-
-
Notifications
You must be signed in to change notification settings - Fork 2
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
6b291e2
commit 2161c70
Showing
1 changed file
with
60 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,60 @@ | ||
| --- | ||
| title: Một số thủ thuật nhỏ khi crawl data | ||
| author: trannguyenhan | ||
| date: 2024-10-01 20:52:00 +0700 | ||
| categories: [Crawler] | ||
| tags: [Crawler] | ||
| math: true | ||
| mermaid: true | ||
| image: | ||
| src: https://raw.githubusercontent.com/demanejar/image-collection/main/ScrapySplash/scrapy_splash_795857e959.png | ||
| --- | ||
|
|
||
| ## Biến của Javascript có thể chứa dữ liệu cần thiết khi crawl website render bằng Javascript | ||
|
|
||
| Khi crawl các trang web render bằng Javascript như bài viết trước chúng ta phải sử dụng một trình biên dịch phía trước để dịch các đoạn mã Javascript này để chúng render ra HTML trước khi tiến hành phân tích. Tuy nhiên rất nhiều trang web khi load HTML về nó đã mang dữ liệu rồi. Ví dụ như Youtube khi load HTML về có đoạn mã trên header như dưới này: | ||
|
|
||
| ```javascript | ||
| var ytInitialData = {"responseContext":{"serviceTrackingParams":[{"service":"GFEEDBACK","params":[{"key":"route","value":"channel."},{"key":"is_owner","value":"false"},{"key":"is_alc_surface","value":"false"},{"key":"browse_id","value":"UCHP_xaIhyLPZv90otD2SehA"},{"key":"browse_id_prefix","value":""},{"key":"logged_in","value":"1"},{"key":"e","value":"9405957,23804281,23966208,23986031,24004644,24077241,24108448,24166867,24181174,24241378,24290971,24425061,24439361,24453989,24495712,24542367,24548629,24566687,24699899,39325798,39325815,39325854,39326587,39326596,39326613,39326617,39326681,39326965,39327050,39327093,39327367,39327561,39327571,39327591,39327598,39327635,51009781,51010235,51017346,51020570,51025415,51030101,51037344,51037349,51041512,51050361,51053689,51057842,51057855,51063643,51064835,51072748,51091058,51095478,51098297,51098299,51101169,51111738,51112978,51115184,51124104,51125020,51133103,51134507,51141472,51144926,51145218,51151423,51152050,51153490,51157411,51157430,51157432,51157841,51157895,51158514,51160545,51162170,51165467,51169118,51176511,51177818,51178310,51178329,51178344,51178353,51178982,51183909,51184990,51186528,51190652,51194136,51195231,51204329,51209050,5.. | ||
