Home
Welcome to MetaFX wiki page!
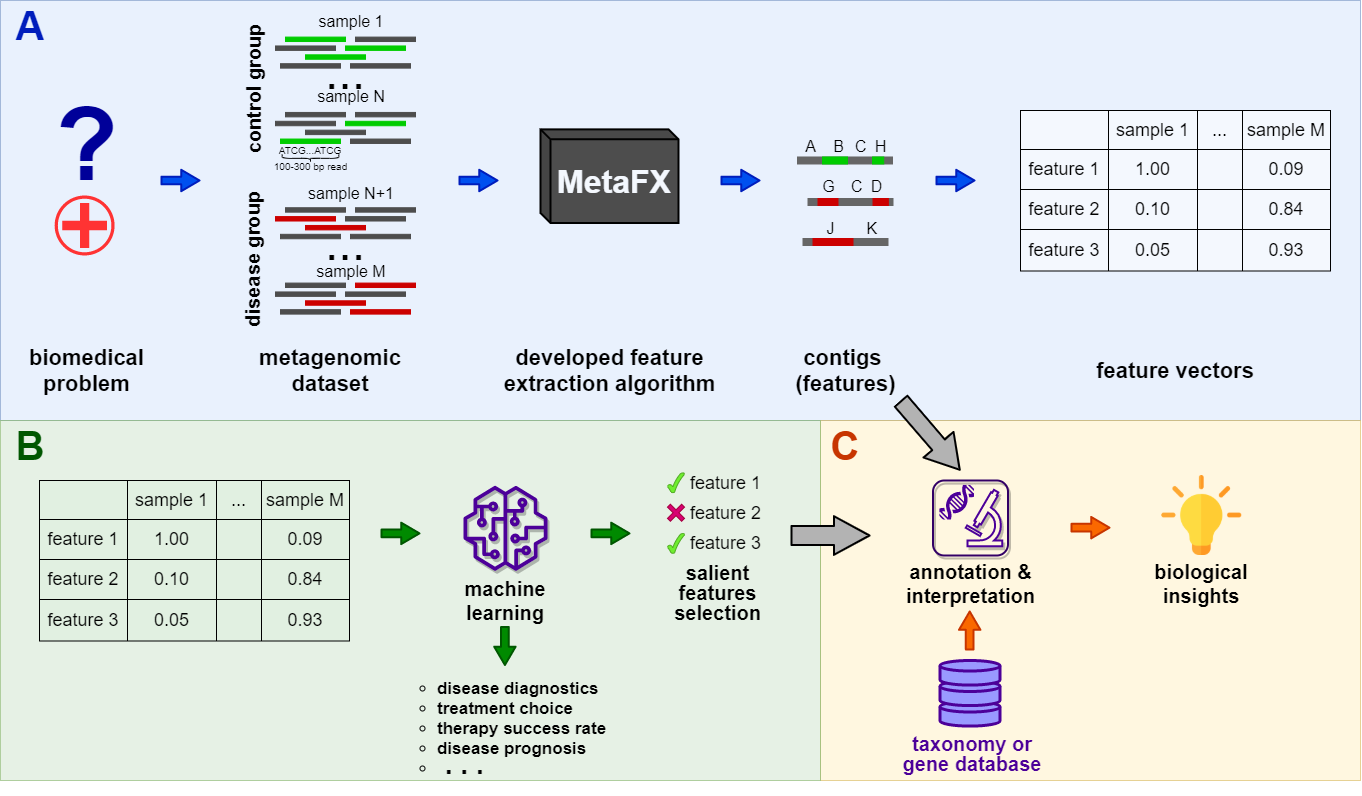
MetaFX (METAgenomic Feature eXtraction) is an open-source library for feature extraction from whole-genome metagenome sequencing data and classification of groups of samples.
The idea behind MetaFX is to introduce the feature extraction algorithm specific for metagenomics short reads data. It is capable of processing hundreds of samples 1-10 Gb each. The distinct property of suggest approach is the construction of meaningful features, which can not only be used to train classification model, but also can be further annotated and biologically interpreted.
