
| ## Lauching pipelines | ||
|
|
||
| Make sure to use a batch account with priority VMs to launch a pipeline and have cheaper | ||
| ephermal (non-priority) VMs for the actual pipeline execution of single jobs. | ||
|
|
||
| Each [pool only has one VM size and type](https://learn.microsoft.com/en-us/azure/batch/nodes-and-pools). | ||
| For for complicated setups with different VM | ||
| sizes and types, multiple pools need to be specified (e.g. using process labels using `withLabel`). | ||
| However, as more than one job can run on a big node (which is a single VM) defining | ||
| non too extensive resources for a process is a good way to economically distribute jobs | ||
| on few nodes. This is very similar to computerome2 if you are familiar with that HPC. | ||
|
|
||
| Overview of what happens when you launch a pipeline on Seqera: | ||
|
|
||
| - Seqera Platform authenticates to Azure Batch and Storage as a service principal | ||
| - It adds a task to Azure Batch which runs Nextflow | ||
| - Nextflow starts on a compute node with an attached managed identity, | ||
| this is used by Nextflow to authenticate and start adding jobs and tasks to Azure Batch | ||
| - An Azure Storage Container bucket is used | ||
| as an intermediate working directory for the pipeline | ||
| - ⚠️ unclear if a job fails how the local storage is handled of the node (VM). Intermediate | ||
| data might not be copied back to the storage container. | ||
| - Each task on Azure Batch (including the Nextflow task) will pull a Docker container from a registry as well as remote storage which might be located | ||
| - The node communicates back to Seqera Platform with the current status of the pipeline including completion | ||
| - Seqera Platform will access the logs and results located on Azure Storage, using the service principal for authentication | ||
|
|
||
| ## Using seqera from the command line - tower cli | ||
|
|
||
| Check out if you the `tw` cli tool if you want to automate runs without using the | ||
| web interface at [github.com/seqeralabs/tower-cli](https://github.com/seqeralabs/tower-cli) | ||
|
|
||
|
|
||
| ## Online Resources | ||
|
|
||
| - [Nextflow](https://www.nextflow.io/docs/latest/azure.html) | ||
| - [Platform](https://docs.seqera.io/platform/24.2/compute-envs/azure-batch) | ||
| - [Service Principal](https://docs.seqera.io/platform/24.2/compute-envs/azure-batch#entra-service-principal) | ||
| - [Managed Identity](https://docs.seqera.io/platform/24.2/compute-envs/azure-batch#managed-identity) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,4 @@ | ||
| # QuantMS on Seqera | ||
|
|
||
| - using [azure batch compute environments](https://docs.seqera.io/platform/24.2/troubleshooting_and_faqs/azure_troubleshooting#batch-compute-environments) | ||
| - |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,33 @@ | ||
| # Setup Azure batch compute environments | ||
|
|
||
| Based on our discussion and the | ||
| [documentation](https://docs.seqera.io/platform/24.2/enterprise/advanced-topics/manual-azure-batch-setup) | ||
| and [FAQ](https://docs.seqera.io/platform/24.2/troubleshooting_and_faqs/azure_troubleshooting#batch-compute-environments) | ||
|
|
||
|
|
||
| ## Setup Permissions | ||
|
|
||
| Here are the key points with setting up Azure Infrastructure using | ||
| a Managed Identity and Batch Pool. | ||
|
|
||
| ### On Azure | ||
|
|
||
| - Create a service principal | ||
| - Create a managed identity | ||
| - Assign roles to the service principal and managed identity | ||
| - Increase quota for the Azure Batch Account | ||
| - Create Azure Batch pools in the Batch account | ||
| - Attach nodes to the virtual network in the right subnet | ||
| - Whitelist internet access on the subnet. | ||
|
|
||
| ### On Seqera Platform within a workspace: | ||
|
|
||
| - Admin permissions to add credentials, compute environment(s) and pipelines to a workspace | ||
|
|
||
|
|
||
| ## On VMs as nodes in a pool | ||
| Nodes in a pool are described based on the VM naming convention: | ||
|
|
||
| 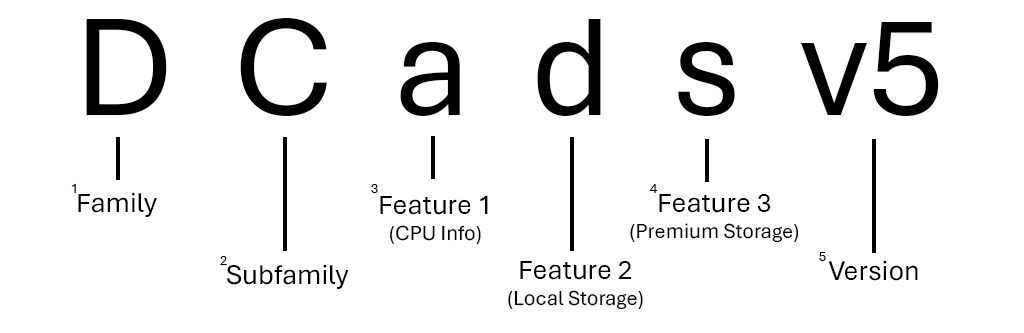 | ||
|
|
||
| See also [Azure Batch documentation](https://learn.microsoft.com/en-us/azure/batch/nodes-and-pools). |