| ``` | ||
|
|
||
| biến này chứa rất nhiều dữ liệu và trong đó có rất dữ liệu mà cần thiết mà không cần lấy ở đâu nữa cả, ví dụ dưới này là một phần nhỏ mình chụp trên dữ liệu của biến `ytInitialData`, vì nó rất nhiều nên không thể chụp hết được. Thông tin chúng ta có được là rất nhiều: tên, mô tả, endpoint, số lượt xem, ngày công bố,... của video. | ||
|
|
||
| 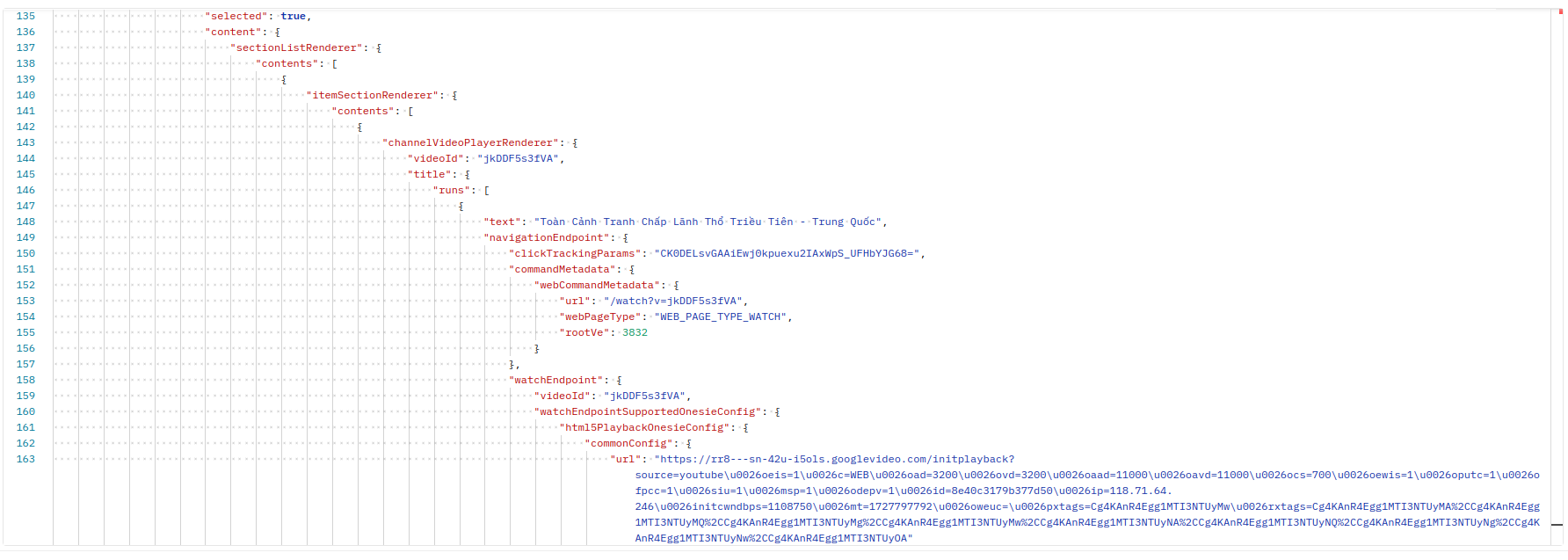 | ||
|
|
||
| ## Sử dung các trang web cache | ||
|
|
||
| Các trang webcache như Google Cache hay web archive họ đã vào các trang web này để crawl một lần rồi và lưu lại thông tin trang web đó chúng ta có thể crawl thông tin thông qua các trang này. | ||
|
|
||
|  | ||
|
|
||
| ## Scrapy getting_forbidden by robots.txt | ||
|
|
||
| Từ phiên bản scrapy 1.1 (2016-05-11) dowloader sẽ tải về tập robots.txt trước khi bắt đầu crawling. Để thay đổi điều này thay đổi trong setting.py: | ||
|
|
||
| ```python | ||
| ROBOTSTXT_OBEY = False | ||
| ``` | ||
|
|
||
| => Liên quan tới các vấn đề bản quyền. Chuyển đổi thành `= True` để tiếp tục crawl ở 1 số trang web. | ||
|
|
||
| ## Các loại trang Facebook | ||
|
|
||
| - [mbasic.facebook.com](mbasic.facebook.com): trang tĩnh -> không có js, chỉ có html | ||
| - [touch.facebook.com](touch.facebook.com), [m.facebook.com](m.facebook.com): là các trang dạng cho mobile cũ (dùng các user agent cũ hay user agent web), nếu dùng user agent cho mobile thì website trả về là dạng khá mới, cực khó phan tích | ||
| - [www.facebook.com](www.facebook.com): giao diện chính, khó phân tích tuy nhiên không phải là không thể | ||
|
|
||
| Tùy vào nhu cầu và mục đích lấy dữ liệu chúng ta có thể sử dụng trang phù hợp. Ví dụ nếu dùng Jsoup Java không thể crawl trang web gen Javascript vậy thì crawl trực tiếp từ trang mbasic sẽ rất phù hợp,... | ||
|
|
||
| ## Trick nhỏ crawl Facebook | ||
|
|
||
| Cái gì nhanh, thao tác liên tục bất thường thì trước sau gì cũng checkpoint, nên cần kết hợp nhiều yếu tố để giảm thiểu: | ||
|
|
||
| - Switch nhiều cookie + kết hợp switch ip | ||
| - Dùng cookie thay vì dùng token | ||
| - Delay chương trình chậm lại sau mỗi thao tác | ||
|
|
||
| ## Bypass Cloudflare | ||
|
|
||
| Sử dụng thw viện [https://pypi.org/project/undetected-chromedriver/2.1.1/](https://pypi.org/project/undetected-chromedriver/2.1.1/), mình đã thử và rất hiệu quả. | ||
|
|