To run MetaFX, one need to clone repo with all binaries and add them to PATH.
git clone https://github.com/ivartb/metafx_new
cd metafx_new
export PATH=bin:$PATHRequirements:
- JRE 1.8 or higher
- python3
- python libraries listed in
requirements.txtfile. Can be installed using pip
python -m pip install --upgrade pip
pip install -r requirements.txt- If you want to use
metafx metaspadespipeline, you will also need SPAdes software. Please follow their installation instructions (not recommended for first-time use).
Scripts have been tested under Ubuntu 18.04 LTS and Ubuntu 20.04 LTS, but should generally work on Linux/MacOS.
To run MetaFX use the following syntax:
metafx <pipeline> [<Launch options>] [<Input parameters>]To view the list of supported pipelines run metafx -h or metafx --help.
To view help for launch options and input parameters for selected pipeline run metafx <pipeline> -h or metafx <pipeline> --help.
By running MetaFX a working directory is created (by default ./workDir/).
All intermediate files and final results are saved there.
MetaFX is a toolbox with a lot of modules divided into three groups:
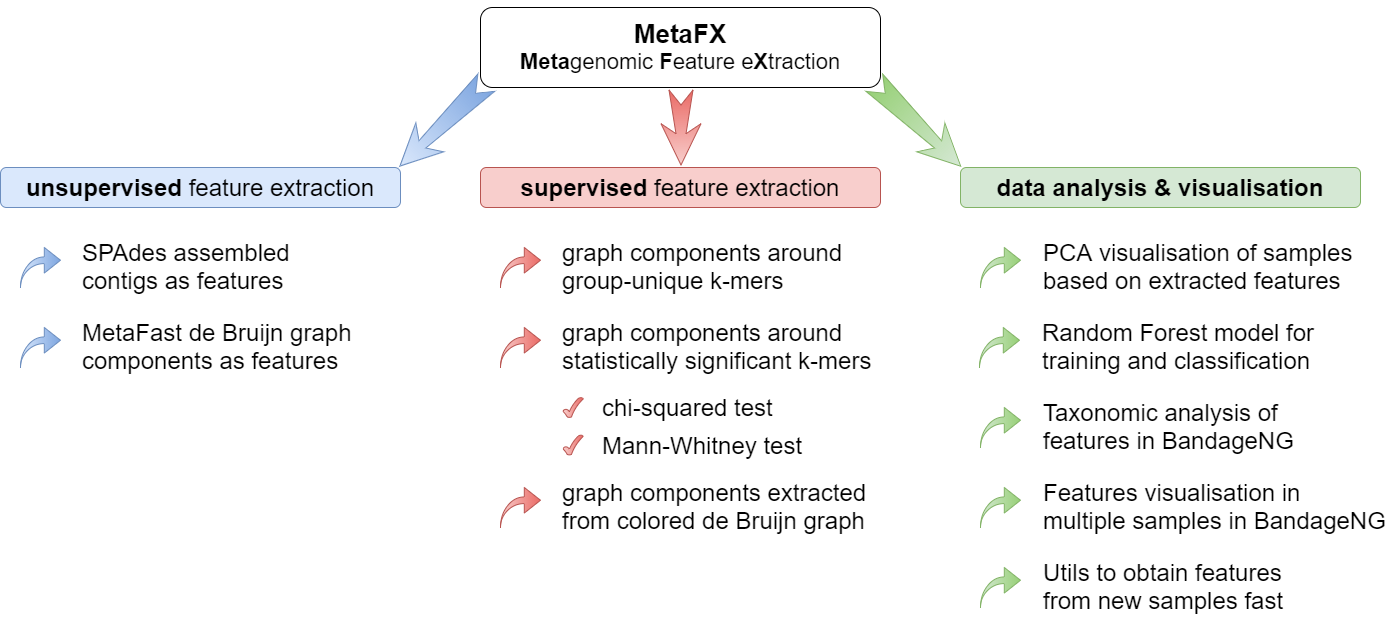
There are pipelines aimed to extract features from metagenomic dataset without any prior knowledge about samples and their relations. Algorithms perform (pseudo-)assembly of samples separately and construct the de Bruijn graph common for all samples. Further, graph components are extracted as features and feature table is constructed.
