

Paper: Reliable Fidelity and Diversity Metrics for Generative Models
Muhammad Ferjad Naeem 1,3*, Seong Joon Oh2*, Yunjey Choi1, Youngjung Uh1, Jaejun Yoo1,4
Work done at Clova AI Research
* Equal contribution 1 Clova AI Research, NAVER Corp. 2 Clova AI Research, LINE Plus Corp. 3 Technische Universität München 4 EPFL
Devising indicative evaluation metrics for the image generation task remains an open problem. The most widely used metric for measuring the similarity between real and generated images has been the Fréchet Inception Distance (FID) score. Because it does not differentiate the fidelity and diversity aspects of the generated images, recent papers have introduced variants of precision and recall metrics to diagnose those properties separately. In this paper, we show that even the latest version of the precision and recall (Kynkäänniemi et al., 2019) metrics are not reliable yet. For example, they fail to detect the match between two identical distributions, they are not robust against outliers, and the evaluation hyperparameters are selected arbitrarily. We propose density and coverage metrics that solve the above issues. We analytically and experimentally show that density and coverage provide more interpretable and reliable signals for practitioners than the existing metrics.

- 1 June 2020: Paper accepted at ICML 2020.
Precision and recall are defined below:
where the manifold is the defined as
is the ball around the point
x with radius r.
is the distance to the kth-nearest neighbour.
Density and coverage are defined below:
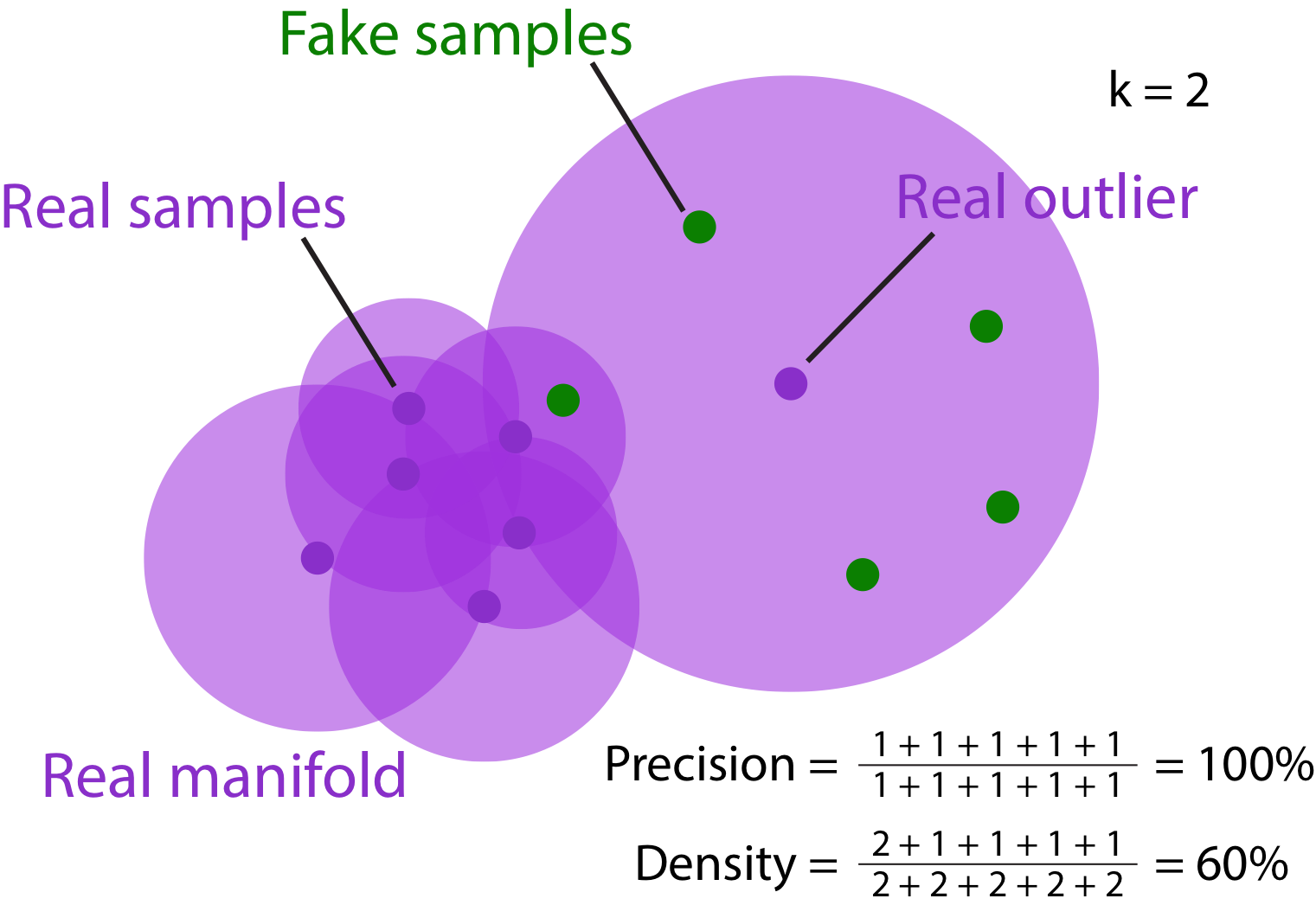
Precision versus Density. Because of the real outlier sample, the manifold is overestimated. Generating many fake samples around the real outlier is enough to increase the precision measure. The problem of overestimating precision (100%) is resolved using the density estimate (60%).
