 |
 |
 |
 |
 |
|---|---|---|---|---|
| 서가은 | 서보성 | 오원택 | 이승우 | 정효정 |
부스트 캠프 AI-Tech 5기 NLP 트랙 Level1 경진대회 프로젝트입니다. Semanic Textual Similarity(STS)는 텍스트 쌍의 의미적 유사도를 측정하는 Task로 모델이 의미상 두 문장의 친밀도를 얼마나 잘 잡아내는지 또는 문장의 의미적 표현을 얼마나 잘 구현하는지 평가하는데 일반적으로 사용됩니다.
- 총 데이터 개수 : 10,974 문장 쌍
- Train(학습) 데이터 개수: 9,324 (85%)
- Dev(검증) 데이터 개수: 550 (5%)
- Test(평가) 데이터 개수: 1,100 (10%)
- Label 점수: 0 ~ 5사이의 실수
Test 데이터의 입력에 대한 결과 값들의 피어슨 상관 계수(Pearson Correlation Coefficient)
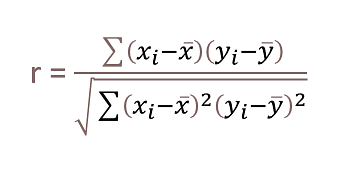
root/
|
|-- code/
| |-- train.py
| |-- inference.py
|
|-- module/
| |-- preprocessing.py
| |-- augmentation.py
| |-- model_params.py
| |-- rdrop.py
| |-- seed.py
| |-- translation.py
| |-- visualization.py
| |-- memo.py
| |-- sweep.yaml- Sentence Refinement
- 특수문자 제거(RegExp)
- 한글 맞춤법검사
- Data Augmentation
- Back Translation
- Easy Data Augmentation
- Token masking & Changing sequence order
- R-Drop
- K-fold
- Model Parameter Freezing
- Label Smoothing
- Add modules to Pre-Trained Model
- Sentence Bert
- Dropout & L2 Regularization
- Model Ensemble
# TRAIN
python3 code/train.py
# INFERENCE
python3 code/inference.py