Performs unsupervised feature extraction and distance estimation via MetaFast (https://github.com/ctlab/metafast/).
metafx metafast -t 2 -m 2G -w wd_metafast -k 21 -i test_data/test*.fastq.gz -b1 100 -b2 500Input parameters
| parameter | description |
|---|---|
| -t, --threads <int> | number of threads to use [default: all] |
| -m, --memory <MEM> | memory to use (values with suffix: 1500M, 4G, etc.) [default: 90% of free RAM] |
| -w, --work-dir <dirname> | working directory [default: workDir/] |
| -k, --k <int> | k-mer size (in nucleotides, maximum value is 31) [mandatory] |
| -i, --reads <filenames> | list of reads files from single environment. FASTQ, FASTA, gzip- or bzip2-compressed [mandatory] |
| -b, --bad-frequency <int> | maximal frequency for a k-mer to be assumed erroneous [default: 1] |
| -l, --min-seq-len <int> | minimal sequence length to be added to a component (in nucleotides) [default: 100] |
| -b1, --min-comp-size <int> | minimum size of extracted components (features) in k-mers [default: 1000] |
| -b2, --max-comp-size <int> | maximum size of extracted components (features) in k-mers [default: 10000] |
| --kmers-dir <dirname> | directory with pre-computed k-mers for samples in binary format [optional] |
Output files
For backward compatibility with supervised feature extraction, every sample belongs to category all.
| file | description |
|---|---|
| wd_metafast/categories_samples.tsv | tab-separated file with 3 columns: <category>\t<present_samples>\t<absent_samples> |
| wd_metafast/samples_categories.tsv | tab-separated file with 2 columns: <sample_name>\t<category> |
| wd_metafast/feature_table.tsv | tab-separated numeric features file: rows – features, columns – samples |
| wd_metafast/contigs_all/seq-builder-many/sequences/component.seq.fasta | contigs in FASTA format as features (suitable for annotation and biological interpretation) |
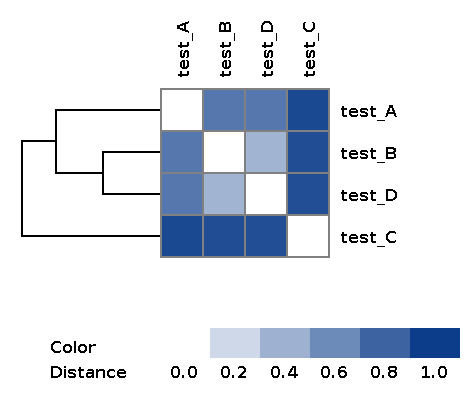
| wd_metafast/matrices/dist_matrix_<DATE_TIME>.txt | Distance matrix between every pair of samples built over feature table using Bray-Curtis dissimilarity |
| wd_metafast/matrices/dist_matrix_<DATE_TIME>_heatmap.png | Heatmap and dendrogram of samples based on distance matrix |
Example of the resulting heatmap with dendrogram:
Performs unsupervised feature extraction and distance estimation via metaSpades (https://cab.spbu.ru/software/meta-spades/)
metafx metaspades -t 2 -m 4G -w wd_metaspades -k 21 -i test_data/test_*.fastq.gz -b1 500 -b2 5000Input parameters
| parameter | description |
|---|---|
| -t, --threads <int> | number of threads to use [default: all] |
| -m, --memory <MEM> | memory to use (values with suffix: 1500M, 4G, etc.) [default: 90% of free RAM] |
| -w, --work-dir <dirname> | working directory [default: workDir/] |
| -k, --k <int> | k-mer size (in nucleotides, maximum value is 31) [mandatory] |
| -i, --reads <filenames> | list of PAIRED-END reads files from single environment. FASTQ, FASTA, gzip-compressed [mandatory] |
| --separate | if TRUE use every spades contig as a separate feature (-l, -b1, -b2 ignored) [default: False] |
| -l, --min-seq-len <int> | minimal sequence length to be added to a component (in nucleotides) [default: 100] |
| -b1, --min-comp-size <int> | minimum size of extracted components (features) in k-mers [default: 1000] |
| -b2, --max-comp-size <int> | maximum size of extracted components (features) in k-mers [default: 10000] |
| --kmers-dir <dirname> | directory with pre-computed k-mers for samples in binary format [optional] |
Output files
For backward compatibility with supervised feature extraction, every sample belongs to category all.