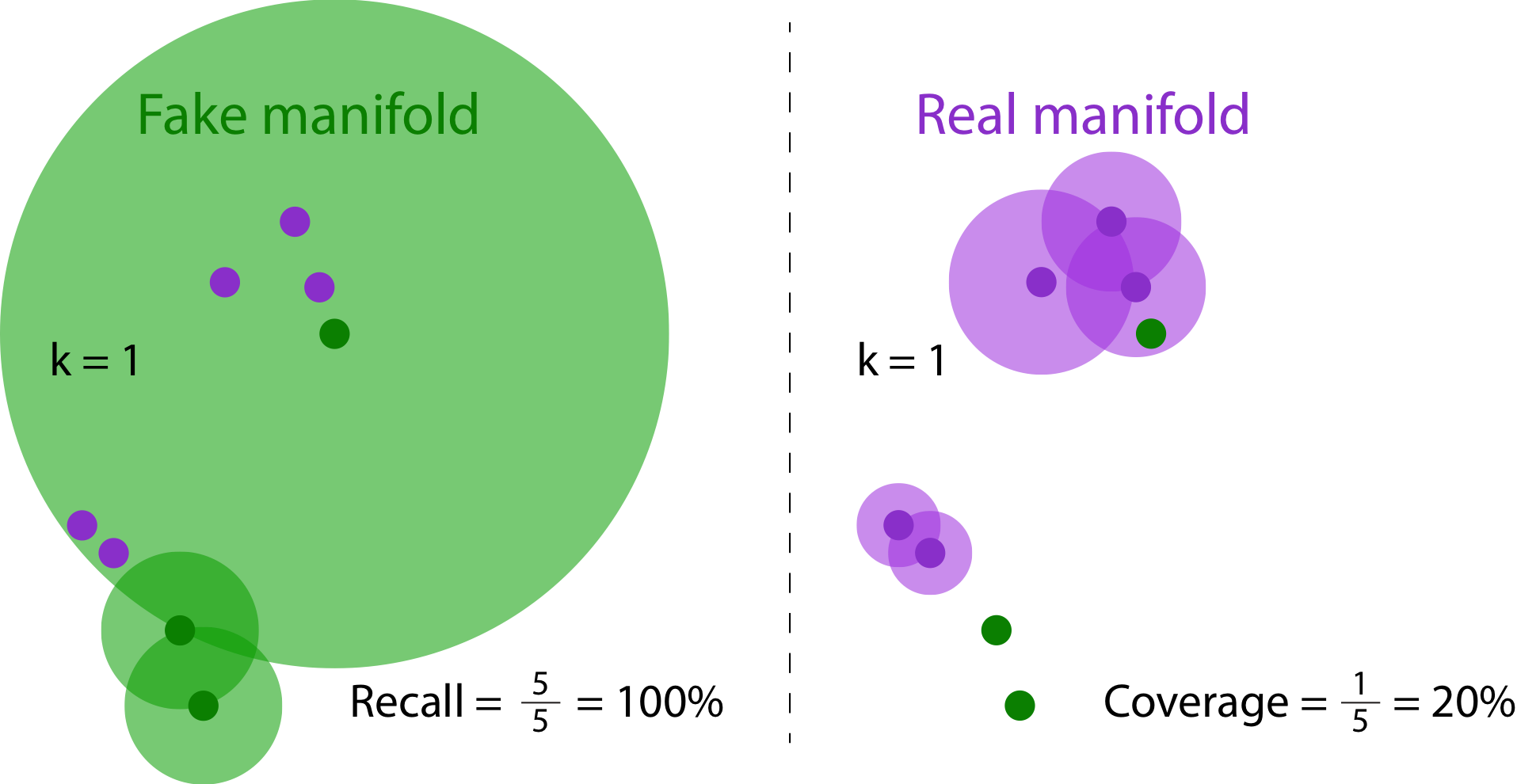
Recall versus Coverage. The real and fake samples are identical across left and right. Since models often generate many unrealistic yet diverse samples, the fake manifold is often an overestimation of the true fake distribution. In the figure above, while the fake samples are generally far from the modes in real samples, the recall measure is rewarded by the fact that real samples are contained in the overestimated fake manifold.
pip3 install prdcTest 10000 real and fake samples form the standard normal distribution N(0,I) in 1000-dimensional Euclidean space.
Set the nearest neighbour k=5. We compute precision, recall, density, and coverage estimates below.
import numpy as np
from prdc import compute_prdc
num_real_samples = num_fake_samples = 10000
feature_dim = 1000
nearest_k = 5
real_features = np.random.normal(loc=0.0, scale=1.0,
size=[num_real_samples, feature_dim])
fake_features = np.random.normal(loc=0.0, scale=1.0,
size=[num_fake_samples, feature_dim])
metrics = compute_prdc(real_features=real_features,
fake_features=fake_features,
nearest_k=nearest_k)
print(metrics)Above test code will result in the following estimates (may fluctuate due to randomness).
{'precision': 0.4772,
'recall': 0.4705,
'density': 1.0555,
'coverage': 0.9735}Kynkäänniemi et al., 2019. Improved precision and recall metric for assessing generative models. Neurips 2019.
Copyright (c) 2020-present NAVER Corp.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
@article{ferjad2020icml,
title = {Reliable Fidelity and Diversity Metrics for Generative Models},
author = {Naeem, Muhammad Ferjad and Oh, Seong Joon and Uh, Youngjung and Choi, Yunjey and Yoo, Jaejun},
year = {2020},
booktitle = {International Conference on Machine Learning},
}