| file | description |
|---|---|
| wd_metaspades/categories_samples.tsv | tab-separated file with 3 columns: <category>\t<present_samples>\t<absent_samples> |
| wd_metaspades/samples_categories.tsv | tab-separated file with 2 columns: <sample_name>\t<category> |
| wd_metaspades/feature_table.tsv | tab-separated numeric features file: rows – features, columns – samples |
| wd_metaspades/contigs_all/seq-builder-many/sequences/component.seq.fasta | contigs in FASTA format as features (suitable for annotation and biological interpretation) |
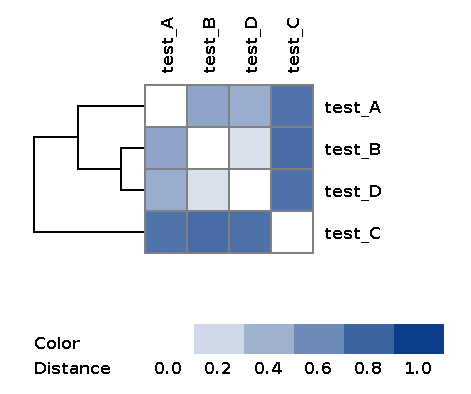
| wd_metaspades/matrices/dist_matrix_<DATE_TIME>*.txt | Distance matrix between every pair of samples built over feature table using Bray-Curtis dissimilarity |
| wd_metaspades/matrices/dist_matrix_<DATE_TIME>*_heatmap.png | Heatmap and dendrogram of samples based on distance matrix |
Example of the resulting heatmap with dendrogram:
There are pipelines aimed to extract group-relevant features based on metadata about samples such as diagnosis, treatment, biochemical results, etc. Dataset is split into groups of samples based on provided metadata information and group-specific features are constructed based on de Bruijn graphs. The resulting features are combined into feature table.
TODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODO
Input parameters
| parameter | description |
|---|---|
Output files
| file | description |
|---|---|
TODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODO
Input parameters
| parameter | description |
|---|---|
Output files
| file | description |
|---|---|
TODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODO
Input parameters
| parameter | description |
|---|---|
Output files
| file | description |
|---|---|
There are pipelines for analysis of the feature extraction results. Methods for samples similarity visualisation and training machine learning models are implemented. Classification models can be trained to predict samples' properties based on extracted features and to efficiently process new samples from the same environment.
TODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODO
Input parameters
| parameter | description |
|---|---|
Output files
| file | description |
|---|---|
TODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODO
Input parameters
| parameter | description |
|---|---|
Output files
| file | description |
|---|---|
TODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODO
Input parameters
| parameter | description |
|---|---|
Output files
| file | description |
|---|---|
TODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODO
Input parameters
| parameter | description |
|---|---|
Output files
| file | description |
|---|---|
TODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODO
Input parameters
| parameter | description |
|---|---|
Output files
| file | description |
|---|---|
TODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODOTODO
Input parameters
| parameter | description |
|---|---|
Output files
| file | description |
|---|---|
Minimal example is provided in the README page.
More sophisticated example is presented as a jupyter notebook with links to input and output data, all commands and commentaries.